EP 90
알파고 이후, 10년 (feat. HyperAccel 이진원 CTO)
인트로 및 게스트 소개 (HyperAccel 이진원 CTO) 00:00
노정석 자, 녹화를 하고 있는 오늘은 2026년 3월 14일. 파이 데이 토요일 아침입니다.
오늘은 AlphaGo 10주년 관련한 이야기를 한번 해볼 텐데요. 놀랍게도 AlphaGo가 우리에게 충격을 준 지 벌써 10년이 지났습니다. 그래서 그 10년을 한번 리캡을 해보려고 하고요.
승준님과 함께 저희가 새로운 게스트 한 분 모셨는데요. HyperAccel의 이진원 CTO님, 저희 오늘 모셨습니다. 어서 오십시오.
이진원 안녕하세요. 초대해 주셔서 감사합니다.
노정석 이진원 CTO님, 최근에는 독파모 심사위원으로도 활동하셨었고 저희 딥러닝 초창기에 굉장히 많은 공을 세워주신 분인데요. 저희 PR 12, PR Twelve라고 읽어야 되나요? 저희 논문 읽기 모임이 굉장히 오랫동안 지속됐는데 저도 도움을 굉장히 많이 받았습니다. 이진원 CTO님, 지금 하시고 있는 사업과 이런 것도 소개 한번 간단하게 해 주시죠.
HyperAccel 소개: 추론 전용 AI 반도체와 서비스 가격 문제 00:59
이진원 안녕하세요. 저는 HyperAccel에서 CTO로 일하고 있는 이진원이라고 하고요. 저희 회사 소개 간단하게 드리면, 저희 HyperAccel은 추론 전용 AI 반도체를 만드는 회사입니다.
여기 기사도 얼마 전에 난 게 있는데, 저희가 AI 서비스를 쓰다 보면 가격이 굉장히 비싸잖아요. 여러 가지 이유가 있지만 HBM 같은 비싼 메모리, 비싼 공정들, 이런 걸 사용하면서 일반인들이 쓰기에 아직은 좀 부담되는 그런 가격으로 사람들이 서비스를 쓸 수밖에 없는데, 좀 더 많은 사람들한테 더 양질의 서비스를 할 수 있는 그런 반도체를 우리가 만들어 보자. 그래서 저희가 HBM을 쓰지 않고 LPDDR이라고 하는 저전력 메모리를 사용해서 10분의 1 가격에 저희가 서버를 공급하고, 지금 쓰고 있는 가장 싼 서비스가 우리나라 돈으로 월에 한 3만 원 정도 내야 되잖아요. 그거를 한 5천 원 이하로 줄여보자, 이런 원대한 목표를 가지고 열심히 칩을 개발하고 있습니다.
노정석 옳은 방향성인 것 같아요.
PR 12 논문 읽기 모임과 커뮤니티의 힘 02:05
이진원 이런 내용들을 2017년에, 그때 오늘 그런 얘기들 많이 하게 될 것 같은데, 그 무렵에 커뮤니티의 역할이 굉장히 컸어요. 지금도 작다고는 할 수 없지만, 그때 커뮤니티 힘이 컸고 우리나라의 딥러닝 발전을 위해서 저도 다른 분들의 도움을 굉장히 많이 받았어서, 이때 지금 업스테이지 대표이신 김성훈 대표님이랑 몇몇 분들이 텐서플로 코리아이라고 하는 모임에서 뜻을 같이 해서, 우리가 논문이 굉장히 많이 쏟아지고 이때 당시에는 새로운 알고리즘들이 너무 많이 나와서 사람들이 논문을 뭘 봐야 될지도 모르겠고, 한 번 읽는 데 시간도 너무 오래 걸리고. 그걸 우리가 조금 도와주자, 그런 취지에서 이 논문을, 이때 당시에 2017년에 Zoom에서 일주일에 두 명씩 돌아가면서 논문을 리뷰하고, 그거를 지금 이 팟캐스트처럼 다 그대로 녹화해서 유튜브에 올리는 걸 시작했고, 현재도 계속되고 있습니다. 재밌게 잘 했고, 저는 지금은 잠깐 쉬고 있는데, 잠시 휴식 후에 다시 돌아가서 계속 참여를 할 예정입니다.
최승준 그러면 그런 일들이 일어난 게 AlphaGo에 영향이 있었다고 볼 수 있을까요? 사람들이 충격을 받은 뒤에 공부한 건가요?
이진원 그럼요. 그때부터 우리나라에 붐이 많이 일었던 것 같아요. 저도 저는 그전에 한 2014년 이때쯤부터 혼자서 이것저것 공부도 하고 해보고 하고 있었는데, 그때 굉장히 어려움이 많았거든요. 자료도 별로 없고, 외국에도 그렇게 많지는 않았던 것 같아요.
근데 2016년에 AlphaGo 사건이 있은 이후에 우리나라에 특히 굉장히 많은 붐이 일어서 사람들의 관심도 높아지고, 그런 커뮤니티도 활성화되고, 그런 일들을 통해서 이것도 시작하게 된 것 같습니다.
AlphaGo 10주년 공식 포스팅과 Noam Brown의 통찰 03:50

최승준 최근에 AlphaGo 10주년이 되면서 공식적인 포스팅들이 Demis Hassabis나 Google DeepMind 쪽에서 있었는데, 지금 “게임에서 생물학, 그리고 그 너머까지: AlphaGo가 남긴 10년의 영향”이라는 포스팅이 하나 있었고, 그다음에 작년에 저희가 에피소드에서 하나 플레이한 그 Google DeepMind 팟캐스트를, 그 해의 마지막 거를 소개를 좀 드렸었잖아요. 그런데 올해의 첫 내용도, 그 작년에 마지막 거가 Demis Hassabis와의 인터뷰였었는데, AlphaGo 10주년에 관련된 팟캐스트로 열었더라고요.
그 두 내용이 좋아서 좀 가져와 봤는데요. 본 내용은 자세히 설명드리기보다는 참고하시면 좋을 것 같고, 이거에 관련돼서 Noam Brown이 이런 포스팅을 했었어요. 번역된 거에서는, 오늘날 최전선 추론 모델들을 가능하게 한 핵심 방식은 놀랍게도 AlphaGo와 비슷한. 방대한 양의 인간 데이터를 모방하고, 더 나은 추론을 위해 추론 시점에 연산량을 늘리고. 당시에는 Monte Carlo Tree Search였는데 오늘날에는 Chain of Thought다. 강화학습을 사용해 단순한 모방을 넘어선다. 이게 굉장히 비슷한 방식인데, Demis Hassabis가 또 댓글을 달았던 것 같아요.
어쨌든 Noam Brown이 이 얘기를 한 다음에 Demis Hassabis가 댓글 단 거가 뭐냐 하면, AlphaZero의 방향으로 가는 거에는 굉장히 주의가 필요하다. 우리가 그 스위치를 넣을지 말지 그런 건 좀 고민을 해봐야 된다라는 얘기를 했었고, 그게 함의하는 거는 결국에는 자기 증강하는 시스템이잖아요. 그래서 오늘 좀 그런 얘기들도 하게 될 것 같습니다.
혹시 이 두 포스팅이나 영상에 대해 보셨거나 코멘트하고 싶으신 부분 있으실까요? 어디를 좀 중요하게 보면 좋을까요?
이진원 저는 AlphaZero로 할 수 있느냐에 대해 생각을 많이 해봤던 것 같은데, 실제로 좀 찾아보니까 그런 움직임들이 있더라고요. AlphaZero로 가는 방향은 인간 데이터 없이 하는 거잖아요. 지금 대규모의 프리트레이닝 작업 없이 강화학습만으로 할 수 있냐, 지금 현재 하고 있는 것들 이상의 것들. 근데 실제로 그쪽의 움직임들이 많이 있는 것 같아서 굉장히 흥미 있게 보고 있습니다.
최승준 결국에 이 Google DeepMind 팟캐스트에서 하거나 블로그 포스팅 했었던 것도, 지금 이 방향이 과학이나 혁신으로 어떻게 연결이 자연스럽게 되느냐의 그 궤적을 좀 짚어주는 것 같아요.
37수와 Platform 37: 대국의 순간이 상징이 되다 06:13

최승준 참 또 하나 흥미로운 게 있었는데, 37수이 건물이 됐더라고요. AlphaGo의 그 놀라운 수라고. 인간인 이세돌 9단의 놀라운 수가 몇 수였죠? 78수였네요. 78수고 AlphaGo의 37수인데, 그 37수의 이름을 따라서 저 Google DeepMind 신사옥이 생기나 봅니다. 여름부터 입주를 한다고 하는데요.
이진원 이건 두 번째 대국이었죠.
노정석 두 번째 대국의 37수일 거예요. 아마 사람들이 다 그 해설자들이 “어, 저기는 왜 왔지”라고 하면서, 인간이라면 절대 못 둘 수였는데, 나중에
이진원 실수한 것 같다라는 얘기도 많이 했었고.
2016년 AlphaGo 대국 현장 이야기 06:54
노정석 저희가 2016년, 10년 전을 반추해 보면 저희 TensorFlow가 나오고 막 이런 거 할 때가 2015년 정도였던. TensorFlow가 나오긴 했지만 그게 뭔지 세상이 전혀 알지 못하던 때였고, 그때 막 사람들이 딥러닝이란 무엇인가, NVIDIA 키노트 보면서 softmax는 어떻고, 그다음 MNIST, 그다음에 MNIST 끝나고 나면 CNN 이런 거를 가장 기초적인 것들을 돌려보던 그런 때였기 때문에 AI라는 표현을 많이 안 썼죠. 그때는 머신러닝, 딥러닝이라는 표현을 많이 썼는데 그거에 대한 기대가 그렇게 높지 않던 때였어요.
근데 사실 2016년에 AlphaGo가 와서, AlphaGo 시작할 때만 하더라도 저도 그 행사장에도 있었는데 그리고 그 전에 전야제라고 그러죠. 갈라쇼를 할 때 가서 Eric Schmidt랑 유명한 사람들 다 모여 있고 이세돌과 Eric Schmidt와 초 VIP들이 맨 가운데 앞 테이블에 앉고 유명한 사람들이 다 뒤로 앉았었는데 그때만 하더라도 이세돌 자신만만했었어요. 인간이 이긴다. 네, 그런데 거꾸로 저는 야, 구글에서 저렇게 별들이 다 넘어올 정도면 얘들이 뭔가 확신을 갖고 넘어왔지 그냥 오진 않았을 거다라고 해서 AlphaGo가 압도적으로 이길 거다라고 저는 배팅을 했었고 그때 한참 내기를 했던 기억이 납니다. 근데 저희 1국이 끝나고 났을 때 사실 모두가 다 충격에 휩싸이긴 했죠. 압도적이었어요.
최승준 라이브로 다 보셨죠? 두 분 다.
이진원 네, 봤습니다.
노정석 봤죠. 저도 바둑을 다 이해하지 못하기 때문에 그 수의 깊음이나 이런 거는 제가 이해는 못했습니다만 그 사람들, 해설해 주시는 해설자들의 탄식과 놀라움과 좌절감들을 보면서 아, 이거 엄청난 거구나라는 생각을 했었죠.
이진원 또 굉장히 재미있었던 거는 그때 유튜브 포함해서 다양한 채널에서 해설, 소위 프로바둑 기사들이 해설을 했는데 의견이 굉장히 많이 갈렸었어요. 어떤 한 수 한 수 나올 때마다 그거를 보는 것도 재미있었던 기억이 있습니다.
최승준 그 당시에는 정책망이 뭐다 가치망이 뭐다 그런 용어들을 저는 잘 몰랐던 때라 가지고 이게 무슨 소리인가 블로그 보기도 하고, 기억이 나네요.
노정석 AlphaGo 대국이 끝나고 나서 웬만한 교수님이나 유명하신 분들이 다 그게 어떻게 만들어졌는지 해설가가 되셔서 발표 자료들, 유튜브 녹화들 굉장히 많이 나왔던 생각이 납니다.
최승준 어떻게 보면 한국이 그 덕을 좀 봤다고도 볼 수 있지 않을까요? 일찌감치 세게 맞아 가지고 당사자성을 가지고서 좀 보게 됐는데, 이게 아마 Demis Hassabis가 대국 끝나고서 KAIST에서 했던 강연 영상이에요. 그래서 여기에서 DQN 같은 거 보여주고 실제로 그게 어떤 맥락에 있는가 같은 것들을 짚었던 얘기들 같은 것들도 해주고 그런 것들을 조금 실감 나게 볼 수 있었던 2016년의 경험이었던 것 같습니다.
노정석 14년, 15년, 16년 이때 하면 사실 DQN만 하더라도 엄청난 첨단 기술이었고 그리고 OpenAI Gym에서 RL스러운 것들 조금씩 해보던 그런 때였던 것 같아요.
최승준 저도 그때 소회 같은 것들을 소셜미디어에 감정을 담아서 썼던 기억들이 나고요. 그래서 저희가 오늘 조금 역사를, 10년을 돌아보는 이야기를 하기 전에 최근에 이게 관련이 있다고 저는 느껴졌는데 Autoresearch가 핫하더라고요. Andrej Karpathy가 작년에는 vibe coding이라고 코딩으로 밈을 선점하더니, 올해는 Autoresearch로 뭐랄까 딱 이렇게 쥐어 잡은 느낌인데 어떻게 보셨나요?
Andrej Karpathy의 Autoresearch와 검증 가능한 신호의 반복 10:24
노정석 이거 Ralph loop랑 뭐가 다른 거예요?
최승준 Ralph loop죠. 하지만 작동하는 딱 도메인, 딱 영역에서 평가 가능한 validation, 그것만 한 거죠. 테스트까지 아니고 그냥 validation 점수만 가지고서 그거를 낮출 수 있는 쪽으로 온갖 아이디어를 내서 실험하고 실험하고 계속 그거를 할 수 있게 하는 그런 느낌이었죠.
노정석 컨셉으로는 RLVR하고 사실 비슷한 거죠. 그러나 레이어가 다른 거죠. RLVR을 학습 과정에서 어떤 그 verifiable한, 검증 가능한 신호를 줄 수만 있다면 그 도메인에서 학습을 계속할 수 있다라는 얘기를 한 거고 얘는 실질적으로 응용하는 과정에 끌고 와서, 그렇죠. 연구나 이런 것들도 결국은 굉장히 뛰어난 모델에게 보상 신호, 좋아지는 방향에 대해서 어떤 목표 설정을 할 수 있다면 자율적으로 걔가 그 목표를 향해서 나아갈 수 있다라는 거를 보여준 거죠.
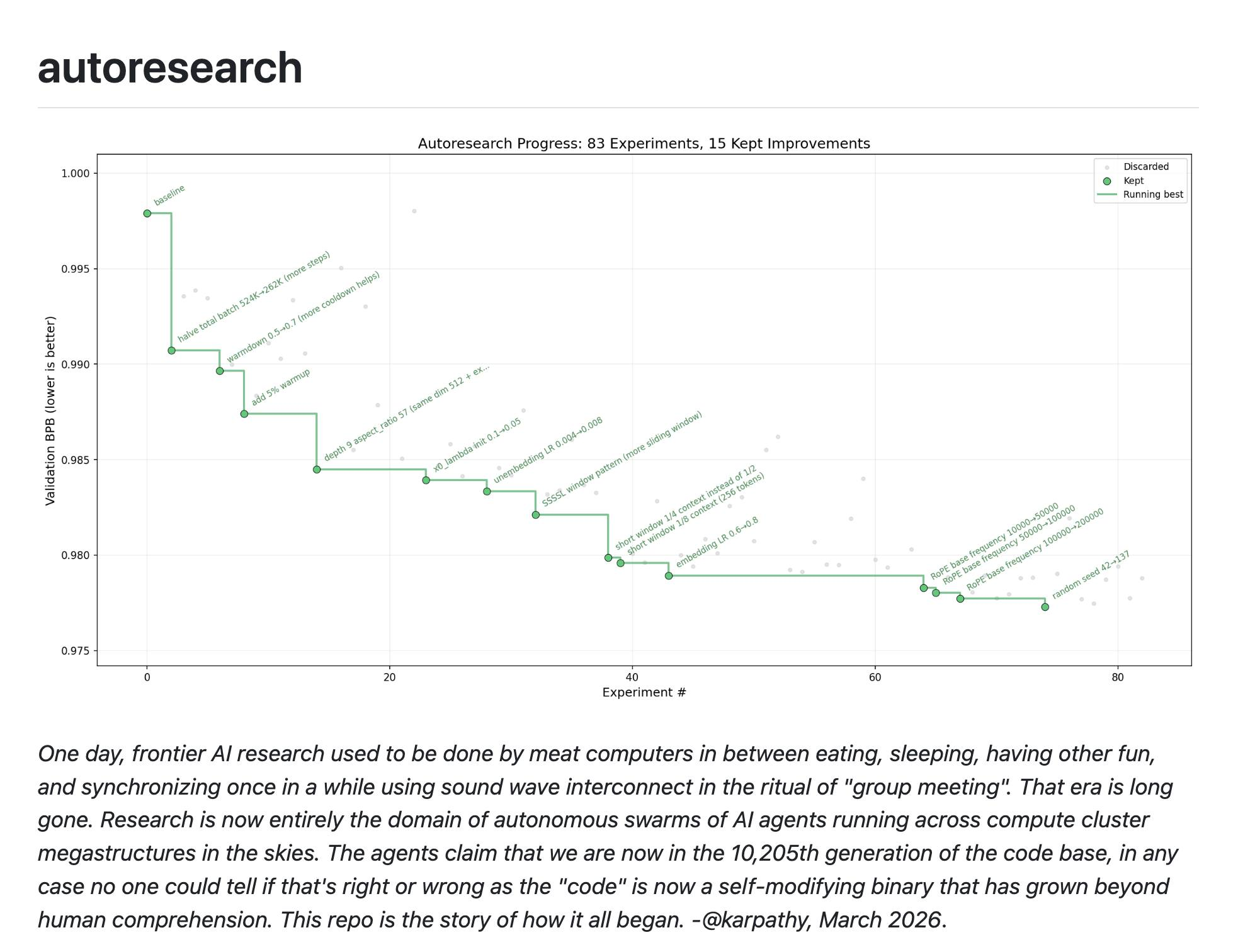
최승준 보상 신호가 RL에서의 보상 신호가 아니라 미분 가능하지 않은데도 그냥 어떤 되고 안 되고만 판정을 해 줬는데 굉장히 간단한 몇 개의 파일, prepare.py, 이거는 별로 중요하지 않고 train.py, program.md 이렇게 있으면 그 조건을 달성하는 거를 될 때까지 낮추는 쪽으로 리서치를 하는 건데 MD 파일이 별로 길지도 않아요. 맨 끝에 재미있는 게 있는데, never stop. 멈추지 말고 만약에 막히면, 아이디어가 막히면 페이퍼 읽고 오고 이 가설 세우고 실험해보고 저 가설 실험해보고, 나한테 계속 갈 거냐 물어보지 말고 계속해라라는 거가 마지막 주문인 것 같은데 그거를 실제로 성과를 보고 있는 것들이 여기에 그래프로 보이고 있죠.
그런 건데 여기 그 Andrej Karpathy하고 Yuchen Jin라는 분이 최근에 이분도 CEO였다가 지금 다른 거 하려고 내려오신 분인 것 같은데 이런 아이디어까지 얘기를 하더라고요. 이게 지금 하나의 스쿼드를 돌리거나 그냥 에이전트 하나가 쭉 이렇게 깊게 들어가는 느낌이라면 그런 연구자들의 소셜미디어를 moltbook처럼 만들면 어떠냐 그런 얘기까지 하는 소셜미디어 포스팅을 좀 재미있게 봤고요.
파생 작업들이 있는데 이거는 그 TinyStories를 어떻게 최적화하는가, 또 TinyStories도 데이터가 작은 셋에 잘 정제되어 있어서 그거 낮추는 거를 통해서 이 사람이 배운 거. 그다음에 이거는 Sparse Autoencoder라고 기계론적 해석 가능성 연구에서 쓰는 것들을 잘 할 수 있게 하는 거를 Autoresearch 방식으로 하는 거. 그리고 이거는 Simon Willison이 사례를 공유해 줬는데 Shopify의 CEO, 이 Tobias라는 분이 자기가 예전에 만들었던 어떤 것을 53% 빠르게 하는 그런 거에 Autoresearch를 응용해서 해냈다. 그러니까 작동하는 영역에서는 이게 다 된다는 거죠.
안 되는 것들도 물론 있겠지만 안 되는 영역이 훨씬 더 많겠지만 작동하는 영역에서 심플하고 우아하게 이거를 토큰을 제대로 태워서 할 수 있는 그런 경로들이 발견되고 있는 중입니다. 근데 그 잘 작동하는 영역이 공교롭게도 AI 훈련하는 그거죠.
노정석 네, 목표를 명확하게 했던 거가 evaluation metric을 명확하게 정의할 수만 있으면 벤치마크가 존재하면 거기는 무조건 된다.
최승준 맞아요. 작년에 정석님이 그 verifiable하게만 바꾸면 많은 것들이 해결될 것 같다, 그런 말씀하시기도 했죠.
노정석 그렇죠. 요새 유행하고 있는 프레임워크들도 다 비슷한 방향성인 것 같아요. 일단 결과를 낼 때까지 무조건 훅을 걸어서 영원히 반복하게 하는 Ralph loop를 기본 탑재하고 Ralph loop가 성공하기 위해서는 그 앞과 뒤를 잘 제어해 주면 되거든요. 출발할 때 굉장히 명료하고 깔끔한 컨텍스트로 시작하는 그 플랜을 만들어주는 거, 그리고 명확하게 이게 되면 성공이다라고 하는 그 evaluation metric을 정의해주는 거. 그래서 기본적으로는 다 Ralph loop고 무한 반복이라는 거는 똑같은데 그 앞과 뒤를 어떻게 정교화하느냐라는 쪽으로 요새 이 커뮤니티가 발전하고 있는 것 같아요.
최승준 그래서 저도 효과를 본 게, 제가 3월 달에 안 풀리고 안 풀리고 아직도 100% 푼 건 아니지만 성공한 케이스가 결국에는 제가 이거를, 이거 메꾸는 거 안 되던 거를 다 모델링을 하는 코드를 짜고 모델링을 직접 해서 제가 일종의 ground truth를 제공하고 이거와 비슷하게 달성할 때까지 돌리니까 알고리즘이 나오더라고요.
노정석 될 때까지 그냥 계속 돌리신 거거든요.
최승준 이게 앞으로만 가는 게 아니라 뒤로 가서 가설을 세우고 다시 가보고, 안 되면 뒤로 가서 다시 가설을 세우고 그거가 되는 알고리즘을 찾아가는 과정을 흥미롭게 볼 수 있었어요.
얻었던 교훈은, 아 정확한 피드백과 정확한 데이터를 주는 게 매우 중요하구나. 내가 이런저런 알고리즘을 스스로 고안하거나 모델이 고안하게끔 안내하는 방법도 작동하는 부분이 있겠지만 그냥 end to end로도 할 수 있구나, 그런 생각을 좀 하게 됐습니다.
Ralphthon: 계획과 평가 하네스 설계의 중요성 16:05
노정석 엊그저께 구봉 님이 Ralphthon이라는 거를 하셨더라고요. OpenAI와 함께 Ralphthon 개최하셨는데, 그게 굉장히 재밌는 게, 그 계획을 한 번 짜고 나면 그다음 12시간 동안은 손을 댈 수 없어요. 그냥 RL 루프로만 돌아야 되는데 공교롭게 그거 1등, 2등 하신 분들이 다 하네스의 설계자들이에요. 1등 하신 분들은 그 Ouroboros라는 하네스를 만드신 분이 1등 하셨고, 2등은
최승준 계속 돌아가는 거네요.
노정석 Oh-My-Codex 만드신 허예찬 님이 2등 하신 것 같은데, 그 로직들을 보면 다 원칙이 있어요. 무한, 될 때까지 무한 반복은 맞는데 어떻게 계획을 정교하게 세우느냐, 그리고 이 결과를 어떻게 evaluate 하느냐, 이런 부분들에 하네스를 정교하게 짜신 분들이 이것들을 더 성공하시더라라는 것들이 러닝이었어요. 구봉 님이 본인이 얻으신 러닝을 정리해 놓은 슬라이드가 있어서 제가 그거 읽었었는데, 너무 맞는 방향이다라는 생각이 들고 방금 Autoresearch나 이것도 뭐 맥락은 다 비슷한 것 같 다라는 생각은 하고 있습니다.
최승준 기억하시나요? 비슷한 거 작년 10월쯤에 OpenAI에서 얘기했던 거.
노정석 그때 Sam Altman과 Chief Scientist인 Jakub Pachocki 둘이 나와서 작년 10월에 발표했죠. OpenAI의 비전 발표하면서, 26년 8월이면 AI 리서치 그쯤이에요. AI 리서치 인턴이 완성될 거고 그로부터 2년 후에 AI 리서치 PhD가 완성된다는 이야기로 이렇게 모호하게 돌려서 얘기했는데 AI 리서치 인턴이 된다는 얘기는 Autoresearch스러운 일이 된다라는 얘기를 한 거죠.
최승준 그래서 지금 Andrej Karpathy도 트위터나 블로그 같은 거에 썼던 거가 결국에는 이게 빅테크가 하고 있는, 싸우고 있는 영역일 것이다. 자기 증강하는 그런 얘기를 한 거고, 자기도 그런 아이디어를 가지고서는 굉장히 심플하고 단순하게 했는데 그게 좀 바이럴 해주고 있는 2026년 3월 현재인 것 같네요.
노정석 맞아요. 사람들이 농담 삼아서 다 그렇게 얘기하잖아요. 저희도 단톡방에서 그 얘기하고 있는데, 저희 어떤 서비스들이나 이런 거 단톡방에 올라오면 “아 저건 1 딸깍 away다” 아니면 “저거는 한 2 딸깍s away, 3 딸깍s away” 뭐 이런 식으로 저희 장난 삼아 얘기하는 그런 것들이 있는데, 그런 2026년 3월을 보내고 있죠.
”라떼는 말이야” - AI 10년 회고 시작 18:44
노정석 자 이제 과거로 한번 가볼까요? 저희 “라떼는 말이야”로 한번 들어가 볼까요?

최승준 이렇게 좀 저희가 티키타카 얘기해 볼 거가 자기 자신들의 이야기들도 될 수 있고 어떤 흐름들이 있었냐인데, 제가 인지하고 있었던 것도 기억이 바로 나는 것만 좀 몇 개를 뽑아봤습니다. 2011년 즈음에는 이거를 타임라인에서 봤었거든요. 이게 Peter Norvig의, 구글 지금도 계신, 구글에 계신지는 가물가물한데 어쨌든 가장 시니어 사이언티스트였죠. Peter Norvig하고 X 하셨던 분이죠. Google X, Sebastian Thrun. 나중에 Udacity 만들었던 분이 같이 AI 강의를 스탠퍼드에서 열었었고, Andrew Ng이 머신러닝 강의를 열었었고, 그다음에 데이터베이스 강의가 또 하나 있었대요. 그거에 대한 타임라인을 훑어보니까 이런 얘기들이 나왔습니다. 그래서 스탠퍼드에서 MOOC, 현대적인 MOOC의 효시가 되는 그런 실험들을 했었고 그거가 모두 다 AI, ML, 데이터베이스 이렇게 돼서 이 정도 인원들이 몰렸다고 합니다.
근데 여기 Daphne Koller라는 이름이 있는데, Daphne Koller가 Coursera를 Andrew Ng하고 공동 창립하고, 이분이 insitro 하셨던 분이에요. 생명과학하고 연결된 분이고, 그래서 이런 것들이 있었고 거기에서 사람들이, 저 포함하고 뭐 다른 분들도 마찬가지시겠지만 딥러닝을,
진원 님은 딥러닝 어떻게 시작하셨어요?
딥러닝 입문기: ImageNet과 삼성전자 NPU 개발 20:22
이진원 저는 굉장히, 이게 어떻게 보면 이 팟캐스트랑도 비슷하다고 할 수 있는데 시작이, 제가 일을 하다가 좀 뭔가 루틴한 거를 벗어나고 뭔가 세상을 바꿀 만한 뭔가가 없을까를 좀 호기심으로 찾아봤던 것 같아요. 근데 그때 제가 2014년에 ImageNet에서 구글이 1등을 했다 이런 거를 보고 그때부터 좀 관심을 가져서, 이게 딥러닝이라고 하는 게 뭘까 그때부터 좀 찾아보게 됐죠.
근데 예전에 우리 다들 얘기하지만 딥러닝, AI 혹은 머신러닝의 암흑기라고 하는 시절이 있었던 거잖아요. 그래서 딥러닝이 어떻게 보면 리브랜딩 된 이름인 건데, 뉴럴넷이라든지 이런 거 하면 다들 싫어하던 그 상황을 좀 돌파하기 위해서 딥러닝이라는 말을 써서, 좀 “이게 뭐지” 하고 봤는데 결국 그거랑 맥락을 같이 하는 거였고 대신에 스케일이 커지고, 우리가 앞에서도 이 팟캐스트에서 여러 번 얘기했던 Bitter Lesson에 나오는 결국 인간의 inductive bias를 줄이고 스케일을 키우는 형태로 AI가 발전하면서 ImageNet이라고 하는, 그때 당시에는 ImageNet이라는 딱 우리가 해결해야 되는 벤치마크가 있었어. 그거에 모두가 도전하던 때였잖아요. 그래서 그때부터 봤어요.
근데 자연스럽게 그런 것들이 나오면서 제가 있던, 제가 그때 당시에는 삼성전자에서 스마트폰에 들어가는 반도체를 개발하고 있었는데 거기에도 NPU라고 하는 거를 만들게 되고 그거를 만들게 되면서 그런 생각을 더 많이 했던 것 같아요. 제가 예전에 만들던 반도체들은 어떤 것들이 있었냐면, 예를 들면 뭐 동영상 코덱 같은 거. 그런 거는 특징이 뭐냐면 스탠다드 스펙이 정해져 있거든요. 사람들이 모여서 스펙을 정하고, 그러면 뭘 해야 되는지, 이 반도체가 뭘 해야 되는지는 이미 정해져 있고 그걸 어떻게 효율적으로 잘 돌릴 거냐, 이거를 잘 만드는 게 좋은 반도체의 조건이었다면 NPU라고 하는 AI 반도체는 무엇을 해야 되느냐에 대한 게 계속 바뀌는 거죠. 알고리즘이 새로운 것들이 계속 나오고 진화를 엄청나게 빠르게 하고 그때 제가 내가 좋은 반도체를 만드는 데 있어서 AI 알고리즘을 잘 이해를 못하면 좋은 반도체를 만든다는 건 말이 안 되는 일이다.
그래서 그때부터 논문도 많이 보게 됐고 아까 앞에서 말씀하신 그 PR 12라는 것도 그런 식으로 해서 시작을 하게 됐던 것 같아요. 저도 논문을 많이 보고 있으니 같이 보는 사람들이랑 의견도 나누고 공유할 수 있으면 좋겠다, 그러면서 공부도 하고 논문도 읽고 그렇게 시작을 했던 거죠.
최승준 2014년 정도에 시작을.
이진원 그렇게 제가 시작했던 건 공부였어요.
유튜브 고양이 인식 실험과 창발 현상 23:00

최승준 그리고 이거 기억나실지 모르겠는데 핵심을 보자면 이 그림이죠. 유튜브에서 고양이를 인식하기 시작했다, 그거였죠.
노정석 이게 실험이 어떻게 설계돼 있는지는 정확하게 안 나와 있는데 이 그림을 보고 제가 이상호 박사님이랑 호들갑을 떨면서 막 얘기했었던 기억이 나는데 얘가 한 유튜브, 그 당시만 하더라도 한 천 대 정도 되는 클러스터 여기에다가 놓고 CNN 구조 비슷한 것들을 놓고 그냥 unsupervised로 유튜브 클립들을 쭉 다 보냈는데 이 특정 레이어 어딘가에 고양이 얼굴을 인식하는 필터가 생겼다, 그런 그림이 몇 장 있었거든요.
그래서 아, 지능이라는 게 특별한 걸 하지 않아도 그냥 학습에 의해서 소위 창발할 수 있다, emerge 할 수 있다라는 걸 보여주는 예시였어요. 저도 너무 오래돼 가지고 어떻게 실험 설계가 됐는지는 잘 생각은 나지 않아서.
이진원 아마 제가 기억하기로는 그 autoencoder 형태로 했었던 것 같고요. 이 이미지를 넣고 그걸 다시 복원하는 형태로. 그러다 보면 이게 딱 전형적인 우리가 LLM에서 많이 얘기했던 창발 현상이죠. 방금 말씀하신 것처럼.
노정석 놀랐죠. 모두가. 이건 누가 봐도 고양이였으니까.
최승준 그때는 그런, 놀라긴 했지만 저는 그냥 그런가 보다, 당연히 될 것 같았는데 아직도 안 됐다고?의 느낌도 있긴 있었거든요.
노정석 저도 그냥 뉴스로 넘어갔었고 저때는 딥러닝, ImageNet 이런 것보다 IBM이 만든 그거 있었죠. 퀴즈 프로에 가서 얘기하던, Jeopardy에 있었던 IBM의 Watson. Watson의 파이프라인이 유행하고 연구하던 때였죠. 한참 또 음성 인식 같은 게 그 당시에 뉴럴 네트워크가 아닌 그 HMM, Hidden Markov Model 가지고 만들어지던 때여서. 학습하면 그런 게 더 먼저 되던 때였던 것 같습니다. 저도 사실 2014년 정도가 될 때까지는 그래, 저런 거 있구나, 신기하다라고 했지 머신러닝이 뭔지만 알고 있었지 딥러닝을 본격적으로 공부해 봐야 되겠다라는 생각은 한 14년 정도부터 했었던 거죠.
최승준 저도 그 Andrew Ng의 강의나 Peter Norvig의 강의가 있다는 걸 알고 영상이나 자료 몇 번 봤지 그걸 파고들 생각은 안 했었거든요.
Andrej Karpathy 문서와 ImageNet 전성기: CS231n, DeepDream, Chris Olah 25:21
최승준 그러다가 타임라인에서 바이럴해졌던 게 이 Andrej Karpathy의 Hacker’s guide to Neural Networks라는 문서가 또 굉장히 회자됐던 것 같습니다.
보셨던 기억들 나지 않으세요?
다 backprop 어떻게 하고, computation graph 어떻게 생기는데 이거 생각보다 그렇게 어려운 거 아니다라면서 JavaScript로 이거를 설명하는 그런 내용이었거든요.
노정석 이게 어느 때에 누구와 함께 어디서 무슨 일을 했냐라는 게 참 중요한 게 이게 인생의 타이밍인데 Karpathy가 그 ImageNet, 화제의 한 중심이던 ImageNet을 하던 Fei-Fei Li 교수님의 박사 과정 학생이었죠.
최승준 그래서 여기가 PhD student Stanford라고 돼 있고 ConvNetJS 만들었다. ConvNetJS가 당연히 Fei-Fei Li 작업하고 관련된 경로니까 그런 거를 하고, Karpathy가 그런 걸 또 알려주고 공유하는 거를 굉장히 좋아하는 성향이었더라고요.
노정석 그때 벤치마크는 지금의 AIME라든지 아니면 Humanity’s Last Exam 이런 벤치마크처럼 그때 가장 유행하던 벤치마크는 ImageNet 점수였잖아요. top-5 accuracy였는데 그때 막 VGG.
최승준 그래서 막 이런 거 만들어서 공유하고 그랬거든요. 웹에서 이런 거 할 수 있다.
이진원 저도 생각나는 게 그 VGG, VGG가 그때 2014년에 2등, classification에서 2등 했었는데 그래도 GoogLeNet보다 훨씬 더 많이 쓰였거든요. 그때 당시에. 왜냐하면 VGG는 굉장히 심플한 아키텍처, convolution도 3x3 convolution만 계속 쌓아 올려서 할 수 있다는 거를 보여줬고, 그래서 이게 심플하니까 다양한 곳에 응용이 될 수 있겠다 해서 사람들이 많이 시도를 했는데.
저도 그때 생각나는 게 제 집에 있는 GPU, 그때 당시에 그 메모리가 2GB였거든요. 2GB짜리 GPU를 꽂아놓고 그거를 학습을 해 보겠다고. 근데 batch가, 정확하게 기억이 안 나는데 batch가 한 2 정도까지밖에 안 됐던 것 같아요. 그래서 그래도 그거라도 해보겠다고 막 돌렸던 기억이 있습니다.
노정석 그때는 뭘 해도 정말 신기할 때였어요. 2014년이 VGG, 아니 GoogLeNet인가가 우승하고 2015년에 ResNet이 우승했고, 이랬던 기억이 나요.
최승준 그래서 그런 어떤, 당시에는 비전 관련된 것들이 되게 핫했죠. 그래서 CS231n의 원래 제목이 Deep Learning for Computer Vision이었거든요. 그래서 여기에서도 기라성 같은 인물들이 나중에 또 나오게 되기도 했고.
이진원 거기에 강의를 하셨던 분들이 많이 스타가 됐죠, 사실.
노정석 저기 Justin Johnson은 맞아요. 유명한 사람이죠.
최승준 지금 Fei-Fei Li하고 World Labs 하고 있죠.
노정석 맞아요. 미시간대 교수로 갔다가 다시 Fei-Fei Li랑 창업한 것 같아요.
최승준 Jian Fan도 있습니다. Jian Fan도 여기 출신이고.
노정석 또 이때 유행하던 게 style transfer라는 거였는데 이렇게 고흐풍 그림으로 사진 바꿔주고.
이진원 neural style이라고 불렀던 거.
노정석 맞아요, neural style. 저희 Justin Johnson이 Lua로 깔끔하게 Torch implementation을 만들어서 저도 많이 돌렸던 기억이 납니다.
최승준 그리고 그런 비전 관련된 거에서 그게 왜 작동하는지를 단초가 된 게 결국에는 Chris Olah 그리고 Alexander Mordvintsev 등이, Mike Tyka, 그렇게 했던 분들이 작업을 했었던 그 DeepDream이라고 불리는 작업인데 이게 예술 쪽에서도 많이 회자가 됐지만 결국에는 그 feature 증폭이잖아요. 이게 어떤 해석 가능성 연구의 단초가 되는 작업으로도 지금은 계보가 말해질 수 있는데
그런 이야기들이 Chris Olah를 주축으로 했었던 그 Distill.pub에서 궤적이 되게 잘 남아 있습니다. 그래서 Olah는 이런 거, 되게 여기 제목 보면 사람들 보면 David Ha도 있고 Olah도 있고 그러거든요. 그래서 이게 RNN 가지고서는 필기 예측하고 하는 거. 주로 비전 쪽 얘기들이 초반에 많았는데 여기는 RNN 얘기가 있어서.
그리고 Chris Olah가 Jeff Dean이 딱 그, Olah가 어렸을 때 “이 사람 데려와야겠다”라고 했던 일화도 있는 건데 2014년 즈음에 Karpathy가 그런 거 많이 공유했을 때도 Olah는 훨씬 어렸는데도 이런 작업들을 공유하고 Yann LeCun한테 댓글 받고 막 그랬었어요.
아직도 그 블로그들이 되게 잘 남아있어서 거기도 좀 재밌습니다.
노정석 이때 한참 시작했던 사람들이 한 4~5년이 지나서 사실 메인스트림이 됐어요. 그리고 2014년이, 2014년 15년만 하더라도 저희가 다 이미지와 스타일 트랜스퍼, CNN, 이런 얘기, ImageNet 이런 거 하고 있을 때였는데 Ilya Sutskever가 시퀀스 투 시퀀스 페이퍼 낸 게 14년이에요. 그런데 RNN을 저희가 가지고 막 신기한 거 학습하고 챗봇 만들고 가지고 놀기 시작한 거는 한 15년 지나서 16, 17년 정도 됐을 때였던 것 같아요.
최승준 Ilya Sutskever의 시퀀스 투 시퀀스의 공동 저자가 Oriol Vinyals였나, 아직 DeepMind에 있는 분. 아마 헷갈리긴 하는데요. 그랬던 것 같기도 하고. 어쨌든 이런 궤적들은 Chris Olah가 결국에는 Anthropic의 공동 창립자 중에 한 명인데 Anthropic의 해석 가능성 연구에 Transformer Circuits의 포스팅 등으로도 계속 꾸준히 연결이 되고 있다.
이진원 근데 저는 Chris Olah 하면 사실 제일 생각나는 거는 RNN 관련된 도식화되어 있는 그림, 블로그에 지금도 강의에서 그 그림을 다 가져다가 사용을 했었거든요.
최승준 굉장히 깔끔하게 그렸어요. 인터랙티브하게 또 작업도 해볼 수 있고. 저는 개인적으로는 TF.js라고 Deeplearn.js로 나왔다가 TF.js로 바뀐 이 코드를, AlphaGo 나오고서는 이거 좀 충격을 받았는데 제가 그래도 좀 이해해 볼 수 있는 정도의 구현이어 가지고 이 코드를 벽에다가 붙여놓고서는 외우듯이 봤던 기억이 납니다. backprop이 어떻게 되고 어떻게 해야 되고. 그래서 당시에 제가 아이가 태어났던 즈음인데 아기 띠 메고 왔다 갔다 하면서 이거를 봤던 기억이 나고요. 그다음에 이게 16년에 정석님 에피소드 얘기해 주실 수 있지 않을까요? 이게 구캠에서, 구글 캠퍼스 서울에서 이런 행사가 있었대요.
딥러닝 프레임워크의 변천: Theano에서 PyTorch까지 31:04
노정석 네, 저는 안 갔었어요. 사실 그때 구글 캠퍼스에 Eric Schmidt도 오고 텐서플로 코리아 모임도 여기서 하고 AlphaGo와 함께 구글이 좀 커뮤니티의 중심에 강하게 서던 때였어요. 그래서 Jeff Dean도 그때 왔던 기억이 나는데 저는 가진 않았습니다.
이진원 제가 여기 갔었는데 사실 기억이 많이 남아 있지는 않아요. 사람들이 굉장히 많이 오셨었고 그때 기억나는 거는 사람들이 챗봇에 그때도 관심을 많이 가졌었는데, Jeff Dean은 그때 제 느낌으로는 챗봇에 그렇게까지 관심이, “챗봇 뭐 그게 그렇게 어려운 건가” 약간 이런 식의 답변을 했던 기억이 좀 남아 있어요.
근데 이때 우리 사실 AlphaGo 그 무렵 좀 전이죠. 3월 9일부터 AlphaGo가 시작했으니까 바로 직전이고, TensorFlow 그때 당시에 사실 제일 사람들이 많이 썼던 건 Caffe라고 하는 거를 많이 썼었는데 Caffe는 아무래도 학교에서 개발한 프레임워크다 보니까 구글이 제대로 여기에 들어와서 한다라는 것 때문에 TensorFlow에 대한 관심이 아주아주 높았던 시절이었죠.
노정석 session, feed_dict 뭐 이런 용어들이 생각납니다.
최승준 그렇죠. 지금 그런 도구들 이름 나온 김에, Andrew Ng 강의의 초반 거는 Octave를 하는 거를 공부를 했어야 되는, 실습을 했어야 되는데 그게 MATLAB의…
노정석 약간 오픈 소스 버전.
최승준 그렇죠, 오픈, 자유, GNU, 그러니까 GNU 버전이죠. 그걸로 좀 힘든, 어떻게든 꾸역꾸역 했던 느낌이고. 저도 기억나는 게 DeepDream 이런 거 돌리려면 아직 Caffe나 Theano 이런 거를 했었어야 됐어요. 그런 거, DeepDream이 물론 TensorFlow 구현도 물론 나오긴 했지만 거기에 파생하는 작업들을 이런 걸 했어야 되는데. 지금 순서를 한번 보니까 Torch가 2002년, Theano가 2007년, Caffe가 2013년, Keras가 TensorFlow보다 조금 먼저 나왔더라고요. Keras, TensorFlow, PyTorch, 이런 순서로 나왔던 거를 살펴봤습니다.
이진원 Theano가 사실 TensorFlow의 전신이라고. 개발자들도 많이 가셨고.
최승준 근데 훨씬 편한 건 PyTorch 왔을 때가 좀 더 편해지는, 근데 그랬던 기억이 나고요.
노정석 그렇죠. 사실 2016년 정도 됐을 때는 PyTorch랑 TensorFlow 양강으로 굳어지던 때였고.
최승준 요새는 TensorFlow 사용하시나요? 잘 모르겠네요.
노정석 글쎄요. 저도 저도 PyTorch를 거의 안 한다고 봐야 되겠죠.
최승준 그러고 보니까 PyTorch 실행시켜 본 지도 사실 좀 오래됐어요. 요 몇 년간, 네, 가끔 뭐 Google Colab에서 뭘 한다거나 뭐 그 정도지 제대로 해본 기억이 잘 안 나네요.
노정석 네, 저도 2020년 정도가 마지막인 것 같은데.
최승준 그래서 뭐 이 당시에 또 유명했던 게 김성훈 대표님이 홍콩 과기대에 계셨을 즈음이었죠. 그래서 막 모두의 딥러닝 이런 강의들 하셨던 때고 이게 2016년 초, 이게 결국에는 AlphaGo 충격의 파생인 것 같아요. AlphaGo에 사람들이 충격을 받고 이거 제대로 알아야겠다고 함께 공부하는 그런 분위기가 형성됐고 그게 페이스북에 텐서플로 코리아 페이스북 그룹이 만들어지고 행사들이 있고 제주도를 가서 같이 워크숍 하기도 하고 그랬던 것.
이진원 제가 여기 텐서플로 코리아, 지금은 AGI Korea라고 페이스북에 이름을 바꾸긴 했는데 텐서플로 코리아 제가 여기도 운영진이었고 굉장히 재미있는 것들이 많았어요. 그리고 TensorFlow 이게 유저 그룹, 정확하게 유저 그룹이라고 하기는 그렇지만 어쨌든 그런 성격이 있었고 유저 그룹이라고 친다고 하면 이게 전 세계에서 제일 큰 규모였어요. 그래 가지고 실제로 구글 행사 같은 데서도 소개가 되기도 하고 그랬었어요.
최승준 시작이 아마 구글 코리아에 권순서 님하고 김성훈 대표님이 같이 하고서 많은 분들이 같이 운영 위원으로 참여하셨던 것 같고. 생활 코딩 이고잉 님의 생활 코딩과 텐서플로 코리아이었죠. 뭔가 페이스북 타임라인이 늘 보이는 거가 그랬던, 커뮤니티가 막 이렇게 에너지가 있었던 시기였던 것 같고요.
David Ha와 크리에이티브 코딩: 커뮤니티가 남긴 흔적 35:45
최승준 그런데 제가 또 재미있게 본 거는 그때 좀 수상한 블로그가 있었어요. 이렇게 생긴 블로그, 이렇게 이렇게 쭉 내려보면 머신 러닝으로 약간 미디어 아트스럽다기도 할 수 있고 크리에이티브 코딩스러운 그런 것들을 막 이렇게 올려놓는 분이 있었어요.
그래서 이분이 이게 otoro가 참치 대뱃살이거든요. 참치 대뱃살 스튜디오라는 거, 사이트를 막 이렇게 살펴보고 그랬었는데 거기에 보면 TensorFlow 가지고 한 창작 작업들이 막 올라와. 이런 것들도 있었고, 이거는 시각적으로 멋지지는 않지만 나와 있는 것들 중에는 제가 인상적으로 봤던 거는 초기 작업 중에 한자, 한자를 없는 한자를 만들어내는 거가 유명한 게 한참 더 여기 즈음인데 이런 식으로 세상에 없는 한자를 만드는 그런 작업을 했었어요.
그런데 이 사람이 누구냐 하면 금융권에 있다가 프로세싱이 있는 걸, 나와서 Processing 같은 걸 공부하고 자기가 작업하는 걸 이렇게 올렸던 사람이 누구냐 하면 현재는 구글 거쳐서 Sakana AI의 대표로 있는 David Ha입니다. David Ha의 사이트에서도 재밌는 것들을 보고 배웠던 기억이 나고.
이진원 요거 가기 전에 사실 제가 하나 얘기해 보고 싶은 게 있기는 한데 승준 님이랑 제일 관련이 있을 것 같은데 사실 이게 제가 딥러닝이라고 하던 시절에 지금도 사실 좀 그렇지만 논문도 읽고 하다 보면 이게 굉장히 유행을 많이 탄다는 생각을 되게 많이 했어요. 사람들이 이게 잘 되네 하면 AlphaGo 때는 강화 학습에 사람들이 엄청 많이 관심을 가졌었고 그런 식으로 유행이 막 흘러가던 중에 사실 어떻게 보면 지금 diffusion generation 하는 거에 전에 GAN이라고 하는 그때 굉장히 유행해서 논문이 거의 그쪽으로만 쏟아지던 시절이 있었거든. 승준님도 그때 좀 그런 것들을 써보신 경험이 있으신가요?
GAN의 유행과 생성 AI의 시작 37:01
최승준 맞습니다, 맞습니다. GAN에 관련된 걸 제가 제대로 구현까지는 못했지만 탐독을 했고, 그 당시에 NeurIPS라고 부르기 전에 NIPS라고 불렀을 시절에 그런 얘기들이 어마어마하게 많았었잖아요.
이진원 재밌는 게 그 Ian Goodfellow의 GAN 논문에 보면 그 술집
최승준 술집, 맞아요. 맥주 마시러 가가지고
이진원 맥주가 너무 맛이 없어가지고 거기서 연구 아이디어를 떠올리게 됐다, 이런 일화가 있었던.
최승준 생성자와 평가자의 discriminator랑 generator에 있어서 걔네들이 경합하게 하는 그거 가지고서 또 한참.
노정석 근데 그게 결과가 참 신기한 게 많았어요. 지금으로 보면 저희가 첫 번째 생성 케이스였잖아요. 뭐 image-to-image translation, text-to-image translation 해서 뭐 DCGAN 무슨 GAN에서 계열도 어마어마하게 많았던 것 같고. 저도 그때 뭐 패션 사업하던 때였는데 그걸 이용해 가지고 스타일 생성하고 이런 거 했던 기억이 납니다.
최승준 그거를 AI를 활용해서 만든 걸 뿌렸을 때 StyleGAN 같은 것들이 또 쓰이기도 하고 그랬던 기억이 납니다. Refik Anadol이라는 작가예요.
노정석 그때만 하더라도 신기하긴 한데 아직 이거 뭐 써먹을 정도는 못 돼 라는 게 전반적인 평이었죠. 그저 신기할 때였습니다. 뭐 되는 게.
클럽하우스 시절 WeeklyArxiv와 Transformer로의 전환점 38:52
최승준 클럽하우스 시절에는 사람들이 만나지를 못하니까 그냥 온라인으로 AI 얘기하고 그러는 방들이 많이 있었죠. 이게 그 뒤에 지금은 수석님이 되신 하정우 박사님이 WeeklyArxiv 토크랑 만담이라는 걸 또 하고 그러셨죠? Zoom에서 하고 그랬던 기억이 나는데요. 저도 게스트로 한두 번 정도는 참여했던, DALL-E 나오고 그랬을 때 기억이 나는데 이것도 또 진원님 관련이 있으시죠?
이진원 네, 이것도 제가 시작할 때 같이 지금 하정우 수석이랑 같이 모더레이터, 그때 당시에 우리가 클럽하우스에 항상 모더레이터라고 하는 게 유행처럼 용어로 쓰였었는데, 고정 모더레이터로 참여를 해가지고
이때는 일주일에 한 번씩 그 주에 나온 AI 논문이랑 또 AI 뉴스들 이런 것들을 돌아가면서.
누구든지 그 클럽하우스가 그런 거였잖아요. 누구든지 손들고 올라와서 얘기하고 또 할 말 없으면 내려가고. 이렇게 재밌게 했었던 것 같습니다.
노정석 저희가 그 앞으로 갑자기 18년 뒤로 이렇게 휙 뛰긴 했는데 사실 2021년 HyperCLOVA가 나오기 전에 저희가 이벤트 하나 반드시 짚어야 되는 게 Transformer잖아요.
Transformer와 Attention의 기원: Bitter Lesson 관점 40:02
최승준 저희가 그 Transformer는 그동안 너무 많이 다뤘어 가지고.
노정석 그리고 2016년만까지만 하더라도 그때가 막 attention 나오고 이러던 때였던 것 같아요.
최승준 attention도 원래는 이미지 쪽에서 먼저 시작이 됐다가 넘어간 거죠.
이진원 그게 Show, Attend and Tell 이런 페이퍼들이 있었어요. 그래서 그림을 보고 그거에 대한 설명을 생성하는 걸 할 때 어디를 attention을 할 거냐 이런 것들이 있었고. 좀 더 뒤긴 하지만 2017년에 ImageNet이, 2017년이 마지막 대회였는데 그때 우승했던 네트워크이, Squeeze-and-Excitation Network이라고 하는 게 있었는데 그것도 사실 CNN에서 그 이미지들이 feature map으로 이렇게 쌓이게 되는데 그중에 어떤 feature map에 attention을 할 거냐 학습하는 거였죠. 사실 그때 사람들이 attention이라고 얘기하지 않았지만 나중에 와서 보니까 이게 사실 attention이었구나라는 걸 알게 됐었고.
사실 Transformer 하면 저도 기억나는 것들이 많은데 그 Transformer 그 논문이 “Attention Is All You Need”라고 하는 제목이었고 사실 제목부터 관심을 좀 끌었죠. 그리고 그때 당시에 제가 항상 입버릇처럼 하던 얘기가 이 딥러닝계의 3대장은 OpenAI와 Google DeepMind와 Facebook이다. FAIR라고 불렀죠. 그런 얘기를 입버릇처럼 많이 했었는데 요 Transformer가 나올 무렵에 ConvS2S, convolutional sequence-to-sequence라고 하는 페이퍼가 Facebook에서 나왔었어요.
그래서 그때 당시에 RNN의 최대 단점은 모든 걸 다 sequentially 앞에 auto-regressive하게 할 수밖에 없는, 그러니까 지금 LLM으로 따지면 프롬프트를 parallel하게 처리해야지만 그것조차도 앞 단어를 처리해야 다음 단어로 할 수 있는 상황이었기 때문에 그런 단점들을 극복하기 위해서 parallelism을 키우는 알고리즘들이, 사람들이 갈증이 있었는데 Google에서 attention을, 우리는 RNN 없이 attention만으로 할 거야. 그리고 Facebook에서는 우리는 convolution만 가지고 할 거야. 이게 약간 경쟁처럼, 결과적으로는 Transformer가 살아남았지만.
사람들이 나중에 이걸 해석하기를 결국 CNN이라고 하는 convolution이라고 하는 거는 bias가 들어간 거죠. 사람들이 이미지에서 local한 것들을 모아서 그걸 layer를 쌓으면 그 receptive field라고 하는 게 커져서 globally 뭔가 정보를 취합하라는, 이게 결국 scale 측면에서 여기도 Bitter Lesson이 들어가는 거죠. 결국에 scale이 커졌을 때는 더 general한 모델인 Transformer가 성능이 훨씬 좋아진다.
노정석 Transformer 논문을 처음 읽으신 해는 언제입니까? 진원님은 나오시자마자 읽으셨을 것 같고.
이진원 네, 저는 나오자마자 바로.
최승준 저는 열어는 봤지만 이해는 못 했습니다.
노정석 저도 열어는 봤지만 이해는 못하고, 제가 Transformer 사실 이해한 건 2020년. 2017년에서 저는 2017년에서 2020년까지 AI 그렇게 열심히 또 안 보던 때였어요.
최승준 저는 2022년 초부터 Transformer를 제대로 들여다보려고 했어요.
이진원 이게 또 약간의 기억, 추억을 소환하자면 사실 2017년에 이 논문이 나왔을 때 꽤 화제가 됐지만 지금같이 됐을 거라고는 사실 아무도 생각 못했을 거예요. 근데 이게 사실 폭발적으로 성장을 하게 만든 첫 번째 계기는 제 느낌에는, 주관적인 느낌으로는 BERT가 나오면서부터였거든요. 2018년에 Google에서 역시 BERT가 나왔고 사실 GPT는 그거보다 좀 더 먼저 나왔지만 그때 GPT-1이죠. GPT-1은 성능이 그렇게 좋지 못했고, BERT라고 하는 게 이 encoder-decoder 구조의 최대 단점은 이게 번역 모델이잖아요. Transformer는 그러면 항상 정답 쌍이 있어야 되는 거죠. 영어를 프랑스어로 번역한다면 뭔가 번역이 이미 되어 있는 데이터가 필요했는데 BERT는 그거 없이 그냥 encoder만 가져와서 쓰는데 빈칸을 만들고 그 빈칸을 채우는 식으로 학습을 시켰단 말이죠. 그게 엄청난 self-supervised learning이라고 부르는 걸 하면서 엄청나게 많은 데이터를 레이블링 없이 쓸 수 있게 되면서부터 폭발적인 scale이 커졌던 것 같아요.
BERT의 등장과 GPT 디코더의 확장성: LLM으로 이어진 길 43:14
이진원 그래서 이때만 해도, BERT만 하더라도 사람들이 이거 너무 커가지고 이거 어떻게 학습해야 되나, 돈도 많이 들고, 클라우드에서 쓰려고 하면, 그런 얘기를 했던 기억이 있어요. 그리고 GPT는 완전히 반대로 decoder 방식이, 현재 지금 LLM이 다 GPT 형태로 되어 있는데 이것도 그때 당시에는 서로 경쟁을 많이 했었는데 지나고 나서 GPT가 승리를 결국에는 하게 됐는데 그거를 또 지나고 나서 생각을 해보면 BERT라는 건 인코더와 디코더의, GPT는 디코더고 그거의 가장 큰 차이는 인코더는 앞 단어에서도 뒷단어로 어텐션을 하게 되죠. 모든 입력이 다 주어졌다고 생각을 하고 중간에 있는 구멍을 채우는 거기 때문에 앞과 뒤를 다 보고 판단을 합니다. 성능이 좋을 수밖에 없겠죠. 뒷단어도 보고.
GPT는 항상 자기보다 앞에 있는 단어만 보고 그다음 단어를 예측해야 되니까 데이터 양이 적을 때는 성능이 낮을 수밖에 없는데 대신에 엄청난 장점이 있는데 그게 뭐냐면 단어가 하나씩 추가된다고 생각을 했을 때 인코더는 맨 앞에 있는 단어부터 연산을 다시 다 해야 됩니다. 근데 GPT 같은 디코더는 항상 자기보다 앞에 있는 단어만 하기 때문에 앞에 나왔던 단어들에 대한 토큰에 대한 연산을 다시 할 필요가 없고 그게 결국에 지금 key-value 형태가 되는 걸로 가져와서 자기 이번에 생성된 단어에 대한 연산만 새로 추가하면 모든 걸 다 할 수 있는, 확장성에 있어서 비교가 안 되는 그런 구조를 가지고 있었던 거죠. 그래서 결과적으로는 그런 과정을 통해서 지금 LLM까지 오게 된 것 같아요.
노정석 BERT 시대를 맞아서 또 그때 회사들 정말 많이 생겼었어요. 그때 진원님 방금 말씀하셨던 가장 큰 BERT도 1 billion이 안 됐던 것 같아요.
이진원 그랬죠.
노정석 네, 근데 그것도 어마어마하게 크다라는 얘기를 그 당시에 했었죠.
이진원 그리고 재밌었던 거는 그 BERT가 또 그 세서미 스트리트 캐릭터이다 보니까 그때 당시에 그 캐릭터의 이름으로 논문 짓는 게 한때 유행해가지고 ELMo도 나왔었고 우리나라에서는 뽀로로라는 제목의 논문이 나왔었던 걸로 기억을 하고 있어요.
노정석 네, 저는 그때 그 BERT류로 QnA라든지 아니면 그 어떤 빈칸 채우기라는 이런 모델을 가지고 실용적으로 서비스를 만들려던 회사들이 많았어요. 지금의 챗봇과 같은 거에 약간의 원시 버전. 질문하면 답하게 하거나 아니면 이게 맞는지 틀리는지 evaluation하게 하거나 혹은 품질에 대해서 이건 긍정적이다 부정적이다라고 하는 그런 classifier를 만들거나. 동작은 굉장히 잘 했어요. 근데 뭔가 완성도 측면에서 끝에 가서 항상 모자라는 게 있었고 그리고 당시의 비용으로는 그걸 만들기가 굉장히 비쌌었고 그러다 보니까 그 당시에 그 BERT를 가지고 어떤 서비스를 만들려고 했었던 회사들이 상당히 다 어려움을 겪었던 그 생각이 좀 납니다.
최승준 역사적 패턴일 가능성이 있네요.
노정석 그러면서 조금 다들 관심도 좀 사그라들고 야 이거 AI 신기하긴 한데 안 돼, 라는 그런 인상도 지배하던 때였죠. 그때 또 한 번 AI 윈터가 오네 뭐 어쩌네라고 얘기하고 그다음에 돈들, BERT 시작됐을 때 막 투자했던 회사들 회수가 잘 안 되고 막 이러던 때에
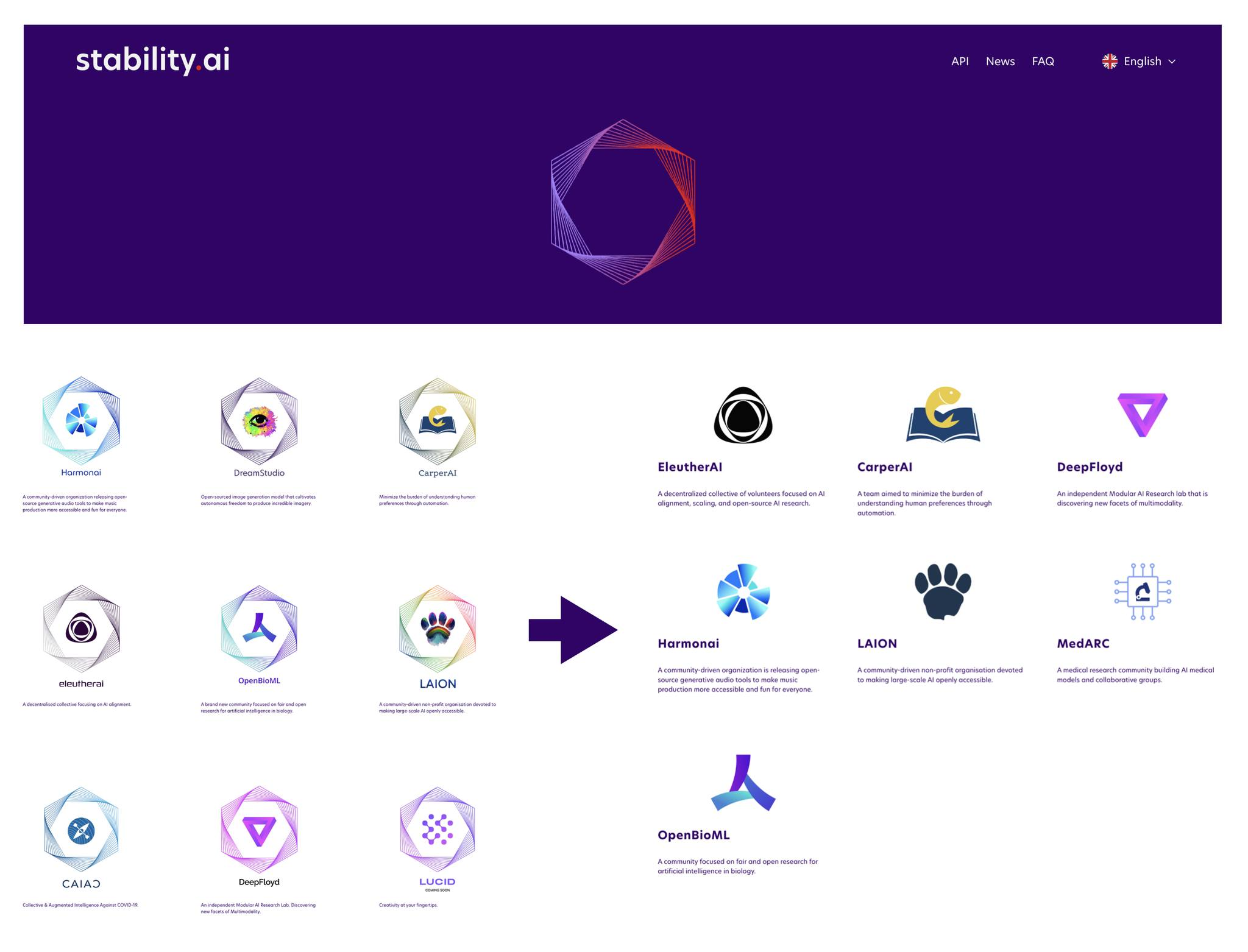
최승준 저 그즈음 그즈음 얘기를 좀 해보면 재밌을 것 같은데요. 22년에는 Stability AI가 핫했거든요. Stability AI가 Stable Diffusion으로 치고 나가가지고 Stability AI의 우산 아래 여러 가지 커뮤니티들, Eleuther나 LAION이나 그런 것들이 이렇게 포진하고 있었던 시기가 있었습니다.
Stability AI 커뮤니티와 한국의 파운데이션 모델: HyperCLOVA 47:30
최승준 근데 여기가 재미있었던 게 LAION이나 Eleuther가, 지금 최근에 한국의 케빈 고 님이라고 업스테이지에 최근에 합류하신 분이 오픈소스 활동을 하면서 이쪽 커뮤니티에도 기여하시면서 뭔가 흥미로운 프로젝트 Polyglot 이런 거 만드셨던 그런, 그리고 이렇게 어쩌다 보니까 HyperCLOVA가 어느 날 보니까 저는 한국에서도 이런 거 한다고 했는데 두 분께서는 좀 더 맥락을 아시지 않나요?
제가 여기에 2021년 HyperCLOVA 등을 발표했었던 네이버의 AI NOW 자료는 찾아놨거든요. 근데 2020년에 상황 판단한 거죠. GPT-3 나온 거 보고서는 큰 투자 한번 해야겠다가 그즈음에 상황 판단이 됐던 건가요?
노정석 그렇죠, 네이버가 먼저 좀 투자를 한 거죠. A100을 잔뜩 샀던 기억이 납니다. 네, 그러고 나서 HyperCLOVA를 내놨죠. 지금 사실 너무 오래돼가지고 관련한 metric이나 이런 것들은 다 까먹었는데 그때 GPT-3가 역시 쓸 만하지는 않지만 그 당시 기준으로는 어마어마하게 신기할 때였잖아요. 드디어 AI가 생각을 하고 말을 하고 few-shot으로 학습을 해가지고 인간처럼 대답하는 그런 것들이 보여졌으니까.
이진원 나는 한국 사람인데 독도가 어느 나라 땅이냐라고 하면 한국 땅이라고 하고, 일본 사람으로 캐릭터를 하면 또 일본 땅이라고 하고 이런 답을 하는 게 그때 당시에 이런 게 가능해? 이런 느낌이 되게 많았던 것 같아요.
최승준 근데 어쨌든 한국에는 HyperCLOVA가 있었고 저는 타임라인에 그즈음에 막 이렇게 LLM 공부하고 OpenAI Playground에서 한 작업 같은 거 막 올리고 하다 보니까 연락을 주셔가지고 사외에서 써보는 거에 초기 참여자로 좀 활동을 하기도 했었습니다. 이런 일들이 있었고
아까 Stability AI는 얘기를 했고 그래서 어쨌든 우리도 파운데이션 모델을 가져야겠다.
사실 이 행간에 카카오 쪽에서도 많은 일들이 있었잖아요. 그래서 카카오 쪽에서도 모델 만들고 튜닙이라는 회사가 나오기도 하고 분사해서 나오기도 하고 막 이렇게 LLM 가지고서는 모델 만드는 거를 한국도 안 하지 않고 많이들 하긴 했었잖아요. 한동안.
이진원 지금 독파모에 나와 있는 LG AI연구원에서도 열심히 했었고, 떨어지긴 했지만 KT에서도 열심히 했었던 기억이 있습니다.
영향력이 엄청나게 커지고 미래의 발전 가능성은 더 크게 느껴지고 하다 보니까 국가들이 다 뭔가 이게 전략 자산이 되는 거 아니냐, 나중에 군사 무기처럼 되는 거 아니냐라는 불안감 같은 것들도 있는 거죠. 그래서 우리가 자체적으로 부족함이 있더라도 자체적인 기술과 모델을 갖고 있는 게 중요하겠다라는 취지에서 시작을 했다고 생각이 들고요.
Vision Transformer와 데이터 스케일의 벽 50:40
이진원 지나간 거 하나 갑자기 생각나서 말씀드리면 Transformer 이 흐름에 있어서 아까 앞에서 우리가 계속 얘기했듯이 처음에는 컴퓨터 비전 쪽 ImageNet을 필두로 한 그쪽의 연구가 더 활발하고 사람들이 아무래도 보여지는 걸 보면 또 와닿는 게 많기 때문에 컴퓨터 비전 쪽에 좀 더 활발한 연구와 결과물들이 있었다고 하면 Transformer를 통해서 자연어 쪽으로 굉장히 많은 흐름이 옮겨갔는데 그때 당시에 그러면 컴퓨터 비전에도 Transformer를 써보자라고 하는 움직임, BERT 나오고 GPT-2, 3 나오면서부터 막 일어나다가 결국에는 Vision Transformer라고 하는 게 또 나왔는데 역시 이것조차도 구글이 처음으로 만들었죠. 거의 선구적인 기술들을 구글이 굉장히 많이 발표를 하는데 재밌는 거는 이 2017년, 아까 6월이었나요? Transformer 페이퍼가 나온 게. 근데 Vision Transformer 논문이 2020년 10월에 나옵니다. 이게 갭이 엄청나게 큰 거죠. 근데 이게 왜 이렇게 늦었냐, 사람들이 시도를 안 해본 건 아니고 정말 많은 시도들을 했었는데 결국엔 다 실패하고 제 기억에 이 Vision Transformer라고 하는 논문이 ICLR에 나왔었는데 거기 open review를 하거든요. 그래서 저자를 가려놓고 페이퍼 오픈이 되는데 그게 나왔을 때 이거 구글 거다라는 걸 모두가 다 알았어요.
왜냐하면 결국에는 비전 트랜스포머가 성공을 어떻게 시켰냐라고 하면 데이터를 많이 넣은 거였어요. 다른 답이 없고 방법은 굉장히 심플하게 이미지를 잘라서 패치로 만들어 가지고 트랜스포머에 벡터로 펴 가지고 넣어주는 건데, 대신에 이게 성능이 나오려면 기존에 CNN보다 좋은 성능이 나오려면 데이터를 많이 넣어야 되는데, 그때 당시에 얘는 supervised learning으로 학습을 했었고 그때 당시에 ImageNet 데이터가 한 1,400만 장 정도 되거든요. 전체 이미지가. 그런데 Google이 hundred million의 데이터, JFT라고 하는 Google이 오픈하지 않은 자기들만의 데이터가 있었는데 그 데이터를 그 정도 데이터를 넣으니까 성능이 올라가는 그래프를 보여줬어요. 그리고 거기에 JFT라는 데이터가 써 있는 걸 보고 사람들이 이거 Google 거네라고 알게 됐었죠. 그래서 그때 한 번 더 이게 스케일의 무서움이 이런 거구나라는 걸 한 번 더 느꼈던 것 같아요.
최승준 그래서 잠깐 여기서 이 국면에서도 생각나는 게 Stability AI에서도 돌파구를 줬던 Stable Diffusion이 결국에는 Stable Diffusion 자체의 기술이 아니라 원래 지금은 Runway 갔다가 다시 Black Forest인가, 하여튼 Black Forest 연구소로 분산. 그 핵심 두 명의 연구자, Patrick이라든가 이런 분들이 만들었던 그 latent diffusion에 관련된 걸 기반으로 한 기술. 그런 것들이 또 한국 분 중에 도엽 님, 아까 PR 또 같이 하셨었죠.
이진원 네, 같이 했습니다.
최승준 예, 그러다가 카카오에 있다가 Runway 가셨다가 지금은 다시 창업하시려고 하는 도엽 님 생각이 나, 저는 직접 뵌 일은 없지만 생각이 납니다.
노정석 또 그 당시는 또 한, 이 Stability AI, Stable Diffusion 나올 때가 ChatGPT 전이었잖아요. 뜨거웠죠. 이걸로 이미지 생성하고.
최승준 근데 지금은 SeeDance 2.0 이런 거 보면 다른 세월로 느껴져요.
노정석 네, 그때 그런 걸 가지고 왜 그랬을까.
최승준 왜 사업을 하려고 했을까?
노정석 맞아요. 예, 저도 어마어마하게 그거 가지고 파이프라인 많이 만들었었습니다. 네, 지금은 Nano Banana가 다 해주는 일인데.
최승준 저는 2022년에 이렇게 타임라인에 적었던 글들만 모아놓은 거예요. 적다가 너무 많아져서 포기했었는데, 결국에는 LLM 쓰기 시작하면서 시작한 거였거든요. 그걸 일 단위로 이것저것 써보고 했던 기억이 나고요.
팟캐스트 회고와 Man-Computer Symbiosis 재방문 54:18
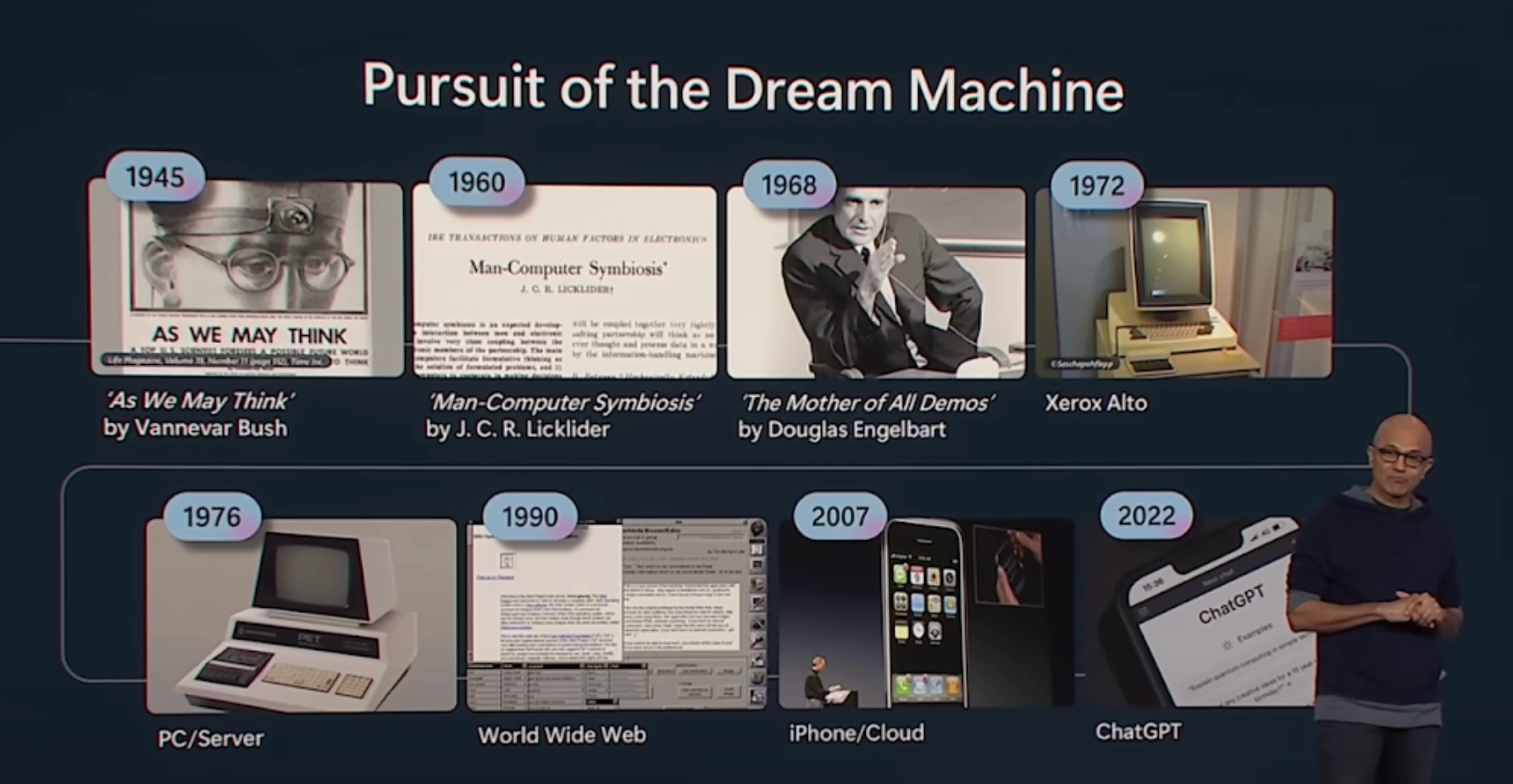
최승준 저희가 저희의 시작점, 저희 팟캐스트의 시작점 근처에 에피소드 3이 역사와 기술이었더라고요. 그래서 이때가 Satya Nadella가 Build 2023 때 이걸 짚었잖아요. 1945년에 As We May Think부터 해서 1960년에 Man-Computer Symbiosis 쭉 해 가지고 ChatGPT까지 어떻게 왔는가를 짚었던 걸 저희가 좀 그 의미를 읽어보는 시도를 했었는데,
저희 에피소드가 이게 나아갈 즈음이면 거의 90번 정도인 것 같더라고요. 어느새 3년이 훌쩍 지나서 이 뒤에 일어난 일들도 어마어마한 거잖아요.
노정석 네, 가속하고 있죠. 더더욱 가속하고 있죠.
최승준 그래서 제가 1960년에 그 J. C. R. Licklider가 했던 이야기, Man-Computer Symbiosis 이야기를 좀 다시 재방문해 봤는데, 인간-컴퓨터 공생이라는 게 어떤 걸 말하는 건가가 앞에 있고, 좀 넘어가면 이 시기가 어떤 시기냐라는 예언 같은 글이 있어요. 그래서 이 부분부터 읽어볼게요. 공군의 미래 연구개발 문제를 검토한 한 다학제 연구 집단은 인공지능의 발전으로 인해 기계 단독이 군사적으로 의미 있는 수준의 사고나 문제 해결을 수행할 수 있게 되는 시점을 1980년경으로 보았다. 그렇다면 인간-컴퓨터 공생을 개발하는 데 대략 5년, 그리고 그것을 활용하는 데 15년이 남는 셈이다. 그 15년이 10년일 수도 있고 500년일 수도 있지만, 그 시기는 인류 역사상 가장 창조적이고 흥미진진한 지적 시대가 될 것이다. 저는 이 예측은 정확하게 맞진 않았지만 그 방향성에서는 이게 정말 우리가 초지능이 나오기 전까지 겪는 시기들이 창조적이고 흥미진진한 시대인 것 같다라는 데는 공감을 하고 있거든요.
노정석 저희가 이 한 10년의 이야기를 훑다 보니까 적응이 안 돼요. 솔직히 저희 일주일 전에 나온 거 가지고 세상이 바뀌는 시대를 꽤 오래 살았잖아요.
한 2024년 GPT-4 이후로 약 2년, 2년 가까이는 정말 정신없이 달려오고 뒤로 올수록 더 압축되는 시절을 살고 있잖아요. 그러다 보니까 그 속도에 어떤 렌즈를 끼고 그 더 전을 바라보니까 너무너무 오래전 얘기인 것 같아요. 지금 살아남아 있는 것들도 하나도 없고, 물론 그것들이 씨앗이 되어서 여기까지 왔습니다마는 좀 압도되는 느낌이 있네요.
최승준 2022년 이후에는 이벤트의 그 점들이 너무 많이 찍혔어요. 굵직굵직한 것만 찍으려고 해도 너무 많더라고요. 좀 더 시간이 지나면 정리가 될 것 같습니다. 한 10년이 지나면 그때 뭐가 정말 핵심이, 지금 우리가 오늘 10년을 돌아보면서 지금 봤을 때는 자명해 보이는 굵직굵직한 것들이 뭔지가 정리되는 것처럼, 10년이 지나면 이 시기의 점들이 더.
이진원 지나고 나면 확실히 통찰이 깊어지는 것 같습니다.
가속하는 변화와 미래 전망: 검증의 난이도 57:15
노정석 어떻게 될까요? 그 사람들이랑 얘기하다 보면 3년 후에, 10년은 너무 길다. 3년 후에 뭐 하고 있을까라고 하니까 이런 얘기 많이 나와요. 그 Elon Musk가 주는 연금 받고 있을 것 같다고. 예, 일은 다 Optimus가 하고, 이 Tesla가 전부 이런 노동도 하고 지적인 일들은 전부 프론티어 랩들과 또 그런 데들이 하고, 그래서 우리는 연금 받으면서 다 놀아야 되는 거 아니냐.
지금 어떻게 보면 사람들도 모두 꿈꾸고 있는데, 이 시기에 나도 뭘 하나 해보겠다라고 전부 하나씩을 잡고 있는데 이것들이 과연 성공할까라는 거에 대한 회의들도 벌써 있는 것 같아요. 안 될 거야 해서 최대한 늦게 시작하면 늦게 시작할수록 이익이다라는 것도 어떻게 보면 누군가에게는 플레이북으로 잡혀 있거든요. 먼저 움직여 가지고 advantage가 생겨야 되는데 그게 아니라 먼저 가서 순교하는 거죠. 잘 만들어주면 나보다 더 많은 컴퓨팅 자원과 나보다 더 많은 market share를 갖고 있는 애가 딸깍 하고 다 가져가 버리는 그런 것도 있을 수 있으니까.
이진원 비슷한 생각을 많이 하는데, 지금의 선구자들은 어떤 방향성을 제시해 주고 이런 것도 할 수 있어, 이런 거 하면 좋아라는 걸, 가능성을 보여주면 뒤에서 큰 것들이 몰려오면서 그 시장을 다 먹어버리는, 그런 게 계속 반복되는 것 같아요.
노정석 근데 그럼에도 불구하고 그 중력장들을 다 탈출해서 서비스를 만들었던 사람들이 있잖아요. 예전에도 저희 웹 2.0, 웹 하던 시절에는 야 이거 네이버랑 다음이 만들면 끝나는 거 아니야라는 게 기본 질문이었는데, 그 뒤에 모바일 시대가 오면서 새로운 폼팩터에서 새로운 distribution 채널, 그 당시 새로운 distribution 채널은 결국 앱 스토어였죠. 한국의 강자가 아닌 더 큰 강자가 만들어주는 그런 기회들을 가지고 생태계들이 한번 쭉 바뀌었던 경험이 있고.
AI는 지금의 강자들이 또 모바일의 강자들이잖아요. 쿠팡, 토스, 카카오, 네이버, 배달의민족, 이런 중간자들이 또 다 자리를 잡았는데 또 한 번 플랫폼 시프트가 오고 있잖아요.
ChatGPT랑 Gemini가 모든 고객들의 정보 접근을 다 제어하는 세상이 올 것인가, 올 것이다. 과연 아니 그러지 않을 거야라고 하면 지금 의견이 분분한데 승준님이 적어주신 것처럼 타이밍의 문제이지, 와야 될 것들은 또 오니까, 어떻게 준비하고 있는지도 다 사람마다 관점이 다른 것 같고. 플레이북에 정답이 없습니다.
이진원 그게 제일 어려운 문제인 것 같아요. 저도 다행히도 아직은 제가 하고 있는 영역에 AI가 그렇게 깊이 들어오지 못하고 있는 부분이 있어요. 역시 또 생각해 보면 verifiable하긴 한데, verify하는 과정이 시간도 많이 걸리고 어려워서. 예를 들면 반도체를 만든다고 했을 때 이게 좋은 반도체이냐를 평가하는 metric도 여러 개 있을 수 있지만, 그 metric 평가하는 과정 자체가 길게 일어나기 때문에 아직은 데이터도 좀 부족하고 그런 부분이 있지만, 저는 항상 저희 회사 직원들이랑 얘기를 나눌 기회가 있을 때 3년 후에는 나는 이 일을 안 할 거다라는 얘기를 입버릇처럼 하거든요. 그러면 뭘 해야 되나 하는 생각을, 뭘 해야 되고 어떤 것들을 좀 하면 좋을까라는 생각을 많이 하는데 아직도 답을 못 찾았어요.
또 생각을 하다가 또 해야 할 일, 당장 해야 될 일들이 몰려와서 또 그 일을 하다가 틈 나면 또 그 생각을 하고, 이걸 계속 반복하고 있습니다.
노정석 그런 게 그냥 모두의 삶인 것 같아요. 낮엔 소를 키우고 저녁 땐 공부를 하고 그렇게 하는데,
AlphaGo 37수의 의미와 다음 에피소드 예고 1:01:00
노정석 아까 방금 전에 저희 도망자 연합 문제 풀이반 그분들이랑 얘기하시다가 진원님이랑 승준님 뒤에 들어오셨습니다만, 어떤 분이 그 얘기하셨어요? “저는 망해도 두렵지 않아요, Claude Code가 있으니까요.” Claude Code가 있으면 언제든지 재기할 수 있다라는 얘기를 하셔 가지고 다 웃었던 기억이 납니다.
어쨌건 시대를 규정하는 가치 생산이, 가치 생산이라는 거에 어떤 관점이 바뀌어 나가는 것 같아요. 소프트웨어가 끝나는 게 아니라 소프트웨어의 시대가 진짜 활짝 열리는 건데, 소프트웨어를 만들던 사람의 시대가 끝난 거죠.
최승준 기술은 걱정할 게 별로 없을 것 같아요. 사람이 걱정이니까.
노정석 그렇죠. 그럼 적응해 나가야 되지 않을까요?
최승준 그러게요. 하여튼 이렇게 오픈 타임라인에 봤었던 Google DeepMind나 Demis Hassabis의 이런 글들, 그리고 이들은 어떻게 앞을 보고 있는가, 그런 거에서 시작해서 10년을 좀 돌아봤는데요. 결국에는 AI가, 이 Platform 37이라는 의미는 그게 바둑에 국한한 게 아니라 그런 일들이 곳곳에 일어나는, 37수 같은 게 곳곳에 일어나는 걸 지향하는 게 아닌가라는 생각을 좀 해봤습니다. 직접 그렇게 얘기한 건 아니지만 행간을 읽었어요.
37수 같은 게 이 도메인에서 저 도메인에서 일어나는 걸 Google DeepMind는 지향하고 있고, 그중에 하나를 보고 있는 거가 생물학이라든가, 저희가 겉만 보고 있지 아직 다루지 못했던 현재 일어나고 있는, 이미 일어나고 있는 방향성들, 그런 것들에 대해서도 차차 얘기해 봐야 되는데.
그래도 저희가 오늘 좀 작정하고 10년을 돌아보려고 했던 건, 그런 이야기들은 끊임없이 나올 거라서 어떤 시기에는 돌아보는 게 중요한 것 같아서 10년을 한번 돌아보는 시기로 오늘 좀 잡아봤습니다. 재밌었어요. 진원님이 또 이렇게 저는 모르고 있었던 이야기를 해 주시니까 너무 좋은데요.
노정석 그렇죠. 또 진원님이, 저희 오늘은 갑자기 게스트로 모셨습니다만, 곧 저희 한번 모시고 칩 관점에서 우리가 도대체 어떻게 이 앞날을 봐야 되는지, 기가와트와 칩과 이런 이야기 한번 저희 듣기로 돼 있지 않습니까?
이진원 네, 저도 오늘 굉장히 재미있게 얘기했던 것 같고, 이 과정 속에서 AI 인프라라고 하죠. 반도체를 포함한 그런 것들도 굉장히 많은 변화와 부침과 challenge들을 겪어왔고 지금도 겪고 있거든요. 다음에 적당한 시점에 한번 나와서 그런 얘기들을 나눠보면 좋을 것 같습니다.
노정석 맞아요. 안 그래도 오늘 아침에 보니까 Dwarkesh Patel과 또 얘기를 하면서 이 칩과 100기가와트 시대는 어떤 모습인가, 이런 얘기를 한번 했더라고요. 그런 이야기 중심으로 또 전문가인 진원님 모시고 그런 얘기들을 한번 해보면 좋을 것 같습니다.
최승준 예, 기대가 되네요. 오늘 재미있었습니다.
노정석 오늘은 이 정도까지 하고, 승준님과 저희도 아마 다음 어떤 테마로 넘어가 보려고. 원 딸깍 어웨이인 것들의, 저희도 호들갑 모드로 계속 가는 거는 아 이건 너무 피곤하다. 저희도 AI science나 이런 쪽으로 한번 좀 더 weight를 좀 옮겨 보려는 그런 와중에 있다는 말씀 좀 드리고 싶습니다.
OpenClaw 행사와 마무리 인사 1:04:02
이진원 기대하고 있습니다. 원딸깍에는 저도 많이 느끼는 게, 원딸깍으로 할 수 있는 게 너무 많아져서 그걸 다 다루는 것도 힘들고 다 쫓아다니기도 힘들고, 어떻게 보면 약간은 식상해지는 그런 느낌이 있는 것 같아요.
노정석 이 변화의 속도에 다 조금씩 적응을 해 나가는 것 같아요. 이게 새로운 어떤 속도로 받아들이고 있는 거잖아요.
최승준 근데 늘 hedging은 중요하지 않나요? 오늘 또 사이오닉에서 OpenClaw 행사하는 거, 또 진원님 가신다고 하지 않았나요?
이진원 네, 이거 마치고 바로 출발할 예정입니다.
최승준 어떤 일들이 벌어지고 있는지는 알아야죠.
노정석 근데 OpenClaw가 저는 굉장히 중요하다는 생각이 들어요. 모두에게, 저희가 지난 에피소드에서 그런 얘기했잖아요. 모두가 회장님의 삶을 살게 된다. 뭘 하든지 최강의 극강의 비서진들을 거느리고 아무리 작은 일이라도 하게 되는 세상이 되는 거가 맞는 방향성이면, 그 극강의 비서진을 잘 만들어 주어서 소비자에게 최종 어시스턴트로, 가장 끝단, 내 눈앞에 바로 어시스턴트로 선택되는 애가 모든 주도권을 쥐게 되는 거라서, OpenClaw가 거기에서 큰 어떤 의미가 있다라고 다들 판단한 것 같아요.
최승준 그렇군요. 주말을 또 재미나게 보내시겠네요.
노정석 예, 가서 또 열심히 들어보겠습니다.
최승준 네, 그러면 오늘은 여기까지 하겠습니다.
노정석 오늘은 이 정도로 마무리하도록 하겠습니다. 진원님, 오늘 감사드립니다.
이진원 네, 불러주셔서 감사하고 너무 재밌었습니다.