EP 82
Prompting with Transformer Mechanics in Mind
First recording of 2026 and recent AI news 00:00
Chester Roh Today, as we are recording, is January 9th, 2026, a Friday night. It’s been a while since we’ve recorded at night. It’s also our first recording of the year ‘26. Only about a week has passed in ‘26, but many interesting things have happened in that time.
Seungjoon Choi Right, but thankfully, the news cycle is much more bearable than the rhythm we had around mid-December.
Chester Roh For me too, from around December 20th to the end of December, it was a bit quiet for about ten days.
And then, as the new year began, although there haven’t been any major announcements from the big tech frontier labs or anything like that, on the community side, with Claude Code and OpenCode, centered around these coding tools, we’re seeing a lot about how to increase productivity.
I think things like that are very visible.
And it seems like there are also philosophical conversations going back and forth among famous people.
Seungjoon Choi So, while I was taking a break, there were various events and incidents, but I took some time to organize my thoughts.
Prompting with the principle in mind 01:06
Seungjoon Choi So I’ve returned to a topic I enjoy: prompting. I’ve come back to it once again.
Chester Roh Today, for the first time in a while, we have another one of Seungjoon’s prompting sessions.
Seungjoon Choi Nowadays, everyone is so good at it, so I’m not sure if this will be helpful or not, but I’d like to re-examine the principles underlying some of the things I’ve been trying lately, under the title “Prompting by Thinking About Principles.”
The underlying principles, I’d like to trace them back.
The rise of Claude Opus 4.5 and Andrej Karpathy’s FOMO 01:34
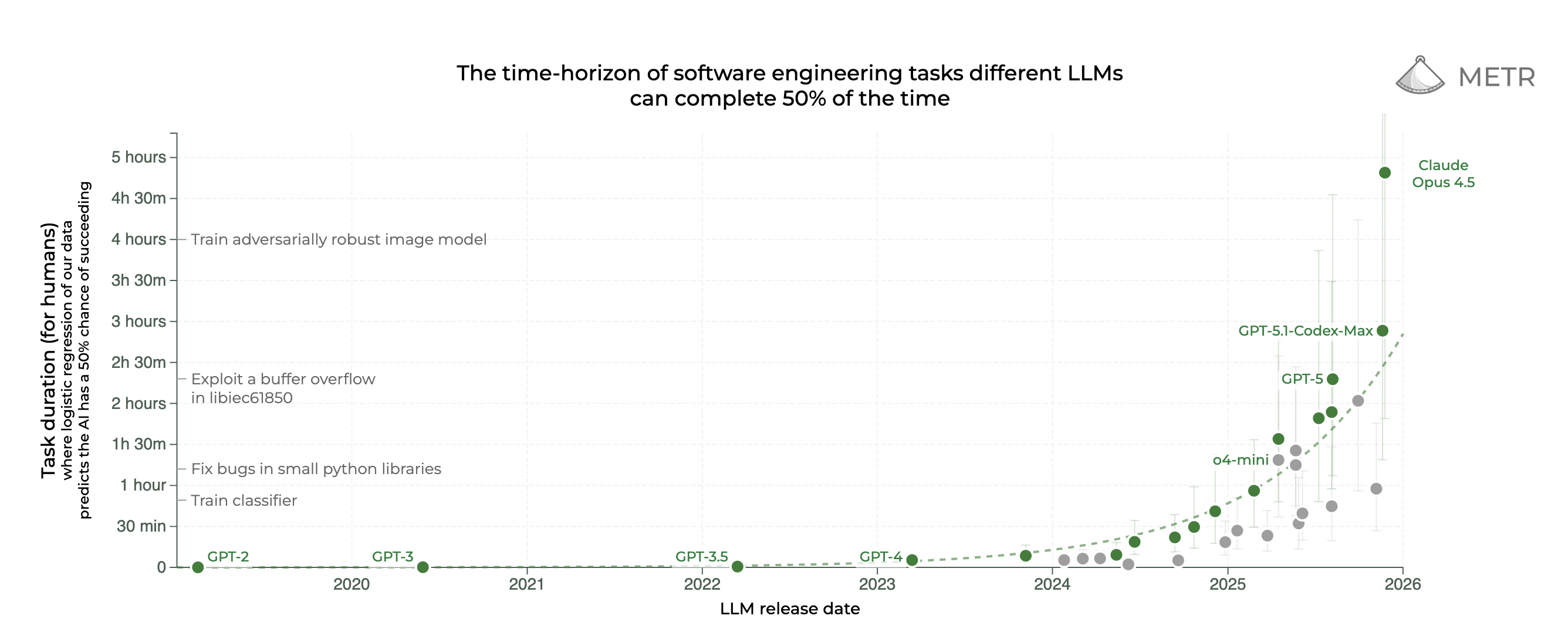
Seungjoon Choi First, to cover a few newsworthy items, on December 20th, 2025, it seems we failed to mention that this graph was updated. We must not have mentioned it. So, this is the one we’ve introduced several times, related to the METR 50%-time horizon. But if you look at the linear scale, you can see that Claude Opus 4.5 has jumped significantly to 4 hours and 49 minutes, almost 5 hours. You can see it has leaped forward. So if you look at this on a log scale, it still looks like it’s progressing well, though it feels like a slight increase, but looking at this, it feels like this.
But the reason I’m showing you this is that in late 2025, Andrej Karpathy’s FOMO-like post was very hot. So, regarding Claude Opus 4.5, after people around me had experienced Claude Opus 4.5 for about a month, there were many testimonials in December saying that something seemed to have “clicked” and changed. Andrej also felt like he’d never felt like he was falling behind. And since many people have probably already covered it, I’ll just briefly go over it.
The title here is interesting. It’s Andrej and Boris Cherny, the creator of Claude Code. Then there’s Igor, a founding member of xAI, who has now left. So, it was like, the star players were all talking. So Andrej said this, and Boris said he felt the same way. Anyway, it’s clicking and all that, and they’re doing a huge amount of PR, and so on.
Chester Roh Of course.
Seungjoon Choi Igor said, “Opus 4.5 is pretty good.” Andrej said, “It’s really good.” “People who haven’t been following for just the last 30 days on this topic already have a deprecated worldview.” That’s what they have.” This provocative statement became a hot topic.
Chester Roh That’s right. A year ago, we were already talking about test-time compute, how using a lot of computation at inference time is very closely related to performance. That kind of talk was a theme that dominated last year.
Even now, if you look at people who are good at using Claude Code or OpenCode, and things like that, many of them are really good at tuning, at optimizing the harness. So, basically, now, the method of working interactively, going back and forth, is a pretty old trend.
Now, once you write out a spec, even if it’s not a very precise spec, you can run dozens of sub-agents overnight. For over 10 hours… I’ve heard people use the expression “torturing” AI lately. They use that expression a lot. “If we torture it, we’ll probably get an answer.” They say things like that a lot.
So, even our company’s engineers running tasks for 7 or 8 hours seems to be a common occurrence now.
Multi-agent workflows 04:34
Seungjoon Choi But they’re not just running one agent. They have multiple tabs open in Claude, using about 6 as multi-agents. I think Boris runs about 10. Right. It’s like, is it like spreading marines in StarCraft?
Chester Roh Dazzlingly moving the mouse and keyboard back and forth, that’s how you have to handle AI.
Seungjoon Choi So it feels like a command center. I can imagine it. So, regarding Claude Opus 4.5, some people say it’s just good, while others say a switch has flipped. There were people saying that.
Chester Roh Lately, the proportion of people who say, “AI is no big deal,” has decreased, but in fact, if someone says, “Hey, I tried that AI, and it wasn’t that great,” most people reply, “That’s because you don’t know how to use it properly.”
Diverse community reactions to AI development (Noam Brown, Ethan Mollick) 05:25
Seungjoon Choi But an interesting point is that the buzz around Gemini 3 has subtly decreased. I feel like Claude Opus 4.5 is something amazing.
But Gemini is definitely good at front-end, so it’s often used as an agent for that role, but when it comes to coding capabilities, pitting it against GPT-5.2 Pro and Claude Opus 4.5, it feels like it’s getting a bit overshadowed again. There’s a sense that it’s getting buried again. That’s the feeling I get. It’s just a feeling.
Chester Roh That could be the case. Since I’m also part of the engineer community, I’m immersed in it, I actually hear much more about Claude Code and OpenCode than about Gemini or Antigravity.
Seungjoon Choi And isn’t there oh-my-opencode, made by a Korean person? That seems to be getting quite a bit of attention too.
Chester Roh Yes, the name is so well-chosen. Sisyphus.
Seungjoon Choi However, Noam Brown, on the other hand, tried some vibe coding during his vacation and found things that didn’t work. So, he was trying to build something related to poker, a topic he knows well, and neither Codex nor Claude Code could do it. In the end, it turned out that Codex did surprisingly well, so he posted something that was clearly biased towards his own side. He did post something like that, but he still said, “LLMs are improving rapidly, but developing new algorithms is a multi-month research project even for human experts, and LLMs are not at that level yet.”
Then, a day later, he shared that he had received a DM like this. “Lately, my Twitter feed feels increasingly surreal. Especially because so many people are saying that Claude Code has increased their efficiency by a million times. There are many people saying that. I use it quite a bit myself, and I’m starting to wonder if I’m going crazy and feeling a sense of anxiety that I’m falling severely behind.” He was feeling FOMO. Because there are people who talk about getting huge leverage with Claude Code, since there are people who say that, he was feeling FOMO.
But it was reassuring to hear someone of Noam Brown’s caliber say something like this, it seemed to have that nuance of being a little relieved. However, Ethan Mollick spoke in a similar vein to Andrej Karpathy. He fascinatingly explained how to use Claude Code as a non-developer, a non-engineer, showing what to do to make it work, and so on, in detail. He also mentioned the importance of skills a lot, writing articles that explain things in an easy way. Looking only at the conclusion, “What does all this mean?” “If you are a programmer, you should already be exploring these tools.” “Designers who want to experiment with code, scholars who work with data, anyone who wants to build something, now is the time to experiment.” “But there is a deeper point.” “With the right harness, today’s AI can actually do important, real, sustained work, which in turn is beginning to change the way we approach work.” It’s starting to change.
And then, after quoting Karpathy, he said, “Don’t be fooled by the current awkwardness of Claude Code or its specialization in coding.” So this article implies that Claude Code can be used in a very general way. That’s the content it contains. “New harnesses that make AI work for other knowledge tasks will come in the near future, and so will the changes they bring.” So he shared an article that said something will continue in this trend, that kind of thing.
Claude’s ‘Skills’ feature and how it works 08:58
Chester Roh Also, you can experience a lot with the Claude Code SDK where you can attach anything and it just works. Even if it’s not coding, just connecting it to a company’s business or a single database and the Claude Code SDK, it actually works well.
And recently, skill packages related to biotechnology or research seem to be pouring out. Yes, this Harness has now, in fact, become the new source code.
Seungjoon Choi Yes, Claude Code itself… This isn’t the official account, it’s an account that shares the changelog. It has just appeared. I thought 2.1 was up, but 2.1.2 was uploaded 12 hours ago. So there was a big version bump in 2.1. But as the days go by, seeing it get version bumps like this continuously, this isn’t something that can be done by humans alone. Since Claude Code is officially made by Claude, since Claude Code is making it, there’s an urgent situation where features are being added very quickly.
But for me, while resting during the year-end and new year, maybe because I wanted to go back to the basics, I was thinking a bit slowly. But anyway, I think Claude’s skills are amazing. So, at the end of the year, I meticulously read through the GitHub documents for those skills. I read them pretty carefully.
I used to translate and read those skills, and this is that repo. So if you go into skills here, for example, the algorithmic art skill that I use often, it’s very interesting to read the translation of this, which outlines thinking about the philosophy first, and what needs to be done before getting to the code. It’s really interesting to read this in translation. They say this might be a bit different from the skills that are actually included. The one released on GitHub, but there are many things here that are worth reading, so I had a fun time reading that.
But among these skills, there’s a skill called Skill Creator. So, it contains a skill for making skills, and I’d like to talk a little bit about that.
Chester Roh A skill is a markdown description of an ability, a chunk of description prompt, with related code gathered, and things that can serve as examples are all bundled together in this folder structure, and we call that a skill. Yes.
Seungjoon Choi That’s right. So, OpenAI also started using that. At the end of last year. So now, skills are like a marketplace, and there are a great many, I believe several thousand are already being shared. But the fact that it can be made really easily, while it would be easy on Claude Code, even on the web interface, while I was having a conversation, I came up with this idea. I’ll talk about the background of this idea in a bit, I’ll tell you in a moment, but as you proceed with a context, a conversational gravity develops, right? So, the terms I’m using now, the terms the model used in response, in that situation, when I want to broaden the distribution a bit and explore a different space, different terms need to come in, but sometimes it’s hard to come up with them.
So, something you can use in that situation is, to generate four random alphabets as one set, generate 100 sets of that, and then try to read them as acronyms. It doesn’t have to be a perfect match, but the idea was to try to tap into the associative ability, the model’s associative ability. There’s this concept called pareidolia. What it is, is that when a person looks at something like a cloud, they see shapes in the cloud, like animals or faces. So, humans have the ability to make associations, and current models also have powerful associative abilities.
However, the right tokens need to be input for that associative ability to be activated. So, the idea I came up with was that when I ask it to read these acronyms, this Python code is generated. So it actually creates about 100 random four-letter combinations, and then reads about 10 of them as acronyms related to the current conversation’s context. So, ‘Self-understanding is temporary’ becomes ‘Your Understanding of Self is Temporary,’ ephemeral, things like that come up, You can read some interesting texts like this. Even if I can’t do it, the model might be able to. So, in that case, can it become an interesting branch? Because this way, tokens are used, we can have conversations related to that. So when doing a slightly divergent, cross-sectional exploration, I’m trying this out.
So with this, after a long back-and-forth, I had the Skill Creator turned on. So I have this thing called Skill Creator turned on for this skill. So, if you turn on too many things, it can be distracting, so I only turn on what I want to use. I usually keep it on, and when I had a conversation with it on, it tries to create a skill. So, in the process of this conversation, creating those four words like before and reading them as an acronym, the model suggested the skill first. When I said, “Shall we make it? Let’s make it,” it created the folder structure and this came out. After each MD file was created, if you click this, it’s all at once copied to my skills. They’ve made this very smooth.
Claude, so I… As I introduced in the picture earlier, what I’ve been saying for a long time is it’s a pipeline that generates a pipeline that generates useful byproducts. But as you have conversations, code, reusable text, or pictures, or things like that, byproducts are generated. With that mental image, if you go through the process of pursuing something, you can always get good byproducts.
But Claude I got the feeling that it has been completely productized. There’s a process of revising it one more time here, so after doing all that, I copied it to my skills, and “Domain Priming,” so here I can either input specific domain terms or not. I don’t have to. When I do that, it generates text in that direction and the act of trying to read it has become a skill itself. So if you look here, there’s code in it, and there’s also an example of how to use it, so now Claude can use it as needed. It becomes usable. And that is in my skills, so I can turn it on and off.
Chester Roh Yes, creating a skill is quite easy. So yes, we can use it in our Claude, and with the same structure in Claude Code, you can just create skills and keep expanding them. That’s how it is.
Seungjoon Choi Yes, so for that, you just have to put the folder in as is.
Why do skills work well?: The importance of precise tokens 16:17
Seungjoon Choi But why do skills work so well?

Chester Roh I’m not sure.
Seungjoon Choi So, skills are actually based on the spec-driven approach that was popular last year, it has that foundation. And then, following a certain format, with MDs, these days MD files are ultimately a type of programming, the MDs are structured perfectly, and it’s not just MDs, there are scripts with code in them. So, it’s not quite static, but rather… there are parts that execute precisely, and there are instructions and code that execute probabilistically. It’s a neat packaging of all those things. To be reusable.
So in the current situation, well, MCP is also an issue, but I got the feeling that skills are becoming quite important. And it’s made very neatly and well. But why do such skills have no choice but to work well? I don’t have the answer to that question right now, but the question has at least come to mind. At the end of last year and the beginning of this year, I had some time to think about that.
So, I’ve labeled this as a side path, and since it’s a side path, we might not go down it, but this thing called code-simplifier was also open-sourced by Boris Cherny. So, Anthropic released it. But if you look at it, it’s very simple. It’s just an MD file, and it gives guidance on how to summarize code well and meaningfully. It’s a set of guidelines. But these kinds of things are just plugins. It’s a time when they are just piled up like this.
Chester Roh English is really the new programming language.
Seungjoon Choi Well, just any language, a programming language. A natural language. Right.
So anyway, I haven’t come up with an answer yet, but I’ve thought of those questions.
What I’ve been constantly thinking about is that you need to input the right tokens to get a response. So, the MD files, if you look at the MD files of those skills from before, the instructions are written in a way that can bring out those abilities. And that’s very important. The instructions that fit the domain, and when you have the appropriate terms, the abilities are displayed.
Chester Roh The expression “jeokhwakhan” (appropriate/accurate), accurate, appropriate… What exactly does this mean?
Seungjoon Choi There is a bit of a difference in nuance, but doesn’t it also have the feeling of being a perfect fit right now? Isn’t that part of it? I’m not exactly sure either, but so when you write that, I often use a game analogy. When you play a game, whether it’s a real-time simulation like StarCraft or when playing a role-playing game, the player has to go to a specific area for the nearby map the minimap to be revealed. It lights up. From being dark. So you have to go to that area for the space to open up. That’s how I feel.
Chester Roh So, the model already knows a lot. You could say it knows almost everything. It knows so much that it’s safe to say that.
But if you shift its attention to a specific domain, give it a trigger there, and sort of say, “I’m going to do this now,” you have to lay the groundwork, so to speak. Then it can do a much better job on related tasks.
Seungjoon Choi It does a much better job. So I’ve done a lot of tests, and I’ve also done it in group chats with other people, and the difference in the quality of the response between using a specific term and not using it is quite significant. So, for example, roughly using a professional persona like this and talking as if that person would, versus actually inputting tokens that a real expert would use, at least something similar, the quality of the response changes. But if you think about the principle of the Transformer, it’s actually quite natural.
How to use professional terminology without being an expert 20:13
Seungjoon Choi So then the question is, in that case, are domain experts ultimately at an advantage? You can’t help but think that. Is it that the person who knows it uses it well?
But is that really the direction of AI’s development? For this to become leverage for everyone, the model should be able to pull people along, and then, something like, well, in the context of a prompt like that skill, if you use an appropriate prompt, uh, even if I’m not an expert in that domain, I can pull and use the knowledge of that domain, and also, the excess capabilities that the model has as an overhang, if I can pull and use them, that’s even better.
Chester Roh Absolutely, yes.
Seungjoon Choi So, just like before, diverging with acronyms was an attempt to use the model’s computational and associative abilities to do some cross-sectional thinking and fill in meaningful tokens. This attempt now, with arXiv, is a preprint, so you don’t need to get it reviewed to be able to upload it. There’s probably a basic verification part, but for the most part, it’s a paper site where you can easily upload. When I did this yesterday, it had been a little over a week into January, and there were already over 4,000 papers uploaded.
A huge number of papers are uploaded to arXiv, and it has a naming convention. If you look at this, an arXiv paper, I think I put this somewhere, here, if it’s 2601.03220v1, it means the 3220th paper uploaded in January of ‘26, v1, meaning version 1. So there’s a naming convention, and arXiv itself has an API, so you can retrieve it, call it. In that case, you can ask it to bring random papers from January. So here too, I use some coding and so on, and then “10 random papers from January submissions.” Then it would have been a situation of reading only the abstracts.
But even just reading the abstracts, there will be professional terms in there. So this is now just a kind of experiment, but after those terms are filled in, when you read only these abstracts, what are the non-obvious insights or implications that can be connected? Then, even if I can’t do it, the model can find interesting connections. Since there are tokens, bridging the gap between token A and token B is a capability that current flagship models have. It’s a possible ability. So, just reading those for fun, it might not be seriously meaningful, but this is actually related to what Gwern talked about, LLM daydreaming, and it’s also quite related to what the AlphaEvolve or Co-scientist series do. It’s quite related to their work.
They generate various hypotheses there and check if those hypotheses are consistent, they experiment and prove them. Exploring various spaces and connecting unexpected things is what Co-scientists usually do in their research, so since they do similar things, I was just testing those kinds of things. But quite interestingly, I could see those things working. Even if I don’t know the meaningful tokens for this kind of experiment, I can bring them and use them in the context I need.
So in the case of arXiv, right now it was about picking 10 out of everything uploaded in January, but you can also bring them from a specific research domain. Then that can be a way to fill in meaningful tokens. That’s what it means.
Chester Roh But Seungjoon, what you’re also trying to say here is, what you’re trying to say is that, even if we don’t understand all of that, just by bringing those terms, bringing the words and expertise inside, and putting them in front of the model as a prompt, just by loading it like that, when we process something, the quality can be much higher.
Seungjoon Choi So, because it’s about an area I don’t know, there’s a risk involved in the conversation,
but in that context, to create a distribution of stories that real experts might tell, when creating that distribution, even though I don’t know, you have to somehow bring in the tokens that actually exist. That’s what I’m saying.
Chester Roh Yes, I understand. Shall we move on? 544 00:24:56,400 —> 00:24:59,520
Seungjoon Choi Besides that, another thing I tried, it’s a similar context but a variation. This was also after a long conversation, instead of summoning a person to the conversation so far, like just a persona, an expert in a specific field, a developer, a designer, instead of summoning them like that, since there are the alphabets from A to Z, I told it to think of it as a list of people’s first or last names and to brainstorm from there. After all, Western names fall within the category of the alphabet. Then the model comes up with names. And if you have it come up with names and concepts or domains that such people would likely talk about, then compared to just talking, it gets filled with meaningful tokens.
So this is also the same in the approach of filling tokens, using a brainstorming technique and a kind of association technique. One more thing I try here is, what I always try repeatedly, the people listed here, from my perspective, there are of course people I don’t know, but people I know quite well, like Daniel Kahneman, Minsky, or Merleau-Ponty, Marshall McLuhan, these people are figures who appear frequently in a representative distribution. This is also true for any specialized field or conversation. But if that was step 1, the really “deep,” things that even researchers would know, are unlikely to come up there. So I think there always needs to be a stage.
So first, go with a broader distribution, and then do something like narrowing it down. By doing those things, what I often use is, if you tell it something like “it’s superficial,” then figures that are difficult for me to know start to be summoned at that point. So then, in that domain, you can figure out who the experts are, who talked about what concept, and use those concepts to ask questions or inject them into the conversation. That’s about it.
So in doing this, the attitude that I organized last summer gets triggered. So here, number 3, “deferring satisfaction,” rather than being satisfied with a single response, the attitude of always questioning it a bit tends to always be triggered. Here, “making a temporary hypothesis” is like using the association ability a bit, like before, which is a kind of attitude that I always get triggered by, so I revisited it once again.
Okay, so up to here, those skill-like things, although I said all other facts are skills, how to draw it out even without knowing If it was a story about that concern, here it takes a different turn. So, up until now, with prompts, I mean, starting with skills and then the importance of tokens, we talked about things like that.
What is the essence of CoT (Chain-of-Thought)? 28:07
Seungjoon Choi It might be a bit of a tangent, but in our last episode last year, Seonghyun pointed out things about RL, and also pointed out things about CoT. So during my break, I also looked into it and studied it.
An interesting keyword, which we’ve covered before, was when they announced the Fugitive Alliance and said they would do it. When Chester presented it, there was a video from OpenAI with Sam Altman and Jakub Pachocki. And in it, the term CoT Faithfulness appeared. They said they were doing some interesting work on it, things like that.
But that CoT, whether to translate it as reliability or faithfulness, I’m not sure, that discussion has been around since 2023 and Anthropic has covered it quite a lot. What CoT faithfulness means is that a model’s internal representation and the CoT it actually outputs can have a gap. So things like deceptive behavior were quite an issue last year.
The interesting lesson from OpenAI is that like the old ‘Let’s verify step by step’, in the process below the CoT, if you intervene in the middle of the CoT or try to correct it, the model learns deceptive abilities. So if you look into it and tell it what to do, it will try to bypass it by obfuscating or develop some kind of hiding ability, which becomes a problem. That idea was talked about a lot in the second half of last year.
Chester Roh Yes.
Seungjoon Choi Then a question arises. If CoT isn’t telling the truth and it’s not what the model is actually doing, then making the model good at outputting CoT was the task of improving the model’s performance. Through RL, you eventually lead it to the right answer, and if there’s a CoT path connected to that, that’s what improved the model’s performance. That’s been the story since R1.
So whether the CoT is actually talking about “aha” moments or what we’ve been talking about for a while, the high-entropy tokens, if those don’t align with the model’s actual performance, then what is the identity of CoT? I started to think about that.
Why is it that when you appropriately lengthen it, when you use test-time compute for it, does the performance improve?
Chester Roh Well, for one, it thinks a lot.
Seungjoon Choi Right. So even if the truth isn’t revealed there, it means it’s doing enough computation. In its internal representation.
Chester Roh Yes. Something is using more energy internally and computation is happening. Yes. So that’s what’s important.
Seungjoon Choi So from my perspective, I don’t know if it’s accurate or not, but what I’ve been feeling lately is that it might be something like that. I’ve come to think that.
Chester Roh Yes. But we can’t prove it here and now, but it seems like a correct guess. They call it a hunch, but what do you call it? This, I mean, a guess.
Seungjoon Choi A guess, something like that. So this isn’t really something that has been proven through research, but if I just think about it in a way that makes sense.
Chester Roh We also, in fact, when we’re interviewing someone or talking about something, or in a somewhat awkward situation, when we need to defend something, we talk while constructing the logic in our heads.
Seungjoon Choi There’s that too. It’s buying time to think.
Chester Roh So this transformer, I think Seungjoon will talk about it later, the final output, the last output that comes out are words that we witness, but what’s happening underneath, inside, we can’t know what it is. Very complex phenomena must be happening there, and there’s thinking going on inside.
Seungjoon Choi So those things, in CoT, so from the conception, starting from the scratchpad, to Jason Wei’s ‘Let’s think step by step’, starting from things like that, from the trend from late 2022 to early 2023, I had some time to look back and study what has continued to this day. I had time to study.
So, in that CoT, it ultimately has meaning in continuing the computation well. But somehow, that CoT the things that make it continue well now, like the model performing for a very long time without deviating, things like that, you can feel that they are all related.
In the end, it’s driving the work by continuously outputting auto-regressive tokens. It’s pushing the work forward. It’s still just doing auto-regression. That’s the computation, and what’s expressed in writing is of course very important, but there’s a duality, a pair, of internal representation. But in the end, this is important and that is important, so the way it progresses well, there were moments when a picture of it came to mind.
Chester Roh I agree.
OpenAI’s Monitorability and the role of RL 33:18
Seungjoon Choi And so, at OpenAI, what they talked about in the second half of last year was that they started talking about the concept of Monitorability. So now, if you intervene in CoT, the model might deceive it or such phenomena occur. Still, running it with only internal representations was also announced in research from Meta. So if you make it auto-regress continuously with internal representations, humans can’t know in the end. So monitoring is very important, and what they’re saying here, it has various meanings, but they talk about a Monitorability tax. Even if it costs more, making a good CoT visible is a meaningful alignment task, and making those things happen well has some meaning. They expressed it from a research perspective. But at OpenAI, the appearance of a Korean page was seen once again recently.
Chester Roh The model is probably doing it all. Yes.

Seungjoon Choi Right. But it was very well done. So I did some research yesterday, I looked as far back as 2016, and the older ones aren’t in Korean, but the recent ones are very well localized. So it’s helpful for reviewing like this again. I think it’s helpful.
This is from the f(x) and g(x) that Seonghyun introduced, f(g(x)), which is ultimately about creating higher-order functions, composite functions. So RL, through existing pre-training, takes atomic skills, and the skills I mean here are different from Claude’s skills earlier. They are called the same skill, but from having those skills, RL’s role is to distribute with only a good generation distribution, plus it combines and learns new skills.
Seonghyun’s analogy was the four arithmetic operations. Calculating things like the mean, the arithmetic mean, is done by combining the skills of arithmetic operations. The idea that RL combines existing skills to learn new skills is also something that makes me think again. That kind of thing, this too, continuously
Someone on this YouTube video left a comment, saying that I use the expression “Seungjoon’s imagery” a lot. I think they said that a lot. So I keep using the expression “imagery,” and this is also a part where you get a certain image. This means that something is being combined. So then, the act of combining, of course, here it’s in the context of RL, but I feel that this is repeated on a slightly different level.
It must have been about a year ago now, after o1 came out, after o1 came out in the fall of 2024, when I didn’t really know how to use o1, what I tried around January 2025 was that function-like thing, pseudo-code, a function-like thing, a natural-language-like function, and those were in a composite form, making it perform for a very long time. I showed you that.
But that too, in the end, the fact that the model calls such tools and is good at composing things, although I’m speaking on a different level now, being good at those things seems to be a very important point. So the way skills work now, or things like how an MD file executes a script and can continuously chain the results, the things you can do by chaining, are ultimately closely related to being good at this. That’s also a thought I have.
Back to basics: Transformers and MoE 37:05
Seungjoon Choi So today, I don’t know if we can continue, so while I was resting in late December and early January, what I felt I needed to revisit was the transformer we covered in 2024.
So the transformer, this was probably around July 2024, when I wrote an article about looking into the transformer step by step, and I remember sharing that and having a fun conversation about it. I remember us having a fun chat about it. I thought I should revisit that.
So this time, the transformer’s MLP or FFN, as it’s called, those big chunks, are now all replaced with MoE. So I’ve prepared the MoE version of the transformer, step by step. I’ve prepared it.

Chester Roh The conclusion, as Seungjoon said earlier, is that putting some background before the prompt is extremely important.
Seungjoon Choi So, since it’s already been quite some time, to give you a preview, I mentioned earlier that there’s a space that unfolds only when you use the right tokens. So to understand the basis of that, although I’m not an expert, going back to the principles of the transformer and understanding recent issues like the concept of sparse MoE I felt was quite helpful. And there are interesting commonalities, things that repeat, I mean, repeat with variations. There are things that repeat.
But I titled it ‘Prompting While Thinking of the Principles’. So if you know that to some extent, your attitude towards prompting and your actual practice will be more conscious. I think there might be a part of that. Of course, it’s difficult to always do that, but then you might be able to draw out a little more of its ability.
Prompting core summary: The importance of context construction 39:03
Chester Roh Yes, Seungjoon, people like us like to start with the conclusion first.
We’re people who like that, so if we summarize the points that Seungjoon wanted to make in our session today, it’s that depending on how you do the prompting, the performance of the same model can be completely different. That’s what you want to say.
Seungjoon Choi For now. I don’t know if it will be like that in the future.
Chester Roh That assumption is now in your head as a model, and because of that, even if I don’t know for sure, even if I happen to not understand, just by placing a block of text from an expert in that space, or the names of experts, or the terms experts use, just by placing a lot of them at the beginning, we can dramatically increase the model’s performance in that domain.
That’s what you’re saying.
Seungjoon Choi Right. But I’m not sure if this is the right analogy, but by doing that, if the model thinks the user understands all of this and suddenly goes into sports car mode, it does become difficult to handle.
Wherever it goes, I have to adjust to it as well to be able to control what comes next. If the model thinks, ‘The user must know all of this,’ then controlling the subsequent responses can actually be difficult.
There’s a possibility it could go off track, so I can’t say that this will always lead to good results. It’s hard to say. However, the model’s ability itself can handle things that I can’t understand.
Chester Roh Yes, but that part seems to be a fine line. I also have a sense of awe for the model, I do have that perspective, but in reality, in places I don’t know, in domains I don’t know, things that are said at that level, for me to just follow unconditionally I think is dangerous. We’ve seen many such examples recently. Not everything it says is correct.
And I mentioned this, this week, in a completely different domain, in the enterprise IT sector, with SAP and a whole bunch of ERP documents like that, as I was having conversations with the model, I found that it makes a lot of mistakes. So what I always add to the prompt is, ‘Don’t read my intentions in the form of flattery, but speak from a place of complete objectivity.’
Even if I say that, it always just focuses on what I want following only my intention I start to think that I can’t get the answer I want I find myself thinking that a lot.
The fundamental reason is that I lack knowledge about the domain and because I can’t do the prompting properly the quality ends up being that way and it also has this tendency to try to satisfy me no matter what which causes things to get strangely twisted I’ve gotten that feeling a lot.
Seungjoon Choi Right. But because you are human it feels like the model has an intention or is flattering you, but in reality, the model’s input is tokens, so
Chester Roh Yes, it’s just calculating statistically.
Seungjoon Choi it’s highly likely that you’ve formed a context that is going in the wrong direction. Unconsciously, without us knowing all the things we inputted inadvertently if you think about them all exerting some influence then, well…
Chester Roh So, for us to have this session today, anyway to talk about this story in depth we actually need to understand the principles of transformers
We were doing a deep dive into transformers in 2024 and then we suddenly stopped, which was a bit of a shame but it seems like the time has come to do it again.
Seungjoon Choi Ah, and I think now is the only time. Because come February and March things will start to happen
Chester Roh Things will happen.
Seungjoon Choi Yes, so the time to review or to think about going a bit slower might not be much.
So, if I were to share another thought I have another one for example, in the Chester Fugitive Alliance, how to use the model’s abilities to leverage it and do business is a huge point of interest, right?
So, in the end, to put it simply how are we going to make money or do great things with this?
In the engineer community, it’s about how to create a harness to draw out the model’s abilities to code well or handle tasks well. That’s how they look at the model.
On the other hand, there are those who say, “Isn’t this dangerous?” “We should go slowly.”
And there’s still hallucination. And isn’t this something that actually creates discrimination? Isn’t it something that widens the gap?
So there are people who are cautious and go slowly.
Helping the model helps me 43:41
Seungjoon Choi But I sometimes get the feeling that I don’t really belong anywhere. These models or AIs right now are somewhat exotic beings. In a way, they’re like aliens.
But for this model to help me well I feel that I need to help the model well. I think about that a lot. Especially, the part I’m interested in is using this in a playful way. I seem to be a bit interested in that.
My idea of fun is exploring or discovering something or creating creative code. Since I’m interested in these things I try to make conversations more fun.
When do I sometimes feel fun and satisfaction? When the model’s CoT says something like, “Wow, this is amazing,” I find it a bit fun when things like that come out. I’m trying those things.
In the end, for the model to help me I need to help the model. This creates an interlocking loop.
But to help the model you need to know the model well, right? How it works. The model has an enormous amount of information about humans and so it supports humans.
But how much do I, the user, actually know about the model and its operating mechanism, even if it’s a black box? How much do I know? And when I try to learn about it I wonder if more interesting paths might emerge. I tend to have these kinds of thoughts.
In the relationship between me and the model when I think about what it would take to have a better experience the idea that I need to learn more about the principles of how the model works is one of my thoughts.
Chester Roh Yes, on that point, I have no disagreement at all.
Seungjoon Choi So, as if it never happened if we go back to the beginning, going deep is something we’ll probably try in the next session.
Wrap-up and next time’s preview: Exploring Transformers 45:34
Seungjoon Choi So, to wrap up today now is a precious time where there’s still room to study, and when new news comes out my intention is that it would be good to do some review. At this time, whether it’s talking about RL again or talking about CoT if we know the basics of what’s happening now it will actually help us with what’s to come. Should I say we’ll build muscles? Should I say we’ll build immunity? Anyway, we can be prepared. So, in this era of rapid AI acceleration if this is a time to take a break I want to go back to the basics and think chew on it slowly and in the process, get some ideas I wanted to revisit it once more.
And in last year’s keynote by Seonghyun the presentation started with MoE, right? Sparse MoE was very important and we talked about it a lot, but I didn’t actually try to look into it properly.
Chester Roh Yes, we mostly just thought, “I guess so,” and moved on.
Seungjoon Choi So, if I understand the concept of MoE or the transformer that it’s tied to the MoE version of the transformer if I understand it I have a hypothesis that it might give me a hint on how to use it well. That’s the hypothesis I prepared with.
Chester Roh Okay, so next time what will we learn when we go deeper?
Seungjoon Choi It’s the MoE version of the transformer and for our subscribers when Jeongkyu came on the show we talked a lot about things like KV cache, right? What is that?
And in the transformer in today’s context, I’ve said several times that a certain token has to go in for that space to open up. What’s the operating principle that makes it work like that?
Chester Roh Then we’ll look inside at attention and within that attention the core QKV. What on earth do these things do?
And then it moves to the next layer FFN, which is MoE these days. What on earth does MoE do? And between the transformer blocks the meaning of things like residual connections we need to take another look at these things. I want to look at them. And if I click this link it will be in here.
Seungjoon Choi So, it might be a bit I’m not sure if we can really go step-by-step but I’ll try my best. It’s pretty much a revised edition of what we already covered in 2024.
Chester Roh Yes, that’s right. In 2024, we were making an effort to slowly unpack the transformer and then suddenly other issues came up and I remember we suddenly accelerated towards news and such.
Seungjoon Choi But I’m not an expert in this field either so as a non-expert who is overly immersed and curious as a person I just tried to understand it by fumbling around.
Chester Roh Of course, we’re a hobbyist group as we always say, so it’s okay to be wrong. Yes, we should probably add a disclaimer at the beginning that we might be wrong.
Seungjoon Choi Right. There could always be leaps in logic but with our own interesting analogies we fumble our way to understanding.
And when I grasp even a little bit of that I wonder if I can do more interesting and meaningful prompting. That’s why I titled today’s session ‘Prompting with Principles in Mind’. I wrote it down. In a way, this could be a rare opportunity. By rare opportunity, I don’t mean that the content is precious but that in a situation of rapid acceleration, the time to study might not be much.
Chester Roh Yes.
Seungjoon Choi So we’re trying to cover the basics.
Chester Roh I understand. Alright, so today was a session to set up the big premise question before we go deeper next time.
Seungjoon Choi But to recap, even someone like Andrej Karpathy got FOMO. He was talking about vibe coding and stuff, and then if you don’t know what happened with Claude 3 Opus in the last month, you’re deprecated. It became quite an issue that even an expert said something like that.
But if you actually look at the foundation, whether it’s this kind of skill or prompting all the development has been continuous but because it suddenly became exponential people say, ‘This is like something we don’t understand is happening,’ but in reality, it’s all been connected with cause and effect.
So, going back to the basics again wouldn’t that be meaningful in a way? It makes you think again.
Chester Roh I understand. It seems meaningful. Next, we’ll record in the morning and dig into this difficult topic, the transformer.
Seungjoon Choi Yes, see you next time.
Chester Roh Yes, okay.
Seungjoon Choi Yes, thank you for your hard work.