EP 90
AlphaGo 以後、10年 (feat. HyperAccel CTO イ・ジンウォン)
イントロとゲスト紹介(HyperAccel イ・ジンウォン CTO) 0:00
ロ・ジョンソク さて、収録している今日は2026年3月14日です。パイの日の土曜の朝です。
今日はAlphaGoの10周年に関する話をしてみようと思います。驚くべきことに、AlphaGoが私たちに衝撃を与えてからもう10年が経ちました。なので、その10年を一度振り返ってみようと思います。スンジュンさんとご一緒に、新しいゲストをお一人お招きしました。
HyperAccelのイ・ジンウォンCTOを、本日お招きしています。ようこそ。こんにちは。
イ・ジンウォン お招きいただきありがとうございます。イ・ジンウォンCTOは、
ロ・ジョンソク 最近ではドクパモ(韓国の独自基盤モデル構築事業)の審査員としても活動されていましたし、私たちのディープラーニング初期に非常に多くの貢献をしてくださった方です。PR 12、PR Twelveと読めばいいのでしょうか。私たちの論文読み会がとても長く続いていたのですが、私も本当にたくさん助けられました。イ・ジンウォンCTO、今取り組まれている事業についても簡単にご紹介ください。
HyperAccelの紹介: 推論専用AI半導体とサービス価格の問題 0:59
イ・ジンウォン こんにちは。私はHyperAccelでCTOを務めているイ・ジンウォンと申します。弊社の紹介を簡単にすると、弊社HyperAccelは推論専用のAI半導体を作っている会社です。
これに関する記事も少し前に出たのですが、私たちがAIサービスを使っていると価格がとても高いですよね。いろいろな理由がありますが、HBMのような高価なメモリ、高価なプロセスなどを使うことで、一般の人が使うにはまだ少し負担になるそういう価格でしかサービスを使えない状況です。もっと多くの人に、もっと質の高いサービスを提供できるそんな半導体を私たちで作ってみよう。そこで私たちはHBMを使わず、LPDDRという低消費電力メモリを使って、10分の1の価格でサーバーを供給し、今使われている最も安いサービスでも月に約3,200円は払わないといけないですよね。それを540円以下くらいまで下げてみよう、そういう大きな目標を持って一生懸命チップを開発しています。
ロ・ジョンソク 正しい方向性だと思います。こういう内容を2017年に、その頃今日もそういう話をたくさんすることになりそうですが、
PR 12論文読み会とコミュニティの力 2:05
イ・ジンウォン その頃はコミュニティの役割がとても大きかったです。今も小さいとは言えませんが、当時はコミュニティの力が大きくて、韓国のディープラーニングの発展のために私も他の方々の助けを本当にたくさん受けたので、その時、今Upstage代表のキム・ソンフン代表と何人かの方がTensorFlow Koreaという集まりで志を同じくして、論文がものすごくたくさん出てきて、当時は新しいアルゴリズムがあまりにも多く出てきたので、人々もどの論文を見ればいいのか分からず、一度読むのにも時間がかかりすぎました。それを私たちが少し助けよう、という趣旨で2017年当時、Zoomで毎週二人ずつ交代しながら論文をレビューし、それを今このポッドキャストのようにそのまま録画してYouTubeに上げることを始め、現在も続いています。楽しくうまくやってきましたし、私は今は少し休んでいますが、少し休んだあとにまた戻って引き続き参加する予定です。では、そういうことが起きたのはある時期には振り返ることが重要だと思って
チェ・スンジュン AlphaGoの影響があったと見ていいのでしょうか。人々が衝撃を受けたあとに勉強したのですか。もちろんです。その時から韓国でブームがかなり起きたと思います。
イ・ジンウォン 私もその前、2014年ごろから一人であれこれ勉強したり試したりしていたのですが、その時はかなり苦労が多かったんです。資料もあまりなくて、海外でもそれほど多くはなかった気がします。
でも2016年にAlphaGoの出来事があって以降、韓国では特に非常に大きなブームが起きて、人々の関心も高まり、そうしたコミュニティも活性化して、そういう流れを通じてこれも始めることになったのだと思います。最近AlphaGo 10周年を迎えて、
AlphaGo 10周年公式ポスティングとNoam Brownの洞察 3:50

チェ・スンジュン Demis HassabisやGoogle DeepMindのほうから公式な投稿がありましたが、今、「ゲームから生物学、そしてその先へ:AlphaGoが残した10年の影響」という投稿が一つあり、それから去年、私たちがエピソードで一つ取り上げたあのGoogle DeepMindポッドキャストを、その年の最後の回として少しご紹介しましたよね。ところが今年最初の内容も、去年の最後の回がDemis Hassabisとのインタビューだったのですが、AlphaGo 10周年に関するポッドキャストで始めていたんです。その二つの内容が良かったので、少し持ってきました。
本文の内容は詳しく説明するより、参考にしていただくのがよさそうですが、これに関連してNoam Brownがこういう投稿をしていました。翻訳されたものでは、今日の最前線の推論モデルを可能にした中核的な方式は、驚くほどAlphaGoと似ている。膨大な量の人間データを模倣し、より良い推論のために推論時点で計算量を増やし、当時はMonte Carlo Tree Searchでしたが、今日ではChain of Thoughtだ。強化学習を使って単純な模倣を超える。これは非常によく似た方式ですが、Demis Hassabisがまたコメントを付けていた気がします。とにかくNoam Brownがこの話をしたあと、
Demis Hassabisが付けたコメントは何かというと、AlphaZeroの方向へ進むことには非常に注意が必要だ。私たちがそのスイッチを入れるかどうか、そういうことは少し考えてみる必要がある、という話をしていて、それが含意しているのは、結局は自己増強するシステムですよね。なので今日はそういう話もすることになりそうです。
もしかして、この二つの投稿や動画についてご覧になったり、コメントしたい部分はありますか。どこを重要に見るとよいでしょうか。私はAlphaZeroでできるのかについて
イ・ジンウォン かなり考えてみた気がしますが、実際に少し調べてみると、そういう動きはあるんですよね。AlphaZeroへ向かう方向は、人間データなしでやることですよね。今、大規模な事前学習作業なしで強化学習だけでできるのか、今現在やっていること以上のことをです。でも実際にそちらの動きがかなりあるようなのでとても興味深く見ています。
チェ・スンジュン 結局、このGoogle DeepMindのポッドキャストで話していたことやブログに投稿していたことも、今この方向性が科学やイノベーションへどう自然につながっていくのかというその軌跡を少したどってくれている気がします。あともう一つ興味深いことがあったのですが、37手がビルの名前になっていたんですよ。
37手とPlatform 37: 対局の瞬間が象徴になる 6:13

チェ・スンジュン AlphaGoのあの驚くべき手だと。人間であるイ・セドル九段の驚くべき手は何手でしたっけ。78手でしたね。78手で、AlphaGoは37手なんですが、その37手の名前にちなんであのGoogle DeepMindの新社屋ができるみたいです。夏から入居するそうです。
イ・ジンウォン これは第2局でしたよね。
ロ・ジョンソク 第2局の37手だと思います。たぶんみんな、あの解説者たちが「え、なぜそこに打ったんだ」と言いながら、人間なら絶対に打てない手だったのに、後になって
イ・ジンウォン ミスをしたみたいだ、という話もかなりありました。2016年、10年前を振り返ってみると
2016年AlphaGo対局の現場の話 6:54
ロ・ジョンソク TensorFlowが出て、ちょうどいろいろやっていた時期が2015年くらいだったんです。TensorFlowは出てはいたものの世の中はそれが何なのかまったく分かっていない時で、その頃は人々が、ディープラーニングとは何か、NVIDIAのキーノートを見ながらsoftmaxがどうこう、その次にMNIST、そのあとMNISTが終わるとCNNみたいなものをいちばん基礎的なものから回してみていた、そんな時期だったのでAIという表現はあまり使っていませんでした。その頃は機械学習、ディープラーニングという表現をよく使っていましたが、それに対する期待もそこまで高くなかった時期でした。でも実際、2016年にAlphaGoが現れて、
AlphaGoが始まる時、私もその会場にいたんですがその前に前夜祭というんですか。ガラショーの時に行ってみるとEric Schmidtと有名な人たちがみんな集まっていてイ・セドルとEric Schmidtと超VIPたちがいちばん中央の前のテーブルに座っていて有名な人たちはみんな後ろに座っていたんですがその時点ではイ・セドルも自信満々でした。人間が勝つ、と。はい、でも逆に私は、いや、Googleであれだけスターたちがみんな来るほどなら彼らは何か確信を持って来たのであってただ来たわけではないだろうと思ってAlphaGoが圧倒的に勝つと私は賭けていてその時しきりに賭けをしていた記憶があります。でも第1局が終わった時には実際、みんな衝撃に包まれましたよね。圧倒的でした。
チェ・スンジュン お二人ともライブで全部ご覧になったんですよね。
イ・ジンウォン はい、見ました。見ました。私も囲碁を全部理解しているわけではないので
ロ・ジョンソク その一手の深さみたいなものは理解できていませんでしたがあの人たち、解説してくれる解説者たちの嘆きや驚きや挫折感を見ながらああ、これはとんでもないことなんだなと思いました。もう一つすごく面白かったのは、その時YouTubeを含めて
イ・ジンウォン さまざまなチャンネルで、いわゆるプロ棋士たちが解説をしていたんですが意見がかなり分かれていたんです。一手一手が出るたびに、それを見るのも面白かった記憶があります。
チェ・スンジュン 当時は政策ネットワークがどうだ価値ネットワークがどうだという用語を私はよく分かっていなかったので、これは何の話なんだろうとブログを見たりもしていましたね。思い出します。
ロ・ジョンソク AlphaGoの対局が終わったあと、たいていの教授や有名な方たちがみんな、それがどう作られたのか解説者になって、発表資料やYouTubeの録画がものすごくたくさん出てきた記憶があります。ある意味、韓国はその恩恵を少し受けたとも言えるのではないでしょうか。
チェ・スンジュン かなり早い段階で強く打たれて、当事者性を持って見るようになったわけですが、これはたぶんDemis Hassabisが対局のあとKAISTで行った講演動画です。それでここでDQNのようなものを見せて実際それがどんな文脈にあるのかといったことを押さえていた話みたいなこともしてくれてそういうものを少し実感を持って見られた2016年の経験だった気がします。
ロ・ジョンソク 14年、15年、16年、この頃だと実際DQNだけを取ってみてもとてつもない先端技術でしたしそれにOpenAI GymでRLっぽいものを少しずつ試していた、そんな時期だった気がします。私もその時の所感みたいなものを
チェ・スンジュン ソーシャルメディアに感情を込めて書いた記憶があります。それで今日は少し歴史を、10年を振り返る話をする前に最近これが関係あると私は感じたんですがAutoresearchが熱いですよね。Andrej Karpathyが去年はvibe codingでコーディングのミームを先取りしたのに、今年はAutoresearchで何というかこう、しっかりつかんだ感じですが、どうご覧になりましたか。
Andrej KarpathyのAutoresearchと検証可能なシグナルの反復 10:24
ロ・ジョンソク これはRalph loopと何が違うんですか。Ralph loopですよね。でも機能する
チェ・スンジュン まさにそのドメイン、その領域で評価可能なvalidation、それだけをやったんです。テストまでではなく、ただvalidationスコアだけを持ってそれを下げられる方向にあらゆるアイデアを出して実験して実験して、ずっとそれを続けられるようにするそんな感じでした。
ロ・ジョンソク コンセプトとしてはRLVRと実際かなり似ていますよね。ただレイヤーが違うんです。RLVRは学習過程で、そのverifiableな、検証可能なシグナルさえ与えられればそのドメインで学習を続けられるという話をしたわけでこれはそれを実際の応用プロセスに持ち込んだ、そうですよね。研究のようなものも結局は、非常に優れたモデルに対して報酬シグナル、良くなる方向について何らかの目標設定ができるなら自律的にそのモデルがその目標に向かって進んでいけるということを示したんです。報酬シグナルがRLでの報酬シグナルではなくて
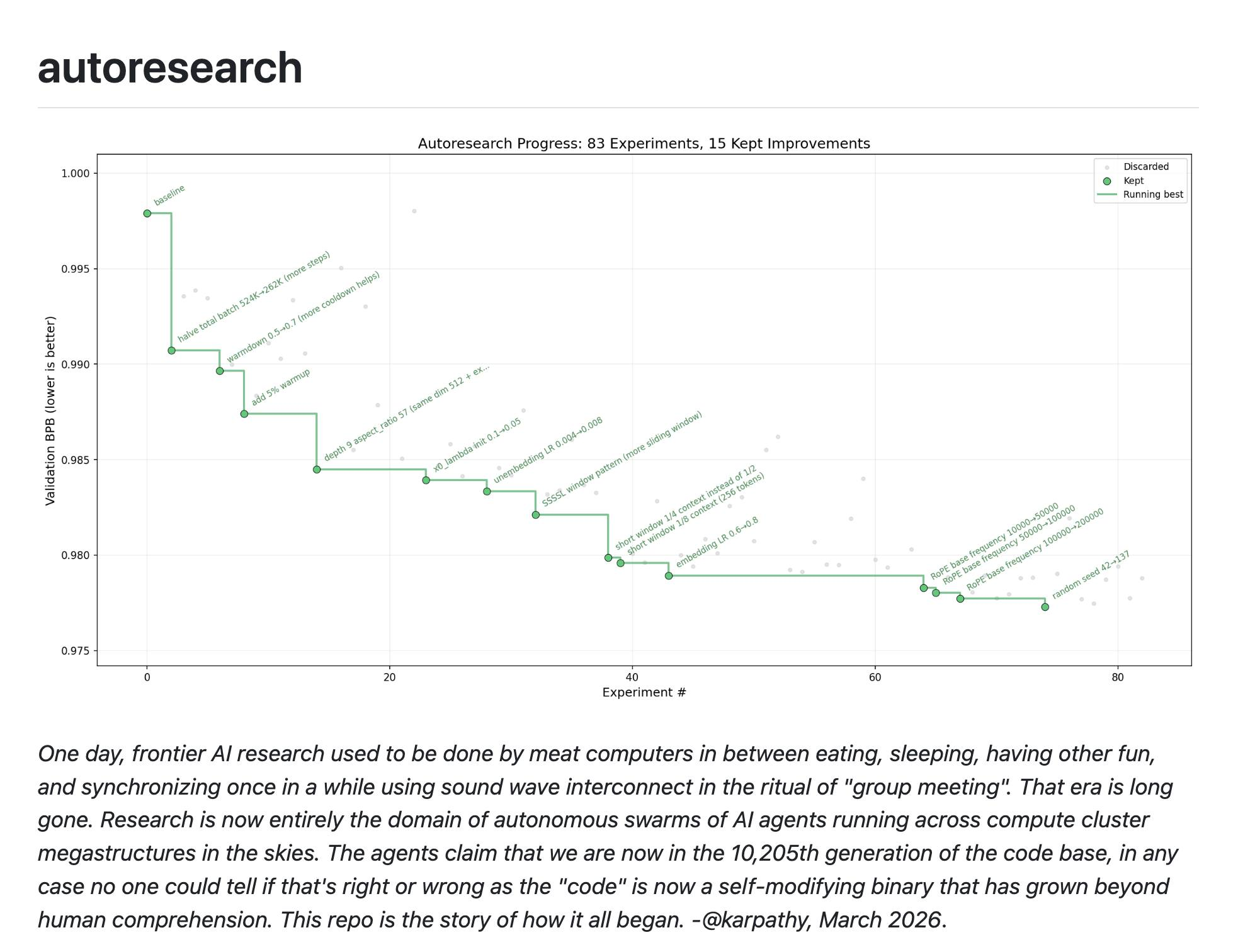
チェ・スンジュン 微分可能ではないのに、ただできるかできないかだけを判定してくれたんですがすごく簡単な数個のファイル、prepare.py、これはあまり重要ではなくてtrain.py、program.md こういうのがあればその条件を達成するものを、達成できるまで下げていく方向でリサーチをするんですが、MDファイルはそれほど長くもないんです。最後のところに面白いことがあるんですが、never stop. 止まらずにもし詰まったら、アイデアが詰まったらペーパーを読んできてこの仮説を立てて実験してみてあの仮説も実験してみて、私にこれで進めるか聞き続けるのではなくとにかく続けろ、というのが最後のメッセージのようですがそれを実際に成果として見せているものがここにグラフで見えています。そういう話なんですが、ここでその Andrej Karpathy と
Yuchen Jin という方が最近、この方もCEOだったけれど今は別のことをやろうとして退いた方のようですがこんなアイデアまで話していました。これは今、一つのスクワッドを回したりただエージェント一つがずっとこう深く入っていく感じだとすればそういう研究者たちのソーシャルメディアをMoltbookのようにしたらどうかそんな話までしているソーシャルメディアの投稿をかなり面白く見ました。派生作業があるんですが
これはその TinyStories をどう最適化するか、また TinyStories もデータが小さいセットできれいに精製されていてそれを下げることでこの人が学んだことです。その次に、これは Sparse Autoencoder といって機械論的解釈可能性研究で使うものをうまくできるようにすることをAutoresearch 方式でやることです。そしてこれは Simon Willison が事例を共有してくれたのですがShopify の CEO、この Tobias という方が自分が以前作っていたあるものを53%速くするということにAutoresearch を応用してやり遂げた。つまり、動く領域ではこれは全部できるということです。できないものももちろんあるでしょうができない領域のほうがはるかに多いでしょうが
動く領域ではシンプルでエレガントにこれをトークンをきちんと使って実行できるそういう経路が見つかりつつあります。でも、そのうまく動く領域というのが偶然にも AI を訓練するあれなんですよね。はい、目標を明確にしたことが
ロ・ジョンソク evaluation metric を明確に定義できさえすればベンチマークが存在するなら、そこは必ずできます。
チェ・スンジュン そうです。去年ジョンソクさんが、それを verifiable にさえ変えれば多くのことが解決できそうだ、という話もされていましたよね。
ロ・ジョンソク そうですね。最近流行っているフレームワークもみんな似た方向性のようです。まず結果が出るまで無条件でフックをかけて永遠に反復させる Ralph loop を基本搭載してRalph loop が成功するためにはその前後をうまく制御してやればいいんです。出発するときに非常に明瞭でクリーンなコンテキストで始めるそのプランを作ってやること、そして明確に、これができれば成功だというその evaluation metric を定義してやることです。だから基本的には全部 Ralph loop で無限反復という点は同じですがその前後をどう精緻化するかという方向に最近このコミュニティは発展しているようです。それで私も効果があったのが、
チェ・スンジュン 私が3月に解けなくて解けなくて今でも100%解いたわけではありませんが成功したケースが結局、私がこれを、これを埋めるのができなかったものを全部モデリングするコードを書いてモデリングを直接やって私が一種の ground truth を提供してこれと似たように達成するまで回したらアルゴリズムが出てきたんです。
ロ・ジョンソク できるまでひたすら回し続けたんですね。これは前に進むだけではなくて
チェ・スンジュン 後ろに戻って仮説を立ててまた進んでみて、だめなら後ろに戻ってまた仮説を立ててそれができるアルゴリズムを見つけていく過程を興味深く見ることができました。得た教訓は、ああ、正確なフィードバックと正確なデータを与えるのが非常に重要なんだなと。
私があれこれアルゴリズムを自分で考案したりモデルが考案するように導く方法も動く部分はあるでしょうがただ end to end でもできるんだな、そういう考えを少し持つようになりました。一昨日グボンさんが
Ralphthon: 計画と評価ハーネス設計の重要性 16:05
ロ・ジョンソク Ralphthon というものをやっていました。OpenAI と一緒に Ralphthon を開催したのですが、それが非常に面白いのは、その計画を一度立てたらその後12時間は手を入れられないんです。ただ RL loop だけで回らなければならないのですが偶然にもそれで1位、2位になった方々がみんなハーネスの設計者なんです。1位になった方はその Ouroboros というハーネスを作った方が1位になって、2位は
チェ・スンジュン 回し続けるわけですね。
ロ・ジョンソク Oh-My-Codex を作ったホ・イェチャンさんが2位だったようですが、そのロジックを見ると全部原則があるんです。無限、できるまで無限反復というのはその通りですがどうやって計画を精緻に立てるか、そしてこの結果をどう evaluate するか、こういう部分のハーネスを精緻に組んだ方々がこれらをより成功させていた、というのが学びでした。グボンさんがご自身で得られた学びを整理しておいたスライドがあって私がそれを読んだのですが、とても正しい方向だと思えて今話した Autoresearch やこれも、文脈はみんな似ているようだと思っています。覚えていますか。似たようなことを去年の10月ごろに
チェ・スンジュン OpenAI で話していたことを。
ロ・ジョンソク そのとき Sam Altman と Chief Scientist のJakub Pachocki の二人が出てきて、去年の10月に発表しましたね。OpenAI のビジョンを発表しながら、26年8月になれば AI リサーチそのころです。AI リサーチインターンが完成してそれから2年後にAI リサーチ PhD が完成するという話としてこう曖昧に遠回しに話していましたがAI リサーチインターンになるという話はAutoresearch 的なことができるようになる、という話をしたんです。
チェ・スンジュン それで今 Andrej Karpathy もTwitter やブログのようなところに書いていたことが結局これはビッグテックがやっている、争っている領域になるだろう。自己増強する、そういう話をしていたので、自分もそういうアイデアを持っていてかなりシンプルで単純にやったんですがそれがちょっとバイラルしている2026年3月の現在って感じですね。
ロ・ジョンソク そうですね。みんな冗談交じりにそう言うじゃないですか。僕たちもグループチャットでその話をしているんですが、うちの何かのサービスとかそういうのがグループチャットに上がると「あれは1クリック awayだ」あるいは「あれは2クリック away、3クリック awayだ」みたいな感じで冗談半分に話したりすることがあるんですが、そんな2026年3月を過ごしています。では、過去に一度行ってみましょうか。
「昔はね」 - AI 10年回顧の始まり 18:44
ロ・ジョンソク 僕たちの「昔はさ」で入ってみましょうか。

チェ・スンジュン こうやって僕たちが掛け合いで話していくと自分自身の話にもなり得ますしどんな流れがあったのかということなんですが、僕が認識していたものの中でもすぐ思い出せるものだけをいくつか選んでみました。2011年ごろには、これをタイムラインで見ていたんですよ。これがPeter Norvigの、Google今もいらっしゃる、Googleにまだいるのかはちょっとあやふやですがとにかく最もシニアなサイエンティストでした。Peter NorvigとXをやっていた方ですよね。Google XのSebastian Thrun。後にUdacityを作った方が一緒にAI講義をスタンフォードで開いていて、Andrew Ngが機械学習の講義を開いていて、そのあとデータベースの講義ももう一つあったそうです。それについてタイムラインをざっと見てみるとこんな話が出ていました。それでスタンフォードでMOOC、現代的なMOOCの先駆けとなるそういう実験をしていてそれが全部AI、ML、データベースという形でこれくらいの人数が集まったそうです。
でもここにDaphne Kollerという名前があるんですが、Daphne KollerはCourseraをAndrew Ngと共同創業して、この方がinsitroをやっていた方です。生命科学とつながりのある方で、そういうことがあってそこで人々が、僕も含めて他の方々も同じだと思いますが
ディープラーニングを、ジンウォンさんはディープラーニングをどう始めましたか。僕はかなり、これはある意味では
Deep Learning入門期: ImageNetとSamsung ElectronicsのNPU開発 20:22
イ・ジンウォン このポッドキャストとも似ていると言えるんですが始まりは、僕が仕事をしていて何かルーティンなものから抜け出して何か世界を変えられるようなものはないかを好奇心で探してみたんだと思います。でもそのとき、僕が2014年にImageNetでGoogleが1位になった、みたいなのを見てそのときから少し関心を持って、ディープラーニングって何だろうとそのころから調べるようになりました。でも以前からみんなが話すようにディープラーニング、AIあるいは機械学習には
暗黒期と呼ばれる時代があったわけですよね。なのでディープラーニングというのは、ある意味ではリブランディングされた名前なんですが、ニューラルネットとかそういう話をするとみんなが嫌がっていたその状況を突破するためにディープラーニングという言葉を使って、「これは何だろう」と見てみたら結局それと文脈を同じくするものだったしその代わりスケールが大きくなって、僕たちがこのポッドキャストでも前に何度も話していたBitter Lessonに出てくる結局は人間のinductive biasを減らしてスケールを大きくする形でAIが発展していきImageNetという、当時としてはImageNetという、まさに僕たちが解くべきベンチマークがあったんです。みんながそれに挑戦していた時代だったじゃないですか。なのでそのころから見ていました。
でも自然とそういうものが出てくる中で僕がいた、当時の僕はサムスン電子でスマートフォンに入る半導体を開発していたんですがそこでもNPUというものを作ることになってそれを作るようになってからそういうことをもっと考えるようになった気がします。僕が以前作っていた半導体にはどんなものがあったかというと、例えば動画コーデックみたいなものです。そういうものの特徴は何かというと、標準仕様が決まっているんですよ。人が集まって仕様を決めると、何をすべきか、この半導体が何をすべきかはすでに決まっていてそれをどう効率よくうまく回すか、これをうまく作るのが良い半導体の条件だったとすればNPUというAI半導体は何をすべきかということ自体がずっと変わるんです。アルゴリズムに新しいものが次々に出てきてものすごい速さで進化していくしそのとき僕は、良い半導体を作るうえでAIアルゴリズムをよく理解していなければ良い半導体を作るなんてあり得ないことだ、と思ったんです。それでそのころから論文もたくさん見るようになったし
さっき前でお話しされていたPR 12というのもそういう形で始めることになったんだと思います。僕も論文をたくさん見ているので一緒に見る人たちと意見も交わして共有できたらいいな、そうしながら勉強もして論文も読んで
そうやって始めたんです。2014年ごろに始めたんですね。
そうやって僕が始めたのは勉強でした。そして、これを覚えていらっしゃるかわかりませんが要点を見るならこの図ですよね。
YouTube猫認識実験と創発現象 23:00

チェ・スンジュン YouTubeで猫を認識し始めた、あれでしたよね。これが実験としてどう設計されていたのかは正確には出ていないんですが、この図を見て
ロ・ジョンソク 僕がイ・サンホ博士と一緒に大騒ぎしながらいろいろ話していた記憶があるんですがこれがYouTubeを、その当時だけでも1000台くらいのクラスタに載せてCNN構造に近いものを載せてただunsupervisedでYouTubeクリップをずっと全部流したらある特定のレイヤーのどこかに猫の顔を認識するフィルタができた、という図が何枚かあったんです。
それで、ああ、知能というのは特別なことをしなくても学習によっていわゆる創発し得る、emergeし得ることを示す例でした。僕もあまりに昔のことで、どういう実験設計だったのかはよく思い出せなくて。たしか僕の記憶では
イ・ジンウォン あのautoencoderの形でやっていたと思います。この画像を入れて、それをまた復元する形で。そうしていくと、これはまさに典型的な僕たちがLLMでよく話していた創発現象ですよね。
たった今おっしゃったように。驚きましたよ。みんなが。これは誰が見ても猫でしたから。その時は、そういう、驚きはしましたが
チェ・スンジュン 私はただ、そういうものか、当然できると思っていたんですがまだできていなかったの?という感じもあったんですよ。私もただニュースとして流していましたし
ロ・ジョンソク あの頃はディープラーニング、ImageNet こういうものよりIBMが作ったあれがありましたよね。クイズ番組に出て話題になっていた、Jeopardyに出ていたIBMのWatson。Watsonのパイプラインが流行して研究されていた頃でした。しばらくはまた音声認識のようなものが当時はニューラルネットワークではなくあのHMM、Hidden Markov Modelで作られていた時期だったので。学習すると、そういうもののほうが先に実現していた時期だった気がします。私も実は2014年くらいになるまではああ、そういうのがあるんだな、不思議だなと思っていただけで機械学習が何かは知っていましたがディープラーニングを本格的に勉強してみようと思ったのは14年くらいからだったんです。私もAndrew Ngの講義や
チェ・スンジュン Peter Norvigの講義があることは知っていて動画や資料を何度か見ましたがそれを掘り下げようとは思っていなかったんですよ。
Andrej Karpathyの資料とImageNet全盛期: CS231n、DeepDream、Chris Olah 25:21
チェ・スンジュン そうしていたらタイムラインでバイラルになっていたのがこのAndrej KarpathyのHacker’s guide to Neural Networksという文書がかなり話題になっていたと思います。
ご覧になった記憶、ありませんか。
backpropはどうやるのか、computation graphはどうなっているのか、これ、思ったよりそんなに難しくないですよと言いながらJavaScriptでこれを説明する、そういう内容だったんですよ。これがいつ、誰と一緒に
ロ・ジョンソク どこで何の仕事をしていたかというのが本当に重要なのはこれが人生のタイミングだからでKarpathyはそのImageNet、話題のまさに中心だったImageNetをやっていたFei-Fei Li教授の博士課程の学生でしたよね。
チェ・スンジュン それでここにPhD student Stanfordと書いてあってConvNetJSを作った。ConvNetJSが当然Fei-Fei Liの作業と関係した流れですからそういうことをして、Karpathyがそういうものをまた広めて共有するのをすごく好む性向だったんですよね。あの頃のベンチマークは今のAIMEとか
ロ・ジョンソク あるいはHumanity’s Last Examのようなベンチマークではなく当時いちばん流行っていたベンチマークはImageNetのスコアでしたよね。top-5 accuracyでしたが、その時はちょうどVGG。
チェ・スンジュン それでこういうのを作って共有したりしていたんですよ。Webでこういうことができる。私も思い出すのはそのVGG、VGGが2014年に2位、
イ・ジンウォン classificationで2位だったんですがそれでもGoogLeNetよりずっと多く使われていたんですよ。当時は。なぜならVGGはとてもシンプルなアーキテクチャで、convolutionも3x3 convolutionだけをずっと積み重ねてできるということを示して、だからこれがシンプルなのでいろいろなところに応用できそうだということでみんながたくさん試していたんですが。私もその時思い出すのは家にあるGPU、
当時それのメモリが2GBだったんですよ。2GBのGPUを挿しておいて、それで学習してみようとして。でもbatchが、正確には覚えていないんですがbatchが2くらいまでしか入らなかった気がします。それでもそれくらいはやってみようと思ってひたすら回していた記憶があります。あの頃は何をしても本当に不思議な時でした。
ロ・ジョンソク 2014年にVGG、いやGoogLeNetだったかが優勝して2015年にResNetが優勝して、そうだった記憶があります。それでそういう、当時はビジョン関連のものがすごく熱かったですね。
チェ・スンジュン それでCS231nの元のタイトルがDeep Learning for Computer Visionだったんですよ。だからここでも錚々たる人物たちが後になってまた出てくることにもなりましたし。
イ・ジンウォン そこで講義をしていた方々がたくさんスターになりましたよね、実際。
ロ・ジョンソク あのJustin Johnsonはそうです。有名な人ですよね。
チェ・スンジュン 今はFei-Fei LiとWorld Labsをやっていますよね。そうです。ミシガン大学の教授になって
ロ・ジョンソク またFei-Fei Liと起業したようです。
チェ・スンジュン Jian Fanもいます。Jian Fanもここ出身ですし。それからこの頃流行っていたのが
ロ・ジョンソク style transferというものでこうやってゴッホ風の絵に写真を変えてくれたり。
イ・ジンウォン neural styleと呼ばれていたもの。
neural styleと呼ばれていたもの。そうです、neural style。Justin JohnsonがLuaで整ったTorch implementationを作って私もたくさん回した記憶があります。
チェ・スンジュン そしてそういうビジョン関連のものにおいて、それがなぜ動くのかという手がかりになったのは結局Chris OlahそしてAlexander Mordvintsevら、Mike Tyka、そうした方々が取り組んでいたそのDeepDreamと呼ばれる作業なんですがこれはアートの分野でもかなり話題になりましたが結局はfeatureの増幅じゃないですか。これがある種の解釈可能性研究の端緒になる作業としても今では系譜を語ることができますがそういう話がChris Olahを中心に進められていた
そのDistill.pubに軌跡がかなりよく残っています。だからOlahはこういうもの、すごくここ、タイトルを見ると人々を見るとDavid HaもいるしOlahもいるんですよ。それでこれはRNNを使って手書き予測をしたりするもの。主にビジョンの話が序盤は多かったんですがここにはRNNの話があって。そしてChris Olahが
Jeff Deanがちょうどその、Olahが幼い頃に「この人を連れてこないといけない」と言ったという逸話もあるんですが2014年頃にKarpathyがそういうものをたくさん共有していた時もOlahはもっと若かったのにこういう作業を共有してYann LeCunからコメントをもらったりしていたんです。
今でもそのブログがとてもよく残っていて、そこもなかなか面白いです。
ロ・ジョンソク この時ちょうど始めた人たちが4〜5年ほど経って実際メインストリームになりました。そして2014年が、2014年15年だけ見ても私たちはみんな画像とstyle transfer、CNN、こういう話、ImageNetみたいな話をしていた頃でしたがIlya Sutskeverがsequence to sequenceの論文を出したのが14年なんです。でもRNNを私たちが持ってひたすら不思議なものを学習してチャットボットを作って遊び始めたのは、15年ほどたってから2016年、17年くらいになった頃だった気がします。
チェ・スンジュン Ilya Sutskeverのsequence to sequenceの共同著者がOriol Vinyalsでしたっけ、まだDeepMindにいる方。たぶん混同しているかもしれないんですが。そんな感じだった気もします。とにかく、こうした軌跡はChris Olahが結局Anthropicの共同創業者の一人なんですがAnthropicの解釈可能性研究にTransformer Circuitsの投稿などを通してもずっと着実につながっているんです。
イ・ジンウォン でも僕はChris Olahといえば、実は真っ先に思い浮かぶのはRNN関連の図式化された図で、ブログにあるその図を今でも講義で全部持ってきて使っていたんですよ。すごくきれいに描かれていました。
チェ・スンジュン インタラクティブにいろいろ試すこともできましたし。僕は個人的には、TF.jsという、Deeplearn.jsとして出てからTF.jsに変わったこのコードを、AlphaGoが出てからかなり衝撃を受けたんですがそれでも自分がある程度理解できるくらいの実装だったのでこのコードを壁に貼って暗記するみたいに見ていた記憶があります。backpropがどうなっていて、どうすればいいのか。それで当時ちょうど子どもが生まれた頃だったんですが抱っこひもを着けて行ったり来たりしながら、これを見ていた記憶があります。その次が、2016年のロさんのエピソードを話していただけるんじゃないでしょうか。これがGoogle Campus Seoulで、こういうイベントがあったそうなんです。はい、私は行っていませんでした。
Deep Learningフレームワークの変遷: TheanoからPyTorchまで 31:04
ロ・ジョンソク 実はその頃Google CampusにEric Schmidtも来てTensorFlow Koreaの集まりもここでやっていてAlphaGoとともにGoogleがコミュニティの中心に強く立っていた時期でした。なのでJeff Deanもそのとき来ていた記憶がありますが私は行きませんでした。
イ・ジンウォン 僕はここに行ったんですが、実はあまり記憶が残っていないです。人がものすごくたくさん来ていてそのとき覚えているのは、人々がチャットボットにその頃もかなり関心を持っていたんですが、Jeff Deanはそのとき僕の印象ではチャットボットにそこまで関心がなくて、「チャットボットってそんなに難しいのか」ちょっとこんな感じの返答をしていた記憶が残っています。
でもこのとき、実はAlphaGoのその頃より少し前ですよね。3月9日からAlphaGoが始まったのでその直前で、TensorFlowその当時、実は一番多く使われていたのはCaffeというものだったんですがCaffeはどうしても大学で開発されたフレームワークだったのでGoogleが本格的にここに入ってきてやるということでTensorFlowへの関心が非常に非常に高かった時代でした。
ロ・ジョンソク session、feed_dict、そういう用語を思い出します。そうですね。今そういうツールの名前が出たついでに、
チェ・スンジュン Andrew Ngの講義の序盤はOctaveを勉強しておかなければならなかったというか、実習しなければならなかったんですがそれがMATLABの…
ロ・ジョンソク ちょっとオープンソース版。
チェ・スンジュン そうですね、オープン、自由、GNU、つまりGNU版ですね。それでかなり大変な思いをしながら、どうにかこうにかやった感じです。僕も覚えているのは、DeepDreamみたいなものを回そうとするとまだCaffeやTheanoなんかを使わなければならなかったんです。そういうもの、もちろんDeepDreamのTensorFlow実装ももちろん出てはいましたがそこから派生する作業ではこういうことをしなければなりませんでした。今順番を見てみると、Torchが2002年、Theanoが2007年、Caffeが2013年、KerasがTensorFlowより少し先に出ていたんですよ。Keras、TensorFlow、PyTorch、こういう順番で出てきたものを見てみました。
イ・ジンウォン Theanoが実はTensorFlowの前身だと。開発者も多く移っていきましたし。
チェ・スンジュン でもずっと楽になったのはPyTorchが来たときのほうがもっと楽になった、そんな記憶があります。そうですね。実際2016年くらいになると
ロ・ジョンソク TensorFlowが強く使われ、PyTorchも出てきた時期でしたし。
チェ・スンジュン 最近はTensorFlow使われますか。よく分からないですね。
ロ・ジョンソク どうでしょうね。私も私もPyTorchをほとんどやっていないと言うべきでしょうね。
チェ・スンジュン そういえばPyTorchを動かしてみたのも実はかなり前ですね。ここ数年は、はい、たまにGoogle Colabで何かをするとかその程度で、ちゃんとやった記憶はあまりないですね。
ロ・ジョンソク はい、私も2020年くらいが最後な気がします。
チェ・スンジュン それで、この当時また有名だったのがキム・ソンフン代表が香港科技大にいらっしゃった頃でしたよね。それで「みんなのディープラーニング」みたいな講義をされていた頃でこれが2016年初め、これは結局AlphaGoショックの派生だと思います。AlphaGoに人々が衝撃を受けて、これをちゃんと知らなければと思って一緒に勉強する、そんな雰囲気ができてそれがFacebookにTensorFlow Korea Facebookグループが作られてイベントがあって、済州島に行って一緒にワークショップをしたりもしたこと。
イ・ジンウォン 僕はこのTensorFlow Korea、今はAGI Koreaという名前にFacebookで変えたんですがTensorFlow Koreaで僕も運営陣でしたしすごく面白いことがたくさんありました。そしてTensorFlow、これはユーザーグループ、正確にユーザーグループと言うのも違うですがとにかくそういう性格があってユーザーグループだとみなすならこれは世界で一番大きい規模でした。それで実際にGoogleのイベントなんかでも紹介されたりもしていました。始まりはたぶんGoogle Koreaのクォン・スンソさんとキム・ソンフン代表が一緒にやって
チェ・スンジュン 多くの方が一緒に運営委員として参加されていた気がします。生活コーディングのイゴインさんの生活コーディングとTensorFlow Koreaでしたよね。何というかFacebookのタイムラインにいつも見えていたのがそうだった、そのコミュニティがすごくエネルギーがあった時期だった気がします。ところで、僕がまた面白く見ていたのはその頃ちょっと怪しげなブログがあったんです。
David HaとCreative Coding: コミュニティが残した足跡 35:45
チェ・スンジュン こういう感じのブログで、こうやってずっと下まで見ると機械学習でちょっとメディアアートっぽいとも言えるしクリエイティブコーディングっぽい、そういうものをどんどん載せている方がいたんです。
それでこの方、otoroってマグロの大トロのことなんですよ。マグロの大トロスタジオというもの、そのサイトをいろいろ見たりしていたんですがそこを見るとTensorFlowを使っていろいろな創作作業がどんどん上がってくるんです。こういうものもあって、これは視覚的にすごくかっこいいわけではないですが出ているものの中で、私が印象的に見たのは初期の作業の中で、漢字、存在しない漢字を作り出すことが有名なのがちょうどこのあたりなのですがこういうふうに世の中にない漢字を作るそういう作業をしていました。ところでこの人が誰かというと
金融業界にいたのですが、Processingがあるのを知って、出てきてProcessingみたいなものを勉強して、自分の作業をこうやって上げていた人が誰かというと現在はGoogleを経てSakana AIの代表を務めているDavid Haです。David Haのサイトでも面白いものを見て学んだ記憶があります。これに行く前に
イ・ジンウォン 実は私が一つ話してみたいことがあるのですがスンジュンさんといちばん関係がありそうなんですが実はこれ、私がディープラーニングと言っていた頃に今も実は少しそうですが、論文も読んだりしているとこれはすごく流行に左右されるなとかなり思いました。人々が、これうまくいくね、となるとAlphaGoの時は強化学習に人々がものすごく関心を持っていましたしそういうふうに流行がどんどん流れていく中で、実は見方によっては今diffusion generationをやっているものの前に、GANというそれが当時とても流行して論文がほとんどそっちにばかり注がれていた時代があったんです。スンジュンさんもその時、そういうものを使ってみた経験はありますか。そうです、そうです。
GANブームと生成AIの始まり 37:01
チェ・スンジュン GANに関連したものを私がきちんと実装まではできませんでしたが読み込んではいましたし、当時NeurIPSと呼ぶ前にNIPSと呼ばれていた時代には、そういう話がものすごく多かったですよね。
イ・ジンウォン 面白いのが、そのIan GoodfellowのGAN論文を見ると、その居酒屋
チェ・スンジュン 居酒屋、そうですね。ビールを飲みに行ってビールがあまりにもまずくて
イ・ジンウォン そこで研究アイデアを思いつくことになった、そんな逸話があったんです。生成者と評価者のdiscriminatorと
チェ・スンジュン generatorにおいて、あいつらを競わせるそれでまたしばらく。でもそれは結果が本当に不思議なものが多かったです。
ロ・ジョンソク 今から見ると、私たちにとって最初の生成ケースでしたよね。まあ image-to-image translation、text-to-image translationもあってまあ DCGANだの何だのGANで、系列もものすごく多かった気がします。私もその時、ファッション事業をやっていた頃でしたが、それを利用してスタイルを生成したりした記憶があります。それをAIを活用して作ったものを広めた時に
チェ・スンジュン StyleGANみたいなものがまた使われたりしていた記憶があります。Refik Anadolという作家です。
ロ・ジョンソク その時だけ見ても不思議ではあったんですがまだこれ、何かに使えるほどではないというのが全体的な評価でしたね。ただ不思議な時期でした。何かできるのが。Clubhouseの時代には、人々が会えなかったので
Clubhouse時代のWeeklyArxivとTransformerへの転換点 38:52
チェ・スンジュン ただオンラインでAIの話をしたりする部屋がたくさんありました。その後、今は首席になられたハ・ジョンウ博士がWeeklyArxivトークと漫談というのもされていましたよね。Zoomでやっていた記憶があります。私もゲストとして1、2回くらいは参加した、DALL-Eが出ていた時の記憶がありますがこれもまたジンウォンさんと関係がありますよね。はい、これも私が始める時に
イ・ジンウォン 今のハ・ジョンウ首席と一緒にモデレーター、その当時、私たちがClubhouseではいつもモデレーターというのが流行のように用語として使われていたんですが、固定モデレーターとして参加して
この時は週に1回ずつ、その週に出たAI論文とまたAIニュースなどを持ち回りで。
誰でも、そのClubhouseってそういうものでしたよね。誰でも手を挙げて上がってきて話してまた話すことがなければ降りていって。こうやって楽しくやっていた気がします。私たちがこの先、急に18年後へ
ロ・ジョンソク こうしてぱっと飛んでしまいましたが実は2021年にHyperCLOVAが出る前に私たちが必ず一つ押さえないといけないイベントがTransformerですよね。
TransformerとAttentionの起源: Bitter Lessonの観点 40:02
チェ・スンジュン 私たちはそのTransformerはこれまであまりにもたくさん扱ってきたので。そして2016年までだけ見ても
ロ・ジョンソク その時がちょうどattentionが出てきたりしていた頃だった気がします。
チェ・スンジュン attentionももともとは画像のほうで先に始まって、それから移ってきたんですよね。
イ・ジンウォン それがShow, Attend and Tellみたいなペーパーがありました。それで絵を見てそれについての説明を生成する時にどこにattentionするのか、というようなものがありました。もう少し後ですが2017年にImageNetが、2017年が最後の大会だったんですがその時優勝したネットワークが、Squeeze-and-Excitation Networkというものがあったんですがそれも実はCNNでその画像がfeature mapとしてこう積み重なっていくんですがその中でどのfeature mapにattentionするかを学習するものだったんです。実はその時、人々はattentionとは言っていませんでしたが後になって見るとこれが実はattentionだったのか、ということが分かったんです。
実はTransformerというと、私も思い出すことが多いのですがそのTransformer、その論文が”Attention Is All You Need”というタイトルで実はタイトルからして少し関心を引きました。そしてその当時、私がいつも口癖のように言っていた話がこのディープラーニング界の三大勢力はOpenAIとGoogle DeepMindとFacebookだ。FAIRと呼んでいましたね。そんな話を口癖のようによくしていましたがこのTransformerが出てくる頃にConvS2S、convolutional sequence-to-sequenceというペーパーがFacebookから出ていたんです。それでその当時、RNNの最大の欠点は
すべてを sequentially 前からauto-regressiveにやるしかない、つまり今のLLMで言えばプロンプトをparallelに処理するとしてもそれすら前の単語を処理してからでないと次の単語に行けない状況だったのでそういう欠点を克服するためにparallelismを高めるアルゴリズムに、人々は渇望があったのですがGoogleではattentionを、私たちはRNNなしでattentionだけでやるつもりだ。そしてFacebookでは、私たちはconvolutionだけでやるつもりだ。これが少し競争のようなもので、結果的にはTransformerが生き残りましたが。人々が後になってこれを解釈するに
結局、CNNという convolution というのはbiasが入ったものなんですよね。人々が画像でlocalなものを集めてそれにlayerを積み重ねるとその receptive field というものが大きくなってglobally 何か情報を取りまとめろという、これは結局、scaleの面でここにもBitter Lessonが入るんですよね。結局、scaleが大きくなったときにはよりgeneralなモデルであるTransformerのほうが性能がはるかに良くなる。
ロ・ジョンソク Transformer論文を初めて読まれたのは何年ですか。ジンウォンさんは出た瞬間に読まれた気がしますし。
イ・ジンウォン はい、私は出てすぐに。
チェ・スンジュン 私は開いてはみましたが、理解はできませんでした。私も開いてはみましたが理解できず、
ロ・ジョンソク 私がTransformerを実際に理解したのは2020年です。2017年から、私は2017年から2020年までAIをそれほど熱心には見ていなかった時期でした。
チェ・スンジュン 私は2022年初めからTransformerをちゃんと見てみようとしました。これも少し記憶、思い出を呼び起こすと
イ・ジンウォン 実は2017年にこの論文が出たとき、かなり話題にはなりましたが今のようになるとは実際誰も思っていなかったはずです。でもこれが実際に爆発的な成長をもたらした最初のきっかけは、私の感覚では、主観的な感覚ではBERTが出てからだったんですよ。2018年にGoogleからやはりBERTが出て実はGPTはそれよりもう少し先に出ていましたがそのときはGPT-1ですね。GPT-1は性能がそれほど良くなく、BERTというのがこの encoder-decoder 構造の最大の短所はこれが翻訳モデルじゃないですか。Transformerは、では常に正解のペアが必要なわけです。英語をフランス語に翻訳するなら何かしらすでに翻訳されているデータが必要だったのですがBERTはそれなしに、ただencoderだけを持ってきて使うのですが空欄を作ってその空欄を埋める形で学習させたんです。それがものすごい self-supervised learning と呼ばれるものをやりながらものすごく多くのデータをラベリングなしで使えるようになってから爆発的にscaleが大きくなった気がします。なのでこの時点でも、BERTだけを見ても
BERTの登場とGPTデコーダの拡張性: LLMへと続く道 43:14
イ・ジンウォン 人々は、これ大きすぎてどうやって学習させるんだ、お金もたくさんかかるし、クラウドで使おうとすると、そんな話をしていた記憶があります。そしてGPTは完全に逆でdecoder方式が、現在、今のLLMはみんなGPTの形になっていますがこれも当時はかなり競争していたのですが時間が経ってGPTが最終的には勝つことになりましたがそれをまた後になって考えてみるとBERTというのはエンコーダで、GPTはデコーダでその最大の違いはエンコーダは前の単語から後ろの単語にもattentionするんです。すべての入力がすでに与えられていると考えて途中にある穴を埋めるものなので前も後ろも見て判断します。性能が良くて当然ですよね。後ろの単語も見ますから。
GPTは常に自分より前にある単語だけを見て次の単語を予測しなければならないのでデータ量が少ないときは性能が低くならざるを得ませんがその代わりものすごい長所があって、それは何かというと単語が一つずつ追加されると考えたときエンコーダは先頭の単語から計算を全部やり直さなければなりません。でもGPTのようなデコーダは常に自分より前にある単語だけを見るので前に出てきた単語たちのトークンに対する計算をやり直す必要がなくそれが結局、今の key-value 形式になる形で持ってきて今回生成された単語に対する計算だけ新しく追加すればすべてできるという、拡張性において比べものにならない、そういう構造を持っていたわけです。なので結果的にはそうした過程を通じて今のLLMまで来たのだと思います。
ロ・ジョンソク BERT時代を迎えて、そのとき本当に会社がたくさんできました。そのとき、今ジンウォンさんがおっしゃった最大のBERTも1 billionには届いていなかったと思います。
イ・ジンウォン そうでしたね。はい、でもそれでもとてつもなく大きいという話を当時していましたよね。それから面白かったのは
そのBERTがまたセサミストリートのキャラクターでもあったので当時、そのキャラクターの名前で論文名を付けるのが一時流行して、ELMoも出ていましたし韓国ではポロロというタイトルの論文が出ていたと記憶しています。
ロ・ジョンソク はい、私はそのとき、そのBERT系でQnAとかあるいは空欄補完のようなそういうモデルを使って実用的にサービスを作ろうとしていた会社が多かったです。今のチャットボットのようなものの、少し原始的なバージョンです。質問すると答えさせたり、あるいはこれが合っているか間違っているかevaluationさせたり、あるいは品質についてこれはポジティブだ、ネガティブだというそういうclassifierを作ったり。動作はとても良かったです。でも何か完成度の面で最後に行くといつも足りない部分があってそして当時のコストではそれを作るのが非常に高かったしそうなると当時そのBERTを使って何かサービスを作ろうとしていた会社がかなりみな苦労していた、その記憶が少しあります。
チェ・スンジュン 歴史的なパターンである可能性がありますね。
ロ・ジョンソク そうして少しずつみんなの関心もしぼんでいっていや、これAIは不思議ではあるけどだめだ、という印象も支配していた時期でした。そのときまたAIウィンターが来るのではないかとか何とかと言ってその次に、お金も、BERTが始まったときどっと投資していた会社の回収がうまくいかずそういう時期に
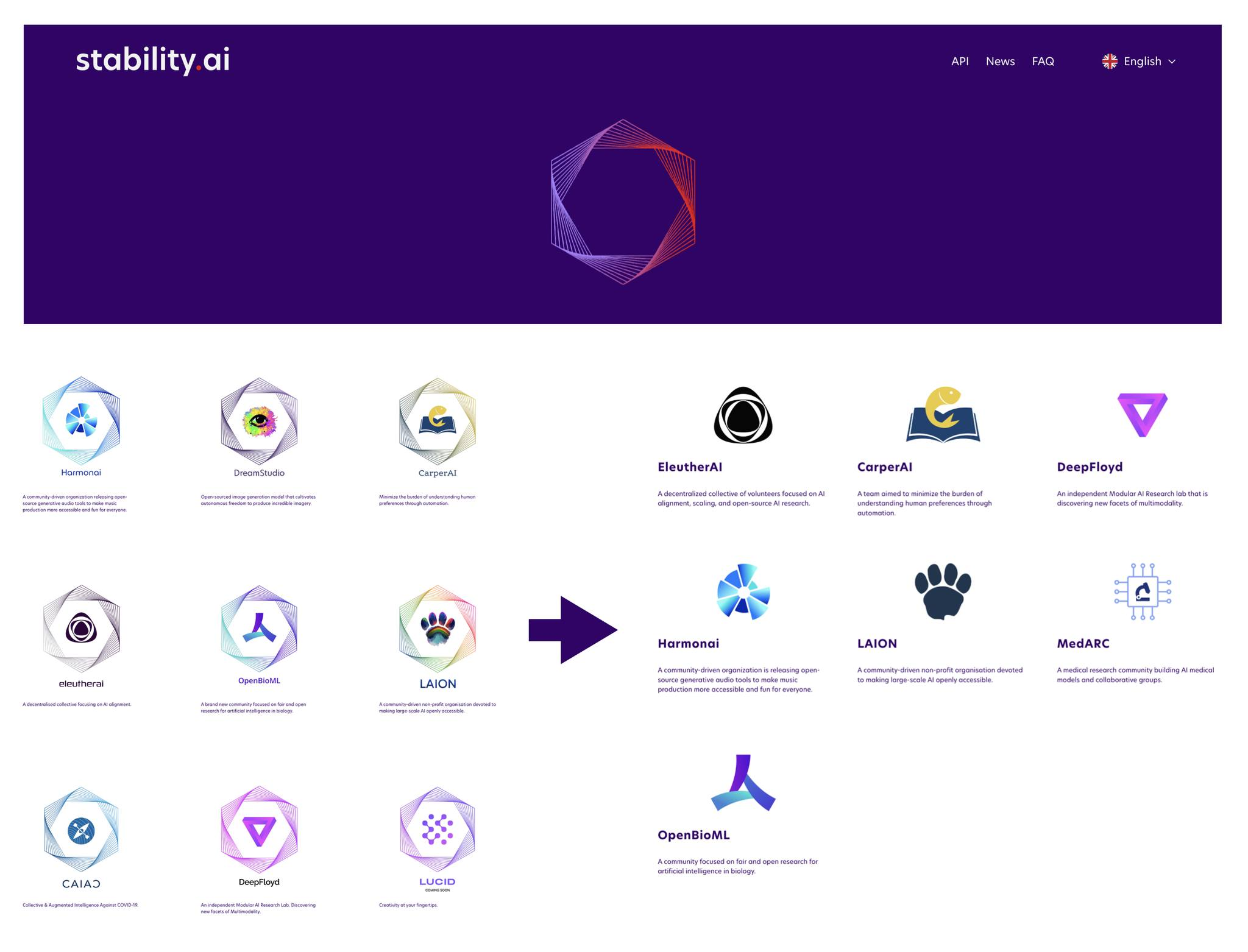
チェ・スンジュン 私、その頃の話をしてみると面白そうですね。22年にはStability AIが熱かったんですよ。Stability AIがStable Diffusionで一気に出てきてStability AIの傘の下にいろいろなコミュニティ、EleutherやLAIONやそういうものがこうして布陣していた時期がありました。でもここが面白かったのは
Stability AIコミュニティと韓国のFoundation Model: HyperCLOVA 47:30
チェ・スンジュン LAIONやEleutherが、最近韓国のケビン・ゴさんという最近Upstageに合流された方がオープンソース活動をしながらこちらのコミュニティにも貢献されながら、何か面白いプロジェクトPolyglotみたいなものを作られていたそんな中で、そしてこうしてなんとなく流れでHyperCLOVAがある日気づいたら私は韓国でもこういうことをやるとは聞いていたんですがお二人のほうがもう少し文脈をご存じなんじゃないですか。
私がここで2021年にHyperCLOVAなどを発表していたNAVERのAI NOW資料は見つけておいたんです。でも2020年に状況判断したわけですよね。GPT-3が出てきたのを見て、大きな投資を一度やるべきだとその頃にそういう状況判断になったんですか。
ロ・ジョンソク そうですね、NAVERが先に少し投資したんです。A100を大量に買った記憶があります。はい、それからHyperCLOVAを出しました。今となっては実はかなり昔のことで、関連するmetricやそういうものは全部忘れてしまったんですが、そのときGPT-3がやはり実用的とまではいかないものの当時の基準ではものすごく不思議で新鮮だったじゃないですか。ついにAIが考えて話して、few-shotで学習して人間のように答えるそういうものが見えてきたわけですから。私は韓国人なんですが独島はどこの国の領土かと聞くと
イ・ジンウォン 韓国の領土だと言い、日本人としてキャラクター設定をするとまた日本の領土だと答える、そういう返答をするのが当時、こんなことが可能なのか?という感覚がすごく多かった気がします。
チェ・スンジュン でもとにかく韓国にはHyperCLOVAがあって私はタイムライン上でその頃ちょうどLLMを勉強してOpenAI Playgroundでやった作業みたいなものをどんどん上げていたら連絡をいただいて社外で使ってみることに初期参加者として少し活動したりもしていました。そんなことがありましたしさっきStability AIの話もしましたし
それでとにかく、私たちもfoundation modelを持たなければならない。
実際、この行間ではカカオ側でもいろいろなことがありましたよね。それでカカオ側でもモデルを作ってTUNiBという会社が出てきたりもしてスピンオフして出てきたりもしてこうLLMを使ってモデルを作ることを韓国でもやらなかったわけではなく、かなりやっていましたよね。しばらく。今、ドクパモに出ている
イ・ジンウォン LG AI研究院でも一生懸命やっていましたし、うまくはいきませんでしたがKTでも一生懸命やっていた記憶があります。影響力がものすごく大きくなって
将来の発展可能性もさらに大きく感じられるようになってくると各国がみな、これは戦略資産になるのではないか、後には軍事兵器のようなものになるのではないかという不安感のようなものもあるわけです。だから私たちが独自に不足している部分があるとしても独自の技術とモデルを持っていることが重要だという趣旨で始めたのだと思います。
Vision Transformerとデータスケールの壁 50:40
イ・ジンウォン 過ぎたことを一つ、急に思い出したので申し上げるとTransformerという流れにおいてさっき前のほうで私たちがずっと話していたように最初はコンピュータビジョンのImageNetを先頭としたそちらの研究のほうが活発で人はやはり見えるものを見るとまた実感することが多いのでコンピュータビジョンのほうに、より活発な研究と成果物があったとするとTransformerを通じて自然言語のほうへ非常に多くの流れが移っていったのですがその当時、ではコンピュータビジョンにもTransformerを使ってみようという動きが、BERTが出てGPT-2、3が出てきたあたりから起こり始めて結局Vision Transformerというものも出てきたのですがやはりこれさえも最初に作ったのはGoogleでした。ほとんど先駆的な技術をGoogleが非常に多く発表するのですが面白いのは、この2017年、さっき6月でしたっけ?Transformerの論文が出たのが。でもVision Transformerの論文は2020年10月に出ます。これはギャップがものすごく大きいんです。でもなぜこんなに遅れたのかというと、人々が試みなかったわけではなく本当に多くの試みをしたのに、結局は全部失敗して私の記憶では、このVision Transformerという論文はICLRに出ていたんですが、そこでopen reviewをするんです。それで著者を隠した状態で論文が公開されるんですがそれが出たとき、これはGoogleのものだとみんな分かっていました。なぜなら結局、vision transformerを
どうやって成功させたのかというと、データを大量に入れたからでした。他に答えはなく、方法は非常にシンプルで、画像を切ってパッチにして、それをTransformerにベクトルとして展開して入れるのですが、ただし、これで性能を出すには既存のCNNより良い性能を出すにはデータを大量に入れなければならず、当時これはsupervised learningで学習していて当時のImageNetデータはだいたい1,400万枚くらいあるんです。全画像が。ところがGoogleには1億件のデータ、JFTというGoogleが公開していない自前のデータがあったのですがそのデータを、それほどの規模のデータを入れると性能が上がっていくグラフを見せたんです。そしてそこにJFTというデータ名が書かれているのを見て人々は、ああこれはGoogleのものだなと分かったんですよね。それでそのときもう一度、スケールの恐ろしさというのがこういうことなんだなと、改めて感じた気がします。
チェ・スンジュン それでここで少し、この局面でも思い出すのがStability AIでも突破口を与えたStable Diffusionが結局、Stable Diffusion自体の技術ではなくもともと今はRunwayに行って、またBlack Forestでしたっけ、とにかくBlack Forest研究所へ分散し。その中核となる2人の研究者、Patrickとか、そういう方々が作ったそのlatent diffusionに関するものをベースにした技術。そういうものに、また韓国の方のドヨプさん、さっきPRもご一緒されていましたよね。
イ・ジンウォン はい、一緒にやりました。はい、そうしているうちにカカオにいて、その後Runwayに行かれて
チェ・スンジュン 今はまた起業しようとしているドヨプさんのことを思い出しますね、私は直接お会いしたことはありませんが、思い出します。またその当時はちょうど、
ロ・ジョンソク このStability AI、Stable Diffusionが出た時期がChatGPT前だったじゃないですか。熱かったですよね。これで画像生成して。
チェ・スンジュン でも今はSeeDance 2.0みたいなものを見ると別の時代のことのように感じられます。
ロ・ジョンソク はい、あの時はどうしてあんなことをしていたんだろうと。
チェ・スンジュン どうして事業をやろうとしたんでしょうか。
ロ・ジョンソク そうですね。はい、私もそれで本当にものすごくパイプラインをたくさん作っていました。はい、今はNano Bananaが全部やってくれることですが。
チェ・スンジュン 私は2022年に、こうしてタイムラインに書いていた文章だけを集めておいたんです。書いていたら多すぎて諦めたこともあったんですが、結局、LLMを使い始めながら始めたことだったんですよ。それを日単位であれこれ試して書いていた記憶があります。私たちの出発点、私たちのポッドキャストの出発点の近くに
ポッドキャスト回顧とMan-Computer Symbiosisの再訪 54:18
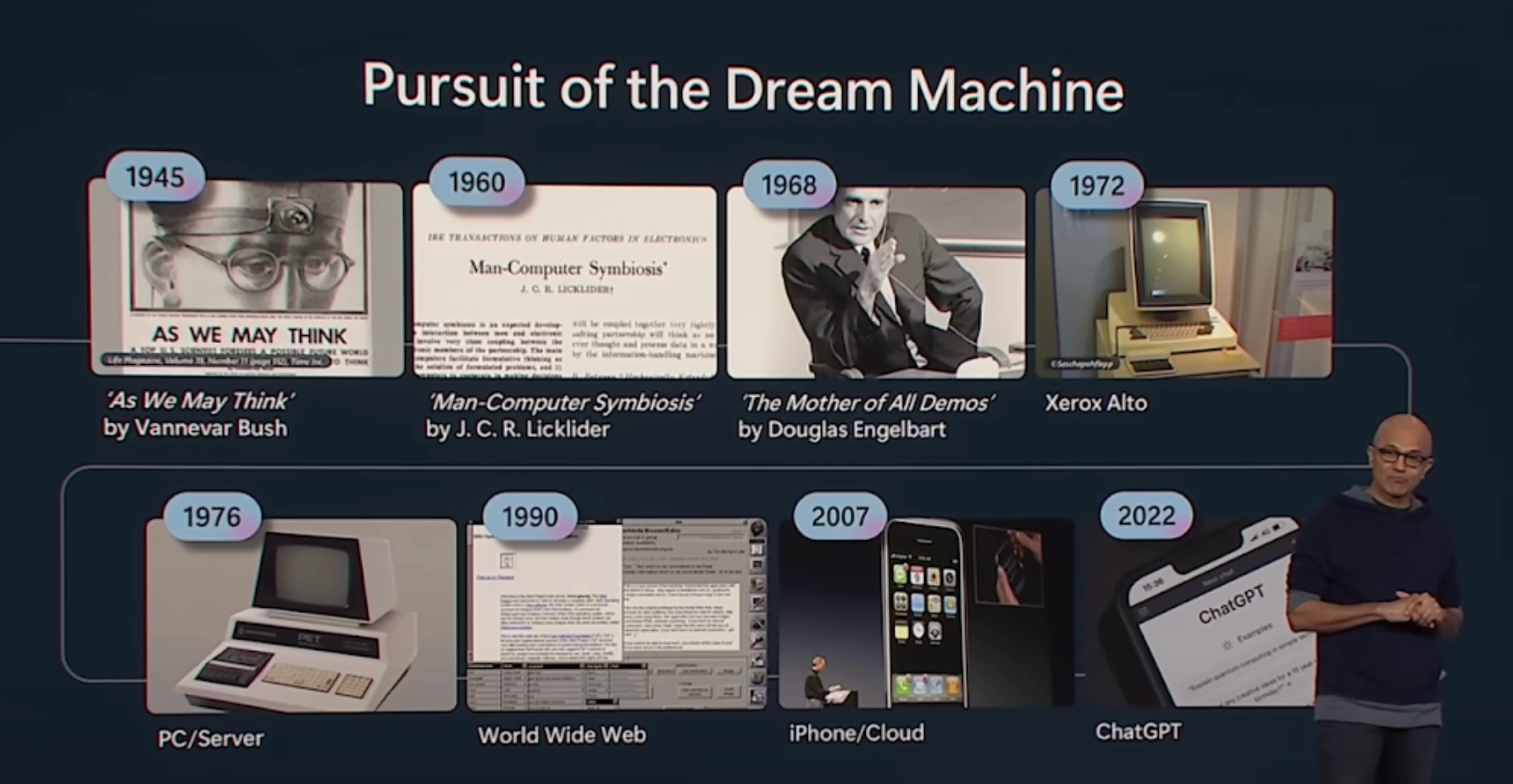
チェ・スンジュン エピソード3が歴史と技術だったんですよね。それでこの時、Satya NadellaがBuild 2023でこれに触れたじゃないですか。1945年のAs We May Thinkから始まって1960年のMan-Computer SymbiosisまでずっとたどってChatGPTまでどうやって来たのかを整理していたのを私たちなりにその意味を読み取ってみようとしたことがあったんですが、
このエピソードが出る頃には、私たちの回数ももう90回近いみたいなんです。いつの間にか3年があっという間に過ぎて、その後に起きたこともとてつもないことじゃないですか。はい、加速していますね。
ロ・ジョンソク ますます加速していますね。
チェ・スンジュン それで私が、1960年にJ. C. R. Lickliderが語っていたこと、Man-Computer Symbiosisの話をもう一度見直してみたんですが、人間とコンピュータの共生というのが何を言っているのかが前にあって、少し進むとこの時期がどういう時期かという、予言のような文章があるんです。なのでこの部分から読んでみます。空軍の将来の研究開発問題を検討した学際的な研究グループは、人工知能の発展によって機械だけで軍事的に意味のある水準の思考や問題解決を実行できるようになる時点を1980年ごろと見ていた。そうだとすれば、人間とコンピュータの共生を開発するのにおよそ5年、そしてそれを活用するのに15年残る計算になる。その15年は10年かもしれないし500年かもしれないが、その時期は人類の歴史上もっとも創造的でわくわくする知的時代になるだろう。私はこの予測は正確に当たったわけではないと思いますが、その方向性においては、これは本当に私たちが超知能が出る前までに経験する時期が創造的でわくわくする時代であるという点には共感しているんです。
ロ・ジョンソク この10年ほどの話をたどってみると、感覚が追いつかないんです。正直、私たちは1週間前に出たものだけで世界が変わる時代をかなり長く生きてきたじゃないですか。
2024年のGPT-4以降の約2年、2年近くは本当に目まぐるしく走ってきて、後になるほどさらに圧縮されていく時代を生きているじゃないですか。そうなると、その速度のレンズを通してさらに前を振り返ると、あまりにも大昔の話のように思えるんです。今生き残っているものも一つもなくて、もちろんそれらが種になってここまで来たわけですが、少し圧倒される感じがありますね。
チェ・スンジュン 2022年以降は、イベントの点があまりにもたくさん打たれました。大きなものだけを拾おうとしても多すぎるんですよね。もう少し時間が経てば整理されると思います。10年くらい経てば、その時に何が本当に核心だったのか、今私たちが今日この10年を振り返りながら今見ると自明に見える大きな出来事が何なのか整理されているように、10年経てばこの時期の点ももっと。
イ・ジンウォン 過ぎてみると、たしかに洞察が深まる気がします。どうなるでしょうか。あの人たちと話していると、3年後に、10年は長すぎる。
加速する変化と未来展望: 検証の難しさ 57:15
ロ・ジョンソク 3年後に何をしているだろうかという話になるとこういう話がよく出るんです。Elon Muskがくれる年金をもらっていそうだと。はい、仕事は全部Optimusがやって、Teslaがこういう労働も全部やって、知的な仕事は全部フロンティアラボやそういうところがやって、だから私たちは年金をもらいながらみんな遊ぶことになるんじゃないかと。
今、ある意味でみんなもそういう夢を見ているんですが、この時期に自分も何かやってみようとみんな一つずつつかんでいるのにこれらが果たして成功するのかということへの懐疑ももうある気がします。どうせうまくいかないからと、できるだけ遅く始めれば遅く始めるほど得だというのもある意味では誰かにとってはプレイブックになっているんです。先に動いてadvantageを作らないといけないのに、そうではなく、先に行って殉教するんです。こちらがうまく作ってあげると、自分より多くのコンピューティング資源と自分より大きなmarket shareを持っているやつがカチッと全部持っていってしまうそんなこともあり得るので。
イ・ジンウォン 似たようなことをよく考えるんですが、今の先駆者たちはこういう方向性を示してくれて、こういうこともできる、こういうのをやると良いという、その可能性を見せると、後ろから大きなものが押し寄せてきて、その市場を全部食ってしまう、そういうことが繰り返されている気がします。
ロ・ジョンソク でも、それでもなお、その重力場を全部抜け出してサービスを作った人たちがいたじゃないですか。昔も、私たちがWeb 2.0やWebをやっていた頃にはこれ、NAVERとDaumが作れば終わりじゃないかというのが基本的な問いだったんですが、その後モバイル時代が来て新しいフォームファクターで新しいdistributionチャネル、当時の新しいdistributionチャネルは結局App Storeでしたよね。韓国の強者ではない、もっと大きな強者が作ってくれるそういう機会によってエコシステムが一度大きく変わった経験があって。
AIは、今の強者たちがまたモバイルの強者たちじゃないですか。Coupang、Toss、Kakao、NAVER、Baemin、こういう仲介者たちもまたみんな地位を固めたのにまたもう一度プラットフォームシフトが来ているじゃないですか。
ChatGPTとGeminiがすべての顧客の情報アクセスをすべて制御する世界が来るのか、来るでしょう。いや、そうはならないだろうというと今は意見が分かれていますが、スンジュンさんが書いてくださったようにタイミングの問題であって、来るべきものはまた来るので、どう準備しているかについても本当に人それぞれ見方が違う気がします。プレイブックに正解はありません。それがいちばん難しい問題だと思います。
イ・ジンウォン 私も幸い、まだ私がやっている領域にはAIがそこまで深く入り込めていない部分があるんです。やはりまた考えてみると、verifiableではあるんですが、検証する過程が時間もかなりかかるうえに難しいので。例えば半導体を作るとしたとき、これが良い半導体なのかを評価するmetricもいくつもあり得ますが、そのmetricを評価する過程自体が長くかかるので、まだデータもやや不足していますし、そういう部分はありますが、私はいつも会社の社員たちと話す機会があると3年後には自分はこの仕事をしていないだろう、という話を口癖のようにするんです。そうすると何をすべきか、何をすればよくてどんなことをやるとよいのかということをいろいろ考えるのですが、いまだに答えを見つけられていません。また考えているうちに、またやるべきこと、
今すぐやるべきことが押し寄せてきて、またその仕事をして、合間ができたらまたそのことを考えて、これをずっと繰り返しています。そういうのって、みんなの人生そのものな気がします。
ロ・ジョンソク 昼は牛を育てて、夕方には勉強して、そんなふうにやるわけですが、さっき少し前にうちの逃亡者連合問題解決班その方々と話しておられるときに
AlphaGo 37手の意味と次回エピソード予告 61:00
ロ・ジョンソク ジンウォンさんとスンジュンさんが後から入ってこられましたが、ある方がその話をされていたんです。「私は失敗しても怖くありません、Claude Codeがありますから。」Claude Codeがあればいつでも再起できるという話をされてみんなで笑ったのを覚えています。とにかく時代を規定する価値生産というものが、
価値生産ということに対する見方が変わっていっている気がします。ソフトウェアが終わるのではなくソフトウェアの時代が本当に大きく開かれるのであって、ソフトウェアを作っていた人の時代が終わったんです。
チェ・スンジュン 技術はあまり心配することはない気がします。人が心配なので。
ロ・ジョンソク そうですね。では適応していかなければならないのではないでしょうか。そうですね。
チェ・スンジュン とにかく、こうしてオープンなタイムラインで見ていたGoogle DeepMindやDemis Hassabisのこういう文章、そして彼らはどう前を見ているのか、そういうところから始めて10年を少し振り返ってみたのですが、結局AIが、このPlatform 37という意味はそれが囲碁に限られたものではなく、そういうことがあちこちで起こる、37手のようなことがあちこちで起こることを目指しているのではないかということを少し考えてみました。直接そう言っていたわけではありませんが、行間を読みました。37手のようなことが、このドメインでもあのドメインでも
起こることをGoogle DeepMindは目指していて、そのうちの一つとして見ているのが生物学であるとか、私たちが表面だけ見ていてまだ扱えていなかった、現在起きている、すでに起きている方向性、そういったものについても少しずつ話していく必要がありますが。それでも私たちが今日あえて10年を振り返ろうとしたのは、
そういう話は絶えず出てくるはずなので、今日を10年を一度振り返る時期として設定してみました。面白かったです。ジンウォンさんがまたこうして、私が知らなかった話をしてくださるのでとてもいいですね。
ロ・ジョンソク そうですね。またジンウォンさんを、今日は急きょゲストとしてお招きしましたが、近いうちに一度お招きして、チップの観点から私たちはいったいこの先をどう見ればいいのか、ギガワットとチップといった話を一度聞くことになっているではありませんか。
イ・ジンウォン はい、私も今日はとても楽しくお話しできたと思いますし、この過程の中で、いわゆるAIインフラですが、半導体を含むそういったものも非常に多くの変化と浮き沈みやchallengeを経験してきましたし、今も経験しているんです。次に適切なタイミングで一度出てきてそういう話を交わせたらいいと思います。そうです。ちょうど今日の朝見たら、
ロ・ジョンソク Dwarkesh Patelとまた話しながらこのチップと100ギガワット時代はどんな姿なのか、そういう話をしていたんですよ。そういう話を中心に、また専門家のジンウォンさんをお招きしてそういう話を一度してみるとよさそうです。はい、楽しみですね。
チェ・スンジュン 今日は面白かったです。今日はこのくらいにして、
ロ・ジョンソク スンジュンさんと私たちもたぶん次は別のテーマに移ってみようかと。ワンクリックアウェイなものの、私たちも大騒ぎモードでずっと行くのはああ、これはあまりにも疲れます。私たちもAI scienceやそういう方向にもう少しweightを移してみようというそんな流れの中にいる、ということをお伝えしたいです。楽しみにしています。ワンクリックについては私も強く感じるのが、
OpenClawイベントと締めの挨拶 64:02
イ・ジンウォン ワンクリックでできることがあまりにも多くなってそれを全部扱うのも大変ですし、全部追いかけるのも大変で、ある意味では少し陳腐になっていくような感じもある気がします。
ロ・ジョンソク この変化の速度にみんな少しずつ適応していっている気がします。これを新しいある速度として受け入れているわけですよね。でも、いつでもhedgingは重要ではないですか。
チェ・スンジュン 今日またSionicでOpenClawのイベントをやるの、またジンウォンさんが行かれるんじゃなかったですか。
イ・ジンウォン はい、これが終わったらすぐ出発する予定です。
チェ・スンジュン どんなことが起きているのかは知っておかないといけませんね。
ロ・ジョンソク でもOpenClawは私は非常に重要だと思うんです。みんなにとって、前回のエピソードでそういう話をしたじゃないですか。みんなが会長の人生を生きるようになる。何をするにしても最強の超強力な秘書陣を従えてどんなに小さなことでもするようになる世界になるのが正しい方向性なら、その超強力な秘書陣をうまく作って消費者にとって最終アシスタントとして、一番末端で、私の目の前ですぐのアシスタントとして選ばれる存在がすべての主導権を握ることになるので、OpenClawにはそこで大きな意味があるとみんな判断したのだと思います。
チェ・スンジュン なるほど。週末もまた楽しく過ごせそうですね。
ロ・ジョンソク はい、行ってまたしっかり聞いてみます。
チェ・スンジュン はい、それでは今日はここまでにします。
ロ・ジョンソク 今日はこのくらいで締めくくりたいと思います。ジンウォンさん、今日はありがとうございました。
イ・ジンウォン はい、お招きいただきありがとうございました。とても楽しかったです。