EP 87
'딸깍'의 시대, 슬픔과 기쁨 사이
인트로: AI 딸깍 시대의 불안감 00:00
노정석 녹화를 하고 있는 오늘은 2026년 2월 21일 토요일 아침입니다. 지난주에 신정규 대표님 세션을 했고, 그야말로 발전이 더 빨라지는 것 같잖아요. 사방에서 딸깍딸깍딸깍 하루 만에 만든, 일주일 만에 만든 양질의 소프트웨어들이 쏟아져 나오고 있어서 저희도 정신이 없는데요. 이와 함께 대두되는 의견이, 너무 짜증 난다, 우울하다, 이걸 어떻게 해결해야 되냐는 목소리가 좀 있어요.
최승준 제가 짜증이나 우울이라는 표현을 직접적으로 많이 쓰지는 않는데, 내심 그렇게 느끼는 부분이 있는 것 같습니다. OpenClaw 즈음인 것 같아요. 에이전트 swarm, 에이전트 팀이 나오면서 뭔가를 많이 돌리는 트렌드를 제가 잘 따라가지 못한다는 느낌을 받았고, 그래서 1, 2월을 빠르게 가기보다는 천천히 생각하는 쪽으로 가고 있긴 한데, 천천히 생각하다 보니 배경은 빠르게 지나가고 있어서 FOMO가 오는 악순환이 좀 있는 것 같습니다. 최근에 있었던 일도 살펴보고, 아직 저도 정답은 없습니다만, 나름의 방식으로 어떻게 풀어내고 있는지 좀 이야기해 보려고 합니다.
MVK: 모르는 채로도 옳은 방향으로 01:15
최승준 제가 2월 초에 Uneven Future에서 발표했을 때 마지막 슬라이드가 “모르는 채로도 옳은 방향으로 나아가려면 최소한 무엇을 알아야 할까”였어요. MVK, Minimum Viable Knowledge, 저희 채널에서도 몇 번 말씀드렸는데, 그걸로 이야기하면서 마무리했었고, 계속 머릿속에 있는 화두예요. 이걸 어떻게 알아갈 수 있을까 하는 고민을 하고 있는데, 오늘 이야기도 관련 있는 흐름이 될 것 같습니다.
METR 벤치마크 포화: Claude Opus 4.6의 14시간 01:47
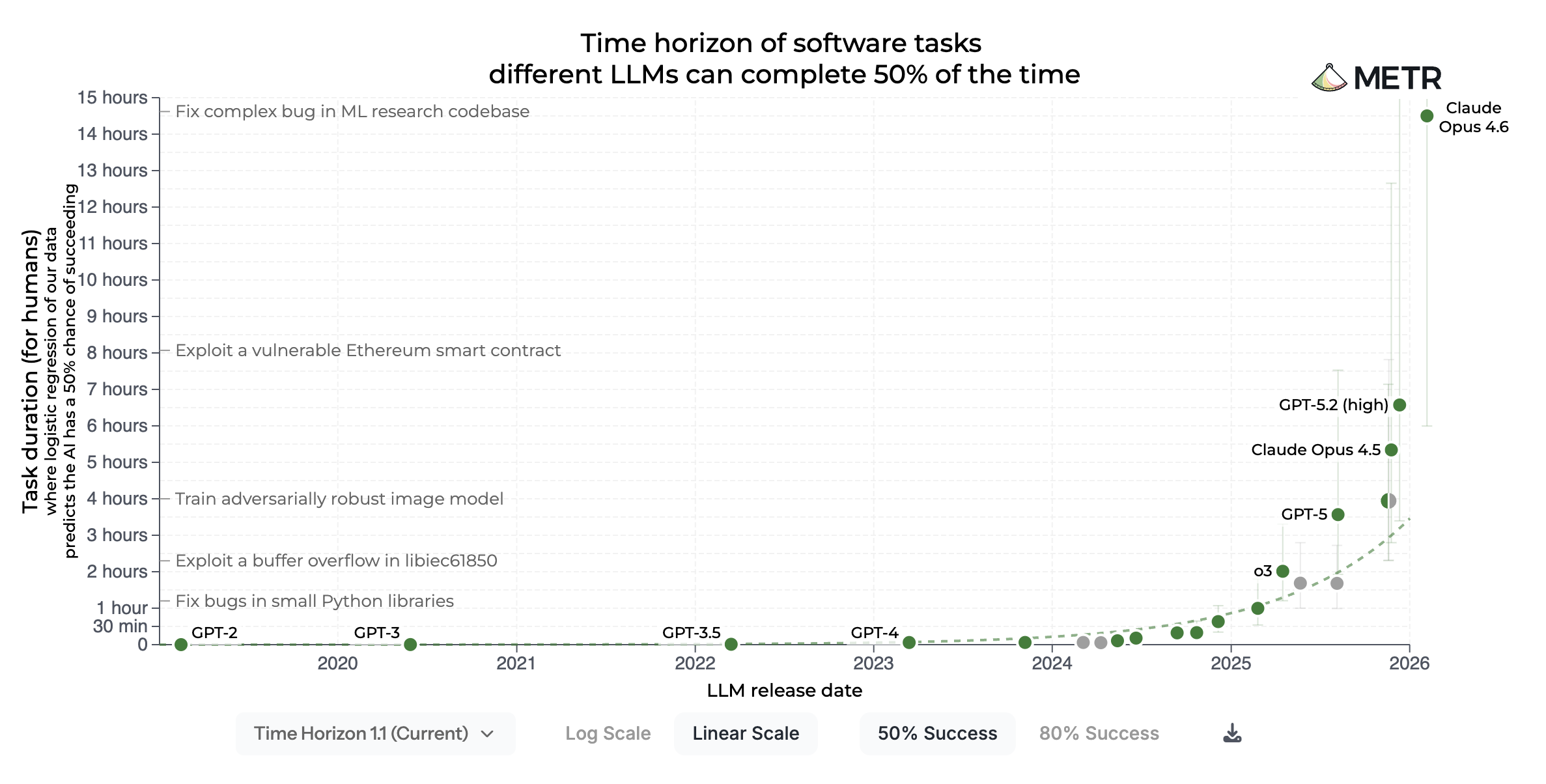
최승준 그 전에, 오늘 새벽에 나온 뉴스인데요. METR에서 Claude Opus 4.6을 측정한 결과를 발표했어요. 그런데 14시간이 나와버렸어요. 저희가 계속 녹화하면서 내년 한 5월, 7월쯤이면 인간 풀 데이 8시간이 될 거 아니냐, 그런 얘기를 했었잖아요. GPT-5.2가 거의 5시간을 끊더니, 4.6이 — 지금 로그 그래프라서 큰 차이 없어 보이고 예상 범위 안이구나 느껴지는데, 리니어로 보면 저만큼 있는 거예요.
노정석 빵 뛰었네요.
최승준 METR에서도 우리 과제가 포화된 것 같다, 다른 것들을 준비 중이라고 했어요. 이 그래프가 의미를 상실하는 순간에 온 것 같습니다.
노정석 사실 그래프의 목적 자체가 AI가 사람의 개입 없이 얼마나 혼자 오래 일할 수 있느냐였는데, 저희가 하루에 8시간 일하잖아요. 그 8시간도 집중해서 일하는 게 아니고 한 3~4시간 일한다고 했을 때, 14시간은 일만 할 거니까.
최승준 그렇죠. 50% 버전이 있고 80% 버전이 있고, 단순히 오래 하는 게 아니라 사람이 일하는 시간에 대응해서 측정하는 건데, 어쨌든 사람이 16시간 할 일의 50% 성공률로 AI가 수행하고 있다는 해석이지만, 포화됐다는 뉴스로 오늘 새벽이 시작됐습니다. 그리고 0.1씩 올리는 게 트렌드가 되고 있는 것 같아요. Sonnet 5가 나온다고 했었는데 4.6이 나왔습니다. 지난주에 아직 제대로 써보지 못했습니다. Claude Opus 4.6을 쓰는 관성이 있어서 Opus를 계속 돌리고 있고, 4.6도 아마 잘하겠죠. 더 저렴하게 할 것 같고.
Gemini 3.1 Pro와 끝없이 나오는 새 모델들 03:40

최승준 그다음에 Gemini 3.1 Pro가 발표됐죠. 벤치마크는 그래도 천장이 꽤 높은 것 같아요. 이것보다 더 좋아질 수 있나 싶은데 계속 더 좋아지고 있으니까 앞으로도 더 좋아질 것 같긴 합니다. 지금 이 정도가 Gemini 3.1 Pro라고 Jeff Dean이 올렸네요. Google AI Studio에서 들어가서 써볼 수 있는데, 제가 어젯밤에 돌린 게 10시간 돌아가고서 생성이 안 됐습니다. 뭐가 나올까 두근두근했는데, 녹화 직전에 뭔가 오류가 있다고 하더라고요. 아직 제대로 성능 테스트를 못 했고요. 모델은 계속 나오고 있다는 거죠. 어떻게 평을 해야 될까요? 이제는 약간 무덤덤한 것 같기도 하고.
노정석 모델이 사실 general함의 끝판왕이잖아요. 뭐든 다 할 수 있는 능력인데, 가장 general한 게 가장 specific한 거다라고 엊그제 Claude Code 만든 Boris Cherny가 Y Combinator 유튜브에 나와서 얘기하더라고요. 그 강력한 general한 지능으로 다른 도메인들도 다 끝장을 내고 있잖아요. 그 영향을 요새 많이 받고 있는 게 과학인 것 같고, 아마 그 얘기 해주실 것 같은데, 안 되는 게 없어요. 바라보고 있는 것만으로도 좀 힘들어요.

최승준 물론 일상생활에서 사용하다 보면 삐걱거리는 부분이 있긴 하지만, 방향성 자체는 계속 안 되던 게 되는 방향인 건 분명하죠. 2월 18일이니까 며칠 전인데요. Chris Lattner라고 LLVM 만들고 Swift도 만들고 Apple에 있다가 Tesla 갔다가 지금은 Modular 만드는 회사를 차렸죠. 그분이 원래 컴파일러 하시던 분이니까 컴파일러를 잘 알지 않겠습니까? Claude Code의 C 컴파일러가 나왔을 때, 그날 포스팅은 내가 여태까지 봤던 컴파일러 관련 문서화의 최고봉인 것 같다는 정도의 인상평을 남기고 좀 들여다보겠다고 했었는데, 들여다본 내용을 블로그에 자세히 써놓은 걸 번역해 봤습니다. 앞부분은 교과서적인 가치가 있을 정도의 구현이라는 얘기를 해요. 칭찬하는 부분이 좀 있었고, 물론 아쉬운 부분도 있고. 제대로 된 방향성을 가지고 있고, slop은 아니고, 살펴볼 만한 가치가 있다. commit 히스토리가 있기 때문에 그걸 살펴보는 내용이 꽤 의미 있다, 같은 얘기들을 합니다.
Chris Lattner의 Claude C 컴파일러 심층 리뷰 05:11
최승준 뭘 잘못했나 하는 부분을 짚어 준 게 있는데, Claude C 컴파일러에서 가장 드러나는 부분은 실수예요. 테스트에 필요한 것을 하드 코딩해 놓은 게 가장 큰 문제인데, 이건 테스트 스위트를 넘어 일반화하기 어렵다는 신호고, 놀랍다기보다는 유익한 정보인 것. 현재 AI 시스템은 이미 알려진 기법을 조합하고 측정 가능한 성공 기준에 맞춰 최적화하는 데는 탁월하지만, 프로덕션 수준 시스템에 필요한 열린 형태의 일반화에는 어려움을 겪는다는 점을 보여준다.
이 관찰이 더 깊은 질문으로 이어지는데, AI 코딩 자체에 대해 무엇을 말해주고 있나 하는 부분을 재미있게 이야기했습니다. 저는 이 부분을 중요하게 봤는데요. 한계 부분을 보면, 알려진 추상화를 구현하는 것과 새로운 추상화를 발명하는 것은 다릅니다. 반복적인 허드렛일을 제거하고 최신 모범 사례에서 더 가까운 출발점에서 시작하게 해주는 이정표 역할은 하지만, 새로운 추상화를 발명하지는 못하고 있고, 이 구현에서 새로운 것은 보이지 않는다. 하지만 교과서적인 구현인 건 맞다.
맺음말에서 이런 얘기를 합니다. 소프트웨어의 종말이나 엔지니어의 종말을 이야기하지 않는다. 그런 건 좀 hype이고, 오히려 문을 더 활짝 열어놓는 일에 가깝다. 구현이 쉬워질수록 진짜 혁신이 들어설 공간은 더 커진다는 거죠. 구현 장벽이 낮아진다고 엔지니어의 중요성이 줄어들지 않고, 오히려 비전, 판단, 취향의 중요성이 더 커집니다. 만들기가 쉬워질수록 무엇이 만들 가치가 있는지를 결정하는 일이 더 어려운 문제가 됩니다. AI는 실행을 가속하지만 의미와 방향, 책임은 근본적으로 인간의 몫으로 남습니다. 이 얘기도 의미심장하네요. 코드를 쓰는 일은 목표였던 적이 없다. 목표는 의미 있는 소프트웨어를 만드는 것이다. 미래는 새로운 도구를 받아들이고 가정을 의심하며 사람들이 함께 만들 수 있도록 돕는 시스템을 설계하는 팀의 것이다.
Andrej Karpathy의 9의 행진: 90%와 99.99% 사이 08:35
노정석 지난주에 신정규 대표님도 오셔서 똑같은 말씀하셨죠. 결국 소프트웨어 로직이 목적물이지, 코드는 그 로직을 구현하는 중간 도구에 불과한 거고, 그게 없어지고 있는 거잖아요. Andrej Karpathy가 예전에 어떤 강연에서 “9의 행진”이란 말을 했었잖아요. “March of Nines”라는 표현을 썼는데, 처음 90%에 들어가는 노력, 90%를 99%로 만드는 거, 99를 99.9, 99.99로 만드는 거, 각각 9를 하나 더 붙일 때마다 들어가는 노력의 크기가 똑같다. Claude C 컴파일러도 한 90%까지는 그냥 해주는 거고, 좀 과장하면 99%까지는 해주는 거고, 그러나 99.99%의 입장에 있는 거장의 눈에는 그 모자라는 0.99%가 어마어마하게 큰 갭으로 느껴질 것 같고, 그 갭이 느껴지는 부분이 아까 승준님이 마지막에 정리해 주셨던 굉장히 인간적인 가치, 취향이라든지 의지라든지 하는 부분에 더 있다. 우리는 앞으로 할 일이 많다, 이런 이야기로 끝맺음해 준 것 같습니다.
최승준 중요한 의미를 가지고 있지만 아직 혁신까지 이르지는 못했다는 게 Lattner가 한 이야기고, 그럼에도 살펴볼 가치는 이 방향성이 의미하는 바, 그리고 이게 뉴노멀이 됐을 때 우리는 무엇을 할 수 있는지를 생각하는 것이 중요하다는 부분을 다시 한번 강조해 보고요. 취향이라는 말을 했잖아요. 저희가 취향이라는 얘기를 반복해서 하고 있는데, 최근에 몇 번 말씀드렸던 강규영 님이 현재 Corca의 CTO로 계신데, “취향이 있는 소프트웨어”라는 글을 쓰고 계신 것 같더라고요. 이 글도 재미있으니까 한번 살펴보시면 좋을 것 같습니다.
모든 것을 검색 문제로: 과학과 신약 개발 10:12
최승준 과학이나 수학에서는 알려진 문제를 반복하는 게 아니라 혁신이 필요하잖아요. 지금 거기서도 무슨 일이 일어나고 있거든요.
노정석 심심치 않게 계속 나오는데 저희가 다 들여다보지 못하고 있죠. 심하게 요약하면, 신약 개발이라는 것도 문제를 일으키는 단백질을 찾고, 그 단백질이 무언가를 발현하는 데 들어가는 기작이 있잖아요. 그걸 방해하거나 촉진하는 형태의 물질, 소위 항체라고 하는 물질을 만들어서 그 과정을 화학적으로 방해하는 게 대부분 약의 기작인 경우가 많거든요. 결국 단백질의 구조를 파악하고, 거기에 들어맞는 다른 구조를 찾는 게임이거든요. 이런 부분도 다 연산으로 치환해서 검색 문제로 풀 수 있다는 걸 지금 보여주고 있죠.
OpenAI 이론물리 사례와 켄타우로스 시대 11:07

최승준 이 내용 말고, 제가 번역하면서 꼼꼼하게 읽은 건 OpenAI의 이론 물리학 논문 사례입니다. OpenAI와 과학 편을 제가 작년 말에 좀 강조했었는데, Kevin Weil이랑 블랙홀 연구하는 과학자의 예를 소개해 드렸었잖아요. 그분이 다른 연구자들, 자기 스승 포함해서 이론 물리학의 첨병에 있는 분들을 OpenAI로 데려와서 같이 뭔가를 얘기하다가 논문이 하나 나온 사례입니다. OpenAI에 들어온 블랙홀 연구하는 과학자분의 스승인데, 1년 전만 해도 AI가 얼마나 도움이 될지 모르겠다는 생각이었고, 2024년 정도 또는 2025년 초에만 해도 그랬는데, 1년 뒤에 GPT-5.2 Pro와 몇 차례 주고받은 끝에 OpenAI 내부 모델에 최종 질의를 보냈고, 그 모델이 양자장론에서 이전에는 풀리지 않았던 문제를 해결했을 뿐 아니라 증명까지 해냈다. 12시간 만에. 모델이 해당 분야에서 세계에서 가장 똑똑한 사람들 중 2명이 해내지 못했던 일을 해낸 것이다. 내가 그들과 함께 있었을 때, 그들은 들떠 있었다. 이런 얘기.
노정석 그러니까요.
최승준 코딩은 이미 켄타우로스 너머의 시절로 가기 시작했는데, 과학은 켄타우로스의 시절로 돌입한 느낌이에요. Gary Kasparov가 Deep Blue에게 지고서 체스 분야에서 켄타우로스 개념이 나왔었거든요. 켄타우로스가 반인반마잖아요. AI와 사람이 같이 팀을 짜면 AI 혼자나 사람 혼자보다 더 잘한다는 식의 켄타우로스 방식 체스가 유행했던 적이 있어요. 과학은 드디어 켄타우로스의 시절, AI와 같이 하는 시절에 돌입했고, 코딩은 AI에게 훨씬 더 위임하는 쪽으로 가서 과학이랑 수학이 그 뒤를 따라가고 있는 느낌을 받고 있습니다.
노정석 정말 모든 문제가 탐색 문제로 바뀌고 있는 것 같아요. 전기와 더 많은 연산을 투입해서 가보지 않은 곳들을 지금 추론 토큰이 다 가보고 있는 거잖아요. 예전에 사람이 하나하나 생각하면서 했을 일들을 이제 다 연산으로 치환하고 있는 것 같아요.
최승준 이들의 경험에 대한 얘기가 트위터에서는 왈가왈부하거든요. 어쨌든 이 블로그의 주변부나 당사자들이 하는 이야기는, 2026년에 AI가 물리학에 대해 하게 될 일은 2025년에 코딩에 대해 했던 일과 비슷할 것이라고 생각한다는 거였고, 제가 이걸 소셜미디어에 번역해서 올렸더니 실제로 한국에 계신 과학자분들 몇 분이 감상을 남겨주신 것도 인상적이었습니다. 이런 일이 벌어지고 있구나, 나도 대비해야 되고, 대학원은 어떻게 될까, 이런 고민의 이야기를 볼 수 있었어요.
내삽인가 외삽인가: 모델 능력의 본질 14:14
노정석 저희가 초창기에 했던 얘기인데, 모델의 발전을 얘기하면서 모델은 단순한 내삽 엔진이라는 얘기를 초창기에 많이 했잖아요. interpolation 정도 하는 거지, 새로운 것으로 나가지 못한다는 이야기를 모델이 좀 바보인 시기에 많이 했지 않습니까? 그런데 지금 나오는 결과들을 보면 사실은 다 반대잖아요. 다 extrapolation, 외삽하는 것처럼 보이는데, 저는 여기에 대해 갖고 있는 생각이, 모델이 투영하고 있는 전체 진리를 100이라고 하면 그 100이라는 부분이 모델에서 매우 희소하게, sparse하게 구현돼 있잖아요. 그냥 interpolation이라고 저는 생각합니다. 이 넓은 공간에서 sparse한 공간들 사이를 interpolation 하는 게 인간 입장에서는 extrapolation처럼 보이는 거라고 생각하고
최승준 굉장히 방대한 영역에서 보간이 일어나면 새로운 것처럼 보일 가능성이 실제로 새로운 게 그렇게 나온 거기도 하고요.
노정석 우리가 인간 고유의 창조라고 부르는 것들도 사실 이미 있었지만 발견하지 못했던 공간을 누군가 찾아내는 것에 불과한 거고, 전체의 보편 타당함을 100으로 보면. 이 모델의 연산이 더 증가하고 일반성이 더 증가하면 그 사이에 있었던 것들도 다 된다는 걸, 물론 시간의 문제가 있겠지만 다 된다는 걸 가정으로 깔아야 되지 않을까 하는 생각이 듭니다. 모델이 다 끝낼 가능성이 있다는 얘기를 저희가 하고 있는 겁니다.
최승준 아까 발표에서는 혁신적인 건 없었다는 인상평이었지만, 그걸 뉴노멀로 놨을 때 해야 할 일은 무엇인가, 어마어마한 걸 해준 건 맞으니까 그런 얘기였고. 제가 이 물리학 관련 얘기에서 계속 매의 눈으로 보고 있는 건 “몇 차례 주고받은 끝”이라는 부분이에요. 내부 모델이라고 했는데, 다른 글에서는 OpenAI가 아직 공개하지 않은 스캐폴딩 또는 하네스라는 표현도 있거든요. GPT-5.2 Pro로는 안 됐던 걸 그 특수한 하네스에서 12시간 돌려서 해냈다는 이야기예요. 그렇게 저는 이해했어요. 그것도 중요하지만 몇 차례 주고받은 것도 중요하게 느끼는데, 왜 그들은 할 수 있었을까. 당연히 최고 전문가이자 최고 수준의 물리학자라서 그걸 했을 건데, 결국 어떤 프롬프트로 환원됐을 거잖아요. 그 프롬프트로 환원되기 전의 것들은 뭘까. 내가 같은 프롬프트를 입력했다면 이해는 못하겠지만 같은 응답을 했을 거잖아요, 그 모델과 하네스는. 저는 이게 계속 궁금한 포인트예요. 무슨 어휘와 무슨 문장을 썼을까.
노정석 승준님이 1월 초에 말씀하셨던 좋은 프롬프트, 프롬프트 잘하기, 그것과 연관된 얘기죠. 사실 한 스텝 한 스텝 띄울 때마다 모델 안의 space가 계속 바뀌는 거잖아요. representation 하는 space가 완전히 바뀌어 있는 거니까 그런 식으로 찾아가는 거겠죠. 그 space를 계속 전이시켜 낼 수 있는 능력, 그게 어쩌면 취향이자 방향을 설정하는 인간의 가치라고 저희가 어렴풋이 느끼고 있는 거 아니겠습니까?
최승준 그렇죠. 지난주에 정규님하고 얘기했을 때도 정규님이 스펙을 길게 쓰던 작년 중순의 스타일에서 지금은 다시 티키타카 모드를 하는 걸 약간의 편린을 보여주셨잖아요. 저희의 지난 편 예시는 굉장히 쉬운 걸 들어서 했지만, 정규님 나름의 어휘랑 지식이 녹아 있는 토큰들을 분명히 썼을 거라는 거죠.
에이전틱 코딩의 현실: 랄프 루프의 한계 18:19
노정석 아, 당연하죠. 요새 저도 agentic 코딩 빡세게 하시는 분들과 많이 교류하는데, 예전에는 oh-my-opencode 같은 것처럼 무조건 목적성에 맞춰서 끝을 내라고 하면서 계속 훅 걸어서 영원히 돌게 하는 — 그걸 통해서는 아까 C 컴파일러에서 얘기했던 것처럼 우리가 알던 거 이상은 안 나온다는 인식이 좀 생긴 것 같아요. 지평을 넓히는 작업으로 넘어가려면 human-in-the-loop가 반드시 필요해요. context를 이해하고 다른 쪽으로 계속 steering 하는 prompt를 넣어줘야 되는데, ralph loop와는 완전히 위배되거든요.
저도 요새 작업하면서 느끼는 게, 정말 간단한 작업이나 너무 명확한데 답을 빨리 내야 되는 건 ralph loop를 돌려서 무식하게 처리해 버리는데, 무언가 로직을 만들어야 되거나 저희 회사 사업에 딱 맞는 무언가를 만들어야 되는 영역에서는 한 스텝 한 스텝 보게 돼요. 기껏해야 서브 에이전트 3~4개 돌려서 답 가져오게 만들고 그거 비교시키고, 비교한 과정을 제가 또 보고. 그렇게 하다 보면 끝나고 나서 느끼는 게 input token의 양이 어마어마하게 많고 output이 작은 작업이 되더라고요. 그러고 나면 이건 괜찮은데, 좋은 게 나왔다는 것들이 생기면서 아까 얘기했던 대로 9가 하나씩 붙는 느낌을 받게 됩니다. agentic 코딩 트렌드도 지금 선각자들, 먼저 가서 모든 걸 경험하시는 분들을 보면 조금 바뀌고 있거든요. 바로 직전까지는 ralph loop였는데 ralph loop로는 안 된다는 의견이 나오고 있어요. 이런 쪽 프론티어에 계시는 분들 한 번 더 모셔서 얘기해 보면 좋을 것 같아요. 사실 정규님도 지난주에 그 얘기해 주신 거죠.
최승준 이것도 일종의 gradient가 생기고 있는데, 계속 알아가는 과정이기 때문에 이걸 약간 외삽해 보면 다음 트렌드가 있겠구나 예상할 수 있죠. 트렌드가 바뀌고 있는 중이니까. 제가 주목한 부분은 티키타카 모드인데, 굉장히 높은 밀도의 어휘와 domain-specific한 것들이 들어가 있는 티키타카 모드가 있고, 어느 정도 티키타카 해서 뭔가가 정해지면 좋은 질문이 나오고 지시문이 나오고, 그러면 오래 돌리는 loop가 그걸 수행할 수 있는 — 2개가 공존하면서 서로 상승 효과를 내는 2가지 결이 있는 것 같다는 생각이 들었고요.
티키타카도 중요하지만 스캐폴딩도 중요한 것 같고, 또는 하네스. 아까 물리 관련 블로그에서, GPT-5.2 Pro는 얼마 지나지 않아 아름답고 일반적인 공식을 제안했지만 증명하지는 못했다. 그런데 내부에 스캐폴딩이 적용된 모델이 12시간 넘게 연속적으로 사고한 끝에 그 공식을 증명해 냈습니다. 증명까지 해서 논문화까지 되는 건 스캐폴딩과 내부 모델의 조합인 것 같아요. OpenAI가 또 흥미로운 — 누가 유행어를 선점하느냐의 문제인데, 하네스 엔지니어링이라는 걸 OpenAI가 먼저 안 했을 수도 있어요. 누군가 한 걸 가져다 했을 수도 있는데, 2월 11일에 이런 포스팅을 했습니다.
하네스 엔지니어링: 모델과 하네스 조합의 시대 21:41

노정석 제너럴하게 이제 쓰이는 말 같습니다. 하네스라는 말.
최승준 그렇죠. 어떨 때는 스캐폴딩이라고 하기도 하는데, 차이가 있나요? 거의 같은 거죠.
노정석 같은 얘기라고 생각합니다. 요새 벤치마크들, Discover AI나 이런 채널에 있는 벤치마크를 보면, Grok 같은 경우에는 아예 최고 모델, 돈 제일 많이 내면 주는 모델이 특정 단일 모델이 아니라 Grok 4.2 Agent Swarm이에요. Grok 4.2 Swarm과 Gemini 3.1 Pro를 비교하는 벤치마크도 하거든요. 단일 모델을 엮어서 쓰는 건 너무 일반적인 트렌드 아닌가.
최승준 저희가 작년 중순만 하더라도 유튜브에서 하네스 이런 얘기하면 댓글에 하네스가 뭐예요? 이런 댓글이 달린 적이 있었는데 지금은 공용어가 된 것 같습니다.
노정석 신정규 대표님도 지난주에 나오셔서 Claude Code의 진짜 물건은 Claude Opus 4.6이 아니라 Claude Code 하네스인 것 같다는 말씀도 하셨었죠.
최승준 Fowler가 익스트림 프로그래밍이나 리팩토링으로 유명한 분이신데, 그분이 팀 조직을 가지고 있나 봐요. 그 안에서 올라온 글인데 실제로 쓴 분은 마틴 파울러가 쓴 건 아니에요. OpenAI 하네스 엔지니어링을 언급하면서 거기에 대해 공감하는 글을 써놓은 게 있고, 상당히 요즘 것들을 다루는 편이더라고요. 마틴 파울러라면 좀 보수적일 거라고 생각했는데, 요즘 이야기되는 것들을 다루고 있습니다. 이런 오래된 분들, 저희보다 연배가 높으신 분들 중 켄트 벡도 있고, 켄트 벡도 최근에 LLM을 적극적으로 활용하고 있죠. 애자일이나 XP 쪽에서 활동하셨던 분들도 지금의 발전 방향을 잘 배워내시고 나름의 생각을 풀어내시고 있는 요즘인 것 같아서, 저도 공부를 좀 더 해보려고 가져온 하네스 엔지니어링이라는 표현이었습니다.
노정석 그러니까요. 요새는 정말 현역의 나이대 스펙트럼이 넓어진 것 같아요. 예전에는 30대 40대가 메인이었고 50, 60, 70 하면 존재가 없었는데, 요새는 30부터 저 위에 70 계신 분까지 전부 다 현역이신 것 같아요.
최승준 그렇죠. 켄트 벡도 코딩하는 게 요새 너무 재밌대요.
노정석 네, 그분이 그런 얘기를 하실 정도니.
최승준 하여튼 다른 지평이 열리고 재미있는 건 맞고, 그런 것들을 가능하게 하는 하네스 엔지니어링 또는 스캐폴딩이 굉장히 중요하게 여겨지고 있는 25년에, Claude Code가 어떻게 보면 촉발한 거죠. 그 이후에 많은 파생이 있었고, 최근에는 OpenClaw도 결국 하네스인 거잖아요. 사람이 몇 차례 주고받을 수 있는 역량, 그 의미가 발생할 수 있는 것을 만드는 것과 스캐폴딩 또는 하네스, 그리고 0.1씩 올라가고 있는 새로운 모델, METR을 saturation 시켜버린 그 모델의 역량, 이런 것들이 3개의 조합 가능한 축인 것 같다는 생각을 해보게 되고요.
FOMO 산업과 AI 우울증 25:11

최승준 하지만 현실은 이게 Matt Shumer가 올린 글이 엄청 바이럴 돼서 몇백만이 봤어요. 저도 번역한 걸 엄청 많이 공유했죠. 300회가 넘게 공유된 것 같은데, 페이스북에서 이 거대한 무언가가 다가오고 있다는 어떻게 보면 현실 인식이기도 하지만 약간 FOMO를 일으키게 만드는 글이었거든요.
노정석 호들갑과 현재 상황의 중첩. 그렇죠, 호들갑으로 봐야 될까요? 아니면 현 상황이라고 봐야 될까요?
최승준 아니, 저는 중첩되어 있다고 보는 것 같아요. 저희도 어떻게 보면 그렇게 비춰질 수 있지만, AI에 관련해서 말하는 게 FOMO를 유발해야 먹고사는 업계가 되어 가고 있는 느낌, 지금 큰일 났으니까 따라가셔야 됩니다 하는 톤을 은연중에 내비칠 수밖에 없죠.
노정석 근데 지금 사실 가치를 만들고 돈을 만지는 회사는 모델을 만들고 컴퓨터를 만드는 회사 빼고, 나머지 기존에 있었던 회사들은 다 우울해지고 있는 상황이고, 그 사이에서 FOMO를 유발하는 유튜버들이 구독자를 늘리며 광고 협찬을 많이 받고 있고, 그러는 거죠.
최승준 하여튼 그런데 이런 스토리가 전염성이 있는 것 같아요.
노정석 다 공감을 불러일으키니까요. 우리 모두가 느끼고 있는, 그래서 나는 어떻게 하라는 거야 하는 그 짜증, 불안 — 불안이라는 말이 제일 좋겠네요. 불안감을 대변하니까요.
최승준 이거는 제가 최근에, 며칠 전인 것 같은데요. 누틸드의 대표님이 AI의 딸깍 시대, 우리는 왜 우울해졌을까라는 블로그 시리즈를 시작하시는 것 같더라고요. 저도 타임라인에서 봤는데 AI 우울증이라는 표현이 흥미로워서 가져와 봤습니다. 딸깍 시대 우울이 생기고 있다면서, 저희도 제프리 힌튼의 우울에서 시작한 채널이긴 한데.
노정석 제프리 힌튼이 그만해, 이러다 다 죽어라는 이야기를 하셨던 게 3년 전이네요.
최승준 근데 왜 딸깍과 우울은 같이 가는 걸까요?
노정석 그 딸깍이 내가 아니니까. 그 딸깍이 내가 하는 사람들은 지금 신나죠.
최승준 근데 딸깍하고 있는 사람도 우울할 수도 있는 거 아니에요?
노정석 네, 그거는 목적 함수가 뭐냐에 따라 다를 것 같습니다.
최승준 되고 있을 때는 신나는데, 지난주에 정규님한테 스타트업의 위험이 뭐냐 얘기했을 때 그 너무 쉬운 복제 딸깍을 또 얘기하시긴 했잖아요. Backend.AI GO 같은 것들이 딸깍으로 치부할 수는 없고 거기에 많은 것들이 녹아 들어간 건 분명한데, 훨씬 더 짧은 시간 안에 된 건 맞잖아요.
노정석 그래서 복잡해지고, 결국 쿠팡에 물건 많은 것과 다를 게 없거든요. 좋고 고품질의 소프트웨어가 굉장히 싼 가격에 많아지는 세상이 되는 거고, 근데 저는 거기에 대해 너무 호들갑을 떨지 말아야 되는 게, 와 이제 모두가 소프트웨어를 만들 수 있는 세상이야, B2B SaaS는 없어질 거야. 제가 최근에 인터뷰했던 데서도 그렇게 워딩이 뽑히긴 했는데, 사실 소프트웨어가 없어지는 게 문제가 아니죠. 좋은 소프트웨어가 훨씬 많아지는 거고, 좋은 소프트웨어가 많아지면 사람들은 좋은 것에서 great한 걸 찾아서 또 거기로 몰려가요. 상대적으로 배경이 바뀌더라도 좋은 것들을 알아보는 눈은 끊임없이 가혹하게 존재하기 때문에, 저는 물건을 파는 장사를 해 보니까 고객들이 귀신같이 다 알아요. 좋은 것과 나쁜 것, 이게 돈의 가치가 있는지 없는지를 알기 때문에 다 상대적인 거다. 그래서 그다음으로 넘어가고, 변화하는 것들에 대해 잘못됐다는 얘기는 하지 말아야 될 것 같습니다. 따라가는 것만이 최선입니다.
과잉 호들갑 경계: 좋은 소프트웨어가 늘어나는 세계 28:05
최승준 하지만 힘들긴 하거든요.
노정석 그러니까 그 비즈니스계 언제나 통하는 격언이 있거든요. 고객은 언제나 옳다. “Customer is always right”라는 그 표현이 있는데 그냥 고객들이 돈 내는 방향을 목적 함수로 세팅하면 그냥 그거 따라가면 됩니다.
최승준 초반에도 말씀드렸지만 1월, 2월에 뉴스를 보고 있긴 하지만 최근 트렌드에 대한 연습을 많이 하고 있지는 않거든요. 그러다 보니 좀 스트레스 덜 받고, 하지만 적절한 도전이 있는, 건강하게 추구할 수 있는 무엇인가에 좀 집중해 보고 있는 요즘인 것 같아요. 나를 재미있게 하는 방향성은 뭔가 놀이 같은 건 뭔가 했을 때, 또 Andrej Karpathy가 떡 하니 뭘 내놨죠?
재미 찾기: Andrej Karpathy의 microgpt 29:48
노정석 microgpt.

최승준 microgpt를 재미있게 탐색하는 시간을 가졌습니다. 빠르게 가보면, 블로그로도 Andrej Karpathy가 올렸고, 앞에 micro가 붙은 게 2020년에 micrograd라는 걸 발표했었어요. 거기에 Value라는 클래스가 있었는데, 자동 미분을 스칼라 기반으로 하는 아주 간단한 구현이었거든요. 한 몇십 줄 되는 구현이었는데, 그걸 활용해서 200줄에 딱 끊었어요. 세 컬럼으로 되는 GPT 코드를 공개했습니다. 근데 상당히 재미있어요.
노정석 그냥 트랜스포머를 구현한 거죠.
최승준 그렇죠, 아주 간단한. 이름을 생성하는 거거든요. GPT 부분은 딱 이만큼, 한 페이지에 보일 수 있는 정도로
노정석 아까 스칼라라는 표현을 쓰신 거구나. 진짜 완전히 저희가 익숙한 for 루프로 무식하게 하는 구현으로 썼네요. 딱 필요한 것들만 정확하게 다 들어 있네요. 한 줄 더, 덜도 없이
최승준 전체 코드를 보면 matmul이나 이런 것들도 다 파이썬으로 구현해 놨어요. 200줄 안에 그게 되는 코드입니다. 저는 이걸 한번 쭉 따라서 타이핑해 봤어요. 재미 삼아 한번 쭉 따라서 해보고 Colab에서 실행해 보고 그랬는데 재미있었고요.
노정석 알파벳이 그거네요. 토큰이 그냥 알파벳 쓴 거네요. 예전에 Andrej Karpathy가 인기를 갑자기 확 끌었던 게 2015년인가 그런데, character RNN. 딱 그 필이네요.
최승준 제가 한 게 아니고 Claude를 시켰던 건데, 좀 실험을 해보려 했던 거는 사실 자동 미분으로 할 수 있는 게 트랜스포머 같은 것만이 아니거든요. 저는 예전부터 이런 것들을 탐색해 왔는데, 예를 들면 이미지 쪽에서 DALL-E 나왔던 2021년에 CLIP도 나왔거든요. CLIP이 나오고서 OpenAI가 CLIP으로 어떤 loss를 만들어서 이미지를 간단한 네트워크로 최적화해서 이미지를 생성하는 작업이 많이 있었어요. 그런 걸 하면서 자동 미분의 힘을 좀 느낄 수 있었는데, 제가 알고 있었던 배경 지식 중에 또 해본 게 Andrej Karpathy가 만든 구현을 응용한 거예요.
자동 미분의 창의적 응용과 배움의 즐거움 31:34
최승준 어떤 건 일정 거리 안에 들어와야 되고, 어떤 건 수직이 맞아야 되고, 어떤 건 겹치고, 어떤 건 겹치지 않게 되어 있는 — 여기는 겹치네요. 그런 규약을 나타내는 건데, 이런 규약들을 미분 가능한 함수로 바꿔주면 자동 미분은 이런 걸 할 수 있어요. 레이아웃 최적화 같은 걸 할 수 있고, 그런 것들이 작동하는지를 Andrej Karpathy가 만든 Value 클래스를 포팅해서 실험해 봤죠.
노정석 사실 큰 틀에서는 딥러닝과 다를 게 하나도 없는 거죠.
최승준 딥러닝인 거죠.
노정석 모델이 매우 간단한 거고 목적 함수가 크로스 엔트로피가 아닌 다른 걸 쓰는 거고, 그러나 러닝하는 데 쓰는 알고리즘은 똑같고. 구독자분들께 드려야 되는 인사이트는 아까 말씀드렸던 초끈 이론의 물리학 최전선에서 답을 찾아내는 것과 방금 승준님이 보여주시는 거기에 들어가는 것의 알고리즘은 같다는 겁니다. 들어가는 컴퓨테이션의 양만 다를 뿐이다.
최승준 제가 이 맥락에서 하고 싶었던 얘기는, 도메인 지식을 제가 주입했을 때 — 아까 Penrose라든가 자동 미분에서의 응용 사례 같은 걸 알고 있다 보니까 — inverse kinematics를 쓴다거나 하는 걸 주입하지 않았을 때도 모델이 그런 걸 제시했을까가 궁금한 포인트였어요. 이런 것들도 그런 기반으로 할 수 있는 건데, 크리에이티브 코딩의 소재를 발상해 보자라고 시작한 대화가 있었습니다. 여기는 제가 알고 있었던 정보를 안 썼어요. 파이썬이 아니라 다른 언어로 포팅해서 응용해도 된다, 실시간 상호작용이 가능한 쪽으로 뭘 할 수 있는지 알아보자라는 걸 ChatGPT로도 했었고 Claude로도 했었습니다. 둘이 비슷하면서도 다른 것들을 소개해 줬거든요.
실시간 그림이 배우는 캔버스, 미분 가능한 파티클 시스템, 미분 가능한 synthesis — 오디오 쪽. 그다음에 computation graph, L-system, 이런 것들이 되나 시켜봤죠. decision boundary를 예쁘게 그려주는 거 하나 뚝딱 나왔었고, 자동 미분의 과정을 computation graph로 시각화하는 걸 예쁘게 만들어서 체인이 어떻게 되는지 그런 걸 만들었고, 좀 도전적인 거는 L-system이라고 해서 나무 같은 거 그리는 알고리즘에서 프랙탈 같기도 하죠. 제가 포인트를 그려주면 거기에 최적화돼서 그런 것들을 좀 해봤는데, 이건 알고 있었던 거긴 했어요. 이런 게 된다는 걸
노정석 예전 같았으면 저런 거 하나하나가 시간을 꽤 써야 되는 작품이었는데, 정말
최승준 요새는 그냥 뚝딱 나오죠. 되는 걸 되게 하는 건 쉬운 일이잖아요. 되는 걸로 알려져 있는 걸 되게 하는 거니까, 새로운 건 없었지만 잘 된다는 걸 확인했습니다. 근데 이 ChatGPT와의 대화는 구현보다 내용을 함께 티키타카 한 게 재미있었어요. 이런 걸 할 때 어떻게 에너지 함수를 만들어야 되는가, 미분 가능해야만 할 수 있는 거기 때문에 내가 만들고자 하는 걸 미분 가능한 형태로 바꾸는 작업이 중요해요. 그걸 요새는 AI한테 부탁하면 되겠더라고요. 내가 하고 싶은 게 있는데 미분 가능한 함수를 어떻게 디자인하면 좋을까를 물으면 되겠구나를 어제 느꼈어요. 예전에 힘들게 했던 작업들을 다 재방문해서 할 게 많구나라는 걸 느꼈어요. 다시 좀 재미를 찾은 거죠.
사실 이런 재밌는 것들이 이미 많이 있거든요. 슬쩍 넘어갔긴 하지만 ChatGPT와 대화에서 제가 알고 있는 것도 얘기했지만 몰랐던 걸 얘기한 것들도 있었거든요. 아까 질문이 이거였잖아요. domain-specific한 용어, Penrose, Bloom 이런 걸 넣어줬을 때의 응답과 넣어주지 않았을 때의 응답에도 인사이트를 줄 수 있는 뭔가가 있었는가. 둘 다 있는 것 같아요. 안 주고 한 버전에서도 배운 게 있었고, 주고 한 버전에서도 배운 게 있었고, 코드를 들여다봤을 때도 배운 게 있었거든요.
결과보다 과정: 다시 배우는 재미와 취향 37:11
최승준 제가 요새 좀 트렌드에 스트레스를 받나 했을 때, 생성물을 들여다보고 결과가 아니라 그 과정에서 얻는 즐거움을 조금 잃어버린 것 같아서 스트레스를 받아왔어요. 사실 코드를 들여다보고 이해하고 배우는 걸 좋아하는 성격이었는데, 지금은 많이 돌려서 이거 나왔네 하는 식으로 가다 보니까 한 1, 2년 정도 코딩을 많이 안 했고 시키기만 했죠. 그러다 보니 스트레스를 받지 않았나 추측하고 있습니다. 그런데 이렇게 다시 공부하고 손으로 타이핑해서 코딩, 아까 그 microgpt 한번 쭉 따라서 하고 일부는 외우려고도 해보고 응용도 해보고 이렇게 저렇게 해보니까 다시 재미있더라고요.
노정석 저도 그 부분은 동의합니다. 랄프 루프 돌려서 와 나 토큰을 얼마 썼어 하는 단계를 넘어서서, 다시 목적성을 명확하게 설정하고 모델과 티키타카 하면서 배우는 것들이 계속 늘어나는 게 재밌더라고요.
최승준 이게 결과 생산성에서도 분명히 중요한 부분이 있는데, 인간인지라 배우는 것에서의 즐거움도 무시할 수 없거든요. 물론 생산성을 늘리려면 하네스를 개발해야 되니까 그 개발하는 즐거움은 있을 수 있죠.
노정석 그래서 여기 저희가 초창기에 하던 그런 이야기들로 많이 돌아가요. 저는 여전히 모델이 하네스가 됐건 뭐가 됐건 단일 모델이건 집합체건 그건 상관없이 꺼낼 수 있는 어떤 산출물의 품질은 그 인간의 한계를 넘어설 수 없다.
최승준 근데 그게 사실 또 고민이기도 한 게, 이것도 중요하긴 한데 제일 처음으로 돌아갔을 때는 이게 됐으면 좋겠거든요. 모르는 채로도 옳은 방향으로 나아가려면 어떻게 해야 될까, 아직 저도 답을 얻지는 못하고 있지만.
노정석 그런데 저는 거기에 대해 어설프게나마 결론은 좀 볼 수 있는 게, 모르는 채로도 옳은 방향으로 나아가려면 나아가 보는 방향에서 자기가 배움을 얻고 결정하는 품질을 높이는 과정과 결합되면 돼요. 그러면 모르는 채로 시작했지만 알아가면서 내가 뭘 가고 싶은지조차 그 과정에서 깨달을 수 있거든요. 시작이 반이다라는 옛 어른들 말씀이 맞다. 모르는 채로 내가 어디에 도착할지 당연히 알 수 없잖아요. 모순이잖아요. 모르는 채로도 답을 얻을 수 있다는 건 저는 그 말 자체가 성립을 안 해요. 그러나 모르는 채로 시작하되, 뭔가를 알게 된 내가 무엇을 원했는지 깨닫는 결과로 갈 수 있다. 그 과정이 모델에 의해서 매우 가속되는 거고, 저희 애가 이제 겨우 20살짜리 대학생이어서 저 친구는 어떻게 살아야 되나 하는 고민을 하면서, 이런 이야기를 많이 해주게 되거든요. 네가 일단 알아야 된다.
최승준 그래서 저도 하여튼 탐색 중이긴 한데, 제가 MVK의 후보로 놓고 있는 거는 가설을 세우고 실험하는 태도 같은 거거든요.
노정석 근데 승준님, 그건 승준님이 고등 교육에 물리·화학·생물 관련 폭넓은 독서, 수많은 코딩 실패, 이런 것들이 다 어우러져 있기 때문에 그 위에서 지금 MVK를 말씀하시는 거잖아요.
최승준 아니, 근데 제가 생후 10개월짜리 어린아이의 사진을 여러 번 보여드렸었잖아요. 소리를 듣고서 잡지책에 귀를 기울여 보는 그런 태도는 사실 10개월 영아도 할 수 있는 거라서, 가설을 세우고 실험하는 건 인간의 본능적인 거라고 생각하는 편이긴 한데. 물론 이걸 발표했을 때 많은 분들의 피드백이 그거예요. 그렇게 평평해지긴 어렵다. 근데 그게 계속 고민의 포인트인 거예요. 알고 있는 사람이 더 잘하는 건 늘 있어 왔던 거기 때문에 AI 시대에는 좀 달라져야 되는 거 아닌가 하는 고민이 있다 보니까 얘기를 하는데, 제가 이런 얘기를 했을 때 늘 받는 피드백은 그게 그렇게 쉬운 일은 아니다, 안 될 것이다라는 얘기를 많이 듣긴 하거든요.
노정석 웃기지만 AI도 물어보지 않는 자에게 답을 주진 않아요.
최승준 질문까지 가져가는 것도 사실 허들이 있긴 하고요.
노정석 근데 그 허들을 넘는 순간, 그걸 계속 넘기로 하는 순간은 승준님이 방금 말씀하신 그게 태도잖아요. 생기는 거죠. 계속 배우는 것들을 모델에 알려줄 테니까.
최승준 지금 저희가 계속 회귀하는 어휘들이 태도나 취향, 때로는 의지, 다른 말이긴 하지만 일맥상통하는 뭔가가 있다고 느껴지긴 하거든요.
노정석 그리고 배울 게 많아요. 저도 요새 회사에서 엉덩이 붙이고 앉아서 다양한 로직을 Codex와 함께 쓰고 있는데, 배우는 것들이, 와 내가 이건 다 모르던 것들이구나, 이렇게 하면 되겠네 저렇게 하면 되겠네. 회계도 알게 되고 마케팅도 더 알게 되고, 메타 광고는 이렇게 돌아가는구나, 어설프게 하던 것들을 디테일하게 알게 되고, 그 자리에서 데이터 백테스트 다 해주고, 이 가설은 맞네 틀리네 다 알려주니까, 와 이거는 아이언맨의 JARVIS랑 일하는 거랑 똑같은 거 아닌가.
건강하게 쓰기: AI가 혹사시키는 메커니즘 42:33
최승준 근데 그게 되다 보니까, 지금 저는 어떤 시절을 살고 있다고 생각하냐면, 과도기일 수도 있고 아닐 수도 있는데, 너무 되다 보니까 건강하게 하는 방법을 사람들이 모르는 중이고, 그게 위험하구나를 알아가고 있는 중인 것 같거든요. AI가 나를 혹사시키고 무리하게 되는 메커니즘이구나. 되다 보니까 안 되지만 될 것 같은 힌트들이 계속 나오고, 무리를 하게 되는데, 건강도 해치고 FOMO도 유발하고, 그게 문제구나를 알아가는 게 2026년의 트렌드가 될 것 같아요.
노정석 그래도 재밌어요. 아침에 일어나면 오늘은 뭘 해볼까라는 그런 재미가 생기니까, 재미있는 시기니까 재미있게 가야죠.
최승준 제가 여기 장표를 보여줬을 때 설명했었는데, 이 프롬프트를 쓸 때 24번 고쳐 쓴 거예요. 앞에 프롬프트가 좀 더 길게 있긴 한데, 원하는 응답이 나올 때까지 24번을 반복해서 고치는 거고, 어휘 하나 바꿔보기도, 문장을 바꿔보기도 하면서, 깎는다는 표현을 요새 많이 하잖아요. 프롬프트를 깎는 과정이었죠.
이러면서 짜증이 재미로 가는 쪽을 탐색해 보긴 했는데, 여전히 짜증이 나는 부분이 있긴 합니다. 다른 층인데, 올해 초에 Gilbert Strang의 선형대수 책을 다시 본다고 했었잖아요. 읽기로 하고 읽어 나갔는데, 아직 1장을 다 읽고 2장을 넘어가지 않고 있습니다. 여전히 모르겠는 부분이 있어서 같은 질문의 변주를 수십 번 물어보고 있거든요. 프롬프트는 많이 하면 결과를 바탕으로 원하는 결과로 조정해 나갈 수 있어요. 그런데 같은 걸 수십 번 하더라도 여전히 모르는 게 있다는 거죠. 손으로도 써보고, AI를 써서 인터랙티브 튜토리얼을 만들어 보기도 하는데, 여전히 모르는 중에 디테일하게 몰라지는 부분이 있어요. 내가 뭘 모르고 있구나를 알게 되는 감각, 그걸 계속 좁혀가고 있다는 느낌을 받는데, 드는 의문이 이걸 내가 결국 알아야 되는 건가. 근데 포기하기 어려운 게, 내가 완전히 그걸 pre-training 해서 소화, grokking을 해냈다고 봤을 때는 해냈다고 그다음을 더할 것 같다는 느낌은 또 있거든요. 공부하는 게 재미있기도 하고, 하다 보니까 진도는 안 나가더라도 알 때까지 좀 더 해봐야겠다는 현재의 태도이긴 한데요. 정답은 없겠지만, 이걸 덮어두고 쓸 수 있으면 됐지 하고 갈지, 정말 알 때까지 해볼지, 이런 요즘입니다.
Gilbert Strang 선형대수와 끝까지 파고드는 공부 43:54
노정석 모두가 다 지금 여행자가 된 것 같아요. 집에 편하게 머물러 있고 싶었는데, 어쩔 수 없이 다 미지의 공간에 떨어뜨려져서.
최승준 떠밀려졌죠.
노정석 이것저것 찾으면서 그 사이에서 누구는 불안을 느끼고, 누구는 재미를 느끼고, 누구는 이 환경이 너무 좋고, 누구는 너무 싫고, 그래도 저희가 이렇게 살아 있는데. 이 대변혁을 눈앞에서 목격하고 있다라는 것도 참 즐거운 일인 것 같아요.
최승준 그것도 무시 못 할 즐거움이고 동기이기도 한데, 이 세상을 잘 살아가려면 어딘가에 마음의 닻을 좀 놓긴 해야 되는 것 같아요. 중심이 너무 흔들려서요. 어느 정도는 흔들리되, 그래야 새로운 탐색을 하지, 근데 또 너무 닻을 내리면 안 변할 거 아니에요. 이 균형감을 갖는 게 쉽지 않은 거고, 정석님은 잘 균형을 잡고 계신가요?
노정석 아니요. 답은 저도 모르겠어요. 항상 배경의 속도와 같이 뛰다 보면 배경 속에서 변하는 것들이 보이거든요. 아니면 그냥 휙 지나가 버리지만, 같이 뛰다 보면 보이는 것들과 그 속에서의 기회들. 저는 비즈니스 하는 사람이니까 항상 이걸 비즈니스 목적으로 치환해서 보고, 사업 기회를 어떻게 할까 하는 쪽으로 많이 생각 실험을 하는데, 그걸 하다 보면 재미있는 사람들도 만나게 되고, 그 사람들은 이 시도를 하는구나 저 시도를 하는구나 하는 것들을 보면서 확실하게 느끼는 건 있어요. 대부분 사람들이 답만 얻고 싶어 하잖아요. 근데 이 AI 공간이라는 게 답만 한 문장 얻어서 가기에는 복잡하게 얽혀 있는 것들이 많다.
비즈니스 관점: 99 vs 99.99의 차이 46:23
노정석 레이어도, 이제는 모델이 하나의 라이브러리처럼 포장돼서 아래로 내려가 버리고, 저희는 콜만 하면 답을 주는 객체가 되어 버렸지만, 거기서도 비즈니스를 세우려면 모델 안을 보지 않고서는 이 산업이 어떻게 갈지 알 수가 없거든요. 그 부분이 또 다른 점이에요. 예전에는 파이썬만 알면 아래 있는 C나 어셈블리는 몰라도 된다고 했는데, 얘는 하드웨어의 컴퓨테이션 레이어에서부터 모델, 그리고 비즈니스까지 다른 층위로 왔다 갔다 해야 답이 좀 보이는 느낌이거든요.
지난주에 정규님이 그 얘기하셨어요. 모델을 깎는 일을 다시 시작했다는 말씀을 하셨거든요. 그리고 모든 소프트웨어의 단위 업무가 하나의 모델 안에 다 들어가고 그 모델 위에 약간의 하네스가 얹어지는 구조가 될 것 같다는 얘기를 했거든요. 지금은 저희가 프론티어 모델들에 다 얹어서 API 콜을 하고 있지만, 정규님이 거기서 합의하신 바는, 그럼에도 불구하고 모든 작은 디테일에도 다시 모델의 세상이 온다는 얘기를 하셨다고 생각하거든요.
그렇게 됐을 때, 그 작은 모델이 새로운 웹 서비스가 될 텐데, B2B SaaS 가져와서 아는 책 한 권 던져주고 파인튜닝하는 걸로 끝날 것인가, 아니면 그 안에서 최전선을 좀 더 적용할 수 있는 사람들이 우위를 가질 것인가. 전부 99와 99.9, 99.99 사이에서 경쟁해야 되는 거면, 고객들은 99가 아닌 99.99에 다 몰려갈 거거든요. 이건 저희가 지금까지 가져오던 속도에 대한 감각, 가치에 대한 감각이 달라지는 거지, 다시 그 공간에 들어가면 그 안에서의 상대적 편차가 새로운 노름이 돼서 벌어질 거예요. 그게 우리 세대에 벌어지고 있는 게 우리의 불행인데, 거꾸로 얘기하면 스타트업이든, 변화가 절실한 개인이든 이거 다 기회죠. 누군가에게 위기는 다 우리에게 기회입니다. 그렇게 치환해서 생각해야 됩니다.
최승준 얘기를 듣다 보니까 거의 확신이 든 부분이 있는데, 정석님은 이게 재미있는 게 분명하다. 비즈니스가 그렇기 때문에 저도 나름의 재미를 추구하고자 하는 거고, 거기서 동기를 얻듯이 비즈니스에 관련된 걸 생각하고, 그런 것들이 재미있으신 거죠.
노정석 그러니까 제가 이 나이에도 이걸 하고 있겠죠.
최승준 어쨌든 건강하게 추구할 수 있는 무엇인가에 대한 이야기를 오늘은 좀 해봤던 것 같습니다.
노정석 하다 보면 저희도 항상 산으로 갑니다마는, 순수하게 공부 목적으로 이걸 하는 거잖아요. 뷰 카운트를 올리고 빨리 구독자를 늘려서 광고를 붙여야 된다는 목적성이 있으면 이걸 전혀 안 할 텐데.
마무리: 구독자 2만, 다음 주에 또 50:08
최승준 하지만 구독자가 올라가면 힘이 되긴 하더라고요. 저희 지금 구독자가 어느 정도인가요?
노정석 2만 명. 자고 일어났더니 2만 명 됐네요. 놀랍다.
최승준 축하할 일이긴 한데, 이렇게 끝까지 시청해 주시는 분들이 꽤 많다고, 한 30% 되신다는 얘기를 저번에 얼핏 하셨던 것 같은데.
노정석 저희가 1시간 반씩 되는데 끝까지 시청 완료하시는 비율이 37%인가 그래요. 대단한 거죠. 감사드릴 뿐이고, 댓글에 의견 남겨주시는 거, 동의하는 의견에는 댓글을 잘 안 다는데 동의하지 않는 의견에는 댓글을 조금씩 달게 되긴 하더라고요.
최승준 이번 편에 동의하지 않는 댓글이 달릴 수 있겠네요.
노정석 그렇죠. 그러면 또 건강한 토론으로 한번 이어보시죠.
최승준 그래서 하여튼 오늘도 재미있었습니다.
노정석 항상 토요일 오전 승준님과 이런 얘기를 하면, 토요일, 일요일 생각할 거리가 생겨서 저는 항상 좋습니다.
최승준 그러면 또 다음에 건강한 모습으로 뵙도록 하겠습니다.
노정석 다음 주에 뵙겠습니다.
최승준 모두 감사합니다.