EP 90
Ten Years Since AlphaGo (feat. Jinwon Lee, CTO of HyperAccel)
Intro and Guest Introduction (HyperAccel CTO Jinwon Lee) 0:00
Chester Roh All right, today, as we’re recording, is March 14, 2026.It’s Saturday morning, Pi Day.
Today we’re going to talkabout the 10th anniversary of AlphaGo.Amazingly, it’s already been10 years since AlphaGo shocked us.So we’d like to recapthose 10 years.
Along with Seungjoon, we’ve invited a new guest today:HyperAccel CTO Jinwon Lee. Welcome.Hello.
Jinwon Lee Thank you for inviting me.Jinwon Lee,
Chester Roh you also recently served as a judge for Dokpamo (Korea’s sovereign foundation model program),and in the early days of deep learning,you contributed a great deal.PR 12, should we read that as PR Twelve?Our paper reading group lasted for a very long time,and I personally benefited from it a great deal.Jinwon, could you briefly introducethe company you’re working on now as well?
Introducing HyperAccel: Inference-Only AI Semiconductors and the Service Pricing Problem 0:59
Jinwon Lee Hello.I’m Jinwon Lee, and I serve as CTOat HyperAccel.To briefly introduce our company, HyperAccelmakes AI semiconductors dedicated to inference.
There was also an article about us not long ago,and when you use AI services,they’re very expensive.There are many reasons, but expensive memory like HBM,and costly manufacturing processes,make it still somewhat burdensomefor ordinary people to use these services,so we asked ourselves whether we could make semiconductorsthat would enable better services for more people.So instead of using HBM,we use low-power memory called LPDDRto supply servers at one-tenth the cost,and the cheapest service people use nowstill costs about 21 dollars a month in Korea, right?We want to bring that down to under about 4 dollars,and with that ambitious goal,we’re working hard to develop the chip.
Chester Roh That seems like the right direction.Back in 2017, these kinds of things,which I think we’ll talk a lot about today,
The PR 12 Paper Reading Group and the Power of Community 2:05
Jinwon Lee were heavily influenced by the community.I wouldn’t say that’s not true now,but back then the community was especially powerful,and for the development of deep learning in Korea,I also received a great deal of help from others.Around that time, with Kim Sung-hoon, now the CEO of Upstage,and several others in a group called TensorFlow Korea,we all felt the same way: papers were pouring out,and at that time, so many new algorithms were appearingthat people didn’t even know which papers to read,and it took far too long to read just one.So we wanted to help with that a bit,and in 2017,two people each week would take turns on Zoomreviewing papers,and we started recording everything just as it was,like this podcast, and uploading it to YouTube,and it’s still continuing now.It was a lot of fun and went really well. I’m taking a short break now,but after a brief rest,I plan to go back and keep participating.Then would it be fair to sayit’s so nice when you tell stories like this that I didn’t know before.Right. And Jinwon, today webrought you on rather suddenly as a guest,but before long we’d like to invite you back
Seungjoon Choi AlphaGo had an influence on those things happening?Did people start studying after being shocked by it?Absolutely. From that point on,I think a real boom started in Korea.
Jinwon Lee Even before that, around 2014,I had been studying and experimenting with things on my own,but it was very difficult back then.There wasn’t much material, and I don’t think there was that much overseas either.
But after the AlphaGo event in 2016,a huge boom happened in Korea in particular,people’s interest grew, communities became more active,and I think that also helped lead to this getting started.With AlphaGo’s 10th anniversary recently,
DeepMind’s Official AlphaGo 10th Anniversary Post and Noam Brown’s Insight 3:50

Seungjoon Choi there were official posts from Demis Hassabisand from Google DeepMind,including one titled “From games to biology and beyond:10 years of impact from AlphaGo,“and then last year on our episode,we covered that Google DeepMind podcast once,and introduced the final episode of that year.But this year’s first episode too, and last year’s final one,which was an interview with Demis Hassabis,opened with a podcast related to AlphaGo’s 10th anniversary.Both of those were good, so I brought them up.
Rather than explaining the contents in detail, I think they’re worth checking out,and related to this, Noam Brown made a post like this.In the translated version, it says that the core approachbehind today’s frontier reasoning models is surprisingly similar to AlphaGo:imitate vast amounts of human data, and for better reasoning,increase compute at inference time.Back then it was Monte Carlo Tree Search,and today it’s Chain of Thought. Use reinforcement learningto go beyond simple imitation. The approach is very similar,and I think Demis Hassabis also left a comment on it.Anyway, after Noam Brown said this,
what Demis Hassabis commented was thatwe need to be very careful about moving in the direction of AlphaZero.Whether or not we should flip that switchis something we need to think carefully about, he said,and what that implies is ultimately a self-improving system.So I think we’ll talk a bit about that today as well.
Have you happened to see either of those posts or videos,or is there anything you’d like to comment on?What parts would be most important to focus on?I’ve thought a lot about
Jinwon Lee whether this can be done with AlphaZero, and when I actually looked into it,there really were movements in that direction.Going in the direction of AlphaZeromeans doing it without human data.Without the large-scale pretraining work we have now,can it be done with reinforcement learning alone,something beyond what we’re currently doing?But it seems like there’s a lot of movement on that front,so I’m watching it with great interest.
Seungjoon Choi In the end, what they did on the Google DeepMind podcastand in that blog post as well,seems to trace the path of how this directionnaturally connectsto science and innovation.There was another interesting thing too:they ended up naming the building 37.
Move 37 and Platform 37: When a Moment in the Match Became a Symbol 6:13

Seungjoon Choi As in AlphaGo’s famous move.What move number was Lee Sedol’s amazing human move again?It was move 78. So it was move 78, and AlphaGo was move 37, and it seemsthe new Google DeepMind headquarters is being named after move 37.They say people will start moving in this summer.
Jinwon Lee That was the second match, right?
Chester Roh It was probably move 37 from the second match.I think all the commentatorswere saying, “Huh, why did it go there?”It was a move no human would ever play, but later on,
Jinwon Lee a lot of people also said it looked like a mistake.If we look back at 2016, ten years ago,
On the Ground at the 2016 AlphaGo Match 6:54
Chester Roh when TensorFlow came out and all that,that was around 2015.TensorFlow had come out,but the world had no idea what it really was yet,and back then people were asking what deep learning even was,watching NVIDIA keynotes and talking about softmax,then MNIST, and after MNISTmoving on to things like CNNs,just trying out the most basic stuff,so people didn’t really use the term AI much.Back then, people mostly said machine learning or deep learning,and expectations for it weren’t all that high.But then AlphaGo arrived in 2016,
and even when AlphaGo was just getting started, I was at the venue,and there was also what you’d call the eve-of-event gathering,the gala show before it,where Eric Schmidt and all these famous people were gathered,and Lee Sedol, Eric Schmidt, and the ultra-VIPswere seated at the center front table,with all the other famous people sitting behind them.Even then, Lee Sedol was very confident.Humans would win.Yes, but on the other hand,I thought, if Google brought over all these stars like that,they must have come with real confidence.They wouldn’t have just shown up for no reason,so I bet that AlphaGo would win overwhelmingly,and I remember there was a lot of betting going on then.But after game one ended,everyone was really in shock.It was overwhelming.
Seungjoon Choi You both watched it live, right?
Jinwon Lee Yes, I did.I did. Since I don’t fully understand Go myself,
Chester Roh I couldn’t really grasp the depth of the moves and all that,but watching those people,seeing the commentators’ sighs, amazement, and frustration,I thought, wow, this is something huge.Another really interesting thing was that back then, including YouTube,
Jinwon Lee commentary was happening across all sorts of channels, with so-called professional Go players explaining it,and opinions were really split.Watching that every time a move came outwas something I remember being really fun.
Seungjoon Choi At the time, I didn’t really know termslike policy network or value network, so I was like, what are they even talking about,and I remember reading blog posts about it.
Chester Roh After the AlphaGo matches ended, just about every professorand every well-known person was explaininghow it had been built, and there were presentation decks and YouTube recordings,and I remember a huge amount of that coming out.In a way, couldn’t you sayKorea benefited from that a bit?
Seungjoon Choi We got hit hard early on, so it felt personal,and that made us pay closer attention. I think this was probably the video ofthe lecture Demis Hassabis gave at KAIST after the matches ended.So he showed things like DQN there,and talked about the context it actually fit intoand things like that,which made it possible to see those ideas more vividly.I think that was what the 2016 experience was like.
Chester Roh Around 2014, 2015, and 2016, even DQN alonewas cutting-edge technology,and I think that was also when people werestarting to experiment a little with RL-type things in OpenAI Gym.I also remember
Seungjoon Choi writing emotional reflections about it on social media back then.So before we talk todayabout looking back over those ten years of history,something recently felt related to this to me,and Autoresearch has been getting hot.Last year Andrej Karpathy kind of claimed the meme with vibe codingin coding, and this year with Autoresearch, how should I put it,it feels like he’s really grabbed hold of it. What did you think?
Andrej Karpathy’s Autoresearch and the Iteration of Verifiable Signals 10:24
Chester Roh How is this different from the Ralph loop?It is the Ralph loop. But it’s just operating
Seungjoon Choi in a specific domain, a specific area, with an evaluable validation metric, that’s all.Not even up to testing, just using the validation scoreto come up with all kinds of ideas for lowering itand experiment, experiment, and keep doing thatwas the kind of feel it had.
Chester Roh Conceptually, it’s actually similar to RLVR.But it’s a different layer.RLVR says that during the training process, if you can provide some verifiable,checkable signal,then you can keep training in that domain.This one pulls that into the actual application process, right.In the end, research and things like that, when given to a highly capable model,if you can set a reward signal, a direction for improvement,and define some objective,then it can autonomouslymove toward that goal. That’s what it showed.The reward signal wasn’t an RL-style reward signal,
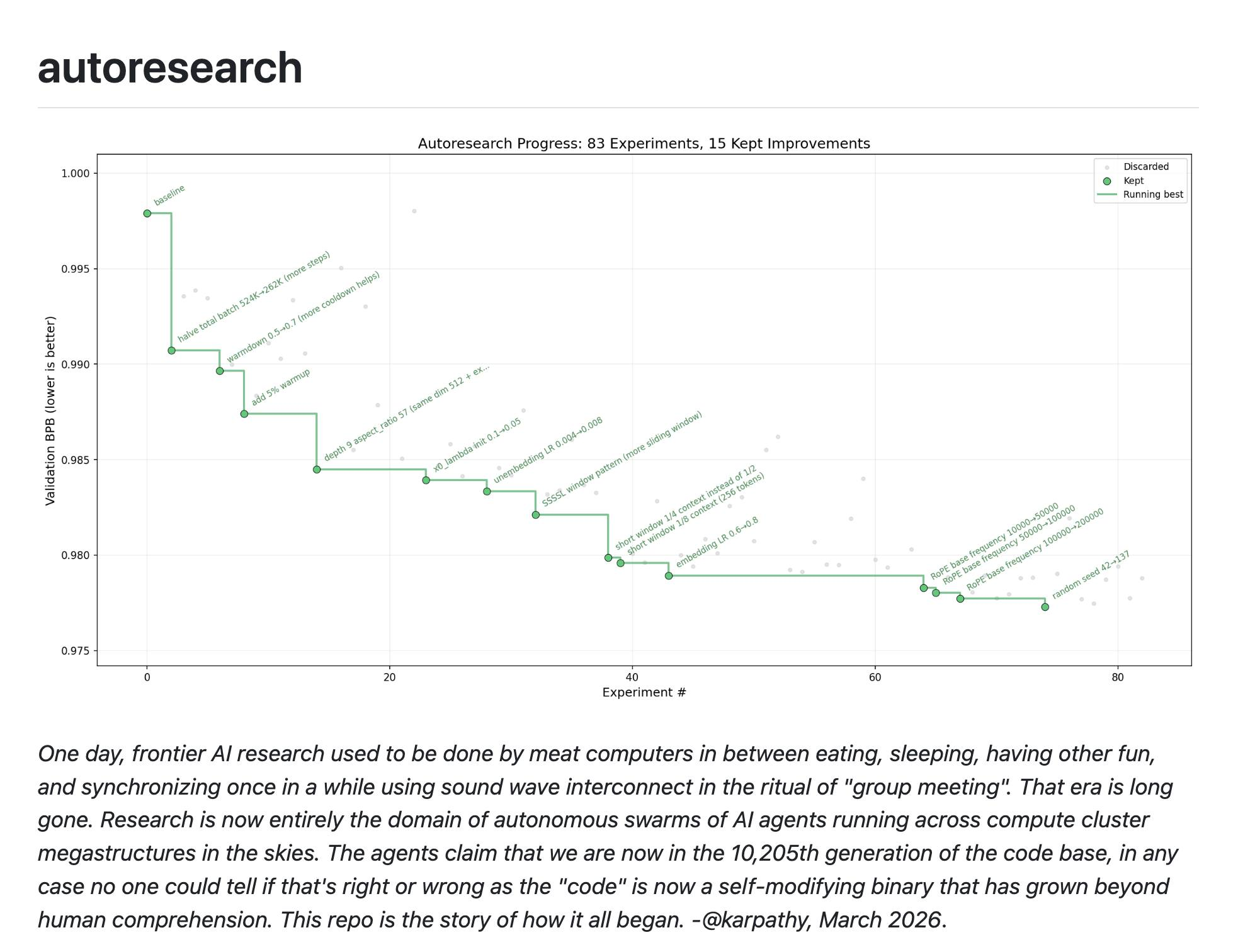
Seungjoon Choi and it wasn’t differentiable either, just a simple pass-or-failjudgment,and with just a very simple few files, prepare.py,which isn’t that important,train.py, and program.md,it keeps researching in the direction of lowering it until it satisfiesthe condition, and the MD file isn’t even that long.There’s something interesting at the very end: never stop. Don’t stop.If you get stuck, if you run out of ideas, go read papers.Form this hypothesis and test it.Test that hypothesis too, and don’t keep asking me whether you should continue.I think the final instruction is to just keep going.And the things that are actually showing results from thatare visible here in this graph.That’s what this is, and here Andrej Karpathy and
someone named Yuchen Jin, who was recently a CEO too,and seems to have stepped down to do something else now,were even talking about ideas like this.If this is currently about running one squador one agent going deep all the way like this,what if you turned researchers’ social media into something like a Moltbook?They were even talking about that.I found that social media post pretty interesting.There are derivative projects too,
like how to optimize TinyStories,and TinyStories as wellhas a small, well-curated dataset,so this is what this person learned by lowering that.Then this is called a Sparse Autoencoder,and in mechanistic interpretability researchit’s about getting better at using those toolsthrough an Autoresearch approach.And Simon Willison shared this example,where Tobias, the CEO of Shopify,took something he had built in the pastand made it 53% fasterby applying Autoresearch.So in domains where it works, it all works.Of course there are things it doesn’t work for,and there are probably far more domains where it doesn’t,
but in the domains where it does work, simply and elegantly,there are ways to do thisby spending the tokens properly.But the domain where it works welljust happens to be AI training.Right, when the goal was made clear,
Chester Roh if you can clearly define the evaluation metric,and if a benchmark exists, then it works there no matter what.
Seungjoon Choi Exactly. Last year Chester also said that if you just make it verifiable,a lot of things would probably get solved.
Chester Roh Right. The frameworks that are popular these daysall seem to be heading in a similar direction.First, they all basically hook into the process until it produces a resultand come with a Ralph loop built in so it repeats forever,and for the Ralph loop to succeed,you just need to control what comes before and after it well.Starting with very clear and clean context at the outset,creating that plan,and defining that if this is achieved, it’s a success,that evaluation metric.So fundamentally they’re all Ralph loops,and the infinite repetition is the same,but in terms of how you refine what comes before and after it,I think that’s how this community is evolving these days.So what worked for me too was,
Seungjoon Choi in March I kept failing and failing,and I still haven’t solved it 100%,but the successful case in the end was that I,with this thing I couldn’t get to fill in,wrote code to model everything and did the modeling myself,so I provided a kind of ground truth,and kept running it until it achieved something similar to this,and then the algorithm emerged.
Chester Roh You just kept running it until it worked.And it doesn’t just move forward,
Seungjoon Choi it goes back, forms a hypothesis, tries again, and if it doesn’t work,it goes back again and forms another hypothesis,and the process of findingthe algorithm that makes it work was interesting to watch.The lesson I got was, wow, precise feedback andprecise data are extremely important.
I might come up with various algorithms myself,or guide the model to come up with them,and there may be parts where that works,but I realized you can also do it end to end,and that got me thinking.The other day, Gubong
Ralphthon: The Importance of Designing Planning and Evaluation Harnesses 16:05
Chester Roh did something called Ralphthon.He hosted Ralphthon together with OpenAI,and what was really interesting was that once you made the plan,you couldn’t touch it for the next 12 hours.It just had to run only on the RL loop,and coincidentally, the people who got first and second placewere all designers of harnesses.The person who got first had made the harness called Ouroboros,and in second place,
Seungjoon Choi So it just keeps running.
Chester Roh I think Heo Yechan, who made Oh-My-Codex, got second place,and if you look at those logics, they all have principles.Infinite repetition until it works is right,but it’s about how precisely you make the plan,and how you evaluate the result,and the people who built those parts of the harness more carefullywere the ones who ended up succeeding more. That was the learning.Gubong had his ownslide deck summarizing what he had learned,and I read it, and it felt like such a correct direction,and I think the context is very similar for things likeAutoresearch and this as well.Do you remember?Something similar, around last October,
Seungjoon Choi that OpenAI talked about.
Chester Roh Back then Sam Altman and the Chief Scientist,Jakub Pachocki, came out together and presented last October.While presenting OpenAI’s vision, they said that by August 2026,we’d have an AI research intern,and then two years after that,an AI research PhD.They phrased it in a somewhat vague way,but saying we’d have an AI research internbasically meant something like Autoresearch.
Seungjoon Choi So now Andrej Karpathy toowrote on Twitter or on his blogthat in the end, this is what big tech is doing,the domain they’re fighting over.He was talking about self-improvement,and that he himself also had those kinds of ideas.We did it in a very simple, straightforward way,and that seems to be what’s going viral a bitas of March 2026.
Chester Roh Right. People all joke about it like that.We talk about it in our group chat too,and when one of our services or things like that gets posted in the group chat,we say, “Oh, that’s 1 click away,“or “That’s about 2 clicks away, 3 clicks away.”That’s the kind of thingwe joke about saying,and that’s the March 2026 we’re living through.Now, shall we go back to the past?
”Back in My Day” - Beginning a 10-Year AI Retrospective 18:44
Chester Roh Shall we get into our “Back in my day” segment?

Seungjoon Choi What we’re going to bounce back and forth on like thiscould be our own personal stories,and also what kinds of trends there were.I picked out a few thingsthat I personally recognized and immediately remembered.Around 2011, I saw this on my timeline.This was from Peter Norvig at Google,who’s still around now, though I’m fuzzy on whether he’s still at Google,but anyway, he was the most senior scientist.Peter Norvig and the person who did X with him.Google X, Sebastian Thrun. The person who later founded Udacityhad opened an AI course together at Stanford,and Andrew Ng had opened a machine learning course,and then there was also a database course.Looking through the timeline for that,this is what came up.So at Stanford, they ran experimentsthat became the beginning of the modern MOOC,and all of that was AI,ML, and databases,and apparently this many people flocked to them.
But there’s a name here, Daphne Koller,and Daphne Koller co-founded Coursera with Andrew Ng,and she’s the one who did insitro.She’s connected to the life sciences, and so things like this were happening,and from there, people, myself included,and probably others as well,
got into deep learning. Jinwon, how did you get started with deep learning?For me, very much, in a way,
Getting Started in Deep Learning: ImageNet and Samsung Electronics NPU Development 20:22
Jinwon Lee you could say it’s similar to this podcast too,in that it started when I was working and wanted to break out of something routineand wondered if there might be somethingthat could change the world, so I went looking out of curiosity.But at the time, in 2014,I saw that Google had taken first place on ImageNet,and that got me interested, like, what is this thing called deep learning?So that’s when I started looking into it.But as we all often say,there had been a period
that people called the dark ages of deep learning, AI, or machine learning.So in a sense, deep learning was a rebranded name,because when you said neural nets or things like that,everyone hated it, and to break through that situation,they used the term deep learning, and I looked at it thinking, “What is this?“but in the end it was in the same context,except the scale had gotten bigger,and as we’ve said many times beforeon this podcast, in The Bitter Lesson,AI ultimately advances by reducing human inductive biasand increasing scale,and there was this thing called ImageNet,which at the time was exactlythe benchmark we had to solve. It was the time when everyone was taking it on.So that’s when I started paying attention.
And naturally, as those things emerged,where I was, at the time,at Samsung Electronics,I was developing semiconductors for smartphones,and we ended up making what was called an NPU there as well,and as I got involved in making that,I think I started having those thoughts even more.The kinds of semiconductors I used to make before were things like,for example, video codecs.Their defining characteristic was that the standard spec was fixed.People got together and set the spec, and then what had to be done,what that semiconductor had to do, was already defined,and the question was how to run it efficiently and well.If making that well was the condition for a good semiconductor,then with an AI semiconductor called an NPU,what it has to do keeps changing.New algorithms keep coming out,and the evolution is incredibly fast,and at that time I thought, if I can’t properly understand AI algorithms,then in making a good semiconductor,it makes no sense to say I can make a good chip.So from then on I started reading a lot of papers,
and that PR 12 you mentioned earlieralso probably got started in that way.Since I was reading a lot of papers too,I wanted to exchange opinions with the people reading them with meand share them if possible, while studying and reading papers,
and that’s how it started.So you started around 2014.
That’s right, it started for me as studying.And I don’t know if you remember this,but if you look at the core of it, it’s this image.
The YouTube Cat Recognition Experiment and Emergent Behavior 23:00

Seungjoon Choi It was that YouTube had started recognizing cats.It’s not laid out exactlyhow this experiment was designed, but looking at this image,
Chester Roh I remember getting all excited with Dr. Sangho Leeand talking about it a lot.What it did was, with YouTube, at that time at least,they put something like a cluster of about a thousand machines there,set up things similar to a CNN architecture,and just fed in YouTube clips unsupervised the whole way through,and somewhere in a particular layer,there were a few images showing that a filter had formed that recognized cat faces.
So it was an example showing that intelligence,even without doing anything special, can so-called emergesimply through learning, that it can emerge.It’s been so long for me too thatI don’t clearly remember how the experiment was designed.If I remember correctly,
Jinwon Lee I think it was done in an autoencoder form.You put in the image and then reconstruct it again in that form.And then that becomes the very typicalemergent phenomenon we’ve talked about a lot with LLMs.
Like you just said.It was surprising. To everyone. Anyone could see it was a cat.Back then, it was surprising, but
Seungjoon Choi I just thought, “I guess that’s how it is,” and assumed it would obviously happen,so there was also this feeling of, “It still hasn’t happened?”I had just moved on after seeing it in the news,
Chester Roh and at the time, more than deep learning or ImageNet,there was that thing IBM made.The one that went on a quiz show, IBM’s system that was on Jeopardy,Watson. It was the time when Watson-style pipelines were popular and being actively researched.Around then, things like speech recognitionwere still being built not with neural networksbut with HMMs, Hidden Markov Models.It felt like those were the things that came first once you trained models.Honestly, until around 2014,I was more like, “Oh, that exists, that’s interesting,“I only knew what machine learning was,and I didn’t seriously thinkI should really study deep learning until around 2014.I also knew there were lectures by Andrew Ng
Seungjoon Choi and Peter Norvig,so I watched some videos and materials a few times,but I never thought about really digging into it.
Andrej Karpathy’s Writing and the ImageNet Golden Age: CS231n, DeepDream, Chris Olah 25:21
Seungjoon Choi Then something that went viral on the timeline wasthis by Andrej Karpathy,a document called Hacker’s Guide to Neural Networks,which I think got talked about a lot too.
Don’t you remember seeing it?
It covered how backprop works and what a computation graph looks like,saying this is not actually as hard as it seems,and it explained it all in JavaScript.It really matters
Chester Roh who you were with, when, and where you were working,because that’s the timing of life,and Karpathy was working on ImageNet, which was right at the center of all the buzz,as Professor Fei-Fei Li’s PhD student.
Seungjoon Choi Right, so here it says PhD student Stanford,and that he made ConvNetJS.ConvNetJS was naturally tied to Fei-Fei Li’s line of work,so he was doing that, and Karpathy was also sharing and explaining those things,and he really seemed to love sharing.Back then, the benchmark was something like today’s AIME
Chester Roh or Humanity’s Last Exam,but the hottest benchmark at the time was ImageNet scores.It was top-5 accuracy, and that was when VGG was all the rage.
Seungjoon Choi So people would make things like this and share them.You could do this kind of thing on the web.What I remember isthat VGG, VGG came in second in 2014,
Jinwon Lee in classification,but it still got used far more than GoogLeNet.At the time. Because VGGhad a very simple architecture, and for convolution too,it just kept stacking 3x3 convolutions,showing that this could work, and because it was simple,people thought it could be applied in lots of places,so a lot of people tried it. What I remember is,the GPU I had at home,
only had 2 GB of memory back then.I plugged in that 2 GB GPU and tried to train on it.But the batch size, I don’t remember exactly,but I think it only went up to around 2.Even so, I remember thinking I’d try it anywayand just running it.Back then, whatever you did felt genuinely amazing.
Chester Roh I remember 2014 being when VGG, or was it GoogLeNet, won,and then ResNet won in 2015.So at the time,vision-related things were really hot.
Seungjoon Choi That’s why the original title of CS231n wasDeep Learning for Computer Vision.And a lot of absolutely huge namesended up emerging from there later too.
Jinwon Lee A lot of the people who taught there became stars, actually.
Chester Roh Justin Johnson, right.He’s a well-known figure.
Seungjoon Choi Now he’s doing World Labs with Fei-Fei Li.That’s right. He went to Michigan as a professor,
Chester Roh and then I think he later founded a company with Fei-Fei Li again.
Seungjoon Choi Jian Fan is there too. Jian Fan also came out of there.Another thing that was popular around then
Chester Roh was style transfer,where it would turn photos into paintings in the style of Van Gogh.
Jinwon Lee They called it neural style.
They called it neural style.Right, neural style. Justin Johnsonmade a clean Torch implementation in Lua,and I remember running it a lot too.
Seungjoon Choi And in that kind of vision-related work, what gave a clue to why it workswas ultimately Chris Olah,and Alexander Mordvintsev, Mike Tyka,people like that, who worked onwhat was called DeepDream.It got talked about a lot in the art world too,but in the end it’s feature amplification.And now it can also be described aswork that provided an early starting point for interpretability research,and that whole story, centered around Chris Olah,
is very well documented on Distill.pub.So with Olah, things like this,if you look at the title and the people here,you see David Ha and Olah and people like that.So this is about using RNNs for things like handwriting prediction.Early on there were a lot of stories mainly about vision,but here there’s also RNN content.And Chris Olah,
Jeff Dean had that exact story, where Olah,when he was young, made him think,“We need to bring this person in.”Even around 2014, when Karpathy was sharing a lot of that kind of work,Olah was much younger but was still sharing work like this,and even getting comments from Yann LeCun.
Those blog posts are still preserved really well, so that’s interesting too.
Chester Roh The people who were just getting started then, after about four or five years,actually became the mainstream.And in 2014, even just in 2014 and 2015,we were all talking about images and style transfer, CNNs,things like that, ImageNet and so on,but Ilya Sutskeverpublished the sequence-to-sequence paper in 2014.But with RNNs, we didn’t really startexperimenting, building chatbots,and playing around with them until later,around 2016 or 2017.
Seungjoon Choi The co-author of Ilya Sutskever’s sequence-to-sequence paperwas Oriol Vinyals, I think, who’s still at DeepMind.I might be mixing that up, though.But I think that’s how it was.Anyway, trajectories like this were something Chris Olah,who ended up becoming one of Anthropic’s co-founders,carried into Anthropic’s interpretability research,through posts like Transformer Circuits,with that thread continuing steadily.
Jinwon Lee But when I think of Chris Olah, the first thing that comes to mind is actuallythose visualized diagrams related to RNNs, on his blog.I even used those images in lectures.He drew them very cleanly.
Seungjoon Choi And you could also work with them interactively.Personally, there was TF.js, which first came out as Deeplearn.js,and then changed to TF.js. After AlphaGo came out,this really shocked me,because it was an implementation I could at least somewhat understand,so I printed the code out and stuck it on the walland remember studying it almost like memorizing it.How backprop works and what you have to do with it.My child had actually just been born around that time,and I remember looking at it while walking around with a baby carrier on.And then, in 2016, Chester,maybe you could tell us about that episode?Apparently there was an event like this at Google Campus Seoul.No, I didn’t go.
The Evolution of Deep Learning Frameworks: From Theano to PyTorch 31:04
Chester Roh Back then, Eric Schmidt came to Google Campus too,the TensorFlow Korea meetup was held there as well,and together with AlphaGo,Google was really standing firmly at the center of the community.So I remember Jeff Dean came then too,but I didn’t go.
Jinwon Lee I went there, but honestly I don’t remember that much.A lot of people came,and what I remember is that people were very interestedin chatbots even then, but my impression of Jeff Dean at the time wasthat he wasn’t all that interested in chatbots, like, “Chatbots? Is that really so hard?”I kind of remember him answering in that sort of way.
But this was actually a little before AlphaGo for us.Since AlphaGo started on March 9,it was right before that, and TensorFlow,because at the time what people actually used the mostwas something called Caffe,and since Caffe was a framework developed at a university,the fact that Google was coming in properlyand doing thismade interest in TensorFlow extremely high.
Chester Roh Terms like session and feed_dict come to mind.Right. Speaking of those tool names,
Seungjoon Choi the early part of Andrew Ng’s course used Octave,so you had to study that and do the exercises in it,which was basically MATLAB’s…
Chester Roh Kind of an open-source version.
Seungjoon Choi Right, open, free, GNU, so the GNU version.I remember struggling through it somehow.I also remember that if you wanted to run something like DeepDream,you still had to use things like Caffe or Theano.Of course, there was also a TensorFlow implementationof DeepDream,but for derivative work around it, you had to do things like that.Looking at the timeline now, Torch was in 2002,Theano in 2007, Caffe in 2013,and Keras came out a little before TensorFlow.Keras, TensorFlow, PyTorch,that’s the order they came out in, from what I saw.
Jinwon Lee Theano was basically TensorFlow’s predecessor.A lot of the developers moved over too.
Seungjoon Choi But things got much easier when PyTorch arrived,I remember that being when it became more convenient.Right. By around 2016,
Chester Roh it was when PyTorch and TensorFlow were solidifying as the two dominant players.
Seungjoon Choi Do people use TensorFlow these days? I’m not really sure.
Chester Roh Well, I guess you could say I hardly use PyTorch either.
Seungjoon Choi Come to think of it, it’s also beenquite a while since I actually ran PyTorch.In the past few years, yeah, maybe I’d occasionally do something in Google Colab,but I can’t really remember properly using it.
Chester Roh Yeah, I think 2020 was the last time for me too.
Seungjoon Choi Another person who was well known at the time was CEO Kim Sung-hoon,when he was still at HKUST.That was when he was giving lectures like Deep Learning for Everyone,and this was early 2016, which in the endfeels like a ripple effect of the AlphaGo shock.People were stunned by AlphaGo and thought they really had to understand this,and an atmosphere formed where people studied it together,and that’s when the TensorFlow Korea Facebook group was created,and there were events, and people even went to Jeju Island together for workshops.
Jinwon Lee I was with TensorFlow Korea, which is now called AGI Koreaon Facebook after changing its name,and I was on the organizing team there too,and there were a lot of really interesting things.And TensorFlow, this was a user group,not exactly a user group in the strict sense,but it definitely had that character,and if you count it as a user group,it was the biggest in the world.So it was even introducedat actual Google events and things like that.I think it probably started with Soonseo Kwon at Google Koreaand CEO Kim Sung-hoon working together,
Seungjoon Choi and then many people joined as members of the operating committee.It was Egoing’s Life Coding and TensorFlow Korea.It felt like that was always showing up on my Facebook timeline, that community,and I think it was a time when it really had that kind of energy.But something else I found interesting wasthere was this somewhat mysterious blog back then.
David Ha and Creative Coding: What the Community Left Behind 35:45
Seungjoon Choi A blog that looked like this, and as you kept scrolling down like this,it had things that you could call a bit like media art made with machine learning,or in the style of creative coding,and there was someone posting lots of things like that.
And otoro means fatty tuna belly, right.It was calledFatty Tuna Belly Studio, and I used to look through that site a lot.And if you look there, using TensorFlow,all kinds of creative works would get posted.There were things like this too, and this one isn’t visually impressive, butamong the things shown here, what I found especially impressive wasthat in his early work, he was creating Chinese characters that don’t exist,which became famous a little later, around this point.He was doing work like this, creating Chinese charactersthat don’t exist in the world.And who this person is,
is someone who had been in finance, then left while doing Processing-related work,studied things like Processing, and sharedthe work he was making online.That person is David Ha, who is now the CEO of Sakana AI after spending time at Google.I remember seeing interesting things on David Ha’s site and learning a lot from them.Before we go there,
Jinwon Lee there’s actually something I’d like to mention.I think it probably relates most to Seungjoon.Back when I still called it deep learning,and even now, really, when I read papers and so on,I often felt that this field is very driven by trends.When people see that something works well,like during the AlphaGo era, peoplebecame hugely interested in reinforcement learning,and while trends were shifting like that, in a way,before today’s diffusion generation, there was GAN,which became incredibly popular at the time,and there was a period when papers were pouring almost entirely into that area.Seungjoon, did you also have experience using those kinds of things back then?Yes, absolutely.
The GAN Boom and the Beginning of Generative AI 37:01
Seungjoon Choi I never fully implemented GAN-related work myself,but I read a lot about it, and back then, before it was called NeurIPS,when it was still called NIPS, there was an enormous amount of discussion about it.
Jinwon Lee What’s funny is that in Ian Goodfellow’s GAN paper, there’s that bar
Seungjoon Choi The bar, right.He went out for a beer,and the beer tasted so bad
Jinwon Lee that he came up with the research idea there,that’s the anecdote.Making the discriminator and the generator,
Seungjoon Choi the evaluator and generator, competeagainst each other with that setup.But it really produced a lot of fascinating results.
Chester Roh Looking back now, that was our first generative case.Things like image-to-image translation,and text-to-image translation,and it feels like there were an enormous number of GAN variants, like DCGAN and others.I was in the fashion business at the time, and I remember using itto generate styles and things like that.When people distributed things made using AI like that,
Seungjoon Choi things like StyleGAN were used too,that’s how I remember it.There’s an artist named Refik Anadol.
Chester Roh Back then, it was fascinating,but it still wasn’t at the pointwhere people felt it was really usable.It was just the stage where it felt amazing that anything worked at all.In the Clubhouse era, people couldn’t meet in person,
The Clubhouse Era, WeeklyArxiv, and the Turning Point Toward Transformers 38:52
Seungjoon Choi so there were a lot of rooms where people just talked about AI online.After that, Dr. Hajungwoo, who is now chief scientist,also did something called WeeklyArxiv talks and chat sessions, right?I remember those happening on Zoom.I also joined once or twice as a guest, around when DALL-E came out,that’s how I remember it.Jinwon, you were involved with this too, right?Yes, when this first started,
Jinwon Lee I was a moderator together with Hajungwoo, who’s now chief scientist.Back then,on Clubhouse, the term moderatorwas always used almost like a trend,and I joined as a regular moderator.
At that time, once a week, we’d go over the AI papers that had come out that weekalong with AI news and things like that, taking turns.
That’s what Clubhouse was like, after all.Anyone could raise their hand, come up, and talk,and if they had nothing more to say, they’d go back down.I think we had a lot of fun doing it that way.We suddenly jumped 18 years ahead there,
Chester Roh just like that,but actually, before HyperCLOVA came out in 2021,there’s one event we absolutely have to touch on,and that’s the Transformer.
The Origins of Transformers and Attention: A Bitter Lesson Perspective 40:02
Seungjoon Choi We’ve covered Transformer so many times by now.And even by 2016,
Chester Roh I think that was when attention was just starting to emerge.
Seungjoon Choi Attention originally started on the image side first and then moved over.
Jinwon Lee There were papers like “Show, Attend and Tell.”So when looking at an imageand generating a description for it,there were ideas about where to place the attention.This came a bit later,but in 2017, ImageNet, 2017 was the final competition year,and the network that won thenwas called Squeeze-and-Excitation Network.In CNNs, too, those imagesget stacked into feature maps like this,and it was learning which feature maps to pay attention to.At the time, people didn’t really call it attention,but later on,we realized that this had actually been attention.
I also remember a lot of things about Transformer.That Transformer paperwas titled “Attention Is All You Need,“and honestly, the title itself grabbed attention.And back then, something I used to say all the time wasthat the big three in deep learning were OpenAI, Google DeepMind, and Facebook.It was called FAIR.I used to say that all the time.Around the time Transformer came out,there was a paper called ConvS2S, convolutional sequence-to-sequence,that came out from Facebook.So at that time, the biggest weakness of RNNs
was that everything had to be done sequentially,in an auto-regressive way,so in terms of today’s LLMs,even if you process the prompt in parallel,you still had to process the previous wordbefore you could move on to the next word,so to overcome those limitations,there was a strong desire for algorithmsthat could increase parallelism.Google said, with attention,we’re going to do it with attention alone, without RNNs.And Facebook said, we’re going to do it using only convolution.It was a bit like a competition, and in the end Transformer survived.Later, people interpreted this as
in the end, what CNN, or convolution, isis a built-in bias.People gather local features from images,and when you stack layers,what they call the receptive field grows,so it ends up aggregating information globally.In terms of scale, this is where the Bitter Lesson comes in too.In the end, once the scale gets larger,the more general model, Transformer, performs much better.
Chester Roh What year did you first read the Transformer paper?I feel like Jinwon must have read it as soon as it came out.
Jinwon Lee Yes, I read it right away when it came out.
Seungjoon Choi I opened it, but I couldn’t understand it.I opened it too, but I couldn’t understand it either,
Chester Roh and I didn’t really understand Transformer until 2020.From 2017, for me, from 2017 to 2020, AIwas something I wasn’t following that closely.
Seungjoon Choi I started trying to properly dig into Transformer in early 2022.To bring back a bit of memory and nostalgia,
Jinwon Lee when this paper came out in 2017, it definitely became a big topic,but I don’t think anyone imagined it would become what it is now.But what really drove this explosive growth,the first trigger, at least in my view,was when BERT came out.In 2018, Google released BERT as well,and GPT had actually come out a bit earlier than that,that was GPT-1.GPT-1 didn’t perform all that well, and BERTthe biggest weakness of this encoder-decoder structureis that it’s a translation model.So with Transformer, you always need correct answer pairs.If you’re translating English into French,you needed data that had already been translated.But BERT just took the encoder and used it without that,by creating blanks and filling them inand training it that way.That was doing what we callself-supervised learning,and it made it possible to useenormous amounts of data without labeling,which is when the scale really exploded.So even at that time, even with BERT,
The Arrival of BERT and the Scalability of the GPT Decoder: The Road to LLMs 43:14
Jinwon Lee people were saying, this thing is so big, how are we supposed to train it,it costs a lot of money, and if you want to use it in the cloud,I remember people talking like that.And GPT was the exact opposite, using the decoder approach,and all current LLMs now are basically in the GPT form,but back then these approaches competed a lot with each other,and in the end GPT ultimately won,and if you think back on that now,BERT is the encoder side, while GPT is the decoder,and the biggest difference isthat an encoder can attend from earlier words to later words.It assumes the full input is given,and because it’s filling in a hole in the middle,it makes its judgment by looking at both the front and the back.So of course performance can be better. It gets to see the later words too.
GPT always looks only at the words before itand has to predict the next word,so when the amount of data is small, its performance is bound to be worse.But it has a huge advantage, which is thatif you think of words being added one by one,the encoder has to start from the very first wordand redo all the computation.But a decoder like GPTonly ever deals with the words before it,so the computation for the tokens of the previous wordsdoesn’t need to be redone,and that eventually gets carried over in the form of key-values,so if you just newly add computation for the word generated this time,you can do everything, and in terms of scalability,it had a structure that was in a completely different league.So as a result, through that process,I think we eventually arrived at today’s LLMs.
Chester Roh When the BERT era arrived, a lot of companies really sprang up then too.Even the biggest BERT model Jinwon just mentionedI don’t think was even 1 billion.
Jinwon Lee That’s right.Right, but even that was talked aboutas being unbelievably huge at the time.And another interesting thing was
that BERT was also a Sesame Street character,so at the time, naming papers after those charactersbecame a bit of a trend, and we got ELMo too,and in Korea, I remember there was even a paper titled Pororo.That’s how I remember it.
Chester Roh Yes, at that time, with those BERT-style models, things like Q&Aor this kind of fill-in-the-blank task,using those kinds of models,there were a lot of companies trying to build practical services.Sort of a primitive version of today’s chatbot.You’d ask a question and have it answer, or have it judge whether something was right or wrong,or evaluate it, or in terms of quality,classify it as positive or negative,making classifiers like that. They worked very well.But in terms of overall completeness,there was always something missing at the end,and with the costs at the time, building those was extremely expensive,so because of that, back then, with BERT,the companies that had tried to build serviceswent through quite a lot of difficulty, from what I remember.
Seungjoon Choi That may be a historical pattern.
Chester Roh And then everyone’s interest started to cool off a bit,like, sure, AI is fascinating,but it doesn’t work, that kind of impression was dominant then.People were saying another AI winter was coming,and then when the money started going in, when BERT began,the companies that had invested heavilyweren’t seeing good returns,
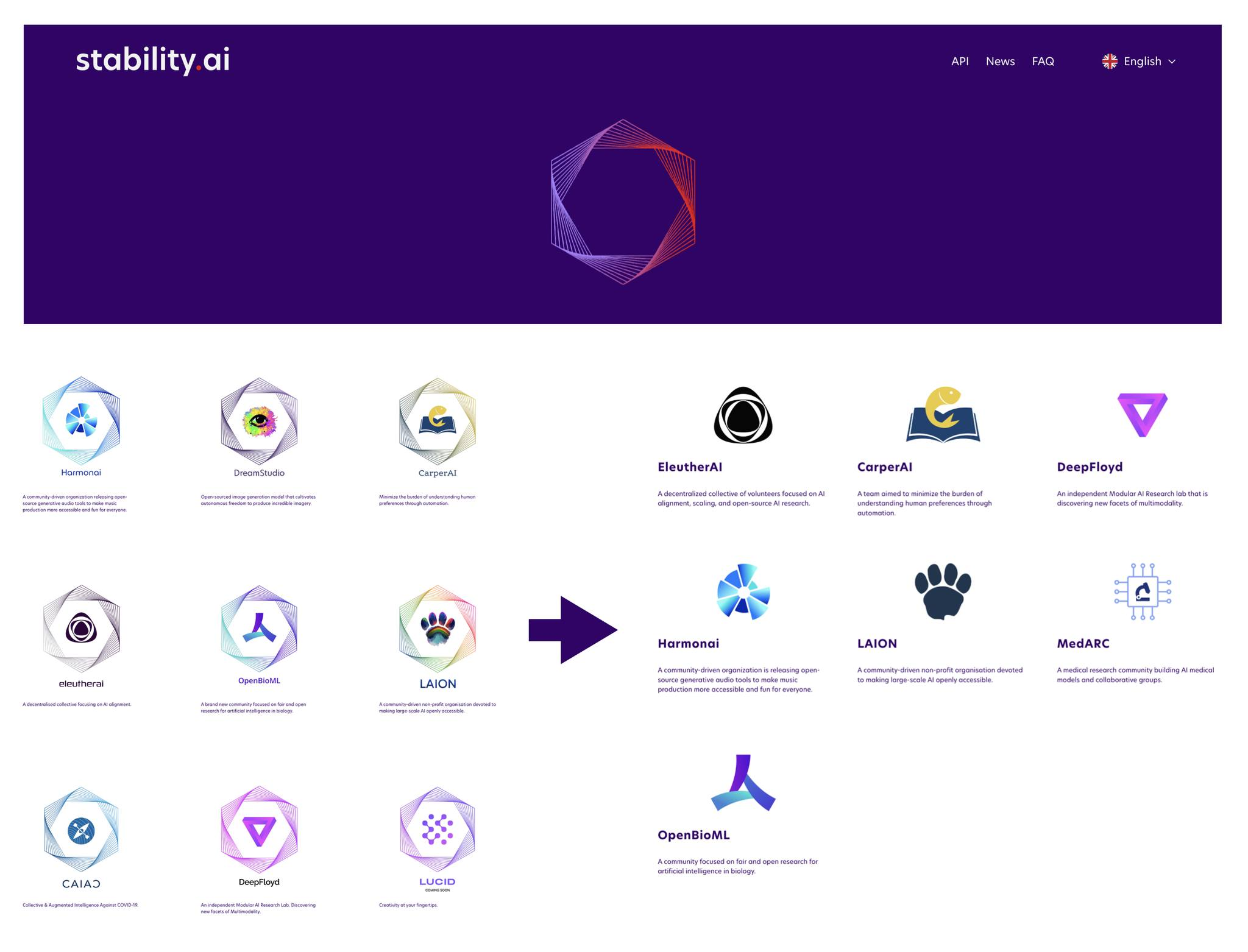
Seungjoon Choi I think it would be interesting to talk a bit about that period.In 2022, Stability AI was hot.Stability AI broke out with Stable Diffusion,and under Stability AI’s umbrella, there were various communities,like Eleuther and LAION,positioned around it during that period.But what was interesting there was
The Stability AI Community and Korea’s Foundation Model: HyperCLOVA 47:30
Seungjoon Choi that with LAION and Eleuther, and more recently someone in Korea, Kevin Go,who recently joined Upstage, was active in open source work,while also contributing to those communities through interesting open-source projectslike Polyglot,and then somehow, as things unfolded,one day I realized HyperCLOVAI had heard that Korea was doing this too,but don’t the two of you know more of the context?
I already looked up NAVER’s AI NOW materials, where they announcedthings like HyperCLOVA in 2021.But in 2020, that must have been when they assessed the situation.After seeing GPT-3, they decided they needed to make a big investmentwas that the conclusion around that time?
Chester Roh Right, NAVER made the investment a bit earlier.I remember they bought a huge number of A100s.Yes, and then they released HyperCLOVA.Honestly, it’s been so long now that the related metrics andthings like that are all a blur, but back then GPT-3still wasn’t really practical,but by the standards of the time, it was incredibly astonishing.AI was finally thinking,speaking, and learning through few-shot prompting to answer like a humanbecause people could actually see those things happening.If I say I’m Koreanand ask whose territory Dokdo belongs to,
Jinwon Lee it says it’s Korean territory, but if I set the character as Japanese,then it says it’s Japanese territory, and answers like thatmade people think, this is possible now?I think that feeling was really common at the time.
Seungjoon Choi But anyway, Korea had HyperCLOVA, andaround then I was studying LLMs a lot on my timelineand posting things I’d done in OpenAI Playground,and because of that they reached out to me,and in terms of trying it from outside the company,I also took part as one of the early participants.So those things were happening,and we already talked about Stability AI earlier,
so in any case, we also concluded that we needed our own foundation model.
Actually, a lot was happening on the Kakao side in between those lines too.So Kakao was building models too,and a company called TUNiB emerged,and there were spin-offs as well,and when it came to building models with LLMs,Korea definitely wasn’t sitting out; a lot of people were working on it for a while.Even LG AI Research,
Jinwon Lee which is now listed on Dokpamo, worked hard on it, though it fell short,and I remember KT was also working hard on it.As the influence grew enormously
and the potential for future development felt even greater,countries all started thinking this might become a strategic asset,and wondering whether it might eventually becomesomething like a military weapon, which created a kind of anxiety.So even if we had our own shortcomings,having our own technology and modelsfelt important, and I think that was the motivation for starting.
Vision Transformer and the Limits of Data Scale 50:40
Jinwon Lee Something from the past suddenly came to mind, so let me mention it.In the flow of Transformers,as we kept saying earlier,at first computer vision, led by ImageNet,had more active research,and when people see something visible,it naturally resonates more with them,so if you say computer vision had more active researchand more tangible results,then through Transformers,a huge amount of momentum shifted toward natural language.At that time, then,there was also a movement sayinglet’s try using Transformers in computer vision too, and after BERT came out,and then GPT-2 and 3 came out, that really started taking off,and eventually something called the Vision Transformer appeared,and again, Google was the first to create even that.Google announced an enormous number of pioneering technologies,and what’s interesting is, in 2017, was it June, earlier?That’s when the Transformer paper came out. But the Vision Transformer papercame out in October 2020.That’s an enormous gap.But why was it so late?It’s not that people hadn’t tried it,there were really a lot of attempts, but they all failed in the end,and if I remember right, the Vision Transformer paperwas at ICLR, and they do open review there.So the paper is opened while hiding the authors,but when it came out, everyone knew this was from Google.Because in the end,
the way they made the Vision Transformer succeed was by feeding it lots of data.There wasn’t any other answer, and the method itself was very simple: slice the imageinto patches, flatten them into vectors, and feed them into the Transformer,but for this to perform well,for it to outperform existing CNNs,you had to feed it a lot of data,and at the time it was trained with supervised learning,and back then the ImageNet datasethad about 14 million images.That’s the full image count. But Google had a hundred million data points,a private dataset called JFT that Google never opened to the public,and once they fed in that much data,they showed a graph where performance went up.And when people saw JFT written there as the dataset,they realized, oh, this is Google’s.So that was another moment whenI really felt once again how terrifying scale can be.
Seungjoon Choi So something else that comes to mind in this phase isthat Stable Diffusion, which gave Stability AI its breakthrough,was ultimately not really Stable Diffusion’s own technology,but something that originally went to Runway and now, is it back at Black Forest,anyway, dispersed to the Black Forest lab.Those two core researchers,people like Patrick,built technology based on latent diffusion.And among Koreans, there was also Doyeop, who on that PR earlier,worked with you too, right?
Jinwon Lee Yes, we worked together.Right, and thenDoyeop was at Kakao, then went to Runway,
Seungjoon Choi and now is thinking of starting a company again,and even though I’ve never met him in person, he comes to mind.And back then, too,
Chester Roh when Stability AI and Stable Diffusion came out,it was before ChatGPT.It was hot. People were generating images with it.
Seungjoon Choi But now, when you look at things like SeeDance 2.0,it feels like a different era.
Chester Roh Yeah, why did we make such a big deal out of that back then?
Seungjoon Choi Why did we even try to start a business?
Chester Roh Right. Yeah, I also put an enormous amount of effort into thatand built a lot of pipelines.Yeah, now Nano Banana does all of that.
Seungjoon Choi This is just a collection of things I wrote down on the timeline in 2022.I gave up because there got to be too many as I kept writing them down,but in the end, it was something I started once I began using LLMs.I remember trying this and that with it on a daily basis.Our starting point,near the starting point of our podcast,
Looking Back on the Podcast and Revisiting Man-Computer Symbiosis 54:18
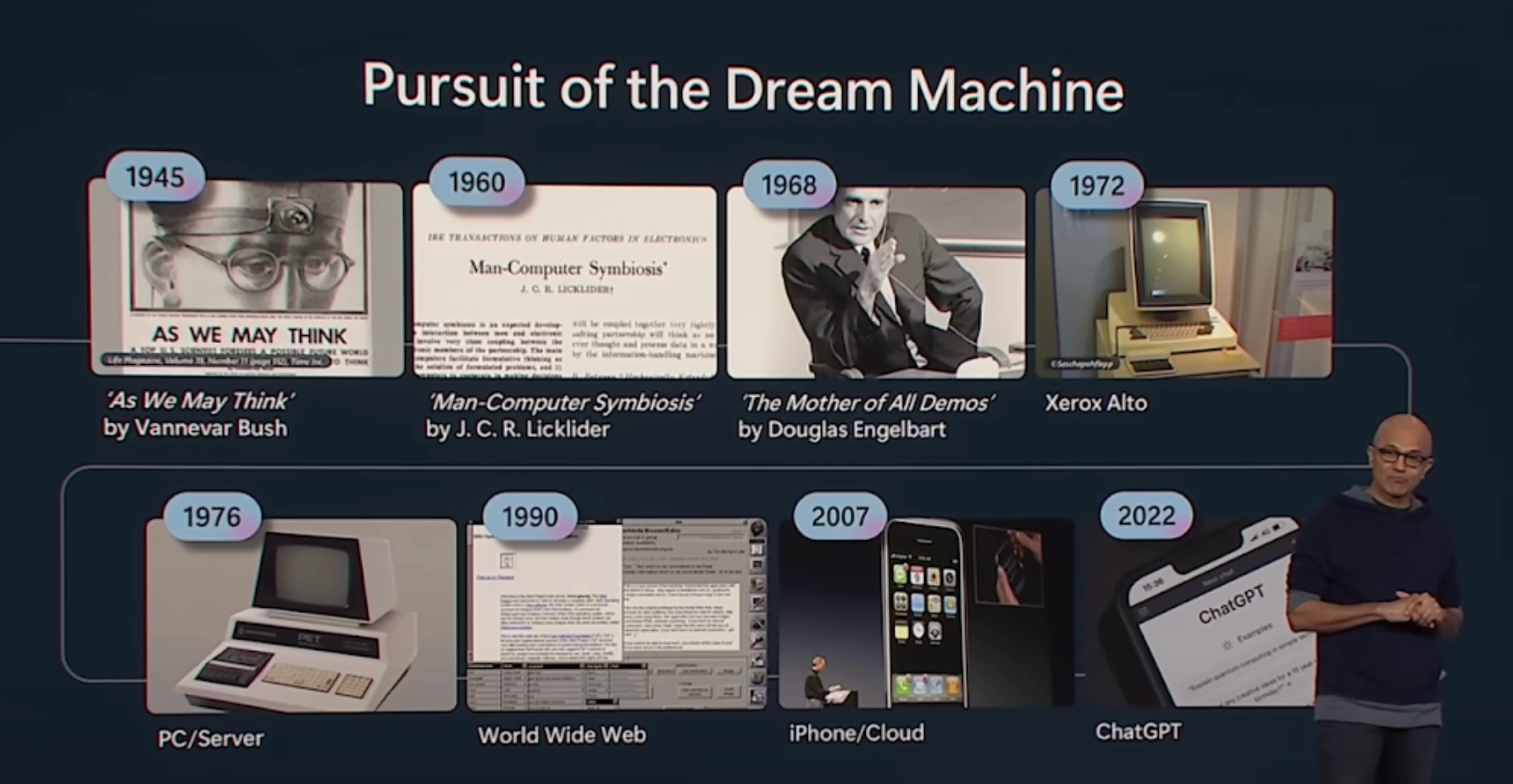
Seungjoon Choi episode 3 was about history and technology.So this was when Satya Nadellapointed this out at Build 2023.Starting with “As We May Think” in 1945and then “Man-Computer Symbiosis” in 1960 and onward,he traced how we got all the way to ChatGPT,and we tried to read into what that meant,
and by the time this episode comes out, I think we’ll be close to episode 90.Before we knew it, more than three years had flown by, and what happened after that toohas been enormous.Yes, it’s accelerating.
Chester Roh It’s accelerating even more.
Seungjoon Choi So I went back to what J. C. R. Licklider said in 1960,and revisited the idea of Man-Computer Symbiosis,and first he talks aboutwhat human-computer symbiosis actually means, and a bit laterthere’s this almost prophetic passage about what kind of era that would be.So let me read from this part.A multidisciplinary research groupthat reviewed future Air Force R&D problems believed that, with advances in AI,the point at which machines alone could carry outmilitarily meaningful levels of thinking orproblem-solving would come around 1980.If so, that would leave roughly five years to develop human-computer symbiosis,and fifteen years to put it to use.Those fifteen years could turn out to be ten years or five hundred years,but that period would be the most creativeand exciting intellectual era in human history.I don’t think this prediction was exactly right,but in terms of the direction,this really does feel like the period we go throughbefore superintelligence arrives isa creative and exciting era, and I do agree with that.
Chester Roh As we’ve been looking back over roughly the last ten years, it doesn’t even feel real.Honestly, we’ve lived for quite a while in an erawhere something that came out just a week ago could change the world.
Since around GPT-4 in 2024, for about two years, almost two years,we’ve really been sprinting nonstop,and the later it gets, the more compressed everything feels.So when you look at earlier timesthrough the lens of this speed, it feels unbelievably long ago.None of those things are still alive now,though of course they became the seeds that brought us here,but it does feel a bit overwhelming.
Seungjoon Choi After 2022, there were just too many points on the event map.Even if I tried to mark only the major ones, there were still too many.I think it will become clearer with more time.In about ten years, what was truly core, what we noware looking back on over the last ten years today,the big things that now seem obvious in hindsight,just as those have become clear, in ten years the points from this era will also become clearer.
Jinwon Lee It definitely seems like your insight gets deeper after some time has passed.What do you think will happen?When I talk with people,they say, in three years, ten years is too far away.
Accelerating Change and the Future Outlook: The Difficulty of Verification 57:15
Chester Roh So when I ask what they’ll be doing in three years,this comes up a lot.They say they’ll probably be living on the stipend Elon Musk gives out.Yeah, Optimus will be doing all the work,and Tesla will be doing all this labor too,while all the intellectual work will be done by frontier labs and places like that,so maybe we’ll all just be living on stipends and doing nothing.
In a way, everyone is dreaming right now,and saying they’ll try something themselves in this era,so everyone is grabbing onto one thing,but I think people are already skepticalabout whether these things will actually succeed.If you think it won’t work and start as late as possible,there are people who see it as a playbookthat the later you start, the better off you are.You’d think moving first should create an advantage,but instead you go first and become a martyr.If you build it well, someone with more computing resources than meand more market share than mecan just click once and take it all away,because that can happen too.
Jinwon Lee I think about that a lot too. The pioneers right nowshow a direction and say, you can do things like this too,and if they show the possibilities by saying, this would be good to do,then the big players come rushing in behind them and eat up the whole market,and that seems to keep repeating.
Chester Roh But even so, there were still peoplewho escaped all those gravity fields and built services.Back in the old Web 2.0, web era,the basic question was always, hey, doesn’t it end if Naver and Daum build this?But then the mobile era arrived,and with a new form factor came new distribution channels,and the new distribution channel at that timewas ultimately the App Store.A bigger giant, not Korea’s local giants,created those opportunities,and we experienced the ecosystem being reshaped all at once.
In AI, today’s dominant players are also the dominant players from mobile.Coupang, Toss, Kakao, Naver, Baemin,all these intermediaries have already secured their places,and now another platform shift is coming.
Will there be a world where ChatGPT and Geminicontrol all customer access to information? There will be.Or maybe not, maybe it won’t happen like that. Opinions are divided right now,but as Seungjoon wrote,it’s a matter of timing, and the things that are bound to comedo come, so even in how people are preparing for that,everyone seems to have a different perspective.There is no single right answer in the playbook.I think that’s the hardest problem.
Jinwon Lee Fortunately for me, at least for now, in the area I’m working in, AIhasn’t been able to come in that deeply yet.Then again, if you think about it, it is verifiable, but,because the verification process takes a lot of time and is difficult.For example, if you’re making semiconductors,whether this is a good semiconductorcan be evaluated with several different metrics,but the process of evaluating those metrics itselftakes a long time, so for now there’s still a bit of a data shortage,and things like that,but whenever I have a chanceto talk with people at our company,I keep saying, almost like a habit, that three years from now I won’t be doing this job.It’s practically a catchphrase of mine.So I keep thinking about what I should do, what I need to do,and what kinds of thingsmight be good to try, but I still haven’t found the answer.Then while thinking about it, there are also things I need to do,
and urgent tasks pile up, so I work on those,and when I get a moment, I think about it again. I just keep repeating this.I think that’s just everyone’s life.
Chester Roh You farm by day and study at night, something like that,and just a little while ago,in our Fugitive Alliance problem-solving group,while you were talking with them,
The Meaning of AlphaGo’s Move 37 and a Preview of the Next Episode 61:00
Chester Roh Jinwon and Seungjoon came in afterward,and someone said this, right?”I’m not afraid of failing, because I have Claude Code.”If you have Claude Code,you can always make a comeback,and I remember everyone laughing at that.In any case, when it comes to value creation that defines an era,
I think the perspective on what value creation means is changing.It’s not that software is ending,it’s that the era of software is really opening wide,but the era of the people who used to make software is over.
Seungjoon Choi I don’t think technology is that much of a concern.People are the concern.
Chester Roh Right. Then shouldn’t we adapt?I guess so.
Seungjoon Choi Anyway, starting with things likethese posts from Google DeepMind and Demis Hassabis that I saw on the open timeline,and looking at how they’re seeing the future,we took a look back over the past 10 years.In the end, with AI, what Platform 37 means isthat it’s not limited to Go,but rather that these kinds of things, like move 37,are happening everywhere, and that may be what it’s aiming for,or so I was thinking.They didn’t say it directly, but I read between the lines.Things like move 37 happening in this domain and that domain,
that’s what Google DeepMind is aiming for,and one of the areas it’s looking atis biology and other areas where we’ve only seen the surface,things happening right now thatare already underway but that we still haven’t been able to handle, those directions too,are things we should talk about gradually.Still, the reason we deliberatelywanted to look back over 10 years today
is that those kinds of stories will keep coming out endlessly,and at certain times I think it’s important to look back,so we decided to make today a time to look back over the last 10 years.It was fun. Jinwon,
Chester Roh to talk about how on earth we should look at the future from the chip perspective,things like gigawatts and chips,aren’t we planning to hear about that sometime?
Jinwon Lee Yes, I think I had a great time talking today too,and in this process, what we call AI infrastructure,including semiconductors, has also gone throughand is still going through a lot of change, ups and downs, and challenges.It would be great if I could come on again at the right timeand talk about those things.Exactly. As a matter of fact, I saw this morning
Chester Roh that while talking with Dwarkesh Patel,they were discussing what this era of chips and 100 gigawatts will look like.They talked about that.It would be great to center the conversation around that and invite Jinwon, the expert,and talk through those topics.Yes, I’m looking forward to it.
Seungjoon Choi Today was fun.Let’s stop here for today,
Chester Roh and Seungjoon and I will probably move on nextto another theme.Things that are one click away,if we keep staying in overexcited mode about that,it just gets too exhausting.We also want toshift a bit more weight toward AI scienceand that side of things. I wanted to mention that we’re in the middle of doing that.I’m looking forward to it.With one-click things, what I feel a lot is that
OpenClaw Event and Closing Remarks 64:02
Jinwon Lee there are now so many things you can do with one clickthat it’s hard to cover all of them, and hard to keep up with all of them,and in a way it can start to feel a little stale.
Chester Roh I think we’re all gradually adapting to the speed of this change.We’re taking this in at a new kind of pace.But isn’t hedging always important?
Seungjoon Choi At Scionic today, there’s also the OpenClaw event,and didn’t you say Jinwon is going too?
Jinwon Lee Yes, I’m planning to leave right after this ends.
Seungjoon Choi We do need to know what’s happening.
Chester Roh But I think OpenClaw is extremely important.For everyone. We talked about this in the last episode, right?Everyone will end up living the life of a chairman.Whatever you do, you’ll have the strongest possible elite assistants around you,so that even the smallest taskgets done that way.If that’s the direction the world is heading,then the one that builds those elite assistants welland gets chosen by consumers as the final assistant,the one right at the edge, right in front of my eyes, will hold all the initiative,so I think everyone judgedthat OpenClaw has major significance there.
Seungjoon Choi I see. Sounds like you’ll have another fun weekend.
Chester Roh Yes, I’ll go and listen closely.
Seungjoon Choi All right, then we’ll stop here for today.
Chester Roh Let’s wrap things up around here for today.Jinwon, thank you for joining us today.
Jinwon Lee Yes, thank you for having me. I had a great time.