EP 99
Opus 4.8 출시, 요즘 AI 경쟁과 인간의 일
Google I/O와 Opus 4.8 이후의 AI 흐름 00:00
노정석 녹화를 하고 있는 오늘은 2026년 5월 30일, 토요일 아침입니다. 저희가 몇 주 공부를 하고 돌아왔는데 그 사이에 Google I/O가 있었고, 또 새로운 버전의 Opus가 발표됐고, 세상에 또 한 번 진보했습니다. 그래서 이것과 관련해서 승준님과 함께 어떤 일들이 있었는지, 그것들의 함의는 무엇인지 오랜만에 찬찬히 보도록 하겠습니다.
Opus 4.8의 43일 출시 주기와 빨라지는 모델 교체 00:27

최승준 며칠 전이었죠. 이틀 전이었나, 어제 새벽이었나요? 어쨌든 Opus 4.8이 기습적으로 또 나왔습니다. 아직 저는 사용도 못 해 봤는데요. 그래도 타임라인에서 정황을 좀 살펴보긴 했는데, 그 얘기로 한번 시작해 보도록 하겠습니다. 그래서 지금 블로그 포스팅이 있고, 날짜를 좀 체크해 봤어요. 제가 제목을 두 달 이하 리듬이라고 적어봤는데, Opus 4.7이 나온 게 4월 16일이거든요. 그러니까 지금 딱 한 달 반 정도 된 거죠. 그래서 Opus 4.7 나왔을 때 저희가 19일에 아마 녹화를 했었는데, 그때는 이런 식으로 최근에 Opus 나온 게 얼추 70일 간격이었다는 거였어요. 그러면 두 달 조금 넘는 간격이었죠. 그런데 지금은 43일 만에 나온 셈이거든요.
노정석 그렇죠. 두 달에 한 사이클 정도를 돌 거라고 예상을 했었는데, 더 짧아지고 있네요.
최승준 두 달이 그냥 나오는 얘기가 아니라 여기저기서 나오는 얘기예요. 그래서 Reiner Pope-Dwarkesh 편 했을 때 Dwarkesh가 flashcard 등의 문제를 푸는 거에서 (요즘 모델들이) 이 Chinchilla optimal의 100배 정도 over-trained된 것 같다, 그런 얘기를 해서 괜히 두 달이라는 표현을 하거든요. 그래서 frontier model이 두 달 동안 deploy됐으면 그게 두 달마다 retire 된다는 패턴이 있었다는 걸 Dwarkesh도 그 전제를 하는 건데, 그랬을 때 몇 token으로 학습이 됐을까를 아주 엉성하다고 해야 될까, 하여튼 성글게 성글게 추정한 건데, 어쨌든 거기서 두 달이라는 표현이 나옵니다. 그러니까 두 달마다 모델이 새로 나오고 retire하고 하는 그런 패턴들이 있다는 거죠.
그리고 이것도 국내 뉴스로 옮겨진 내용인데, Sam Altman이 호주의 행사에서 화상 대담할 때 두 달 만에 세상 바뀌는데 회사 연간 계획 필요할까라는 자극적인 문구를 뽑아 놓았지만, 어쨌든 Sam Altman이 그런 뉘앙스의 얘기를 했나 봅니다. 그래서 이게 두 달이 2026년의 어떤 패턴이라고 생각을 했었거든요. 그런데 43일이 나와서 저도 좀 어 했었습니다.
싱귤래리티를 향한 개발 속도 가속 02:43
노정석 그런데 이거는 저희가 싱귤래리티라는 표현을 할 때 항상 예상을 했던 거잖아요.
최승준 이 주기가 계속 짧아지고.
노정석 발전 속도는 계속 증가하기 시작해서 어느 시점이 되면 이게 무한히 증가하는 그 시점이 된다. 그리고 그 지점이 싱귤래리티라고 얘기를 하는데, 그 지점을 향해 가고 있는 거죠.
Anthropic의 Opus 효율화와 Mythos급 모델 예고 03:05
최승준 Anthropic 블로그에서 저는 벤치마크나 이런 걸 보기보다는 맨 끝의 얘기가 좀 인상에 남았는데, 한번 읽어볼게요. 사용자들은 Opus 4.8이 이전 모델 대비 작지만 분명히 체감할 수 있는 개선을 이루었다고 느낄 것입니다. 아직 해야 할 일이 남아 있습니다. 우리는 Opus와 동일한 역량을 다수 제공하면서도 더 낮은 비용으로 사용할 수 있는 모델을 개발하고 출시하기 위해 노력하고 있습니다.
그리고 더 높은 지능을 갖춘 새로운 계열의 모델을 출시할 계획입니다. 그래서 Mythos Preview를 일부 소수의 조직이 사용하고 있는데, 안전장치가 준비되면 공개할 거라고 했었죠. 그런데 그 안전장치 준비하는 게 빠르게 진전을 이루고 있어서 앞으로 몇 주 안에 Mythos급 모델을 모든 고객에게 제공할 수 있을 것이라고 기대하고 있습니다. 그래서 앞으로 몇 주가 10주 이하겠죠. 10이라는 것 이하일 거라고 생각하게 되는데, 그러면 최대 두 달, 그렇죠?
노정석 뭔가 이 모델 range를, 체급을 좀 조정하고 있는 느낌이네요. 이제 Mythos가 새로운 Opus가 되고, Opus가 Sonnet이 되고, 사실 지금 Sonnet, Haiku는 몇 개의 정말 embedding 모델스러운 이 단위 task 말고는 유명무실하잖아요. 사람들 다 Claude Code 할 때도 Opus 붙여서 쓰고 있고요.
최승준 그래서 어쨌든 Opus가 이름이 어떻게 바뀔지는 예측하기 어렵지만, 더 높은 체급의 모델들이 나올 예정이고, 그게 아마도 여름에 걸쳐 있는, 여름에서 초가을 그런데 지금의 패턴을 봤을 때는 이 정도일까. 저는 6월이나 7월에 뭔가 Opus 4.8 정도 나올 거였는데 5월 말에 나왔단 말이죠. 그러니까 이것도 당겨서 추정한다고 하면 7월 정도에 무슨 일이 있지 않을까라는 생각을 하게 됩니다. 7월 또는 8월. 그래서 그러면 또 새롭게 unlearning하고 배워야 되는 것들이 있을 것 같은데, 아직 시작도 못 했습니다.
Gemini 3.5 Flash와 여름 모델 경쟁의 조짐 05:12

그런데 저희가 그냥 큰 이벤트일 거라고 기대하다가 결국에 뚜껑을 열어봤을 때는 언급하지 않고 있었던 Google I/O가 또 있었단 말이죠. Google I/O에서 Gemini 3.5 Flash가 주인공이었잖아요. 그러니까 Pro는 준비되지 않았습니다. 그런데 키노트의 얘기를 들어보면 계속 그 얘기를 하는 거예요. 몇 주 후에는 우리가 다음 것을 공개할 수 있을 것이다. 여름 즈음이 될 것 같다, 그런 이야기들을 좀 했었거든요. 그래서 이게 시기가 맞아떨어지고 있는, 지금 방향성이 여름에 뭔가 Google도 지금 상황에서 물론 전사적으로, 전방위적으로 이걸 방어해내고는 있긴 하지만 한 방이 크게는 없었던 느낌이었는데, 그것들을, 그게 뭐가 될지 몰라도 준비하고 있고, 그다음에 Anthropic은 지금 선제적으로 나오고 있고, 그런데 여전히 성능에 대한 이야기는 타임라인에서는 GPT-5.5를 얘기하고 있거든요. Codex를 얘기하고 있고, 그래서 GPT-5.6이 나오는 타이밍은 Opus 4.8이 GPT-5.5를 꺾지 못하는 느낌일 때는 안 나오다가 얼추 이렇게 얘기가 나올 때는 나오겠죠.
토큰 경제와 지연시간 중심의 모델 선택 06:26
노정석 아마도. 그런데 Anthropic도 앞에 작아진 모델이라는 표현을 썼잖아요. Opus 4.8이 확실히 Opus 4.7이나 Opus 4.6 대비 좀 작고 효율화됐는데 성능은 유지한 그런 형태의 모델이라는 걸 얘기하고 있고, 또 밖에서 보이는 벤치마크들이나 사람들의 반응도 Opus 4.8 성능이 떨어진 것 같다는 얘기는.
최승준 그렇죠. 몇 개 하긴 하더라고요. 벤치마크 지표는 실제로 Opus 4.7 대비 떨어진 것들이 있긴 하더라고요. 늘어난 것도 있고요. 그래서 이게 결국은 이 token economics에서 살아남기 위한 처절한 몸부림 아니겠습니까?
노정석 계속 변화하는 시기니까요. 이게 예전에 자동차 때도 그랬는데, 자동차들이 배기량 경쟁을 하던 때가 있었거든요. 그래서 4,000cc, 5,000cc, 6,000cc 막 나오다가 어느 정도 효율화를 이루고 난 다음에는 상업적인 운용에서는 이 정도면 충분하다고 해서 이렇게 좀 flat하게 된 시기가 있었는데, 모델도 그러지 않을까 싶어요.
사실 저희 요새 대부분의 업무라고 하면 Codex나 Claude Code 혹은 그걸로 이루어진 agent system과 interaction하는 게 이제 회사 업무가 되어가고 있다고 느끼거든요. 거의 대부분의 사람들도 이제 이메일과 PowerPoint와 Excel이 떠 있었다면, 이제는 화면에 거의 agent application들이 떠 있거든요. 저희 회사는 아예 그런 쪽으로 거의 다 바꿔놔서 사람들이 아예 Slack에 붙어서 agent와 일하는 것만으로 일들이 끝나게 그렇게 좀 만들어 가고 있는 중인데, 그런데 아쉬움이 느껴지는 부분들이 latency예요.
이 이야기가 나올 것 같거든요. 왜냐하면 뭔가 만족스러운 결과가 나오고 나면 그다음에 원하는 건 당연히 그게 빨리 나와야 돼요. 그리고 그 latency가 정해진 품질 안에 나온다면, 그게 Opus든 뭐든 최고급 모델이 아니라 그냥 빠르고 좋은 모델이라는 어떤 개념이 생길 것 같습니다. 그게 Google에서는 이 Flash 모델을 메인으로 이번에 선보인 이유.
최승준 그런 것들을 계속 건드리는 느낌이에요. 그런데 사람들이 정작 그 성능이 안 나오면 바로 윗 tier로 가고, 그런 것들이 탐색 중인 요즘인 것 같은데, Gemini 3.5 Flash에 관련해서는 저는 이 영상 하나가 제일 인상에 남았어요. Varun Mohan이 보여줬던 거거든요.
Gemini Flash의 Doom 부팅 데모와 장기 작업 08:44
노정석 예, 한번 볼까요?
최승준 그래서 이게 Varun Mohan이 데모했을 때 뭔가 이걸 읽은 다음에 보면 좋을 것 같네요. 93개의 subagent를 구동해서 15,000여 번의 model call을 통해 custom kernel, filesystem, driver를 처음부터 작성하게 해서 12시간 뒤 Doom이 부팅됐습니다. 그거거든요.
그래서 이거 쭉 넘겨보면 그런 것들을 Antigravity가 자기가 하더니 OS를 만들고 나중에는 거기서 Doom을 구동하는, 여기서는 Doom을 구동하는 부분이 안 나오는 것 같은데, 이게 아마 source가 어떻게 지금 바뀌고 있는지 그걸 보여주는 거네요. Varun Mohan이 보여줬던 것에는 그게 싹 나오는 것까지 보여줬었거든요.
그래서 결국에는 이런 어떤 long-horizon 작업을 낮은 token 소모로, 그런데 Gemini 3.5 Flash가 이전 Flash보다는 3배가 비싼 모델이더라고요. 그래서 적정 수준의 모델로 그걸 해내는 작업들을 보여주는 게 그래도 좀 인상에 남았습니다. 그래서 그걸 다들 하고 싶어 하는 것 같은데, Dynamic Workflows가 이번에 Opus 4.8과 함께 나왔거든요.
Anthropic Dynamic Workflows와 서브에이전트 조율 10:00
노정석 이거 이제 Google I/O 소식이 아니라 다시, 그렇죠?
최승준 그렇죠?
노정석 이제 Anthropic 소식으로 돌아와서 어제 나온 Dynamic Workflows라는 것에 대해서.
최승준 예를 들어서 ultracode라는 표현을 쓰면 UI가 화려하게 변해서 뭐가 또 재밌는 게 나오더라고요. 그래서 여기에는 그것까지는 나오지 않은 것 같은데요. 한번 그냥 쓱 보시면. 그리고 요새 Claude는 이렇게 귀여운 게 콘셉트인가 봐요. 영상들을 되게 예쁘게 만들더라고요. 그냥 한번 빠르게 지나가기 때문에 무슨 내용인가 자세히 보기는 어려운데, 그래도 뭔가 앱을 만들려고 하는 것 같아요. 연출이라서 저렇게 빨리 돌아가지 않았을 수 있습니다. 그냥 체크리스트 착착착착 해서 push해서 merge하고, 그런 걸 할 수 있다는 건데, 여기에는 Dynamic Workflows가 소개가 되지 않지만 그런 식으로 하게 된다.
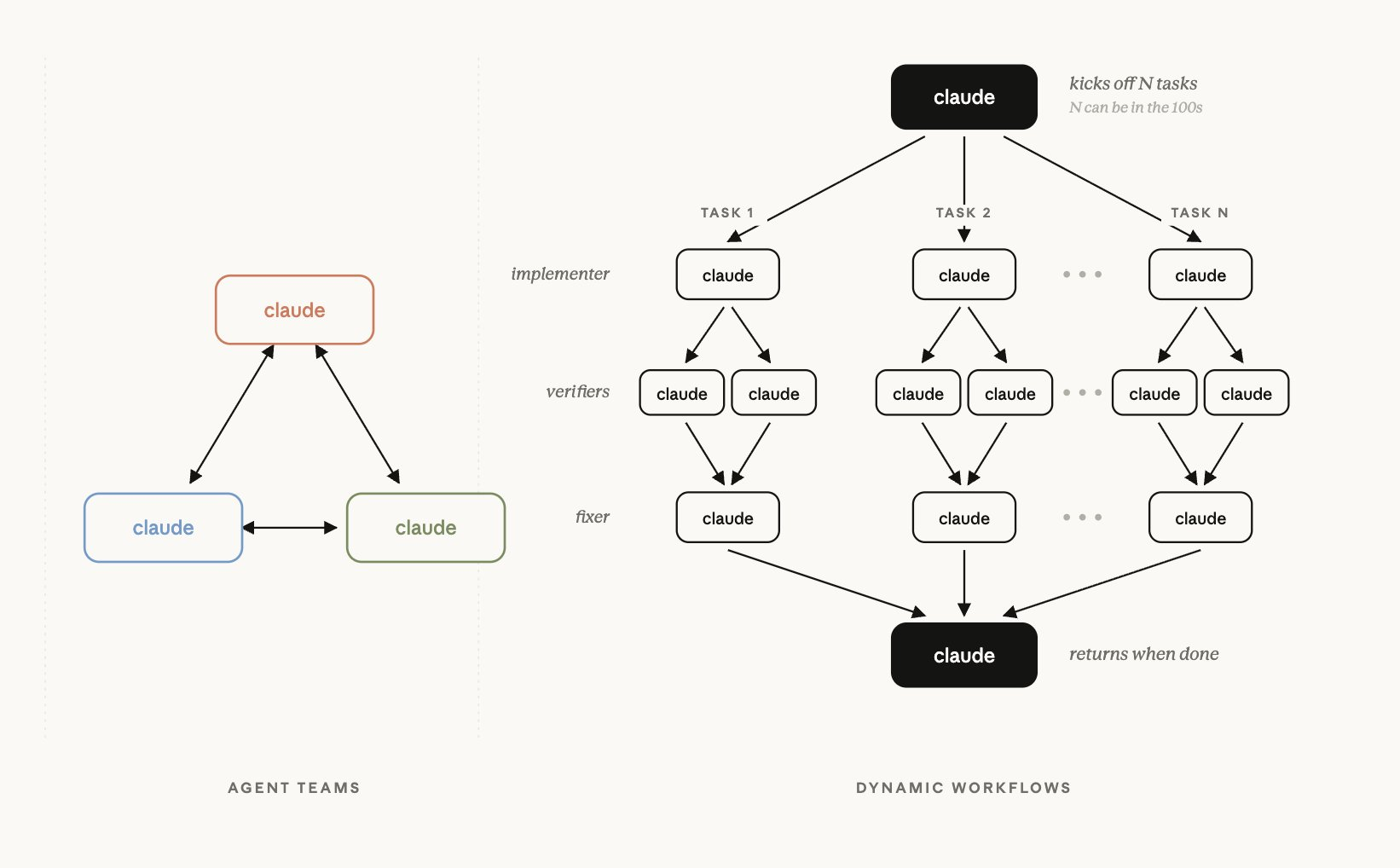
그래서 Dynamic Workflows가 뭐냐 하면, 이게 Cat Wu가 올린 트윗에 보면 이런 식으로 Claude가 있고, 여러 개의 다른 Claude한테 주고, 거기서 주고, 그걸 종합하고 종합하는, 그래서 이게 사실은 그동안 많이 보았던 그런 개념들인데, Agent Teams라는 기존의 Anthropic 제품하고는 좀 달라진다. 그런데 이거에서 흥미로운 포인트는 큰 모델이 계속 이걸 조율하는 게 아니라 처음에 어떻게 orchestration할지를 결정적인 코드로 짜고, 그게 될 때까지 쭉 하는 그런 느낌이더라고요.
노정석 그러면 이제 이 분기점을 모델이 다 읽고 그 사이사이에 판단을 하는 게 아니라, 처음에 어떤, 뭐라고 그래야 할까요? dynamic harness라고 그래야 되나, 이런 harness를 자신들이 생성한 다음에.
최승준 그런 느낌이에요. 저도 아직 써보지 않아서 정확하게는 모르겠는데, 영상 몇 개 본 거랑 이 글을 봤을 때는 이게 subagent를 조율하는 JavaScript라는 거죠. Dynamic Workflows가 그래서 이게 어떻게 보면 모델한테 맡기면 사실 모델이 게으름을 피우잖아요. 평가하고 자기가 했던 것, 자기가 평가하게 하면 됐다고 뻥치고 그러는 경우들이, 특히 어려운 일을 시킬 때 그런 일들이 있는데, 그런 것들을 어떻게 한 횟수를 좀 조이려고 했을 때는 결정적인 도구들, 코드들을 써서 체크하는 게 필요한데, 그걸 또 자기 context 안에서 평가하게 하면 문제가 되거든요.
그래서 아예 새로운 context인 subagent들에서 그런 어떤 상황들에서 그걸 착착착 해서, 물론 이게 이런 방식일 때, 아까 같은 그림에서의 방식일 때는 이 집계하는 것의 문제는 집계할 때까지 기다리는 그 뭐지, pipeline parallelism 비슷하게 이게 문제가 생길 거라고 생각이 되긴 하는데 어쨌든 그 시간하고 별도로는 이러한 느낌적 느낌으로 해내는 어떤 새로운 뭔가를 소개했다. 그런데 타임라인의 반응은 우리도 그런 거 했었어요가 되게 많았거든요. 이거 이미 있는 개념이고, Anthropic이 약간 빨랐겠네, 그런
노정석 그렇죠. 또 콘셉트로 저희 oh-my-openagent나 OMX나 이런 데서도 많이 잘 돌리고 있었던 콘셉트이긴 하네요.
최승준 그런 약간 하소연이나 허탈함 같은 것들이 타임라인에서 좀 있긴 했었는데요. 그런데 여기 이 블로그 포스팅에서는 나오진 않긴 합니다만, 그전에 Managed Agents를 다루었던 약간 뇌와 손을 분리하기 글에는 흥미로운 연구가 하나 인용이 됐었는데 여기 prior work라고 해서 지금 보면, 예를 들면 context가 일종의 object가 될 수 있고 어디에서의 object냐 하면 REPL, 그래서 REPL. 그러니까 이게 REPL이 코딩 도구잖아요. feedback loop가 있는 read-eval-print loop인가? 갑자기 생각이 안 나는데 하여튼 보통 우리가 REPL을 쓴다고 많이 얘기를 하는데 그런 것을 LLM이 programmatically 할 수 있게 하는 어떤 결정적인 도구를 써서 하는 그런 느낌이에요.
Managed Agents와 Recursive Language Models의 연결 14:00

그런데 여기 인용한 논문이 Recursive Language Models라는 논문입니다. 그래서 이 alex zhang이라는 분이 이런 얘기를 했습니다. 그래서 우리의 paper를 읽어봐라. 이게 이미 했던 그런 어떤 regime이 있는 거다. 그런 얘기를 한 게 이거 하나만 아니었거든요. 그런데 이 RLM이라는 게 DSPy에 들어 있더라고요. 그래서
노정석 그런데 저 RLM 논문 저자에 Omar Khattab이 있는데 Omar Khattab이 DSPy를 Stanford에서 만든 사람이니까 당연히 넣었을 것 같아요.
최승준 저는 그거를 DSPy를 잘 모르고, 그런 게 있고 사람들이 많이 얘기하는 것 정도만 인지하고 있었는데 이런 식으로 하는 것들이 조금 뭔가 또 trend가 되어 가고 있구나, 그래서
DSPy와 TextGrad로 보는 메타 최적화 15:40
노정석 그냥 DSPy나 그다음에 TextGrad라든지 방금 얘기한 것들이나 이런 것들을 보면 일종의 다 meta optimization이잖아요. 승준님, 그래서 결국은 하나의 layer가 쌓이면 그 layer 위에서 또 다른 어떤 게 쌓이고 그 layer 위에서 쌓이고, 그래서 이 optimization의 층위를 하나 더 올리는 이런 느낌이라고 생각하시면 맞을 것 같아요. 저 DSPy도 결국은 어떤 prompt 자체의 성능도 어떤 meta optimizer를 돌려서 계속 올릴 수 있다. Karpathy가 얘기하던 auto research 개념하고 똑같거든요. 어떤 문제든 evaluation metric만 존재하면 모델은 우리가 어떤 걸 설정하더라도 그냥 optimize computing을 투입해서 성능을 올리는 방향으로, 즉 그냥 검색하는 방향으로 전환해서 풀 수 있다는 그 핵심 개념인 것 같아요.
최승준 여기에 보면, 그냥 몇 개만 읽어보면 LLM이 code execution하고 recursive sub-LLM call을 하게 하는 게 DSPy 쪽에서, 그러니까 RLM에서 다루는 이야기고요. 그다음에 Managed Agents에서는 session abstraction을 이렇게 context 밖 object로 두고 sandbox와 REPL을 쓰는 그런 어떤 연결선이 있는 부분이 있었다. 그다음에 Dynamic Workflows는 그걸 orchestration할 때 script에 어떤 걸 둔다는 거죠, context가 아니라. 그래서 이게 결정적인 도구들을 결국 harness가 그걸 하는 거잖아요. 그래서 script를 활용해서 그거를 꽉꽉 조여 가지고 제어를 하게 하는 그런 느낌으로 가고 있습니다.
그런데 아마 그 Gemini 3.5 Flash, 아까 빠르게 돌아갔던 영상에서 말하고자 하는 숨어져 있는 것도 비슷한 층일 거라고 추측하게 되거든요. 그냥 모델이 하는 게 아니라 그걸 하는 scaffold나 harness를 써서 OS를 만들고 Doom을 바로 띄울 수 있는 정도로 한 번에 쭉 long-horizon task를 하는 거죠.
노정석 그러니까요. 그 long-horizon task도 사실은 안을 들여다보면 이게 깔끔하게 one-shot으로 끝났다기보다는 수많은 error들을, 그렇죠, error들을 끊임없이 evaluation을 돌면서 이거 틀렸네, 이거 고치고 오고, 또 이거 틀렸네, 이거 고치고 오는 약간은 소위 tinkering 과정이
최승준 어마어마하게. 수학에서 일어나는 일도 비슷한데 가설 세우고 그거를 실험하고, 문제가 생겼네. 기록하고, 그 기록에서 통찰을 얻고, 다음 가설 세우고 이거를 계속 쭉 밀어붙이는 거거든요.
노정석 그렇죠. 그래서 방금 소개해 주신 글도 결국은 이 모델에 해당하는 objective를 뭘로 바꿨느냐만 다른 거지, 쓰고 있는 방법론은 사실은 똑같은 meta.
Code as harness와 Cloudflare Dynamic Workflows 18:27
최승준 그런 얘기를 Corca의 CTO이신 강규영 님하고 하다가 강규영 님이 흥미로운 표현을 해 주셨는데 code as harness라는 표현을 해주셨어요. 듣고서 약간 귀에 착 감기는 표현이었는데 그러면서 Cloudflare의 Dynamic Workflows와 이 Project Think를 소개해 주셨는데 이걸 저는 모르고 있었거든요. 그런데 여기도 이름이 같네요. Dynamic Workflows로. 그래서 여기에서도 차세대 agent 구축에서 그러니까 code as harness가 되는 그래서 여기는 어떤 거를 가지고 오든지 그걸 해낼 수 있는 어떤 cloud platform을 만드는 그런 것들을 해서 똑같은 얘기 또 나오죠. 장기 실행 agent, actor model, Durable Objects. 그래서 다들 이런 식으로 가고 있구나라는 걸 자세하게는 아니더라도 느낌적으로 파악을 하는 정도였습니다.
기업 에이전트 활용에서 커지는 latency와 harness 수요 19:22
노정석 그렇죠. 저도 저희 Slack에서 저희 회사 구성원들이 task를 시키는 것들을 맨날 보고 있으니까 그러면 agent가 꽤 복잡한 일을 시키면 기본 20, 30분씩은 돌고, 아무리 짧게 돌아도 10분씩은 돌거든요. 그러다 보니까 latency에 대한 needs가 막 생겨요. 그리고 저 harness도 지금은 저희가 나와 있는 harness들을 주로 쓰고 있는데 우리만의 harness를 써야 되겠구나라는 그런 needs도 계속 생기고 있고요.
최승준 맞아요. 그런데 나중에 한번 소개해 드리고 싶긴 한데 제가 1년 전에 Minecraft 가지고 agent 만드는 거를 다시 요새 재방문하고 있는데 세상이 달라졌더라고요. 어저께 자기 전에 10시간짜리 돌려놓고 잤는데 아침에 뭔가 성과를 보이더라고요. 그런데 그 과정도 보면 Minecraft 최신 버전에 아직 Mineflayer라고 봇 붙이는 게 아직 오픈소스 프로젝트가 따라가지 못하고 있어서 제가 바닥부터 한번 만들어 봤는데 그걸 할 때 protocol 추측하고, block ID 추출하고 해 가지고 쌓아 올리는 데 되게 재밌었습니다. 나중에 한번 소개해 드릴게요.
노정석 이제는 생각을 하면 된다는 느낌이 있으니까.
그런데 아쉬운 거는 일어나서 보니까 Codex weekly limit이 8% 남았다라고 보고가 돼 있어서 token을 많이 쓰게 되는 거죠. 그래서 그런 일들과는 별도로 수학에서도 5월에 흥미로운 일들이 있었는데 이게 관련이, 좀 전에도 얼핏 말씀드렸지만 관련이 있다고는 느껴지거든요. 그래서 저도 수학을 깊이 하는 건 아니라서 그냥 대강만 살펴봤는데 에르되시 문제 중 하나를 푸는, 에르되시 문제가 여러 가지인데 그중에 하나를 푸는 거를 모델이 해내서 세상이 또 좀 놀란 시기가 5월 중순에 있었어요. 그래서 OpenAI가 그거를 GPT-5.5가 아니라 아마 이건 내부 모델이었던 것 같아요. 내부 모델에서 그거를 특수한 스캐폴딩으로 해냈던 것 같은데 그랬더니 Sholto가 지금은 Anthropic에 있잖아요. 그래서 그거 한번 칭찬해 주고 그다음에 Mythos도 해냈다라는 포스팅을 했거든요. 그런데 제가 여기 링크를 지금 안 내놨지만 Gemini도 해냈다, 가 있었어요. 그래서 비슷한 거를 다 해냈다.
AI가 푼 에르되시 문제와 수학 연구의 변화 20:42
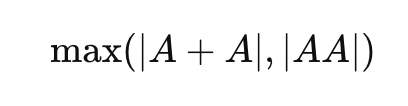
그런데 그거 말고 제가 재미있게 본 거는 Noam Brown의 이 표현이 재미있었어요. 그래서 이거가 링크를 타고서는 계속 다른 사람으로 넘어가게 되는데 그거를 제가 여기다가 번역을 해 놨거든요. 그런데 번역을 해 놨지만 의미를 읽기는 어렵습니다. 그런데 어쨌든 다 수학에 계신 분들이 이게 굉장히 흥미로운 거를 얘기했는데 Noam Brown의 이야기를 먼저 소개한 다음에 Noam Brown이 알파고 이후 인간 바둑 기사들의 실력은 눈에 띄게 향상되었다. 나는 수학에서도 비슷한 패턴이 나타날 것이라고 생각한다. 그래서 이거는 이 이야기, 수학자들이 이야기한 이야기는 뭐냐 하면 OpenAI의 모델이 푼 얘기가 아니라 수학자들이 푼 얘기예요. 그래서 그 에르되시 문제를 모델이 해낸 걸 알려진 다음에 수학자들도 영감을 얻고 해 가지고 뭔가를 급진전시킨 현상이 일어났다는 거죠. 그래서 그게 너무 흥미롭다.
AlphaGo 이후 바둑처럼 강해지는 인간 수학자 21:59
그래서 여기 Timothy Gowers가 또 유명한 수학자거든요. 그래서 이번에는 가법 조합론의 또 다른 문제, 주요 문제가 해결되었다. 이번에는 AI가 아니라 인간들이 해낸 일이지만 단위거리 추측에 대한 AI 해법과 관련된 방법들을 사용했다. AI 해법을 배워서 활용했다는 거죠. 그런데 그게 신진서 9단 등이 이렇게 하시는 일들이 AI와 많이 대국하면서 자기가 배워내잖아요. 그런 일들이 벌어지고 있는 건데 이번에 OpenAI의 그 시도도 흥미로운 게 인간을 되게 중요한 역할로 줬어요. 모델이 혼자서 추진해서 하는 게 아니라 평가를 하는 걸 인간이 제대로 하는 어떤 그런 메커니즘이 좀 들어가서 기존의 시도하고는 좀 달랐거든요. 그러니까 human in the loop를 중요하게 조금 다루는 느낌이 생기기 시작했습니다. 그래서 이게 GPT랑 읽었던 내용인데 알파고 이후 인간 바둑이 세진 것처럼 AI가 수학에서도 인간의 탐색 공간과 직관을 넓히기 시작한 것 아니냐는 얘기죠.
노정석 너무 당연하게 그럴 것 같습니다.
최승준 OpenAI의 이번에 에르되시 문제에도 그냥 인간, 인간의 한 수학 전문가라면 한 분야 수학 안에서도 여러 장르가 있는데 정수론에 정통한 학자, 조합론에 정통한 학자, 그런데 서로의 문헌을 모를 수 있잖아요. 그런데 AI는 pretraining을 통해서 전체적인 걸 아니까 그 문헌 사이를 연결할 수 있는 걸 할 수 있게 되는 그런 뉘앙스가 좀 컸거든요. 그래서 그런 것들에서 자극을 받고 인간도 이런 것들을 연결할 수 있구나를 알아차리게 되면 전이를 시키는 게 가능해지는데 그런 일들이 벌어지기 시작했다는 신호를 읽게 됩니다.
그래서 여기에 이렇게 그냥 모델과 대화했던 내용은 재미있긴 하지만 그냥 스르륵 넘어가겠습니다. 그래서 인간 창의성의 지형을 바꾼 사건이다. 창의성을 죽인 사건이 아니라. 그래서 제가 요새 많이 고민하던 게 생성형 소화 불량이라는 얘기를 작년 봄 즈음에 했었는데, 요즘에 생각하고 있었던 건 생성형 인지 저하거든요. 내 생각을 자꾸만 offloading, 모델에게 위임해서 대신 생각하게 하다 보면 내 생각하는 힘, 근육이 줄어간다는 느낌. 그리고 Dwarkesh 편 공부하면서도 flashcard의 자극을 받았던 게, 대화를 깊게 하고서는 그거에 대해서 flashcard 만들어서 물어보면 많은 걸 내가 금방 잃어버리고 있구나. 대신 생성하게 하는 거는 인지 저하를 하게 한 거다. 그러니까 skill이 줄어드는, 내 역량이 줄어드는 그런 느낌을 많이 받아서 고민이 많았는데 그런 일들이 현재 분명히 생기고 있거든요. 우려스럽게.
생성형 인지 저하와 intelligence augmentation의 공존 24:31
그런데 한편에서는 아예 intelligence augmentation 또는 amplification을 하는 부분들이 있다. 그래서 이게 지금 역시 또 이번 판도 다시 기술이 격차의 도구로 작용하고 있나 이런 고민들을 좀 하게 돼요. 저는 초지능으로 가까이 가거나 AGI로 가까이 갈수록 그게 되게 격차를 얇게 하는 뭔가가 될 거라고, 기회, 새로운 전인미답의 기회가 될 거라는 상상을 작년 여름에 했었는데 실제로 뚜껑을 열어 놓고 보니까 이게 되게 slot machine으로 dopamine이 터지지만 일은 물론 해내지만, 내 능력 자체는 저하되는 일이 벌어지고 있을 수 있는데 한편에서는 능력을 획득하는 경우도 일어나고 있다. 이거 좀 생각하게 된다는 겁니다.
AI 시대에 달라지는 일과 인간의 조건 26:05
노정석 이건 또 관점을 어떻게 보느냐에 따라서 정반합 형태로 계속 달라질 문제일 것 같긴 해요. 당장은 격차를 늘리는 것 같지만, 결과적으로 보면 격차를 매우 줄여 놓을 거고
최승준 평균은 올라갈 가능성이 있겠죠. 이래나 저래나.
노정석 그렇죠. 예전에는 일의 개념이 저희가 생각하는 지금의 개념과 완전히 달라질 것 같은 게, 예전에 예를 들어서 집을 짓는데 단위 시간당 흙을 얼마나 많이 옮기느냐라고 하면 당연히 체력과 요령, 이런 것들이 그 사람의 능력치였는데 포크레인 같은 굴착기 같은 그런 기계가 나오면서 사실 지금은 그 자격시험, 운전면허시험으로 바뀌어 있잖아요. 그런 것처럼 저희가 아직은 상이 맺혀 있진 않지만 지식 산업 관련한 부분도 무언가 우리가 생각의 근육으로 문제 해결을 해내는 데 써 왔다면 그게 더 이상 필요 없어지고, 다른 형태의, 다른 층위의 어떤 새로운 자격증이나 능력 같은 게 생겨난다고 봐야 되겠죠. 저희도 지금 agent로 맨날 일을 하다 보니까 이게 과연 일을 잘하는 것은 무엇인가에 대해서 굉장히 이런저런 생각들을 저도 많이 하고
최승준 오늘 다룰 얘기는 아니지만 이게 되게 고민스러운 거거든요. 인간의 조건하고 연결되는 거라서, 생각하는 게 인간의 일이었잖아요. 그런데 그게 이동하고 있어서 상당히 고민스럽습니다. 개인적으로는.
노정석 생각하는 게 인간의 일이라는 것도 사실은 통념인 거죠. 과연 그런 게 맞아요. 맞아요.
Simon Willison이 본 OpenAI와 Anthropic의 product market fit 27:40
최승준 그럼 도전적인 질문을 던져 볼 수 있겠네요. 그래서 오늘 이야기의 마지막은 조금 다시 현실로 돌아와서 Anthropic과 OpenAI는 product-market fit을 찾은 것 같다. Simon Willison이 이 포스팅을 한 게 되게 인상적이었어요. 5월 27일이었는데, 이게 OpenAI는 703개의 잡 포스팅을 하고 Anthropic은 390개의 공개 채용 공고를 했다는 것을 API를 써서 Simon이 분석했더라고요. 그래서 이걸 그냥 다 읽지는 않지만, 그래도 읽어보면 기업 고객들이 이제 API 가격을 내고 있다. lock-in된 거죠. 이제는 강을 건넜잖아요. 안 쓸 수가 없거든요.
노정석 그럼요. 인당 100달러, 200달러 요금제, 거의 다 하나씩 주고 있지 않아요? 이제 엔지니어들이 아니라 다른 사람들도 Claude Code를 이제 다 쓰고 있기 때문에 저희도 비엔지니어 분들이 100달러, 200달러 플랜을 쓰는 비중이 높아지고 있습니다.
최승준 나는 agent를 광범위하게 사용하는 기업들도 비슷한 할인을 받고 있을 것이라고 생각했다. 그런데 알고 보니 완전히 틀렸다. 비싸지고 있고 이제 API 가격을 내야 되는 거예요. 안 낼 수가 없어서 이제 그 usage fee에 대해서 다 페널티를 주고 있잖아요. Claude도 그렇고, Gemini도 그렇고 OpenAI는 아직 괜찮지만, 이제 usage fee 페널티 주면 API 가격 내야 되면 Slack에다 넣는 건 되게 비싸질 거거든요. 그런데 써야 되죠.
노정석 그럼 Codex로 옮겨야죠.
최승준 그렇죠. 그런데 Codex도 버텨내지 못하면 이제 바꿀 수 있기 때문에 완전히 안심할 수는 없을 가능성이 있다고 봅니다.
토큰 가격과 AI 수요의 장기 방향 29:11
노정석 그런데 어떻게 보세요? 이 토큰 가격이 지금 단기적으로는 상승 여력이 많은데요.
최승준 중국 쪽도 상승하고 있어요.
노정석 수요가 계속 증가하고 있는 거죠. 지금 메모리 가격 증가하고 있는 거 보면 수요가 계속 늘고 있는 건 맞으니까. 그런데 이 수요가 두 가지 시각이 있어요. 사람들이 이제 쓸 사람들은 다 쓰고 거의 끝에 왔다, 이 plateau에 도달했다라고 보는 시각이 있고 그런데 그런 시각을 가지고 계신 분들은 거의 대부분 이 tech world 밖에 계신 분이에요. 밖에 계시면서 투자적인 관점으로 이게 이렇다 저렇다, Anthropic과 OpenAI가 위험하다고 해석하시는 그런 세력이 있고, 그런데 이 안에서 Jensen의 keynote에 열광하고 그다음에 OpenAI나 Google의 발표를 보면서 이렇게 막 박수를 치는 그런 테크 안쪽에 있는 사람들 입장에서 보면 이제 겨우 시작한 거 아닌가 생각은 많이 하죠. 이제 겨우 시작 아닌가. 토큰 가격은 전기처럼 될 것 같아요, 전기.
최승준 그래서 그건 어떻게 될지는 저도 정확히는 모르겠어요. 이 전 단계에서의 예측은 당연히 싸질 거다였잖아요. 그런데 지금 랠리가, 이게 피크가 어디까지 갈지는 모르지만, 약간 기울기가 바뀐 느낌이고 그게 또 어디로 갈지는 아무도 모르는 일 아닐까요?
노정석 그런데 저는 역사적으로 살펴볼 때 얘는 낮아진다에 베팅하는 게 무조건 높은 확률값입니다.
최승준 그래서 어쨌든 기업들은 lock-in되어 있고 돈을 내고 있기 때문에, 돈을 내고 있으니까 최소한 둘은 product-market fit을 찾았다는 게 Simon의 관점이에요. IPO를 둘 다 준비하고 있지만 지금 많이들 돈을 내고 있기 때문에 혹시 흑자 전환도 가능한 거 아니야? 그런 얘기들이 있다는 거죠. IPO 전에.
AI 기업 채용 확대와 개발자 고용의 재해석 31:13
그래서 그런 얘기들이 좀 있으면서 이어지는 게 확장하고 있다. 그래서 자기가 찾아봤더니 OpenAI는 현재 703개의 공개 채용 공고를 내고 있고 그중에서 지원 관련 229개, 이런저런 것들. 그리고 거기에는 Go To Market이나 FDE 같은 직무가 포함된다. 그리고 Anthropic도 390개의 공개 채용 공고를 내고 있다. 그래서 Meta는 최근에 8천 명 layoff 하는 것 때문에 또 이슈가 있었고 Microsoft도 계속 좀 줄여가는 느낌이었는데 이런 쪽들은 늘려 간다는 거죠.
그리고 다시 요새 우리나라 타임라인에서 나오는 게 개발자 고용이 늘어가는 부분들도 있다, 같은 뉴스들을 좀 봤거든요. 그래서 지금 이것도 또 두 개가 양립하고 있는 거 아닐까요? 한쪽에서는 talent density를 높여서 작은 팀으로 이렇게 밀어붙이는 일들도 벌어지지만 또 이렇게 AI를 쓰는 개발자들이 여전히 AI 혼자는 아니기 때문에 더 필요해서 고용을 늘리는 게 같이 가고 있는 건가요? 저도 잘은 모르겠거든요.
엔지니어에서 AI native problem solver로의 전환 32:19
노정석 저는 이제 개발자라는 표현의 의미가…
최승준 모두 그냥 빌더다?
노정석 네, 다 새로운 층 위에 어떤 problem solver가 된 거고, Claude Code를 다룰 줄 알면 그들을 새로운 엔지니어로 부를 것인가. 엔지니어들 어느 누구도 지금 코딩을 하고 있지 않거든요. 그런데 지금 문제 해결을 잘하는 엔지니어들을 보면 어떤 엔지니어들이냐면, 그래도 다양한 층위에 대해서 AWS에서 어떤 문제가 벌어지는지, 그다음에 웹 서버에서 어떤 문제가 벌어지는지, Redis에서 저 workload를 어떻게 분산하는지, DB 최적화는 어떻게 해야 되는지, SQL은 뭔지, C는 뭔지, 뭐 해서 OS 전반에서부터 아키텍처링부터 서비스까지 그 다양한 부분의 관점을 가지고 있었던 분이 Claude Code를 만났을 때 훨씬 더 강력하거든요. 주니어가 했었어야 될. 그런데 문제는 거기까지예요. 고객은 그러한 아키텍처를 사는 건 아니거든요. 고객은 자신들의 문제가 해결되는 걸 산단 말이에요. 그러면 예전에 뭐가 빨라졌냐면 어떤 앱을 만들어 줘라고 했을 때 그 단위 앱에 요건이 생기고 그 안에서 PM이 요건 분석을 하고 디자이너가 그걸 펼친 다음에 PRD를 쓰고 그걸 task로 쪼개고 어쩌고저쩌고 해서 빌드돼서 고객 눈앞에 새로운 UX workflow를 가져다 놓는 그 구간만 줄었지, 그럼 그걸 가지고 진짜 고객을 더 획득하고 문제를 해결하고 하는 그 구간은 여전히 남아 있는 문제거든요.
그럼 이제 그 능력들을 다 갖춘 상태에서 고객의 문제가 무엇인지를 이해하고 거기에 맞춰서 더 이상 마케터와 영업을 사이에 두고 고객을 대응하는 게 아니라, 그들조차 그냥 건너뛰어서 고객과 바로 얘기해야 되는 역량이 필요하거든요. 그러니까 이제는 그러한 엔지니어링 능력을 갖추고 고객의 문제를 해결할 수 있는, 저희 소위 예전 표현으로 하면 마케터나 세일즈의 역량까지 다 갖추고 있어야 이 문제가 한 번에 끝나는 거거든요. 그러니까 이제 엔지니어의 채용이 늘고 있다는 부분들은 저는 조심해서 봐야 될 것 같아요. 그냥 전통적인 기준의 엔지니어 숫자가 늘어나고 너 Claude Code 쓸 줄 알아? 네, 쓸 줄 알아요라고 한 사람이 회사 안에 한 명 더 앉아 있다 해서 뭐가 더 좋아지진 않거든요.
결국은 저희가 계속 이야기하던 고객의 문제에 관련한 그 domain의 어떤 문제 해결점, 그걸 Claude Code한테 어떻게 잘 시킬 수 있는지, Claude Code한테 어떻게 잘 시킬 수 있는지에서 엔지니어링 역량이 있는 게 도움은 되지만 그러한 역량조차도 사실은 저희가 agent로 workflow를 만들다 보면 많이 느끼게 되는 거지만, 계속 어떤 암묵지화되면서 agent의 메모리 안에 계속 쌓이거든요. 그래서 예전에는 어제 매출, 이렇게만 얘기하면 얘가 그냥 마음대로 hallucinate했다면 그동안 계속 쌓여 온 context가 있기 때문에 지금은 그냥 저희 agent한테 어제 매출이라고 얘기해도 정확하게 회사가 원하는 관점으로 가공해 오거든요. 마찬가지로 이 엔지니어링과 관련된 아키텍처링이나 이런 것들도 충분히 오히려 더 구조적으로 암묵지화돼서 agent에 쌓일 수 있기 때문에 점점 더 어떻게 보면 우리가 과거에 갖고 있었던 엔지니어링 역량도 살짝 필요 없어지는 거긴 하거든요.
encapsulation돼서 아래 layer로 쌓여 내려가는 거라서 지금 더 명확하게 표현하면 이제는 엔지니어라는 개념보다는 그냥 모두가 다 문제 해결사이자 단위 사업의 사업가라고 정의 내리는 게 맞고, 저도 회사에서 구성원들에게 이제 저희 Claude Code를 써서 전통적인 개념에서 엔지니어링을 하는 그 직군 중에 전통 엔지니어 출신은 반이에요. 나머지 반은 전통 엔지니어 출신이 아니에요. 예전에는 마케터였던 사람, 예전에는 그냥 PM이었던 사람. 심지어 그런 분들이 Claude Code를 결합하게 되고 이미 엔지니어들이 만들어 준 암묵지 prompt를 그냥 가져와서 그 skill로 불러 쓰기 시작하니까 문제가 한 번에 끝나는 경험들을 많이 하거든요.
이제는 인력에 대한 개념이 바뀔 거다. 아직 그 용어가 명확히 나오지 않았다고 봐요. 그냥 저희가 그걸 총칭해서 엔지니어라고 부르고 있을 뿐이고 만약에 그냥 밑도 끝도 없이 Claude Code 쓸 줄 아는 엔지니어를 채용하자라는 의사결정이 어떤 기업에서 나왔다면 그 기업의 경영자가 문제의 본질이 뭔지 아직 전혀 모르고 있을 가능성이 있는 거고, 그러니까 엔지니어 개념에서 조금 더 나간 게 이제 소위 FDE, Forward Deployed Engineer라는 건데 이제 FDE보다도 좀 더 나갈 것 같아요. 저는 AI native talent라고 개인적으로 지금 부르고 있는데 이제 다 갖춰진 사람이 있습니다.
AI를 쓰는 인재 수요와 문제 해결 시장의 확대 37:26
최승준 결국에는 이 AI를 공급하는 입장에서 보면 누가 됐든 상관없는 거잖아요. AI를 쓸 사람이 결국에는 자기들의 어떤 고객이 되는 거기 때문에 누가 됐든 상관없고 엔지니어가 됐든 빌더가 됐든 그 AI를 쓰는 사람을 필요로 하는 직업이 줄어가는 게 아니라 늘어가는 구간도 있을 수 있겠구나라는 생각은 Simon Willison의 얘기를 보면서 하게 된 거죠.
노정석 저도 그 지점은 동의합니다. 이제는 사실 사람이 할 일이 더 늘어나잖아요. 그리고 그때 신정규 대표도 그 얘기하셨잖아요. 사람들은 문제를 해결하는 속도보다 문제를 만드는 속도가 빠르기 때문에 수요는 또 한참 늘어날 겁니다. 그리고 이제 저희가 전통적으로 엔지니어라고 부르던 개념은 아마 한 layer 아래로 내려가서 이제 inference를 어떻게 더 빨리 하게 할 거냐, 고도의 token engineering, infrastructure engineering, model building, 이런 쪽으로 떨어지지 않을까. AX가 만약에 성공이 된다고 하면
최승준 AI를 잘 쓸 수 있는 인재가 되는 거니까 그 사람은 고용을 유지하고 또 새로운 AI를 써줄 사람이 아직은 필요한 스테이지라고 하면 고용이 늘어날 수 있겠구나라는 생각을 Simon Willison의 이야기를 보면서 좀 했었고요. 근데 알 수 없는 일이죠. 그래서 여기 후반부는 AI 때문에 비용이 커졌다. 그런데 지금 이게 11월에 사람들이 작년에 예산을 짜서 올해 예산을 쓰다 보니까 gap이, 그러니까 차이가 발생하는 거지, 이제부터라면 그걸 또 조정할 수 있을 거다라는 느낌적인 느낌으로 저는 읽었는데 어쨌든 지금 4월 정도가 한 번 크게 변곡점이 됐다가 Simon Willison의 얘기였어요. 그래서 여기 지금 제가 중간에 좀 건너뛰었는데 연구소의 어떤 투자가 계속 얼마나 이걸 지탱할 수 있을지 모르겠지만 진행이 되고 있고, API 매출의 중요성은 줄어들고 있다. 이게 무슨 얘기였는지 지금 잘 기억이 안 나는데요.
API 비용 증가와 온프레미스 모델 수요 38:50
노정석 다 200불짜리 seat에 사람들이 훨씬 몰려가고 있고, 그리고 예를 들어서 대기업들, 은행권이라든지 아니면 초대형 IP들을 가지고 사업을 하는 회사들은 Claude Code나 이런 거 쓰긴 좀 어렵거든요. 그래서 Claude Code harness를 가지고 그냥 로컬 모델 Qwen이나 GLM 같은 것들을 붙여서 돌려야 되는데, 예를 들어서 GLM 500B 정도 모델이나 Qwen 그 정도 모델은 꽤 성능이 좋거든요. Cursor의 모델도 Qwen base로 만들어졌다고 저희에게 알려져 있잖아요. 그런 것처럼, 근데 그 안의 수요도 엄청나게 있거든요. 대형 엔터프라이즈 안에서의 on-premise로서의 어쨌든 Claude Code나 Codex. 사실은 이제 Claude Code나 Codex가 코딩 에이전트가 아니라 그냥 아주 기본적인 default 문제 해결 앱이 된 것 같아요.
최승준 그거를 잘 알아야겠네요. 결국에는 우리가 다뤄야 되는 문제의 규모가 어떤 급의 모델로 풀어야 될지를 촘촘하게 알아서 잘 배치해야지, 아니면 굉장히 예산에 미스가 나게 되고 순식간에 그냥 날아가 버릴 거 아니에요.
노정석 모델의 성능, 저희가 accuracy라고 해야 되나? 모델의 어떤 벤치마크 성능과 latency의 trade-off이지 않을까 싶어요.
최승준 하여튼 그런 얘기들 포함해서 저도 벌써 이렇게 하루, 어저께 읽었는데 기억이 잘 안 납니다.
여름에 예상되는 Gemini와 Mythos와 GPT 경쟁 41:19
노정석 요새 저희가 한 달이 1년 같다고 그랬는데, 2주가 1년 같다고 그랬는데, 이제는 거의 일주일 사이에도 깜짝깜짝 놀랄 growth들이
최승준 그러기도 하고 뭔가를 많이 살펴보고 하다 보니까 그냥 제 인지 능력의 저하가 좀 일어나는 것 같아요. 뭔가 많이 살펴보고 소화하려고 했다고 하는데 실패를 하는 거죠. 그래서 그래도 인덱스 정도는 남거든요. 아직 그래도 뭘 봤지, 뭐는 중요하지, 이거를 좀 소개해 봐야겠다 정도의 인덱스에 남은 것 중 하나가 이번 주는 Simon Willison의 글이었고요. 이게 4월이 변곡점이었다. 이 부분에 저도 동의하게 되고
노정석 지나보니.
최승준 그리고 여름에 한 번 clash가 있을 것 같다는 전망 정도 해보게 됩니다. 그 Anthropic Mythos급, 그거에 대항하는 OpenAI의 모델, Gemini의 모델, 그런 것들이 이제 다 가리키는 방향이 지금 내일이 6월, 내일모레가 6월인데 여름으로 들어가면서 이제 한 번 우리를 힘들게 하면서 또 기대하게 하는
노정석 Gemini 3.5 Pro와 Anthropic의 Mythos와 GPT-5.6 정도로 대변되는 세계 메이저 플레이어들의
최승준 그러면 기존에 잘 돌아가고 있었던 것들을 유지할지, 아니면 migration하고 한 번 싹 갈아엎을지, 이런 일들을 또 푸닥거리를 하게 되겠죠. 예정된 일이라는 거죠.
노정석 또 얼마 안 남았어요. 두 달 이내에.
최승준 그렇기 때문에 뭔가를 공부하고 내 역량을 키우려면 모델이 나오면 그 모델을 공부해야 되잖아요. 그러니까 집중해야 될 걸 집중하지 못하게 되는 그런 일들이 지금 쳇바퀴 돌듯이 반복하고 있어서 저희가 저번에 Dwarkesh나 Reiner Pope 편에 배운 것 같은 걸 배우려면 빨리 해야 된다.
모델 성능보다 중요해지는 harness와 비용 최적화 43:07
노정석 그러니까요. 저희가 사실 모델 이야기를 상당히 안 하고 있다는 게 저는 많이 느껴지거든요. 얘는 어느 일정 수준 이상을 지났어. 얘의 진보를 살피는 게 좀 더 중요한 얘기가 아니라 이제 다음 층 위로 기어가 좀 바뀌었어요. 모델은 이제 충분히 좋아졌고 그 좋아지는 거가 위에, 얘가 AGI로 가든 말든, 나는 내 단위 업무를 어떻게 가장 저렴한 가격으로 가장 빠르게 해결할 것이냐. 그거는 모델의 능력과 harness의 정도와 이것들을 어떻게 align을 잘 할 거냐라는 것들을 판단하는 이런 것들이 중요해지는 시기로 좀 넘어가는 것 같고.
a16z 관점의 AI 플랫폼 사이클과 인프라 붐 43:51
그리고 저는 오늘 아침엔가 갑자기 보다 봤는데 a16z에서 나온 얘기가 있거든요. 저희가 항상 쓰는 인터넷 시대, 모바일 시대, 이런 것들에 과거에 어떤 테크의 붐이 있을 때 어떤 일들이 일어났었냐. 항상 처음에는 칩이라든지, 모바일 때도 그랬죠. 저전력 칩이라든지 이런 것들이 한참 이슈였고, Qualcomm이라든지 ARM이라든지 이런 회사들의 수혜가 쭉 갔었고, 그다음이 iPhone이나 Android 같은 그런 회사였고, 그 위는 사실 애플리케이션이었잖아요. 그 위에 Uber라든지 카카오톡이라든지 아니면 Airbnb라든지 이런 새로운 층위의 앱들이 쭉 떴었는데, 이제 AI도 똑같은 걸 하고 있는 것 같고. 어쩌면 그렇게 보면 지금 NVIDIA와 하이닉스나 삼성전자의 주가가 이렇게 막 고피크를 찍는 게 이게 피크고 곧 AI 붐 꺼져요가 아니라 이 붐의 시작을 알리는 서막에 불과하다 라고 볼 수 있다는 거죠.
그러니까 사람들은 항상 과거의 기준으로 미래를 평가하는 나쁜 버릇이 있거든요. 과거의 패턴은 반복되지만, 그 패턴 속에서 이렇게 y축으로 존재하는 intensity, amplitude는 상대적으로 다 보강, 보정해서 사용해야 되거든요. inflation adjusted를 해야 되는 건데, 예전에 모바일에서 이만큼 갔으니까 이번에도 그거에 비교하면 피크야라고 얘기하는 게 저는 많이 틀릴 수도 있겠다.
Vinod Khosla가 말한 intelligence 수요의 상방 45:30
그리고 Khosla Ventures의 Sun Microsystems를 만들었던 제가 존경하는 할아버지가 한 명 있어요. Vinod Khosla라고. 근데 Vinod Khosla가 이거는 기존에 있었던 앱과는 다르다. 왜냐하면 이거는 intelligence라서 이거는 상방이 없다. 예를 들어서 무한히, 영원히 살 수 있는 약을, 암을 해결했어. 그럼 사람들이 암을 해결했으니까 그게 끝났을까? 아니요. 무한히 살고 싶을 거고, 무한히 살고 싶은 걸로 끝날까? 아니에요. 더 예쁘고 더 건강하고 그런 삶을 살 거고, 그게 끝나고 나면 또 그다음 걸 찾을 거고, 이게 끝이 없다. 인간의 욕구는 열려 있다. 근데 과거의 어떤 플랫폼의 어떤 전이들은 항상 걔가 delivery할 수 있는 상방의 끝이 꽉꽉 닫혀 있었거든요. 인터넷이 나왔어. 그러면 그래, 시장이 좀 커지긴 하겠지만, 과거 TV나 신문이나 이런 거 대비 몇 배. 모바일에 의해서 뭐 됐어. 그러면 PC를 못 사는 사람도 살 수 있으니까 몇 배 되지만, 이거는 intelligence다. 거의 영원히 수요가 증가한다라는 얘기를 했는데, 저는 그 말에 굉장히 동감이 가요.
OpenAI와 Anthropic의 IPO 가능성과 의미 46:42
최승준 가까운 미래에 대한 그냥 아무 말이나 해보자면 저는 OpenAI와 Anthropic이 올해 안에 IPO를 할 수도 있을 것이다라는 뉴스를 많이 보면서 그거는 알겠는데, IPO를 하면 무슨 일이 생기는 거예요?
노정석 IPO를 하면 무언가, 지금 이미 private market에서도 fundraising을 하는 데 아무 문제가 없기 때문에 IPO를 하면 나름의 어떤 하나의 milestone일 것 같아요. 지금은 그들 회사 입장에서는 사실 private market에서 받은 주식이라든지 이런 것들 구성원들이 파는 데 아무 문제도 없고, 다 사고 싶어 하고, IPO를 가면 그냥 그거에 유동성이 확 증가하는 거고. 그다음에 기존의 투자자들에게 묶여 있던 굉장히 많은 obligation들이 있거든요. 예를 들어 private round에서 Series A, B, C, D, E 이렇게 해서 막 받으면 valuation을 높일 수 있지만, 그것들이 회사의 경영진을 옥죄는 굉장히 많은 조건들이 따라붙어요.
근데 대부분 그것들을 다 release하고, 그냥 투자자들은 5년이 회사와 아무 관련 없이 다 떠나는 게 사실 IPO라는 기점이거든요. public market에 들어가면 그때는 자유 시장 경쟁 체제에서 주가가 떨어지는 걸로 반응을 하든, 아니면 팔고 싶으면 팔고, 사고 싶으면 사고 그렇게 되는 거니까. 그게 계속 투자를 받아왔던 회사 입장에서는 걔를 한번 해소하는 타이밍이고, 또 합법적으로 이제 누군가에게 의존하지 않고 회사 주도하에 fundraising을 지속할 수 있고, 또 valuation을 높이는 것들이 나름의 순위를 매기는 게 되잖아요. 지금도 보면 1등은 어디고 2등은 어디고 3등은 어디고, 그러면 그 사람들 사이에서도 나름의 leaderboard가 생기는 거니까. 나 IPO 했다. 회사 valuation 얼마다. 이런 것들을 그냥 단순히 objective로 찍고 가고 있지 않을까 싶어요. 근데 저희 같은 투자자 입장에서 더 중요한 거는 그 IPO가 시작일 것이냐, 끝일 것이냐.
최승준 어쨌든 네 글자 code가 생기는 거잖아요.
노정석 지켜봐야죠.
최승준 그렇죠. 뭐가 될지는 모르겠지만 뭐라고 할까, OpenAI 뭔가(티커가) 생기겠네요.
100회와 3주년 이후 하드웨어와 inference 탐구 48:54
노정석 이미 다 선점해 두지 않았을까요? 궁금하네요. 저희가 다음이 이제 100회네요.
최승준 그래서 저희가 5월에 시작했기 때문에 100회와 3주년과 그다음에 구독자 3만 명 넘었죠. 여러 가지가 겹쳤는데,
노정석 여러 가지가 겹쳤는데,
최승준 밋밋하게 일상처럼 가야 하지 않을까요? 어떤 것들을 좀 다루겠다는 계획 같은 거 있는데, Dwarkesh 편에서 공부한 것들의 연장선에서 이런 어떤 하드웨어를 왜 알아야 되는가, 지금 벌어지고 있는 일들의 기반이 되는 기술에 대해서 좀 깊이 알고자 초청 인사들을 이렇게 말씀드려 보고 있는 스테이지잖아요.
노정석 네, 사실은 에이전트 시대가 되면서 inference의 중요성이 어마어마하게 많아지고 있고, 사실 어마어마하게 토큰들이 밀려오고 있기 때문에 그 토큰 공장의 안을 한번 살펴보는 게 저희가 의미가 있다는 생각이 들었고, 그 관련해서 하드웨어의 깊은 곳에서부터 그것들을 orchestration하는 orchestration layer요. 그 위로 올라가는 소프트웨어 영역, 그 사이를 한번 살펴보려는 생각을 하고
최승준 잘 해나갈 수 있을지는 모르겠지만 그런 방향성을 좀 가지고 있다 정도 말씀드리고.
실리콘밸리 일정과 다음 회차 예고 50:07
노정석 맞아요.
최승준 또 이제 여름이 다가오고, 또 정석님도 다른 일정이 있으신 것 같으니까
노정석 맞습니다. 제가 또 6월에는 실리콘밸리에 있을 예정이어서 또 가서 베이에 계시는 분들 저한테 연락 많이 주시면 또 소식 한번, 근황 나눌 수 있으면 좋을 것 같아요.
최승준 원격으로도 한번 해야 될 것 같긴 한데요.
노정석 네, 원격으로 몇 번 해야 될 것 같은데요.
최승준 즐거운 시간 되시기 바랍니다.
노정석 네, 승준님. 그럼 오늘 시간 감사드립니다.