EP 80
Will 2026 Be the Year of Science? AI and Science
Passing the Year of Coding in 2025 to the Year of Science in 2026 00:00
Chester Roh Today, as we record this, is December 21st, 2025, a Sunday morning. Yes, the year 2025 is now drawing to a close.
If I were to pick the biggest event of 2025, it would undoubtedly be what started with the release of Claude Code, the year of coding.
In 2026, coding will be a done deal, and it will be a year where science is also finished, by AI.
Stories like this, summarizing 2025 and looking ahead to 2026, are being featured in many sessions.
Today, with Seungjoon, we’ll take a look at those stories.
Seungjoon Choi Yes, the outlook for 2026. So, there are still about 10 days left in 2025. Since today is the 21st.
Chester Roh Yes, ten days left. Exactly.

Seungjoon Choi Yes, but I feel like 2026 is already starting to seep in these days. So, regarding what’s come out recently, I’ve gathered some news from the timelines.
In our previous discussions, we talked about the OpenAI podcast, “The Future of AI and Science,” and Google DeepMind’s documentary “The Thinking Game,” and then stories from the co-founder of Google DeepMind, Shane Legg. We introduced things like that. So we’re continuing to build the context. We mentioned some previews regarding science. In the last 10 days, related news, evidence, and signs have been emerging strongly.
Advances in Science and Mathematics with GPT-5.2 01:32

Seungjoon Choi So, OpenAI published a blog post titled “Advancing Science and Math with GPT-5.2” on December 11th, about 10 days ago. They’ve been releasing their blog posts in Korean lately. So it’s easy to read. Oh, I forgot to put the link here, but I think a new benchmark called Frontier Science was created. Ultimately, when that benchmark is created, there’s a slightly ironic situation where performance improves, and that continues to happen. There was news related to that, and here, the part about GPT-5.2 in that blog post, the case study section, actually had some profound implications. The content is a bit difficult, though.
So, this is about how it solved a problem from what’s called COLT, the Conference on Learning Theory, a problem they made public. They asked GPT-5.2 Pro to solve it, and then experts, through review and verification, managed to prove it. So, in the entire process, the human role wasn’t to provide the mathematical scaffolding, but was limited to focusing on verification and clear writing. So, the model is moving towards doing that work itself.
And the problem being addressed itself has some implications. It was related to something that’s good at this kind of thing. But my personal impression is, up until this year’s coding news, I was able to follow along somewhat, but for the science news of 2026, I feel like I won’t understand it even if I read it. I’m getting that kind of gut feeling.
Chester Roh That’s right. In fact, math, chemistry, and physics go beyond the level we learned in high school or university. There’s a lot of deep content, so our domain knowledge in those areas is significantly less than in coding.
So, it’s a bit difficult to go in and see what all the content is about.
But still, at a general common-sense level, what it is is well-described, so I think we can gain something by looking into it.
Seungjoon Choi And also, by using AI, leveraging AI, if you read the content and make an effort, you can catch on to some extent, but I worry that the feeling of truly internalizing it might not be there.
And next, what was the date.
AI Changes the Speed of the Lab: Biological Research Combined with Robots 03:47

Seungjoon Choi December 16th, so, “Evaluating AI’s ability to accelerate biological research in a laboratory setting.” They say GPT-5 was used to increase the efficiency of molecular cloning protocols by 79 times. But just glancing at the pictures here, the interesting part is the experiment, I mean, the part connected to the laboratory seems quite significant. So it’s not just done through simulation, there’s an image that appears later on, they run these things with a robotic system, and I think they succeeded in creating a feedback loop between actually experimenting and obtaining data. I think they succeeded. Things like comparing what the robot performs with what a human performs are coming out.
Chester Roh I didn’t see exactly what the unit on the left is,
Seungjoon Choi I didn’t look at this properly either.
Chester Roh It’s about 2.5 times faster than what a human did.
Seungjoon Choi So, compared to what a human performed, it did it faster, and the performance was similar.
Chester Roh Wow, the pace of development is just so, so fast. We were talking about pre-training and RLHF really only until August 2024, and all of this started after GPT-5. After the Thinking model came out, how on earth is that made. And then in January 2025, the paper on R1 came out, showing how the Thinking logic is constructed.
After GRPO came out, since then, it seems the belief has dominated that if you can just create a verifiable reward, then it’s just a game the model can solve. That belief seems to have taken over. So, areas like coding or mathematics, areas governed by logic, those areas seem to have been mostly conquered. Now, it has moved on, to the realm of science.
Seungjoon Choi Among the things we covered last time, Period Labs was also related to superconductors. It had a furnace, you know, a kiln, and it was about creating an environment where you can bake things and experiment. It has a somewhat similar feel.
And if 2024 and 2025 were about engineers discovering what they could do with models, now mathematicians and scientists are realizing, ‘Hey, this works in our domain.’
Chester Roh And what many scientists are saying is, the laboratory environment you showed earlier, where humans do the work, that kind of lab environment, where water is actually moving back and forth, and you’re transferring things from beakers, transferring other things, that experimental environment, we call that a wet lab, right? A “damp” lab. That part was actually a complete bottleneck, but now AI can, to some extent, filter out candidate materials and methodologies as much as possible using logic.
Instead, the final reward signal of whether it’s right or not is obtained by direct experimentation. And now that experimental environment is also being automated with robots.
Yes, so those kinds of labs will emerge in large numbers in 2026. Labs that can create verifiable rewards in each vertical, whether it’s chemistry or biology, and biology and chemistry also have many sectors. There are many predictions that it will be a year where such things emerge.
Seungjoon Choi Hearing this reminds me of something. In the Google DeepMind podcast, when you look at the robotic arms or humanoid robots equipped with Gemini 3, compared to the fancy robots that have been emerging in China recently, they are less fancy, but they introduced many robots of the kind that can actually be used in a lab.
About two weeks ago. So I think this is all connected. So, in areas where there was a human bottleneck, like actually handling beakers or handling materials, even in those things, by robots, and especially not just any robots, but robots equipped with reasoning, I think we’ll start to see situations where they are deployed in labs.
Chester Roh For Tesla’s autonomous driving, Elon Musk said that right now, in LLM terms, it’s just an instruct model. But he’s talking about introducing reasoning to it.
Yes, so when the car is in a deadlock or a similar situation, right now it just uses the model to instinctively back up and muddle through. But once reasoning is introduced, I think it will devise a strategy and act.
Seungjoon Choi Those kinds of things are now simultaneously being seen and are scheduled to proceed. In mathematics, there was a very interesting event.
Solving Mathematical Challenges: Collaboration between AI and Humans (Terence Tao’s case) 08:14

Seungjoon Choi So, this is a translation of Terence Tao’s blog. There’s a famous mathematician named Erd흷s, and this is about solving a problem he proposed. It’s written at length here, but I asked it to explain all the mathematical formulas in words. Because when math formulas appear, I find them too difficult. But to give you the TLDR, the key point, is the part that utilized collective intelligence. Online collaboration, so researchers on the Erd흷s problems site exchanged ideas in the forum, and AI tools appear. the automated theorem prover Aristotle, and then Google DeepMind’s AlphaEvolve, these things, I understand that not everyone can use them, but it seems Terence Tao now has access and is using it. So there’s content where Terence Tao used that AlphaEvolve, and then other people ran deep research on literature, things that humans can’t connect or find, doing literature searches to solve problems in a comprehensive way. So this is a very multi-layered story with various units, a story of how humans and AI collaborated to achieve this. It’s quite interesting.
So, how a question that was posed in 1975 was solved… Collaboration happened online, and a certain mathematician used AI tools to get some hints, and while looking at that, Terence Tao thought, ‘Oh, this is a task that AlphaEvolve can do,’ and then after doing that, humans got another idea, leading to the final solution. I haven’t understood all of this in detail either. I just looked at the general flow. The conclusion is, ‘Collaboration is now possible.’ So after doing this, there were also parts that connected with proof assistant tools like Lean, but anyway, the point is that mathematical problems are being solved.
But it’s not just stories about Terence Tao and his circle; they’re repeatedly coming out from other places these days. S챕bastien Bubeck is at OpenAI, he’s a mathematician. So he retweeted a lot of things, and right now, mathematicians here and there with GPT-5… what could this mean? He solved his own unsolved problem regarding intersection numbers in the moduli space of curves. We can tell it’s about mathematics.
So a problem in a narrow domain of mathematics was solved using GPT-5. And this part here is an interesting expression. This is something I pulled up from a later discussion. There’s a lot of low-hanging fruit in mathematics. That can be tackled using AI.
Chester Roh In a domain that is difficult, there are actually quite a lot of low-hanging fruits, is what he’s saying. Yes, but this has implications for us too. Because in our business domains, there are still so many domains we haven’t entered, so within each of them, I also think there will still be many good fruits like that.

Seungjoon Choi Here again, COLT, from the Conference on Learning Theory I mentioned earlier, it seems to be another problem. And GPT-5.2 solved this.
So the story of the proof, the connection with Lean, they even released the prompt, and a certain mathematician introduced those processes, and this is a translation of that. But besides that, I keep seeing more.
S챕bastien Bubeck retweets things, so if you go to S챕bastien Bubeck’s timeline, stories from the mathematics or science fields recently that used such models as leverage are continuously appearing. This seems to be the present state of mathematical proofs. It wasn’t like this last year. There wasn’t much talk like this last year.
Chester Roh Yes, we joke that all the smart people that exist on Earth are now attached to AI, that’s what people say. And mathematicians, physicists, and others, in fact, including doctors and lawyers who used to say AI isn’t there yet, especially those in the professional class, used to say that a lot, but now it seems to have become the default for all of them to work with AI. As a result,
Seungjoon Choi Right. Right. What surprised me at the Fugitive Alliance was that many people came from the medical field.
So anyway, just as Chester mentioned, in an OpenAI podcast episode in early 2025, a scientist researching black holes said, ‘As recently as early 2025, I had a somewhat negative view, but after seeing what’s possible, it just clicked.’ A situation where they just jump right in.
So now many mathematicians, scientists, and people in this field are starting to become like that. It’s a feeling of ‘I’m participating too.’
Chester Roh That’s right. A subscriber on our YouTube channel left a comment, and when we say ‘Wow, this model is really good’ here, we’re talking about expensive models. These are results that come from using models like GPT-5.2 Pro and also doing sophisticated prompting.
But they just throw a single line of an abstract prompt at a free model, and when the response is poor, they make the judgment that ‘Hey, AI isn’t there yet.’ I’ve witnessed a lot of that, and I remember them saying it’s a shame. Learning the techniques for good prompting is still very effective.
Seungjoon Choi Yes, it’s solved when experts ask good questions, continuously and arduously prompt back and forth, and exercise collective intelligence.
Things being solved with just a click like this is not yet the reality of today. And also, powerful models, as you mentioned earlier, using the models at the very forefront, the flagship models that exist, that’s certainly a part of it.
America’s New Challenge: Genesis Mission 14:18
Seungjoon Choi But now, the Department of Defense, the U.S. Department of Defense, that is, the White House, the White House just issued an order. So, should I call it the Genesis Mission, they announced the Genesis Mission. So I’ve translated it all here. Google DeepMind, Anthropic, and then OpenAI have all responded, in a state of ‘we’ll do it together.’
The Genesis Mission, if you skim through it, is ultimately a national science and technology challenge, like the Apollo Project in the past, or was it Russia’s Sputnik? After that satellite was launched, the American scientific community in the 60s became extremely tense and their all-out effort was ultimately intertwined with the development of computers. So it feels similar to that, but anyway, they will proceed with this on a government-wide level.
Google DeepMind also supported the Genesis mission like this, writing a blog post about a ‘national mission’ to accelerate innovation and scientific discovery. So they will provide advanced AI tools to American scientists. So just like Tao could use AlphaEvolve earlier, AlphaEvolve, AlphaGenome, WeatherNext, I think this was probably related to supercomputing, they will do things like opening up access to such things. So these kinds of things have been happening.
So by doing these things regarding participation, the direction is to tackle the challenges we face, from energy to disease to security. That’s the direction they’re taking. And on Anthropic’s side, they briefly mentioned this much. ‘We will participate.’
Chester Roh It’s the Manhattan Project. This is about who between China and the U.S. will reach superintelligence first, and since this part is directly related to national security, a national-level project has now been formed.
Seungjoon Choi That’s right. Before Apollo, there was Manhattan. Jared Kaplan is also a physicist. He was at Johns Hopkins, and although OpenAI and Google DeepMind are sending strong messages in the context of science, when it comes to co-founders being scientists, Anthropic has the most.
So there are many physicists, and they’ve recruited many physicists, so while they are focusing their efforts on coding models here, I speculated that they might have other ideas as well. And OpenAI, saying they would deepen their collaboration with the Department of Energy, covered it in more detail. The contents are all similar.
Chester Roh That’s something to be envious of. Something to be envious of.
Seungjoon Choi So, the context is that these things, there’s a current national mission in the U.S., evidence is emerging, so if we go back to the beginning, back to Demis Hassabis’s interview, I’ll close some tabs.
Analysis of Google DeepMind CEO, Demis Hassabis’ Interview 17:14
Seungjoon Choi You said you saw this too, Chester?

Chester Roh Yes, I saw it. I’ve seen this professor, Hannah Fry, so many times that I’m familiar with her now. Yes, I think it’s the season finale episode.
Seungjoon Choi Right. This year’s last episode of the Google DeepMind podcast. The content was interesting as expected, but the problem is, because I watch so many of these in such a short time, it evaporates quickly. So let’s try to recall our memories as we have this conversation.
Chester Roh I think it’s a conversation that best summarizes the change in perspective, the change in sentiment, that has been around for a while.
Yes, at the beginning of this year, it was all predictions about whether AGI would happen or not, and when, but as we moved into the latter half of the year, it changed to ‘this is a game that will happen, the question is when.’
Now, at this point, as 2025 comes to an end, the biggest point is that… are all saying that this is definitely going to happen. They are all finalizing it.
Seungjoon Choi That’s why Demis Hassabis, too, who is originally a very cautious person, and originally, Google DeepMind’s first mission was to approach AGI. So, in a way, he’s the head of the team that has been doing this the longest.
Looking at it now, Demis Hassabis is now making such radical statements to the point where you could say he’s saying these things.
Chester Roh He always spoke cautiously, and even if someone said it was possible, he used to say, “We have to wait and see.”
Seungjoon Choi Right. That’s why he said the scientific method is most important. That was in 2024, before Google and Google DeepMind merged. The message he put out was that we need to proceed cautiously, and not follow the hype. That’s the kind of person he was.
Chester Roh Let’s take a look at the points. The things Demis talked about.
Seungjoon Choi The beginning was very impressive.
AI and Energy: The Future of Nuclear Fusion 19:02
Seungjoon Choi He talked about the assumption that the energy problem will be solved. So if nuclear fusion is solved, and there’s also SMR, Small Modular Reactors, of course, what would happen if nuclear fusion were solved?
So he started by painting a picture of an age of abundance. The conversation with Hannah Fry, so that story makes you wonder if they’re also working on something energy-related. And it turns out they actually are. With Commonwealth Fusion, they apparently announced a deep partnership.
Naturally, solving this and that ultimately means energy, as we’ve always said, energy and intelligence, watts and intelligence, are interchangeable. We’ve talked about that, right?
Chester Roh That’s right. We don’t say things like “how many NVIDIA GPUs” anymore. This is something Jeongkyu mentioned, talking about computational power in terms of electrical power has become the new unit. So gigawatts, the gigawatt-class, seems to have become a standard.
Seungjoon Choi Exactly. So this sounds a bit like science fiction, but if we solve the energy problem, many existing problems will disappear. He framed the beginning of the talk like this.
Chester Roh Yes, they can all be substituted.
Seungjoon Choi So if energy is cheap, renewable, and clean, if there’s energy produced 24/7, 365 days a year, that will eventually be used for AI. He talked about that kind of imaginative scenario in the beginning.
Then, he said it’s still erratic. He said we seem to be only about 50% of the way there. There are clearly obvious problems, and it’s erratic, but he said that they are not problems that can’t be solved. he said that it’s not an unsolvable problem.
The End of Data Depletion? AI’s Self-Learning and Evolution 20:37
Seungjoon Choi There were talks about data exhaustion, which I think came up later. He said that’s not the case, we can generate as much as we want, and then, moving away from human-dependent data is also part of it now, this part.
What’s missing today is online learning, that is, continual learning, which is currently missing, but between the lines, he implied they are working on it. We could read into such things, like in the previous Shane Legg episode, and so on.
Then, Hannah Fry asked about this part, about Google DeepMind’s previous stance. Should they have kept it in the lab for longer? But Demis, after merging Google DeepMind, has been very involved in releasing products, and he said there are advantages to that. So they lost some things and gained some things. If they had kept it in the lab a bit longer, they might have been able to solve cancer, he even said something like that. If they had focused more on making things like AlphaFold, and focused more on that, they might have solved those problems.
But by actually releasing products, there were many things to be gained, many possibilities. He said things like that. Right.
And then it created a crazy competitive situation. So in that kind of situation, it’s difficult to do rigorous science, but they are trying to strike a balance. This part was also interesting.
Also, interestingly, the general public is actually only a few months behind the cutting edge. So everyone has had the opportunity to feel what AI is. And governments have also come to better understand the path towards AGI, he said.
Chester Roh At a dinner a while ago, I happened to meet Jeongkyu again, and he said this. “What you, Chester, are saying about” “Elon Musk or Sergey Brin” “seeing the frontier several months ahead of us” “is probably wrong.” “At most, they’re probably seeing it about a month earlier.”
He said the gap between the frontier and its public release is much smaller than you’d think. That’s probably due to the competition between China and the US, and between OpenAI and Google. Things like that must have had an impact, but conversely, from the perspective of ordinary people like us, hobbyists, people who can’t participate in training due to lack of capital, from this standpoint, it’s a happy world.
Because they’re letting us in on it.
Seungjoon Choi Of course, let alone $200 a month, even 20,000 or 30,000 won (about $14-21) a month is a bit of a cost, so it might not be for everyone. But the barrier to entry is incredibly low right now, isn’t it?
Chester Roh And the $200 plan, until around this spring or summer, was something most people didn’t use. But now, people who spend $200, I see them very often. So that means it’s more than worth the money.
Seungjoon Choi But the problem is, the horizon of perception is also erratic.
Chester Roh The gap has widened enormously. Between those who follow the AI frontier and those who are trying to get there somehow, whom we’ve defined as “fugitives,” and those who have decided not to, the gap has become too wide.
Seungjoon Choi Anyway, these are the times we live in.
Then, another thing he talked about was about scaling. So here too, with synthetic data and so on, he said, “Anyway, we never said scaling doesn’t work.”
So now, this part, this paragraph is interesting. Even if it doesn’t always shoot up like this, there was always something to be gained. It’s not a 0 or 1 situation. Because there’s something in between, I read it with the nuance that “we were continuously scaling.” I read it with that nuance.
Chester Roh To get a numerical sense of this part, while I was reading the Nemotron paper, I felt something like this. Usually, to train these frontier models, the number of tokens used is over 20 trillion. About 27 trillion is the total number of tokens used.
But what’s interesting is that among them, the parts for math, science, or core logic, like with Qwen 30B and others, we’ve seen in previous papers, they are continuously improving the quality of this pre-training dataset. But the amount of such high-quality dataset that they say is “this much” is still less than 1 trillion tokens. It’s about 500 billion.
Since it’s a number around 500 billion, the unrefined, raw pre-training data is also constantly improving in quality in the background and being rewritten. So even in that area, I believe scale continues to dominate. It’s a completely different area from RLHF, just the pre-train domain, but there too, as the dataset quality continues to improve, the yield per unit of energy gets better. So there’s still a big upside here as well.
Seungjoon Choi And since it’s bootstrapping, once the system gets good enough, it generates its own data. In domains like coding or math, where the answer, the answer can be verified in some sense, it can produce unlimited data. Hassabis said something like that.
Chester Roh So, talks about the limits of scaling, that it’s a wall, are fading as 2025 comes to an end.
Seungjoon Choi 50% is spent on scaling, 50% on innovation. So even in the existing regime, they are trying to scale, and in other methods as well, they are striving for innovation. He said that.
The hallucination problem, hallucinations still exist, but it will likely be solved. He wasn’t certain or precise about it here, but anyway, he spoke of it as improving. But of course, he did admit it. It’s still there.
Simulating the World: The Potential of World Models 26:33
Seungjoon Choi And he talked about the world model. He mentioned things like Genie, Veo, and SIMA. This part was actually very sci-fi and an interesting story.
So if we go a little further here, in the end, Demis Hassabis, from the very beginning, He has a gaming background, doesn’t he? So things like theme parks, or famous simulation he developed those kinds of games in his childhood. “This is a problem that can be solved if it can be simulated.” With that kind of thinking, he’s now introducing things like SIMA or Genie.
Genie is for generating environments, right? In real-time, SIMA is an agent that goes into that environment and can act within it. So, what would happen if a SIMA agent, equipped with Gemini’s reasoning abilities, were to continuously solve problems within the environment created by Genie? He talked about this.
Chester Roh Then, those problem spaces that we can’t define, those problem spaces, will all be solved through search. And he’s saying that all problems can be solved. If given infinite computation.
Seungjoon Choi That was back in August. So Genie came out, entered this space, and could actually navigate. That’s what it was, but SIMA came out in November. So within that, this is actually inside a game like No Man’s Sky, exploring it. It’s an agent that can enter any game. But internally, what they’re trying to do now is connect Genie to SIMA and do things like creating worlds on the fly. I’m forgetting the paper right now, but there’s also a paper about that that Google DeepMind released. The one that created that loop. I’ve seen so much information, I’m a bit hazy, so there might be errors, but anyway, I think I saw it.
Chester Roh Exactly. What I feel from what Demis is doing is, Demis and Elon Musk say similar things, but what Yann LeCun or Sutton say is a bit old school. In fact, regardless of the model’s structure, if you remove as much inductive bias as possible, make the model general, and put infinite computation into it, the idea that there are no unsolvable problems is their basic perspective.
In fact, Transformer, well, it calculates attention between languages, but they put it in as a general logic, add images, and are using it for everything. So, in the end, once you pass a certain threshold, another formal system will emerge and solve everything. They are also saying this, and looking at examples like Genie or Veo, they say that even though it was simply trained, doesn’t it have a very sophisticated physics engine? That’s what they say.
So personally, for AGI and ASI, I think that the Transformer architecture or models of this type are architecturally somehow limited. That kind of old school talk from Yann LeCun or Sutton, I think that kind of talk is meaningless.
Seungjoon Choi Demis says something similar, that current simulations have visual-level precision, but they don’t have truly perfect precision. But the direction is to try to achieve that. Can it withstand a proper physics-grade experiment? He talked a bit about things like that.
So, regarding this simulation, he talks about his long-held thoughts, mentioning some experiments from the Santa Fe Institute, and talks about how economic structures and such emerge in a grid world, and also talks about consciousness.
So Demis’s thought is, “If it can be simulated, then it’s possible, isn’t it?” He touches on that here and brings it up again in the latter half.
Is AI a Bubble? Comparison with the Industrial Revolution 30:26
Seungjoon Choi So, moving on, this question was also interesting. Hannah Fry asked point-blank, “Is it an AI bubble or not? And what happens if the bubble bursts?” So what Demis candidly admitted was, “There is a bit of a bubble right now.” “Part of the AI ecosystem is probably a bubble.”
But regarding it bursting, about what would happen if it bursts, he didn’t give a direct answer. He said Google, Google DeepMind, is safe even if it bursts.
He pointed out what we are hedged against, what kind of foundation we have, and things like that. We have TPUs, how our research is structured, and while talking about those things, he said, “We’re fine if this direction continues, and even if it doesn’t, we can still do well.” He boasted a little about that.
Chester Roh Yes, but this is also what CEO Jeongkyu talked about at that dinner, and he also talked about it when he was on our podcast before. “Isn’t this too much of an over-investment?” He said it would soon be in surplus, right? He said it was the end of computing resources, but what’s already being discussed as a real-world example is that 97% of our internet traffic is Video. It’s YouTube and Netflix. Only 3% is used to move text and other such data.
And for token generation, for us to use a million tokens with Claude, how hard is that? Even if we use a lot, it’s 250,000 tokens, something like that. But in reality, on some nanobanana, just generating one image is 25,000, and if you generate about 30 seconds of Video, you use up hundreds of thousands of tokens.
So this area will grow even bigger in the future, so this is just the beginning. Here too, most of the tokens will come from this multimedia, meaning Video and such content. Things like text, coding, science, and logic will be a very small part of it, he said. Yes, so that made sense.
Seungjoon Choi Yes, you had an interesting dinner.
Chester Roh Yes, that’s why this semiconductor investment cycle, it’s not a question of whether it’s an over-investment phase, but should be seen as just the beginning. Yes, and it’s not widely known yet, but people like Jinwon Lee, whenever I meet people who work on chips, they say, “I want to develop something, but I can’t buy RAM.” Not even HBM, just buying LPDDR, the next delivery is a year from now, two years from now.
And Samsung has sold all its LPDDR, doubled the price, and so on. So the memory super cycle has started again. So what does that mean?
Seungjoon Choi Since Jinwon’s name came up, we should invite him sometime so we can also talk a bit…
Chester Roh We should hear about semiconductors.
Seungjoon Choi So here, the echo chamber part is about sycophancy, what is it? It’s about flattery, but I’ll skip it for now.
So this story about AGI is now connected to the previous Shane Legg episode, and this part introduces a bit of what’s happening in connection with that. Anyway, we are getting closer to an AGI for something emerging. So, a candidate for proto-AGI right now, if things like Genie, SIMA, and so on are all integrated, it seems it could become a candidate for proto-AGI.
And this part was also interesting. Lessons from the Industrial Revolution. About the Industrial Revolution, he said he’s been reading a lot of books recently. Demis said that when it comes, in terms of mitigating some of the chaos, he felt the need to study that history again, so he read up on those parts. But here he says it will be 10 times bigger than the Industrial Revolution and happen 10 times faster. It will unfold over about 10 years, not a century. Related to the Industrial Revolution, it happened over almost 200 years, as I recall.
Chester Roh But what we consider the practical period is about 100 years. We look at the period from the late 1800s to the late 1900s.
Seungjoon Choi But the world was in chaos back then. Even then. But if it happens within 10 years now, it means there will be even more chaos, in fact.
Chester Roh To bring it back to a real-world story, back then, it happened over generations, so if the parents became unemployed, the children could live in a world with new jobs. But now, it’s a world where parents and children become unemployed at the same time.
Seungjoon Choi It’s not something to say with a smile, but it’s just so absurd.
Chester Roh Yes, it’s not something to laugh about, but that’s right. But in the end, the government system will become much more important, I think.
Wealth will be extremely concentrated in a few companies, and then with what’s gained from there, a real universal basic income, or going beyond universal, Sam Altman calls it a massive income, right? Much more.
Seungjoon Choi Right, right. There are people who talk about something that isn’t basic income.
Chester Roh In ‘26, in fact, the productivity changes that accumulated in ‘25 will become a reality, everyone is predicting. Mass layoffs will actually happen at companies. As early as ‘26.
Seungjoon Choi So, in fact, that ties back into the energy discussion. If the energy problem is solved, a significant part of that kind of economic pressure or the kind of pressure individuals have to face could be resolved, couldn’t it?
Of course, even if the energy problem is solved other problems will still be intertwined, but anyway, this has many things that I feel are interlocked and running together.
Chester Roh Let’s not go too far into social discourse.
Seungjoon Choi I agree. But it’s what Demis said. Demis covered a lot of that in this episode. So he talked about a new economic system, things like that.
Chester Roh For now, quickly adapting to change is what we’re aiming for, so let’s adapt quickly.
Seungjoon Choi Well, talk about post-AGI and such is something Shane, Shane Legg is said to be leading the thinking efforts on. So with some economists and the government, he talks in that context. So here, what I said a moment ago was that.
He heard interesting things from his economist friends and hopes there will be more related work, and there’s a philosophical aspect too. Jobs change and other things change, but maybe nuclear fusion has been solved. So if there’s abundant energy and it becomes a post-scarcity world, what happens to money?
Everyone lives better, but what happens to purpose? Because many people find purpose in their jobs and find purpose in supporting their families, and that’s a very noble purpose. But if that disappears, then these questions blend from economic questions into philosophical ones. He talked about this in this episode.
Anyway, and for things like that, international cooperation is necessary. But it’s not happening as much as one might think. So to get everyone’s attention, what kind of incident or accident would be needed? To that, he said most labs are responsible, but since there are also open models, not everything can be controlled.
So if a somewhat manageable incident were to happen, wouldn’t that be okay? That rogue AI, rogue, the term “rogue” refers to the side that does dangerous things, right?
Chester Roh Yes, rogue. Yes.
Seungjoon Choi Yes, that’s right. There’s a Rogue in X-Men, too, but anyway, so it means delinquent. It’s hard to stop rogue states or rogue organizations, but if something of a medium scale happens, it would be a warning shot.
Then international cooperation or standards might be established better. He also talked about things like that.
What are the Limits of AI? 38:05
Seungjoon Choi So, is there anything that only humans can do? But there are no limits. So this part, in fact, is something that Chester is also interested in and is very connected to. Demis also seems to be a believer in computation.
So, in the von Neumann architecture, using the Turing machine method, there’s no evidence yet of something that can’t be achieved. He said he would keep pushing forward with this method. So everything can be replicated with a classical computer.
So here, one, Fry asked a challenging question: sitting here, feeling the warmth of the lights, hearing the machine sounds in the background, the tactile sensation in your hands, all of that with a classical computer can be replicated, Demis says, he pointed that out once more.
So Demis talks about two philosophers. He talks about Kant and Spinoza, and I didn’t know Spinoza well either, so I looked him up and some interesting things came up.
The simulated world is important. What are the limits of what can be simulated? If you can simulate it, in a sense, you have understood it. So what Demis is thinking was revealed a lot in this episode.
Chester Roh That adjective “Isomorphic” used up there…
Seungjoon Choi Isomorphic, yes. It’s another company where Demis is the CEO.
Chester Roh Yes, Isomorphic Labs, it’s a biotech new drug development company. Also, the adjective “Isomorphic” is a key adjective in “G철del, Escher, Bach.”
Seungjoon Choi Really? Is that so?
Chester Roh Yes, it means that ultimately, everything is governed by relationships, and all that remains are the relationships. Whatever the medium may be, if the relationships are identical, then it’s the same thing. It’s the principle of isomorphism.
Seungjoon Choi I hadn’t thought of it that way. I should take another look at it. So Demis also said this, he can’t sleep. He’s excited for various reasons, but he also has a lot of work and is doing what he’s dreamed of.
Chester Roh He stands at the absolute forefront of science in many fields. Noam Brown also said that before. Waking up in the morning and seeing how much the frontier has advanced is truly a certain… he used the word “privilege.” A privilege, yes.
Seungjoon Choi That’s right. Yes, he said that.
Chester Roh I’m envious.
Seungjoon Choi Since a lot of time has passed, if we just move on quickly, yes, things like the relationships between AI leaders, and the concerns, and then, this is ultimately about concerns and expectations. And the interesting part here is Demis’s mission is to help the world safely transition to AGI.
Post-AGI is a job for other people. Of course, if they call on him, he’ll participate because he’s a cooperative person. But my mission is to help the world safely transition to AGI. And he wants to take a sabbatical.
After that, he said things like that and concluded this episode. I think this episode revealed more about who Demis is than ‘The Thinking Game’ episode. He said a lot of very honest things.
Chester Roh People who use their brains a lot seem to lose their hair really fast. Like Ilya Sutskever,
Seungjoon Choi Well, of course, there are people who don’t. So we’ve covered that here for a bit. So, a person named roon is rumored to be one of OpenAI’s tech staff, but it hasn’t been confirmed. But he tells a lot of interesting stories, and here, he made a counterargument against some criticisms of AI.
Was it today? He posted it early yesterday morning. So, similar to the stories we introduced today, roon also touched upon them. We can see new forms of organizations being born with machine intelligence as a first-class factor of production. This part was quite memorable.
Chester Roh That’s what we’ve been calling AI, AI-native companies these days.
Seungjoon Choi With machine intelligence as a first-class factor of production, new forms of organizations are being born. He said things like this, and interestingly, I asked it to fact-check the highlighted part of what this person said, and these days, GPT-5.2 does fact-checking well, ironically. Even though it’s an LLM model with hallucinations, since it has tools to investigate, you can see that it does fact-checking quite well. It’s interesting.
Mostly true, partially true, and for that, it even provides accurate citations and says it’s well-founded. It’s a fact that Terence Tao did this. There is strong speculation. It’s difficult to say for certain. This part is false, with a very high possibility of exaggeration. So even if you just ask it to do a fact check once, these are the kinds of things that come out these days.
Andrej Karpathy’s 2025 AI Year-End Review 42:52
Seungjoon Choi We’ve already been at it for almost an hour. The year-end review, Andrej Karpathy did his annual review again, and I think it’s already been circulating a lot on the timeline. So, what happened this year?
Also, Karpathy is quite neutral, so things like ghosts vs. animals, new layers, Cursor, LLM, and Claude, Codex, then vibe coding or innovations in image models, LLM GUI, so the Generative UI side also had big things happen in the latter half of the year. Yes, and the conclusion was “Fasten your seatbelts.”
Chester Roh One of our company’s engineers was talking about that. AI writes the entire UI layer, and our company builds everything on top of Next.js. Why do we need to use Next.js? We can just use native JavaScript directly. He was saying things like, let’s get rid of that framework.
Seungjoon Choi These days, anyway, there are many things to talk about related to that, and various things come to mind, but due to time constraints, I’ll move on for now.
Gemini 3 Flash came out too. Yes, it’s fast. Of course, the performance might be a bit lacking, but there must be spaces where it’s a perfect fit. So anyway, it’s out.
Chester Roh That’s right. Yes.
Seungjoon Choi And anyway, Flash came out, so models are continuously being released. Christmas is four days away, but it feels like they’re still not resting. When are these people going on their year-end vacation? They’ll go soon, I guess.
Chester Roh I wonder if they can’t go, don’t you think? Yes, this is almost a game of chicken. They keep coming out, yes.
Seungjoon Choi Right.
There are reasons why they’re coming out.
In fact, OpenAI is also at a crossroads right now, although “crossroads” might not be the right word, anyway, they’re under a lot of pressure, and right now, whether you call it needing to press each other down or whether you’d say they need to confirm it, or prove it such things are continuously happening, even though it’s the end of the year.
Chester Roh OpenAI and Google are kind of pulling ahead as the two leaders and Anthropic dug a coding moat, but that part is getting a little bit thinner I get that kind of intuitive feeling.
Seungjoon Choi There are also rumors about Sonnet 4.7. So maybe that has the performance of Opus 4.5 with the speed and other aspects of 4.7. I’m seeing speculations like this on my timeline. But nothing has been confirmed yet.
Recently, Claude had some outages, and there were strange speculations about whether the outages were due to them experimenting with models. There were some strange speculations like that.
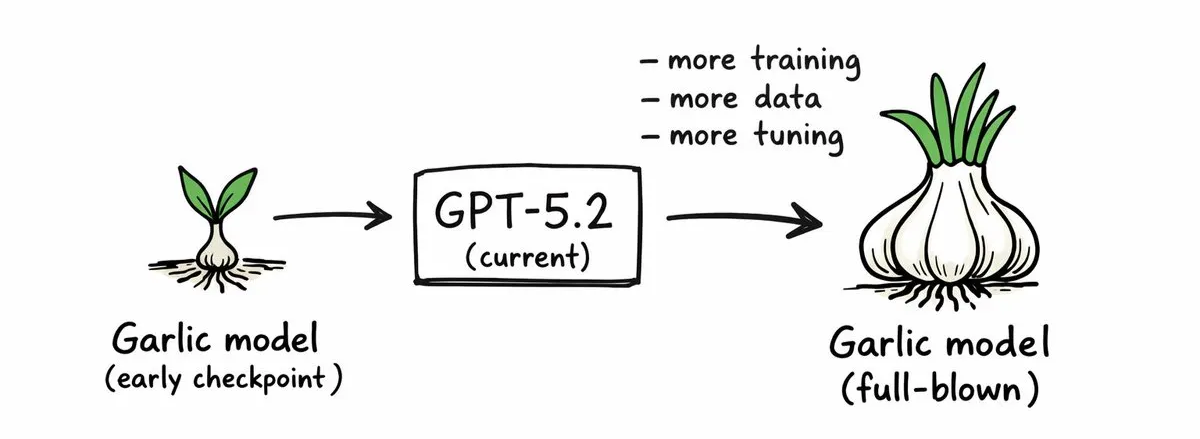
Then, regarding GPT-5.2, this was from an article in The Information. There’s a rumor that it’s just an early checkpoint. So they’re continuously releasing things like this.
And this GPT-5.2, the basis for it is what we talked about last time, the second version of… what was it? Was it Shallotpeat? Not that model, but a model codenamed Garlic. This is an early checkpoint, and we’ll see the full-blown Garlic early next year. That’s the talk.
The Future of NVIDIA Nemotron and Hybrid Architectures 45:54
Seungjoon Choi And Chester, you said you looked into it quite a bit, NVIDIA Nemotron, what is it?
Chester Roh NVIDIA Nemotron is a model that NVIDIA has fully released, just like Llama. The reason I’m looking into it with interest is that the datasets, training recipes, including the code, are all publicly available. Since everything is public,
Seungjoon Choi So it’s not just an open model, but open source.
Chester Roh It’s completely open source. And from NVIDIA’s perspective, they need more people doing these kinds of things, so by creating these recipes they have a strong incentive to distribute them to everyone. Because more people doing this means far more people will buy their chips. But Nemotron, regarding the things we’ve discussed so far, like pre-training, SFT, then RLHF, then RLVR, then math and science, then coding, the datasets for these areas, these parts too, they’ve released everything, including what they made themselves, and how it’s all structured is all just uploaded to GitHub, so I’ve been looking at it diligently these days.
For me, just intuitively, in response to the question, “Where should we run to?” as an answer to that question, first is, of course, solving real-world problems using the harness of the current frontier models. That’s one thing. But another sense of d챕j횪 vu I get is that the efficiency relative to computation is continuously increasing. The improvement of algorithms, the growth of datasets, the opening of datasets, because of these things, perhaps at the level of what Andrej Karpathy called a “cognitive core,” even with under 10B parameters, models that can perfectly cover a single business will likely emerge. And companies that provide training for such things, companies with RLVR environments, will probably emerge as a new kind of SI company. But if there’s a difference, it’s that to do such things, the amount of basic information you need to have is immense, and that’s the difference.
So, because I think that kind of world is coming, I believe that in addition to creating harnesses, this model work, including training, then fine-tuning, RLVR, and the evaluation loop, needs to be held within any given business logic. That’s what I’m thinking. So our company is also trying to internalize that part.
But going back to Nemotron, the topic of SSM and Mamba came up in a big way about 1-2 years ago, maybe a year and a half ago. It was a big topic once, and around the end of ‘24, places like Falcon were creating Mamba-based models. SSM and Mamba are really interesting. We should do a review sometime on how these were created, I think that would be good.
But just speaking from intuition, we first had RNNs, right? With RNNs, de facto language modeling was done with RNNs. But because at the very end, with just a single context vector, it had to infer the entire context, the performance wasn’t great. So what came out of that was the attention model. It took all the hidden activations from the context that came in as input before, and held onto them, and used them again each time it performed an inference. So by using attention, it was shown that this problem could be completely solved. And what came from taking just that attention logic is the Transformer. So what the Transformer solved was, RNNs are very efficient for inference, but training couldn’t be parallelized, so you had to read the entire sentence to train it. And in the process, problems like vanishing gradients or exploding gradients would occur. That was the issue. What solved this was the Transformer. But the bad thing about the Transformer is, it can be parallelized, but when it calculates the attention logic inside, if the length always gets longer during inference, if the context length increases, the computational load increases quadratically, O(n짼). That was the problem with the Transformer. Of course, numerous logics to solve this have emerged, like grouped-query attention or, in the computation process, things like FlashAttention, and many parts have improved, but still, the efficiency of RNNs is unbeatable.
So a very, very obvious question arises here. What if we could take only the strengths of RNNs and only the strengths of Transformers? What if we could have a very efficient structure during inference time like an RNN, and be able to parallelize during training like a Transformer? How great would that be? What created that intuition was SSM. And what solved a few of the problems that SSM had is Mamba. If you look at it, the parts in between are just like an RNN, very similar in feel, and the paper itself, I feel, is just a mathematical trick. It’s interesting. What’s interesting is that this Nemotron is completely Mamba-based. But the problem Mamba has is, it’s like an RNN, summarizing the sequence into a single context vector, whereas attention is about continuously calculating the relationships between tokens. So RNNs are good at summarization, and Transformers are good at remembering relationships. They each have their pros and cons in these areas. The models coming out these days are called hybrids.
For example, the current Transformer models we’re familiar with have dozens of so-called Transformer blocks stacked up. Nemotron has about 8 Mamba blocks stacked, with self-attention on top, and an FFN in between. In an MoE fashion, the FFN is included in the same way, and then another 8 Mamba blocks are stacked, with one attention block on top of that. So there are about 8 or 9 of these groups that make up the structure. So out of a total size of 30B, about 3B are activated, and it’s incredibly fast. It’s several times faster. I think this was born about a year and a half ago, and this hybrid, this too is a kind of new algorithmic gene. I think the world will move forward a lot with this model, because the advantages of this hybrid approach are overwhelmingly large in terms of computation, and then inference time. With much less computation and a smaller model size, it produces results that are slightly better than a Transformer. Saying it’s “several times better” seems a bit risky right now, but because they are releasing this, my personal prediction is that the next generation of frontier models will also very likely move towards this kind of hybrid Mamba plus Transformer hybrid model.
Seungjoon Choi What you just mentioned, describing it as an “alternative gene,” that expression is a very important point in a way. An alternative architecture, in reality, there wasn’t enough investment to scale it up, but if it’s shown to work, then architectures can be swapped out, springing up all over the place.
Chester Roh Right. So not many things like this have come out. There are only a few, but Nemotron is consistently pushing in that direction.
If it’s proven once again here that with a small amount of computation, you can create a model comparable to the frontier that fits their own domain, then in fact, all verticals will jump in this direction, and the incentive to do so will arise.
So from NVIDIA’s perspective, it’s good because they can sell more of this framework and their chips.
And from the perspective of a company like ours, equivalent to this frontier knowledge, recipes, and even code datasets.
So I thought this was something worth looking into deeply.
This Nemotron fine-tuning and RLHF, I am thinking about trying it myself.
Seungjoon Choi So in the end, as you mentioned at the beginning, it seems we need to hedge a bit. Just as we’ve been doing with the existing frontier models, the harnesses for the models that are already out, we need to build those, and where possible, for model work, we should also look at the current situation and dig into it.
Because we don’t know where things will go, we don’t know where we’ll get gains.
Chester Roh Yes, but we can’t give up on models because right now, most of the value capture, the part that captures value, is all with the model companies. So companies that aren’t model companies all have to compete in a very thin layer.
Seungjoon Choi As you briefly mentioned earlier, there are companies like TML that handle new forms of infrastructure, and other such companies exist. So anyway, there was talk like that, and if we go deeper into it next time, it will be another interesting session.
Chester Roh Let’s have an SSM chat sometime.
Latest AI Model Trends, including Xiaomi 54:40

Seungjoon Choi Xiaomi, Chester mentioned this, so I looked it up, and Xiaomi is doing it too.
Chester Roh I haven’t read the paper, just the abstract, but it’s not like they just took another model and copied it. They really did it from scratch. So…
Seungjoon Choi Korea is also doing things from scratch these days. So China is really surging ahead right now, which makes me feel a sense of tension.
Chester Roh My feeling is that China is just at the US level. From what I see, yes.
Seungjoon Choi In a way, they are the two powerhouses right now. Anyway, these are the times we live in. And then, there’s another model from China. It now separates out the layers like this. So the generation is done in layers. It’s not about extracting layers.
Chester Roh I’ll have to try this out.
Seungjoon Choi And Yao Shunyu, who was at OpenAI, moved to Tencent.
Chester Roh He’s a star researcher, and he moved to Tencent.
Seungjoon Choi So, I’m tired now, so I don’t know if I can cover this, but Simon Willison has come back down to earth a bit and written about things we can do today. He posted a really interesting article.
So, this thing called JustHTML, it wasn’t made by Simon Willison, he was quoting the story of the person who made it. There were some very interesting stories about it. About how it was done.
So, they created a huge number of tests and made progress in very small increments to port something or create something new, and he laid out that process.
When I read this about a week ago, I found it quite interesting, but now I don’t remember it that well already. But if you’re interested, if you look into how this was actually done, I think you can gain some insights.
Wrap-up and Preview of the Next Episode 56:31
Seungjoon Choi So, even though it’s the end of the year, the news every week and information just doesn’t stop.
Chester Roh Because the machines are always running. The pre-training code and RLHF code are running vigorously even at this hour, so maybe that’s why.
Seungjoon Choi Exactly. Do we have a chance to record an episode to wrap up the year?
Chester Roh Probably so. We have about one more. On the 27th, with Seonghyun, we’re supposed to have a recording to wrap up the year, aren’t we?
It will probably be about “How did the frontier advance this year?” That’s what the topic will likely be. I think we’ll get to talk about models one last time then, don’t you think?
Seungjoon Choi To wrap things up, there shouldn’t be any new news, so we can do a retrospective. It’ll be a problem if there’s more news that week. Alright, let’s stop here for today.
Chester Roh Yes, we’ve skimmed through things again today.
Seungjoon Choi Yes, it feels like we only skimmed. We didn’t go deep into many things, but yes, I understand.
Chester Roh Yes, thank you for your hard work.
Seungjoon Choi Yes, thank you.