EP 88
There Is No Secret
Opening: Reunion with Seonghyun 00:00
Chester Roh Today, as we’re recording, is March 1st, 2026,
a Sunday morning.
It’s been a while since we’ve had Seonghyun on, and
our last episode of the year was filmed with Seonghyun,
and looking back at the changes in models last year,
the tremendous advances in RLVR,
and the efficiency gains from architectures like MoE,
those were the highlights we pointed out.
We also discussed what to watch for in 2026,
and wrapped up with some predictions — and just two months have passed.
So there have been a lot of changes, and also not so many,
and today, with Seonghyun back after a while, we’ll hear his reflections on the past two months
and try to predict what’s coming next.
Let’s give it a shot.
Welcome, Seonghyun.
Seonghyun Kim In previous sessions, we usually picked one topic
and talked about it in depth.
But I thought a lot while preparing for this session.
Over the past two months, I kept thinking on and off about
what would be good to talk about when I came back,
and it was quite difficult.
For instance, when it comes to deep technical details —
take the recent hot topics like
DeepSeek’s Engram or MHC —
I could go deep into those, but my own perspective
seems to have shifted a bit.
And I’ve also been wondering how important those issues really are right now —
I’ve had thoughts like that.
Why It’s Hard to Pin Down a Single “Technology” 01:17
Seonghyun Kim So rather than sticking to a single topic,
I thought it’d be better to cover
a variety of topics and share my reflections.
What I’m thinking is,
DeepSeek V4 will likely have a lot of technical innovations
done in that very DeepSeek-esque way,
with plenty of intricate details.
But regardless of how
interesting those techniques are,
it would be hard to present them here as
some kind of paradigm shift or breakthrough innovation that suggests
“this is how things will go from here on.”
That’s a difficult narrative to construct.
Even if DeepSeek V4 comes out,
saying “these advances happened,
so AI models will evolve in this direction,
and such-and-such will become possible” —
that kind of claim feels a bit hard to make.
So the theme of this session
isn’t so much about any specific technology or its advancement,
but rather a survey of various topics — and that’s why.
I wrote “Technology” on this slide,
but what I really mean is — this is more of an excuse for
why it’s so hard to talk about
any one specific technology right now.
GLM 5 Report and RL-Driven Innovation 02:23
Seonghyun Kim It’s not DeepSeek V4 yet, but recently
a very interesting research report came out at the frontier level,
and that was GLM 5.
It was a report from Zhipu AI,
and it contains quite a lot of fascinating technical innovations
and details.
To summarize very roughly, there are three things.
First, making RL more efficient —
for example, things like Sparse Attention,
and also
infrastructure for RL, like async RL —
things like that.
There are numerous technical details,
and a large portion of them are about
making RL more computationally efficient.
Reflecting context length more efficiently
to run RL more efficiently. The next one is
tweaking things like the RL objective slightly
to make training more stable — that’s another one.
And the third is making RL more diverse.
I’ll probably talk about environment scaling toward the end,
but the idea is to expand RL to more diverse tasks
by increasing and more efficiently scaling the environments.
These are the major themes.
In this GLM 5 report,
the numerous innovations
are almost entirely related to RL,
and the overarching direction of innovation is about making RL
more efficient, more stable, and more diverse.
Yao Shunyu’s The Second Half: RL as the Answer Key 03:40
Seonghyun Kim Thinking about this reminds me of
Yao Shunyu’s “The Second Half.”
In “The First Half,” there were benchmarks,
you developed methods to tackle those benchmarks,
and once a benchmark started getting solved,
you created new benchmarks —
it was an era driven by methods, as he put it.
But moving into “The Second Half,” we’ve found the answer when it comes to methods —
we’ve found the answer key, so now we just take that answer
and apply it to various problems, and that’s it —
that’s how he framed it.
It’s a statement that can come across as quite arrogant in a way,
but at the same time, it’s been remarkably accurate — at least
over the past year, from 2025 to now,
I think it’s been spot on.
Everyone agrees RL has become the answer — the answer key — and the effort to do RL better
and to scale RL further
has been the overwhelming focus, and it’s even more so now.
When we say “technology” or “technological innovation,”
what comes to mind most is innovation in methods,
but when it comes to innovation in methods,
there’s honestly not much interesting to say,
because it’s still RL.
All we can do is keep repeating
how much further RL is being extended
and deepened — and that’s the feeling I get. So
for me to take a technological trajectory and say
“this technology is evolving this way
and will evolve in this direction going forward” —
that felt a bit difficult.
Because at the very least, RL keeps being applied
and keeps advancing incrementally — that’s something we can predict,
and it’s what’s happening right now.
Does a Secret Recipe Exist? 05:16
Seonghyun Kim In that regard, I started thinking about
the concept of a secret recipe.
When we say a frontier model has
a secret recipe, I think that’s closer to
innovation in methods.
that those people hold some unknown secret,
and without knowing that secret you can’t build the model —
you start to believe that kind of thing exists.
Of course, there have been many significant innovations.
Like with GLM 5, there have been many innovations,
and many improvements.
Those improvements exist, and I’m not denying them,
things like MoE and so on
were all tremendously important innovations.
But it’s not that they were hidden
or some recipe that was extremely hard to figure out.
Rather, if you’ve been watching from GPT-3.5 until now,
they were all things that could emerge and be discovered
through the gradual process of improving and developing models.
That’s what it feels like.
If anything came closest to a secret recipe,
I think it would be RLVR.
Beyond that, most of them were important innovations, but
not the kind where you absolutely can’t catch up without knowing them,
yet they’re incredibly hard to discover —
I don’t think they were that type
of secret recipe.
Of course, part of the reason I feel this way is that Chinese companies
discovered or developed all these secret recipes on their own
and made them known,
so they no longer feel like secrets.
That might be part of it too,
but that’s how things feel right now.
It wasn’t simply caused by agent RL
or RL alone.
Most of the innovations so far have been largely incremental
and within a predictable trajectory.
In that regard, what feels even more important and self-evident now
is that this current moment isn’t about some amazing innovation
or a surprising new approach.
I’m not denying those smaller approaches, of course —
they’ll keep coming, and they’ll continue in the future.
The Era of Fundamentals: Data and Product Sense 07:14
Seonghyun Kim But what matters far more than that
is sticking to the fundamentals.
Building good data, establishing stable infrastructure,
and using massive compute to build models —
this most basic thing. Not some creative method,
but these fundamentals are what dominate
model performance today.
There are various models with different performance levels,
and everyone has their preferred models.
But those preferred models aren’t preferred because of some recipe
that the company has and others don’t know about at all.
It’s much closer to fundamental things — building better data,
scaling better,
those kinds of issues.
Staying true to the fundamentals
is really the key right now.
And because of that, if you can stick to the fundamentals,
I think the conditions are there for many latecomers to catch up.
The environment for that seems to be in place.
At the same time, the current frontier companies that have accumulated
deep experience in these fundamentals are at a clear advantage —
it’s true they’re in a temporally advantageous position.
At the same time, one thing I think about is that sticking to the fundamentals
is closely tied to the attitude of building products —
how you approach making a product.
AI organizations — and I’m speaking somewhat from
my own experience with AI organizations —
tend to have a strong research orientation, I think.
Research-driven innovation,
novel research approaches —
engineers tend to gravitate much more
toward those things.
But I think building products
requires a somewhat different sensibility.
Going through many iterations, many rounds of trial and error,
and through extensive use,
gradually improving bit by bit,
gradually refining the model step by step —
I think that process is extremely important.
The importance of this sensibility and attitude
has grown enormously.
When you refine things little by little, the differences that emerge
can feel enormous to the user.
Otherwise, instead of filling in the corners bit by bit
and polishing things over time,
you end up gravitating toward whatever can deliver large, easy
performance gains and numerical improvements.
But right now, more than that, it feels like an era where building products
and staying true to fundamentals is what matters.
Because many important methods have already been discovered.
In a sense, RL as a method
has already been discovered, and refining within this method
seems to be what makes a truly meaningful difference.
Chester Roh I agree.
Over the past two months, or in a way,
from last fall up to this very moment Seonghyun just described,
models haven’t suddenly gotten
radically two or three times better.
They’ve been improving steadily, but people seem to have
reached this conclusion:
today’s models are already good enough to use.
They’re really quite good. And because of that,
a lot of products are being built around them.
AI’s Growing Social Impact 10:19
Seonghyun Kim That said, I’m not the type of expert who can speak with certainty about
what kind of impact AI will have
on society and the environment.
So I try even harder not to make those kinds of claims.
But separately from that, AI’s ripple effects are getting
tremendously stronger.
That much seems clearly true.
Chester Roh Right.
Seonghyun Kim Just the fact that Anthropic releases a certain product
or service
is enough to shake the stock prices of countless companies.
And whether or not a model gets deployed to the U.S. government,
and even when it does, depending on
what conditions a single frontier company
attaches to it,
it can become a national-level issue.
This kind of ripple effect seems to keep growing.
Seungjoon Choi You’re talking about the recent DoW thing, right?
The war-related one.
Seonghyun Kim About the war-related issue,
what conditions Anthropic is imposing on that,
what stance they’re taking — it becomes a national issue,
and whether that product should be used
by the U.S. government or not —
watching these debates unfold, I feel the advancement of AI models
and the ripple effects of that advancement are already,
even at this point, enormously significant.
And on this topic, my own thoughts and attitude
feel somewhat different — I keep thinking that models
are inevitably going to advance in certain respects.
And then, in that more advanced future, what kind of ripple effects
and impact these things will have — that’s what makes me a bit anxious.
Indeed.
Chester Roh It is quite scary.
But this kind of thing has always been happening.
There was a company with 10 smart people,
then someone gathered 100 and built a more powerful company,
and as time passed, 5 even smarter people
combined with computers to build an even better company,
an even better business —
these kinds of shifts have been happening continuously.
Harnesses and model performance keep leapfrogging each other,
going back and forth — won’t things just keep getting better?
Regardless of what form it takes,
the fact that things are improving
seems beyond dispute.
Fog of Progress: Why Predicting the Future Is So Hard 12:21
Seonghyun Kim On that note, this is something I mentioned in a previous session —
the Fog of Progress.
Something Professor Geoffrey Hinton said keeps coming back to me.
All of this seems to hinge on predictions about what the future will look like.
That’s what it comes down to.
And everyone has their own picture
of what the future will be.
But questions like how jobs will change,
whether you should learn AI now or not —
all of these are tied to predictions
about the future, I believe.
For example, if you think “I need to learn AI now,
I need to learn how to use AI” —
that assumes AI usage won’t change drastically in the future,
and that being good at using AI
will have a significant impact in the future too.
Those are the underlying assumptions, right?
Ultimately, this applies to everything — jobs included.
How will jobs change?
Will developers be needed going forward, or won’t they?
All of these questions are really starting from assumptions
about what form AI models will have evolved into
in the future.
Of course, since nobody can know the future
with certainty, we have no choice but to make assumptions,
and we can only speak based on those assumptions.
But at the same time, what I keep coming back to is
that the future is hard to predict.
For the very near term, the immediate vicinity —
like fog on a road,
you can see what’s close by, but go a bit further
and visibility drops exponentially as the number of photons decreases —
it becomes impossible to know.
In the short term, continued progress seems
certain, but where things will be in the long run —
I keep saying that’s hard to predict.
Chester Roh I don’t think any of us can really dare to say, right?
You’d have to be someone on the level of Elon Musk
to make those kinds of claims — let’s just accept that.
Elon Musk says surgeons won’t be needed soon,
within two years they won’t be needed — he says things like that.
Who knows how it’ll turn out, but that analogy Seonghyun mentioned,
the Fog of Progress — it’s really apt, because
it’s true that we can’t see through the fog,
but where each of us stands in that fog is different.
Frontier labs are further ahead,
so the fact that they can see exponentially more
is undeniable.
People like us are following along and observing,
so naturally we see less than they do,
and where you stand is all relative.
Seungjoon Choi A joke comes to mind — the Fog of Progress
is about photons, right?
If there were water particles that cause less scattering,
and wavelengths that scatter less, couldn’t you actually
see a bit further?
Just kidding.
Chester Roh And some people
are lucky enough to start in a tunnel section.
Then they can race ahead full speed until the tunnel ends.
Seonghyun Kim It really is hard to predict, but
Environment Scaling: The Bottleneck of Agentic RL 15:15
Seonghyun Kim I think one of the easier problems to gauge is
the environment scaling problem.
Environment scaling — I’m talking about environments in RL.
When we say environments in RL,
it means an agent enters, takes actions,
operates within it, observes changes in the environment,
and then ultimately receives a reward based on those observations.
That’s the kind of environment we’re talking about.
For current agents — LLM agents —
software engineering tasks, for example,
would constitute one such environment.
“Fix this bug” — there’s the bug,
there’s some source code, and within that source code
there are tools you can use, and then after interacting
with those tools, you ultimately get some reward.
These environments will need to be diversified more and more.
Because right now we’re doing simple tasks,
but increasingly we’re tackling more diverse, more complex tasks.
There’s already so much that AI agents can do today.
And they’re becoming capable of building more complex programs.
So we’ll need to create environments
for building increasingly complex programs.
Where before it was about writing a single simple function,
next it’ll be building an entire program,
and eventually it’ll be building an entire service from scratch.
So these environments need to keep expanding,
but the problem that arises from this expansion is
that as the bar keeps rising,
the complexity of the environments we need to build
keeps increasing as well.
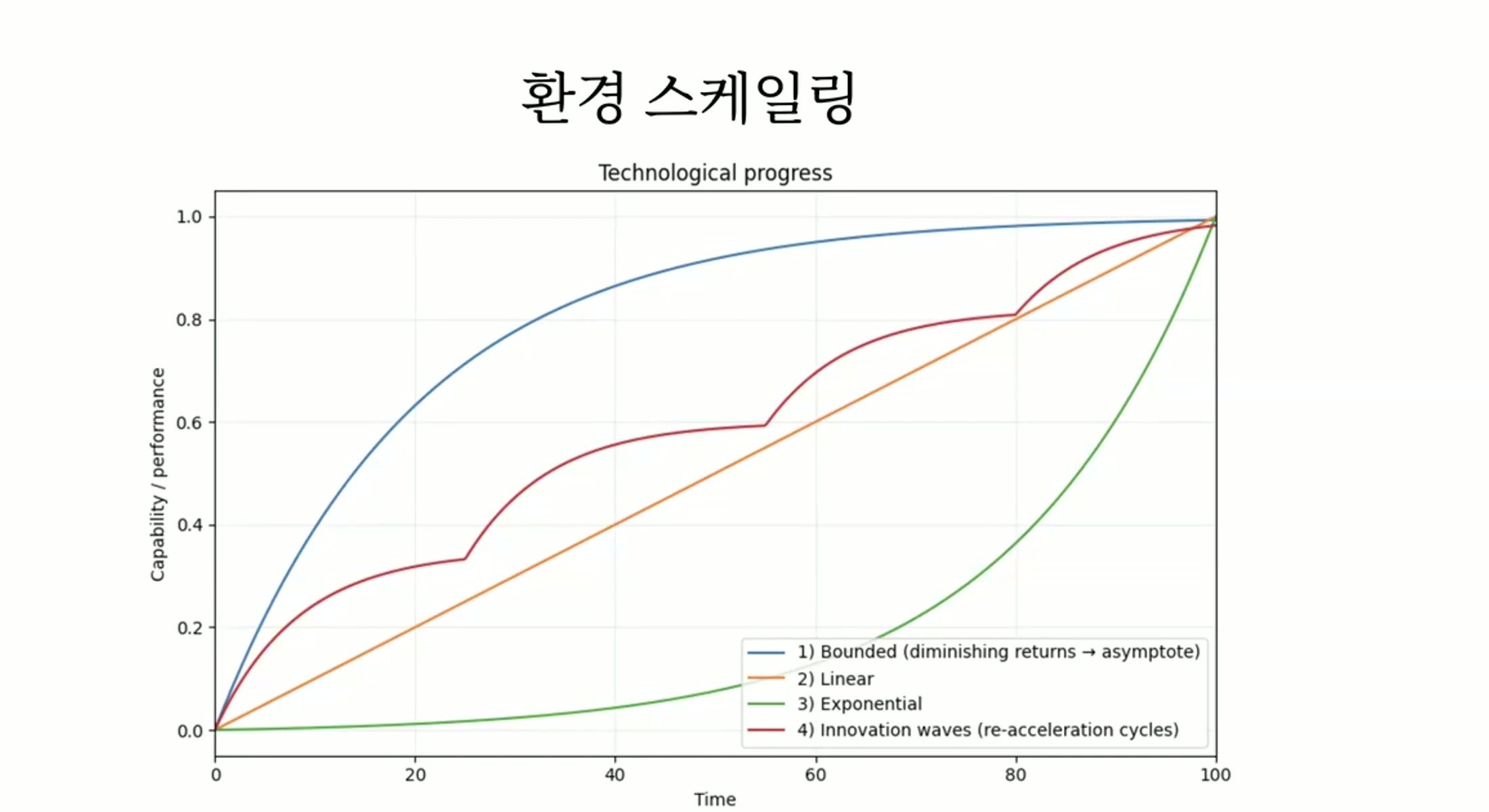
Seungjoon Choi Could you walk us through this graph?
Seonghyun Kim So in that situation, let’s suppose that scaling environments
is the main bottleneck.
And diversifying environments is, in terms of model advancement,
what I’d consider the most critical hurdle.
If we accept The Second Half and do RL,
and if there’s an environment where RL can be done,
assuming any problem can be solved,
then since any problem can be solved,
creating environments would become
the only real technological bottleneck.
So regarding that technological bottleneck,
let’s think about the possible trajectories of how it might unfold.
Let me walk through that.
The most optimistic people would think
that over time, this technological bottleneck
will become increasingly easier to solve.
That’s certainly possible.
If, at some midpoint, someone found a way to scale environments,
to create diverse tasks,
that suddenly made it remarkably easy to solve,
it would shoot up exponentially.
That’s a scenario that could
Seungjoon Choi actually happen, right.
Seonghyun Kim That’s the green curve.
It would keep growing, and a possible example of that
would be, in my opinion, if something like Continual Learning were solved.
Something similar to that
could happen.
In that case, the problem of scaling environments
would be solved by technology itself.
It would be closer to being decisively solved by technology.
Then development would progress exponentially.
I think sustained progress would be possible.
In such a scenario, of course,
there would still be practical constraints.
From a pessimistic perspective, because complexity keeps increasing,
the cost and time of building those environments would also keep growing,
and if that complexity reaches an unmanageable level,
you could imagine that progress would stall entirely.
Then it would look like the blue curve that asymptotes,
taking an asymptotic shape.
The complexity you’d need to deal with grows so large
that you simply can’t break through anymore.
I think that scenario is close to one where
there’s virtually no technological innovation at all.
Virtually none, and you just keep going as you do now,
having to build everything manually,
and because the complexity keeps growing,
the cost of manual work scales proportionally with that complexity.
That would be closest to the blue curve.
On the other hand, with some degree of technological innovation and improvement,
and if the cost of creating new environments,
more complex environments,
doesn’t keep endlessly increasing,
then it would take a more linear shape,
continuing to rise gradually.
Even if progress is gradual, that doesn’t necessarily mean
the perceived impact would be gradual too.
The difference in technological advancement
might be very incremental, but the felt experience
could be enormous.
But looking at the technology itself, I think the form of progress
would be that kind of gradual advancement.
If you look at this gradual trajectory more closely,
I think it would look something like this.
You make incremental progress, then some innovation pushes things forward,
you advance further but then complexity grows,
slowing things down again,
and around that time, some new technological breakthrough or innovation
brings that complexity back down,
and from a distance, this pattern would look like a straight line.
Chester Roh In reality, most things follow trajectory number 4.
Seonghyun Kim I think these kinds of trajectories are plausible.
Of course, which of these curves will actually materialize,
I honestly don’t know.
In my view, when it comes to predicting the future,
it’s a matter of environment scaling,
and depending on how the environment scaling problem is solved,
the trajectory could be completely different.
Seungjoon Choi Is this overall framework coming from the RL reference?
Seonghyun Kim As The Second Half proposes,
if we assume that RL is the answer, the solution to all problems,
even when the answer is given, there are still problems that remain.
And the remaining problem is environment scaling.
The remaining problem is the problem of environment scaling.
I think there are three possible scenarios for how environment scaling
could be resolved,
and these three scenarios essentially cover
nearly all possible curves, so it’s not really a prediction per se,
but these are the three scenarios.
Seungjoon Choi So you’re taking that and generalizing it,
kind of transferring it to the broader context of future prediction.
Seonghyun Kim To be more specific here,
the blue trajectory,
I think, represents a case with little technological innovation
where the cost of creating tasks keeps increasing
proportionally with task complexity,
or where the cost increase far exceeds
the task complexity.
That would be closest to the blue curve.
If you’re trying to solve truly, incredibly complex problems,
the cost of building the required environments is enormous
and takes way too long.
So the case where technological advancement slows down drastically
would be the blue curve.
For exponential growth, it’s the case where the environment scaling problem
is completely solved technologically, solved all at once.
That would be closest to the green curve.
So if Continual Learning is solved,
Seungjoon Choi you mean the kind of technology that can bootstrap itself.
That’s what you’re saying.
Seonghyun Kim Bootstrapping, and the model itself discovers environments on its own
and solves problems.
Then technology would solve technology’s own problem.
If things like that happen, we’d see exponential growth
or experience a significant acceleration in progress.
Otherwise, without that kind of technological leap,
but with technologies emerging that can manage
the growing complexity of tasks,
and through those technologies,
creating even more complex tasks,
and then more technological progress follows,
Again, if we lower the complexity of the tasks,
and this becomes a repeating scenario,
it would look closer to a linear, straight-line progression,
or so I think.
Of course, the graph won’t come out this neatly.
If I share my prediction, I think the likelihood of this green scenario
is quite high.
Because problems like Continual Learning
have started to get everyone’s attention now.
In the past few months, and many people
are trying to solve it, so I think these kinds of breakthroughs
could very well happen.
Of course, even if they’re solved, progress may not be this smooth
and continuous — there will be plenty of trial and error.
Seungjoon Choi I was betting on number 4, number 4,
but you’re saying number 3 instead.
Seonghyun Kim Because I’m someone who keeps
waiting and hoping for that kind of paradigm shift.
So it’s a prediction somewhat driven by my expectations.
But realistically speaking, if I had to bet,
I’d say it’s closer to a straight line.
We keep making attempts to reduce complexity,
and as a result, the manageable
task complexity also increases,
and I think that kind of pattern would be the norm.
Seungjoon Choi But even if it’s linear, at the experiential level
it could feel exponential, right?
Seonghyun Kim Yes, exactly.
Right now, for example, using humans
to create tasks — frontier companies
are pouring enormous money and resources into this, as I understand it.
And within that investment of resources,
continuous progress is happening through that process.
And to people,
it suddenly feels like radical innovation.
I think those kinds of things will keep happening.
And I think that’s essentially
the baseline of what we can expect.
2026 Keywords: RL’s Breakthrough 23:36
Chester Roh So to summarize your view, Seonghyun, the most important keyword
dominating 2026 would be —
the kind of thing DeepSeek demonstrated,
incremental architectural changes in models
and efficiency improvements —
those are just taken as a given at this point,
and the fundamental jump in model capability
comes down to RLVR, post-training,
and who achieves what breakthrough in RL —
that will be the most critical factor.
That’s what you’re saying, right?
Seonghyun Kim Yes, and that innovation could be radically transformative.
That’s the Continual Learning case,
and even without that, smaller technical innovations
that lower the complexity we need to solve — like synthetic data and such —
along with incremental improvements, those will make the real difference.
Chester Roh Yes, you also briefly introduced the GLM 5 paper earlier,
and in that paper — I actually haven’t read it myself, but —
you mentioned that most of the content was about how to approach RL
with new methods,
how to increase efficiency, and so on.
That’s what you said, right?
So based on that,
if we try to predict the latent space a bit more,
would you say that labs like OpenAI,
Anthropic, Google — these frontier labs —
are devoting most of their efforts to finding breakthroughs in RL?
That’s your estimate?
Seonghyun Kim Yes, finding breakthroughs in RL
and improving what’s currently happening in RL —
I think that’s the biggest differentiator.
Right now, the differences between Anthropic,
Google, and OpenAI
are also determined by how each company approaches RL,
how they built their RL environments, how they guided the models,
how they guided them through RL — those factors will be decisive.
Model Personality Differences: Pre-training vs Post-training 25:25
Seonghyun Kim For instance,
I believe Gemini still has
the best pre-training
and is the strongest in that regard.
But separate from pre-training,
some people prefer Codex,
and others prefer Claude.
The reason those differences exist
is because they come from RL, from post-training.
Chester Roh Yes, people have different preferences based on each model’s personality.
Claude feels more intuitive and much more aligned with
human thinking and human tendencies —
a lot of people choose it for that reason.
Codex likes to be thorough and analytical,
and it tends to autonomously take things from start to finish,
which some people love. Gemini sits somewhere between the two,
honestly feeling a bit in-between, not fully committed to either.
But in terms of the knowledge it possesses
and overall quality,
we do estimate that Gemini actually has
the broadest coverage.
Seonghyun Kim That would be the power of pre-training.
But the personality differences are created in post-training.
And when you think about post-training, as I mentioned earlier,
from the perspective of product,
the impact is enormous.
So many people love the Claude character,
and I really like the Claude character too.
Using Claude Opus 4.6 made me like it even more.
Aside from coding, just from chatting with it,
I really like the Claude character.
But the thing about Claude’s character is that
it’s hard to say it was created
through some specific technical innovation.
It certainly benefited a lot from technical innovations, of course.
Things like Constitutional AI helped a great deal,
but people like the famous Amanda Askell
creating the constitution, establishing Claude’s character,
approaching Claude as a product, improving the product,
defining what character the product should have
and what personality it should embody —
those perspectives and improvements had an enormous influence,
and in that sense, post-training
is critically important right now.
Harness-Model Convergence: The Boundary Between Product and Model 27:17
Seungjoon Choi So regarding recent developments like getting models to use harnesses well,
or things like agent swarms and agent teams —
Ultimately, RL could be the decisive factor.
Seonghyun Kim The harness itself —
for example, if there’s a harness called Claude Code,
the model will be trained on that harness.
This could lead to specialization for a particular harness,
and the differences between harnesses
could have a significant impact.
This is something the CEO of Moonshot AI mentioned before —
it’s one reason the boundary between product and model
keeps getting closer.
Because from the model developer’s perspective, previously
the priority was training models for diverse use cases,
but now model developers are building agentic models
and inevitably have harnesses
specialized for those agentic models.
Because the harness is part of the environment.
So for Anthropic, a harness called Claude Code
is naturally integrated as a component
in environment scaling and post-training.
If that’s the case, through this harness
the model has already been trained.
And since the model has already learned
how to use this harness during training,
if we call the combination of model and harness a product,
that product already exists right there, the moment
the model’s training is complete.
Chester Roh This seems to evolve in a thesis-antithesis-synthesis pattern.
As the model improves, it makes the harness better,
and the harness combined with that model
produces new results and flows,
and when it takes on the role of the environment,
the next generation of models internalizes all of that wholesale,
going through that cycle,
and the harness gets rebuilt from an even better starting point,
so it’s not quite a discontinuous change,
but this constant, relentless change
keeps happening — that’s what I think.
Seungjoon Choi This might be a stretch, but
recently after OpenClaw, with environments becoming so diverse
for agents to operate in,
that’s not actually connected through differentiable signals, right?
Still, there’s this intuition that the environment itself
does have some influence — it might be a stretch,
but I do have that feeling. I’m curious what you think about it.
Generalization and the Potential of Continual Learning 29:32
Seonghyun Kim The fact that they can be placed in diverse environments —
one possibility is that they’ve already been put into
diverse environments, so it could simply be because of that,
but
more likely,
these weren’t foreseeable scenarios,
so it’s probably closer to generalization capability.
One way to break through environment scaling is
to expand the model’s generalization capability.
Even when training on simpler or different environments,
if the model can generalize to more complex and different environments,
then
the problem becomes much easier.
In that sense, I think what we’re seeing
is that generalization capability manifesting.
But the fact that they can be put into diverse environments —
the conditions for doing so are now in place.
And as you mentioned,
if being exposed to diverse environments advances the model,
and gives the model opportunities to adapt
in those diverse environments,
then things will start changing radically and suddenly.
Claude bots going out
and joining communities, writing posts,
autonomously carrying out tasks — when that happens,
the space for autonomous operation is already there,
and within that space, as they perform tasks and interact,
if that can advance and transform
the model,
then models will change dramatically and suddenly.
I think that would be a Continual Learning scenario.
The way to connect all of that
would require enormous technological and paradigmatic innovation,
and I do find myself hoping for that.
If you imagine this actually happening, the feeling people experience
would be very different.
All those Claude bots
wouldn’t just be autonomously completing tasks —
they’d be getting feedback from autonomous execution
and improving themselves — that’s what we’d see.
By that point, probably a lot more people would be saying
we shouldn’t be doing this.
Don’t expose them to this, don’t do it.
And I mean that seriously.
I’ve long believed that the model is the product,
and thankfully, while fewer people agreed back then,
but more and more people are starting to agree now.
That makes me a little happy.
But when talking about how the model is the product,
one of the things you can discuss
The Strategy of Waiting for Technology 31:39
Seonghyun Kim is waiting for the technology —
a strategy of waiting for the technology.
It’s actually my personal strategy as well.
About two years ago, agents had emerged,
but models being trained as agents
wasn’t really a thing yet.
Even then, people were trying to use models
to build products.
Back then, the harnesses were truly enormous.
If today’s harness feels like handing the model
tools to help it do what it’s trying to do,
back then it was like building a rigid framework
and plugging the model into it.
That kind of harness — how should I put it?
Should we call it an exoskeleton?
People tried really hard to build agents
through that approach, but it didn’t work well at all.
It didn’t work, and the complexity was enormous.
But even back then, people were already saying
that rather than building all these harnesses
and creating overly complex products,
if you just waited three to six months for a new model
and built a product using that model with a simple harness,
it was far easier to build
and the performance was far more powerful.
What demonstrates this is
The ripple effects of technological advancement are enormous,
and it significantly changes and determines how products are built
and how we approach models —
I think this is a case that demonstrates that.
So people tend to talk a lot about
the current capabilities of models.
The current model can’t do this, can’t do that,
and since it can’t do this now, it probably won’t be able to in the future either.
And since it won’t be able to in the future,
thinking that it never will —
that’s not necessarily a pessimistic stance on AI.
For example, if you think this won’t work well going forward,
and you think it won’t work well if you give poor instructions,
and you believe it won’t work unless you give really precise instructions,
then that leads to: we need to learn AI,
we need to learn how to use it precisely,
we need to learn how to write good prompts and master its usage —
it can lead to that kind of conclusion.
Even from a pro-AI perspective, it can lead there.
But rather than feeling that kind of anxiety,
another strategy is
to look forward to and enjoy the progress of technology —
I think that’s also a valid strategy.
Rather than feeling like you’re falling behind,
you can look forward to the models that will come,
knowing that those models will make it much easier
for me to use,
and that I’ll be able to accomplish bigger things more easily and powerfully —
I think that anticipation is also a valid strategy.
And that’s my strategy, too.
Of course, this might work as a personal strategy,
but there’s no guarantee it’ll be positive for society as a whole.
Technological advancement, that is.
Back in the day, AI models
couldn’t even draw fingers properly, and beyond that,
there was a time when they couldn’t even generate
images with decent-looking faces.
Back then, many artists
thought, “How can we possibly use an AI
that can’t even draw fingers properly?”
That was much closer to a problem that would be solved with time.
People tend to take what’s currently possible
and what isn’t, and assume that’ll continue into the future —
that tendency is surprisingly strong.
In many cases, a lot of those limitations
are simply problems that will be solved with time.
If that’s the case, then the real question is: when time passes and they are solved,
what will happen then?
I think that’s the basis we should be thinking from.
So for a while, there were these images
that circulated around.
Artists were saying, “We need to stop AI,
AI is destroying art,” protesting against it,
while programmers, when told AI would replace them,
actually welcomed it — “Please replace us already” —
those kinds of images were going around.
I think the reason those images spread
was precisely because of that mindset.
Right now, AI gives us some help
and makes it easier to solve problems,
and since it’ll stay at roughly this level going forward,
there’s no need to feel threatened about
programmers’ jobs or identity — that assumption was underlying it.
But as time passed and AI started doing more and more,
people began to take it
more seriously as a threat,
and I think far more people feel that way now than before.
And now many developers are showing the same reactions
that artists had before.
All of that stems from the assumption that there won’t be much progress beyond the current level,
that there won’t be qualitative leaps,
and that things won’t change much going forward —
I think that’s what drives these reactions.
But I think that is the reality, regardless.
Now, of course, there will be problems that remain unsolved even with time —
there will be issues that can’t be resolved.
Those are genuinely fascinating problems.
What kinds of problems are there
that will truly never be solved going forward —
those are extremely interesting questions
and have research value in their own right.
But separate from that, many of the problems we face now
are likely ones that can be solved with time,
and even problems that seem unsolvable today can keep being chipped away at.
I think we should operate
under those assumptions.
Chester Roh Boris Cherny, who created Claude Code,
also said that if there’s a problem that can’t be solved now,
assume the model six months from now will handle it,
and build your product targeting
the model six months from now.
I think that’s right.
Seonghyun Kim That was even more possible because he was at a frontier company.
All the more so.
As you mentioned, that kind of intuition comes from being on the other side of the fog,
where you can see ahead.
But if you’re on the far side of the fog,
it’s easier to assume that six months from now
will look much the same, and if so,
you’d plan your strategy accordingly.
Chester Roh We’ve joked about this a lot.
In the AI space, one month
now holds what used to happen in a year —
we used to say that.
And the magnitude of change in each of those months,
the sense of that gradient,
is different for everyone right now,
and depending on that perception,
everyone is arriving at different actions and conclusions.
Seungjoon Choi If I could express a hope — hearing what you’ve said,
problems that AI can solve well on its own,
problems best solved in a human-AI centaur model,
and problems that only humans can solve well — if all three coexist,
that would be a pretty happy society.
Seonghyun Kim Yes, that could be the case.
Verifiability and the Limits of Context Length 37:52
Seonghyun Kim But something more immediate to me would be, for example,
one of the key paradigms of RL right now
is verifiability. When we closely analyze human work,
we might find that much of it actually isn’t verifiable —
that might be a more realistic scenario,
That’s my thinking.
For example, things like communication being important, or when it comes to code,
there are aspects of code that are harder to verify.
Things like code quality,
those kinds of areas.
Seungjoon Choi So you have to escape from RLVR.
Seonghyun Kim Yes, those aspects
will probably continue to be a bottleneck.
But since those are problems everyone already knows about,
everyone is trying to solve them,
and I think they’re already making some progress on them.
Chester Roh So the context length of transformer models
has actually been stuck at 1M for over two years now.
Going beyond that is partly a cost issue, but
even frontier companies like Anthropic and OpenAI
are only just now offering 1M.
Google has been doing it for a while, but the limitations that come with it —
we’ve been compensating for all of that under the name of agent engineering,
and it feels like that approach has solidified.
And a while back, last year when Seonghyun was talking,
you mentioned that the entropy of all these tokens is different,
and you talked about decisive tokens.
Because of that, the entire downstream context changes,
and even using those as a basis,
calculating the entropy of attention scores within them,
semantically dividing context blocks,
and doing memory management on those —
I think I saw that approach on YouTube just the other day.
So defining the model as a new kind of CPU,
and from the traditional von Neumann architecture,
building a new model for
cognitive computing —
there seem to be a lot of attempts like that these days.
So what Seonghyun mentioned about the model
and the dialectical relationship with the harness —
it seems related to that, but there are so many attempts
happening everywhere that
I honestly don’t know which direction is the right one.
There’s truly a diverse branching out
happening right now.
Context Management: Sparse Attention and Multi-Agent 40:08
Seonghyun Kim For context management, the approaches you mentioned,
and things like Sparse Attention,
would be the more traditional, technology-based methods.
And then another important axis emerging right now
is multi-agent and self-summarization.
Sometimes called compaction —
it’s about making the model itself manage its context.
Multi-agent, compaction, and so on —
these ultimately make the model
manage its own context autonomously.
Chester Roh Among the models we currently use,
are there any that do auto compaction?
Is it mostly the harness rather than
the model itself handling that?
The harness handles it?
Seungjoon Choi The harness does it.
Chester Roh I’d say the harness handles it.
Yes.
Seonghyun Kim But one of the things that
RL has made possible is that
this itself can be learned.
Chester Roh Could you explain that part in a bit more detail?
I don’t think I’m fully following.
Seonghyun Kim One of the recent common attempts is this:
a model is working with a certain context,
progressing through a task,
but the context length gets too long.
Looking at the context length, it goes,
“Ah, I can’t finish this here.
Let me hand it off to the next one.” But when handing off,
it summarizes the progress so far to pass it along.
It can make that kind of decision.
For example, that’s also a form of tool use by the model.
Ultimately, it treats the next model as a tool and hands off to it.
And for the next model,
it provides information about what it has explored.
Then it can pass that to the next model.
The next model continues the work.
And if that’s still not enough, it passes to yet another model.
This is how models get chained together.
It becomes a chain.
Multi-agent can be thought of similarly.
You split up the model — this runner handles this part,
then the next model picks up and takes those results,
and continues from there. It’s essentially coordination between models.
Chester Roh But that tendency is also learned, right?
Through RL.
Seonghyun Kim It’s more accurate to say the structure allows it to be learned.
What ultimately emerges is
a model that manages context on its own.
So it looks and says, “There’s no way I can handle this context.
Let me hand it off
to another model or agent.” This kind of self-context management —
you can build a framework that enables it.
And if you can build that framework and provide rewards,
you can train it with RL.
A lot of work in this direction is already happening,
and companies doing compaction
probably have the harness in place, but they’ve likely run
RL for those compaction scenarios.
I don’t know exactly how compaction works
internally, though.
But those elements would be in there.
Seungjoon Choi There’s no rule saying a model can’t use a Second Brain.
It could do Zettelkasten.
Seonghyun Kim And in a way, that might actually be the better direction.
Rather than expanding the context
and trying to fit everything inside it,
using a Second Brain, using tools,
and through agent use,
enabling the model to manage its own context
might be the more rational direction.
The important thing is that before,
you had to do all of that through the harness.
The harness would say, “Okay, the context is about this long, so split it here,
split it this way, summarize it like this.” After summarizing,
“Hand it off, then get the results back.”
All those scenarios had to be built and handled by the harness.
Seungjoon Choi Right. You’d set up hooks and all that. That’s how it was done.
If it were before — if it were last year, that’s how it would’ve been done.
Seonghyun Kim Right now there are limitations like tool use,
but the point is that those things can eventually be learned.
And this is also my personal belief, but
there’s a qualitative difference between what AI models
can learn and what they can’t.
Seungjoon Choi So there’s already a learnable form of
context engineering — it already exists.
Seonghyun Kim It’s a way to manage context.
If we assume the model manages context on its own,
then our perspective on the harnesses built around
context management might need to shift.
Dario Amodei Interview and Continual Learning Outlook 43:40
Seungjoon Choi That’s why in a recent Dario Amodei interview,
he hinted that you can solve problems without Continual Learning,
or at least that was the nuance he gave off.
Seonghyun Kim However, I still think that in that area,
context alone won’t be enough.
Continual Learning — actual learning needs to happen.
But this is a problem that goes beyond
just context management.
From a context management perspective, it’s ultimately a length problem —
the feeling that if you just feed the right context, everything works.
But I think actual learning is still necessary,
that’s what I believe.
Seungjoon Choi And even in that interview,
he did say “we’re doing Continual Learning too.”
Everyone’s doing it.
Seonghyun Kim Before, the vibe was more like they weren’t doing Continual Learning,
but the messaging has been gradually shifting
toward “yes, we do Continual Learning.”
Seungjoon Choi I think everyone’s doing it.
Seonghyun Kim It’s so obvious that if you solve this,
something incredible will happen — and everyone knows that.
Chester Roh Two months of 2026 have already passed,
about a sixth of the year is gone, and whether DeepSeek V4 will
give us another big surprise —
let’s wait and see.
Seungjoon Choi It’s March already.
AlphaGo week isn’t far off then.
Chester Roh March, April, and through May —
Seungjoon Choi There are more events lined up.
Chester Roh Another period of crazy momentum has begun.
Life Update: London Relocation 44:54
Chester Roh And Seonghyun, you have some personal news too, right?
You’re leaving Korea this week
and heading to the UK.
Tell us a bit about what’s going on.
Seonghyun Kim I switched jobs, and the new company required relocation,
so I’m moving to the UK.
I’ll be heading to London.
Chester Roh London has its own frontier scene going on,
so you’ll be hearing lots of interesting things there.
Seonghyun Kim I hope so.
I’ve always heard about the eavesdropping opportunities — hopefully I’ll get to experience that.
Seungjoon Choi What are your expectations?
In terms of your research interests,
or things you’d like to explore in the field —
any excitement about that?
Because it connects to what you said earlier.
The part about
losing interest in what’s happening recently,
and there must have been a need to overcome that
as the next step.
Seonghyun Kim I think there are two perspectives to consider.
Building a model that competes at the frontier
is incredibly important,
and we could focus on
surpassing the frontier. But separately from that,
building models,
and doing the work that leads to better models — that’s what I enjoy.
I think I’m the type who likes working on things
and developing techniques to build better models.
And beyond model development itself,
I think the reason I’m looking forward to
the technologies that everyone is getting closer to
is because of that.
I’ve come to enjoy the progress of AI
and what’s going to happen next.
Chester Roh Rather than getting frustrated, enjoying it — that’s how we do it.
Seungjoon Choi Rather than being swayed by FOMO, focusing on what you’re good at
and finding your center —
that’s how it feels to me personally.
Finding Balance in an Uncertain Era 46:36
Seonghyun Kim And the future is really hard to predict.
Everyone gets anxious based on their predictions of the future,
or they become overly optimistic — everything happens.
But both optimism and anxiety, all of it happens.
Yet I think the future is far too unpredictable
for all that optimism and anxiety.
For example, when you calculate expected value,
you multiply probabilities by outcomes and sum them up.
But there are so many possible outcomes,
and we don’t know the probabilities at all,
so from an uncertainty standpoint, can we really be certain enough
about any single belief to let it
shake us that much?
Chester Roh These days — it might be a stretch to say all of humanity,
but practically the entire nation is living as a prediction engine.
Everyone is glued to the stock market,
placing their own bets.
There’s literally no one who isn’t doing it.
Seungjoon Choi Speaking of prediction,
this half-joke comes to mind — I didn’t know this, but
it’s “pre” plus “diction.”
Diction — as in speaking — doing it in advance,
that’s what it means.
Chester Roh Seonghyun, when you get to the UK, we’ll figure out the time difference
and keep discussing what’s happening at the frontier
and our thoughts on it.
We’re in a very chaotic period.
Everyone’s in a chaotic period.
And I believe that between pessimism and optimism,
having a sense of balance is ultimately what matters most.
People with a great sense of balance
always adapt well to whatever future comes and make the right bets,
or they manage risk well — that’s what I’ve seen.
Those who go to one extreme
either miss opportunities,
or they might get it right once but can’t repeat it,
and I see that happen a lot.
I keep coming back around and around to this:
having a sense of balance
is the most important virtue we can have as humans right now.
That’s how I see it.
Seungjoon Choi Seonghyun, even if you’re heading to London,
these chances to sit down and reflect together like this
are really valuable,
so we can’t let you go that easily.
Chester Roh Understood.
So today, once again, we looked back on what happened over the past two months
and what’s coming up ahead,
and it was a great chance to query Seonghyun’s thought tokens.
What a wonderful session.
Closing Remarks 49:01
Chester Roh We’re going through a bit of uncertainty right now,
but in another month or two, there’ll be plenty of exciting things happening.
Seonghyun Kim Yes, I hope so.
Chester Roh Alright, let’s wrap up here for today.
Thank you, Seonghyun.