EP 96
LLM 추론 인프라와 토큰 경제학
연휴 동안 공부한 Dwarkesh 새 에피소드 00:00
노정석 녹화를 하고 있는 오늘은 2026년 5월 4일, 월요일 아침입니다. 저희가 이번 연휴 동안 Dwarkesh의 새 에피소드를 공부했는데요. Dwarkesh가 포맷을 바꿨어요. 갑자기 칠판을 가지고 와서 판서를 하면서 가르쳐 주는 그런 형태의 포맷을 새로 했는데요. 그 내용이 굉장히 좋았습니다. 지금 시점에서 저희가
최승준 4월 30일이었죠.
노정석 맞아요. 저희가 한 3일 동안 이걸 공부했는데, 지금까지는 항상 training이 어떻다, 그다음에 모델 크기가 어떻다, 이런 얘기만 했었는데 사실은 저희 Claude Code도 그렇고 Codex도 그렇고 inference의 중요성이 훨씬 더 커지고 있지 않습니까?
그렇죠. 그래서 코드를 돌리면 context도 정말 길게 넣어야 되고, 그리고 그 긴 context도 끊임없이 바뀌고 그러는 workload도 많아지고, 또 그 사이에 reasoning token도 굉장히 많이 걸리잖아요.
저만 하더라도 GPT-5.5에 x-high를 걸고 거기에 코드 넣고 이러면서 작업들을 진행하는데 그 workload가 상당하거든요.
그래서 그것들을 가능하게 하는 현대의 추론 인프라스트럭처. 저희가 한참 모델 얘기하면서 training 얘기를 많이 했는데, 이제는 training보다 추론이 훨씬 중요해진 시기가 왔기 때문에 그 추론이 어떻게 일어나는지에 대해서 한번 깊게 배워볼 필요가 있는데, 이번 Dwarkesh 에피소드가 정확하게 그 내용을 이야기하고 있습니다.
오늘 그 내용들이 상당히 어렵긴 하지만 재밌을 거기 때문에 그 내용들을 한번 풀어 나가는 그런 에피소드로 해보도록 하겠습니다.
최승준 바로 들어가 보시죠.
DeepSeek 그래프로 보는 컨텍스트 비용 절감 01:38
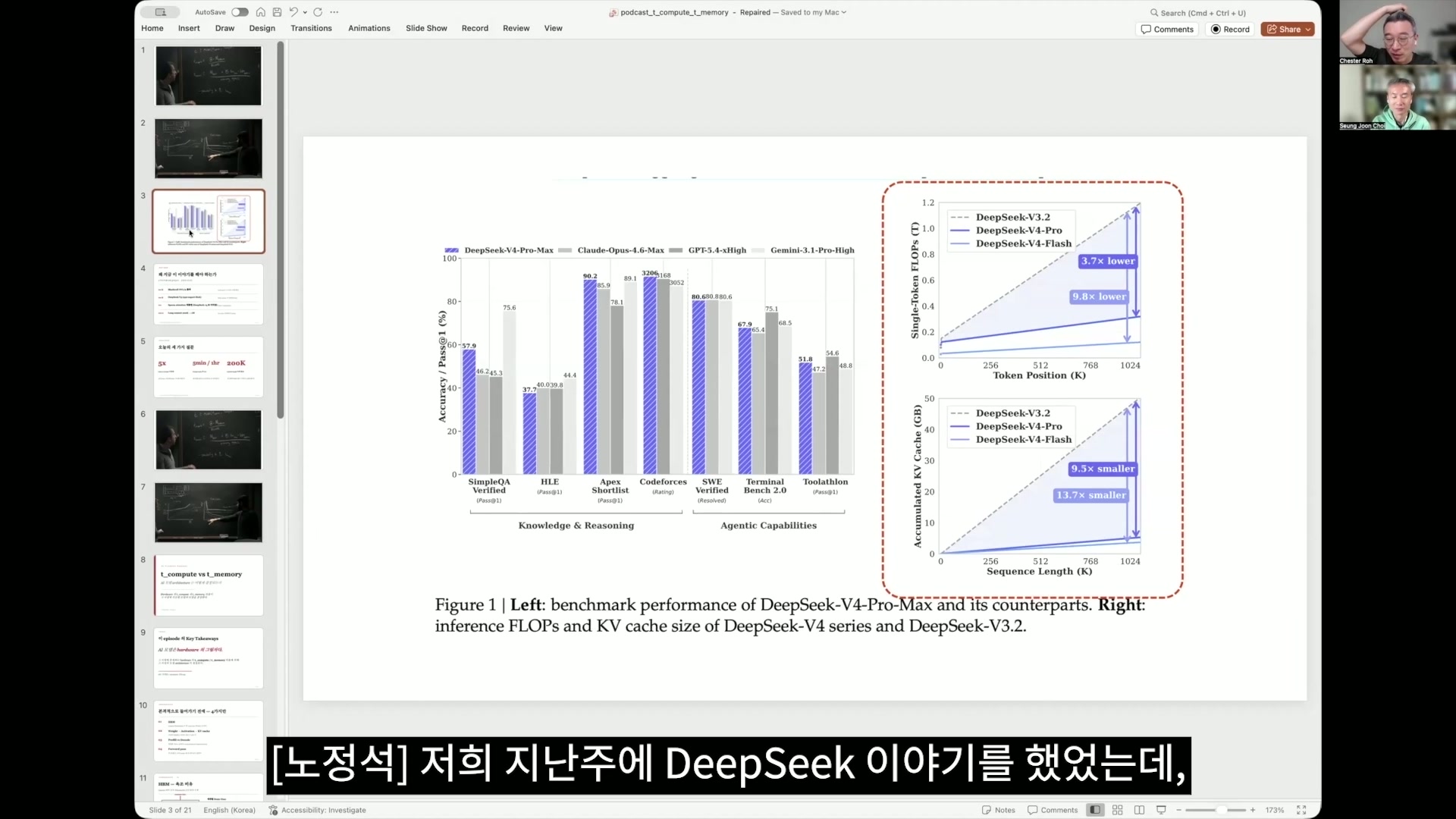
노정석 저희 지난주에 DeepSeek 이야기를 했었는데, 사실 DeepSeek이 페이퍼 가장 1장에서 내놨던 내용이 사실 이거지 않습니까? 이 오른쪽에 있는 그래프가 사실 이 논문의 앙꼬라고 말씀드렸는데, 위에 있는 게 computation에 대한 내용이고 아래에 있는 게 메모리에 대한 내용인데요.
이거 그냥 요약하면 토큰 포지션이 k니까 0에서부터 100만까지를 나타내는 건데, 요새 100만 토큰의 context length를 프론티어 랩들이 다 제공을 하고 있는데 사실 100만은 굉장히 비싼 서빙이거든요. 그래서 대부분 현실적으로 20만 이 정도에서 티어가 나눠져 있는 걸로 알고 있는데, 그 티어가 왜 나눠져 있는지도 저도 이번에 알게 됐거든요.
그런데 이 DeepSeek이 computation과 메모리 사용에 있어서도 context가 커지더라도 매우 효율화했다. computation은 3분의 1, 메모리는 10분의 1로 줄였는데, 이게 도대체 이 agent 세상, agentic 어떤 era라고 그러죠? agent 세상이 되어 가고 있는 이 현시대에 어느 만큼의 큰 의미가 있는지 오늘 에피소드를 한번 따라오고 나면 이해를 할 수가 있습니다.
NVIDIA GPU와 HBM 중심의 서빙 인프라 개요 02:53
모델 이야기를 하면서 사실 NVIDIA 얘기를 하면 대부분 사람들이 못 알아들어요. 그렇죠. 그런데 GPU라는 게 있고 GPU가 있어야 모델이 돌아간다고 얘기를 하지만, 젠슨 황이 항상 이 행사에 나와서 하드웨어 다 보여주는데
최승준 막 들고 다니면서 보여주고.
노정석 네. GPU 칩이 있고 그다음에 칩이 있으면 옆에 항상 이야기하는 게 연산 유닛이 얼마나 늘어났고, 속도가 얼마나 빨라졌는지 얘기를 하고, 그 바로 옆에 붙어 있는 게 대한민국이 요새 한참 수혜를 보고 있는 HBM이 옆에 붙어 있고, 걔들이 묶여서 또 CPU랑 묶이고 하나의 랙이 되고, 그다음에 GPU 간 통신, 그다음에 랙 간 통신, 이런 것들에 대한 인프라스트럭처를 하나씩 하나씩 다 설명해 주는데, 저희가 그 내용들을 정확하게 이해하고 있진 않잖아요.
오늘 그 내용들에 대해 그것들에 대해서 한번 이야기를 해보겠습니다.
Blackwell NVL72와 랙 단위 메모리 확장 03:52
사실은 저희가 오늘 이야기할 내용의 결론을 먼저 좀 깔고 가면, 이 Blackwell NVL72 GPU 간 통신이 예전에는 기존에는 8개까지만 됐는데 지금은 72개가 됐고, 그리고 개별 GPU의 용량도 사실 일론 머스크가 Colossus에 깔았던 H100이나 H200만 하더라도 GPU당 메모리가 80GB, 100GB 정도에 불과했잖아요.
그런데 지금 나오고 있는, 작년부터 올해 막 출하되고 있는 GB200이나 GB300은 메모리가 192GB에 막 288GB짜리도 있고 이러거든요.
그런데 그런 것들이 72개가 한 랙에서 하나로 다 연결돼 있고
최승준 그러면 얼마예요? 20TB 정도 되나요?
노정석 20TB 정도 되죠. 사실 그런 것들이 함의하는 바가 다 있고, 지금 최신 모델들은 이 하드웨어의 구조를 정말 잘 이용하고 있고 거기에 의해서 모델의 아키텍처도 형성되고 있다고 봐도 무방할 정도로 그게 관련이 있는데,
최승준 요즘 만나는 모델이 왜 확 4.5, 4.6쯤부터 달라졌는가가 설명이 되는 거죠.
노정석 맞아요.
최승준 출시 시기 보면은. 그리고 저희가 GPT-3.5가 2022년 10월에 나왔는데, 그다음에 GPT-4.5가 1년 반에서 2년 가까이 후에 나왔는데, 그 사이에 GPT-4.0이 한참 동안 플레이를 했었고 그게 2023년 3월이었죠.
노정석 그렇죠. 한 1.8T 정도 되는 모델이라고 생각을 했었잖아요. 그리고 Claude Opus 4.5나 4.6 이런 것도 저희 Swyx가 얘기하길, 그냥 도는 소문에, 누구도 confirm을 안 해 주지만, maximum 1T에서 2T 모델일 거다라는 이야기를 했었거든요. 그런데 지금 갑자기 나오고 있는 모델들은 막 5T 모델에 10T 모델, 이런 모델 사이즈가 갑자기 확 커졌단 말이에요.
최승준 그렇죠. Mythos가 10T고, 그다음에 5T 정도가 지금 서빙되어 있을 거다라는 추측들이 많죠.
노정석 그런 것들이 왜 지금 갑자기 일어나고 있나. 이게 갑자기 반복되고 있는 데는 이유가 있다. 그래서 Dwarkesh와 Reiner Pope이라는 Google 하드웨어 출신의 창업자분이 나와서
Reiner Pope 강연과 오늘의 로드맵 06:09
최승준 TPU 하던 분이더라고요.
노정석 이 칠판에 판서를 하면서 설명을 해 주시죠. 그래서 오늘 그 칠판의 판서 내용을 몇 개 따라가며, 그리고 최종적으로는 현대의 LLM 서빙 아키텍처가 도대체 어떻게 돌아가는지, 그들은 어떤 게임을 하고 있는지 등등에 대해서 장황한 이야기를 한번 저희도 따라가 보려고 합니다.
오늘 에피소드의 내용은 그래서 상당히 어렵게 느껴질 수도 있을 거예요. 그런데 여러분들 Claude Code나 이런 걸 이용해서 그냥 단지 이용만 하고 싶다고 하시는 분들은 이 에피소드의 내용이 크게 재미는 없을 수 있어요.
그러나 NVIDIA GPU 출하 시기와 그다음에 모델의 출하되는 아키텍처들과, 이것들이 미래를 어떻게 보여주는 선행 지표들이거든요.
최승준 맞아요. NVIDIA만의 얘기가 아니라 비등한 것을 경쟁자들도 할 수밖에 없기 때문에 지금 시대 상황을 아마 읽는 지표가 될 것 같다는 느낌이 있습니다.
노정석 오늘 그 이야기를 한번 해보도록 하겠습니다.
토큰 가격표와 캐시 가격의 의미 07:22
그래서 왜 저희가 Claude Code 쓰고 여러분들 캐시 최적화에 이런 얘기를 하다 보면 이런 얘기들을 그냥 아무렇지 않게 사용하거든요.
input token과 output token은 가격 차이가 있고, 심지어 이 가격 차이도 어떤 데는 얼마 안 나고 어떤 데는 많이 나요.
DeepSeek이나 Gemini나 Anthropic이나 다 pricing scheme이 다르거든요.
그것도 다르고, 그다음에 캐시도 5분 캐시, 1시간 캐시 해서 그것들의 가격도 전부 다 다르고, 그다음에 심지어 Gemini 같은 걸 보다 보면 context length가 200K, 그러니까 20만까지는 좀 괜찮다가 20만 넘으면 다른 가격 티어로 받는 이런 가격표들도 있거든요.
왜 도대체 이런 것들이 있는지, 최신의 LLM 서빙 아키텍처와 하드웨어와 이것들 사이에는 어떤 관계가 있는지를 한번 오늘 알아보려고 하는데, 그걸 풀어보는 것들이 이 아저씨가 하는 이 판서에 나오는데 이 판서의 내용은 조금 있다가 저희가 기초를 한번 다뤄보고 나서 다시 들어와서 이 t_compute와 t_memory, 그리고 이것들이 왜 이렇게 구성되는지는 좀 알아보도록 하겠습니다.
그래서 이 식을 가지고 이 그래프를 도출하거든요.
결국은 batch size당 걸리는 시간, 그다음에 batch size당 생기는 가격표들 해서 이 가격표들을 보면서 사실은 앞에 방금 얘기했었던 이런 것들을 모두 답할 수가 있거든요.
그래서 핵심 키워드는 t_compute와 t_memory에 제한이 된다.
최승준 여기서 T가 뭐죠?
노정석 시간이죠? 시간 계산에 걸리는 시간과 이 메모리를 recall하는 데 걸리는 시간, 이 두 개의 조합으로 현대의 LLM inference의 모든 가격이 결정이 된다. 이런 이야기를 좀 오늘 해보려고 합니다.
추론 기초 용어 정리 KV cache prefill decode 09:19
그래서 AI 모델은 이 하드웨어의 그림자다. 이렇게 발전하고 모델이 그렇게 발전하기 때문에 하드웨어가 그런 방향으로 틀기도 하고, 하드웨어가 그렇게 되어 있기 때문에 모델이 그걸 fully utilize하기 위해서 바뀌기도 하죠.
오늘 내용이 좀 어렵지 않습니까? 승준님, 저희가 사실 에피소드를 하면서 transformer를 어떻게 하면 쉽게 설명할 수 있을까를 굉장히 여러 번 try를 했었어요. 그런데 이게 참 잘 안 돼요.
항상 도대체 HBM, 그다음에 transformer의 기본 구조, 그 안에서 이 attention과 fully connected layer, dense block은 무엇을 의미하는지, KV cache 이야기, 여기저기서 많이 하는데 도대체 그 녀석이 뭔지, 그다음에 prefill과 decode가 뭔지, 그리고 forward pass가 뭔지.
그런데 다행인 건 추론은 어쨌든 training보다는 쉽다.
최승준 저희가 training을 하지는 않을 거니까요.
노정석 그 한 가지의 위안을 좀 얻으시고 오늘 추론과 관련해서 forward pass까지만. backward pass가 사실 training에 대한 건데, 그건 이제 저도 보고 싶지도 않아요. 어떻게 모든 현대 아키텍처에서 이 MoE와 sparse attention들을 깔아놓은 것들을 가지고 training할지는 저도 이제는 감히 열어볼 엄두가 나지 않아서 한 이 정도에서 한번 설명을 해보죠. 자, 그럼 승준님, 저희 transformer 이야기 한 번만 다시 해볼까요?
트랜스포머 동작 흐름과 KV cache 재활용 10:49
최승준 큰 구조에서 좀 얘기를 해봐야 될 것 같은데요.
이제 여기를 자세히 들어가긴 할 건데, 그리고 전체 상을 잡을 때 왜 이런 얘기를 하나일 때는 IT 분야의 영역만 아니라 다른 데도 그럴 텐데, 자원이 있으면 그거를 최대한 뽑아내려는 경향이 있잖아요. 놀면 안 되잖아요.
그래서 그런 거가 이후에도 좀 얘기가 나올 건데, 일단 저는 transformer 관련된 것을 좀 얘기해보겠습니다.
그래서 전체적으로 뭔가 prompt를 우리가 쓰면 그게 prefill이라는 게 돼서 한 번에 쭉 다 병렬로 계산이 되고, 그 병렬로 계산이 될 때 KV cache들이 만들어지거든요. 좀 이따 설명드리겠습니다.
KV cache들이 여기서 만들어지면 그거가 된 다음에 맨 마지막에 그 토큰에서 이어진 그 벡터에서 다음 토큰을 추론하고, 그게 다시 입력으로 가서 여기 화살표가 이렇게 돼 있죠. decode를 해 가요.
그래서 prefill 된 것과 그다음에는 한 토큰씩 decode 되는 단계를 구분해서 생각하는 게 중요할 수 있거든요.
노정석 그러니까 이거를 진짜 쉽게 설명해야 될 것 같은데, 사실 prefill과 decode의 개념이 이해가 되시면 졸업해도 되는데 솔직히
최승준 그런가요?
노정석 아니, 농담 삼아 얘기한 겁니다. 이걸 처음 들으시는 초보자 관점에서 이 개념이 와 닿으시면 사실은 우수한 거다라는 말씀을 드리고 싶어서 말씀을 드리는 건데, 그냥 이해를 돕기 위해서 한 번만 설명을 제가 곁들여 보면, 코멘트해 주세요, 승준님이. 저희가 Claude Code에서 “야, 이 코드 봐줘.”라고 하면서 코드를 갑자기 천 줄짜리를 빵 집어넣으면
최승준 그렇죠. prefill 해야 돼요.
노정석 그렇죠. 그게 트랜스포머에 들어가서 이 모델이 그다음 토큰을 뱉어내기 위해서 선준비를 해야 되잖아요. 그렇죠. 그 선준비를 하는 과정이 저희가 prefill이라고 보시면 돼요. 그리고 그 prefill이 대부분 긴 input token에 관한 내용이라고 생각하시면 얼추 맞습니다.
최승준 그리고 유저가 입력하는 것도 prefill 되는 거죠. 유저 프롬프트니까 마찬가지예요. 입력이 그거죠.
노정석 맞아요. 길게 들어가니까 input token은 무조건 prefill이 되죠. 그래서 들어가는데 그 prefill 되는 토큰들도 token by token이 있는데, 그 토큰 하나하나마다 QKV가 한 번씩 다 계산을 하는데, 그런데 QKV에서 Q는 한 번 사용하고 버려지는 거고, KV는 뒤로 갈수록 뒤에 있는 query 토큰들이 앞에 있는 KV들을 전부 다 봐야 되잖아요. 그래서 하나씩 다 저장하는 거라고 생각하시면 맞을 것 같아요.
그래서 좀 이따 좀 더 자세히 들여다보겠지만 방금 말씀해 주신 거에서는 트랜스포머가 블록이 여러 개 있거든요. DeepSeek V4가 61개 있었나 그랬을 거예요. 맞아요.
최승준 지난주에 살펴봤었던 게, 그래서 거기마다 한 토큰마다 KV가 다 붙는 거거든요. 그래서 입력이 만약에 100글자였다. 100글자마다 한 레이어에서 다 KV가 붙고, 그다음 레이어에서 또 KV가 붙고, 61번 그 KV가 100글자마다 다 붙는다고 대강 생각하시면 되거든요.
노정석 맞습니다.
최승준 어마어마하게 많아지죠.
노정석 저희가 조금 이따 트랜스포머 블록을 보면서도 얘기를 하겠지만, 이게 사실 토큰이 입력되면 똑같이 생긴, 이게 트랜스포머의 매력인데 똑같이 생긴 트랜스포머 블록을 그냥 61번 반복해서 토큰이 지나가는 거잖아요. 그 말씀을 방금 승준님이 하신 거고, 그리고 output token은 맨 위에 있는 블록에서 꺼내서 걔를 다시 토큰으로 바꾸는 거죠.
최승준 그렇죠. 맨 마지막에 생성된 거에서 이제 돌려줘야 되는데, 그게 autoregressive라는 방식이거든요. 자세한 부분은 시간이 좀 걸릴 수도 있겠습니다만, 이 트랜스포머 익스플레이너 사이트가 굉장히 잘돼 있어요. 이게 3차원으로 보는 버전보다도 이해하기가 쉽게 설명이 되어 있고, GPT-2가 실제로 돌아가게 되는데, 제가 딸깍 한국어 버전으로 설명을 만들어 봤습니다.
노정석 아이고, Codex가 해줬군요.
최승준 그래서 트랜스포머가 이런 얘기고, GPT-2 Small 활용해 가지고 지금 예시를 좀 보여주려고 하고 있고요. 그래서 지금 보면 Q, K, V가 하나의 토큰에 대해서도 multi-head로 붙어서 이렇게 다양하게 생성이 돼요. 그런데 이건 너무 자세하니까 일단 이 정도로 하고 넘어가겠습니다. 그래서 “Data Visualization Empowers Users to” 그런데 Empowers가 두 개의 토큰으로 분리가 될 수 있습니다. 토큰이랑 단어랑 좀 다르거든요. 대강 퉁쳐서 단어라고 생각하지만
토큰화 token ID vocab size 개념 15:29
노정석 네.
최승준 자, 이걸 한번 따라가 보겠습니다. 그래서 이 다음에 올 가능성이 가장 높은 토큰은 무엇인가 한번 지시문대로 생성을 눌러볼게요. 그러면 저게 이렇게 계산이 돼 가지고, 그래서 create 다음에 올 단어가 comma라고 지금 찍혔어요. 21.17%로.
그래서 이 과정을 해서 comma가 다시 입력으로 가서 그다음 생성이 되는 거거든요. 그래서 만약에 또 생성한다고 하면 manage가 나왔죠. 여러 가지 후보들이 있는데, 그래서 이게 계속 prefill 다음에 반복이 되는 겁니다. 그래서 지금 prefill이 이거 한 번에 이렇게 쭉 다 QKV가 계산이 되는 그런 과정이었던 거고요.
조금 더 자세히 들여다보면, 여기에 보면 embedding이라고 해서 얘가 token ID는 고정인데 그거를 벡터로 바꿔주는 작업을 하게 돼요. 그래서 저런 식으로
노정석 token ID라는 게 뭐죠?
최승준 token ID가 이거는 보통 GPT-3 시절에는 한 5만 개의 vocabulary 사전이 있어 가지고, 실제로 이 tokenization 되는 Empowers가 두 개의 토큰으로 되는데 em이 795번이라는 ID, 이건 고정이에요. powers가 30132번, 이렇게 고정인 겁니다. 이거는 ID는 고정이라서 항상 처음에는 똑같은 게 할당이 되는데, 벡터화되고 나서는 내부의 residual을 따라서 흐르면 맥락이 섞여서 달라지죠.
노정석 그러면 저 토큰이 단어마다 그냥 붙어 있는 일종의 일련번호라고 생각하면 되겠고, 그다음에 저희가 흔히 vocab size라고 얘기하는 게 이 모델이 가지고 있는 이 단어장에 단어가 몇 개냐, 그런 거죠.
최승준 그렇죠.
그런데 중요한 거는 이후에도 토큰하고 hidden space를 섞어서 말할 건데, state를, 실제로는 벡터화되기 때문에 이 벡터를 저희가 hidden state, 또 embedding, 여러 가지 말로 섞어서 부르거든요. 그런데 그거는 맥락에 따라서 다시 말씀드리겠습니다.
어쨌든 이 토큰들마다 벡터가 생기는 게 중요합니다.
그리고 positional은 좀 어려우니까 후딱 넘어가서, 어쨌든 위치에 관련된 정보를 주입을 하고, 그거를 트랜스포머 블록이 똑같은 게 아까 정석님 말씀해 주신 대로 GPT-2의 경우에는 이렇게 계속 있어요. 그래서 똑같은 게 지금 몇 개 남았다, 그거를 보여주고 있죠.
그래서 계속 이거를 통과하면서 어떤 쪽으로 가야 되는가, 최종 출력해야 되는 게 어떤 쪽으로 가야 되는가를 도출하기 위한 계산들이 진행이 됩니다. 그리고 그 모든 층에 QKV가 만들어지고, KV는 남겨 놔요. 나중에 다시 계산하기 위해서.
Attention causal mask와 KV 압축 기법 18:29
그래서 쿼리는 이 프롬프트들로부터, 토큰으로부터 만들어진 질의 같은 느낌이라면 키하고 밸류는 실제로 지식에서 이거를 soft search라는 개념으로 설명할 때가 많이 있거든요. 정확하게 key-value를 찾는 게 아니라 soft하게 정보를 찾는 느낌적인 느낌인 거죠.
노정석 그러니까 여러분들이 이거 보시면서 QKV의 어떠한 의미에 대해서 이해하시려고 하면 어려워져요. 이거는 트랜스포머의 저자가 “이거 토큰들이 들어오는 것들을 그 안에서 서로의 연관성을 계산하게 하려면 어떻게 해야지?”라고 하면서 그냥 자신들이 구조적으로 만든 일종의 bias입니다.
그래서 그 토큰이 들어오면 그거는 query, key, value로 쪼개서 다 계산을 하고, QKV는 이런 식으로 계산을 시키자라는 식으로 해서, 물론 철학적인 의미는 당연히 있습니다.
그런데 그렇게 만들어 놓은 일종의 inductive bias, 저희가 그냥 어떤 저자의 설계라고 생각하시면 맞아요.
얘가 왜 이렇게 되면 query가 되고 key가 되고 value가 돼요라는 질문은 하시지 말고 넘어갑시다.
최승준 하지만 이 애니메이션은 재미있으니까 한번 보겠습니다. attention 자세히 들어가서 보면 저런 식으로 모든 서로의 토큰에 대해서 뭔가를 계산을 해요. 그래서 그 맥락 정보가 생기거든요. 그런데 여기 삼각형 모양으로 생기는 거는 미래의 거를 프롬프트에 입력할 때, 그건 넘어갈게요. causal mask 설명하려면 좀 어려워서
노정석 네, 그냥 넘어가고요. 당연히 앞에 것만 봐야죠. 왜냐하면 미래의 토큰은 아직 도착하지 않은 상태이기 때문에 저 삼각형으로 돼 있는 거는 그냥 causal mask라고 저런 게 있습니다. 저자가 잘 만든 거예요. 그런데
최승준 그래서 그런 게 multi-head로 있고, 이게 옛날 트랜스포머와 요즘 트랜스포머의 차이는 예전에는 이런 KV를 다 남긴다면 요새는 그거를 압축하는 게 또 중요한데, 그거는 나중에, 나중에.
노정석 네. 그거는 안에 엄청난 테크닉들이 많이 있는데, 그리고 최근에
최승준 MLA나 sparse attention, 이런 것들 다.
노정석 맞아요. 그거의 끝판왕이 지난주에 했었던 DeepSeek V4가 끝판왕을 한번 보여줬다고 생각하고 넘어가시겠습니다.
MLP와 MoE 구조 sparse MoE 직관 21:06
최승준 예. 왜냐하면 너무 많아지거든요. 저장하기에. 그래서 그다음에 여기가 MLP 부분인데, attention을 통과한 다음에는 FFN이라고 하기도 하고, MLP라고 하기도 해서 아주 작은 층의 hidden state가, hidden이 하나 정도는 hidden layer가 하나 정도 있는 MLP를 통과하거든요. 하나 또는 두 개가 될 때도 있는데,
그래서 그렇게 되면 거기서도 느낌적인 느낌으로는 어떤 정보를, 거기서 이 들어가고 있는 벡터들에 의해서 인출하는 크기로 보면 attention보다 MLP가 훨씬 더 weight가 크거든요.
그래서 여기에 뭔가가 더 많이 있고, 이 부분이 MoE랑 연결이 되는 부분
노정석 네. 저 MLP 부분이 예전에는 큰 하나의 블록이었고, 그 모든 것들을 다 계산을, dense하다는 표현을 했죠. 촘촘하다고, 다 계산했어야 됐는데 MoE가 이제 걔를 쪼개 놓은 거죠.
최승준 그래서 이게 지금은 sparse MoE 같은 경우 DeepSeek V4 지난주에 했을 때 384개 중에 6개 정도 activate 되는 그런
노정석 숫자는 까먹었는데 사실 굉장히 큰 숫자였고 굉장히 sparse했습니다. 네.
최승준 그래서 그게 오늘에도 여러 번 중요하게 나올 거고요. 그렇게 해서 여러 후보들, 여기 보면 logit이라는 개념이 나오는데, logit이 결국에는 어떤 확률로 만들기 전의 것이거든요. 그래서 어떤 점수들이 나오는데, 그거의 확률로 해 가지고 5만 개 정도의 단어장에서 뭐가 토큰이 될지, 그래서 이때는 벡터가 아니라 다시 토큰으로 만들고, 그 토큰이 ID째로 처음으로 돌아간 다음에 다시 벡터가 되는 게, 그게 자기 회귀(autoregressive)라는 방식이 되는 거죠
노정석 그래서 input에 넣은 거는 여러 단어는 한 번에 처리가 되는데, 이제 그다음 단어 예측은 그냥 그다음 단어 예측은 앞에 있는 게 하나가 나와야 그 위에 쌓아서 또다시 다음 단어를 요구할 수 있는 거잖아요.
최승준 그리고 좋은 아이디어는 이미 앞에 KV들은 앞에 것들 다 계산해 두었다는 거거든요. 재활용할 수 있다. query는 그 새로 생긴 한 토큰에 대해서 다시 생기지만 나머지는 이미 있던 걸 쓰고, 새로 생긴 토큰의 KV를 거기에다 합쳐주는 그런 방식으로 진행이 됩니다. 여기 뭐 top-k, top-p는 넘어가도록 하겠습니다. 그래서 여기까지가 트랜스포머를 되게 quick하게
노정석 맞아요. 트랜스포머가 이런 식으로 생겼습니다. 단어가 들어오면 단어를 어떤 토큰이라는 걸로 쪼개서 바꾸고, 걔를 그냥 우리가 인지하는 hello는 몇 번이고 뭐는 몇 번이고라는 그 이름표가 있는데, 그 이름표를 모델에 넣기 위해서 뭔가 position도 더하고 embedding을 거쳐서 이해할 수 있는 그런 벡터로 바꾸죠. 단어가.
그리고 이제 저희가 그게 사실은 토큰이라고 부르는 거고, 걔가 들어가서 attention을 거치고, 그리고 attention 블록 안에 중요한 개념이 KV cache라는 게 있고, 그리고 그 나온 attention 블록을 나온 다음에 다시 MLP 블록에 들어가서 연산을 하고 나오죠.
최승준 예. 그리고 나온 게 이렇게 돌아가는 건데, 중요한 거 하나 빼먹은 게 residual stream의 개념을 얘기를 하긴 했어야 되는데, 그게 하나씩 나오면 자기 자신한테 더해서 조금씩 의미를 갱신해 가거든요. 네. 그게 사실 되게 중요한 부분입니다.
노정석 중요한 개념인데
최승준 그래서 이렇게 해서 이때마다 residual stream이 생겨요. 모든 벡터들에 대해서, 토큰이 벡터 된 거에 대해서 attention 한 정보를 자기 자신한테 더하고, 그래서 그다음에 MLP 한 거를 자기 자신한테 합치고, 그래서 그거를 계속 모든 블록에 대해서 연쇄해 가거든요.
노정석 네, 그렇죠.
최승준 이게 사실은 중요한 흐름이 생기는 중요한
노정석 그렇죠. 여기 그림에서 보시는 블록 1, 2, 3, 4, 5, n이 있는데 DeepSeek 같은 경우에는 얘가 61블록이 있는 거죠.
최승준 GPT-3는 오히려 더 많았어요. 90개 정도였고
노정석 그렇군요. 그리고 그 블록 안에 존재하는 것들이 attention과 MLP 블록이고, 그게 두 개가 핵심인 거고 그리고 저희가 요새 보고 있는 여러 최신 모델들의 아키텍처 변화가 거의 대부분 그 안에 있는 attention을 어떻게 더 메모리를 작게 쓰고 계산을 더 빨리 하게 할 거냐에 대한 것과 그다음에 dense 블록, 거기를 어떻게 더 작게 만들고 계산을 더 효율화하게 할 건가.
최승준 그렇습니다. 그래서 이렇게 LM head 설명을 안 했는데 LM head는 어쨌든 맨 마지막, 많은 걸 계산해 놓고 그래서 맨 마지막에 있는 토큰에 그러니까 이 벡터에 대해서만 다음 거를 추론할, 다음 토큰이 뭐가 나올지를 예측하는 데 쓰이긴 하는데요. 그거와 다음 장이 아마 좀 전에 말씀해 주셨던 그거의 메커니즘을 다이어그램으로 표현한 거고 더하기가 있는 게 residual을 합쳐주는 부분입니다.
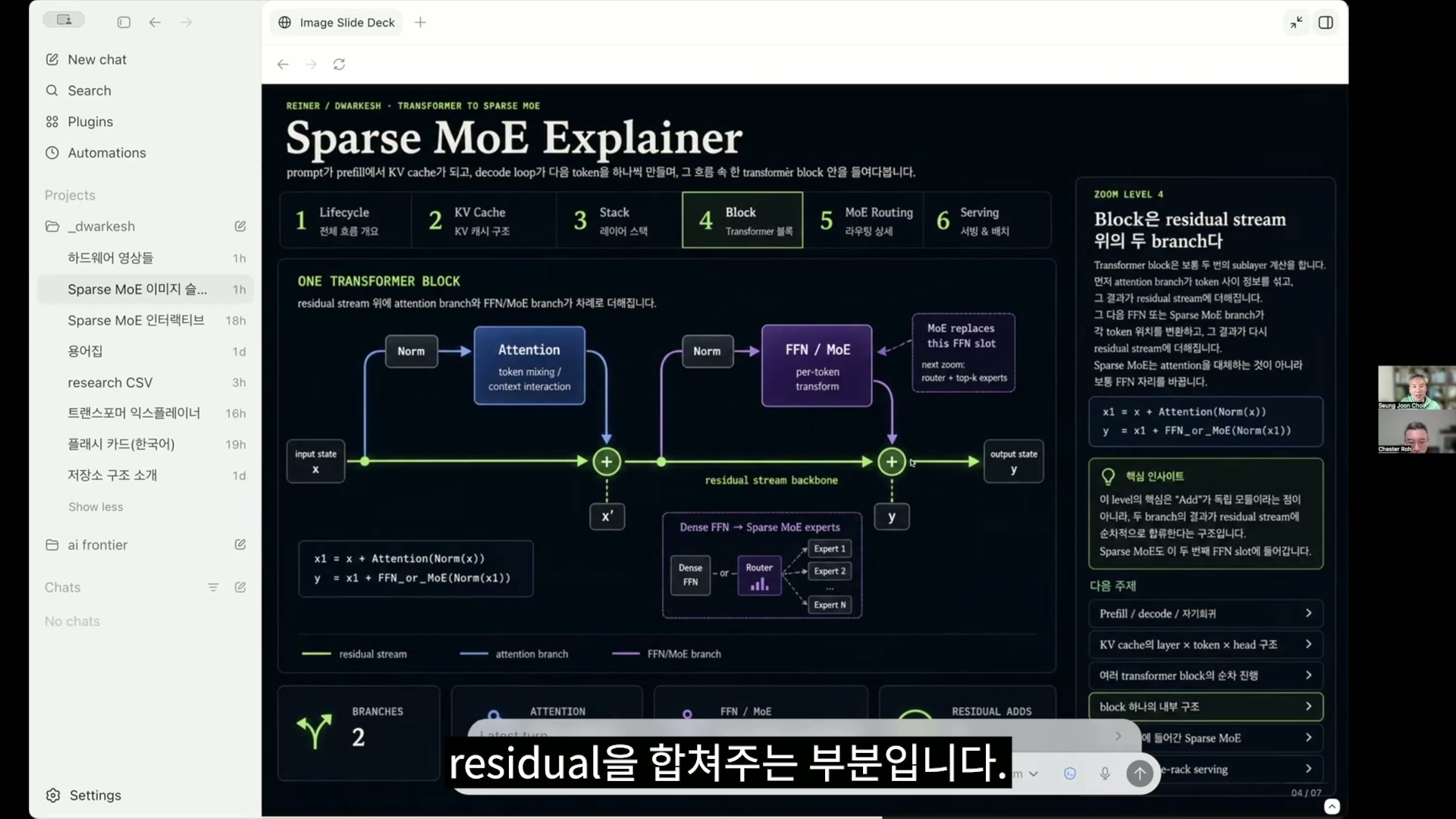
노정석 아래 녹색 선이 residual connection이죠.
최승준 잔차 연결을 하는 거죠.
노정석 지금 이게 transformer 블록 하나를 보여주고 있는 거네요.
최승준 그렇죠. 그래서 하나의 블록을 도식화할 수가 있습니다.
그런데 여기 방금 FFN 또는 MLP, 그리고 MoE 이렇게 된 거가 요새는 parameter를 키워야 되니까 메모리에 올릴 수 있을 만큼 크게 하려면 나눠줘야 된다는 문제가 생기는 거죠. 이게 오늘 핵심 중의 하나인데 그거를 제가 interactive한 버전으로 만든 거가 그래서 이게 토큰 또는 벡터마다 일부의 MoE만 켜지잖아요.
그래서 처음에 예를 들어서 하나만 켜놨다고 하면 지금 제가 여기서 두 개만, 실제와 다르게 전체 16개에 있는 MoE 중에 두 개만 연결이 되게 한 거예요. 이거에 대해서는 두 개의 어떤 FFN 또는 MLP가 작동되게 한 거죠.
그리고 그거에 가중치 합을 해서 다음으로 연결해 주는 건데 이게 하나 하면 네 개 됐죠.
그런데 어떨 때 보면 두 배가 아닌 경우가 생길 때가 있어요. 지금까지는 다 두 배였는데 지금 1, 2, 3, 4, 5, 6, 8. 두 배였네요.
다른 route를 한번 볼게요. 그래서 이때는 1, 2, 3, 4, 5, 6, 7.
7개니까 8개가 될 것 같은데 7개가 되는 거는 한 전문가.
노정석 expert가 두 번 한 거죠. 이게 여기서 MoE, Mixture of Experts라고 해서 많은 분들이 헷갈리는 부분이 expert라는 개념이 전문가니까 내가 수학을 물어보면 수학은 어떤 expert가 처리하고, 물리를 물어보면 어떤 건 다른 expert가 처리해서 expert가 지식들을 담고 있는 다른 단위인가 보다라고 생각하시는 분들이 있는데 그렇지 않습니다. “I am a boy.” 라고 치더라도 그게 다 각자 다른 expert를 지나갈 가능성이 있습니다.
최승준 그리고 토큰, 아까 토큰들마다 다른 expert를 지나가죠.
노정석 그게 그냥 묶이는 것뿐이죠. 그래서 그런 거가 왜 그러냐라고 물어보시면 저희도 몰라요.
최승준 그리고 전문가들은 transformer 블록마다 여러 개가 있는 겁니다. 몇백 개가. 그래서 그 부분도 중요한 거고요.
랙 내부 통신 NVLink NVSwitch와 랙 간 병목 28:43
그래서 마지막으로는 그런 것들이 어떻게 serving이 되는가의 하드웨어 구조인데 보통 하나의 데이터 서버 랙이라고 하죠. 랙이라는 형태가 어떻게 생긴 건지 좀 이따 영상으로 한번 볼 건데요.
그거 안에 GPU들이 여러 개 있는데 하나의 GPU 안에 MoE를 같이 두 개 정도 묶어 놓는 게 좋더라고요. 요새 하는 거 보니까 그랬을 때 걔네들이 서로 다 연결이 되어야지 빠르게 계산을 할 수 있거든요.
이 안에서의 계산은 굉장히 NVLink 같은 걸로 빠르게 되고, 요새 NVSwitch라는 게 또 있더라고요. 빠르게 되는데 랙 사이에는 이게 좀 오래 걸리고 멀어지는 것 같습니다. 하드웨어상.
노정석 이게 조금 이따가 저희가 랙의 개념에 대해서 한 번 보긴 할 텐데 사실 랙 안에서는 서로 GPU들끼리 통신하는 게 빠르고 랙 밖으로 넘어가면 느려지니까 가장 빠른 네트워크 안에서 처리하는 게 무조건 답이겠네요.
최승준 그리고 이 GPU들 사이에서 전달하는 거는 결국에는 tensor 같은 거죠. activation 된 것들이나 그런 것들이 서로 전달이 되는데 동시다발적으로 서로를 이렇게 연결해 줘야 되는 문제가 있어서 그런 아키텍처가 필요한 것 같습니다. 그러면 일단 NVL72가 아까도 살짝 언급이 나왔던 그 영상을 보면, 이게 한 2분 정도 되는 영상이거든요.
NVL72 랙 구성 영상으로 보는 데이터센터 30:00
노정석 네, 우리 기계가 어떻게 만들어지는지를 보여주네요. Blackwell GPU 한 장이 이 다이 두 개 합쳐져서 만들어졌다.

최승준 숫자가 빠르게 지나가긴 할 건데요. 저 노란색으로 붙은 거가 HBM이에요. HBM 메모리네요. 그리고 두 개에, 하나가 붙었어요.
노정석 GPU 두 개에 CPU 하나.
최승준 슈퍼칩이라고 불리는.
노정석 그리고 CPU와 GPU 사이도 굉장히 빠르게 연결되네요.
최승준 그래서 이게 하나의 슬롯이 되는 거죠.
노정석 그럼 한 슬롯에 GPU 4개, CPU 2장.
최승준 그러니까 Blackwell 두 개에 CPU 하나죠.
노정석 방금은 통신을 위한 interface 카드가 들어가고

최승준 그래서 이게 합하면 72개 쌓을 수 있다는. 그리고 이게 스위치, 좀 전에 다이어그램에서 봤던 거죠. 저걸 이제 spine에다가 꽂아서 결국에는 어떤 고속도로를 깔 수 있느냐인 것 같아요. 물리적으로. 그래서 여기에 랙 하나, 72개를
노정석 72개의 GPU가 들어간.
최승준 그런데 InfiniBand라는 게 있어요. 큰 대역폭이 필요한 것은 아까 같이 랙 간으로 연결하기 위해서 이게 DC 스위치라고도 하는 것 같습니다. 그리고 저게 냉각 파이프라인.
노정석 수랭식.
최승준 그래서 AI 팩토리 데이터 센터를 이런 식으로 어마어마한 비용이 들 것 같긴 한데요. 만들 수 있다. Blackwell 시절에 보여줬는데 Rubin 시절에 보여주는 거는 또 하나 더 올라가더라고요.
노정석 네.
최승준 그래서 영상이 하나 더 있긴 한데 이거는 올해 GTC에서 쭉 어떻게 이게
Video On April 6th, 2016, a decade ago, we introduced DGX-1.
최승준 짚어 주는 게 있거든요. 한번 GTC 1시간 7분쯤부터 나옵니다. 그래서 그걸 한번 보시면 될 것 같아요. 그래서 이게 요즘에 어디까지 왔나, 그런 것들.
Jensen Huang Hot water, 45 degrees, which takes the pressure off of the data center, takes all of that cost, all of that energy.
최승준 이만큼은 이것도 이제 72개.
Jensen Huang They use LPDDR5, LPDDR5 and incredible single thread performance.
최승준 이제는 Jensen Huang이 들어서 보여줄 수 없는.
Jensen Huang That’s it. We built that so that it could go along with the rest of these racks for agentic processing.
최승준 여기까지는 이제 Blackwell. 그래서 이런 식으로 해서 NVLink 운영하는. 그래서 이 Dwarkesh 영상을 보고 나니까 Jensen Huang의 키노트를 다시 살펴보게 되더라고요.
노정석 맞아요. 자, 승준님, 저희가 그러면 앞에 배경 설명들을 좀 했으니까 오늘의 메인 콘텐츠를 한번 시작해 보도록 하겠습니다. 저희가 3일 동안 공부한 콘텐츠가 이 Dwarkesh가 Reiner Pope이라는 분과 함께한 강연인데요.
roofline analysis로 보는 LLM 서빙 시간 분해 33:31
어떻게 이 GPU들이 serving이 되는지를 간단한 수식을 가지고 저희가 몇 개의 숫자들에 감추어진 그런 의미들을 읽을 수 있도록 만들어 주신 세션인데요. 이 세션 한번 저희가 따라가면서 의미들을 짚어보도록 하겠습니다.
roofline analysis를 해주겠다는 얘기를 하면서 이야기를 진행하는데요. 이 아저씨가 얘기를 하는 게 저희가 결국은 그냥 Codex나 Claude Code나 아니면 ChatGPT에다 뭘 글을 쓰고 엔터를 딱 누르면 그게 돌아오는 결과가 나오는 시간이 있잖아요.
그런데 그 결과도 그냥 A4 용지 한 장에 빵 나오는 게 아니라 토큰이 generate 되는 게 저희가 보이지 않습니까?
최승준 decode 되는 과정이 보이죠.
노정석 그렇죠. 그 과정이 어떤 건 굉장히 빠르고 어떤 건 느리고, 물론 지금은 굉장히 상향 평준화돼 있지만 예전엔 느린 경우도 저희가 왕왕 목격을 했지 않습니까?
최승준 맞아요. 그리고 첫 토큰 나오는 시간이 또 미묘하게 다르지 않나요?
노정석 그렇죠. 그런데 그런 것들이 도대체 안에서 어떤 일들이 일어나는지에 대한 개념에 대해서 설명을 해 주는데 이게 그냥 저희가 딱 건너뛰고 결론만 얘기하기에는 중간에 있는 내용들을 조금 안 따라가면 어려운 부분이 있어 가지고 저희도 한 스텝씩 따라가 보도록 하겠습니다.
t_mem과 t_compute로 보는 latency 결정 35:12
최승준 좋습니다.
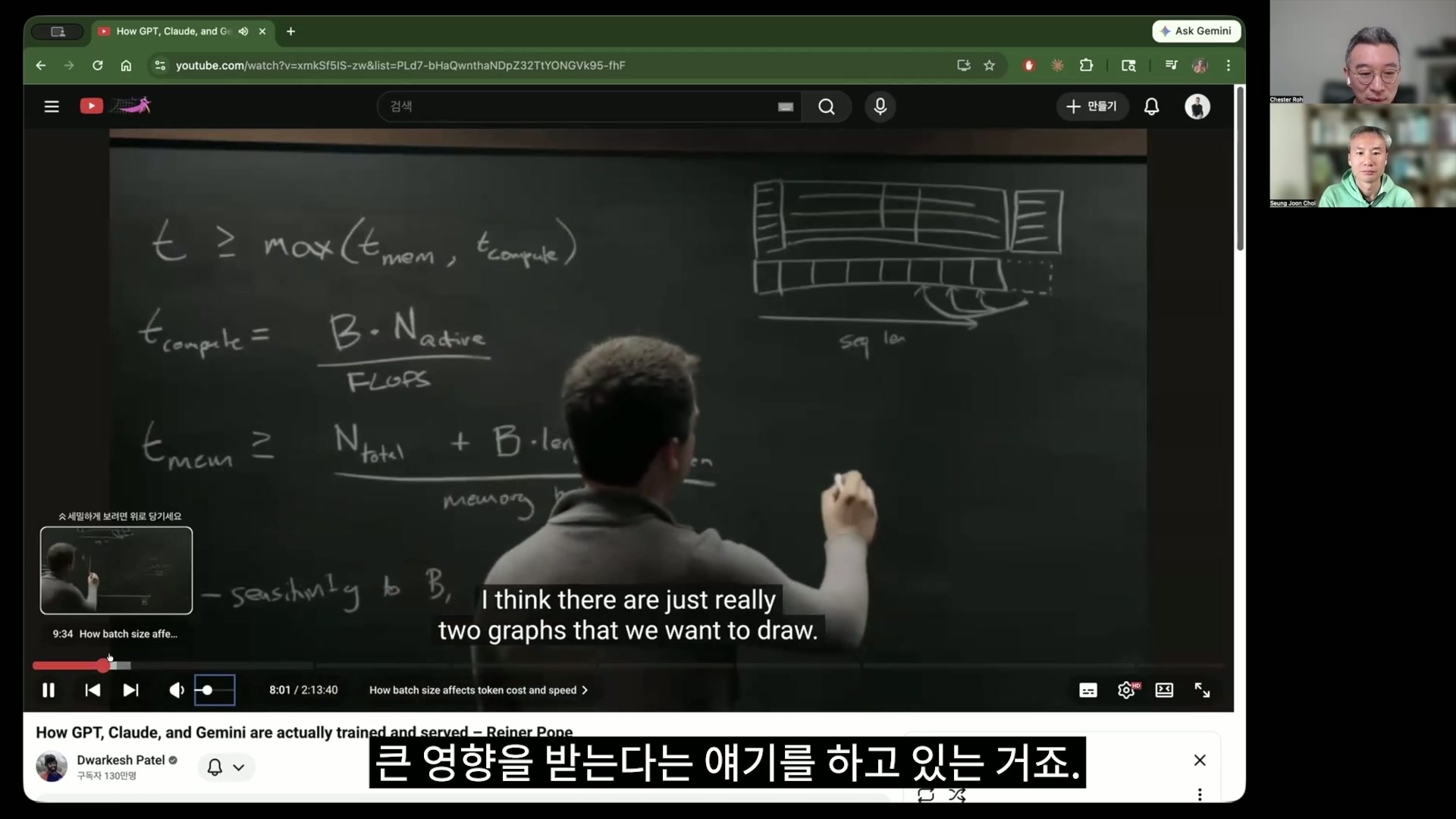
노정석 여기서 이제 t =시간이죠. 즉 걸리는 시간은 LLM이 무언가를 이렇게 결과를 내는 데 걸리는 시간은 t_mem과 t_compute, 이 두 개로 얘기를 하거든요. 그래서 메모리 시간과 compute 시간, 그 둘 중에서 많이 걸리는 거에 제한이 된다, bound 된다라는 이야기를 여기서 하는 것 같아요. 그렇죠. 그리고 그래서 compute가 걸리는 시간은? 하고 있습니다.
최승준 active parameters라는 얘기가 나왔어요.
노정석 이 compute에 걸리는 시간은 사실은 저희가 방금 transformer에서 이야기를 했죠. computing하는 데 메인으로 걸리는 요소는 사실 attention 계산하는 부분과 그리고 뒤에 dense 블록, MLP 블록이라고, multi-layer perceptron이라고 불리는 저희가 전통적으로 익숙한 그런 neural network.
최승준 이게 이름이 헷갈려요. MLP라고 부를 때도 있고 FFN이라고 부를 때도 있는데 같은 걸 말하는 거죠.
노정석 맞아요. 같은 걸 말하는 거죠.
최승준 지금은 expert를 말하는 거고.
노정석 그렇죠. 그런데 이제 그 블록 두 개를 계산하는 시간의 합인 건데 그렇죠. 그런데 여기서는 t_compute를 계산하면서 그냥 그 dense 블록만 계산을 했어요. 계산의 편의를 위해서 여기에 compute에 걸리는 시간은 사실은 뭐죠? 이 parameter의 개수에다가 사실 저희가 넣는 토큰의 개수를 곱한 거잖아요. 그렇죠. 넣는 토큰은 저희가 batch로 처리해서 하는데 이 batch라는 것의 개념을 사실은 설명하고 들어가긴 해야 되겠네요. 그러니까
추론 배치 개념과 스케줄링 오케스트레이션 36:46
최승준 sequence length 비슷하다고 볼 수 있지 않나요? 그런데 여러 명이 쓰는 sequence length랄까.
노정석 그러니까 여기서 저희가 training에서의 batch와 추론에서의 batch를 조금은 구별할 필요는 있을 것 같아요. 그러니까 training에서의 batch는 저희가 여러 문장을 한 번에 계산하기 위해서 저희가 batch라는 표현을 쓰잖아요.
최승준 그렇죠. GPQA 한 번에 돌리려고 그렇게 하죠.
노정석 한 번에 돌리려고. 그래서 배치가 있으면 한 배치에 sequence length는 보통 training이 허용하는 범위에서 예를 들어 4K, 8K다라고 하면 그 범위 동안 sequence length는 꽉 차 있죠. 그렇죠. 그래서 보통 training할 때 저희가 뭔가 집어넣는 텐서의 dimension을 보면 batch, 그다음에 sequence length, 그다음에 embedding, 저희가 hidden dimension이라고 부르는 이거 3개의 곱인데,
최승준 d_model.
노정석 그렇죠. 얘가 꽉 차 있죠. 그래서 batch 곱하기 어떤 sequence length가 사실상 데이터셋의 크기가 되는 건데, inference의 경우에는 조금은 문제가 달라져요. 어떻게 달라질까요?
최승준 어떤 입력을 하느냐에 따라서 생성되는 길이도 다르고, 입력도 다르고, 다 다른 거 아니에요?
노정석 맞아요.
그런데 저희가 prefill할 때는 여러 개의 토큰이 한 번에 들어가니까 여차하면 training과 비슷한 상황이 될 수도 있는데, decode의 경우에는 반드시 이 앞 토큰 하나가 들어와야 그다음 한 토큰이 전진을 하잖아요.
그렇기 때문에 사실은 입력되는 토큰이 하나밖에 안 된다는 말이에요. 그러니까 sequence length가 하나밖에 안 되는 거니까.
그래서 그냥 전통적인 training 관점에서 보면 batch를 한 유저라고 가정했을 때 어떤 유저는 “Hi”라고 한 문장을 쓸 수도 있고, 어떤 유저는 그냥 Codex에서 막 50K짜리 context를 던질 수도 있고, 어떤 유저는 그냥 한 단락일 수도 있고, 사실은 length가, 그러니까 길이가 너무 다 달라지잖아요.
만약에 그걸 training과 같은 그런 dimension을 채워야 된다고 하면 다른 부분들은 padding으로 밀어야 되지 않습니까? 아무것도 안 들어 있다.
최승준 놀잖아요.
노정석 그렇죠. 그러면 어마어마한 메모리 낭비가 되니까 그냥 합리적인 생각은 padding을 다 없애고 다 이어 붙이면 되는 거지 않습니까?
그렇죠. 그게 추론에서의 사실 batch의 개념인 거죠. 맞아요.
얘를 이어 붙이면 사실은 엉망이 되는 구간이, dimension들이나 KV나 이런 것들이 다 망가지잖아요. 사실은 그렇죠.
training할 때는 한 batch에 쭉 들어가 있는 sequence length에 따라서 KV가 정확하게 align이 되어 있는데, 추론할 때는 그냥 한 batch에다가 여러 유저들의 그 단 하나짜리에, 그냥 next token으로 가기 위한 그 토큰들을 다 집어넣어 버리면 KV cache가 전부 망가지지 않습니까?
최승준 자세히는 모릅니다. 저도
노정석 이게 망가지니까 사실은 그거는 vLLM이나 SGLang 같은 애들이 메타 레이어를 둬서 전부 매칭을 해주거든요. 그래서 결론만 놓고 나면 결국은 inference도 그 한 batch에, 우리가 지금 이용하고 있는, 우리가 한 GPU에 몇천 명이 같이 동시에 붙어 있다고 보면 되는 거죠.
최승준 스케줄러가 있어야겠네요. 그거 한
노정석 네, 스케줄러가 있죠. 스케줄러가 있고 메타 레이어가 있어서 그거를 “이 batch에 100번째 있는 거는 유저 최승준이고, 103번째 있는 토큰은 노정석이고, 누구 것인 토큰은 누구인 거고”라고 그 토큰들에 대한 인덱스를 다 갖고 있고, 그다음에 그게 transformer block을 통해서 연산을 통해 나오면 그 사이에 중간중간에 KV 연산들을 다 해야 되잖아요. 그렇죠.
그런데 그 사용자들의 상황도 다 다를 거예요. 어떤 유저는 앞에 context가 이미 막 80만 context를 쓴 유저도 있고, 어떤 유저는 context가 0일 수도 있고.
최승준 cache가 날아간 경우가 많이 있을 건데, 네.
노정석 compact돼서 날아가는 경우도 있고. 한데 결국은 그 앞에 있는 context라는 게 저희가 앞서 얘기했던 KV cache 덩어리이기 때문에 그 KV cache 덩어리를 다 매핑해 주는 메타가 전부 돕니다. 메타 레이어가, orchestration layer가 다 돈다는 가정을 하면 되고요.
그래서 추론과 training에서의 어떤 dimension이 조금은 다르고, training에 익숙한 분들이 생각하는 batch와 지금 오늘 저희가 이 Dwarkesh가 얘기하는 이 batch는, 추론에서의 batch는 지금 다르다고 말씀을 드려야 될 것 같아요.
그렇게 하는 이유가 중요하죠. 이렇게 하는 이유가 어떻게 보면 가장 중요한 이유일 것 같은데.
GPU utilization과 MFU 차이 41:36
최승준 어마어마한 GPU를 놀리면 안 되니까.
노정석 비싼 자원이기 때문에 놀면 안 되거든요. 놀면 안 되기 때문에 이 한 스텝, 스텝 돌 때마다 꽉꽉 채워서 돌려야 돼요. 그래서 GPU 사용률을 거의 한 70에서 80%를 돌려야 이게 남는 장사가 되는 거니까.
최승준 MFU가 그건가요? Model FLOPs Utilization, 그게 관련이 있는 거 아니에요?
노정석 MFU와 GPU utilization은 좀 다른 개념이라고 봐야 될 것 같아요. MFU는 사실은 FLOPs니까, 이 GPU가 낼 수 있는 얘가 그냥 풀로 돌았다고 가정했을 때
최승준 아웃풋이 최대일 때.
노정석 네. 메모리 bottleneck이나 이런 걸 계산 안 하고 그냥 단지 계산만 optimal로 했을 때 얘가 100을 계산하는데, 사실 현실에서의 계산은 그게 안 되잖아요. 데이터가 준비될 때까지 기다려야 되고, 뭐 해야 되고, block되는 것들이 되게 많기 때문에 사실은 많은 연산들이 compute-bound 되는 게 아니라 memory-bound 되는 경우가 많기 때문에 MFU는 다 쓸 수가 없죠.
그런데 MFU와 I/O나 이런 거를 다 계산해서 그냥 GPU가 돌고 있으면 이건 도는 거다라고 하는 개념이 GPU utilization인 것 같아요.
그래서 training이나 inference에서는 MFU 수치를 높이는 게 무조건 좋죠. 그리고 얘가 조금 이따가 얘기를 하는데 MFU가 maximize되는 포인트가 그냥 t_compute와 t_memory가 같으면 그게 max 되는 거 아니냐고 그냥 퉁치고 넘어가는 거.
최승준 우선 이렇게 만나는 교차점 같은 거.
노정석 그래서 제가 말로 썰을 풀긴 했는데, 이게 적어도 transformer의 training에 있어서의 아까 얘기했던 B, N, 그다음에 모델 dimension, 이 텐서의 개념이 머리에 딱 박혀 있지 않으면 사실은 얘를 그냥 계속 이해하기가 조금은 어렵긴 하니까 그런가 보다라고 넘어가시면 됩니다.
그런데 추론에서는 batch와 sequence를 그냥 하나로 다 펴버려서 그냥 그거를 하나의 열차로 두고 그 열차 안에 여러 유저들의 workload를 동시에 태우는 거죠.
그래서 한 clock이 뿅 돌 때 최대한 많은 유저들을 태우기 위해서, 그런데 그 열차에는 굉장히 다양한 승객들이 타 있는 거죠.
예를 들어서 그 유저가 그냥 decode, 모두가 다 decode 과정에 있다고 가정하면 사실은 input으로 넣는 토큰이 하나밖에 안 될 거고, 그러면 예를 들어 batch가 2천 개다라고 하면 2천 명을 동시에 태울 수도 있는 거고.
최승준 응. 만약에 그냥 좀 거칠게 말해서, 뭔가 모델이 계속 그 weight에다가 행렬 곱을 해줘야 되는데, 그 행렬 곱할 거를 승객들의 데이터 가지고 채우는 그런 느낌인 거죠. 한 번에 그걸 해야 되고, 계속 그거를 20ms든 뭐든 이게 계속 반복해서 열차는 계속 출발하는 그런 느낌인 거잖아요.
노정석 한 clock을 그냥 20ms에 세워 놓는데, 그건 이 뒤에서 또 얘기가 나오니까 왜 20ms인지는 한번 얘기해 보는 걸로 하고.
결국은 열차를 채우는데, 아까 하던 얘기를 그냥 마무리하면 한 토큰씩만 들어가면 2천 명이 동시에 쓸 수도 있는데, 예를 들어 누가 Claude Code에서 코드를 그냥 왕창 밀어서 넣어서 prefill을 해야 되는 게 막 천 개가 들어 있다라고 하면 사실은 그 천 개가 prefill로 차고, 그다음에 decode하는 유저들은 그 뒤에 천 명 정도가 차는 거니까.
이런 식으로 prefill과 decode 되는 과정을 어떤 식으로 optimize할 거냐라는 것들이 요새 최신 현대 LLM serving하는 거의 핵심이더라고요.
그 목적은 뭐냐.
결국은 어느 단위 시간당 메모리나 compute나 이걸 다 maximize해야 되는 거죠. utilization을.
어떻게 이걸 꽉 쓸까에 모든 게 다 맞춰져 있다고 보시면 맞겠죠.
좋습니다.
그러면 그 정도 하고, 뒤에 나가면서 또 개념이 나오면 하나하나 해 보는 걸로 하죠.
그래서 t_compute는 얘가 그냥 이렇게 얘기하는 거죠.
batch, 몇 명을 태울 거냐.
그냥 편의상 한 토큰이라고 해 봅시다.
그러면 2천 명을 태운다고 하면 B가 2천인 거예요.
그리고 N_active는 그냥 activate되는 parameter의 숫자.
이 친구가 이제 이분이 MoE 개념을 갖고 와서 사실은 sparsity의 개념이 전체 parameter는 이만큼인데, MoE의 핵심 개념이 계산할 때는 몇 개의 expert만 빠르게 계산한다잖아요.
그것 때문에 사실 computing에서의 효율이 생기잖아요.
최승준 parameter의 전체 크기를 키우는 방법이기도 하고, 효율이기도 하고 그런 거.
노정석 그렇죠. 그 효율을 위해서 얘는 그래서 t_compute는 batch 곱하기 이 number of parameters, active parameters의 number에 bound 된다고 표현하기 위해서 이 표현을 쓴 거죠. 걔를 FLOPs, 초당 몇 번 계산할 수 있느냐로 나누면 거기에 걸리는 단위 시간이 나오겠죠. 그렇죠?
최승준 밑에는 그냥 분모를 computing power라고 생각을 대강 퉁쳐서 하면
노정석 가정하는 거죠.
최승준 이렇게 나오겠죠.
노정석 네, 나오네. 그래서 물론 여기 attention 이게 하나가 빠져 있는데, 이게 빠져 있는 거를 이 친구는 그냥 여기에 편의상 이렇게 계산의 개념을 위해서 하겠다고 하는 거죠. 그런데 attention이 sequence length 안에 들어가는 그 context length가 커지면 사실 attention 가격은 높아지고, 작아지면 줄어드는 거니까.
그런데 사실상 중요한 포인트라서 이건 말씀드리고 넘어가야 될 것 같은데, 사실상 이게 길어도 다 쪼개서 넣긴 하더라고요.
예를 들어서 우리가 넣어야 되는 Claude Code에서 보내는 코드가 막 5만 토큰이라고 하더라도 그 5만 토큰을 동시에 넣지 않더라고요. 또 그걸 다 쪼개서 막 천 개씩 쪼개서 다른 사람들의 decode 토큰과 다 섞어서 태우는
최승준 어떻게든 채운다는 거잖아요.
노정석 그렇죠. 어떻게든 채운다. 그래서 그런 얘기들을 안 그래도 Dwarkesh가 물어보죠. 저희가 이 이야기를 거의 다 했기 때문에 저희 이제 메모리 쪽으로 그냥 넘어가도록 하겠습니다. 그래서 이 수식을
최승준 이제 decoding 되는 거 쓰는 것 같은데요. 네.
노정석 네, decoding 되는 거 쓰면서 쭉 쓰는데, 사실은 저희는 이제 얘를 놓고 계산 바로 보는 게 맞을 것 같아요. 그러면 memory time은 어떻게 결정이 되냐. 첫 번째로는 N_total인데, 사실은요. 여기는 total이죠. 왜냐하면 얘는 다 들고 있어야 되잖아요. 계산할 때 메모리에 전체 이 모델 weight를 다 올려서 가지고 있어야죠. 그리고 expert 같은 경우에는 activate되는 expert만 계산을 하면 되니까, 되는 거니까 compute는 이걸 active로 했고.
메모리 시간 모델 전체 로딩과 KV cache 비용 48:16
최승준 그렇죠. 계산할 때는 active한 것만 weight 끌어다 써서 하면 되는데, 메모리 계산할 때는 다 들고 있어야 된다는 거군요.
노정석 그렇죠. 근데 메모리 계산할 때는 다 들고 있어야 되니까 N total을 한 거고, 그다음 플러스 여기에다가 사실 이 attention에서 위에는 빼먹었는데 여긴 또 넣었어요. batch에다가 그다음에 각 batch마다 length가 다 다르죠. context가 decode인 경우에는 1일 거고, 그다음에 누가 prefill을 하고 있는 과정에 있으면 얘는 상당히 길어질 거고, 그거에 따르고, 여기는 토큰당 몇 byte 들어가는지를 곱해주면 이게 나오는 거죠. 그렇죠. 여기도 사실 잠깐 제가
최승준 헷갈리는 게 decode일 때는 1이에요? 결국에는 앞에 prefill된 거 플러스 1씩 계속 가는 거거든요. length니까.
노정석 아니죠. 그렇게, 왜냐하면 그 부분이 참 승준님 많이 헷갈리는 부분이긴 한데, 사실 decode할 때 들어가는 토큰은 그 앞에서, 그러니까 바로 전 단계에서 output된 마지막 토큰. 걔 하나만 input으로 들어가거든요.
최승준 왜냐하면 이미 앞에 KV는 있으니까.
노정석 그렇죠. 그래서 input으로 들어가고, 사실상 그 transformer block에서 이 flow를 타는 tensor는 그 input 토큰 하나예요.
근데 그 input 토큰 하나가 들어가지만, 각각의 transformer block에서 앞에 있었던 prefill됐든 아니면 앞에 decode 단계였든, 앞선 context의 KV cache block들이 block마다 다 있을 거예요. 그렇죠. 다 있어요.
그건 cache에서 불러오는 거죠. 그게 HBM에 있으면 빨리 되는 거고, HBM에 없으면 다른 데 가서 긁어 와야 되는 거고, 어찌 되었건 걔를 어쨌거나 HBM에 loading돼야 계산은 되는 거니까.
그 계산을 하는 거기 때문에 사실은 아까 말씀드린 것처럼 이 하나의 inference batch에 굉장히 많은 유저들을 같이 실을 수 있는 거죠. 왜냐하면 decode인 경우에는 input 토큰이 하나만 지나가니까.
최승준 그렇죠. 그렇게 섞여 있을 거라는 거고요.
노정석 그러니까 이게 복잡해지는 부분인데, 대신 유저들의 KV cache가 길이가 다 제각각일 거란 말이에요. 누구는 길고 누구는 짧고, 이런 것들이.
최승준 KV cache는 시간 지나면 날아가는 거기 때문에 다시 prefill로 처음부터 앞에 입력까지 다 긁어가지고 다시 만들기도 할 거잖아요.
노정석 맞아요. 만약에 cache가 hit가 안 되면, 내가 뭐라고 말하고 엔터 탁 치고 갑자기 옆에서 누가 불러서 밥 먹고 와서 1시간 있다 오면 사실상 cache에서 다 날아가죠. 그런 경우에는 사실 다시 prefill인 거죠. 맞아요. 다시 prefill loop를 저 앞에서부터 돌면서 KV cache를 building해야 되는 거니까, 사실 input 토큰의 가격이 그때 다시 계산되니까 비싸죠.
최승준 그렇죠. 비싸지는 거죠.
노정석 근데 만약 cache에서 불러오는 거면, cache가 hit되면 싸게 가져올 수 있으니까 싸지는 거고, 이런 것들이 inference의 경제학이 있는 거죠. 대신 KV cache가 아까 말씀드린 대로 다시 돌아가서, 하나의 batch에 여러 유저들의 그런 단 하나씩의 decode 토큰들을 실어 가지고 위로 그 cycle을 계산하면서 올라가는 걸 생각해 보면, KV cache의 길이들이 유저마다 전부 다 다를 거잖아요.
최승준 물론이겠죠.
PagedAttention과 KV cache 메모리 효율화 52:12
노정석 그 다른 부분들을 굉장히 효율화해서 하나의 memory block에 그냥 잔뜩 담아두게 만드는 게 사실은 vLLM이 만들었던 PagedAttention이라는 혁신이거든요.
만약에 PagedAttention이 없었다면 유저들의 KV cache를 우리 training처럼 굉장히 static한 그런 tensor들에 넣고, 빈 부분들은 그냥 padding으로 채워야 되고, 이런 것들이 생기니까 메모리 낭비가 심했을 텐데, 그걸 그렇게 하지 않고 그냥 하나의 block 단위로 나눠서 마치 저희가 pointer로 전부 그 KV cache들이 어디에 있는지 전부 찍어 놓는 거예요.
그래서 그 연산이 위로 올라가면 올라갈수록 그 KV cache에 있는 page들을 찾아서 이 token들을 다 계산해 주는 역할들을 하는 거죠.
이런 것들을 그냥 어떻게 하나의 vectorized 연산으로 다 만들 거냐가 이 추론 과정의 정말 모든 거라고 봐도 무방하더라고요.
그래서 이 대화 중간중간에 계속 얘기를 하겠지만, 이걸 하는 목적은 뭐냐.
그냥 GPU utilization을 maximize하기 위해서 다 이런 고려를 한다고 생각하시면 되고, 즉 하나의 GPU를 정해진 시간에 그렇게 utilization을 maximize해서 2천 명씩 동시에 serving을 하지 않으면 저희가 이걸 20불씩 내고 쓸 수가 없는 거죠.
최승준 또 궁금해지는 게 이따가 분명히 나올 거긴 한데, 지금 메모리, 그러니까 어쨌든 HBM을 쓰고 있는 게 모델의 weight도 쓰고 있고, KV cache도 쓰고 있고, 그런 거잖아요. 요새는 어디에 더 많이 쓰일까요?
노정석 여기서도 산수가 필요한데, 예를 들어서 저희가 아까 보고 온 가장 최신의 GB300의 NVL72로 연결된 그 rack, 그거 하면 한 rack에
20TB HBM에서의 모델 가중치 KV cache 배분 54:03
최승준 한 2TB 정도?
노정석 아니요. 20.
최승준 20. 맞아요. 20TB, 하나가.
노정석 그렇죠. 한 rack에 들어있는 HBM이 약 20TB 정도가 되고, 그리고 거기에 CPU에도 또 LPDDR5가 다 물려 있거든요. 근데 그 메모리의 크기도 한 20TB 정도가 돼요. 그래 가지고 도합…
최승준 CPU용으로?
노정석 CPU용으로. 우리가 그냥 흔히 아는 RAM, 그게 20TB 돼서 도합 한 40TB 정도의 메모리를 갖고 있고, 안에 storage가 SSD로 있는지 그건 잘 모르겠네요. 어쨌건 storage도…
최승준 그렇죠. 그거 offloading해야 되는 거잖아요.
노정석 있겠죠. 있다고 치고. 근데 계산할 때는 보통 storage까지는 계산을 안 하니까.
최승준 Blue 뭔가가 있었어요. 까먹었지만. (NVIDIA BlueField)
노정석 그렇게 치면 메모리가 한 40TB 있는 건데, HBM에 보통 우리 weight를 다 올리니까요. 20TB가 사실상 우리가 deep learning 연산을 하기 위해 있다고 가정해 봐도 되는 거죠.
최승준 그럼 모델을 그냥 FP8으로, 그냥 byte로 생각하면 굉장히 여유 있는 거 아니에요? 요새.
노정석 맞아요. 예.
최승준 5TB, 5T 모델이 5TB니까.
노정석 5T 모델을 승준님 말씀하신 것처럼 FP8으로 계산하면 걔가 모델을 그냥 fully 적재하는 데만 5TB 용량을 빼앗아 가죠. 그렇죠. 그럼 나머지 15TB가 남잖아요.
그래서 많은 분들이 또 혼돈을 일으키시는 부분이, 그럼 거기에 모델 4개를 적재하면 되는 거 아니냐라고 말씀하시지만 아니죠.
사실은 이게 input이 들어오는 그 용량도 필요하고, 그 input이 transformer block을 돌 때마다 attention 계산하는데 사실은 다 그 activation하는 부분들에 대해 메모리가 다 필요하잖아요. 중간 계산을 위해서 그 중간 결과값들을 해서, 그 activation되는 value들을 저장하는 그것도 필요하고, 무엇보다도 제일 크게 차지하는 거는 KV cache죠.
context가 길건 짧건 모든 유저들의 KV cache를 다 들고 있어야 되니까 KV cache가 잔뜩 차지를 하고 있는데, 이거는 배분하기 나름이에요. 여기서 사실 batch를 얼마를 가져갈 거냐, 그리고 사용자에게 허용하는 context length를 얼마를 줄 거냐, 이것으로 사실 KV cache의 개수가 결정되긴 하잖아요.
그렇기 때문에 그것들에 약간의 trade-off가 있는데, 한 20TB 메모리 정도가 있으면 5TB는 모델에 할당하고, 또 사실은 그거보다 더 작을 수도 있겠죠. 요새는 FP4로 많이 더 줄이니까.
그러니까 20TB 중에서 한 13, 14TB 정도는 KV cache에 할당하더라고요. 그리고 한 2TB 정도를 중간에 계산하는 activation variable들.
근데 그 variable들은 계속 overwrite하면 되니까 걔들은 그렇게 많이 안 가지고 있어도 되고요.
최승준 근데 저희가 지금 얘기를 당겨서 한 것 같긴 한데, 어쨌든 5T라는 모델을 상정했을 때, 이미 5T라는 모델을 상정하는 게 지금 문제이긴 한데요. 사실은 지금 우리가 알고 있는 거는 1T에서 2T 정도의 모델의 serving이었고, NVL72가 나와서 5T 정도가 된 거라고 추정하게 되는 거였잖아요.
노정석 맞아요. 사실상 training 과정은 이게 아니어도 할 수 있는 방법은 많으니까, H100이나 H200 cluster에서도 5T 모델을 학습시키려면 학습시키는 방법들이 당연히 있는데, 이런 큰 모델들을 사실은 H100이나 H200 같이 메모리가 작고, 그다음에 NVLink 같은 GPU 간 통신이 굉장히 작은, node의 개수가…
최승준 2023년까지만 해도 8개가 1개였죠. 22년인가 23년인가, 하여튼 그 정도였던 것 같거든요.
노정석 25년 초까지 아니었을까요? NVL72가 나오기 전에.
최승준 나오기 전에는 8개였죠.
노정석 8개였죠. 근데 NVL72가 나온 지가 얼마 안 돼요. 사실.
최승준 2024년 말이었어요.
노정석 맞아요. 저희가 이런 출시 시기와 숫자와 architecture는 좀 약하죠. 신정규 대표님이 계시면 여기서 쫙 풀어주셨을 텐데, 지금은 저희 둘이 힘겹게 공부하고 있기 때문에 일단 오늘은 그냥 넘어가도록 하겠습니다.
그래서 결국은 승준님이 말씀하신 포인트가 맞긴 맞아요. NVL72가 됐기 때문에 가장 최신의 현대의 어떤 inference 환경에서는 어마어마한 이득이 있다 정도로 얘기를 하면 될 것 같아요. 저희가 이거 메모리 얘기하다가 갑자기 이야기가 여기로 튀었는데, 다시 이 수식 2개를 정리하면 얘를 이해해야 그다음 것들이 전부 다 이해가 되거든요. 그래서 이거는 당연히 이해가 되셨죠?
batch에 따른 latency 그래프와 amortize 개념 59:07
compute는 이해를 했고, 메모리는 total memory를 loading하는 그런 시간, 그다음에 여기는 이제 context를 loading하는 데 걸리는 시간, 이것들을 더한 것을 메모리 대역폭으로 나눈 거죠. 결국은 메모리도 이 전체를 꺼내오는 데 시간이 걸리니까.
최승준 분모가 약간 다 시간 term이 있는 게, 이게 t를 계산하는 거기 때문이죠. 아까 FLOPs도 floating point 부동소수점을 per second에 얼마큼 계산하느냐고, 지금도 대역폭을 byte per second로 한 거기 때문에 결국에는
노정석 숨어 있던 초가
최승준 t로 올라오는 거잖아요.
노정석 그렇죠. 산수죠. 그래서 위아래에 있는 그 핵심이 다 용량들이니까요. 그래서 결국은 초가 나오는 거죠. 그래서 이 두 개를 가지고 현대의 LLM inference가 도대체 시간이 어디서 걸리는지를 하겠다는 거죠. 그래서 이것과 t_memory가 batch와 context length에 큰 영향을 받는다는 얘기를 하고 있는 거죠.
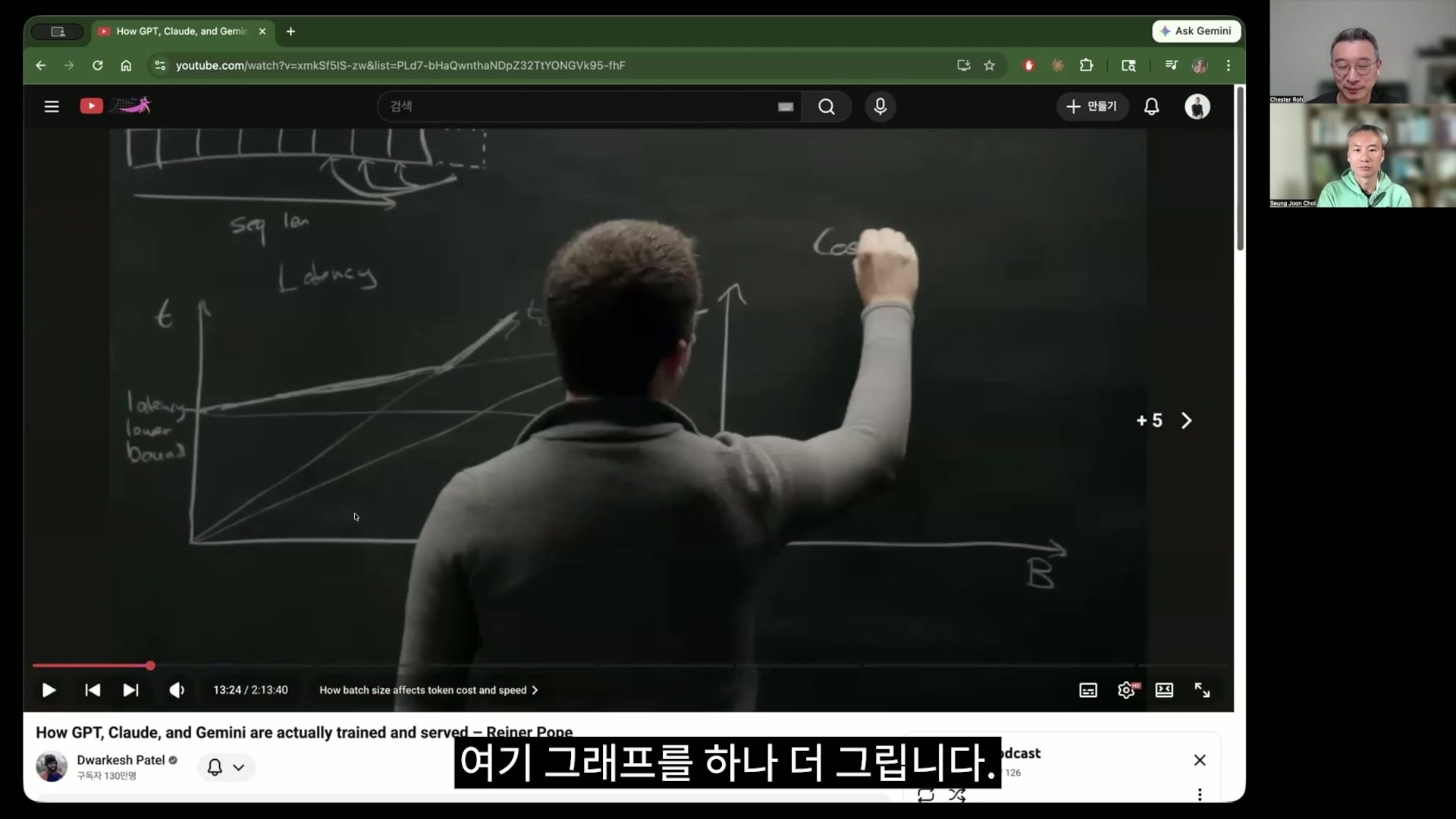
이제 넘어가 볼까요? 그래서 이 그래프를 제가 자막을 좀 끄겠습니다. 이 그래프를 그리는 게 오늘 이해하는 데 매우 중요하잖아요. 이 오른쪽 x축에는 batch, 그러니까 한 time당 유저를 얼마나 처리할 거냐라는 이 batch size와 그것 때문에 걸리는 시간, 이것의 함수를 얘가 그려보는 거죠.
그러면서 이 앞에 있는 이 term들에서 저희가 산수를 해요. t_compute는 사실 여기 배치에 선형 함수일 테니까 얘가 이렇게 선형으로 그린 거고 그다음에 이 메모리 타임에 total memory 로딩하는 타임은 그냥 한 번 로딩하면 그다음은 계속 꺼내서 쓸 수 있으니까, 그렇기 때문에 여기에 굉장히 큰 intuition이 하나 들어 있죠.
이 메모리를 한 번 올리고 나면 얘는 오래 쓰면 쓸수록 사실 거기에 들어간 비용을 상쇄할 수 있는 거니까 이 표현으로는 amortize한다고 분할 상각한다는 얘기를 회계 용어를 끌어와서 쓰는데 그 얘기를 굉장히 많이 하죠.
최승준 amortize가 여러 번 나왔었어요.
노정석 그러고 나서 그다음 그래프를 그리는 게 이 KV cache를 갖고 오는 시간이죠. 근데 이거는 KV cache가 배치가 길어지면 길어질수록 당연히 KV cache를 로딩하는 시간은 길어질 테니까 얘도 왜 그럼 compute보다 아래 그렸냐. 이건 그냥 이 사람 마음이에요. 대충 이런 정도로 이 cache time이 증가할 거다라고 얘기를 하는 거죠.
최승준 근데 지금 N_total하고 N_active가 다르긴 한데 그냥 퉁쳐서 한 거죠.
노정석 그렇죠. 퉁쳐서 하는 거죠. 근데 compute에는 사실 N_total은 영향을 미치진 않으니까요. 왜냐하면 N_total은 메모리 쪽 변수지, 컴퓨팅할 때는 저 total memory가 컴퓨팅하는 시간에 어떠한 영향도 안 주거든요. 왜냐하면 active한 것만 계산하니까 그걸 얘기하는 거로 받아들이면 되고요. 그러면 우리 여기서 방금 이 아저씨 그래프가 잘 보이게 만들어 보자.
최승준 저기가 또 곱하기가 아니고 더하기였기 때문에, 어쨌든.
노정석 그렇죠. 근데 여기서요. 이거 승준님, 넘어가기 전에 아까 DeepSeek 이야기에서 봤던 거가 여기에 큰 영향을 미치는데 이 KV cache time과 이 t_compute time, 이 두 개의 선형 그래프 있잖아요. 그렇죠. 이 그래프의 기울기 가지고 사실 시간과 비용을 다 설명하잖아요. 근데 DeepSeek이 얘를 아래로 쭉 낮춘 거가 문제인 거죠. 이게 낮춤으로써 모든 frontier curve가 다 낮아지는 거죠.
최승준 그러면 이제 교점도 낮아지기 때문에 이제 그거에 관련된 얘기를 하게 되죠.
노정석 그래서 거기에 대한 얘기를 이제 하게 되죠. 그래서 이 compute 파란색 그래프는 아까 compute에서 왔고 KV cache와 그냥 total parameters를 로딩하는 거에 이 선형 함수 이 두 개를 얘가 이제 더하겠죠.
최승준 상식적인 차원에서 저도 하드웨어는 잘 모르지만 HBM이 아무리 빠르다고 하더라도 on chip이 아니라 GPU 옆에 있는 거잖아요. 그래서 시간이 걸리는 거죠.
노정석 그러겠죠.
최승준 그래서 지금 그런 것들이 비용에 지금 들어가고 있는 거잖아요. 너무 많은 것들이 얽혀 있고 저는 이번 세션이 이 하드웨어의 생김새와 그다음에 실질적으로 알고리즘이 도는 거에 그거에 어디서 맞물려 들어가는지 거기에 대해서 이렇게 스파크를 튀겨주는 게 좋았거든요.
그러면 다시 이 그래프로 좀 돌아와서 어렵지만 이 산수지만 어려워요. 그래서 방금 그렸던 t_compute와 t_mem을 얘가 여기에 그래프에 도식화를 한 거고 방금 그린 이 약간 분홍색으로 된 그래프가 KV cache 이것과 그다음에 이 total parameters 로딩하는 이 time, 이 두 개를 그냥 더한 거예요.
두 개를 더하면 사실 우리 중학교 때 배웠던 그게 나오겠죠. 이게 나오는 거죠. 사실상 이게 t_mem이죠.
그리고 결국은 t_mem을 아까 맨 앞에서 봤었죠. 우리가 인식하는 total time은 뭐냐. 여기에 bound된다. 이거에 두 개의 둘 중에 max인 거에 bound된다라는 게 나오는 거죠.
근데 저 꺾이는 부분이 B가 연결이 되는 거죠, 지금.
노정석 그렇죠. 저 꺾이는 부분이 어떻게 되냐에 따라서 하드웨어의 스펙이나 모델의 모양이나 이런 거에 따라서 다 바뀌겠죠.
최승준 그러면 저희가 제일 처음에 했었던 거가 max 함수를 놓고서는 둘 중에 어떤 게 큰 거에 bound된다는데 t_compute에 bound되는 거와 t_mem에 bound된 거가 둘 중에 더 큰 거에 의해서 bound되는 건데 지금 그게 B에 의해서 결정난다는 거네요.
노정석 그래서 최적의 B점을 잘 결정하면 의미가 있다라는 얘기를 하기 위해서 이걸 하고 있는 건데 여기서 보시면 이거네요. 배치가 작을 때는 메모리에 bound되고 그렇죠. 배치가 커지면 이제 compute에 bound된다라는 intuition이 나오네요. 의미가.
그래서 이제 이거는 사실상 이게 T니까 T는 뭐냐. latency를 얘기하는 거거든요. 그러니까 얼마만큼 많이 기다려야 되냐. 그래서 여기가 어떤 작은 task를 시작하더라도 이 weight를 다 로딩하는 시간은 기본으로 걸리기 때문에 이게 latency lower bound라고 얘기를 하는 거죠.
그래서 latency라고 얘기하고 이렇게 latency lower bound라는 표현을 하고 이 그래프는 latency 그래프입니다. 하나를 더 그려요. 설명을 방금 저희가 했었던 설명들을 여기서 해요.
latency가 궁금하신 분들은 이 사이에 했었던 설명들이 이거예요. 승준님과 저와 방금 나눈 대화 같도록 그럼 attention 뭐가 줄어들면 저게 줄어드는 거냐 늘어나는 거냐, 이런 얘기를 했고 여기 그래프를 하나 더 그립니다.
batch에 따른 토큰당 비용 곡선과 최적점 1:06:48
cost, 토큰당 cost인 거예요. 근데 이거죠.
최승준 얘가 나누기로 들어갔네요.
노정석 그렇죠. 결국은 이게 이거를 전체 시간을 배치로 나눈 거니까 이게 얼마만큼 처리했냐, 단위 시간당 얼마만큼 처리했냐라는 거를 나타내거든요. 그러면 이것도 역시 B, x축은 그대로 놔두고 이 그래프의 y만 다시 바꾸는 거죠. 산수인데, 산수인데 이 내용을 잘 따라가야 돼요.
저 앞에서 t_compute는 그냥 linear하게 증가하는 그래프니까 여기서는 그냥 쭉 선을 댈 거고, 나눠버렸으니까요. 이게 이해가 안 되실 거예요.
처음 보시는 분들은 배치부터 T부터 latency부터 우리가 얘기하고 있는 term들이 머리에 안 들어오시는 분들도 굉장히 많으실 거라서 이걸 굳이 이해하지 않아도 된다. 중요한 건 우리는 결론만 떼도 되는 건데 결론을 떼기 위해서 승준님이랑 저랑 오랜만에 생각 토큰을 지금 돌려보기로 한 거니까
최승준 저희 공부한 거죠.
노정석 그러면 여기 지금 그리죠. t_compute는 여기 그냥 linear였으니까 여기에 있는 B 나누기 T니까 그냥 직선이 될 거고 직선이 되고, KV cache는 이거보다 기울기가 좀 낮은 linear 그래프니까 그 아래에 그냥 선이 될 거고 그리고 이 메모리는 왼쪽에서 그냥 직선이었으니까 이걸 B로 나누면 어떻게 돼요? 이 parabola가 되겠죠. 이런 식으로 쭉 해서 이런 함수가 되겠죠. 그렇죠.
그럼 여기서도 t_compute는 그냥 정해져 있고 t_memory가 사실 이 KV cache와 이거의 합이니까 그러면 여기서 계산을 하면 어떻게 되겠어요? 그냥 이 당연하겠지만 위에 한 줄이 더 생기겠죠. 위에 한 줄이 더 생기는 게 사실상은 이제 t_memory의 bound인 거고.
max로 계산해 보면 이 정해진 걸리는 시간은 T는 항상 compute bound와 이 memory bound에서 더 오래 걸리는 거에 제약된다. bound된다라는 게 원래 처음의 출발의 전제였으니까.
최승준 근데 이거 비슷한 거가 똑같지는 않지만 비슷한 거가 Jensen Huang 이번 GTC keynote에도 token economics 부분에서 나왔던 것 같아요. 비슷한 느낌으로.
노정석 다 똑같지 않을까요? 그래서 얘를 그냥 계산을 해보니 이렇게 되는 거죠. 어떻게? 이 토큰 가격은, 이게 가격이죠. 이제 그 세로축은 cost가 됐습니다. 토큰당 cost. 토큰당 cost는 배치가 낮으면 되게 비싸고 배치가 어느 정도가 되면 이 compute bound에 이제 얘 때문에 더 많아지는 거죠. 여기에 bound된다라는 거를 얘기하는 거죠.
그러면 이제 이게 결국은 이 다음 장으로 나가는 건데 이 지점을 어디로 놓냐에 따라서 optimum이 생긴다라는 얘기를 해 주죠. 저는 이 부분은 이 다음 얘기는 태어나서 처음 들었어요. 태어나서 처음 들었어요. 저렇게 계산하면 되겠구나라는 거는 우리가 계산과 생각을 해 본 적이 없다라는 사실을 저도 알게 됐고,
얘를 이해하고 나면 사실은 IDC 가격이, 하드웨어 가격을 저만큼 투입하고 제가 토큰당 얼마를 생성하는데 그 가격을 input token당 100만 토큰당 5불을 받고 그다음에 output token은 10불, 15불을 받고 이런 것들을 계산하면 그 프론티어 랩들의 inference farm의 어떤 경제성, 수율 이런 것들이 개선될 수 있겠다.
최승준 이분들이 reverse engineering 한 거잖아요, 일종의. 가격 가지고.
노정석 그렇죠. 그거 하는 것들에 대한 관점이 저도 이번에 처음 생겼습니다. 그래서 이 그래프를 그려준 거고요. 그래서 이 논의를 하면서 배치를 몇 개로 하는 게 최선인지 계산을 해보자라는 얘기를 합니다. 근데 이 계산이 정확하진 않아요. 거듭 얘기하지만. 이분들도 roofline analysis라고 그러거든요. 그냥 천장에 어렴풋한 선을 가지고 큰 생각 실험을 해보는 거지 정확한 계산은 아니라는 얘기를 중간중간 몇 번을 합니다. 왜냐면 이 다음 할 때 이 정확하지 않다라는 게 계산이 되는데.
최승준 저기 루트 씌운 부분도 사실 재밌긴 했는데.
노정석 sparse attention 부분인 거죠. 그 얘기는 이제 또 뒤에 가서 한 번만 하죠.
여기서 결국은 가정을 하는 거죠. 이게 결국은 균형이 되고 이 throughput을 maximize하는 지점은 computing하는 시간과 메모리하는 시간이 같아지면 그 두 개가 조화롭게 티키타카를 이룰 테니 그 지점으로 batch size를 maximize하면 되겠다. 이렇게 얘기를 하면서 간단한 수식 하나를 가져옵니다.
FLOPs 대역폭 비율과 sparsity로 추정한 최적 배치 1:12:07
얘 어디 갔냐, 여기서. 이 메모리 대역폭과 N_total은 이 t_mem에서 attention 부분 싹 떼내버리고 그냥 이것만 가져온 거예요. attention 부분이 사실 굉장히 중요하고 큰 부분인데 그냥 계산할 편의를 위해서 얘 떼버려요.
최승준 지금 뭔가 equal로 놨는데요. 등식으로.
노정석 그러니까요. 이건 t_compute이고 이게 t_mem이잖아요.
최승준 같은 시간이니까.
노정석 그렇죠. memory time에서 여기에 B 함수가 여기 들어 있는데 걔를 떼버리고 그냥 편의를 위해서 이 두 개를 동치로 놓습니다. 그러면 그냥
최승준 equation이 된 거죠.
노정석 산수가 나오는 거죠. 이 산수가 나오는 거죠. 이거 플러스 아래로 가고 이렇게 자리를 바꾼 거죠. B 값을 계산하기 위해서 그렇게 계산을 해버리고 나니까 사실상은 전체 로딩되는 이 파라미터의 숫자에서 activation되는 파라미터의 숫자의 비율이 나오고
최승준 이거 어디서 많이 들은 거잖아요. sparsity.
노정석 그렇죠. 저희가 DeepSeek 논문과 Kimi 논문 하면서 계속 얘기했던 sparsity 얘기인 거죠. 그리고 이제 sparsity에 대해서는 논문이 많아요. 그게 왜 되는지에 대해서는 저도 아직 이해는 못하겠는데 이게 넓히고 전체 파라미터의 크기를 키우고 sparsity를 늘려가지고 그냥 activate되는 파라미터를 소수로 만들더라도 성능상의 이득이 있다라는 게 지금 우리가 발견한 거잖아요.
최승준 heuristic 같은 거지만 뭔가 있겠죠. 아직 모르는
노정석 그렇죠. 그래서 여기서 사실상 방금 승준님 말씀하신 것처럼 오른쪽에 있는 항은 sparsity가 되는 거고 왼쪽에 있는 항이 이제 FLOPs / 메모리 대역폭인데 그렇죠. FLOPs도 사실은 하드웨어에서 다 정해지는 숫자고 메모리 대역폭도 그냥 다 정해지는
최승준 정해져 있는 숫자죠.
노정석 근데 확실한 거는 H100, H200, GB200, GB300, Rubin 이렇게 가면서 모든 숫자는 다 좋아져요. FLOPs도 좋아지고 HBM 용량도 커지고 그리고 HBM의 대역폭도 커져요. 근데 이게 재밌게도 이 숫자가 맞는지 안 맞는지는 모르지만 이 사람들도 그냥 guesstimation을 하는데 FLOPs / 메모리 대역폭의 크기는 하드웨어가 계속 발전함에도 불구하고 FP4를 가정했을 때 약 300의 배율을 유지하고 있다. 여기서 300이라는 숫자가 나온 거죠.
최승준 그게 매직 넘버 같은 느낌이긴 한데 어쨌든 300이라고.
노정석 맞아요. 그러면 이게 B 계산이 그냥 되는 거죠. 배치 계산이.
최승준 그래서 얼마가.
노정석 B는 저 300이라는 숫자와 sparsity를 곱한 거. 엄밀하게 얘기하면 sparsity로 나눈 숫자여야 되는 거죠. sparsity는 분수니까, 예를 들어 최신 sparsity가 막 8분의 1에서 12분의 1 되니까 예를 들어 8분의 1이다. 계산해 보면, 배치가 8 곱하기 300, 2400.
최승준 이게 아마 DeepSeek V3 예로 하지 않았어요?
노정석 네, V3로 했습니다.
최승준 그래서 2400이다. 그 8이니까.
노정석 아마 저희가 올해 중반을 넘어가고 내년 초반이 되면 사실은 그냥 MoE 관련한 이런 guesstimation이 아니라 sparse attention까지 계산된 것들을 논의하고 있겠죠. 그렇죠.
근데 사실은 저는 DeepSeek V4가 저는 DeepSeek V4를 지금 메인 모델로 쓰고 있거든요.
물론 Codex 돌릴 때는 GPT-5.5 쓰는데 제가 그냥 일반 업무를 하고 제 Emacs에서 부르는 모델은 DeepSeek V4를 붙여서 한번 쓰고 있거든요.
좋아요.
이게 Claude Opus급이다. 그 급이다라고 말은 못 하지만 확실한 건 Claude Sonnet보다는 좋아요. 확실히.
최승준 그래요? API로 쓰시는 거예요?
노정석 API를 쓰죠. AI API 요금이 어마어마하게 쌉니다. DeepSeek이. 지금 또 출시 기념 할인까지 하고 있어서 더 싼데 제가 2불 걸어놨는데 2불 다 쓰기도 힘들어요. 이 코딩 워크로드를 돌리지 않는 한. 제가 그냥 제 거 막 티키타카해가지고 제 거 Emacs Roam Notes에서 돌리는 걸로는 지금 1불도 다 못 썼어요. 솔직히.
그래서 여기서 보면, 다시 메인으로 돌아오면 저 배치를 몇 개로 할까라고 하는 부분에 사실 오늘의 핵심적인 내용들이 다 들어있는 건데 sparsity를 높이면 배치를 높게 쓸 수 있다. 배치를 높게 쓸 수 있다는 얘기는 뭐냐. 한 사이클당 서빙할 수 있는 유저의 숫자를 훨씬 늘릴 수 있다는.
그 얘기는 뭐냐. 그럼 어차피 GPU를 사서 NVIDIA한테 준 돈과 단위 시간당 들어가는 전기세는 고정이니 결국은 그냥 프론티어 랩 입장에서는 얘가 단위 시간당 더 많은 유저를 서빙하는 게 무조건 이익이라는 얘기거든요.
최승준 거꾸로 말하면 그만큼의 유저를 못 모으는 회사는 불리한 거네요.
노정석 그렇죠. 그러니까 트래픽이 다 놀고 있는 거죠. 감가상각 계속 때려 맞으면서 사실상 못 도는 거니까 그런 계산들을 하죠. B에서 sparsity 계산을 하고 그 이야기를 한참 하고 광고 들어가죠.
최승준 광고도 재밌게 하긴 했어요.
노정석 예. 이 광고하는 회사가 Jane Street이라는 회사인데 그거거든요. quant 회사거든요. 그냥 알고리즘으로 돈 버는 회사인데 돈 잘 벌죠.
그리고 나서 그다음 이야기로 넘어가는 게 기차 얘기 좀 전에 기차 얘기였죠. 기차 얘기, 이 얘기를 하죠. inference를 할 때 한 번의 연산 사이클, 이 클럭이 왜 그렇게 정해졌는지는 모르는데 얘가 20밀리세컨드 정도 된다고 얘기해요.
20ms 연산 열차와 drain time 직관 1:17:56
이게 한 배치를 채워서 그 배치를 연산을 시켜가지고 그러면 저 위에 prefill이면 LM head가 없을 거고 decode한 거면 LM head가 있을 거고 해가지고 값들이 나올 거잖아요. 이 앞에 승강장에서 토큰들이 탔으면 걔가 한 번 쫙 다 연산을 하고 저 위에 승강장에서 내리는데 그때까지 걸리는 시간이 한 20ms가 되도록 조정한다고 얘기를 하고 있거든요.
최승준 tensor 계산만 하는 게 아니라 여러 가지 합쳐서 20ms인 거죠.
노정석 네, 근데 그 20ms의 바운드를 결정하는 굉장히 중요한 변수가 얘가 지금 여기 썼는데 메모리 용량을 이 대역폭으로 나눈 값이거든요. 그러면 그 용량.
최승준 헷갈리는 게 계산이 아니라 배치만 지금 이거 생각하는 거였나요? 배치를 포함한 건가요?
노정석 배치와 계산을 다 포함한 거죠. 왜냐하면 메모리 로딩과 compute는 항상 동시에 도니까. 그 메모리 compute보다는 메모리가 느린 게 확실하기 때문에, 여기서 아래 써 있잖아요. 300의 차이가 있잖아요. FLOPs가 훨씬 빠르고 메모리 왔다 갔다 하는 건 느리거든요. 그래서 그 비율이 300 정도로 유지가 되고 있다는 얘기를 한 거니 그래서 얘는 한 번에 연산이 일어나는 그 사이클을 뭘 기준으로 짜면 좋냐라는 거에서 이 아저씨도 guesstimation을 엄청 많이 써요.
최승준 guess + estimation.
노정석 맞아요. 그래서 이 drain time이라는 용어를 가져옵니다. 이 drain time이 HBM 메모리가 288GB인데 GB300 기준으로 걔 대역폭이 이제 20TB/s이니까
최승준 바이트죠. 비트 아니고.
노정석 바이트요. 나눠보니 저게 그럼 이제 위가 용량이니까
최승준 B가 날아가네.
노정석 예, 그러면 분자로 second만 나올 거잖아요. 그 second가 20밀리세컨드다. 최신 GPU들은 15, 다음에 옛날 것들은 40인데 그 비율 때문에 대략 20에서 30밀리세컨드 정도가 이게 유지가 된다.
최승준 300에서 20 나누면 10, 어쨌든.
노정석 300에서 20 나눈 거니까 저게 15가 돼야 맞죠?
최승준 그렇죠.
노정석 근데 이제 하여튼
최승준 왔다 갔다 한다는.
노정석 퉁 쳐서 20에서 30밀리세컨드 정도가 이 HBM이 전체 메모리를 한 번 다 읽어내는 시간이다. 그러니까 그게 20ms이니 20ms를 기준으로 한 사이클을 짜면 되겠다라는 걸 만든 거죠.
최승준 그 안에 weight도 끌어와야 되고 배치도 만들어서 채워 넣어야 되고.
노정석 네, 그래서 사실상 저희가 항상 training 쪽에만 관심이 많아서 inference 쪽에서 이 하드웨어와 어떤 식으로 조합이 일어나는지에 대해서는 사실 저도 최근까지 이걸 생각해 본 적이 없다는 걸 알게 됐어요. 생각해본 적이 없어요. 그냥 Jensen Huang이 FP4가 어떻게 됐고 뭐가 됐고 그러면 내가 Claude Code 200불이면 얼마 쓸 수 있냐까지만 생각이 나지, 이게 어떤 식으로 발전하고 있는지에 대해서는 전혀 계산을 안 해 봤는데 이번에 이거 하면서 저도 빡세게 한번 계산을 다 해 본 케이스가 됐네요.
최승준 이 편을 보고 나서 이 전 편인 Jensen Huang 편을 보면 또 다를 것 같아요.
노정석 맞아요. 그래서 결국 이 얘기의 핵심으로 넘어가는 건데 그래서 최근의 어떤, 여기서 Reiner Pope와 Dwarkesh가 얘기는 하고 있진 않지만 그러고 나서 제가 ChatGPT와 Claude한테 이 내용들을 주면서 저한테 이것저것들을 가르치게 하면서 최신 serving 아키텍처 vLLM과 SGLang이나 이런 데들이 안에서 도대체 뭘 하고 있는지에 대한 것들을 여기에 맞춰서 AI가 저를 한번 싹 가르쳐 줬거든요. 놀라웠어요.
vLLM SGLang의 핵심 목표 배치 채우기와 chunked prefill 1:22:04
근데 핵심만 놓고 보면 결국은 20ms에 한 번씩 어떤 연산을 수행하는데 그 연산에 얼마만큼의 배치를 채워 넣는 게 좋을까라고 하는 거는 여기서 한 2400에서 한 3000. 심하게 요약을 하면 결국은 20ms에 한 번씩 출발하는 연산 열차에 배치의 최적치는 얼마다라고 얘기를 해 주는데 저 배치를 어떻게 놓치지 않고 꽉꽉 채워서 보낼 것이냐.
그럼 유저들이 막 몇만 명, 몇천 명씩이 동시에 접속을 하고 그들이 Claude에 거는 워크로드는 정말 다양하잖아요. 누구는 Claude Code를 갖고 오고 누구는 안녕하세요 가져오고 누구는 뭐 가져오고. 이렇게 해서 굉장히 다양한 워크로드가 오는데 걔를 어떤 식으로 orchestration을 해야 이 각각의 rack에 있는 열차들이 매일 20밀리세컨드 토큰을 꽉꽉 채운 상태로 돌 수 있냐라는 거죠.
그리고 그걸 가능하도록 만들어지는 그런 알고리즘적인 개선이 vLLM이나 그 어디죠? SGLang이나 이런 데 굉장히 많이 있어요. 배치별로 KV cache가 다 달라지는 부분들은 어떻게 PagedAttention으로 메모리 용량은 줄이면서 각각의 토큰들이 holding하고 있는 KV cache 포인터들을 효율적으로 가져다줘서 한 번에 연산할 것인가라는 부분도 돼 있고
그다음에 decode 과정에서는 사실 input이 하나씩만 들어오는데 prefill 과정에서는 굉장히 여러 개가 들어오잖아요. 근데 그 prefill과 decode를 하나의 워크로드에서 어떻게 동시에 처리할 것이냐.
그럼 prefill이 굉장히 길어지면 사실은 하나짜리 decode하는 애들이 거기에 밀려날 가능성이 있기 때문에 prefill도 5만짜리 토큰이 들어오더라도 걔를 굉장히 잘게 쪼개서 여기저기 넣더라고요. 그렇게 넣어서 그걸 이제 chunked prefill이라고 부르던데 그런 식으로.
최승준 그런데 여기서 말하는 2400이 유저가 2400이라는 건 아니에요. 유저는 훨씬 더 많아야 되는 거잖아요.
노정석 아니죠, 아니죠. 아니에요. 배치가 2400이라고 하면요. 엄밀하게 얘기하면 한 유저가 만약 decode 단계에서 사실 그 정확한 숫자는 하드웨어 그런 거에 따라서 다르겠지만 예를 들어 메모리 상황이나 이런 거에 따라서 전부 달라지겠지만, 2400 배치인데 그게 모두가 다 decode다라고 하면 그냥 2400바이트예요.
최승준 그러면 그 비싼 거를 2400명이 동접해서 쓴다는 거는 근데 이제 train마다니까.
노정석 그렇죠. train마다 한 사이클마다 2400명씩이 탄다는 거고 근데 만약에 2400바이트로 그냥 그 length는 정해놔요. 그래야 이 모든 것들을 거기에 대해서 optimize할 수 있는 거니까 그래서 그런 식으로 computation을 규격화시켜서 optimize를 할 수 있는 거고
근데 반면에, 반면에 KV cache 같은 경우에는 유저마다 너무 상황이 다르거든요. 누구는 짧고 누구는 길고 이런 상황 때문에 어느 정도의 워크로드가 이상이 되면 사실은 memory bound인 거죠.
KV cache 때문에 다 compute bound가 아닌 memory bound 문제로 전환될 수 있는 거죠.
최승준 그러니까 지금 앞단에서 푼 거는 compute bound 되는 거에 대한 수식이었던 거군요. 300 곱하기 sparsity.
노정석 네, 근데 여기에 보면, 여기에 보이는데 조금만 더 설명을 하면서 넘어가 보면 이야기가 중간중간에 좀 뛰긴 했는데 그 vLLM이랑 SGLang이랑 이런 것들이 얘를 optimize하기 위해서 정말 극악의 consideration들이 되어 있다는 얘기를 제가 드리고 싶었던 거고
그리고 프론티어 랩들의 진짜 어떤 그들의 자산, moat라고 볼 수 있는 것들은 이런 엔지니어링 인프라 능력인 것 같아요. 이 엔지니어링 인프라 능력이 가장 핵심이 되어 가는 것 같아요.
어떻게 하드웨어를 잘 이해하고 사용자의 워크로드를 잘해서 이 serving throughput을 늘릴 수 있느냐라는 거는 이거는 굉장히 중요한 기술이다. 그리고 이것들을 이제 밖에 다 공유하지 않고 있죠.
이 워크로드별로 어떤 워크로드는 사실은 ‘안녕하세요.’ ‘뭐 해요?’ 해서 굉장히 짧은 context length들이 막 떨어지는 그런 워크로드가 있을 수 있고
그런데 그런 것들은 유저 숫자를 늘려 받을 수가 있는 거고
최승준 그러면 싸져야죠.
노정석 근데 만약에 어떤 청크를 나눈다고 하더라도 context length가 길어지는 워크로드, 코딩이나 이런 것들을 보면 사실 막 1,000k에서 몇만 k 정도까지는 그냥 나오잖아요.
그런 것들은 어떤 유저들을 태우는 것들이 그러니까 유저들의 숫자가 좀 줄어들겠죠. 왜냐하면 단위 랙당 computation과 메모리가 한정돼 있다고 할 때 input이 짧은 유저들은 유저를 더 많이 받을 수 있고 input이 긴 유저들은 유저를 적게 받아야 되고, 이런 것들은 다 이미 정해지는 거니까. 그렇죠.
200K 컨텍스트 임계점과 가격 티어의 경제학 1:28:06
근데 long-context가 됐을 때 사실 이 그래프에서 얘기하는 거를 심하게 요약해 보면 compute와 KV cache가 균형을 이루는 그런 지점이 있잖아요. 근데 그 지점을 넘어서고 나면 사실 이 그래프에서 보이죠. computation이 남아도는 시점이 되는 거죠.
computation은 아무리 빨라지더라도 메모리가 거기에 따라가지 못하기 때문에 전반적인 속도가 다 memory-bound로 떨어지는 그런 시점이 생기는데, KV cache의 길이 때문에 그게 이분들이 추정하건대 그 optimal point가 200k 정도 되는 것 같다.
최승준 그래서 가격을 그렇게 정했다는 거에서 역산한 거잖아요. 사실.
노정석 그렇죠. 그래서 200k 아래에 있는 것들은 다 같은 워크로드에서 처리해도 그게 큰 차질은 안 줄 정도로 optimize가 돼 있는데, 200k가 넘어가면 그걸 처리하기 위해서 유저 숫자를 현저하게 적게 받아야 하는 그런 GPU 클러스터가 있는 거죠. 그리고 많은 코딩 워크로드나 이런 것들이 그쪽으로 배치되고 있을 가능성이 있고, 거기는 사실 제공자 입장에서는 좀 비싸게 받아야 되는 그런 영역인 거죠.
최승준 그러니까 이건 경제성의 원리네요.
노정석 이런 것들을 가지고 역산을 주룩주룩 해보면 Google에서도 우리가 초당 몇 토큰을 처리하고 있다는 거 가끔 컨퍼런스에서 발표하잖아요. 그럼 발표하는 것들을 계산해 보고 역산해 보면, 아, 랙 1대가 전체 토큰 처리하는 거에 약 1,000분의 1이 랙 1대, 그러니까 결국 랙이 1,000대쯤 있을 거다라는 추정도 해볼 수 있는 거다.
최승준 맞아요. 그리고 이 두 분이 얘기하는 것 중에 그런 얘기가 있었는데, 결국에는 가격을 비용 근처에서 선정하고, 왜냐하면 경쟁 상황이다 보니까, 그것 때문에 역산이 가능하다, 그런 뉘앙스를 얘기했던 것 같아요. 그런 프론티어 랩들이 의도치 않게 지금 정보를 주고 있었다.
노정석 그러니까 그들이 API 가격으로 내세우는 그런 것들을 보면 걔네들이 내부적으로 가지고 있는 일종의 token economics, 그게 어떤 식으로 구성되어 있다는 거를 보여준다고 얘기하죠.
캐시 계층과 TTL에 따른 비용 구조 1:30:32
그리고 그 cache의 가격 얘기를 하면서 저희가 뭔가 이렇게 생각하면 좋을 것 같은데, 제가 Claude Code로 작업을 하고 있어요. 그럼 그 작업을 계속하고 있을 때는 사실상 KV cache가 어떤 기계의 HBM에 올라가 있을 거잖아요. 그러면 내가 하는 작업들은 계속 그 기계로 보내는 게 무조건 유리하잖아요. 근데 제가 잠깐 물 마시러 온 사이에도 얘가 1분 내에 올지, 30초 내에 올지, 10분 내에 올지 사실 그 AI는, 그 GPU 팜은 알 수가 없는 상황이고, 그러니 어떠한 기간 동안 예를 들어 1분은 HBM에서 그걸 잡고 있는 거죠. 메모리에서 그냥 기다리는 게 얘를 없애고 다른 유저의 워크로드를 받아버리는 것보다는 더 이익인 상황이 있으니까, 그게 cache 전략인데 그래서 HBM에 있으면 바로 hit가 되는 거고.
근데 제가 한 10분 놀다 왔어요. 그러면 얘를 10분 동안 HBM에 잡고 있는 거는 또 그들에게 손해니까 내려버리는 거고, 내려버리는 단계가 CPU 옆에 있는 DRAM으로 내리는 거, 한 1단계. 다음 flash drive에 올리는 게 2단계. 아니면 진짜 전통적인 HDD에 내려버리는 게 4단계. 이런 식으로 하고, 그마저도 다 시간이 expire돼 버리고 나면 싹 없애버리고. 그런 식으로 해서 cache 가격들이 쭉 다 달라지는 형태도 사실 이런 dynamics에 있는 거고.
저희가 2년밖에 안 됐잖아요. 이게 AI 신기하다 뭐 하다라고 하더라도 Claude Code를 본격적으로 쓰기 전까지는 저는 다 애들 장난이었다고 생각하거든요. 그냥 ChatGPT에다 넣고 뭐 넣고 하는 것들을 보면 워크로드가 그렇게 높지가 않은데, 사실 Claude Code 나오고 Codex 나오고 하면서 이 애들이 쓰는 inference 양이 정말 어마어마해졌잖아요. 그리고 생각 token도 엄청 돌리고, thought token, reasoning token도 엄청 돌리고, 그다음에 중간에 tool call 한 번 갔다 오면 tool call이 읽어오는 정보도 전부 다 prefill해야 되는 데이터고, 그래서 context를 어떻게 manage하느냐가 가장 핵심적인 bottleneck이 돼버리고, 그것들이 가장 큰 기술 발전에 있어서 가장 중요한 요소가 돼버렸다는 생각이 들고요.
모델 training하는 거랑 별 상관이 없는 완전히 inference와 serving의 infrastructure 기술이거든요. 이 부분은 우리가 많이 인지하고 있지 못하지만 사실 굉장히 많은 중요한 핵심이 들어가 있는 부분이다 라고 생각할 수 있을 것 같아요.
Dwarkesh 학습법 flashcard와 복습 루틴 1:33:22
그래서 저희가 사실 이 2시간 강연 중에 앞에 30분 본 거거든요. 30분 본 얘기를 이렇게 길게 했는데, 뒤에가 사실은 여기에 대한 이해를 가지고 더 재미난 내용들이 쭉 있는데, 한번 그거는 숙제로 남겨 드리겠습니다.
최승준 그래서 Dwarkesh가 참 대단한 것 같습니다.
노정석 맞아요. 이 사람만 할 수 있는 콘텐츠예요. 솔직히. 그러면 한번 승준님.
최승준 Dwarkesh가 이거를 준비하는 과정이 또 재미있었어요. 그래서 Dwarkesh가 자기가 이거를 어떻게 공부했는지를 flashcard를 만들어서 한 거를 제가 번역을 Codex 시켜서 해봤습니다. 그래서 원래 있던 거에 한국어 버전을 한 거거든요.
이게 자기가 맞춰보려고 이런 것들을 문제를 스스로 내고서는 알고 있나 모르나 그런 걸 확인하나 봐요. 이거 저희 다뤘었죠.
한 번의 forward pass 한 번의 시간의 방정식은 무엇인가. 그리고 t_compute의 방정식은 무엇인가. 정석님이 열심히 설명해 주셨는데 암기하고 있지는 않습니다. 저도. 근데 뭐 들어갔었죠? 뭐 들어갔었죠? 이거, 이거 active plus요.
노정석 네, 배치 곱하기 active.
최승준 이거를 그러니까 Dwarkesh도 제일 중요한 거로 맨 위에 3개로 꼽은 거죠. t_mem, 여기는 조금 더 길어졌었죠. sequence length 있고, 그렇죠. 이거. 그다음에 latency의 선을 그려보라. 이게 시간을 많이 들여서 얘기했었죠, 이거.
노정석 그럴 수 있는 거죠.
최승준 weight fetch lower bound, 이게 어디서 오나. lower bound 얘기했었죠? 뭐였죠?
노정석 loading하는 time이 lower bound.
최승준 메모리. 메모리 때문에. 하여튼 이런 식으로 자기도 계속 공부를 했던 거예요. 그래서 저는 여기에다가 하나 더 붙여가지고 이 내용이 강의 어느 부분에 있는지 이런 거를 만들어 놓긴 했습니다.
노정석 좋네요. 참 이런 원하는 것들이 Dwarkesh도 이걸 딸깍으로 만들었는데, 그렇죠. 승준님은 그걸 또 가져와서 이거 하는 걸 또 딸깍했고. 딸깍딸깍, 정말 좋은 세상에 살고 있습니다.
최승준 문제는 그런데 저희가 계속 이거를 오늘 서로 대화를 나누면서 이렇게 되새김질을 했잖아요. 알고 있는 것들을 얘기해 보고. 이게 없으면 사실 금방 날아가는 거긴 해요. 이거 만들었다고 내 거가 되는 건 아니잖아요. 오늘 저희가 간만에 좀 머리에 열 나는, 생각 토큰이 많이 쓰이는 세션이었어요. 항상 뭐가 어떻다 저떻다라고 하면서 instruct model 형태로 항상 했었는데, 간만에 진하게 생각 토큰을 많이 쓰는 그런 세션이었습니다. 후반부에 이런 내용도 사실 재미있어요. 중반부였나.
노정석 중반부에 training에서.
최승준 중반부, 이런 것들이 6이 왜 나왔나, 이런 것들도 재미있고 그랬는데 하여튼 저희가 다 다룰 수는 없기 때문에 이 정도 소개해 드리겠습니다.
노정석 맞아요. 사실 중요한 내용이 앞에서 너무 다 써버려서 뒤에 있는 내용들은 여러분들이 Dwarkesh를 직접 따라가면서 한 번씩 해보시면 더 재미있는 내용들 몇 개 있습니다.
최승준 전시 소개 상상캠퍼스 체험형 작업 1:36:39
최승준 저도 정말 마무리로 광고 하나를 하겠습니다. 어린이날 즈음인데요. 어린이 전시 하나를 오래간만에 해서, 여기 경기도에 있는 상상캠퍼스, 수원 쪽에 있는 곳에서 체험 전시에 참여를 하고 있거든요.
노정석 승준님이 참여하고 계세요.
최승준 그래서 제가 끝부분에 코스로 참여하고 있는데 이런 거를 만들어 봤습니다. 그래서 손으로 건드리고.
물론 이것도 AI들의 힘을 빌어서 만든 건데, 이렇게 손을 뻗쳐가지고 행성이라든가 항성 같은 것들을 조금 다뤄볼 수 있게 하는.
그래서 이렇게 해서 다시 건드리면 됐다가 저걸 조작할 수 있거든요.
그리고서는 여기 이 정도를 한번 보겠습니다 하고 주먹을 쥐고 기다리면 다시 새로운 항성계가 만들어지는 그런 거를 만들어 봤었는데요.
그런 거를 해봤다 정도 광고 한번 드리고, 오늘 긴 시간 제가 이렇게 마무리하면 좀 안 될 것 같은데 어떻게 마무리를 해야 될까요?
노정석 승준님이 만든 작품인 거죠, 저게?
최승준 그렇죠, 전시가.
노정석 승준님의 본업이 또 미디어 아티스트이시기 때문에 이런 것들을 하셨고, 지금 전시 중에 있으니 관심 있으신 분들은 한번 방문해 보시면 좋을 것 같습니다.
최승준 그래서 긴 시간 오늘.
노정석 내용이 정말 어렵고 힘들고, 저희도 머리에 열이 나고. 이 Dwarkesh 팟캐스트가 참 배울 게 많아요. 그리고 이 친구가 항상 어떻게 더 지식의 frontier를 더 전진시켜야 하는지, 그리고 그거를 좀 쉽게 이야기해서 대중에게 전달해야 하는지 무언가 명확하게 포지션을 잡은 것 같아요.
Dwarkesh의 학습 태도와 에피소드 마무리 1:38:11
최승준 그래서 오늘 긴 시간 탐구의 과정이었는데요.
Dwarkesh가 최근에 NYT에 또 기사로 등장을 했더라고요.
근데 보면 굉장히 열심히 공부를 해요. 인터뷰이 한 명 만나면 2주 정도를 공부한대요.
그거를 제가 번역을 해 놨는데, 어떻게 Dwarkesh가 이런 인기가 있고 사람들이 기대를 하는 이유가 다른 누구도 못할 만한 질문을 해내기 때문에 그렇다고 하는데요.
그래서 그런 Dwarkesh가 공부하는 방법 같은 것들에서도 오늘의 맥락에서 하나 층위가 더 있다고 하면 이런 걸 어떻게 파고들었을까, Dwarkesh가 이런 걸 어떻게 공부해냈을까 하는 것도 살펴보시는 포인트가 되지 않을까 해서 그거를 마무리로.
노정석 덕분에 저희도 휴일에 머리에 땀나게 공부를 한번 해봤고 정말 많은 것들을 알게 된 소중한 계기가 됐습니다.
최승준 수고하셨습니다.
노정석 오늘 고생하셨습니다.
최승준 휴일에 놀지 않고 일했다 정도.
노정석 그럼 또 남은 휴일 푹 쉬시기 바랍니다.
최승준 수고하세요.