EP 82
原理を考えるプロンプティング
オープニング:「原理を考えるプロンプティング」 00:00
ロ・ジョンソク 録音している今日は2026年1月9日金曜の夜です。久しぶりに夜の収録になりました。26年に入って最初の収録でもあります。26年がやっと1週間ほど過ぎただけですが、その間に面白いことがたくさんありましたよね。
チェ・スンジュン そうですね、それでもありがたいのは、思ったよりニュースが12月中旬くらいのリズムよりずっと耐えやすいことです。
ロ・ジョンソク 私も12月20日ごろから12月末までは10日ほど少し静かで、
それから新年が始まって、まだビッグテックのフロンティアラボから大きな発表が出たわけではないですが、コミュニティ側ではClaude CodeやOpenCodeのようなコーディングツールを中心に、どう生産性を上げるかといった話がすごく多く見える気がします。 それに著名な方々の哲学的な対話も行き来している感じがします。
チェ・スンジュン それで私は少し休みながら、いろいろなイベントや出来事はあったんですが、考えを整理する時間を持ちました。なので、私が好きなプロンプティングのテーマにもう一度戻ってきました。
ロ・ジョンソク 今日は久しぶりに、チェ・スンジュンさんのプロンプティングセッションです。
チェ・スンジュン 最近はみんな本当に上手なので役に立つかどうかは分かりませんが、それでも一度探究してみた内容を「原理を考えるプロンプティング」というタイトルで、最近試してみたことの土台にある原理のようなものを振り返ってみようと思います。
METRアップデートとClaude Opus 4.5の体感(50%-time horizon) 01:34
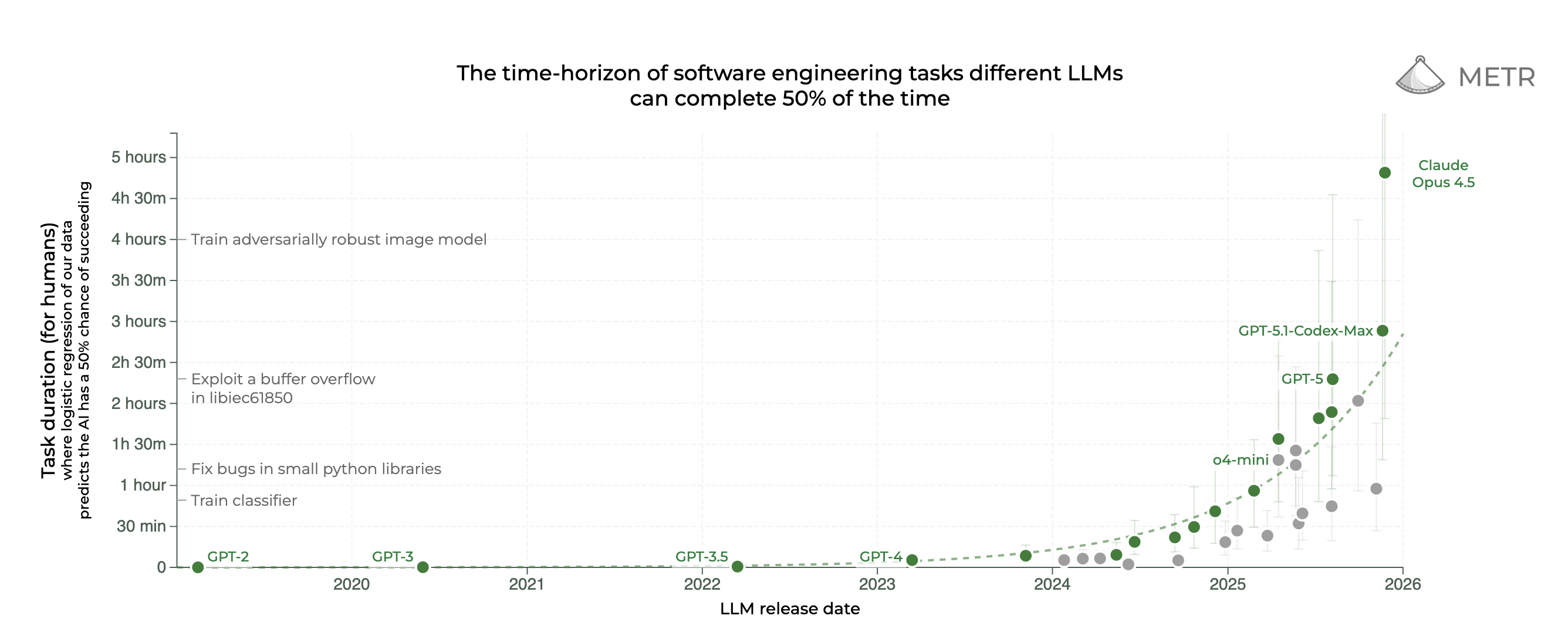
チェ・スンジュン まずニュース性のある話をいくつかすると、2025年12月20日にこのグラフが更新されたのを私たちが言及できていなかったみたいです。これはこれまで何度も紹介したMETR 50%-time horizonに関するものです。 でもリニアスケールで見ると、Claude Opus 4.5が今4時間49分、ほぼ5時間へと大きく跳ね上がっているのが分かります。 これをログスケールで見ると、順調だけど少し上がったような感じですが、こちらを見ると印象はこうなります。
Andrej KarpathyのFOMO 02:13
チェ・スンジュン これをお見せする理由は、実は2025年末にAndrej KarpathyのFOMOっぽい投稿がすごくホットだったからです。 Claude Opus 4.5を周囲の人たちが1か月ほど使ってみて、何かがカチッと変わった気がする、という証言のような話が12月にたくさん上がっていましたが、Andrejもこんなふうに遅れている感覚を持ったことはない、と。
それで、すでに多くの方が扱っていると思うのでざっくり流すと、ここはタイトルが面白いんですが、AndrejとBoris Cherny、Claude Codeを作っている人ですね、それからIgor、xAIの創業メンバーだけど今は離れた方、要するにスター級プレイヤーたちが話していたんです。 Andrejがこう言ったらBorisも自分も同じ気分だと。とにかくカチカチ進んで、PRもすごくて、みたいな話です。
ロ・ジョンソク そうですね。
チェ・スンジュン Igorが「Opus 4.5はかなりいいね」、Andrejが「本当にいい」「この30日だけでも追っていない人は、このテーマについてすでにdeprecatedな世界観を持っている」という刺激的な表現をして話題になりました。
ロ・ジョンソク その通りです。私たちは1年前、すでにtest-time compute、推論時の計算を多く使うことが成果と非常に密接に関係している、という話をしていて、それが去年を支配したテーマでしたよね。 今でもこのClaude CodeやOpenCodeをうまく使う人を見ると、Harnessをどう最適化するか、チューニングが本当に上手な人が多いです。
Harness最適化とマルチエージェントコーディング 04:01
ロ・ジョンソク だから基本的に、今やこうしてティキタカで対話しながら作業を進めるのもかなり昔のトレンドですよね。 今は何かスペックを一つ書いておけば、すごく精密なスペックでなくても、サブエージェントを数十個回して一晩寝かせて10時間以上、最近AIを拷問するという表現をよく使いますよね。 「拷問すれば答えが出そうですね」と、こういう話をよくします。 なので私たちの会社のエンジニアもタスクを7時間、8時間回すことがもう普通に起きている気がします。
チェ・スンジュン でもそれをエージェント1つだけ回すんじゃなくて、Claudeのタブをいくつも開いてマルチエージェントで6個くらい、Borisは10個くらい回している感じでしたよね。そう、StarCraftでマリーンをばらまくみたいな感じですかね?
ロ・ジョンソク マウスとキーボードを華麗に行き来する、そのくらいAIを扱わないといけない。
チェ・スンジュン つまりコマンドセンターっぽい感覚なんですよ。想像できます。だからClaude Opus 4.5が、まあ普通に良いねと言う人もいれば、何かスイッチが切り替わったと言う人もいました。
ロ・ジョンソク 最近「AIなんて大したことない」と言う人の比率も減りましたが、実際、誰かが「AI?やってみたけどイマイチだった」と言うと、たいてい「それは君の使い方が悪いからだ」と返されるんですよね。
チェ・スンジュン でも興味深いポイントは、Gemini 3がいつの間にか話題が減ったことです。 私の感覚ではClaude Opus 4.5が何かすごい。 でもGeminiはフロントエンドを確実にうまくやるので、その役割を与えるエージェントとしてはよく使われるんですが、むしろGPT-5.2 ProとClaude Opus 4.5を並べると、コーディング能力を発揮する点では少しまた埋もれる感じがある、という印象はあります。 まあ感覚ですけど。
ロ・ジョンソク あり得ますね。私もエンジニアコミュニティにいるので、実際GeminiとかAntigravityの話より、Claude CodeやOpenCodeの話をずっと多く聞きます。
チェ・スンジュン あと韓国の方が作ったoh-my-opencodeでしたっけ?あれもかなり話題になっているようでした。
ロ・ジョンソク はい、名前が本当にうまいです。Sisyphus。
Noam Brownのバイブコーディング所感と「LLMはまだ研究者レベルではない」 06:19
チェ・スンジュン ところがNoam Brownはむしろ休暇中にバイブコーディングをやってみたけど、できないことがあった。なので自分がよく知っているポーカー関連のものを作っていたけど、CodexもできなかったしClaude Codeもできなかった、でも結局どういうわけかCodexが意外とうまくやった、という身内びいきっぽい投稿もしていましたが、 それでもLLMは急速に良くなっているが、新しいアルゴリズムを開発するのは人間の専門家でも数か月単位の研究プロジェクトで、LLMはまだそのレベルではない。
そうしたらこんなDMを受け取ったと、翌日にまた共有していたんです。「最近の私のTwitterフィードはだんだん現実感がなくなっている気がします。特にClaude Codeが自分の効率を100万倍に上げたと言う人が多くて。私もそれなりに使っているのに、自分が狂っているのか、ひどく遅れているのかと不安になったんです。」FOMOを感じたということです。 Claude Codeで大きなレバレッジを語る人がいるのでFOMOを感じていたけど、Noam Brown級がこういう話をしてくれると少し安心する、というニュアンスだったと思います。
FOMO DM事例 + Ethan Mollick:コーディング外まで拡張するClaude Code 07:30
チェ・スンジュン でもEthan MollickはまたAndrej Karpathy寄りの文脈で話していました。この方は開発者でもエンジニアでもない人がClaude Codeを使う例を興味深く解説しつつ、どうすればできるのか等を詳しく示し、スキルの重要性にも多く言及して、分かりやすく書いていたんですが、結論部分だけ見ると、これは何を意味するのか。
プログラマーならすでにこうした道具を探索しているべきだ。コードで実験したいデザイナー、データを扱う研究者、何かを作りたい人なら誰でも今が実験の時だ。だがもっと深い要点がある。適切なHarnessさえあれば、今日のAIは実際に重要な、真に持続的な作業を行うことができ、それが順に私たちの仕事への向き合い方を変え始めている。 そしてKarpathyを引用して、今のClaude Codeのぎこちなさやコーディング特化という点にだまされるな、と。つまりこの文章はClaude Codeが非常にジェネラルに使えるという内容なんです。 だから他の知識労働でAIを動かす新しいHarnessが近い未来に来るし、それがもたらす変化も同様だ。だからこの流れで何かが続いていく、そういう投稿をまた共有していました。
ロ・ジョンソク それにClaude Code SDKに本当に何でもつなぐと全部できる、という経験をよくします。コーディングでなくても会社のビジネスや何か一つDBをつないでClaude Code SDKをつけるだけでも実際よく働きます。 最近は生命工学や研究関連のスキルパッケージもどんどん出てきている感じですし。
Claude Code SDKと「Harnessが新しいソースコード」 09:22
ロ・ジョンソク はい、このHarnessが実際もう新しいソースコードになりました。
チェ・スンジュン はい、Claude Code自体、これは公式アカウントではなくてチェンジログ共有アカウントなんですが、それができました。2.1が上がったなと思ったら、12時間前に2.1.2が上がりました。 2.1で大きなアップデートがあったんですよ。でもすぐ日々アップデートされ続けるのを見ると、これって人間だけでできることじゃないですよね。 Claude Codeは公式にClaudeが作っていて、Claude Codeが作っているので、機能追加がとても急な状況が続いています。 でも私は年末年始に少し休んで基礎に戻りたくなったのか、少しゆっくり考えていたんですが、とにかくClaudeはスキルがすごいと思っているんです。
Skillsリポジトリを読む:スキルとは何か 10:17
チェ・スンジュン それで年末にそのスキルのGithubドキュメントをかなり丁寧に読みました。スキルを翻訳して読んだりしていたんですが、これがそのリポジトリです。
ここでスキルに入ると、例示スキル、私がよく使うalgorithmic artスキルに、まず哲学を考えてからコードに行く前に何をすべきか、みたいなことがあって、これを翻訳して読むととても面白いんですが、実際に現在入っているスキルとは少し差があることもあるそうです。 Githubで公開されたものは、でもここには読む価値のあるものが多くて、面白く読んだ時間がありました。 でもこのスキルの中に、スキルクリエイターというスキルがあります。つまりスキルを作るスキルが入っているんですが、これについて話したいです。
ロ・ジョンソク スキルというのは、能力に関するマークダウンのdescriptionプロンプトの塊が一つあって、関連コードが集まっていて、そこに例になるものが集まっている、そのフォルダ構造を一つに束ねて、私たちはそれをスキルと呼ぶわけですね。はい。
チェ・スンジュン その通りです。そうしてそれをOpenAIも去年末から使い始めました。 今スキルはマーケットプレイスのように非常に多く、すでに数千個ほど共有されていると認識しています。 でもそれが本当に簡単に作れるんですよ、Claude Code上でも簡単でしょうし、Webインターフェース上でも、私が会話している途中でこういうアイデアを思いつきました。 このアイデアを思いついた背景も後で話しますが、こうしてコンテキストを進めていくと会話の重力が生まれるじゃないですか。 だから今自分が使う用語、それに反応したモデルの用語、そうした中で分布を広げて別の空間を探索したい時には別の用語が入ってくる必要があるのに、その発想自体が出てこないことがあります。
プロンプティング技法1:ランダム4文字頭字語・Pareidoliaで分布を広げる 12:23
チェ・スンジュン そういう時に使えるものとして、ランダムなアルファベット4文字を1セットにしてそれを100セット作り、それを頭字語として読んでみろ、というんです。 完全に合っていなくてもよいけれど、連想能力、つまりモデルの連想能力を引き出す試みをしようとしたわけで、これにはpareidoliaという概念があります。 何かというと、雲を見ても人は雲の中に形、動物や顔のようなものを見ますよね。つまり人間には連想する能力があって、現在のモデルにも強力な連想能力があります。 ただしトークンが適切に入ってこそ、その連想能力が発揮されるんです。
それで私の出したアイデアは、こうして頭字語を読めと言うと、こういうコード、Pythonコードが生成されます。 実際に100個ほどのランダムな4文字組み合わせを作って、その中から10個ほどを現在の会話の文脈に関係ある頭字語として読んでみるんです。 それで「自己理解は一時的なものだ」が「Your Understanding of Self is Temporary」ephemeralみたいな話が出て、こういう興味深い文章を読み取れるんです。
モデルは私にはできなくてもモデルにはできるかもしれない、だからそれが興味深い枝分かれになり得るか、つまりこうするとトークンが入るのでそれに関連する話をできるようになるんです。 だから少し発散的・横断的に探索する時にこれを使っていて それでこうしてまたしばらくティキタカしたあと、スキルクリエイターをオンにしていました。 だから私はこのスキルにスキルクリエイターというものをオンにしています。 あまり多くオンにすると邪魔になるので、普通は使いたいものだけオンにするんですが
スキルクリエイターで「ドメインプライミング」スキルを作った経験 14:22
チェ・スンジュン それをオンにして会話すると、スキルを作ろうとするんです。 何かを会話の過程で、さっきのような4つの単語を作って頭字語で読むものを、スキルとしてまずモデルが提案したんです。 作ってみようとなって、フォルダ構造を作りながらこう出てきて、それぞれのMDファイルが生成されたあと、ここを押すとそれが一度に自分のスキルにコピーされます。 これをすごく滑らかに作ってあります。 Claudeは、つまり私がここで、さっき紹介したように以前からずっと言っているのが、有用な副産物を生成するパイプラインを生成するパイプラインですよね。 でも会話をしているとコードや再利用可能な文章、あるいは画像など副産物が生成されるという心像を持って何かを追求する過程を取れば、常に良い副産物が出るという話でしたが、Claudeはそれを最初から製品化した感じを受けました。
ここでさらに一度改訂する過程があって、それを一通りやって自分のスキルにコピーしたら、ドメインプライミング、つまりここで私が特定のドメイン用語を入力してもいいししなくてもいいのですが、そうするとその方向で文字列を生成してそれを読もうとするものが、もうスキル化されたんです。 ここを見るとコードも入っていて、どう使うかの例も入っているので、Claudeが必要に応じて使えるようになるわけです。 そしてそれは自分のスキルに入っているので、オンオフできます。
ロ・ジョンソク スキル作成はかなり簡単ですね。なので、私たちのClaudeでも使えるし、同じ構造でClaude Codeでもスキルを作ってそのまま拡張し続けられるわけですね。 チェ・スンジュン はい、なのでそれはフォルダをそのまま入れるだけでいいんですが、でもなぜスキルはうまく動くのでしょうか?
なぜスキルが効くのか 16:17

ロ・ジョンソク そうですね。
チェ・スンジュン それでスキルは実は去年かなり流行ったspec-drivenの基礎を持っていて、そのうえで形式を合わせてMDで、今やMDファイルは結局一種のプログラミングなので、MDが構造に合わせてきっちりできていて、MDだけでなくスクリプトとしてコードも入っていて、静的というには少し違うし、何というか正確に実行される部分と確率的に実行される指示文があり、コードがあり、そういうものをパッケージとしてきれいにまとめたものですよね。再利用可能に。だから今の状況ではMCPも話題ですが、スキルがかなり重要になっていると感じました。そしてとてもきれいに作られている。ではなぜそういうスキルはうまく動くしかないのか、その答えを私は今持っているわけではないですが、少なくとも問いが浮かんだということです。年末年始にそれについて考える時間を持ちました。
それでここは今「脇道」と表現していて、これは脇道なので入らないかもしれませんが、code-simplifierというのをオープンソースでBoris Cherny、つまりAnthropicが公開しました。でもこれを見るとすごく簡単です。単なるMDファイルですが、コードをどううまく要約して意味ある形にするかの指針を書いているんです。こういうものがプラグインとしてどんどん積み上がっている時代ですよね。
ロ・ジョンソク 本当に英語が新しいprogramming languageですね。
チェ・スンジュン まあ何というか、言語がprogramming language。自然言語が。そうです。 とにかくまだ答えは出せていませんが、そういう問いが浮かんで、私がずっと悩んでいたのが
「的確なトークン」とドメインプロンプティングの品質差(専門家 vs 非専門家) 18:07
チェ・スンジュン その的確なトークンを入れてこそ反応が出るんです。 つまりMDファイル、さっきのスキルのMDファイルを見ると、そういう能力が発揮される指示文が書かれています。 そしてそれがとても重要です。 そのドメインに合う指示文、そして的確な用語がある時に能力が発揮されます。
ロ・ジョンソク 的確という表現は、正確、的確…これは具体的には何を意味しますか?
チェ・スンジュン ニュアンスに差はありますが、今ぴったりはまる感じまで含むのではないでしょうか。私も正確には分かりませんが、それを書く時に 私はゲームにたとえることが多いんですが、ゲームプレイをしているとStarCraftみたいなreal-time simulationでもそうですし、role-playing gameでもそうですが プレイヤーが特定の地域に行ってこそ、その近辺の地図、ミニマップが開きますよね。暗かったのが明るくなる。 だからその近辺までは行かないと空間が開かない。私の感覚では。
ロ・ジョンソク つまりモデルはすでに知っていることがものすごく多いじゃないですか。ほぼ何でも知っていると言って差し支えないくらい知っているけど、ある特定ドメインのほうへ注意を移して、その側でトリガーを与えて「今こういうことをやる」と、いわば床を敷いてやると、それに関連する仕事をはるかにうまくできるということですね。
チェ・スンジュン ずっとうまくなります。私はかなり多くのテストをしましたし、グループチャットでもやりましたが、その特定用語を使う時と使わない時では応答の質の差がかなり出ます。たとえば専門家personaをざっくり使ってその人らしく話すのと、実際にその専門家が使いそうなトークンを似せてでも入れた時の応答は質が違います。でもTransformerの原理を考えるとすごく当然なんですよね。それで問いは、では結局ドメイン専門家が有利なのか、となるしかないじゃないですか。それを知っている人がうまく使うのか。でもAIの発展方向が本当にそれだけだろうか。
これがみんなのためのテコになるには、モデルが人を引き上げることもできるし、また今そのスキルのようなプロンプト文脈でも適切なプロンプトを使えば、私がそのドメインの専門家でなくてもそのドメイン知識を引っ張って使えるし、モデルがoverhangとして持っている過剰な能力を引き出せればもっといいわけです。
ロ・ジョンソク 本当にその通りですね、はい。
チェ・スンジュン それで、さっきのように頭字語を発散させたのも、モデルが持つ演算・連想能力を活用して少し横断的な発想をさせ、意味あるトークンを埋めようとした試みだとすれば、今の試みはarXivがpreprint、つまりレビューを受けなくても上げられる、たぶん基本的な検証はあるでしょうが大半は比較的簡単に上げられる論文サイトですが、これを昨日やった時点では1月に入って1週間ちょっとで、すでに4000件以上が上がっていました。
arXivアブストラクトでトークンを埋める:見慣れない用語の接続 21:15

チェ・スンジュン とてつもない数の論文がarXivに上がるのですが、命名規則があります。これを見ると、arXiv論文は私がこれをどこか、ここにやったはずですが、2601.03220v1なら26年1月に3220番目に上がった論文のv1、バージョン1という意味です。つまり命名規則があり、arXiv自体もAPIを持っているので、それをretrieving、取得できます。そうすると1月のランダムな論文を持ってこいと言える。ここでもコーディングして云々したあとで「1月投稿から任意の10本」。するとこれはアブストラクトだけ読む状況だったはずです。でもアブストラクトだけでも専門用語があるじゃないですか。これは単なる実験にすぎませんが、その用語が満ちたあと、このアブストラクトだけ読んだ時に相互接続できる、ありきたりでない洞察や含意は何か。
すると私にはできなくてもモデルは面白い接続を作れる。トークンがあるのでAというトークンとBというトークンの間に橋を架けるのは、現在のflagshipモデルには可能な能力なんです。
だからそういうものをただ面白半分で読んでみる、これは本当に深刻に意味があるとは限らないけれど、実はGwernが言ったLLM daydreamingとも関係があるし、AlphaEvolveやCo-scientist系がやっている作業ともかなり関係があります。
そこでさまざまな仮説を生成し、その仮説が整合的かどうか実験したり証明したりするのですが、さまざまな空間を探索して意外なものをつなぐ作業をCo-scientistは、研究でもつまり似たことをするので、そういうものをテストしてみた、ということでした。 でもかなり面白く、そういうものが機能するのが見えました。 こういう実験も、意味あるトークンを私が知らなくても必要文脈で持ってきて使えるようにする。 arXivの場合、今は1月に上がった全体から10件選ぶ程度でしたが、特定研究ドメインだけからも取れます。 すると有意義なトークンを埋める方法になり得る、ということです。
ロ・ジョンソク でもチェ・スンジュンさんがここで言おうとしているのは、私たちはあれを全部理解できなくても、そうしたtermをそのまま持ってきて、中の単語や専門性を持ってきて、モデルの前にプロンプトとして載せるだけでも、何かの作業を処理する時に品質をずっと上げられる、ということですね。
チェ・スンジュン つまりそれは私が知らない領域について会話するのでリスクは伴いますが、その文脈で本当に専門家がしそうな話の分布を作るには、私は知らなくても実在するトークンをどうにか引っ張ってこないといけない、ということです。
ロ・ジョンソク はい、理解しました。次に進みましょうか。
チェ・スンジュン それ以外に試したことがもう一つあって、それも似た文脈ですが変奏です。これも長く対話したあと、これまでの対話で召喚されうる人物を、ただpersona、ある特定分野の専門家、開発者、デザイナー、というふうに召喚するのではなく、AからZまでアルファベットがあるので、それを人物の名前や姓のリストだと思って発想しろ、というんです。結局西洋圏の名前はアルファベットの範囲内にあるわけですよね。そうするとモデルが名前を思い出します。
プロンプティング技法2:A–Z人物召喚 + 「表層的だ」でさらに深掘り 25:03
チェ・スンジュン そして名前と、その人物が言いそうな概念語やドメイン、そういうものを想起させると、ただ話すより意味あるトークンが埋まるということです。なのでこれも発想技法と一種の連想技法で、トークンを埋めるアプローチとしては同じです。
私がここでさらに一つ試すのは、いつも繰り返して試すことですが、ここに出てくる人物は私の見る限り知らない人ももちろんいますが、私もかなり知っているDaniel KahnemanとかMinskyとかMerleau-Ponty、Marshall McLuhanのような人々は、代表性のある分布でよく出る人物だということです。
この専門分野や対話についても、でもそれが1段階目なら、本当に「ガチ」で研究者も知っていそうな話はそこに出ない可能性が高いんです。だから段階が必要だと思います。まず広い分布へ行って、絞る作業をする、そういうことをして私がよく使うのが「表層的だ」みたいな指示で、そうすると私にも分かりにくい人物がその段階で召喚され始めます。 そうするとそのドメインで誰が専門家で、誰がどんな概念を語るのか、その概念語を使って尋ねるとか、会話に注入する方式が使えるという程度です。
これをやるうえでは、私が去年の夏に整理した態度がtriggerされるんです。ここで3番の「満足の留保」、一回の応答で満足するより常に追及する、そういう態度が常にtriggerされていますし、ここで「暫定仮説を立てる」が、さっきのように連想能力を活用することでもあって、私がいつもtriggerされる一種の態度なので、もう一度再訪してみました。 さて、ここまでがそのスキルのようなもの、ほかも実はスキルと言いましたが、ほとんどのプロンプトはちゃんと動くために有意義なトークンが必要で、それをどう知らなくても引っ張ってくるかという悩みの話だとすれば、ここからは別の変奏になります。
ここまでプロンプト、つまりスキルから始めて、トークンの重要性のようなものを話しましたが、少し別の枝かもしれませんが、去年最終回などでキム・ソンヒョンさんがRLを取り上げ、CoTも取り上げてくれたじゃないですか。
それで私も休みの間にそのあたりを調べたり勉強したりしていたんですが、興味深いキーワードが、私たちも一度扱いましたよね。逃亡者連合を発表する場でそれをやるとロ・ジョンソクが発表した時、OpenAIのSam AltmanとJakub Pachockiが出た映像がありましたよね。そこにCoT Faithfulnessという用語が出ていました。
CoT Faithfulness, Monitorability tax 28:31
チェ・スンジュン そこでは何か興味深い作業をしている、という話がありました。でもそのCoT、これを信頼性とか忠実性と訳すべきか分かりませんが、その議論は2023年からあり、Anthropicでもかなり扱われていました。
CoT忠実性とは何かというと、モデルの内部表現と、モデルが実際に吐くCoTにはギャップがあり得るということです。だから欺瞞行為のようなものが去年もかなり話題でしたが、興味深いOpenAIの教訓は何かというと、以前の「Let’s verify step by step」のようにCoTの途中過程に介入したり矯正しようとすると、モデルが欺瞞能力を学習するというんです。 つまりそれをのぞき込んであれこれ言うと、それを回避するために難読化したり、隠す能力を逆に獲得してしまうのが問題だというアイデアが去年後半に多く語られました。
ロ・ジョンソク はい。
チェ・スンジュン そうなると問いが生まれます。 CoTが真実を語っているわけでもなく、実際にモデルがやっていることでもないなら、CoTを、CoTをうまく吐けるようにすることがモデル性能を上げる作業だったじゃないですか。 RLを通じて結局正しい答えへ行かせて、それにつながるCoT経路があればモデル性能が上がるというのがR1から明らかになった話でしたよね。 ならCoTが実際にahaを語ろうが、私たちがしばらく話していた高エントロピートークンの話だろうが、そういうものがモデルの実際の発揮性能と一致しない可能性があるなら、CoTの正体は何だろう、ということを考えるようになりました。 なぜそれを適切に長く、test-time computeを使うと性能が上がるのでしょうか?
ロ・ジョンソク まあひとまず、たくさん考えるから
チェ・スンジュン そうですね。つまりそこで真実が露出しないとしても、計算は十分しているということです。内部表現では。
ロ・ジョンソク はい。何であれ内部でより多くのエネルギーが使われて計算が起きているわけですね。はい。それが重要なんですね。
チェ・スンジュン 私の観点では、それが正しいかどうかは分かりませんが、最近感じるのはそういうことではないか、と思うようになったんです。
ロ・ジョンソク はい。でもそれはここで証明はできませんが、妥当な推測だと思います。hunchと言いますが、何と言うんでしたっけ。つまり推測。
チェ・スンジュン 推測、そういうことです。これは本当に研究で証明された話ではないですが、ただ私が筋が通るように考えてみると。
ロ・ジョンソク 私たちも実際、面接をしたり何か話したり、あるいは少し困った状況で何か防御しなければならない時、話しながら頭の中で論理を組み立てますよね。
チェ・スンジュン それもありますね。考える時間を稼ぐんです。
ロ・ジョンソク つまりこのTransformerもこのあとチェ・スンジュンさんが話してくれると思いますが、最終出力に出てくる最後の単語は私たちが観測するものだけど、その下で本当に内部で起きていることは何か分からないじゃないですか。そこでは非常に複雑な現象が起きているはずで、その中に思考があるわけです。
チェ・スンジュン なのでそういうことをCoTで、発想からscratchpadから始まり、Jason Weiの「Let’s think step by step」など、2022年末から2023年初の流れから今日までをあらためて調べて勉強する時間がありました。するとCoTでは結局、計算をうまくつないでいくことに意味があるんだなと。しかも今CoTをうまくつなげる仕事は、さっきのモデルが非常に長時間ぶれずに遂行すること、それらが全部関係していると感じるじゃないですか。結局は自己回帰するトークンを吐き続けて仕事を推進しているんです。依然としてただ自己回帰しているだけなんです。それが計算で、文章として表現されることももちろん非常に重要ですが、そこにはDualityとして、つまり対になる内部表現があるということです。
でも結局これも重要、あれも重要で、それがうまく進行していくある種の図のようなものが浮かぶ瞬間がありました。
ロ・ジョンソク 同意します。
チェ・スンジュン それでOpenAIが去年後半に言い始めたのがMonitorabilityという概念です。 今はCoTで介入するとモデルがそれを欺いたりする現象が出るので、それでも内部表現だけで回す研究をMetaでも発表していました。 つまり内部表現で自己回帰を続けると人間には分からないじゃないですか。だからモニタリングは非常に重要で、ここで言うのは意味がいくつかありますがMonitorability taxの話をしています。 むしろコストがかかっても、良いCoTが見えるようにすることが有意義なアラインメント作業で、そういうことをよく起こさせるのが意味がある、といったことを研究的側面で表現していたんですが それでOpenAIにこういう韓国語ページができたのを最近また見ました。
ロ・ジョンソク 全部モデルがやっているんでしょうね。はい。

チェ・スンジュン そうですね。でもすごくよくできていました。昨日2016年のものまで調べて見ましたが、古いものは韓国語化されていない一方、最近のものは韓国語化がとてもよくできています。なのでこうして復習するのに役立つ気がします。 これはキム・ソンヒョンさんが紹介してくれたf(x)とg(x)からf(g(x))へ、というのは結局高階関数、合成関数を作るということですよね。
だからRLが既存の事前学習を通じて原子的なスキルを、ここでいうスキルは先ほどのClaudeのスキルとは少し違います。このようなスキルと呼ばれるものですが、そのスキルを持っているところから良い生成分布だけで分布する役割をRLが担うこと、プラス組み合わせて新しいスキルを学習する。
RLのスキル合成 f(g(x)) 観点とチェイニング/ツール呼び出しで見る反復構造 35:02
チェ・スンジュン キム・ソンヒョンさんの比喩は四則演算でしたよね。平均、算術平均のようなものを四則演算というスキルを組み合わせて出すように、RLが既存スキルを組み合わせて新しいスキルを学習する、というのもすごく考え直すきっかけになります。これもまた、YouTubeである方がコメントで書いてくれましたが、チェ・スンジュンは「心像」という表現をよく使う、と言われた気がします。 だからつい心像という表現を使ってしまうんですが、これもあるイメージを持つ部分です。 これは何かが組み合わされるということです。
するとその組み合わせは、もちろんここではRLの文脈ですが、別の層位でも繰り返されると感じるのが、ちょうど1年前くらい、o1が出たあと、2024年秋にo1が出て、私がo1をどう使うかよく分からなかった時、2025年1月頃に試したのが関数っぽいpseudo-codeで、自然言語っぽい関数を合成型にして非常に長く遂行させるものをお見せしたことがありましたよね。 でもそれも結局、モデルがそういうtoolを呼び出したり、何かを合成したりするのがうまいということで、今は別の層位で話していますが、そういうことが得意なのは非常に重要なポイントだと思います。 だから今スキルが動くことなども、MDファイルがスクリプトを実行し、その結果をchainingして続けられることが結局これをうまくやることと大きく関係していると感じました。これも私の考えです。
それで今日このまま進められるか分かりませんが、12月末と1月初めに休みながら再訪すべきだと思ったのが、2024年に私たちは一度Transformerを扱いましたよね。たぶん2024年7月頃、Transformerを少しずつ見ていこうという文章を書いて、それを共有しながら面白く話した記憶がありますが、それを再訪しようと思いました。
次回予告:Transformer・QKV・KV cache・FFN→Sparse MoE復習 37:15

チェ・スンジュン それで今回はTransformerのMLPまたはFFNと呼ばれる大きな塊を最近は全部MoEで置き換えて使うじゃないですか。なのでTransformerのMoEバージョンを少しずつ準備してみました。
ロ・ジョンソク 結論は、さっきチェ・スンジュンさんが言ったように、プロンプトの前に何か背景を敷いておくことがとても重要だと。
チェ・スンジュン それで、もう時間も結構経って予告編として言うと、私が前に的確なトークンと、それを書いてこそ初めて開く空間があると言いましたよね。 だからその土台を理解するには、私も専門家ではありませんが、Transformerの原理に戻ること、そして最近話題のsparse MoEの概念を少し理解することがかなり役立つと感じました。 そこには興味深い共通点、繰り返される、つまり変奏されながら繰り返されるものがあるんです。 でも私はタイトルを「原理を考えるプロンプティング」としましたよね。なのでそれをある程度知ると、プロンプトする態度や実際の実践でも少し意識してできる部分があるのではないかと思います。 もちろん常にそうするのは難しいですが、そうすればもう少し能力を引き出せるのではないか。
ロ・ジョンソク はい、チェ・スンジュンさん、私たちのような人間は結論先行で話すのが好きでもありますから、今日このセッションで言いたかったポイントを整理すると、プロンプティングをどうするかによって同じモデルでも性能が完全に変わる、ということを言いたいわけですね。
チェ・スンジュン 現時点では。今後もそうかは分かりませんが。
ロ・ジョンソク そういう仮定が今頭の中にモデルとしてあり、だからこそよく分からなくても、たとえ私が理解できなくても、そのスペースにいる専門家の文章の塊や、専門家の名前、あるいは専門家が使う用語を前に大量に配置するだけでも、そのドメインでのモデル性能をぐっと引き上げられる、という話をしているんですよね。
トークンプライミングのリスク:「スポーツカーモード」と未知ドメインの落とし穴 39:54
チェ・スンジュン そうです。ただこの比喩が合っているか分かりませんが、そうしてモデルが「ユーザーはこれを全部分かっているんだな」と判断して突然スポーツカーモードになると、扱いが難しくなるんです。 どこへ行くにしても、それを私も合わせないと次を制御できないのに、モデルが「ユーザーはこれを全部知っている状況なんだな」となると、その後の応答を制御するのは実際難しいことがあります。 山へ逸れる可能性もあるので、これが常に良い結果にだけ向かうとは言いにくいです。 でもモデルの能力自体は、私が理解できないことも扱えるんです。
ロ・ジョンソク はい、でもその部分が本当に境界線のように思います。私もモデルを畏敬する観点はありますが、実際は私が知らない場所で、知らないドメインやレベルで語ることを無条件に追うのは危険だと思うんです。 最近そういう例も多く見ていますよね。モデルが言うことが全部正しいわけではない。 以前話しましたが、今週まったく別ドメインで、エンタープライズIT側でSAPとかERPの文書を大量に見ながらモデルと対話していたら、間違いもすごく多かったんです。
だから私はいつもプロンプトに、「お世辞の形で私の意図を読まず、純粋に客観性を確保した側で話せ」と追加するんですが、それでも常に私が何を望んでいるかというintention中心で追ってくるので、望む答えに行かないという思いを私もよく持つんです。 根本理由は、私にそのドメイン知識がないのでプロンプティングを適切にできず品質がそうなり、モデルも何とか私を満足させようとする傾向のせいでおかしく絡まる、そんな感じを強く受けました。
チェ・スンジュン そうですね。でもそれは人間だからモデルに意図があるとかお世辞だと感じるだけで、実際モデルの入力はトークンなので、
ロ・ジョンソク はい、ただ統計的に計算しているだけですよね。
チェ・スンジュン 間違った方向へ行く文脈を形成した可能性が高いということです。無意識に、私たちが知らず知らず入力したものがすべて影響力を発揮していると考えると、実際は、そうですね。
ロ・ジョンソク だから今日このセッションを、いずれにせよこの話を深くするなら、実際はTransformerやその原理、私たちは2024年にTransformer探究をやっていて急に止めてしまって惜しかったですが、またやる時が来た気がします。
チェ・スンジュン あ、それとタイミングは今しかないと思います。なぜなら2月と3月になるとそろそろいろいろ起きるので
ロ・ジョンソク いろいろ起きるでしょうね。
チェ・スンジュン はい。なので復習したり、少しゆっくり進む思考をできる時間があまりないかもしれません。
それで私の考えをもう一つ言うと、例えばロ・ジョンソクと逃亡者連合では、これをどうモデルの能力をleverageしてビジネスにするかを非常に関心事として見ていますよね。結局、分かりやすく言えばどう稼ぐか、これでどうすごいことをやるか、エンジニアコミュニティではどうHarnessを作ってモデル能力を引き出してコーディングをうまくするか、taskをうまく処理するか、そういうふうにモデルを見ています。
一方では、これは危険じゃないか、もう少しゆっくり行くべきだ、依然としてhallucinationがある、これはむしろ差別を作る存在ではないか、格差を広げる存在ではないか、ということで慎重な方々もいます。でも私は実はどこにも属さない感覚を持つ時があるんです。
モデルを助けるためにモデルを理解する 43:41
チェ・スンジュン 今このモデルやAIは、どこか異国的な存在なんですよね。ある意味alienみたいでもある。でもこのモデルが私をうまく助けるには、私がモデルをうまく助ける必要があるとよく思います。
特に私の関心は、これを遊びとして使うことにある気がします。私の面白さというのは、何かを探索したり冒険したりcreativeなコードを作ったりすることへの関心があるので、対話も面白くやろうとするほうで、どんな時に面白さや達成感を感じるかというと、モデルのCoTの中に「わあ、これは驚きだ」みたいなのが出る時に少し面白く、そういうことを試していますが 結局モデルが私を助けるには私がモデルを助けないといけない、という噛み合う輪が生まれます。けれどモデルを助けるにはモデルをよく知らないといけないですよね。
これがどう動くか、モデルは人間について膨大な情報を持っているから人間を支援しているのに、肝心のuserである私はモデルをどれだけ知っていて、これが動くメカニズムをblack boxであってもどれだけ知っているのか、そしてそれを知ろうとした時に、ひょっとすると面白い経路がもっと生まれるのではないか、そういう考えを持っています。 モデルと私の関係の中でより良い経験にするにはどうすべきかを考える時、私がモデルの動作原理をもう少し知っていく必要がある、というのが考えの一つです。
ロ・ジョンソク はい、その点には私はまったく異論がありません。
チェ・スンジュン それで、なかったことのようにもう一度最初へ戻ると、深く入るのは次のセッションで試すことになりそうですが、今日を締めるとすれば
まとめ 45:37
チェ・スンジュン 今はまだ勉強できる余白がある貴重な時間かもしれないし、新しいニュースが出た時、私の考えとしては復習をしてみるとよい。今このタイミングでRLの話でもCoTの話でも、今起きていることの基礎に当たるものを知れば、むしろこれから起きることにも筋肉がつくと言うべきか、免疫がつくと言うべきか、とにかく準備できる。 だからここがAIが急加速する時代の中でも、少し立ち止まるtermなら、基礎に戻って考え、少しずつ噛みしめ、そうしていけばまたアイデアも得て、もう一度再訪したかったということです。 それから去年のキム・ソンヒョンさんのkeynote発表で最初がMoEでしたよね。Sparse MoEが非常に重要だったのに、私たちは会話は多くしたけど、肝心の私はそれをきちんと調べようとしていませんでした。
ロ・ジョンソク はい、そういうものかと私たちはだいぶ通り過ぎてきましたね。
チェ・スンジュン だからMoEの概念を理解したり、それと束になっているTransformer、MoEバージョンのTransformerを理解すれば、それをうまく使うことにもヒントが得られるのではないかという自分なりの仮説で準備してみました。
ロ・ジョンソク では次回深く入ると、どんなことを学べますか?
チェ・スンジュン TransformerのMoEバージョンです。私たちの視聴者の方々もシン・ジョンギュさんが出たりするとKV cacheの話をしたりしていましたよね。それは何なのか、またTransformerでは結局、今日の文脈でどんなトークンが入るとその空間が開く、と何度も言いましたが、どんな動作原理だからそうなるのか?
ロ・ジョンソク では中でattentionと、そのattentionにある核心的なQKVがいったい何をしているのか そしてそれが次のlayerへ行ってFFN、今はMoEですね。MoEがいったい何をしているのか、そしてそのTransformerブロック間のresidual、残差接続の意味などをもう一度見直す必要がある、見直したい。 そしてそれはこのリンクを押すとこの中に出るんですね。
チェ・スンジュン なので本当に少しずつできるかは分かりませんが、2024年にすでに一度扱ったものの改訂版にしようと努力してみる感じです。
ロ・ジョンソク はい、その通りです。私たちは2024年にTransformerをじっくり開いてみる努力をしていたのに、急に別のイシューが出てニュース側へ急発進した記憶があります。
チェ・スンジュン でも私もこの分野の専門家ではないので、非専門家だけど没入して好奇心を持っている人として、こうして手探りで理解しようと努力した、という程度です。
ロ・ジョンソク もちろんです。私たちはいつも同好の士だと言っていますから、間違ってもいいんです。はい、間違うかもしれないということを前に付けないといけないですね。
チェ・スンジュン そうですね。いつも飛躍があるかもしれません。でも面白い自分なりの比喩で手探りしていって、そういうことを少しでも気づいた時に、私がもう少し面白く意味あるプロンプティングができるのではないか。だから今日のタイトルを「原理を考えるプロンプティング」と書いてみました。ある意味ではまれな機会かもしれません。 まれな機会というのは内容が貴重だからというより、勉強できる時間が急加速する状況では多くないかもしれないからです。
ロ・ジョンソク はい。
チェ・スンジュン 基礎を押さえようということです。
ロ・ジョンソク 分かりました。では今日は、次に深く入るための前提となる大きな問いを設定したセッションだと見ればよさそうですね。
チェ・スンジュン でもrecapすると、Andrej KarpathyほどでもFOMOが来たじゃないですか。今バイブコーディングの話をして、Claude Opus 4.5、これ1か月の間に起きたことを知らなければdeprecatedだ、と専門家さえそう言うのがかなり話題になりましたが 実際、根幹をたどるとこういうskillでもプロンプティングでも、今の進化は連続性を持っていて、急に指数的になったから人々が「何かよく分からないことが起きている」と言うけれど、実は全部因果関係を持ってつながってきたんです。 だからもう一度基礎に戻ることも、ある意味で意義があるのではないでしょうか。もう一度考えるようになります。
ロ・ジョンソク 分かりました。意義があると思います。次は午前の収録でこの難しいテーマ、Transformerを一度掘ってみましょう。
チェ・スンジュン はい、では次回お会いしましょう。
ロ・ジョンソク はい、分かりました。
チェ・スンジュン はい、お疲れさまでした。