EP 99
Opus 4.8 Launch, Today's AI Competition, and Human Work
AI Trends After Google I/O and Opus 4.8 0:00
Chester Roh Today, as we’re recording, is May 30th, 2026, a Saturday morning. We’ve come back after studying for a few weeks, and in the meantime, Google I/O happened, a new version of Opus was announced, and the world advanced once again. So together with Seungjoon, in relation to all this, we’ll take our time, after a while, to look at what happened and what the implications of those things are.
Opus 4.8’s 43-Day Release Cycle and Faster Model Replacement 0:27

Seungjoon Choi It was a few days ago, right? Was it two days ago, or early yesterday morning? Anyway, Opus 4.8 suddenly came out again. I haven’t even had a chance to use it yet. Still, I did look a bit at the situation on the timeline, so let’s start with that story. So there is a blog post now, and I checked the dates a bit. I wrote the title as a rhythm of less than two months, and Opus 4.7 came out on April 16th. So it has been exactly about a month and a half now. When Opus 4.7 came out, we probably recorded on the 19th, and back then, in this way, the recent Opus releases had been at roughly 70-day intervals. So that was an interval a little over two months. But now it has come out after 43 days. Right. We had expected it would run
Chester Roh at about one cycle every two months, but it’s getting shorter.
Seungjoon Choi The two-month figure is not just something being said casually; it’s something coming up here and there. So when we did the Reiner Pope-Dwarkesh episode, Dwarkesh, in talking about solving problems like flashcards, said that today’s models seem to be over-trained by about 100 times this Chinchilla optimal, and that’s why people use the expression two months. So if a frontier model has been deployed for two months, then it gets retired every two months; there was that kind of pattern, and Dwarkesh is also assuming that premise. From there, estimating how many tokens it was trained on was, how should I put it, very rough, anyway, a very coarse estimate, but in any case, that is where the expression two months comes up. So models come out anew every two months, and retire; there are patterns like that. And this is also something that was carried in Korean news,
but when Sam Altman had a video conversation at an event in Australia, the headline pulled out a provocative phrase like, “If the world changes in two months, do companies need annual plans?” Anyway, Sam Altman seems to have said something with that nuance. So I had thought that two months was a kind of pattern for 2026. But now 43 days has come out, so I also went, huh.
Accelerating Development Toward the Singularity 2:43
Chester Roh But this is what we always expected when we used the expression Singularity.
Seungjoon Choi This cycle keeps getting shorter. The pace of progress keeps starting to increase,
Chester Roh and at some point, there comes a point where it increases infinitely. And that point is what we call the Singularity, and we are moving toward that point.
Anthropic’s Opus Efficiency Gains and the Preview of Mythos-Class Models 3:05
Seungjoon Choi In Anthropic’s blog, rather than benchmarks and things like that, the part at the very end stayed with me, so I’ll read it once. Users will feel that Opus 4.8 has achieved small but clearly noticeable improvements over the previous model. There is still work left to do. We are working to develop and release a model that provides many of the same capabilities as Opus while being usable at a lower cost. And we plan to release
a new family of models with higher intelligence. So Mythos Preview is being used by a small number of organizations, and they said they would make it public once the safeguards are ready. But preparing those safeguards is making rapid progress, so within the next few weeks, they expect to be able to provide Mythos-class models to all customers. So “the next few weeks” would be under 10 weeks. You come to think it will be less than the number 10, so at most two months, right?
Chester Roh It feels like they’re adjusting this model range, the weight class a bit. Now Mythos becomes the new Opus, and Opus becomes Sonnet, and in fact, Sonnet and Haiku now, aside from a few really embedding model-like unit tasks, are almost nominal, aren’t they? When people use Claude Code, they all attach Opus to it. So anyway, Opus,
Seungjoon Choi it’s hard to predict how the name will change, but higher weight-class models are scheduled to come out, and that will probably span the summer, from summer into early fall. But looking at the current pattern, I wonder if it will be around then. I thought something like Opus 4.8 would come out in June or July, but it came out at the end of May. So if we pull that estimate forward as well, it makes me think that something might happen around July. July or August. So then there will again be things we have to newly unlearn and learn, but I haven’t even started yet.
Gemini 3.5 Flash and Signs of the Summer Model Competition 5:12

Seungjoon Choi But while we were just expecting it to be a big event, when we eventually opened the lid, there had also been Google I/O, which we hadn’t been mentioning. Gemini 3.5 Flash was the star at Google I/O, right? So Pro was not ready. But if you listen to the keynote, they keep saying that. In a few weeks, we will be able to reveal the next thing. It seems like it will be around summer; they said things like that. So the timing is lining up, and the current direction is that, in the summer, Google too, in this situation, of course company-wide and across the board, is defending against this, but it felt like there wasn’t one big shot. They are preparing those things, whatever they may be, and then Anthropic is coming out preemptively now. But still, when it comes to talk about performance, on the timeline, people are talking about GPT-5.5. They are talking about Codex, and so the timing for GPT-5.6 coming out is, when Opus 4.8 feels like it cannot beat GPT-5.5, it won’t come out, but when the conversation roughly comes up like this, it probably will.
Model Selection Centered on Token Economics and Latency 6:26
Chester Roh Probably. But Anthropic also Chester used the expression earlier, a smaller model. Opus 4.8 is definitely, compared with Opus 4.7 or Opus 4.6, a bit smaller and more optimized, while maintaining performance. That is how it is being described, and the benchmarks visible from the outside and people’s reactions also do not really say that Opus 4.8’s performance seems to have dropped. Right. Though there are a few. In the benchmark metrics,
Seungjoon Choi there are actually some that have dropped compared with Opus 4.7. And there are some that have gone up. So in the end, this is all a desperate struggle to survive in token economics, is it not? Because we are in a period of constant change. This was the case with cars in the past too.
Chester Roh There was a time when cars competed on engine displacement. So 4,000cc, 5,000cc, 6,000cc kept coming out, and then after they achieved a certain level of efficiency, people said this is enough for commercial operation, and there was a period when it became somewhat flat like that. I wonder if models will be the same. In fact, when we talk about most of our work these days,
interacting with Codex or Claude Code, or with agent systems built out of those, is now becoming company work, I feel. For most people, if email and PowerPoint and Excel used to be open, now agent applications are open on the screen almost all the time. At our company, we have changed almost everything in that direction, so people are basically attached to Slack and work gets finished just by working with agents. That is the direction we are building toward. But the part where I feel something is lacking is latency. I think this topic is going to come up.
Because once you get a satisfying result, the next thing you naturally want is for it to come out quickly. And if that latency comes within a defined level of quality, then rather than whether it is Opus or some top-tier model, I think a concept will emerge of just a fast and good model. That is why Google made this Flash model the main model it introduced this time. It feels like they keep touching on those things.
Seungjoon Choi But when people do not actually get the performance they need, they immediately move up to the tier above, and I think these things are being explored these days.
Gemini Flash’s Doom Boot Demo and Long-Running Tasks 8:44
Seungjoon Choi Regarding Gemini 3.5 Flash, this one video stayed with me the most. It was something Varun Mohan showed. Yes, shall we take a look?
Seungjoon Choi So when Varun Mohan demoed this, I think it would be good to look at it after reading this. By running 93 subagents and making around 15,000 model calls, it had them write a custom kernel, filesystem, and driver from scratch, and after 12 hours, Doom booted. That is what it is. So if we scroll through this,
Antigravity did those things on its own, created an OS, and later ran Doom on it. It seems the part where Doom runs does not appear here, but this probably shows how the source is changing right now. In what Varun Mohan showed, Varun Mohan showed it all the way through to that appearing.
So in the end, carrying out this kind of long-horizon task with low token consumption, though Gemini 3.5 Flash is apparently three times more expensive than the previous Flash model. Still, showing that kind of work being done with an appropriate level of model left an impression on me. So I think everyone wants to do that,
Anthropic Dynamic Workflows and Subagent Orchestration 10:00
Seungjoon Choi and Dynamic Workflows came out this time together with Opus 4.8. This is no longer Google I/O news now, but back to, right? Right? Now back to Anthropic news,
Chester Roh about Dynamic Workflows, which came out yesterday.
Seungjoon Choi For example, if you use the expression ultracode, the UI changes in a flashy way, and something else interesting comes out. So I do not think that part appears here. Just take a quick look. And these days, Claude seems to have this cute concept. They make the videos really nicely. Since it just passes by quickly, it is hard to see in detail what the content is, but it seems like it is trying to build some kind of app. Since it is staged, it may not actually have run that quickly. It is saying it can just go through the checklist one by one, push, merge, and do things like that. Dynamic Workflows is not introduced here, but it works in that sort of way.
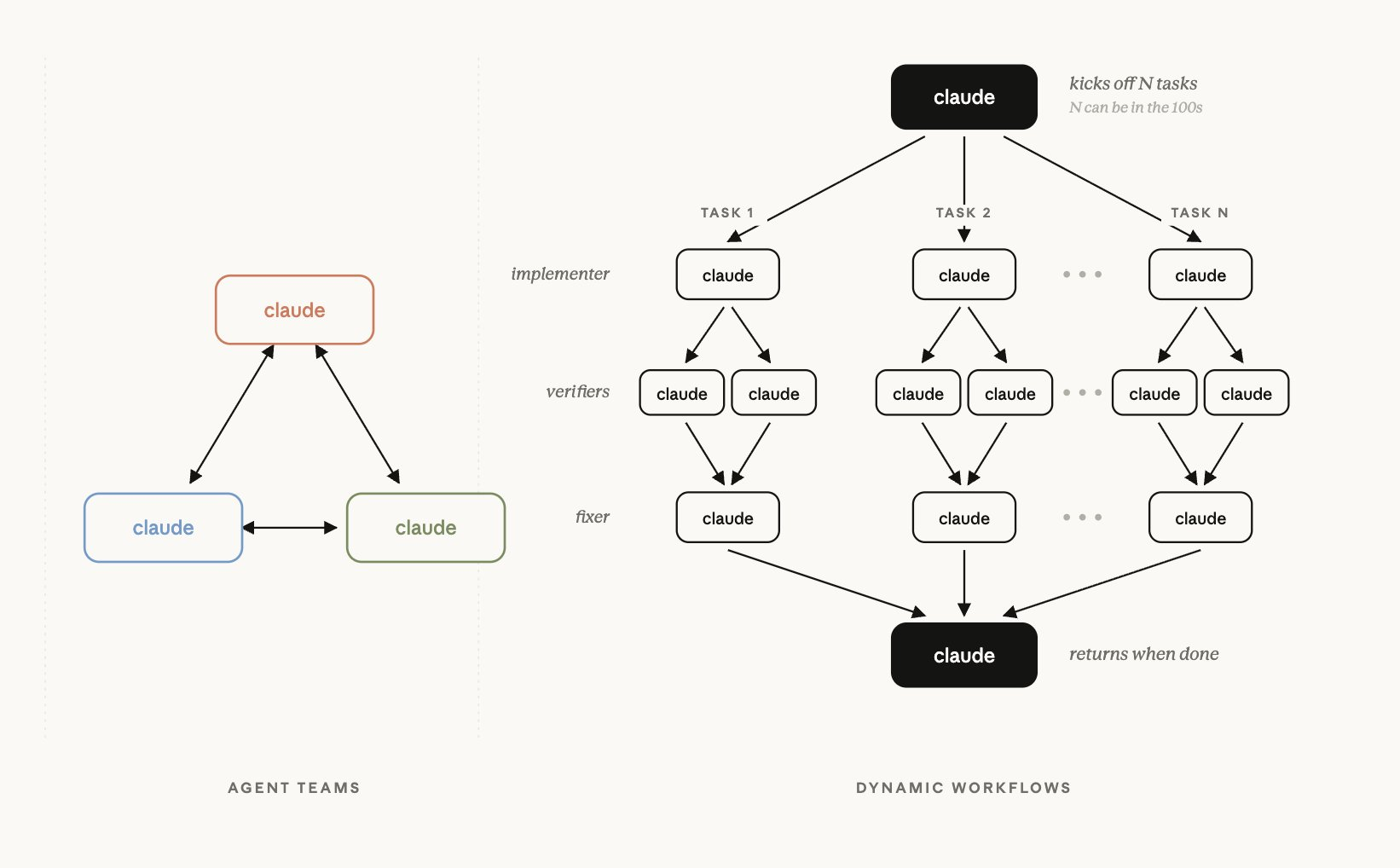
So what Dynamic Workflows is, if you look at the tweet Cat Wu posted, there is Claude like this, and it gives tasks to several other Claudes, they pass things along, and then it synthesizes and synthesizes them. So this is actually a concept we have seen a lot before, but it differs somewhat from Anthropic’s existing product, Agent Teams. The interesting point here, though, is that a large model is not continuously coordinating this. Instead, at the beginning, it writes deterministic code for how to orchestrate it, and then it keeps going until it works. That was the impression I got.
Chester Roh Then the model is not reading all these branch points and making judgments in between. Rather, at the beginning, it creates some kind of, what should I call it? Should we call it a dynamic harness? After they generate that kind of harness themselves. That is the feeling.
Seungjoon Choi I have not used it yet, so I do not know exactly, but from watching a few videos and reading this post, it is JavaScript that coordinates subagents. That is Dynamic Workflows. In a way, if you leave this to the model, the model is actually lazy. Cases where it evaluates something it did itself, and if you make it evaluate itself, it lies and says it is done. That especially happens when you give it difficult work. So when you want to tighten the number of times it does those things, you need deterministic tools and code to check it. But if you make it evaluate that again inside its own context, that becomes a problem.
So instead, in subagents with entirely new contexts, In those kinds of situations, it handles that step by step, though of course, when it works this way, when it is the approach from the diagram earlier, the problem with aggregating this is the need to wait until aggregation is done, what is it, something like pipeline parallelism, I do think that will create a problem, but anyway, apart from that time issue, it introduced some new thing that gets things done with that sort of feel. But the reaction on the timeline was full of people saying, we did that too, there was a lot of that. This is already an existing concept, and Anthropic was just a bit faster, that kind of Right. And as a concept, it is something we were also running well
Chester Roh in places like our oh-my-open agent or OMX.
Seungjoon Choi There was a bit of that kind of complaining or emptiness on the timeline.
The Link Between Managed Agents and Recursive Language Models 14:00

Seungjoon Choi But in this blog post here, it does not appear, but in the earlier post about Managed Agents, the one about decoupling the brain from the hands, an interesting study was cited. Here under prior work, if we look now, for example, context can become a kind of object, and where is it an object? In the REPL, so REPL. I mean, REPL is a coding tool. Is it read-eval-print loop with a feedback loop? I suddenly cannot remember, but anyway, we usually say we use a REPL quite often, and this feels like using some decisive tool that lets an LLM do that programmatically. But the paper cited here is a paper called Recursive Language Models. So this person named alex zhang said something like this. Read our paper. This is already a regime that has been done before. That was not the only person saying something like that. But this thing called RLM was in DSPy. So
Chester Roh But Omar Khattab is one of the authors of that RLM paper, and Omar Khattab is the person who created DSPy at Stanford, so it makes sense that Omar Khattab would have included it. I did not know DSPy well, and I was only aware
Seungjoon Choi that it existed and that people talked about it a lot, but seeing things done this way, I thought this is becoming a bit of a trend too, so
Meta-Optimization Through DSPy and TextGrad 15:40
Chester Roh If you look at DSPy, and then TextGrad, and the things we just talked about, they are all a kind of meta optimization. Seungjoon, in the end, once one layer is built, something else gets built on top of that layer, and then something gets built on top of that layer, so I think it is accurate to think of it as raising the level of optimization by one more layer. DSPy also ultimately says the performance of a prompt itself can keep being improved by running a meta optimizer. It is exactly the same as Karpathy’s concept of auto research. As long as any problem has an evaluation metric, whatever we configure the model to do, by simply putting in optimized computing, it can be converted into improving performance, in other words, into searching, and solved that way. I think that is the core idea. If you look here, just reading a few parts,
Seungjoon Choi having the LLM do code execution and recursive sub-LLM calls is what DSPy, meaning RLM, deals with. Then in Managed Agents, there was a connection where the session abstraction is placed as an object outside the context, using a sandbox and REPL. There was that kind of link. Then Dynamic Workflows says that when orchestrating it, you put something in the script, not in the context. So those decisive tools are ultimately what the harness is doing. So it is moving toward using a script to tightly constrain and control it.
But probably with Gemini 3.5 Flash, in the video earlier where it ran quickly, I would guess the hidden thing it was trying to show is on a similar layer. It is not just the model doing it. It uses a scaffold or harness for that to make an OS, enough that it can launch Doom right away, and it carries out a long-horizon task all in one go.
Chester Roh Exactly. Even that long-horizon task, if you look inside it, rather than ending cleanly in one-shot, it handles countless errors, right, errors, by constantly running evaluation, saying, this is wrong, fixing it and coming back, then this is wrong again, fixing it and coming back, in a kind of so-called tinkering process.
Seungjoon Choi Tremendously so. What happens in mathematics is similar too. You form a hypothesis, test it, then a problem appears. You record it, gain insight from that record, form the next hypothesis, and keep pushing that forward continuously. Right. So the article you just introduced
Chester Roh is ultimately different only in what it changed the objective for this model to, while the methodology being used is actually the same meta approach.
Code as Harness and Cloudflare Dynamic Workflows 18:27
Seungjoon Choi Alan, who is the CTO of Corca, said something like that, and Alan used an interesting expression. Alan called it code as harness. When I heard it, it kind of stuck in my ear, and while saying that, Alan introduced Cloudflare’s Dynamic Workflows and this Project Think, which I had not known about. But the name is the same here too. Dynamic Workflows. So here too, in building next-generation agents, it becomes code as harness. So they are building a kind of cloud platform that can take whatever you bring to it and get it done, and the same story comes up again. Long-running agents, actor model, Durable Objects. So even if not in detail, I was able to grasp, at least intuitively, that everyone is moving in this direction.
Growing Demand for Latency and Harnesses in Enterprise Agent Use 19:22
Chester Roh Right. Since I also see every day in our Slack the tasks that our company members assign, when an agent is given a fairly complex task, it basically runs for 20 or 30 minutes, and even when it runs very briefly, it still runs for about 10 minutes. So as a result, needs around latency start coming up. And that harness too, right now, we are mostly using the harnesses that are already out there, but this sense that we need to use our own harness keeps coming up as a need as well. Right. I would like to introduce this sometime later,
Seungjoon Choi but the agent-building work with Minecraft that I was doing a year ago, I have been revisiting it lately, and the world has changed. Yesterday, before going to sleep, I set a 10-hour run going and went to bed, and in the morning it was showing some kind of progress. But looking at that process, for the latest version of Minecraft, attaching a bot called Mineflayer is still something the open-source project has not caught up with yet, so I tried building it once from the ground up, and when doing that, guessing the protocol, extracting block IDs, and building it up that way was really fun. I will introduce it sometime later.
Chester Roh Now there is this feeling that you just have to think. But the regrettable thing is, when I woke up and checked,
it reported that only 8% of my Codex weekly limit was left, so you end up using a lot of tokens.
The Erdős Problem Solved by AI and Changes in Mathematical Research 20:42
Chester Roh So separately from those things, there were interesting developments in mathematics in May as well, and as I mentioned briefly earlier, it does feel related. I am not someone who goes deeply into mathematics either, so I only looked at it roughly, but one of the Erdős problems, and there are various Erdős problems, the model managed to solve one of them, so there was a period around mid-May when the world was somewhat surprised again. So OpenAI did that not with GPT-5.5, but I think this was probably an internal model. It seemed to have done it in an internal model with a special scaffolding, and then Sholto is at Anthropic now, right? So Sholto praised that once, and then posted that Mythos had done it too. I did not put the link here now, but there was also one saying Gemini had done it too, there was that. So they all accomplished similar things. But besides that, what I found interesting was this expression from Noam Brown. So if you follow this link, it keeps taking you to other people, and I translated that here. But even though I translated it, it is hard to read the meaning. Anyway, all the people in mathematics were saying that this was extremely interesting,
Human Mathematicians Becoming Stronger, Like Go Players After AlphaGo 21:59
Chester Roh so after first introducing Noam Brown’s comment, Noam Brown said that after AlphaGo, the skill of human Go players improved noticeably. I think a similar pattern will appear in mathematics. So this is that story, and what the mathematicians were talking about was not the story of OpenAI’s model solving it, but the story of mathematicians solving it. So after it became known that the model had solved that Erdős problem, mathematicians were also inspired by it, and a phenomenon occurred where they rapidly advanced something. So that is extremely interesting. Timothy Gowers here is also a famous mathematician. So this time, another problem in additive combinatorics, a major problem, was solved. This time it was done by humans, not AI, but they used methods related to the AI solution for the unit distance conjecture. In other words, they learned from the AI solution and used it. And that is like what 신진서 9-dan and others do, where they learn themselves by playing a lot against AI. Those kinds of things are happening, and what was interesting about OpenAI’s attempt this time too was that it gave humans a very important role. It was not that the model pushed forward and did it alone, but rather that humans properly performed the evaluation, with that kind of mechanism included, so it was somewhat different from previous attempts. So it is starting to feel like human in the loop is being treated as somewhat important. So this is something I read with GPT, and the point is that just as human Go became stronger after AlphaGo, maybe AI has started expanding humans’ search space and intuition in mathematics as well.
Chester Roh It seems almost obvious that it would.
Seungjoon Choi In OpenAI’s Erdős problem this time as well, if it were just a human, a human mathematical expert, even within one field of mathematics there are multiple genres, such as scholars well-versed in number theory and scholars well-versed in combinatorics, but they may not know each other’s literature. But because AI knows the whole picture through pretraining, it becomes able to connect between those bodies of literature, and that nuance was quite strong. So when humans are stimulated by those things and realize that they too can connect these things, transfer becomes possible, and I read this as a signal that such things are beginning to happen.
So the content here from just talking with the model is interesting, but I will just move quickly past it. So it was an event that changed the terrain of human creativity. Not an event that killed creativity.
The Coexistence of Generative Cognitive Decline and Intelligence Augmentation 24:31
Seungjoon Choi So what I have been thinking a lot about lately is that around last spring I talked about generative indigestion, and what I have been thinking about these days is generative cognitive decline. If I keep offloading my thinking, delegating it to the model, and making it think on my behalf, it feels like my own power to think, my thinking muscle, is shrinking. And while studying the Dwarkesh episode too, what stimulated me about flashcards was that after having a deep conversation, if I make flashcards about it and ask myself, I realize I am quickly forgetting a lot of it. Making it generate on my behalf caused cognitive decline. So I got a strong sense that my skill was decreasing, my own capability was decreasing, and I had a lot of concerns about that, and those things are clearly happening right now. Worryingly. But on the other hand, there are parts that are outright doing intelligence augmentation or amplification. So this current round, too, is making me wonder again whether technology is acting as a tool of disparity. That is something I find myself thinking about. Last summer, I imagined that the closer we got to superintelligence or AGI, it would become something that really narrows the gap, that it would become an opportunity, a new, unprecedented opportunity. But when we actually opened the lid and looked, dopamine is bursting like a slot machine, and of course it gets work done, but my own abilities may actually be deteriorating, while, on the other hand, some people are acquiring abilities. That is what I keep thinking about.
Work and the Human Condition Changing in the AI Era 26:05
Chester Roh Depending on how you look at this, I think it is an issue that will keep changing in a thesis-antithesis-synthesis kind of way. Right now it seems to widen the gap, but in the end, it will probably reduce the gap a great deal.
Seungjoon Choi The average may rise. One way or another.
Chester Roh Right. In the past, the concept of work seems likely to become completely different from what we think of now. For example, in the past, when building a house, if the question was how much dirt you could move per unit of time, then naturally stamina and know-how, those things were the person’s capabilities. But with machines like excavators, machines like backhoes, now it is actually that certification test, it has changed into a driver’s license test. In the same way, for us, the picture has not fully formed yet, but in areas related to the knowledge industry, if we have used the muscles of thought to solve problems, that will no longer be needed, and some new kind of certification or ability at a different form, a different layer, will emerge, I think. Since we are working with agents every day now, I also think a lot about what it really means to be good at work. This is not today’s topic, but it is something I really wrestle with.
Seungjoon Choi It connects to the human condition, because thinking was the work of humans. But that is moving elsewhere, so it is quite troubling.
Seungjoon Choi Personally. The idea that thinking is the work of humans is actually also a common assumption. Whether that is really true. Yes, yes. Then we can pose a challenging question.
Simon Willison’s View of OpenAI and Anthropic’s Product-Market Fit 27:40
Seungjoon Choi So for the final part of today’s discussion, returning a bit to reality, Anthropic and OpenAI seem to have found product-market fit. I found Simon Willison’s post on this very striking. It was on May 27, and Simon analyzed, using the API, that OpenAI had 703 job postings and Anthropic had 390 public job openings. So I will not read all of this, but if you look at it, enterprise customers are now paying API prices. They are locked in. They have crossed the river now. They cannot not use it. Of course. The $100 or $200 per-person plans,
Chester Roh aren’t almost everyone getting one now? Not just engineers anymore, because other people are now using Claude Code too. For us as well, among non-engineers, the share of people using the $100 or $200 plan is increasing.
Seungjoon Choi I thought companies using agents broadly would be getting similar discounts. But it turns out I was completely wrong. It is getting more expensive, and now they have to pay API prices. Since they cannot avoid paying, they are now imposing penalties on those usage fees. Claude is doing that, and Gemini is doing that too. OpenAI is still okay, but once they start penalizing usage fees, if you have to pay API prices, putting it into Slack will become very expensive. But you have to use it.
Chester Roh Then you have to move to Codex. Right. But if Codex also cannot withstand it, then you can switch again,
Seungjoon Choi so I think there is a chance we cannot feel completely at ease.
Token Prices and the Long-Term Direction of AI Demand 29:11
Chester Roh But how do you see it? Token prices have a lot of room to rise in the short term right now.
Seungjoon Choi Prices in China are rising too. Demand keeps increasing.
Chester Roh Looking at memory prices rising now, it is true that demand keeps growing. But there are two views of this demand. One view is that the people who are going to use it are already using it, and we are almost at the end, that we have reached this plateau. But the people who hold that view are mostly outside the tech world. From outside, from an investment perspective, there are groups interpreting this or that, saying Anthropic and OpenAI are in danger. But from the perspective of people inside tech who get excited about Jensen’s keynote and then watch announcements from OpenAI or Google and applaud like this, people on the inside of tech, many think this has only just begun. Hasn’t it only just begun? Token prices will become like electricity, like electricity. So as for how that will turn out,
Seungjoon Choi I do not know exactly either. The prediction in the previous stage was naturally that it would get cheaper. But this rally, this peak, I do not know how far it will go, but it feels like the slope has changed a bit, and where that will go is something nobody knows, isn’t it? But when I look at it historically,
Chester Roh betting that this will come down is unquestionably the higher-probability bet.
Seungjoon Choi So in any case, companies are locked in, and because they are paying, because they are paying money, Simon’s view is that at least those two have found product-market fit. Both are preparing for IPOs, but because so many people are paying now, maybe they could even turn profitable? That is the kind of talk going around. Before the IPOs. So as those discussions are happening,
Expanding Hiring at AI Companies and a Reinterpretation of Developer Employment 31:13
Seungjoon Choi what follows is that they are expanding. So when he looked it up, OpenAI currently has 703 public job postings, and among them, 229 are support-related, and other various roles. And those include roles like Go To Market or FDE. And Anthropic also has 390 public job postings. So Meta recently had another issue because of laying off 8,000 people, and Microsoft also felt like it was continuing to trim down, but these areas are expanding.
And again, what has been showing up lately on our timelines in Korea is that developer hiring is increasing, and I saw some news like that. So maybe these two things are coexisting right now too? On one side, they are raising talent density and pushing ahead with small teams, but on the other hand, developers who use AI are still needed more because AI cannot do it alone, so is increased hiring happening alongside that? I am not really sure either.
The Shift from Engineer to AI-Native Problem Solver 32:19
Chester Roh I think the meaning of the expression developer now…
Seungjoon Choi Everyone is just a builder? Yes, everyone has become
Chester Roh some kind of problem solver on top of a new layer, and if someone knows how to use Claude Code, should we call them a new engineer? None of the engineers are coding right now. But when you look at engineers who are good at solving problems now, what kind of engineers are they? Still, across various layers, what kind of problem happens in AWS, then what kind of problem happens in the web server, how to distribute that workload in Redis, how DB optimization should be done, what SQL is, what C is, and so on, from the overall OS to architecting to the service, people who had perspectives on all those various parts become much more powerful when they meet Claude Code. Things that juniors used to have to do. But the problem is, that is as far as it goes. Customers are not buying that architecture. Customers are buying the fact that their problems get solved. Then what became faster before was, when someone said, make me some app, requirements would arise for that unit app, a PM would analyze the requirements within it, a designer would lay that out and then write a PRD, break that into tasks and so on, and it would be built and put a new UX workflow in front of the customer’s eyes. Only that interval got shorter, but then using that to actually acquire more customers and solve problems, that interval is still a remaining problem.
Then now, with all those capabilities in place, you have to understand what the customer’s problem is, and instead of dealing with the customer through marketers and salespeople, you have to skip even them and have the capability to talk directly with the customer. So now, with that kind of engineering capability, someone has to be able to solve the customer’s problem, or in our old way of putting it, they have to have even the capabilities of marketers or sales, for this problem to be solved in one go. So as for the idea that hiring engineers is increasing, I think we need to look at it carefully. If the number of engineers by traditional standards simply increases, and someone says, do you know how to use Claude Code? Yes, I do, and one more person like that is sitting inside the company, that does not really make anything better.
In the end, it is about the customer’s problem we have kept talking about, the problem-solving point in that domain, and how to get Claude Code to do that well. In how to get Claude Code to do it well, having engineering capability does help, but even that kind of capability is actually something that, as we build workflows with agents, we feel a lot: it keeps becoming tacit knowledge, and keeps accumulating inside the agent’s memory. So in the past, if we just said, yesterday’s sales, it would just hallucinate however it wanted, but because there is context that has kept accumulating, now, even if we just say yesterday’s sales to our agent, it processes it accurately from the perspective the company wants. Likewise, things related to engineering, like architecting and so on, can sufficiently, if anything, become tacit knowledge in an even more structured way and accumulate in the agent, so in a way, more and more, the engineering capabilities we had in the past are becoming slightly unnecessary too.
They are being encapsulated and accumulated down into the lower layer. To put it more clearly now, rather than the concept of an engineer, it is right to define everyone as a problem solver and as an entrepreneur of a unit business, and at my company too, among the people who now use our Claude Code and do engineering in the traditional sense within that job category, half are from traditional engineering backgrounds. The other half are not from traditional engineering backgrounds. People who used to be marketers, people who used to just be PMs. When even those people combine it with Claude Code, and simply bring in the tacit prompts already created by engineers and start calling them as skills, they often experience the problem being solved in one go. Now the concept of personnel will change.
I think the terminology just has not clearly emerged yet. We are simply calling all of that collectively engineers. If a company made a decision to hire an engineer who knows how to use Claude Code, without any deeper basis, there is a possibility that the company’s management still has no idea at all what the essence of the problem is, So what goes a bit further than the concept of an engineer is now what is called an FDE, Forward Deployed Engineer, but I think it will go even further than FDE. I personally call it AI native talent right now, and now there are people who have everything equipped.
Demand for Talent Using AI and the Expansion of the Problem-Solving Market 37:26
Seungjoon Choi In the end, from the perspective of supplying this AI, it does not matter who it is. The person who will use AI, in the end, becomes their customer in some form, so it does not matter who it is, Whether it’s an engineer or a builder, the need for people who use that AI may not be shrinking as a profession, but could also be increasing in some areas, and that was what I came to think while reading Simon Willison’s comments. I agree with that point too. In fact, there is more work for people to do now.
Chester Roh And Jeongkyu said that back then too. Because people create problems faster than they solve problems, demand will also grow by a lot. And the concept we traditionally called engineers will probably move down one layer into how to make inference faster, advanced token engineering, infrastructure engineering, model building, and areas like that. If AX succeeds,
Seungjoon Choi that means becoming talent that can use AI well, so that person keeps their job, and if we are still at a stage where people who can use new AI are needed, then employment could increase, which is something I thought a bit while reading Simon Willison’s story.
Rising API Costs and Demand for On-Premises Models 38:50
Seungjoon Choi But we can’t know for sure. So in the latter part here, because of AI, costs increased. But since now, in November, people made budgets last year and are spending this year’s budgets, a gap, meaning a difference, is occurring, and from now on, they should be able to adjust that again, was the vague feeling I got as I read it. Anyway, around April now became one major inflection point, according to Simon Willison. So I skipped over some of the middle here, but investments by the labs are continuing, though we don’t know how long they can sustain this, and the importance of API revenue is decreasing. I don’t quite remember what that was about right now. People are flocking much more to the $200 seats, and for example, large enterprises, banks, or companies that do business with massive IPs have a hard time using Claude Code or things like that. So they need to take the Claude Code harness and attach local models like Qwen or GLM to run it. For example, models around GLM 500B or Qwen at that level are quite good. We know Cursor’s model was also built on a Qwen base. Like that, there is also enormous demand inside that space. Within large enterprises, Claude Code or Codex as on-premise solutions, in any case. In fact, now Claude Code or Codex are not coding agents, but seem to have become very basic default problem-solving apps. We need to understand that well.
Seungjoon Choi In the end, we need to know in detail what scale of model is needed to solve the scale of the problems we handle, and allocate them well. Otherwise, the budget will be badly off, and it will just disappear in an instant.
Chester Roh The model’s performance, should we call it accuracy? I think it may be a trade-off between a model’s benchmark performance and latency. Anyway, including those kinds of discussions,
Seungjoon Choi I read this just a day ago, yesterday, and I already don’t remember it well.
The Expected Summer Competition Among Gemini, Mythos, and GPT 41:19
Chester Roh These days we said a month feels like a year, and then we said two weeks feel like a year, but now there are surprising growth moments even within almost a week.
Seungjoon Choi That too, and because I look into so many things, I feel like my cognitive ability is declining a bit. I say I tried to look through a lot and digest it, but I fail. Still, at least an index remains. I still remember what I saw, what is important, and what I should try introducing, and one of the things left in that index this week was Simon Willison’s post. This says April was the inflection point. I came to agree with that part too, looking back.
Seungjoon Choi And I find myself making a rough forecast that there may be one clash in the summer. That Anthropic Mythos-level model, OpenAI’s model that counters it, Gemini’s model, all of those are now pointing toward the fact that tomorrow is June, the day after tomorrow is June, and as we enter summer, they will once again make things hard for us while also making us expect more.
Chester Roh Gemini 3.5 Pro and Anthropic’s Mythos and GPT-5.6, representing the world’s major players. Then we will have to decide whether to maintain
Seungjoon Choi what had already been running well, or migrate and overhaul everything again. It is something scheduled to happen.
Chester Roh There isn’t much time left either. Within two months.
Seungjoon Choi So if you want to study something and build your capability, when a model comes out, you have to study that model. So things that keep us from focusing on what we need to focus on are now repeating like a treadmill, so as we learned last time in the Dwarkesh or Reiner Pope episode, if you’re going to learn, you have to do it quickly. Exactly.
Harnesses and Cost Optimization Becoming More Important Than Model Performance 43:07
Chester Roh I really feel that we are actually talking about models considerably less. This one has passed a certain level. Tracking this one’s progress is no longer the more important discussion. Now the gear has shifted up to the next layer. Models are now good enough, and whether that improvement takes this toward AGI or not, for my own unit of work, how do I solve it at the lowest cost and the fastest speed? That depends on the model’s capability and the degree of the harness, and judging how to align these things well seems to be what is becoming important now.
The AI Platform Cycle and Infrastructure Boom from a16z’s Perspective 43:51
Chester Roh And I suddenly saw something this morning, I think, from a16z. In the internet era, the mobile era, and things like that, which we always talk about, when there was some kind of tech boom in the past, what kinds of things happened? At first, it was always chips, and it was the same during mobile. Low-power chips and things like that were huge issues for quite a while, and companies like Qualcomm and ARM kept benefiting from that, and then came companies like iPhone or Android, and above that, it was really applications. On top of that, apps like Uber or KakaoTalk or Airbnb and these new layers of apps kept rising, and now AI seems to be doing the same thing. In that sense, maybe the fact that NVIDIA and SK hynix or Samsung Electronics’ stock prices are hitting these huge peaks right now does not mean this is the peak and the AI boom will soon die out, but rather that this is only the opening act announcing the start of this boom.
People always have this bad habit of evaluating the future by the standards of the past. Patterns from the past do repeat, but within those patterns, the intensity and amplitude that exist along the y-axis have to be relatively reinforced and adjusted before being used. It has to be inflation adjusted, so saying that mobile went this far before, and compared with that, this must be the peak, could be very wrong, in my view.
Vinod Khosla on the Upside of Demand for Intelligence 45:30
Chester Roh And at Khosla Ventures, there is someone who created Sun Microsystems, an older gentleman I respect. His name is Vinod Khosla. But Vinod Khosla said this is different from the apps that existed before. Because this is intelligence, there is no upside limit. For example, suppose there is a drug that lets people live infinitely, forever, and cancer has been solved. Then, because cancer has been solved, would that be the end? No. People would want to live forever, and would wanting to live forever be the end? No. They would want to live a prettier, healthier life, and after that is done, they would look for the next thing, so there is no end. Human desire is open-ended. But the transitions of past platforms always had a clearly closed-off ceiling on what they could deliver. The internet came along. Then, yes, the market may grow somewhat, but compared with past TV or newspapers it was a few times bigger. Something happened because of mobile. Then even people who could not buy PCs could participate, so it became a few times bigger, but this is intelligence. He said demand increases almost forever, and I very much agree with that.
The Possibility and Meaning of IPOs for OpenAI and Anthropic 46:42
Seungjoon Choi If I were to just say anything about the near future, I have been seeing a lot of news saying that OpenAI and Anthropic could do IPOs within this year, and I understand that, but what happens if they do an IPO?
Chester Roh If they do an IPO, since they already have no problem fundraising in the private market right now, I think an IPO would be a kind of milestone in its own way. Right now, from those companies’ standpoint, there is really no problem with employees selling shares they received in the private market and things like that, and everyone wants to buy them, but if they go public, the liquidity of that just increases sharply. And then, for existing investors, there are a lot of obligations that had been tied up. For example, in private rounds, if they raise through Series A, B, C, D, E, and so on, they can raise the valuation, but those come with many conditions that constrain the company’s management.
But most of those are released, and the point at which investors simply leave after five years with no relation to the company is, in fact, the IPO. Once they enter the public market, then under a free-market competitive system, the response can be the stock price falling, or if people want to sell, they sell, and if they want to buy, they buy. So from the standpoint of a company that has kept receiving investment, it is a moment to resolve that once, and also, legally, without depending on someone else, they can continue fundraising under the company’s lead, and raising the valuation becomes a kind of ranking in its own way. Even now, you see who is first, who is second, who is third, so among those people as well, a kind of leaderboard emerges. I did an IPO. The company’s valuation is this much. Things like that may simply be getting marked objectively as they go. But what is more important from the standpoint of investors like us is whether that IPO will be the beginning or the end.
Seungjoon Choi In any case, a four-letter code gets created.
Chester Roh We’ll have to watch. Right. I do not know what it will be,
Seungjoon Choi but how should I put it, OpenAI will get some kind of ticker. Wouldn’t they have already reserved them all?
Exploring Hardware and Inference After Episode 100 and the 3rd Anniversary 48:54
Chester Roh I am curious. Our next one is now episode 100. Since we started in May,
Seungjoon Choi episode 100, the third anniversary, and then we passed 30,000 subscribers.
Seungjoon Choi Several things have overlapped, Several things have overlapped, but shouldn’t we just continue plainly, like usual?
Seungjoon Choi We do have a plan for some topics we want to cover, and as an extension of what we studied in the Dwarkesh episode, we are at the stage of talking to guests because we want to understand more deeply why we need to know this kind of hardware, and the technologies underlying what is happening now. Yes, actually, as we enter the agent era,
Chester Roh the importance of inference is becoming enormous, and because an enormous number of tokens are really coming in, we thought it would be meaningful to take a look inside that token factory, and in relation to that, from deep inside the hardware to the orchestration layer that orchestrates those things, and the software domain that sits above it, we are thinking of taking a look through that space. I don’t know whether we’ll be able to do it well,
Seungjoon Choi but I wanted to say that we do have that kind of direction in mind.
Silicon Valley Schedule and Preview of the Next Episode 50:07
Chester Roh That’s right. And now summer is approaching, and it seems Chester has other plans as well, That’s right. I’ll be in Silicon Valley in June,
Chester Roh so if people in the Bay reach out to me a lot while I’m there, I think it would be nice to catch up and share updates.
Seungjoon Choi I think we’ll probably have to do this remotely at least once too.
Chester Roh Yes, I think we’ll have to do it remotely a few times.
Seungjoon Choi I hope you have a great time.
Chester Roh Yes, Seungjoon. Thank you for your time today.