EP 78
Ilya Sutskeverの説明
オープニング: Ilya Sutskeverと「研究の時代」宣言 00:00
ロ・ジョンソク 収録している今日は2025年11月29日、土曜の朝です。今週いちばん大きなニュースを挙げるなら、やはりIlya SutskeverとDwarkesh Patelのポッドキャストでしょう。
Ilya Sutskeverが、現在のpre-trainingは壁に到達した、何か新しい発想が必要だ、これでスケーリングの時代は去り、研究の時代が再び到来した、という話を軸に語って、コミュニティが一度ざわつきましたよね。インパクトが大きかったのか、少し修正したツイートも上がりましたし。スンジュンさん、要約をお願いします。
チェ・スンジュン 今のお話を聞くと、Claude Opus 4.5が埋もれましたね。Ilya Sutskeverの話題で。
ロ・ジョンソク 多少そういう面もありますが、エンジニアの間ではClaude Opus 4.5が非常に賢い。なのでAntigravityとClaude Opus 4.5を行き来して、トークリミットが来たらあちらに行ってこちらに戻って、という流れが少し定着した感じです。
チェ・スンジュン なので今週も、期待していたことがひとまず全部明らかになった状況で、まずIlya Sutskeverの話から始めたんですが、タイトルはひとまず「イリヤトークン」にしました。今朝未明にタイムラインがあまりに沸騰したのか、Noam Brownが整理した投稿を上げていましたけど。タイムラインの沸騰を、ソンヒョンさんはどう見ましたか?なぜこういうことが起きているのでしょうか?
スケーリング論争: 経済・安全保障問題へ拡張したAI 01:17
キム・ソンヒョン もしAIという領域自体が学問的な領域だったら、こういう問題は起きなかった気がします。学問の領域ではこうした論争はずっとありました。LLMは可能だ、無理だ、Yann LeCunをはじめとしてそういう議論はありましたし、それは日常的なことです。でも私は、スケーリングというテーマ自体が大きすぎる経済領域の問題と結びつき始めた気がします。私としては少し戸惑いもあるし、非常に慎重にさせられる部分でもあるんですが、スケーリングが論点になると、ではデータセンターをたくさん建てなければならない、莫大な投資をしなければならない、となります。
データセンターをたくさん建てるというのは、単にGPUをたくさん買うだけでなく電力インフラも必要で、そのインフラを整えなければならず、結局投資額が大きくなって、これは政府保証が必要だという水準にまで進んでいますよね。そうなると、そのスケーリングは本当に効果的なのか、そこまで投資することに本当に可能性があるのか、そう投資すればAGIが来るのか、このテーマは単なる学問問題ではなく社会経済問題になったように思います。国家的問題になっている気もしますし、場合によっては米中間の対立という形で安全保障イシューにもなっている気がします。あらゆる経済領域と国家安全保障領域に影響し始めたんです。だからこそ、これがより沸騰しているのだと思います。
似たパターンはGPUとTPUの論争でも起きている気がします。GoogleがTPUを使っていることを、AIエンジニアで知らない人はほぼいなかったはずです。Googleは以前からGemini 1.0の時点でTPUを使っていましたし、Gemini 3でTPUを使ったのは当然です。その前から使っていたので。でもTPUを使ったというニュースが、別のタイプの集団、つまりGoogleがTPUを使っていることを知らなかった人たちに伝わり始めると、ものすごい波及効果を起こすんですよ。おそらく株式市場にも実際に影響したのではないかと思います。だからNVIDIAが説明することになります。GPUとTPUは違う、GPUには競争力がある、という説明をしていました。
チェ・スンジュン 俗に言えば賭け金が大きいってことですね。
キム・ソンヒョン 大きくなりすぎたんです。大きくなりすぎて、この事実ひとつにかかっている問題があまりに大きい気がします、最近は。
ロ・ジョンソク 実際、この1週間の株式市場はソンヒョンさんがおっしゃった通り、まさにそのように動きました。GoogleがGemini 3をNVIDIA GPUを使わずに作ったというその一点だけで、Google株はかなり上がり、NVIDIA株は揺れました。ふらついたと言ったほうが正確ですね。
チェ・スンジュン そういうことがあったんですね。ではまずNoamが何と言ったのか見て、また戻ってきましょう。
人物紹介: Ilya Sutskever 03:59
ロ・ジョンソク この話を議論する前に、Ilya Sutskever、Noam Brown、Andrej Karpathyのような方々をご存じない方も多いと思うので、Ilya Sutskeverは非常に伝説的なGeoffrey Hintonの弟子であり、AlexNetを最初に作った伝説的AI研究者です。Googleに行ってsequence-to-sequence RNNモデルを作り、language translationも作って、その後OpenAIに移り、前回Sam Altmanとの経営権争いでOpenAIを去った、AI時代を代表するアイコンです。だからこの人が何を言っても市場が揺れ、やや先覚者モーセのような役割をしているのではないかと思います。それだけ重みのある人物の発言なので、私たちが注意深く聞く必要があるわけです。
チェ・スンジュン それで今回、Dwarkesh PatelのIlya Sutskeverインタビューは2回目なんです。1回目はGPT-4が出た2023年3月でした。なので今回は2回目のインタビューで、そのインタビューがSutton編と似ていて、さらにAndrej Karpathy編も似た形で、Dwarkeshがそういうキュレーションをしています。別の地平を見せようとするキュレーションをしているので、それが論争を呼んでいて、見方によっては健全な方向性かもしれないと思います。
Ilyaの釈明とNoam Brownの整理: スケーリングと研究のギャップ 05:15
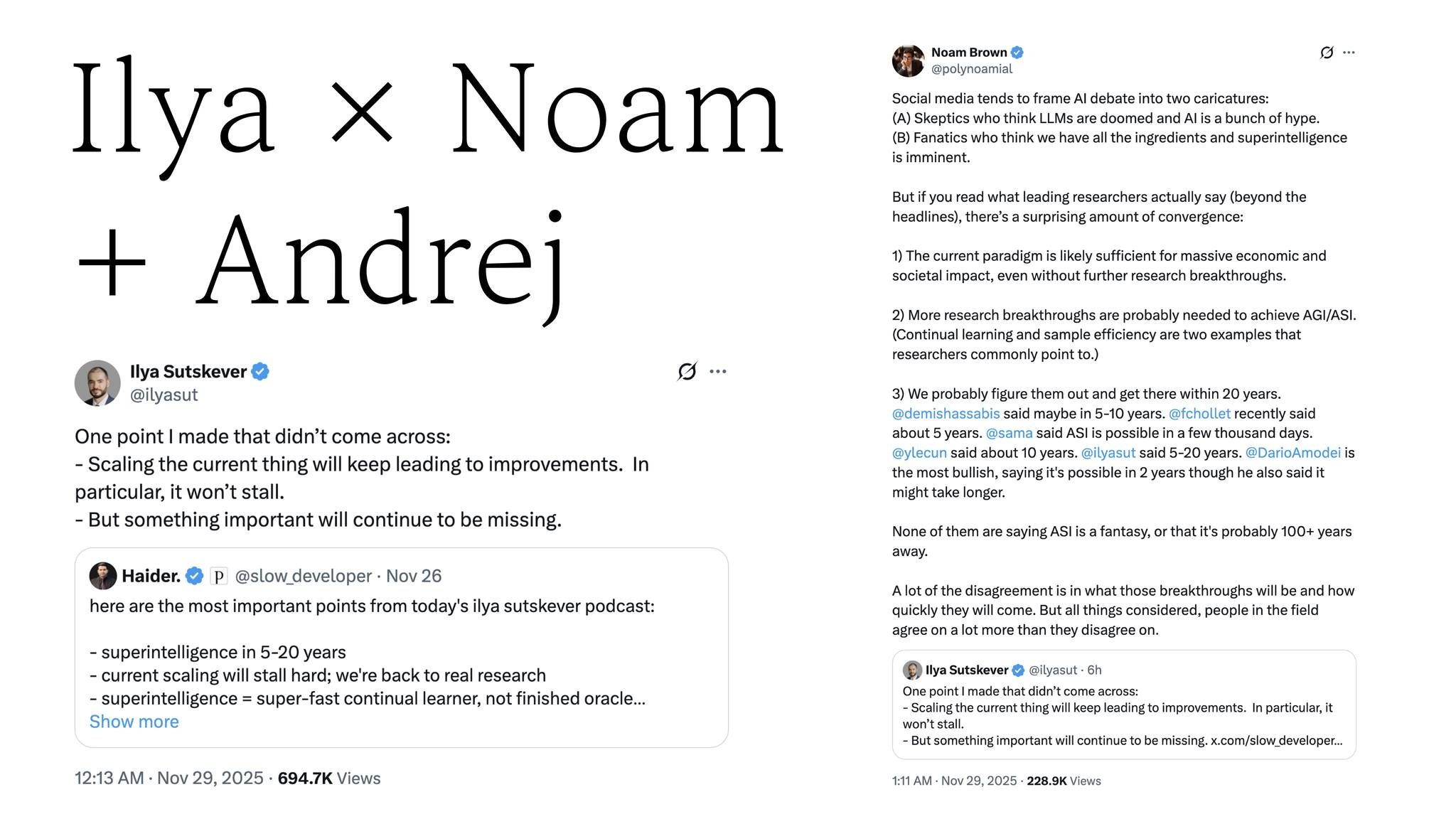
チェ・スンジュン ところが未明にNoamが少し整理してくれました。Ilya Sutskeverは、自分がDwarkeshインタビューで話した内容の中に伝わっていないポイントがあると。誰かが自分を引用しながら整理した部分をリツイートしていて、それを引用しながら話したんです。今の方法をさらに大きくしていけば、つまりスケーリングすれば性能向上は続くのであって、ないと言っているのではなく、少しギャップがある程度だと言った。特にこれは途中で止まるわけではないと、もう一度補足しました。ただ、それでもなお重要な何かは引き続き欠けているだろう。だから自分のポイントはそこを話したことだとツイートしました。
ところがそれをNoamがもう少し誇張して説明したんです。Noamが強調したのは、今は懐疑論者と狂信者がいるが、研究者たちの話を聞くと収束する点が多い。現在のパラダイムだけでも追加の研究ブレークスルーなしで巨大な経済・社会的インパクトを出せる可能性は高い。だが本当にAGI、ASIに行くには継続学習やサンプル効率など追加のブレークスルーがさらに必要である確率が高い。とはいえ私たちはそうしたブレークスルーを見つけるだろうし、20年以内にはそこに到達するだろう。
ただしこの予測は先駆者ごとに違う。Hassabisは5〜10年、Cholletは5年、Sam Altmanは数千日、Yann LeCunは10年、Ilya Sutskeverは5〜20年、Amodeiは最もアグレッシブに2年以内でも可能だと言った。つまり100年かかると言う人は誰もいない。全体として見ると、互いに異なる部分より同意する部分のほうがはるかに多いと整理してくれました。
そしてAndrej Karpathyが前回上げた内容まで引用して、ずっと紹介してくれたんです。KarpathyもDwarkesh出演の後に一度また整理文を上げました。その内容は私が翻訳しておいたので、リンクから見ていただければと思います。ではこの時点で、私たちがもう少し話すことはありますか?
研究者たちの合意点と「継続学習(Continual Learning)」の必要性 07:34
キム・ソンヒョン ここでも話せることがありそうで、私はここでNoam Brownが研究者の考えは似ていると言うのは正しいと思います。なぜなら私の場合も最初のセッションでcontinual learningについて言及したじゃないですか。あれは私のアイデアから来たわけではなく、私もそのとき研究者たちの話を聞いて、最近はこういう研究が起きていて、こういう問題意識を持っているということを紹介しただけでした。だから私にはとても自然な話に感じられました。Ilya Sutskeverの話もそうです。むしろなぜこれが不自然に聞こえたのかが、逆に気になるくらいです。
似たことがこれまでなかったわけではないんです。pre-trainingのスケーリングが最初の最大パラダイムでした。でもpre-trainingのスケーリングだけで今出ているモデルの性能向上が起きたわけではありません。明らかにpre-trainingのスケーリングだけで今のレベルのモデル性能に到達しようとすれば、そのスケールはとてつもないものになったはずです。ところがその突破口を見つけたのが、非常に研究的アプローチだったo1とRLです。o1とRLによって、pre-trainingスケーリング以上にはるかに大きい性能向上を引き出せたわけです。
だとすれば、そういうパラダイムの発見は今後も重要で必要だと考えられます。それはスケーリングと衝突することでもありません。pre-trainingスケーリングと対立するわけではないけれど、そうした研究的発見や開発がモデルをはるかに強力にできる。ここで要約されている内容と似ていると思います。つまりIlya Sutskeverが要約したように、スケーリングは引き続き性能向上を生み出すが、何かが不足していて、その不足に対して突破口を見つけ、さらに大きな性能向上幅を得るには、推論のような新しいパラダイムが必要であり、そうしたパラダイムはスケーリングだけで得られるものではなく研究が必要なテーマです。
チェ・スンジュン だからIlya Sutskever編のタイトルが「研究の時代」という副題だったんですよね。
ロ・ジョンソク 私もIlya Sutskeverが最初に話したときに違和感を覚えたのは、Suttonのときに感じたのと似ていて、今は単にスケーリングを伸ばすこと、まだスケールがどこまで行くのか誰にもわからないじゃないですか。GoogleはGemini 3を作りながらpre-trainingについても何かを解いた、みたいなことを言っていて、私たちは知らないんですが、私はこうしてリソース、computationをさらに増やして進むある種の高尚な方向性が間違っていて、別の基底構造を変えることだけが次の道に導くのだと断定する部分が不快だった気がします。
ただ、ソンヒョンさんは事業的観点で情報を取得して受け取る人がなぜ違って受け取るのかを少し気にされたかもしれませんが、見方を変えると前回スンジュンさんが見せてくれた「ゲーデル、エッシャー、バッハ」の図のように、問題の本質は次元を異にしていても存在していて、今は各自の観点や言葉の定義などが違うために像の結び方が違って見えることで生じる問題であって、その異なる像もまた少し同型性を持っている、本質的には同じ問題をaddressしているという気はします。
だからIlya Sutskeverも、今おっしゃった通り、Twitterを通じて自分の意見を一つ修正しましたよね。scaling lawが間違いだという話ではなく、引き続きgainはあるが、これを次の段階にジャンプさせるには研究が必要だと。当然同意です。当然同意です。

チェ・スンジュン これ面白いんですが、ユジンさんが教えてくれて私も見たんですけど、Dwarkesh podcastのthumbnailが変わりました。最初は “It’s back to the age of research, again, just with bigger computers.” となっていたんです。単に研究の時代で、ただもっと多くのcomputationでやるということ。でもpre-trainingがtargetをovershootした、に変わりました。ソーシャルメディアで話題になったのでトーンを変えた気はします。
何を言ったのかは少し後で見ますが、ミーム化している話があります。これもロ・ジョンソクが教えてくれましたが、Dwarkeshが、ではSSIはどうやってお金を稼ぐのか、と聞いたら、研究にだけ集中し、質問への答えはおのずと明らかになる、可能な答えは多いはずだ、と。実際Noam Brownも似た話をしたと私は感じました。なぜなら「おそらく私たちはそうした突破口を見つけるだろう」。だからOpenAIはOpenAIなりに何か突破口を見つけようとしていて、すべてのtop labが他に何があるか探るのは当然ですよね。研究しないといけないので。
ただSSIも、今は明かせないが今すぐ稼ぐより研究に集中するルートで行く、fundraisingした資金で。そう話したことが今ちょっとミームになっている時点ではあるようです。ではIlya Sutskeverの内容を全部は抜き出せませんが、いくつかのスライドで、Claude Opus 4.5が作ってくれたスライドなんです。なのでAIが私たちを使って、AIが抽出したポイントで話してみるのも面白いと思います。
ある話を抜き出したんです。私が最初の場面を紹介すると、これはインタビュー序盤にかなりinformalに出る場面です。DwarkeshとIlyaがまだ収録開始もしていないのに撮影だけ回して会話しているときに、今の風景はSFから飛び出してきたような風景だ、という話をしていて、Ilyaが興味深い言葉を投げるとDwarkeshが空気を作って「じゃあ今から話してみようか、議論してみようか?」と言ってこの場面が展開されたんです。次の章が研究の時代ですが、研究の時代については先ほど話したので飛ばします。この部分は少し話しがいがありそうです。「驚異的な能力とあきれるミスの共存」。これについてソンヒョンさんはきっと考えがあると思いますが。
驚異的な能力とあきれるミスの共存 (RLスケーリングの限界) 13:40

キム・ソンヒョン これは1万時間競技コーディング問題を学習した人と100時間だけ学習した人の差、という言及とともに出たテーマだと思いますが、なぜこういう現象が起きるのかは多様に解釈できる気はしますが、私は今のRL scalingの限界だと考えます。RL scalingをしようとすると結局環境が必要ですよね。その環境の中でモデルがRLをして学習していかなければならないので、それらを一つ一つ作ってあげる必要があります。考えてみると評価は普通、自動でできることを望むし、あるいは人が介入しても最小限で済むことを望むので、評価というもの自体が一つの環境です。その環境をtargetにしてRLでモデルを学習させられる。すると評価はうまくなります。
でも問題は、その環境が実際に経済的に価値のある仕事、あるいは人々が使うものとどれだけ関係があるかは別問題だということです。だとすると実際に人がモデルと相互作用する方法、人がモデルを使う方法については、それに合った環境を作ってあげる必要があります。そしてその環境をどう作るかが今いちばん大きい問題です。最近よく言うbench-maxxingをした、という話とも一脈相通じます。benchmarkをtargetにして学習させればbenchmarkは解けます。でもbenchmarkをよく解けるからといって、そのモデルが実使用環境でうまく動く保証はないわけです。
するとここで非常に多くの問題が生まれます。ではそうした環境をどう作るのか、人が一つ一つ作るのにも限界があります。人がモデルでやろうとする課題の長さはどんどん長くなるのに、その長くなるものの環境をどう作るのか、その環境を実際の人の使用環境にどう近づけるのか、そしてその環境は結局人が直接作るべきなのか、モデルで作れないのか、さらに言えばこの特定環境で学習したモデルが新しい環境にもどう一般化できるのか、こういう問題が続々と出ます。そしてそれらをどうtackleするかが、今post-trainingで各big techが競争している部分でしょう。
この環境をどう作っていくべきかについては、知られていることがさらに少ないです。つまりpre-trainingの時点でもpre-trainingをどうやったかには秘密が多かったし、そこにはノウハウも多くあったはずです。でもそれは推測してみると、まだ推測できる領域ではありました。ところが環境を広げてpost-trainingをする領域は、さらにベールに包まれています。だからこの人たちが実際どうしているのか、どんなノウハウがあるのか、どんなディテールがあるのか、よくわからないんです。
だから考えようによってはGemini、Claude、そしてGPT-5のようなモデルがfrontier labで作られていますが、post-trainingされた結果物は全部違うはずです。なぜならpost-trainingのノウハウなどが全部違って適用されているからです。だからそれ自体も研究問題と言えるし、引き続きその問題を解決するために多くの努力が今も注がれている問題です。どうにかRLをもっと良くしてこうした問題を緩和しようとアプローチしていくと、「これをもっと上手くできる方法はないか」「この問題をもっと根本的に解決できる方法はないか」と考えるようになります。それがたぶんSutskeverが言う問題の一つだと思います。特に一般化の問題と関連づけて。
チェ・スンジュン そうですね。今ここで言っているのは、Sutskeverが投げた論点が、評価はすごく良いのに実際に使うとどうして間抜けなバグを出すのか、つまりbenchmarkをあれだけ通過するのにこの問題はなぜ解けないのかというギャップが感じられて、RLをやると少しspikyに、ある能力はすごく高いのに空白点がある感じだ、というニュアンスの話だったと思います。「1万時間の学生と100時間の学生」、さっきソンヒョンさんが少し触れた、つまりモデルは1万時間必死に勉強した学生のようで、100時間で感覚のある学生ではないようだ、という話でしたよね。一般化能力が著しく落ちるんです。モデルが。
キム・ソンヒョン はい、そうですね。そう考えられます。一般化が著しく低いと考えられるのは、人間がもしその程度のデータを学習しその程度の環境で学習したなら、新しい問題にもとても強いのではないでしょうか。そしてさらに言えば、新しい問題でも少し学べばできるようになりますよね。でも一般化は非常に多様な形で問題になり得ます。
先ほども一般化の問題を申し上げましたが、ある環境で学習すると、例えばClaude Codeを使って何かをすることを学習したら新しい環境でもうまくできるべきではないか、ここにも一つの一般化があります。そしてさらに、例えば5分짜리課題を遂行できるなら1時間짜り課題にも一般化されるべきではないか、こういう一般化もあります。非常に多様な軸での一般化が存在し得ます。そしてその一般化については、今までそれほど成功していない気がします。
実際post-trainingというこのパラダイムに限定せず、ディープラーニング全体で考えると、一般化問題については私は進展がほとんどないと思います。このアーキテクチャ全体が一般化をはるかにうまくするモデルを作る、それ自体がそれほど成功した事例は私にはない気がします。今の解き方はpre-trainingをすることです。つまりデータをさらに多く使うことですよね。でも一般化といえば普通はデータ効率的なものを考えます。データを少し使ってもうまくできること、同じ量のpre-trainingをしたとしてもどんな方式でpre-trainingすればはるかによく解けるか、そういう問題を考えるわけです。でもそうした問題についてはほとんど進展がないようです。非常に難しい問題でもあります。とても難しい問題です。ここについて突破口を見つけたとか進展があったわけではないと思います。
感情は価値関数だ: 限定合理性とヒューリスティック 19:44
チェ・スンジュン でもSutskeverがちょっと不思議な、あまり聞いたことのない話をしていました。価値関数というのはRLでは馴染みのある話ですが、感情が価値関数だという話をして、私もこの部分はすぐには腑に落ちなかったんです。
キム・ソンヒョン これはその話ですね。人が主に考える、感情がまったくなく完全に合理的で理性だけある人間なら常に合理的で理性的な選択だけをするのではないか、というものですが、実際にはそういう人は選択をまったくできないという話です。
チェ・スンジュン 脳の切除術とかそういう話をしながら。
キム・ソンヒョン 実際にあった事例だから言及しているのだと思いますが、だから人が考えるように感情がなければ完璧で徹底的に合理的な決定だけできるはずだ、でも実際に起きるのは決定をまったくできない状態になることです。原因が正確に何かは私がその事例を勉強していないのでわかりませんが、おそらく無数の可能性について絶えず合理的・理性的に考えようとするあまり、その情報や可能性に押しつぶされて選べなくなる、そういう状態に近かったのではないかと思います。
感情があればそうした問題に役立ちます。私たちは合理性だけでは意思決定できない場合が多いんです。結局、不確実性の中で飛躍しなければならない場合があります。そしてその不確実性の中で飛躍するときには、感情のようなものが理性とはまったく別の領域で作用して助けになります。ではそのとき感情の機能は何かと考えると、いろいろ可能性はあると思いますが、私もこの問題をそこまで深く考えたわけではないので一つ考えるなら、価値関数にたとえたのでそれと結びつけると、価値関数はある状態がどの程度の報酬につながるかを表す関数と言えます。
つまりこの状態はより大きい報酬につながる、ある状態は大きくない報酬につながる、という形です。でもこれを漠然と考えると非常に合理的に推定されると思うかもしれません。つまりこの状態、この環境、この条件が大きい報酬につながる可能性が高いと、人は合理的理由を通じてその関連づけをすることもできるでしょう。しかし人の意思決定が実際にそういう形で行われるか、さらに言えば世界がそういう形で構成されているか、これは別問題でしょう。
世界は不確実で予測不可能な要因が多く起きます。ではその不確実な状況で意思決定し、「この状態が良いはずだ」「この判断が良いはずだ」と考えるのは、かなり感情的で信念に根ざした領域である可能性があります。そしてその信念は意思決定にとても大きく役立ち得ます。
チェ・スンジュン なのでふと聞いてみると、Suttonは巨大世界仮説を話しながら限定合理性を語ったけれど、Ilyaは少し似ていても違うトーンで、結局感情のような、まだLLMに欠けている何かが人間を実行可能なエージェントにし得る、そこに何かヒントがあるのではないか、というニュアンスで話していた気がします。
キム・ソンヒョン 「限定合理性」と表現すると、合理的条件だけではすべてを判断できない問題があるということですよね。そのとき非常に役立つのがヒューリスティックです。例えば汚いものを見たら避けるでしょう。それはヒューリスティックですが、もし本当に合理的に意思決定するなら、その汚いものが自分に危険かどうかを見極める必要があります。でもそれよりずっと直接的なヒューリスティックを使います。そして汚いものを避けることは感情と最も結びついています。嫌悪という感情とそういう形で絡み合っていると考えられる気がします。
でも私はこの価値関数への言及で、Sutskeverがもう少し機械学習関連へ進みながら言っているのは、RLで価値関数が果たす役割を見ると、よりサンプル効率的にし、学習をより速くする効果がある、ということです。これについてなら非効率ですが似たことはできます。つまり価値関数がなくても非効率な方式で似た結果に到達できます。
でもSutskeverが言っているのは、それよりもう少し根本問題に触れているように見えます。単に非効率でも到達できるのではなく、非効率にしても到達できない問題、そういう問題により関心があるように見えます。価値関数を超えて。Sutskeverはこういう話をよくしていました。感情関連でも研究していましたし、以前はモデルが自己意識を持つ必要があるだろう、自己意識がある方が有用だから、という趣旨の言及をしたこともあり、似た話をずっと続けているようです。
「ゲーデル、エッシャー、バッハ(GEB)」とAGIの誕生条件 (奇妙なループ) 24:30
ロ・ジョンソク なので私はこの議論について、自分なりの雑哲学はあるんです。
チェ・スンジュン 気になりますね。
ロ・ジョンソク 「感情とは何か」「魂とは何か」みたいなことについて、以前スンジュンさんも好きなGEB、「ゲーデル、エッシャー、バッハ」。実際かなり難解な本なので解釈や見方が分かれますが、こういうのありますよね。あのゲーデル、エッシャー、バッハはその本でも証明されていない事実について語るんです。そうすると彼が言いたかった核心は「I, Who am I」「私は誰か」という、私たちの体内で回っているこの魂というシステムの存在は何か、ということをこの分厚い本で証明しようとするものなんですが、Douglas Hofstadterはこう言います。
最初の例に出すのがアリ。アリ一匹、アリも実は一種のintelligenceですよね。少しのneural netでできたintelligenceで、その一つの単位体もcomputationの単位になり、それらが群れを作る。アリ一匹はただ愚かで単純なinstruction setだけど、それが巨大な群れを作ると問題解決力は非常に大きい。intelligenceと呼べるものです。 そして「Ant Fugue」と呼ぶんですが、つまり、十分にスケールが大きくなるとその下の基底が何であっても次のものが立ち上がるという話をしたわけで、ただここでもっと重要な話へ一歩進みます。これだけでは不十分です。スケールだけでは。
そこでその魂が誕生するために必要な2つの条件として、彼が挙げるのが1つはスケール、2つ目が「Strange Loop」「奇妙なループ」と呼ばれる存在なんです。この「奇妙なループ」が実はgeneralizationと密接につながっています。これが魂の誕生点だと語る部分なんです。 鏡と鏡を向かい合わせにすると、その中に永遠の像が生まれて、その永遠性をどう扱うかという過程で「私」という概念がぽんと飛び出すと言うんです。
この下にあるハードウェアと上にあるソフトウェアが積み重なっていて、例えば私たちの思考がそうです。ソフトウェアが何か決定すると、その決定のために再びハードウェア、つまり媒体が変わるじゃないですか。ニューロンの接続が変わるじゃないですか。だからソフトウェアとハードウェアが絶えずつながっている、まるでEscherの絵の無限に上る階段のように上位と下位がつながり続けると、ぱっと誕生する概念が「I」、つまり「私」という概念という新しいOSが生まれる、と言うんです。
HofstadterのGEBのような視点は、単に下で十分なスケールが確保され、そのスケールのレイヤーが絡み合って回りながら「Strange Loop」「Tangled Hierarchy」と説明するんですが、その中で矛盾が発生し、それを処理するために生まれる概念が、システム内にありながらシステム外からシステム内を見下ろすような上位価値として誕生する。それが魂であり、それは私たちがハードウェアとソフトウェアの結合構造だから発生すると言うんです。
では再びLLMの話に戻ると、そのHofstadterが「Who am I」というそのsoulというoperating systemが生まれるために言った2つの条件のうち1つがスケールです。で、そのスケールは今進んでいる方向で、2つ目が「Strange Loop」です。つまりinputとoutputが絡まないといけない。
これはソンヒョンさんが話していたcontinual learningの概念とぴったり接続しているんです。ただ、そのcontinual learningという概念はこれが必ず1つのTransformer circuitの中で実装される必要はないんです。人間もメモとか私たちが話すこととか、こういうすべての環境をRAMとして使っています。実際メモリとして使っていて、絶えずflowが回っているわけです。
だから私は、今私たちが使っているTransformerは入力する瞬間だけautoregressiveに回り、トークンを増やすインセンティブを与えるほどそのトークンの中で奇妙なループのような動力学を形成するんです。だから魂があるように見えるんですが、これをもし誰かがGoogleでもOpenAIでも、あるシステムにハードウェアとソフトウェアを結び、inputとoutputを適切なツールと一緒に結んで、この中で永遠に再帰的に回るように作っておけば、Hofstadterの言葉によればそれは必然的に「私は誰か」という質問をするようになり、システム外に飛び出す新しい存在になるはずです。
これがAGIだと私は個人的に思っているんですが、話が長くなったのでLong story short、今の研究的観点などにも私は同意する一方で、哲学的視点に変えて考えるとAGIの誕生時点はスケールとループをつなぐことだと思っていて、スケール部分はもう必要条件を満たした気がし、2つ目の条件が満たされればこれが自分で考えながら自我という概念をぽんと思い浮かべるようになって、そのときにはたぶん人間にしかできないとされることもこれがやるようになり、そのループが報酬関数であれ何であれ、これが自分で解く出発点になるのではないかと想像しています。 だからもしかすると問題は簡単に解けるかもしれない、いや、すでに終わった問題なのではないか、と。なので最初に雑哲学と言ったんです。同意しない部分もあるかもしれません。
チェ・スンジュン ロ・ジョンソクの話をさらに圧縮して私なりに表現すると、computationが生命のsoupだという話ですよね。ロ・ジョンソクはそう考えているわけで、ここで次に行く前にコメントありますか?
真の知能はモデルではなくシステムだ 30:35
ロ・ジョンソク そうです。ソンヒョンさんのフィードバックを聞きたいです。実は私の理論ではなくHofstadterの話です。
キム・ソンヒョン でも実際それは継続学習を考えられる方法の一つでもあります。なぜならそういう表現はよくするんです。実際OpenAIの人が言ったと思いますが、OpenAIで本当の知能、あるAGIというものが出るなら、それはGPT-5のようなモデルではなく、そのGPT-5というモデルを学習させるRLというフレームワーク、システム、それ全体が合わさって一つの知能対象になる、という話をするんです。
ではそのRLシステムとモデルが結合するとはどういう意味かと考えると、そのRL環境はあるシステムがモデルを継続的に修正していくわけです。継続学習の文脈で考えると、新しく取り組む問題、新しい課題に対して、そのシステムが自分自身を修正するんです。自分自身と言っても簡単に言えば、そのシステム内のモデルの重みを修正していくでしょう。
ただ、その修正していく過程は、そのシステムが考えるにこういうもの、こういう方式で修正すべきだ、こういうスキルを獲得すべきだ、こういう判断、ある報酬によって修正していくでしょうし、さらに考えるとこういう方式で修正すべきだと決めるのがシステム内のモデルであることもあり得ます。そういう形でもループは作れるはずです。
はい、continual learningと考えるなら最も簡単に思い浮かぶのがそういうシステムです。モデルがモデル自身を、あるいはシステムがシステム自身を継続的に修正していく。新しい課題に対して。もちろんそれをどう実装できるかが今の重要問題ではありますが、それも一つの方法、すぐ考えられる方向だと言えます。
人間のサンプル効率と内的動機 (社会的欲求) 32:16
チェ・スンジュン それで今Sutskeverは6歳の子どもをたとえにして「人間ははるかにサンプル効率的だ」という話をしていて、そうしたことが先ほどの価値関数、感情の比喩と似て、進化が私たちに何らかの欲求をエンコードした可能性がある、そしてそれが最終的に私たちのような存在を作ることをdrivingしただろう、という話がありますが。もしコメントしたいことがあればお願いします。なければ進めます。
キム・ソンヒョン 2つともあるんですが、1つはこの社会的欲求というのもとても面白い問題で、この話をOpenAIの元研究者が似たことを言っていました。つまり子どもは探索しますよね。子どもが探索するときは匂いへの欲求、そういう側に近いでしょう。でも子どもが成長して言語ゲームに入り、言語的社会に入ると、社会的欲求と言語的問題が動機を与え始めます。社会的地位への欲求が生まれます。そういうものが内的動機になるはずです。ではその内的動機をどう実装できるか、これが興味深いテーマだと実際にOpenAIの研究者が言及したことがあります。
チェ・スンジュン 誰がそんな話をしましたか?
キム・ソンヒョン Yao Shunyuがインタビューでこういう言及をしたことがあります。そういうmotivationをどうモデルに付与できるか、「これは興味深い問題だ」と話していて、それが以前にも言及されていたintrinsic motive、内的動機という問題に似ています。その内的動機が人に、報酬がない状況でも何かを継続的に追求させます。
そのときYao Shunyuが例に挙げたのが数学証明です。フェルマーの最終定理のような証明ですね。その証明を達成する報酬はほとんどの人に与えられていないはずですし、一生かけて結局一度経験する報酬ですよね。でもその報酬に到達するために多くの数学者が内的動機を持って探索しました。
そしてその内的動機の中で、ある小さな突破口を発見しながら報酬を得たのでしょう。こういうメカニズムはどうして起こり得るのか、これを実際に興味深く見ているテーマのようです。OpenAIで、あるいはIlya SutskeverがOpenAI内でこういう話をたくさんしていたかもしれません。
チェ・スンジュン そうかもしれませんね。つまりRLにたとえるとrolloutがとてつもなく長いのに、それをやったということですよね。その報酬を。
一般化(Generalization)と帰納バイアス(Inductive Bias) 34:29
キム・ソンヒョン 一般化についても話せそうです。これも非常に興味深い話で、一般化と言うと、今機械学習研究者がとても嫌う概念を話さないといけないんです。inductive biasという概念に言及しないといけません。inductive biasを普通は大雑把にどんどん取り除く形でモデルが発展した、という話をよくします。 でも一般化というのはinductive biasがなければ可能になりません。なぜならinductive biasの概念自体が、新しいデータを見たときそのデータについてどう予測するか、そこに必要なバイアスがinductive biasだからです。
人間のinductive biasは何でしょうか。これは本当に難しい問題です。人間にはパターンを発見する能力がありますよね。あるパターンを見つけてそれを要約し原理を作るバイアスがあります。でもそのパターンが人間だからといって常に成功的とは限りません。ある現象についてとんでもない説明を作ることもあるし、とても複雑な説明を作ることもあります。
でも私もこの一般化をどう扱うべきかは本当に難しい問題だと思います。特に機械学習という側面で。ただそこで出てくるものの一つが最小アルゴリズムです。最も簡単なアルゴリズム、やや情報理論やSolomonoff inductionの側から考えると最小長アルゴリズムと言えるでしょう。
すると最小長のアルゴリズムを探さなければならないのに、Solomonoff inductionのようなものは基本的に演算・計算不可能な問題ですよね。ではモデルが一般化するためには最小長アルゴリズムを好む、最も簡単で単純なアルゴリズムを好む何らかのバイアスが与えられるべきなんです。
チェ・スンジュン オッカムの剃刀みたいなものですね。
キム・ソンヒョン オッカムの剃刀のような。そういう話は私が以前にも少ししましたが、最高の一般化はアルゴリズムを発見することで、そのアルゴリズムを発見するにはモデルや学習条件がアルゴリズムを実行できる条件を備える必要がある、と言及したことがある気がしますが、それは最小条件でしょうし、それを通じてどう一般化に到達できるか、これらが興味深いテーマになるでしょう。 例えば推論の場合、それは一般化に対してはるかに強力な方法です。そしてその推論が一般化につながり得たのは、推論条件が単純なアルゴリズムを好み、暗記を避けるbias、バイアスを持っているからです。 これは興味深い問題ですが、これがどう解かれていくかは本当に難しい問題だと思いますし、今までのパラダイムとはある意味で衝突する部分も多いので、どう解かれるかはよくわかりません。
ロ・ジョンソク 実際Transformerも一種のbiasですよね。こういう形でパターンを内部でこのように計算せよというbiasを注入したわけで、それを単にスケールを上げてデータを入れたら急に魔法のようなことが起きて、計算もして何もかもして考えているようにも見える、ということだと思いますが、Transformerというそのモデル自体、GPT-5がAGIにならなければならないという概念より、先ほどソンヒョンさんも言ったようにGPT-5が新しいelementになり得るんです。ひとつのニューロンになり得るんです。それが上位のharnessで100個集まり1万個集まれば、これも見方によってはまた別のスケール問題に置き換えられるし、これはある意味また研究なんです。
キム・ソンヒョン この問題はずっと絡み合っています。continual learningをしようとするとサンプル効率性が高い方がはるかに良いんです。Ilya Sutskeverではなく別の人の表現だった気がしますが、人は熱いものに手を触れると一度経験した後は二度と触れないでしょう。そして継続学習にはそういうことが大きく役立つはずです。継続学習をするとしても何度も試行錯誤するのではなく、1、2回の経験だけで素早く学習できるなら、その方がはるかに価値が高い可能性が高いです。
チェ・スンジュン 今回Opus 4.5が出て、そんな話がありましたよね。Opus 4.5はSonnet 4.5より安くなり得る、few-shotで、つまり何度も行かなくてもSonnetが長くrolloutするより性能が高く、しかも安い、という。つまりサンプル効率性が高く一度で仕事をうまくやれば、それがより効果的になり得るという気がします。で、今おっしゃった文脈で私が思い浮かぶのは、inductive biasに関連してNoamが言っていたか、結局モデルがinductive biasを作れるようにすることが方向性かもしれない。つまりinductive biasを作れる程度のアルゴリズムを発想させるのが重要かもしれない、という点も一つ思いつきました。
この図表で面白いのは、これがClaude Opus 4.5が作ったものじゃないですか。私これ作れと言ってないんです。flocking behaviorを。でもflocking behaviorをこの話から作ったんです。結局、社会的欲求が私たちの現在の存在が生じ、存在できることをdrivingしたということを、最終的に社会的相互作用にたとえて表現しているんです。面白くないですか?
超知能(ASI)へ直行する: すべてを学べる種 39:17
チェ・スンジュン では次に進みます。超知能へ直行する。ここで私がIlyaの観点を面白く読んだのは何かというと、特定ドメインに特化したspikyな能力を持つでこぼこしたAGIがIlyaの目指す方向ではなく、何でもできる種のようなものを作りたいという欲求を感じたんです。何でもできるものを。Dwarkeshは結局それを経済や社会にdeployしたいのか、という追質問をしましたが、Ilyaが惜しんでいるのは最近RLを活用して性能を上げたLLMはあきれるミスをする、でもそういうものをうまく解決できる新しい種を発想したい、それが自分の考える超知能への経路だ、と私は読みましたが、違って見る方はいますか?
キム・ソンヒョン そういう表現だったと思います。最初からあるエージェントがいてそのエージェントが全問題を解けるのではなく、そのエージェントも実際には解けない問題がある。けれどそのエージェントがdeployされ、実現場に入ったとき、そのエージェントが新たに必要なスキル・技術を開発し学習していきながら、その問題をうまく解くようになるんです。
私も同じく、この絵は多くの人が似たように描いている気がします。continual learningという概念が入ってきて、そのcontinual learningを通じて実現したいものがまさにそういう形の絵なんです。そうならざるを得ない領域が明らかに存在します。例えば会社なら、会社には社内機密があり、その会社の外に情報が流出しない、そしてその会社内のprocessみたいなものがありますよね。
そういうものが存在するなら、その会社内で起きる仕事についてモデルを事前学習させることはできないでしょう。するとそのエージェント、どんなエージェントが最も効果的かと言えば、そのエージェントはその会社に入り、会社内で必要な情報を獲得し、会社内のprocedureやprocessを学び、そのprocessを学んだ後に会社の仕事を処理する、そういうエージェントが必要になります。そういうエージェントの方がはるかに適しています。
チェ・スンジュン 誰でもそれを望みはしますよね。
キム・ソンヒョン はい、そして実際多くの研究者が、continual learningに言及する多くの人がその絵を構想していると思います。そしてそれらは超知能と見なせる特性を備えることもあり得ます。その会社内のすべての情報、すべてのprocessを素早く把握し、継続的に学習しながら人間のレベルを超えるんです。
そういう表現をしますよね。今の技術だけでも経済的インパクトは十分あるだろう。でも新技術の開発は必要だろう。そういう意味だと思います。Dario Amodeiがそういう表現をした気がしますが、今のモデルでも経済的利益の創出は可能だ。でも私たちがさらに投資するのは次段階のモデルで競争するためだ、という表現をしています。 だから今レベルの技術でも経済的価値が創出されるのは明らかでしょう。でももしこういう問題、こういう問題が解け始めたときに生まれる経済的価値は莫大だと思います。
チェ・スンジュン orderが違い得ますね。
キム・ソンヒョン はい、規模が違うでしょう。完全に違う感触になるはずです。
ロ・ジョンソク その通りです。だから先ほどNoam Brownが整理した文章、ロ・ジョンソクが見せてくれたものにも必ず入っているのが、今の人工知能のレベルでも不足はない、とても使えるし、実際私たちが3年前、数年前の視点で見れば超知能のように見えることをやっているじゃないですか。その点は絶対に見落としてはいけない気がしますし、そして私たちがAGIが出るだろう、何だろうと言っていても、人間ってそうじゃないですか。期待が後ろに繰り延べられ続けると今すぐactionせず待ちたいインセンティブが生まれるので、そういうものにさらに期待値を持ってしまう問題はある気がして、私たちもかなり警戒して解釈すべきだとは思います。
チェ・スンジュン もう後半ですが。リスナーの方々はどう思うかわかりませんが、実はこのスライドを作らせた私自身もこのスライド内容を考えずに今日この場に臨んでいるんです。単にClaude Opus 4.5が投げてくるものを使ってやっているだけです。
ロ・ジョンソク TikTokにいるインフルエンサーの中にも偽物はかなり多いんです。気づかないだけで。でも私たちが顧客としてその動画を見て面白く満足できて自分の助けになるなら、それがAIか人間かにいったい何の違いがあるんですか?同じです。
良い研究のための「センス(Taste)」と目利き 43:42
チェ・スンジュン 最後にSutskeverが、Ilyaが締めるのがセンスを話していたんです。taste。でも私はこれが最近すごく重要な価値を持つ表現、圧縮された表現だと感じます。センスです。
キム・ソンヒョン はい、そうですね。研究者も本当によく言う話です。センスが良くないといけない。私もずっと悩む問題です。ではセンスが良くないといけないとして、その良いセンスはどう涵養できるのか。
チェ・スンジュン さっき私たちがずっと話してきたことに反復記号を打つ話ですね。
ロ・ジョンソク ここでもstrange loopが形成されるんです。反復記号が繰り返されながら上のレイヤーと下のレイヤーがentangleするんです。でもこれがすべての進歩の始まりだとDouglas Hofstadterは言いました。
チェ・スンジュン そうです。Douglas Hofstadterは実はあのGEBがそのanalogy、つまり類推シリーズの最初の仕事なんです。かなり若いときに書きました。なのでHofstadterはそういう何か興味深いもの同士に比喩を作りながらその仕事を続けてきて今日に至っている方だと思います。まさに良い研究センスを持っているのかもしれませんね。
ロ・ジョンソク 実際Noam Brownもその話をしましたよね。自分がこのthinking modelを掘るようになったのもIlya Sutskeverと食事しながらSutskeverが報酬をくれたから。そうしてその大家に認められ、その後その人が正しいと言うからその信念で進んだ、それも一つの方向性だったのではないかという気がします。
キム・ソンヒョン センスというのは本当に面白い問題ではあります。つまり見方を変えると美学ですよね。一種の。でも研究でもそういう美学が重要だと言いますし、数学者もある数学が美しいという表現をよくする気がします。だから美しい数学とは何か、こういうことが重要問題で、それが機械学習研究者にとっても非常に重要な問題だと思います。機械学習研究者にとって良いセンスとは何かと考えると、研究をする前に、その研究結果が出る前に、その方向へ進むべきだとわかる能力でしょう。こういう方向でアプローチし進むのが良い、というのがたぶん良いセンスだと思います。でも問題は、そのセンスをどう育てるか、これが重要問題だと思います。
ロ・ジョンソク ソンヒョンさんが言ったことについて、私はまた雑哲学ですが、量質転換だと思います。量が増えればいつも質は必ず出る、という信念があるんです。
量質転換とエネルギーの高いトークン 45:59
チェ・スンジュン さっきの話と同じ文脈が続いているわけですね。
ロ・ジョンソク だからまた質の高い情報が増えれば、そこからまた次のレイヤーへ上がる。
チェ・スンジュン でも今、行間に圧縮があるということですね。量をそのまま持っていくのではなく。圧縮して取り出すと質が上がるということですよね。
ロ・ジョンソク そうです。量から実はエッセンスだけ取り出して、そのとき私はソンヒョンさんが前回話してくれた決定的分岐を作るエネルギーの高いトークン。
チェ・スンジュン エントロピーが高い。
ロ・ジョンソク はい、私はそれがすごく良かったんです。そのエネルギーの高いトークンも前にある無駄でエネルギーの低いものが積み上がっているからこそ次の跳躍を成し遂げたわけですよね。何か統計的にその選択をしたはずですが、そういう相転移する時点がだからthinking tokenの中にもあるし、そして私たちが今この話をしている話の階層、レイヤー間にもあるし、だから私たちは還元的すぎる視点でそのレイヤーの一段上から話そうとする視点があるけれど、それを自然に行き来しながら考える必要があるんです。するとDouglas Hofstadterが言う比喩の最も鮮明な例がそれなんです。水があり、水が渦を作って激しく渦巻くとき、その二つの関係は何か、その基底と上位の意味、substrateとmeaningの差を作ることには何の関係もない。突然生まれるものだと言うんです。
チェ・スンジュン とにかくここまでIlyaの話をスライド化して話してみましたが、Claude Opus 4.5は最後の図を黄金比の螺旋で作ってくれましたね。美しいものを表現しようとしたようですが、こういうセンス、目利き、そういうものは結局LLMを使うときにも強く感じるのが、自分がどこまで何を定めるかによってそれを推進させることが可能なんです。 でも今日はこれで話が終わりじゃないんです。速く行きましょう。
OpenAI科学チームの逸話: ブラックホール研究者とGPT Proの協業 48:10

ロ・ジョンソク 早く現実の話を少し見て、早めに終えましょう。 チェ・スンジュン 先週と先々週で私に印象を残した動画を2つ挙げるなら、Ilyaのこれとこれなんです。Kevin Weilとこのブラックホール研究の科学者、それからポッドキャストの進行者で今はOpenAIを離れた方ですが、とにかく一緒に仕事はしています。圧縮して言うと、このAlexさんはブラックホール研究者です。OpenAIに来ることになりました。ここで翻訳を「AIハイ」としましたが、AGI pilledを食らったきっかけがあったそうです。
Mark Chenと話したんですが、Mark Chenが科学者たちにこれAIを使ってみて、有意義に使ってみてとやっていて、この方に会ったとき難しい問題を一つ投げてみてと言われて、完全なdomain expertのブラックホール科学者が質問を投げました。対称性に関する、しかも最近論文を上げた内容だそうです。GPT Proがその問題を解こうとしたけど間違えた。だから「ほら見ろ、まだ人間のほうが優れてる」。でもMark Chenは少ししょんぼりした表情で「簡単な問題を出してみてください」と言ったそうです。その文脈で、完全にブラックホール問題でなくても少し簡単な問題を同じcontextで出してみてと言った。9分ほど考えたら美しい答えを出したそうです。
そしてここが重要です。「さあ、ウォーミングアップ例でprimingされたので、このチャット画面でまた難しい問題を投げてみてください。」18分考えて完全に正確で美しい答えを出したそうです。最新で、まだpre-trainingに入っていない話を。だから衝撃を大きく受けて、「今はここに参加すべきだ。今すぐ参加しないのは狂っているようなものだ」となってOpenAI科学プログラムに入ることになります。
そういうエピソードがあるんです。でもこれは今示唆するものがあります。これは単に実用面でもこの部分が本当に重要なんです。primingすること、難しい問題を投げるだけでなくウォーミングアップする作業のようなものがまだ必要で、そこにinsightを与える部分がありました。そしてその部分はKevin Weilが指摘します。能力限界の最前線に問題を投げると間違えることが多いが、それは人間も同じだ。まだ自動ではない。だから多くの相互作用、back and forthが必要だ。だからモデルをうまく活用する研究者は、モデルと粘り強く対話をやり取りする人たちだ。それが自然なことだ。能力の限界値で作業する2人が協業する方式と似ている。
なのでここにも今かなり、ある意味当然多くの方が最近それを感覚しているかもしれませんが、意外とさらに多くの方が感覚できていないエッセンスがこの回には入っているんです。私はこの部分の内容が良くて、少し地に足をつけて今日可能な実用の話を非常に速く進めると、Claude Opus 4.5が出ました。
Claude Opus 4.5実戦テスト: 2行で作る「CloudBook」 51:04
チェ・スンジュン Claude Opus 4.5、私がMatt Shumerのvibe checkを見て真似してみました。私の例でお見せします。プロンプトにGoogle Colab competitor, UI、そのColabに似たものを作れ。次に「all compute is in browser」、ブラウザだけで動くJupyter Notebookみたいなものを作れ、というプロンプトを書いていたんです。Matt Shumerがそうやったら、これが計8分の動画なんですが、Claude Opus 4.5がどんどん計画を立てて、これ2行書いたじゃないですか。
で、何が出たか見てください。CloudBookというものをすぐ作りました。今見るとPython、Markdown実行、これPyodideというWASMがあるんです。WebAssemblyがあって、これはブラウザでPythonを回しNumPyを回せるようにします。それを、これまさにIPython NotebookやJupyter Notebookそのままが今作られたじゃないですか。カチッ、できました。そこでもう一つやってみました。ここでMarkdown cellに話を書いたらPythonコードを変えるgenerative featureを追加しよう。結論から言うとカチッ、できました。ここにMarkdown cellでテキストを書くとPythonコード生成されてNumPyが回って全部できます。
ロ・ジョンソク いやあ、まったく。はは。
チェ・スンジュン 苦笑が出ますよね。これがClaude Opus 4.5 vibe check computational notebook一発作成でした。
ロ・ジョンソク こういうことがほぼ1、2週間単位で、実際Opus 4.5は4.1が出たあとほぼ3、4か月で出ているわけですよね。

チェ・スンジュン でも今あれ3次元認識、つまりmultimodalは生成はしないけど読む能力のbenchmarkがすごく高いです。Gemini級で、だからvoxelとかもやります。Claude Opus 4.5は不思議ですね。次に、これはcontinual learningを迂回する現在の姿のようです。これ、文章がとても良かったんです。「長期実行エージェントのための効果的なharness」。Gitの構成管理をrollbackしたりしながらメモリ節約しcontext圧縮し、それを人間も結局scratchpad、メモ帳を使って外在化してcontext管理するのが人間の大きな強みじゃないですか。でもそれをする方向へ行く、その方向性を見せました。しっかりと。
長期実行エージェントと記憶の外在化 (Harness) 53:00
チェ・スンジュン そして先週のニュースが、Claude Codeがデスクトップにも入りましたね。デスクトップで更新すると対話モード、コードモードですが、初心者でも複数spawnして並列管理するのをすごく簡単にしたインターフェースを作っていて、とてもきれいです。だからこれは後で説明しますがGroup Chatでの既視感があり、同じ方向性でGoogle AntigravityのYouTubeチャンネルはぜひ見てほしいです。短いですが内容がとても濃いです。なのでArtifactsやknowledgeなどの意味を噛みしめて外在化することがAntigravityにも全部入っているんです。だから今のトレンドを捉えるのにすごく役立ちます。
私がここに書いたのは「外在化を通じて、現在モデルでできるcontinual learning能力不足を迂回する現象が見える。」人間がcontext管理するのと似ていて、それを今後数か月以内に超人的にうまくやる可能性を想像するようになりました。とりあえずでき始めたので。Group Chat、それを最近かなりハードに練習しているんですがまだ少しぎこちないけど可能性を強く感じます。これはもう1週間寝かせて私がもう少しpracticeを積んでから紹介します。すごく面白いポイントがありますが、1つだけ挙げると、複数人がいるので複数人に応対しないといけないじゃないですか。だからこれが非同期で全部queuingして回答するんです。なので会話しながら絵を描いて、1番、2番、3番、4番、5番を一度に描けと言うとspawnされてずっと全部答えてくれます。
ロ・ジョンソク 別のinstanceで全部回るという話ですね。
チェ・スンジュン そうです。とても興味深い可能性がここに入っていて、対話モードに入っているエッセンスもあるんですが、次回一度紹介してみます。
ロ・ジョンソク はい、私はこれが会社の未来だと思います。
チェ・スンジュン 今の状況は短く話せるものではないんです。
ロ・ジョンソク はい、あとで一度扱いましょう。
クロージング: 逃亡者連合と締めくくり 55:23
チェ・スンジュン 今日の締めです。ついに、もちろん今ソンヒョンさんは研究者ですが、AI同好人に過ぎない私たちもAIをてことしてより良いトークンを世界に残しpre-trainingに入れるように貢献できるのか、より良い世界に貢献できるのか。 でも逃亡者連合に応募する方々が口をそろえて言う話に、また既視感を感じます。似た風景を見る人たちと対話してみたい。良い話をしたい。分かち合いたい、ということです。
ロ・ジョンソク 今日はこのあたりで余韻を残して締めくくりたいと思います。
チェ・スンジュン 良い週末をお過ごしください。
ロ・ジョンソク ソンヒョンさんが来てくださってとても良かったですし、ソンヒョンさんがこれからも私たちのこのトークに加わって、いろいろな別視点のフィードバックをしてくださるととても嬉しいです。ありがとうございます。
キム・ソンヒョン ありがとうございます。