EP 80
2026年は科学の年になるのか?AIと科学
2025年のコーディングの年を越えて、2026年は科学の年へ 00:00
ロ・ジョンソク 収録している今日、2025年12月21日の日曜朝です。はい、2025年もいよいよ暮れに向かっています。 2025年最大の出来事を挙げるなら、やはりClaude Codeのリリースで始まったコーディングの年だったでしょう。 2026年はコーディングはすでに終わった話で、今度は科学もまた終わる、そんな一年になるはずだと。AIによって。 こうした話が、2025年を総括して2026年を展望するセッションとしてたくさん出てきていますが、今日はスンジュンさんと一緒にその話を一通り見ていきたいと思います。
チェ・スンジュン はい、2026年の見通しですね。というか2025年はまだ10日くらい残ってますね。今日は21日ですから。
ロ・ジョンソク はい、10日残ってます。正確に。

チェ・スンジュン はい、でも最近は2026年がもう入り込んできている感じがするんですよね。なので最近出てきたタイムライン関連のニュースを集めてみたんですが、以前の話でOpenAIポッドキャスト、AIと科学の未来、それからGoogle DeepMindのドキュメンタリーThe Thinking Game、そしてGoogle DeepMind共同創業者のShane Leggの話なども紹介しましたよね。なので今、文脈がずっとつながってきています。
科学に関する予告編のような話をしてきましたが、ここ10日で関連ニュースや証拠、兆候が濃く出ています。OpenAIでは「GPT-5.2で科学と数学を前進させる」というブログ投稿を12月11日、約10日前に出していましたね。最近は韓国語でもブログを出してくれるんですよ。なので読みやすくなっています。
GPT-5.2とともに進む科学と数学の発展 01:32

チェ・スンジュン あ、ここリンクを貼り忘れたんですが、Frontier Scienceというベンチマークもたぶんできたはずです。結局、ベンチマークができると性能が上がるという少し皮肉な状況がずっと続いていて、そういう関連ニュースがありました。 ここでGPT-5.2が上のブログに出ている事例の部分に、実はかなり意味深いところがあったんですが、内容は少し難しいです。 なので今、COLTというConference on Learning Theory側が公開した問題をどう解いたかという話で、GPT-5.2 Proに解かせて、その後に専門家がレビューと検証を行って証明まで出した事例です。
つまり全過程で人間の役割は数学的な足場を提供することではなく、検証と明確な文章化に集中するところに留まっていた。なのでモデルがそれをやり切る方向に行っている。そして扱っている問題自体にも少し含意があります。こういうことが得意な側に関係する何かだったんですよね。 ただ個人的な感想としては、今年のコーディングニュースまでは追えていたんですが、2026年の科学ニュースは読んでもよく分からない、そんな感覚を少し持っています。
ロ・ジョンソク その通りです。実際、数学でも化学でも物理でも、私たちが高校や大学で学んだレベルを超える深い内容が多いので、 私たちはそちらのdomain knowledgeがコーディングより明らかに不足しているから、入っていってこれがどういう内容かを全部見るところまでは確かに難しいですが、 それでも全体的な常識レベルでこれは何か、ということはうまく説明されているので、また見ていけば得るものはあると思います。
チェ・スンジュン それにAIを活用して、AIをてこに内容を読めば、努力すればある程度はキャッチできるんですが、本当に体得される感じではないかもしれない、という不安は出てきますね。
AI、実験室の速度を変える: ロボットと結合した生物学研究 03:47

チェ・スンジュン そして続いて、これ何日でしたっけ。12月16日、つまり実験室環境で生物学研究の速度を高めるAI能力の評価です。分子クローニングプロトコルの効率を79倍高めるのにGPT-5が使われたそうです。 ただここで図だけざっと見たときに興味深いのは、こういう実験、つまり実験室とつながった部分が意味深い気がするんです。 単なるシミュレーションだけではなくて、後半に画像が出てきますが、ロボットシステムでこうしたことを回して実際に実験し、データを得ることにフィードバックループを作ることに成功したのではないかと思います。 ロボットが実行したものと人間が実行したものを比較する内容が出ています。
ロ・ジョンソク これ、左側の単位が何かは正確には見られてないんですが。
チェ・スンジュン 僕もこれをきちんとは見てません。
ロ・ジョンソク 人がやるより2.5倍くらい速い、という感じですね。
チェ・スンジュン なので人間が実行したものより速く、そして性能は類似していたということです。
ロ・ジョンソク いや、本当に進化スピードがものすごく速いです。私たちがpre-trainとRLHFの話をしていたのは実は2024年のちょうど8月までで、これが全部GPT-5以降に始まった話なんですが、Thinkingモデルが出た後にそれがいったいどう作られるのか。2025年1月ですよね。R1の論文が出てThinkingロジックはこう構成されている。GRPOが出て以降は、verifiable rewardさえ作れればこれはモデルが解けるゲームだ、という信念が支配したように思います。だからコーディングや数学、論理が支配する部分はほぼ攻略されてきたようで、今これが科学の領域に 넘어갔네요。
チェ・スンジュン この前扱った中でPeriod Labsも超伝導体関連でしたが、furnaceがあって、つまり窯があって焼いて実験して、そういうことができる環境自体を作る側でしたよね。少し似た感じがあります。 それに、エンジニアがモデルでできることを発見したのが2024年、2025年にあったとすれば、数学者や科学者たちが今は「自分たちのdomainで動くね」というのを
ロ・ジョンソク それに多くの科学者が話しているのは、さっき見せてくれた人間が直接やる実験室環境、実際に水が行き来してビーカーであれこれ移し替えるような実験環境を私たちはwet labと呼ぶじゃないですか。ウェットなラボという意味ですが、 その部分が実は完全なボトルネックだったのに、そこでもAIがある程度は候補物質や方法論を最大限ロジックで絞り込み、 その代わりそれが合っているかどうかという最終的なreward signalは直接実験して確認し、その実験環境もまたロボットでautomationされてきているわけです。なので2026年にはそういうラボがたくさん生まれるだろうと、 verifiable rewardが化学でも生物でも、それぞれのverticalで、生物や化学にもセクターが非常に多いので、そうしたものが生まれる年になるという予測が多く見られる気がします。
チェ・スンジュン
今その話を聞いて思い出したんですが、Google DeepMindポッドキャストでGemini 3がついたアームロボットやヒューマノイド型ロボットを見ると、最近中国で出てきている派手なロボットに比べると派手さは少ないけど、実際に実験室で使えるタイプのロボットを今回かなり紹介していたんですよ。2週間くらい前に。 なのでこれはつながる話だと思います。つまり人間のボトルネックだった、実際にビーカーを扱ったり材料を扱ったりするところでもロボットによって、 しかも単なるロボットではなくreasoningを備えたロボットが実験室に投入される状況を見ることになりそうです。
ロ・ジョンソク Teslaの自動運転もElon Muskが今はLLMで言えば単なるinstructモデルだと言ってるんです。そこにreasoningを導入すると言っています。 なので車がデッドロック状態になったりすると、今はモデルで本能的に後退したりしてごまかしていますが、 これからreasoningが入れば戦略を立てて対処するようになると思います。
チェ・スンジュン そういうことが同時多発的に見え始めていて、これから進んでいく予定ですね。
数学難問の解決: AIと人間の協業(Terence Taoの事例) 08:14

チェ・スンジュン 数学側ではとても興味深い出来事がありました。これはTerence Taoのブログを翻訳した内容なんです。 Erdősという有名な数学者がいて、その人が提案した問題を解く話がここに長く出ているんですが、僕は数学公式を全部、式を言葉で解いて説明してもらうよう頼んだんです。公式が出ると僕には難しすぎるので。
でもTLDRで要点を抜くと、集合知を活用した部分があります。オンライン協業ですね。研究者たちがErdős problemsサイトやフォーラムでアイデアを交換し、AIツールが登場する。自動定理証明のAristotle、それからGoogle DeepMindのAlphaEvolve。これは誰でも使える状況ではないと認識していますが、Terence Taoはaccessを得て使っているようです。
なのでTerence TaoがAlphaEvolveを使った内容があって、さらに他の人たちがdeep researchを回して文献を、つまり人間がつなげられないものまで見つけ出す文献検索も含め、総合して問題を解く。これは非常に多層的で多様な単位で、人間とAIが協業して成し遂げた話なんです。 かなり面白いです。
つまり1975年に投げかけられた問いをどう解いたか。オンラインで協業が起き、ある数学者がAIツールでヒントを得て、それを見たTerence Taoが「あ、これはAlphaEvolveでできる課題だね」となって試したら、また人間がアイデアを得て、最終解決まで。僕もこれを細部まで全部理解したわけではありません。流れだけ追ったんですが。結論は「協業が可能な状態だ」です。これを受けてLeanのような証明支援ツールとつながる部分もありましたが、とにかく数学問題が解かれているという話です。しかもTerence Tao周辺だけでなく、他でも最近繰り返し出ています。Sébastien BubeckがOpenAIにいますが、数学者ですよね。その人がリツイートをたくさんしていて、今あちこちで数学者がGPT-5で…どういう話かというと、曲線のmoduli空間における交差数に関する未解決問題を解いた。数学の話だというのは分かるはずです。
つまり数学のある狭いdomainの問題をGPT-5で解いた。そしてここで面白い表現があって、これは後の話を先に持ってきたんですが、低いlow-hanging fruitが数学には多い。AIを活用して取れるものが。
ロ・ジョンソク 難度のあるdomainにこそ低いlow-hanging fruitがかなりあるようだ、という話ですね。はい、でもこれは私たちにも含意があります。business domainでもまだ入っていないdomainが非常に多いので、その中にも個別に良い果実がまだたくさんあると僕も思います。

チェ・スンジュン ここでもまたCOLT、さっきのConference on Learning Theoryで出た別の問題みたいですね。GPT-5.2がこれを解いた。 その証明の話、Leanにつないだ話、promptまで公開して、ある数学者がその過程を紹介したものを翻訳したんです。 でもそれ以外にもずっと見えるんです。Sébastien Bubeckがリツイートしていて、Sébastien Bubeckのtimelineに入ると最近の数学や科学でモデルをてことして使った話がずっと出てきています。 これが今の数学証明なんだと思います。去年はこうじゃなかったです。去年はこういう話はあまりなかった。
ロ・ジョンソク はい、私たち冗談半分で「地球上にいる賢い人はみんなAIに張り付いている」と言うんですよね。数学者や物理学者など、まだAIはそうでもないと言っていた専門層、医師や弁護士も含めて、そういう人たちが多くそう話していましたが、今はその人たちも本当にAIと一緒に働くのが基本になった感じです。そうなると
チェ・スンジュン そうですね。逃走者連合で驚いたのが医療分野の方が多かったんです。 とにかく今ロ・ジョンソクさんが言ったように、2025年初めのOpenAIポッドキャストのエピソードでもブラックホール研究の科学者が2025年初めの時点では 「自分は少し否定的な見方だったけど、何が可能かを見てクリックした」と。すぐ飛び込む状況。 つまり今、多くの数学者、科学者、この分野の人たちがそうなり始めた。「自分も参加する」こういう感覚ですね。
ロ・ジョンソク その通りです。私たちのYouTubeである購読者の方がコメントを残してくれたこともあるんですが、ここで「わあ、このモデル本当にいい」と言っているのは高価なモデルなんです。
GPT-5.2 Proのようなモデルを使って、promptingも精密にうまくやったときに出る結果なのに、無料モデルに抽象的なprompt1行だけ投げて出た回答が弱いことに対して「AIはまだだ」と判断するのをよく見かけて残念だ、という話が印象に残っているんですが、 promptingをうまくやる技法を学ぶのは今も非常に有効です。
チェ・スンジュン はい、専門家が良い質問を投げて、粘り強く行き来しながらback and forthでpromptingして、集合知を発揮して解けるのであって、クリック一発で解けるのはまだ今の姿ではないんです。 それに、強力なモデル、先ほどおっしゃったように現存する最前線のflagshipモデルを使う部分ももちろんありますしね。
米国の新たな挑戦: Genesis Mission 14:18
ロ・ジョンソク ところがこういうのを今、国防総省が、つまり米国国防総省が、White House、つまりホワイトハウスがそのまま命令を出したんです。Genesis Missionを発表する、と。 ここに翻訳を並べましたが、Google DeepMind、Anthropic、それからOpenAIまでが全部呼応して「一緒にやる」という状態です。
Genesis Missionをざっと見ると、結局これは国家科学技術の挑戦課題で、昔のアポロ計画やロシアのスプートニクでしたか、人工衛星打ち上げの後、60年代に米国科学界が非常に緊張して総力を注いだことが結局コンピュータ発展とも連動していたじゃないですか。 なのでそれに似た感じもありますが、とにかく政府横断でこれを進める。 Google DeepMindもGenesis任務を支援し、革新と科学的発見を加速する「国家的使命」としてブログ投稿を出しました。
つまり米国の科学者に先端AIツールを提供する。さっきTaoがAlphaEvolveを使えるように、AlphaEvolve、AlphaGenome、WeatherNext、これはたぶんsuper computing側だったと思いますが、そういったものにアクセスできるよう開放する作業をする。 こうしたことがこれまであった。 なので参加に関する話をして、直面する課題、エネルギーから疾病、安全保障まで、そういう方向だと。 Anthropic側は簡潔にこの程度で「参加する」と言及していました。
ロ・ジョンソク Manhattan Projectですね。これは中国と米国の間でどちらが超知能に先に到達するか、それが安全保障に直結する内容なので、国家単位のプロジェクトまで結成されたと。
チェ・スンジュン その通りです。アポロの前にManhattanがありました。今Jared Kaplanも物理学者ですよね。 この人はJohns Hopkinsにいましたが、科学関連の文脈でOpenAIとGoogle DeepMindが強くメッセージを出している一方、共同創業者が科学者なのはAnthropicが一番多いんですよ。 物理学者が多く、物理学者の採用も多かったので、ここでもコーディングモデルに全力を注いではいますが、別の考えもあるかもしれない、という推測をしてみました。 そしてOpenAIはエネルギー省との協力を深めると、もう少し詳しく扱っていました。内容はみんな似ています。
ロ・ジョンソク うらやましい話ですね。うらやましい話。
チェ・スンジュン なのでこうした文脈として、今米国の国家的ミッションがあり、証拠も出ていて、なので最初のDemis Hassabisのインタビューに戻ってタブ整理をします。ロ・ジョンソクさんも見たとおっしゃってましたよね?
Google DeepMind CEO、Demis Hassabisインタビュー分析 17:14

ロ・ジョンソク はい、見ました。Hannah Fry教授も見慣れてきましたね。はい、今回シーズン締めの回みたいです。
チェ・スンジュン そうですね。今年最後のGoogle DeepMindポッドキャスト回ですが、内容はやはり面白かったです。ただ問題は短時間でこういうのをたくさん見るので、すぐ揮発するんですよ。なので会話しながら記憶を引き出してみましょう。
ロ・ジョンソク ある程度、長く続いた一種の視点変化、sentimentの変化を最もうまく要約している対話だと思います。はい、今年前半まではAGIになるかならないか、いつになりそうか、そういう予測だったのが、 後半に入ってこれはなるゲームで、いつなるかに変わったんです。 25年が終わるこの時点で最大の点があるとすれば、これは必ずなるという話でみんな締めていることです。
チェ・スンジュン なのでDemis Hassabisももともとかなり慎重な人ですが、そうでありつつGoogle DeepMindの最初のミッションはAGIに近づくことだったじゃないですか。ある意味この仕事を最も長くやってきたチームのトップですよね。今見るとDemis Hassabisが今やこういう発言をするのかというほど急進的な発言をします。
ロ・ジョンソク いつも慎重に話して、誰かができると言ってもそれは少し見守るべきですと言っていました。
チェ・スンジュン そうです。だから科学的方法が一番重要だ。2024年にGoogleとGoogle DeepMindが統合される前に出していたメッセージは、私たちは慎重に進むべきでハイプを追ってはいけない、そう話していた人なんですが
ロ・ジョンソク ポイントを一度見てみましょう。Demisが話したことを。
AIとエネルギー: 核融合の未来 19:02
チェ・スンジュン 冒頭でとても印象的だったのが、エネルギー問題が解けるという仮定の話でした。核融合が解ければSMRという小型原子炉ももちろんありますが、核融合が解けたらどうなるか、つまり豊穣の時代のイメージを描きながら始めたんです。 Hannah Fryとの対話で、その話はエネルギー関連も何かやっているのかという話でしたが、実際にやっているそうです。Commonwealth Fusionとの深いパートナーシップを発表したといいます。 当然ですが、これが解けるというのは結局エネルギーは私たちがずっと言ってきたように、エネルギーと知能、ワットと知能が置換される、そういう話でしたよね。
ロ・ジョンソク そうです。私たち今はNVIDIA GPU何枚という表現をあまりしないじゃないですか。これはシン・ジョンギュ代表がおっしゃっていたことですが、電力量で計算量を置き換えて話すのが新しい単位になっていました。なのでギガワット、ギガワット級が一つの基準になった感じです。
チェ・スンジュン ですよね。だから今少しSFみたいな話ですが、エネルギー問題を解決すると既存の多くの問題が消える、そう言って冒頭を組み立てていました。
ロ・ジョンソク はい、全部置き換えられます。
チェ・スンジュン なのでエネルギーが安く、再生可能でクリーンで、24時間365日生産できるエネルギーがあれば、それは結局AIに使われるわけで、そういう想像をかき立てる話が前半にありました。そしてやはりまだムラがある。50%くらいまで来たようだという話をしていました。自明な問題があるのは確かでムラはあるが、解けない問題ではないだろうという話でした。
データ枯渇の終わり?AIの自己学習と進化 20:37
チェ・スンジュン データ枯渇の話は後で出てきた気がしますが、そうではない、いくらでも生成できるし、人間依存データから離れる体制に行くことも今、という部分ですね。今不足しているのはonline learning、つまりcontinual learningで、現状は抜けているが行間ではそうしたことを扱っている。
前回のShane Legg回でもそうでしたし、そういう話が読み取れました。そしてこの部分でGoogle DeepMindの従来姿勢をHannah Fryが聞いたんです。もっと長くラボ内に閉じ込めるべきだったのか。ところがDemisもGoogle DeepMind統合後は製品を出す側にかなり参加しているので、その利点もある。だから何を失い、何を得たか。
もしラボにもっと閉じ込めていたらがんを解決できたかもしれない、そんな話もしていました。AlphaFoldなどを作る側にもっと集中していればそういう問題を解けたかもしれないが、実際に製品を出しながら進めることで得たものも多かった、そんな話をしていました。 そうですね。そして狂った競争状況を作り出した。だからそういう状況では厳格な科学をやるのは難しいが、そのバランスを取ろうとしている、この部分も面白かったです。 また興味深くも一般大衆は実際の最先端から数か月しか遅れていない。だから誰でもAIが何かを感じる機会を持てるようになった。そして政府もAGIへ向かう流れをよりよく理解するようになったという話でした。
ロ・ジョンソク 少し前の夕食の席でシン・ジョンギュ代表に偶然また会ったんですが、その話をしていました。ロ・ジョンソクさんが言うElon MuskやSergey Brinが私たちより数か月先のfrontierを見ているというのは多分違う。多めに見ても1か月くらい早く見ている程度でしょう、と。 このfrontierと公開のギャップは思ったよりかなり小さい。たぶんそれは中国と米国の競争、OpenAIとGoogleの競争などが影響したのでしょうが、 逆に私たちのような一般人、同好の士、資本がなくてtrainingに参加できない立場から見ると幸せな世界ですよね。入れてくれるわけだから。
チェ・スンジュン もちろん月200ドルどころか月2, 3만 원も多少コストがかかるので、誰にでもというわけではないかもしれませんが、今しきい値がものすごく下がっているのは確かですよね?
ロ・ジョンソク それに200ドル料金プランも、春から夏にかけて来る頃まではほとんどの人が使っていない領域でした。でも今は200ドルを使う人を私はかなり頻繁に見ます。つまりそれだけ元が取れる以上の価値があるということです。
チェ・スンジュン でも問題は認識の地平にはやはりムラがありますよね。
ロ・ジョンソク gapはものすごく広がっています。このAI frontierを追う人と、何とかそちらへ行こうとする、私たちが逃走者とdefineした領域と、そうしないと決めた人のgapは大きく開いています。
チェ・スンジュン とにかくそういう時代ですが、その次に話したのがscalingの話でした。 ここでも合成データなど、とにかく私たちはscalingしないと言ったことはない。 ここが少し面白い段落なんですが、いつもこう急上昇しなくても常に得られる部分はあった。0か1かではないということです。その間にある領域があるので、私たちはずっとscalingしていたというニュアンスで読みました。
ロ・ジョンソク この部分について数字の感覚を少しつかむと、僕はNemotron paperを読みながらそれを感じたんですが、通常このfrontierモデルの学習に使われるトークン数は20兆を超えます。全体で使われたトークンは27兆程度ですが、面白いのはそのうち数学、科学、あるいは中核論理に当たる部分はQwen 30Bのように、以前のpaperで見たようにpre-training datasetの品質を上げ続けているんです。ところがそうして上げたhigh-quality datasetはこれだけだ、と言う量がまだ1兆未満です。つまり5000億程度なんです。5000億程度の数字なので、まだ精製されていないrawなpre-training dataも後ろで絶えず品質が上がって再利用されている。だから依然としてそこでもscaleが支配していると見ています。 RLHFとはまた全然違うpre-train領域ですが、そこでもdataset品質が上がれば上がるほど単位エネルギーあたりの収率が良くなるので、ここもまだupsideが大きい。
チェ・スンジュン それにbootstrappingが起きているので、システムが十分良くなると自前データを生成する。コーディングや数学のように答えを、ある意味で検証できるdomainは無限データを生産できる、そうHassabisは話していました。
ロ・ジョンソク なのでscalingの限界だ、wallだという話も25年の終わりには薄れてきています。
チェ・スンジュン 50%はscalingに、50%は革新に使う。つまり既存regimeでもscalingの努力をしていて、それ以外の方法でも革新に取り組んでいる、そう話していました。そして幻覚問題は、幻覚は依然あるものの解決の可能性はあるだろうと。ここで確信的な言い方はしていませんでしたが、とにかく良くなっている方向の話です。 ただもちろん認めてはいました。まだあると。
世界をシミュレーションする: World Modelの潜在力 26:33
チェ・スンジュン それからworld modelの話をしていたんです。GenieやVeo、そしてSIMAの話で、この部分は実はかなりSF的でありながら興味深い話でした。
ここを少し進むと、結局Demis Hassabisはそもそもゲームのバックグラウンドがありますよね。テーマパークや有名なシミュレーションをするゲームを幼い頃に開発していたんですが、これがシミュレーションできれば解ける問題だ、という形で今SIMAやGenieを紹介するんです。 Genieは環境を生成するものですよね。リアルタイムで。SIMAはその環境に入って活動できるエージェントです。 つまりGeminiの推論能力を持つSIMAエージェントがGenieが作る環境の中で絶えず問題を解いたらどうなるか、という話でした。
ロ・ジョンソク そうなると私たちが定義できないような問題空間、problem spaceを全部searchで解くことになって、すべての問題を解決できるという話ですね。無限のcomputationさえ与えられれば。
チェ・スンジュン それが8月でしたね。Genieが出て、この空間に入って実際にnavigationできるとかそういう話ですが、SIMAは11月に出たんです。 そこでこれは実際にNo Man’s Skyのようなゲーム内を探索するものですが、どんなゲームにも入れるエージェントです。 しかも内部で今試しているのがGenieをSIMAにつないで即席で世界を作ることで、僕が今論文を抜かしましたが、それをやる論文もGoogle DeepMindが公開しているんです。 そのループを作った話。情報をあまりに多く見ていて曖昧なので誤りがあるかもしれませんが、とにかく見た気がします。
ロ・ジョンソク そうなんです。Demisがやっていて感じるのは、DemisとElon Muskが似た話をするんですが、Yann LeCunやSuttonの言うことは少しold schoolです。
実際、モデルは構造がどうであれinductive biasを最大限除去してモデルをgeneralにし、そこに無限のcomputationを入れれば解けない問題はない、というのが彼らの基本視点です。実際Transformerだって、言語間のattention計算ですがgeneralなlogicとして入れて画像も入れて全部使っているじゃないですか。 つまり結局ある臨界点を超えると別の形式体系が出てきて全部解いてくれる、という話を彼らもしていて、例として挙げるのがGenieやVeoで、単に学習しただけなのに非常に精巧な物理エンジンを持っていないかという話をするんです。
なので僕個人としても、AGI、ASIのためにTransformerアーキテクチャのようなモデルはarchitecturally何か制限があるというold school、Yann LeCunやSuttonのような話は意味がないと思います。
チェ・スンジュン Demisも似た話をしますが、まず現在のシミュレーションは肉眼精度であって本当に完全精度ではない。けれど方向性はそこを目指している。きちんとした物理学グレードの実験に耐えられるか、そういう話をしていました。
それでこのシミュレーションについてのDemisの古い考えをずっと話すんですが、Santa Fe Instituteのある実験にも言及し、そこで経済構造などがgrid worldで創発する話や意識の話もして、つまりDemisの考えはシミュレーションできるならいいのではないか、というところをここで一度押さえ、後半でも再び押さえます。
AIはバブルか?産業革命との比較 30:28
ロ・ジョンソク ここから進むと、これも質問が面白かったです。Hannah Fryが単刀直入にAIはバブルかどうか、バブルが弾けたらどうなるか。Demisが率直に認めたのは、今バブルは入っている。AIエコシステムの一部はたぶんバブルだ。 でも弾けることについては、弾けたらどうなるかに直接は答えず、Googleは、Google DeepMindは弾けても安全だ。私たちは何にhedgingできていて何の基盤があるか、そういう点を示しました。 TPUがあり研究がどうなっているかなどを挙げながら、私たちはこの方向が続いてもよいし、そうでなくてもやれる、という話を少し誇っていました。
ロ・ジョンソク はい、でもこれもシン・ジョンギュ代表がその夕食の席で話していたことで、以前このポッドキャストでも話していたんですが、これって過剰投資じゃないか、余るんじゃないかという話があったじゃないですか。 コンピューティング資源はもう終わりと言っていましたが、今すでに現実の例で言われているのが、インターネットトラフィックの97%は動画なんです。YouTubeとNetflixなんです。 テキストや他データの転送に使われるのは3%だけで、トークン生成もClaudeで100万トークン使うのがどれだけ大変か、本当に多く使っても25万トークンとかですが、 実際にはnanobananaで画像生成を1回させるだけで2万5千、動画を30秒1本生成すれば数十万トークン使ってしまうので、今後はこの側がもっと大きくなる。まだ始まったばかりに過ぎない。 ここでもやはりトークンの大半はこのマルチメディア、つまり動画などのコンテンツから出て、テキストやコーディング、science、logicはその中でごく一部だという話でした。 はい、なのでmakes senseでした。
チェ・スンジュン はい、興味深い夕食時間を過ごされましたね。
ロ・ジョンソク はい、だからこの半導体投資サイクルは実は過剰投資局面かどうかではなく、今始まるところだと見ないといけない。 はい、それに外ではまだ噂が多くないですが、イ・ジンウォンさんのようなチップをやる人たちに会うたびに聞く話が、開発したいのにRAMが買えない。HBMを買う以前にLPDDRですら次の納期が1年後、2年後だ。 それにSamsungもLPDDRは売り切って価格を2倍に上げた、そんな話なんです。 なのでメモリのスーパーサイクルがまた始まった。 つまりそれは何かというと
チェ・スンジュン ジンウォンさんの話が出たので、いつかお招きして僕らも話をちょっと
ロ・ジョンソク 半導体の話を一度聞かないとですね。
チェ・スンジュン それでここはecho chamber側のsycophancy、何でしたっけ、へつらい関連の話ですが、ひとまず飛ばします。 この部分はAGIの話で、前回のShane Legg回とつながって起きていることを少し紹介した部分でした。とにかく何かemergingのためにAGIに近づいている。 今proto-AGIの候補くらい、つまりGenie、SIMAのようなものが統合されるとproto-AGIの候補くらいになるのではないか。 それにこの部分も面白かったです。産業革命から学ぶ教訓、産業革命について最近本をたくさん読んだそうです。Demisが。なのでそれが来たとき、混乱を和らげるという側面で昔の歴史をもう一度学びたい部分を読んだそうです。 ただここで、産業革命より10倍大きく10倍速く起きる。1世紀ではなく約10年にわたって展開するだろうと。 産業革命はほぼ200年にわたって起きましたよね、私の記憶では。
ロ・ジョンソク でも私たちが実質的に見るのは100年くらいですよね。1800年代後半から1900年代後半までを見る。
チェ・スンジュン でも当時も世界は大混乱だったんです。今それが10年で起きるなら、さらに大混乱という話ですよね、実際。
ロ・ジョンソク 現実の話に戻して言うと、当時は世代をまたいで起きたので親が失業しても子どもは新しい職業がある世界で生きられた。でも今は親と子が同時に失業する世界だという話です。
チェ・スンジュン 笑って話すことではないんですが、あまりに呆然としてしまって。
ロ・ジョンソク はい、笑って話すことではないですがその通りです。でも結局、政府システムが私はもっと重要になると思います。富が数社に極端に集中して、そこから得たもので本当の普遍所得、basic incomeとか、あるいは普遍を超えてSam Altmanは巨大な所得と言いますよね。もっと多い
チェ・スンジュン そうですね。そうですね。basic incomeではないものを話す人もいますね。
ロ・ジョンソク 26年には、実際25年に蓄積されたこうした生産性変化が現実に来るとみんな予想していました。企業で大量解雇が実際起きるだろうと。26年にもう。
チェ・スンジュン それが実はまたエネルギーの話と噛み合って回るんですよね。エネルギー問題が解ければ、そういう経済的圧力や個人が受ける圧迫をかなり解消できる部分があるのではないか。もちろんエネルギー問題が解けても他の問題は絡んだままではあるでしょうが、とにかくいろいろが同時に噛み合って回る感じを受けます。
ロ・ジョンソク 社会的談論までは行きすぎないようにしましょう。
チェ・スンジュン 僕もそうなんですが、Demisが話したことなので。Demisが今回かなりそういう話を扱っていたんです。新しい経済システムとかそういう話もしていて。
ロ・ジョンソク とにかく私たちは変化への迅速な適応を志向しているので、早く変化に適応しましょう。
チェ・スンジュン post-AGIとか、そういう話はShane、Shane Leggが考える努力を主導していると言っていました。なので経済学者や政府ともそういう文脈で話している。ここで僕がさっき言ったのはそれですね。経済学者の友人たちから興味深い話を聞いたし、もっとこの関連作業があればいいし、哲学的側面もある。仕事が変わり他も変わるが、もしかすると核融合が解決されているかもしれない。そうなると豊富なエネルギーがあり希少性後の世界になる。ではお金はどうなるか。皆がより豊かに生きても目的はどうなるか。多くの人は職業から目的を得て、家族を養うことから目的を得るが、それはとても高貴な目的だ。ではそれがなくなったら。こうした問いの一部は経済的問いから哲学的問いへ混ざっていく。今回そういう話をしていました。とにかく、そこでは国際協力が必要だと。
でも思ったより起きていない。だからみんなに注目させるには何らかの事件事故が必要なのか。すると大半の研究所には責任感があるがオープンモデルもあるので、すべてを統制はできない。だから扱える程度の事件が起きれば悪くないのではないか。rogue AI、rogue、こうrogueという表現は少し危険な側を指すじゃないですか。
ロ・ジョンソク はい、rogue。はい。
チェ・スンジュン はい、そうです。X-MenにもRogueはいますが、とにかく、つまり不良ですね。不良国家、不良組織のようなものを防ぐのは難しいが、中程度のことが起きれば警告射撃になるだろう。そうすれば国際協力や標準がより作られるのではないか。そういう話もしていました。
AIの限界はどこまでか? 38:05
チェ・スンジュン それで人間にしかできないことがあるのか。けれど限界はない。
この部分は実は私たち、そしてロ・ジョンソクさんの関心ともかなりつながるんですが、Demisも計算を信じる人でした。von Neumann体制でTuring machineの方法を追求してできないという証拠は今までない。この方法で押し切る、という話でした。
つまりすべては古典コンピュータで複製可能だと。ここでHannah Fryが挑戦的な質問をしたんですが、ここに座っていて照明の暖かさを感じ、背景の機械音が聞こえ、手にある触感、そういうものまで全部古典コンピュータで複製可能だとDemisは言うのか、とさらに確認していました。 そしてDemisは哲学者2人を挙げます。KantとSpinozaを挙げるんですが、Spinozaは僕もよく知らなくて調べたら興味深い話が出てきました。 シミュレーションされた世界が重要だ。シミュレーションできることの限界は何か。シミュレーションできるならある意味では理解したことだ。Demisが何を考えているかが今回かなり明らかになりました。
ロ・ジョンソク 上で使っていたIsomorphicという形容詞。
チェ・スンジュン Isomorphic、はい。Demisが代表の別会社ですね。
ロ・ジョンソク はい、Isomorphic Labsという生命工学の新薬開発会社です。それにIsomorphicという形容詞はゲーデル、エッシャー、バッハでも中核の形容詞なんです。
チェ・スンジュン そうなんですか?そうなんですか?
ロ・ジョンソク はい、結局はすべて関係が支配していて、残るのは関係だけで、媒体が何であれその関係が一致するなら同じだということです。同型性の原理ですが。
チェ・スンジュン そこまで考えたことはなかったので、僕ももう一度見てみます。Demisもそういう話をしていて、眠れないそうです。いろいろな理由で興奮もするし仕事も多いし、夢見てきたことをやっているし。
ロ・ジョンソク 多方面で科学の絶対的最前線に立っている。以前Noam Brownもそう言ってました。朝起きてfrontierがどれだけ進歩したかを見るのは、自分に与えられたprivilegeだという表現でしたね。特権。
チェ・スンジュン そうです。はい、そういう話をしていましたね。
ロ・ジョンソク うらやましいです。
チェ・スンジュン 時間がだいぶ経ったので、ここはさっと進めると、はい、AIリーダー間の関係、そして懸念点、そして結局のところ懸念すること、期待すること。 ここで面白いのはDemisはAGIを安全に越えるよう世界を助けるのが自分のミッションだという点です。post-AGIは他の人の仕事だ。 もちろん自分を呼んでくれれば協力的な人間だから参加する。だけど自分の任務はAGIを安全に越えるよう世界を助けることだ。そしてサバティカルを取りたい。 その後はまあ、そういう話で今回を締めていました。 Demisがどんな人物かをむしろ「The Thinking Game」編よりよく分かる回だった気がします。かなり率直な話をしていたので。
ロ・ジョンソク 頭を 많이 쓰시는 분들은 탈모が本当に早いですね。Ilya Sutskeverもそうだし。
チェ・スンジュン まあ、そうでない人ももちろんいますけどね。ということでここまで一通り扱ってみました。 それでroonという人がOpenAIのtech staffの一人ではないかという噂がありますが確認はされていません。 でも面白い話をたくさんする人で、ここでAI批判論に少し反論する話を今日でしたっけ?昨日の未明に上げていました。なので今日紹介した話に近いことをroonも押さえていました。 機械知能を第一級の生産要素として生まれる新しい形の組織を見ることができる。 この部分が印象に残りました。
ロ・ジョンソク 私たちが最近言っているAI、AI-native companyのような話ですね。
チェ・スンジュン 機械知能を第一級の生産要素として生まれる新しい形の組織がある、という話をしていて、しかも面白いことにこの人の発言でさっき強調した部分をfact checkしてみてと言ったら、最近GPT-5.2が皮肉にもfact checkをうまくやるんです。 hallucinationがあるLLMモデルですが調査できるツールがあるので、fact-checkingもかなりうまくやるのが見えたりして面白いです。
おおむね事実、一部事実、そしてそれに対する正確な引用のようなものも出してくれて、根拠がある。Terence Taoがこれをやったのは事実だ。強い推測がある。断定は難しい。この部分は虚偽、誇張の可能性が非常に高い。fact checkを一回頼むだけでこういうものが出る時代です。
Andrej Karpathyの2025年AI年末総括 42:52
チェ・スンジュン もうほぼ1時間やりましたね。年末総括、これはAndrej Karpathyがまた年次レビューしてくれてタイムラインでもかなり回っていたようですが。今年何があったか。Karpathyは比較的中立な方なので、幽霊対動物、新しいレイヤー、CursorやLLM、そしてClaude、Codex、それからvibe codingや画像モデルの革新、LLM GUI、つまりGenerative UI側も後半に大きな出来事がありました。 はい、そして結論は「シートベルトを締めろ」でした。
ロ・ジョンソク うちの会社のエンジニアの一人がそんな話をしていました。AIがUI layerを全部書いてくれるなら、うちの会社はNext.jsの上で全部ビルドされているけど、なぜNext.jsを使う必要があるのか。もうnative JavaScriptを直接使えばいい。フレームワークを剥がそう、みたいな話でした。
チェ・スンジュン 僕も最近それ関連で話したいことは色々ありますが、時間の関係でひとまず進めます。Gemini 3 Flashも出ましたね。はい、速かったです。もちろん性能は少し物足りなさもあるかもしれませんが、こうピタッとはまるfitの空間があるはずですよね。ということで出ました。
ロ・ジョンソク そうですね。はい。
チェ・スンジュン とにかくFlashが出て、モデルはずっと出続けています。今クリスマスまで4日ですが、まだ休まない感じです。この人たち年末休暇はいつ行くんでしょう?そろそろですかね。
ロ・ジョンソク 行けないんじゃないですか、行けないんじゃないですか?はい、これはほとんどチキンゲームです。ずっと出ていますし、はい。
チェ・スンジュン そうですね。出る理由があるんです。今OpenAIも分岐点に立っていて、分岐点という表現も少し違うかもしれませんが、とにかくかなり圧力を受けていて、お互い押し込まないといけないのか、確認させないといけないのか、証明しないといけないのか、そういうことが年末でも続いています。
ロ・ジョンソク OpenAIとGoogleがツートップで抜け出して、Anthropicはコーディングの堀を掘ったけど、その部分が少しずつ薄くなるような感覚はあります。
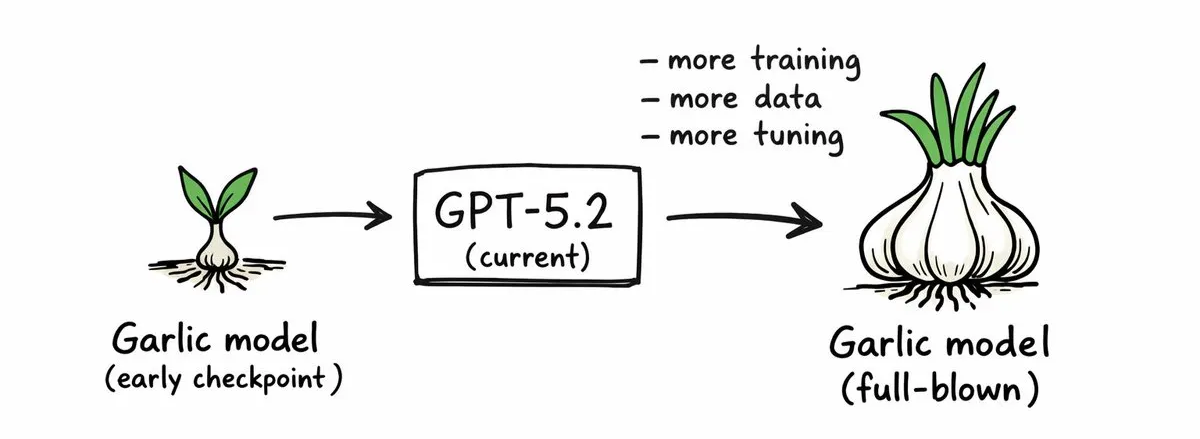
チェ・スンジュン Sonnet 4.7の噂もありますね。それがOpus 4.5級の性能で4.7の速さなどを持つのではないか、そんな推測がタイムラインに見えます。ただまだ確認はされていません。 最近Claudeに障害がありましたが、ああいう時にモデル実験で障害が起きたのではないかという妙な推測もありました。 それからGPT-5.2はThe Informationの記事でしたが、単なるearly checkpointだという噂もあります。だからこうやって出し続けているわけです。
そしてGPT-5.2の土台になっているのが、前回話したその第2弾に入る何でしたっけ?Shallotpeatでしたか、あのモデルではなくGarlicというコードネームのモデルで、これがearly checkpointでfull-blown Garlicは来年初めに会えるだろう、という話があります。そしてロ・ジョンソクさんがかなり見ていたというNVIDIA Nemotron、これは何ですか?
NVIDIA Nemotronとハイブリッドアーキテクチャの未来 45:54
ロ・ジョンソク NVIDIA NemotronはLlamaのようにNVIDIAが完全公開したモデルですが、僕がこれを面白く見ている理由はデータセットとtraining recipe、コードまで含めて全部公開されているからです。全部公開されているので。
チェ・スンジュン 単なるオープンモデルではなくオープンソースなんですね。
ロ・ジョンソク 完全オープンソースです。そしてNVIDIAとしてはこういうことをやる人が増えるべきなので、こうしたrecipeを作ってみんなに配るインセンティブが十分あるんです。増えればチップを買う人がずっと増えるからです。
でもNemotronは私たちがこれまで話してきたpre-training、SFT、RLHF、RLVR、そして数学とscience、そしてコーディング、この部分のデータセット、そういうものも自分たちで作ったものまで全部公開し、それがどうなっているかを全部GitHubに上げていて、僕は最近これを熱心に見ています。
僕も感覚的に、私たちはどこへ逃げるべきかという問いへの答えとして第一は当然、現実の問題を今のfrontierモデルのharnessで作ることですが、同時に後ろで感じる既視感は、このcomputation比効率が上がり続けていることです。アルゴリズムの増加、データセットの増加、データセットのオープン化、こうした理由で、もしかするとAndrej Karpathyが言っていたcognitive coreのような水準、10Bパラメータ以下でも一つのビジネスを完全にカバーするようなモデルが出る気がします。 そしてそういうものを学習させるRLVR環境の会社も新しいSI会社として少し生まれるはずです。ただ違いがあるとすれば、それをやるために必要な基礎情報が非常に多いことが差です。
なのでそういう世界が来る気がして、僕はharnessを作ることに加えて、このmodel workもtraining、それからfine-tuning、RLVR、evaluationのloopをビジネスロジックの中に持つべきだと思っているんです。だからその部分をうちの会社も内製化しようと努力していますが、Nemotronの話に戻ると、SSMとMambaの話は1〜2年前、1年半前くらいに一度大きく来て、24年末頃にFalconなどでMamba-basedモデルを作ったりしましたが、このSSMとMambaが非常に面白いんです。
これもいつかどう作られたかレビューすると良さそうですが、intuitionだけ言うとこうです。最初にRNNがありましたよね。RNNで実質的なlanguage modelingをやっていた。でも最後にcontext vector一つだけで全文脈を推論しないといけないので性能が出にくい。
そこで出たのがattentionモデルでした。前からinputとして入ってきたcontextのhidden activationを全部持っていて、推論するたびにそれをもう一度使う。attentionをすればこの問題が完全に解決されるという話が出たわけです。だからそのattention logicだけを取り出して出てきたのがTransformerですよね。
Transformerが解決したのは、RNNはinferenceは非常に効率的だがtrainingのparallelizeができず文を全部読まないとtrainingできなかったこと、その間にvanishing gradientやexploding gradientなどの問題が発生したことでした。これを解決したのがTransformerです。
ただTransformerの悪い点はparallelizeはできるが、内部でattention logicを計算する時にlengthが長くなると、inference時にcontext lengthが長くなると計算量がO(n²)でquadraticに増えることでした。もちろんこれを解決する多数のlogicが出て、grouped-query attentionや演算過程のFlashAttentionなどでかなり改善されましたが、それでもRNNの効率には追いつけません。
ならここで質問は当然出ます。RNNの強みだけ取り、Transformerの強みだけ取ったらどうなるか。RNNのようにinference timeで非常に効率的な構造を持ち、Transformerのように学習時にparallelizingできたらどれほど良いか。そのintuitionを作ったのがSSMです。 そのSSMが持ついくつかの問題を少し解決したのがMambaですが、見ると中身はRNN感覚とかなり似ていますし、論文自体は僕の感覚では数学的trickです。面白いんです。面白いのはこのNemotronが完全にMamba-basedだという点です。
ただMambaの問題は、これはRNNのように一つのcontext vectorにsequenceを要約する感覚で、attentionはtoken間の関係を絶えず計算する感覚で、だからRNNは要約が得意でTransformerは関係記憶が得意、こうした長短があるのですが、最近のモデルはこれをhybridと言うんです。
例えば今私たちが慣れているTransformerモデルはTransformer blockが数十個積まれていますよね。NemotronはMamba blockが8個くらい積まれた上にself-attentionを置き、その間にFFNを置きます。MoE方式でFFNは同じように入り、またMamba blockが8個ずつ積まれてその上にattention blockが1つあり、そのグループが8〜9個構成される構造です。 なので30B全体サイズで3B程度がactivationされるモデルですが、とてつもなく速い。何倍かと言っても、これは1年半前に生まれたんですが、このhybrid、これも一種の新しいアルゴリズム遺伝子ですよね。
このモデルでまた世界がかなり回るだろう、このhybridの利点が計算面で圧倒的に大きいからです。その次にinference timeでTransformerよりは少ない演算量と小さいモデルサイズで少し良い結果を出す。何倍良いという表現は今は少し危険ですが、これを出しているので、僕の個人的予想では次世代frontierもこうしたhybrid、MambaプラスTransformer hybridモデルへ移る可能性が非常に高いと思います。
チェ・スンジュン 今おっしゃった代替的遺伝子という表現がある意味かなり重要なポイントですが、代替アーキテクチャは実はそこにscalingを入れるほど投資がなかった。けれど動くのが見えれば、雨後の筍のようにまたアーキテクチャを差し替えられるわけですよね。
ロ・ジョンソク そうです。なのでこういうのが出たのはまだ数が少ないです。少ないんですが、 Nemotronがそこを着実に押して、ここでまた小さい計算量でこのfrontierに準ずる自分たちのdomain向けモデルを作れると証明されれば、実はすべてのverticalもこの方向へ走りたくなるインセンティブが生まれるので、 NVIDIAにとってはこのフレームワークと自社チップがさらに売れて良いし、 私たちのような会社にとってはfrontierに準ずるknowledgeとrecipe、コード、データセットまで全部くれるわけだから、これは深く見る必要があると思って、Nemotronのfine-tuningとRLHFは僕が一度自分でやってみようか今考えています。
チェ・スンジュン 結局最初におっしゃったように、少しヘッジする必要があるわけですね。既存frontier側で既存のモデル、すでにあるharnessを構築することもやらないといけないし、可能なところではmodel workも今の状況を把握して掘り下げる。どこへ行くか分からないし、どこでgainを得るか分からないから。
ロ・ジョンソク はい、でもモデルを捨てられないのは、今ほとんどのvalue capture、価値を取る区間が全部モデル会社にあるからです。モデル会社でない他社は全部、非常に薄い領域で競争しなければならない。
チェ・スンジュン さっき少し触れましたが、新しい形のインフラを扱うTMLのような会社もありますし、とにかくそういう話がありました。次回深く入ればまた興味深いセッションになりそうです。
ロ・ジョンソク 一度SSM漫談をやりましょう。
Xiaomiなど最新AIモデル動向 54:40

チェ・スンジュン Xiaomi、これもロ・ジョンソクさんが教えてくれて僕も調べましたが、Xiaomiもやっていますね。
ロ・ジョンソク paperは読んでなくてabstractだけ見ましたが、どこかのモデルを持ってきて真似したのではなくfrom scratchで本当に自分たちでやったのは確かです。なので。
チェ・スンジュン 最近は韓国もfrom scratchでやっていますよね。なので中国は今かなり突き抜けていて緊張感を持たせます。
ロ・ジョンソク 感覚的に中国はもう米国レベルです。僕が見るとそうですね。
チェ・スンジュン ある意味、現時点で2強ですね。とにかくそういう時代で、その次もやはり中国側モデルですが、今はレイヤーをこう抜いてくれるんですよね。つまり生成がレイヤー化されているんです。レイヤーを抜くんじゃなくて。
ロ・ジョンソク これは使ってみないとですね。
チェ・スンジュン そしてYao Shunyuという、以前OpenAIにいた人がTencentへ。
ロ・ジョンソク スター研究者ですが、Tencentに転職しましたね。
チェ・スンジュン それで疲れていてこれを扱えるか分かりませんが、Simon Willisonがまた少し地に足をつけて、今日できることをこう面白く書いた投稿があるんです。JustHTMLというのはSimon Willison本人がやったのではなく、それをやった人の話を引用したものですが、かなり興味深い話がありました。 どうやったか。非常に多くのテストを作って、すごく小さい単位で進めながら何かをportingしたり新しく作ったりする過程を広げて見せているんです。 これを1週間前くらいに読んだ時はかなり面白く読んだんですが、今はもう記憶が薄れています。ただ関心のある方はこれをどう実際にやったかを見ればインサイトを得られると思います。
締めくくりと次回エピソード予告 56:31
チェ・スンジュン なので年末なのに毎週ニュースと情報が尽きません。
ロ・ジョンソク 機械は回り続けていますからね。pre-trainingコードとRLHFコードはこの時間も力強く回っているからじゃないですか?
チェ・スンジュン ですよね。私たちが今年を締めるエピソードをもう1回収録する機会はありますか?
ロ・ジョンソク たぶんそうでしょう。あと1回くらいありますよね。27日にキム・ソンヒョンさんと今年を整理する収録をしようと言っていたじゃないですか。今年frontierはどう進歩したか、という話になりそうですが、その時もう一度最後にモデルの話をすることになる気がします。
チェ・スンジュン 整理するにはニュースがない方が回顧できるんですが、その週にもニュースがまた出ると困ります。では今日はここまでにしましょう。
ロ・ジョンソク はい、今日も一通り見ました。
チェ・スンジュン はい、一通り見ただけという感じですね。深く入ったところはそれほど多くないですが、はい、分かりました。
ロ・ジョンソク はい、お疲れさまでした。
チェ・スンジュン はい、お疲れさまでした。