EP 96
LLM推論インフラとトークン経済学
連休中に勉強したDwarkeshの新エピソード 0:00
ロ・ジョンソク 収録している今日は2026年5月4日、月曜日の朝です。私たちは今回の連休の間にDwarkeshの新しいエピソードを勉強したんですが。Dwarkeshがフォーマットを変えたんです。急に黒板を持ってきて、板書しながら教えてくれるそういう形のフォーマットを新しくやったんですが。その内容が非常に良かったです。今の時点で私たちが
チェ・スンジュン 4月30日でしたよね。そうです。私たちが3日ほどこれを勉強したんですが、
ロ・ジョンソク これまではいつもtrainingがどうだ、それからモデルサイズがどうだ、という話ばかりしていましたが実際には私たちのClaude Codeもそうですし、Codexもそうですしinferenceの重要性がはるかに大きくなっているじゃないですか。そうですよね。なのでコードを回すとcontextも本当に長く入れなければならないし、
そしてその長いcontextも絶えず変わってそういうworkloadも増えていて、またその間にreasoning tokenも非常に多くかかるじゃないですか。
私だけでもGPT-5.5にx-highをかけてそこにコードを入れたりしながら作業を進めていますがそのworkloadがかなり大きいんです。
なのでそれらを可能にする現代の推論インフラストラクチャ。私たちはしばらくモデルの話をしながらtrainingの話をたくさんしましたが、これからはtrainingよりも推論がはるかに重要になった時期が来たのでその推論がどのように起こるのかについて一度深く学ぶ必要がありますが、今回のDwarkeshのエピソードがまさにその内容を話しています。
今日はその内容がかなり難しくはありますが、面白いはずなのでその内容を一度解きほぐしていくそういうエピソードにしてみたいと思います。
チェ・スンジュン さっそく入ってみましょう。私たちは先週DeepSeekの話をしましたが、
DeepSeekのグラフで見るコンテキストコスト削減 1:38
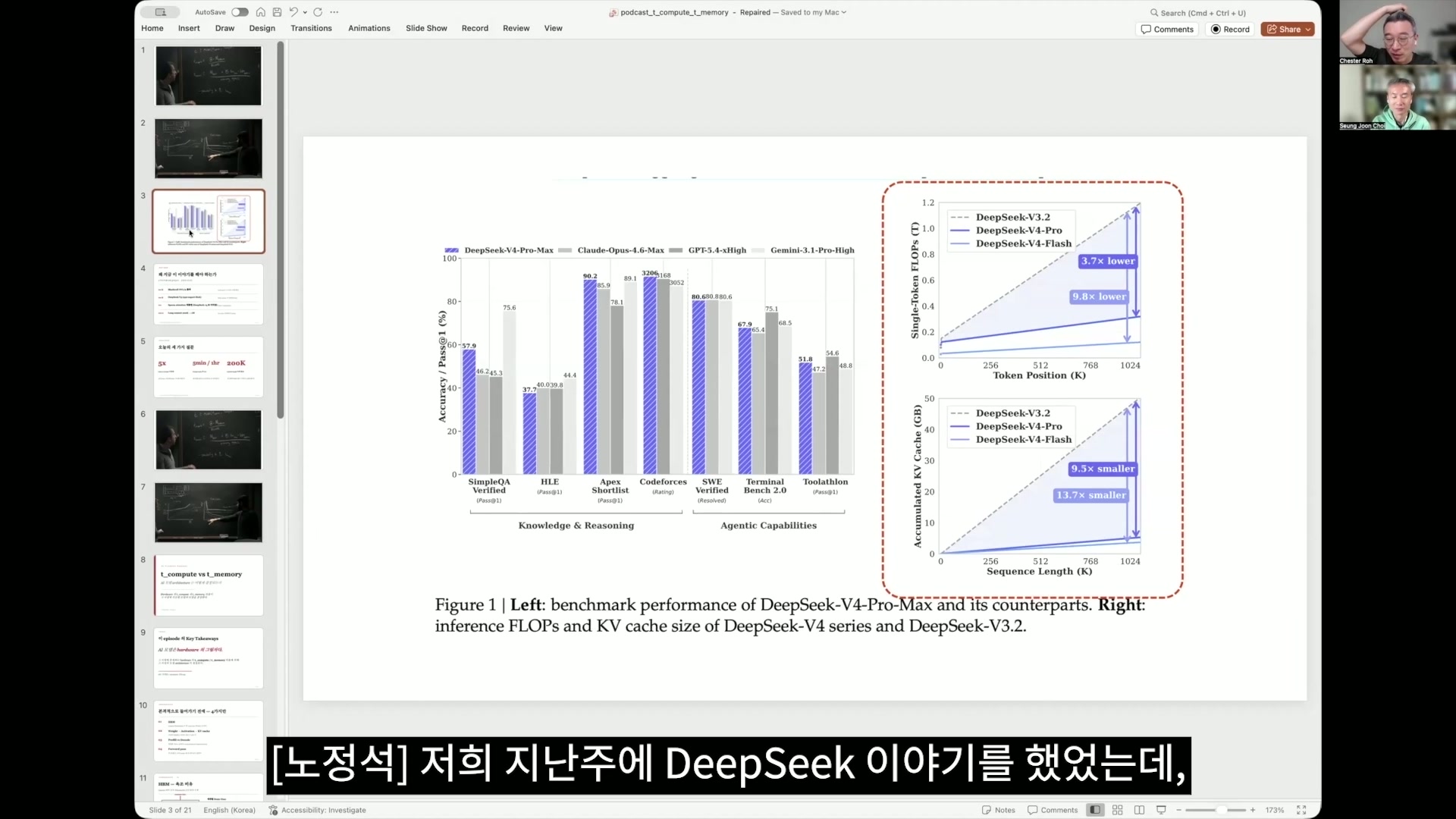
ロ・ジョンソク 実はDeepSeekが論文のいちばん最初のページで出していた内容がまさにこれじゃないですか。この右側にあるグラフが実はこの論文の肝だと申し上げましたが、上にあるのがcomputationに関する内容で下にあるのがメモリに関する内容です。これをそのまま要約すると、トークンポジションがkなので
0から100万までを表しているんですが、最近は100万トークンのcontext lengthをフロンティアラボがみんな提供していますが実際、100万は非常に高価なサービングなんです。なので大半は現実的に20万、このくらいでティアが分かれていると理解していますが、そのティアがなぜ分かれているのかも、私も今回わかったんです。ところがこのDeepSeekが
computationとメモリ使用においても、contextが大きくなっても非常に効率化した。computationは3分の1、メモリは10分の1に減らしたんですが、これがいったいこのagentの世界、agenticな何というeraでしょうか。agentの世界になりつつあるこの現代においてどれほど大きな意味があるのか今日のエピソードを一度追っていくと理解することができます。
NVIDIA GPUとHBM中心のサービングインフラ概要 2:53
ロ・ジョンソク モデルの話をしながら、実はNVIDIAの話をするとほとんどの人は理解できません。そうですよね。ですがGPUというものがあり、GPUがあってこそモデルが動くと言いますが、Jensen Huangがいつもこのイベントに出てきてハードウェアを全部見せてくれますが
チェ・スンジュン 持ち歩きながら見せたりして。はい。GPUチップがあって、それからチップがあると
ロ・ジョンソク その横でいつも話すのが、演算ユニットがどれだけ増えたか、速度がどれだけ速くなったかという話をして、そのすぐ横についているのが韓国が最近かなり恩恵を受けているHBMが横についていて、それらがまとまってまたCPUとまとまり、ひとつのラックになって、それからGPU間通信、それからラック間通信、こうしたものに関するインフラストラクチャを一つ一つすべて説明してくれるんですが、私たちはその内容を正確に理解しているわけではないじゃないですか。今日はその内容について
それらについて一度話してみます。実は私たちが今日話す内容の結論を先に少し敷いておくと、
Blackwell NVL72とラック単位のメモリ拡張 3:52
ロ・ジョンソク このBlackwell NVL72のGPU間通信が以前は既存では8個までだったのが、今は72個になり、そして個別GPUの容量も実際Elon MuskがColossusに敷いたH100やH200だけを見てもGPUあたりのメモリが80GB、100GB程度にすぎなかったじゃないですか。
ところが今出ている、昨年から今年にかけて出荷されているGB200やGB300はメモリが192GBで、288GBのものもあったりするんです。ところがそういうものが
72個、ひとつのラックで一つに全部つながっていて
チェ・スンジュン そうするといくらですか。20TBくらいになりますか。20TBくらいになりますね。実際そういうものが意味するところはすべてあって、
ロ・ジョンソク 今の最新モデルはこのハードウェアの構造を本当にうまく利用していてそれによってモデルのアーキテクチャも形成されていると見ても差し支えないほど、それが関係しているんですが、
チェ・スンジュン 最近出会うモデルがなぜ急に4.5、4.6あたりから変わったのかが説明できるわけですよね。そうです。リリース時期を見ると。
そして私たちはGPT-3.5が2022年10月に出たんですが、その次にGPT-4.5が1年半から2年近く後に出たんですが、その間にGPT-4.0がかなり長い間プレイしていてそれが2023年3月でしたよね。
ロ・ジョンソク そうです。だいたい1.8T程度のモデルだと思っていたじゃないですか。そしてClaude Opus4.5や4.6のようなものも、Swyxが言うには、ただの噂で、誰もconfirmしてくれませんが、maximumで1Tから2Tモデルだろうという話をしていたんです。ところが今、急に出てきているモデルは5Tモデルに10Tモデル、こういうモデルサイズが急にぐっと大きくなったわけです。
チェ・スンジュン そうですね。Mythosが10Tで、その次に5Tくらいのものが今サービングされているはずだ、という推測が多いですね。そういうことが、なぜ今急に起きているのか。
ロ・ジョンソク これが急に繰り返されているのには理由がある。それでDwarkeshとReiner PopeというGoogleのハードウェア出身の創業者の方が出てきて、
Reiner Popeの講演と今日のロードマップ 6:09
チェ・スンジュン TPUをやっていた方でしたね。この黒板に板書しながら説明してくださるんです。
ロ・ジョンソク なので今日は、その黒板の板書内容をいくつか追いながら、そして最終的には現代のLLMサービングアーキテクチャが一体どう動いているのか、彼らはどんなゲームをしているのか、などについて長い話を、私たちも一度追ってみようと思います。今日のエピソードの内容は、
そのためかなり難しく感じられるかもしれません。ただ、皆さんがClaude Codeやこういうものを使って、ただ単に使いたいだけだという方には、このエピソードの内容はあまり面白くないかもしれません。しかしNVIDIA GPUの出荷時期と、それからモデルとして出荷される
アーキテクチャ、そしてそれらが未来をどう示すかという先行指標なんです。その通りです。NVIDIAだけの話ではなく、
チェ・スンジュン 同等のことを競合他社もやらざるを得ないので、今の時代状況を読む指標に
なるのではないかという感じがあります。今日はその話をしてみたいと思います。
トークン価格表とキャッシュ価格の意味 7:22
ロ・ジョンソク それで、なぜ私たちがClaude Codeを使い、皆さんにキャッシュ最適化の話をしていると、こういう話を何気なく使うんですよね。
input tokenとoutput tokenには価格差があり、しかもこの価格差も、あるところでは大したことがなく、あるところでは大きいんです。
DeepSeekでもGeminiでもAnthropicでも、pricing schemeがそれぞれ違うんですよ。
それも違いますし、それからキャッシュも5分キャッシュ、1時間キャッシュという形で、それらの価格も全部違います。さらにGeminiのようなものを見ていると、context lengthが200K、つまり20万までは少し問題ないのに、20万を超えると別の価格ティアで課金するこういう料金表もあるんですよ。一体なぜこういうものが存在するのか、
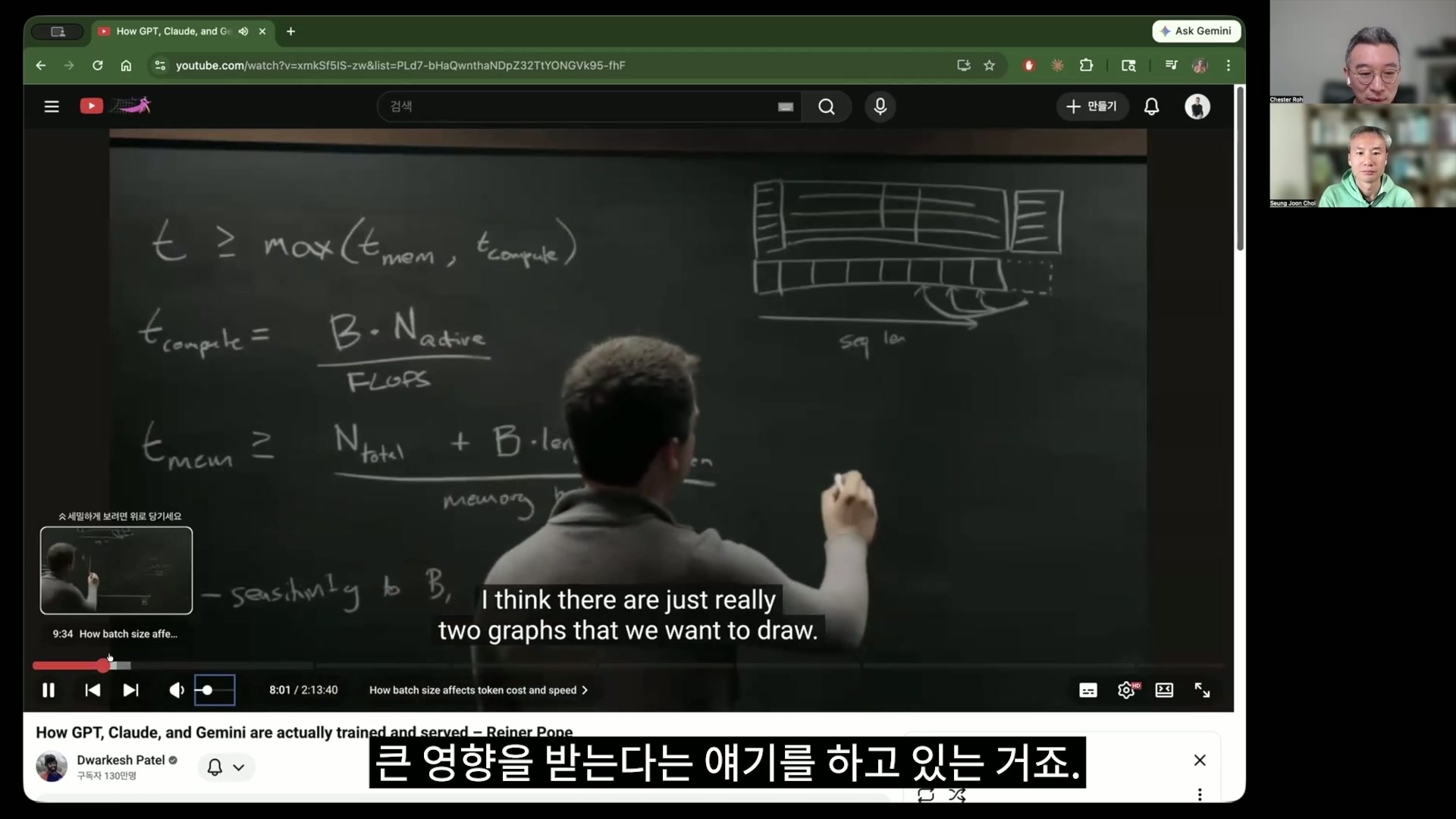
最新のLLMサービングアーキテクチャとハードウェア、そしてこれらの間にはどんな関係があるのかを、今日は見ていこうと思うのですが、それを解きほぐす内容がこの方がしているこの板書に出てきます。この板書の内容は、少し後で私たちが基礎を一度扱ってから、もう一度戻ってきて、このT_computeとT_mem、そしてこれらがなぜこのように構成されるのかを見ていきたいと思います。
それで、この式を使ってこのグラフを導き出すんです。結局はbatch sizeごとにかかる時間、
それからbatch sizeごとに生じる料金表ということで、この料金表を見ると、実は先ほど話していたこういうものすべてに答えられるんです。
つまり核心のキーワードは、T_computeとT_memに制限される、です。
チェ・スンジュン ここでTとは何ですか?時間ですよね? 時間。計算にかかる時間と、
ロ・ジョンソク このメモリをrecallするのにかかる時間、この2つの組み合わせで、現代のLLM inferenceのすべての価格が決まる。今日はこういう話をしてみようと思います。つまりAIモデルは、このハードウェアの影だ。
推論の基礎用語整理 KV cache prefill decode 9:19
ロ・ジョンソク このように発展し、モデルがそう発展するからこそ、ハードウェアがその方向に舵を切ることもありますし、ハードウェアがそのようになっているからこそ、モデルがそれをfully utilizeするために変わることもあります。今日の内容は少し難しいですよね。
スンジュンさん、私たちは実はエピソードをやりながら、transformerをどうすれば簡単に説明できるかを本当に何度もtryしてきました。でもこれが、なかなかうまくいかないんです。
いつも、一体HBM、それからtransformerの基本構造、その中でこのattentionとfully connected layer、dense blockは何を意味するのか、KV cacheの話、あちこちでよくするけれど、一体それは何なのか、それからprefillとdecodeとは何なのか、そしてforward passとは何なのか。
ただ幸いなのは、推論はとにかくtrainingよりは簡単だということです。
チェ・スンジュン 私たちはtrainingをするわけではありませんからね。
ロ・ジョンソク その一つの慰めを得ていただいて、今日は推論に関してforward passまでにしましょう。backward passは実際trainingに関するものですが、それはもう私も見たくありません。すべての現代アーキテクチャでこのMoEとsparse attentionを敷いているものを使ってtrainingするにはどうするのか、私ももうあえて開いてみる気になれないので、このくらいで一度説明してみましょう。では、スンジュンさん、私たちのtransformerの話をもう一度だけしてみましょうか。
Transformerの動作フローとKV cacheの再利用 10:49
チェ・スンジュン 大きな構造から少し話す必要がありそうです。
これからここを詳しく見ていくことになりますが、そして全体像をつかむときに、なぜこういう話をするのかというと、IT分野の領域だけでなく他でもそうだと思いますが、リソースがあれば、それを最大限引き出そうとする傾向がありますよね。遊ばせておくわけにはいかないじゃないですか。なので、そういうことがこの後にも少し出てくるのですが、
まず私はtransformerに関することを少し話してみます。
それで全体として、何かpromptを私たちが書くと、それがprefillというものになって、一度にずっと全部並列で計算され、その並列で計算されるときにKV cacheが作られるんです。少し後で説明します。KV cacheがここで作られると、
それができた後、最後にそのトークンから続いたそのベクトルから次のトークンを推論し、それがまた入力に戻って、ここでは矢印がこうなっていますよね。decodeしていきます。なので、prefillされたものと、
その次に1トークンずつdecodeされる段階を区別して考えることが重要になり得るんです。つまり、これは本当に簡単に説明する必要がありそうですが、
ロ・ジョンソク 実はprefillとdecodeの概念が理解できれば、正直、卒業してもいいくらいなんですが、そうなんですか?いや、冗談半分で言ったんです。これを初めて聞く初心者の観点で
この概念がピンと来たなら、実はかなり優秀だと申し上げたくて言っているんですが、ただ理解の助けになるように、一度だけ説明を私が付け加えてみますので、コメントしてください、スンジュンさん。私たちがClaude Codeで「ねえ、このコード見て」と言いながらいきなり1000行のコードをドンと入れると
チェ・スンジュン そうですね。prefillしないといけません。そうですね。それがTransformerに入って
ロ・ジョンソク このモデルが次のトークンを吐き出すために事前準備をしないといけないじゃないですか。そうです。その事前準備をする過程が私たちがprefillと見ればいいものです。そしてそのprefillの大部分は長いinput tokenに関する内容だと考えれば、おおむね合っています。
チェ・スンジュン それからユーザーが入力するものもprefillされるわけです。ユーザープロンプトなので同じです。入力がそれなんです。
ロ・ジョンソク そうです。長く入るのでinput tokenは必ずprefillされます。それで入っていくんですがそのprefillされるトークンにもtoken by tokenがあって、そのトークン一つひとつごとにQKVが一回ずつ全部計算されるんですが、ただQKVのうちQは一度使って捨てられるもので、KVは後ろに行くほど、後ろにあるqueryトークンたちが前にあるKVを全部見なければならないじゃないですか。だから一つずつ全部保存するものだと考えれば合っていると思います。
それで少し後でもう少し詳しく見ていきますが、今おっしゃってくださったことではTransformerにはブロックが複数あるんです。DeepSeek V4は61個あったか、そんな感じだったはずです。
そうです。先週見ていたものがそうで、だからそこごとに、1トークンごとにKVが全部付くんです。それで入力がもし100文字だったとします。100文字それぞれに、1レイヤーで全部KVが付き、次のレイヤーでまたKVが付き、61回、そのKVが100文字それぞれに全部付くとざっくり考えればいいんです。その通りです。
チェ・スンジュン とてつもなく多くなりますよね。
ロ・ジョンソク 私たちが少し後でTransformerブロックを見ながらも話しますが、これは実はトークンが入力されると同じ形をした、ここがTransformerの魅力なんですが、同じ形をしたTransformerブロックをただ61回繰り返してトークンが通っていくわけじゃないですか。それを今スンジュンさんがおっしゃったわけで、そしてoutput tokenは一番上にあるブロックから取り出してそれをまたトークンに変えるんです。そうですね。最後に生成されたものから今度は返してあげないといけないんですが、
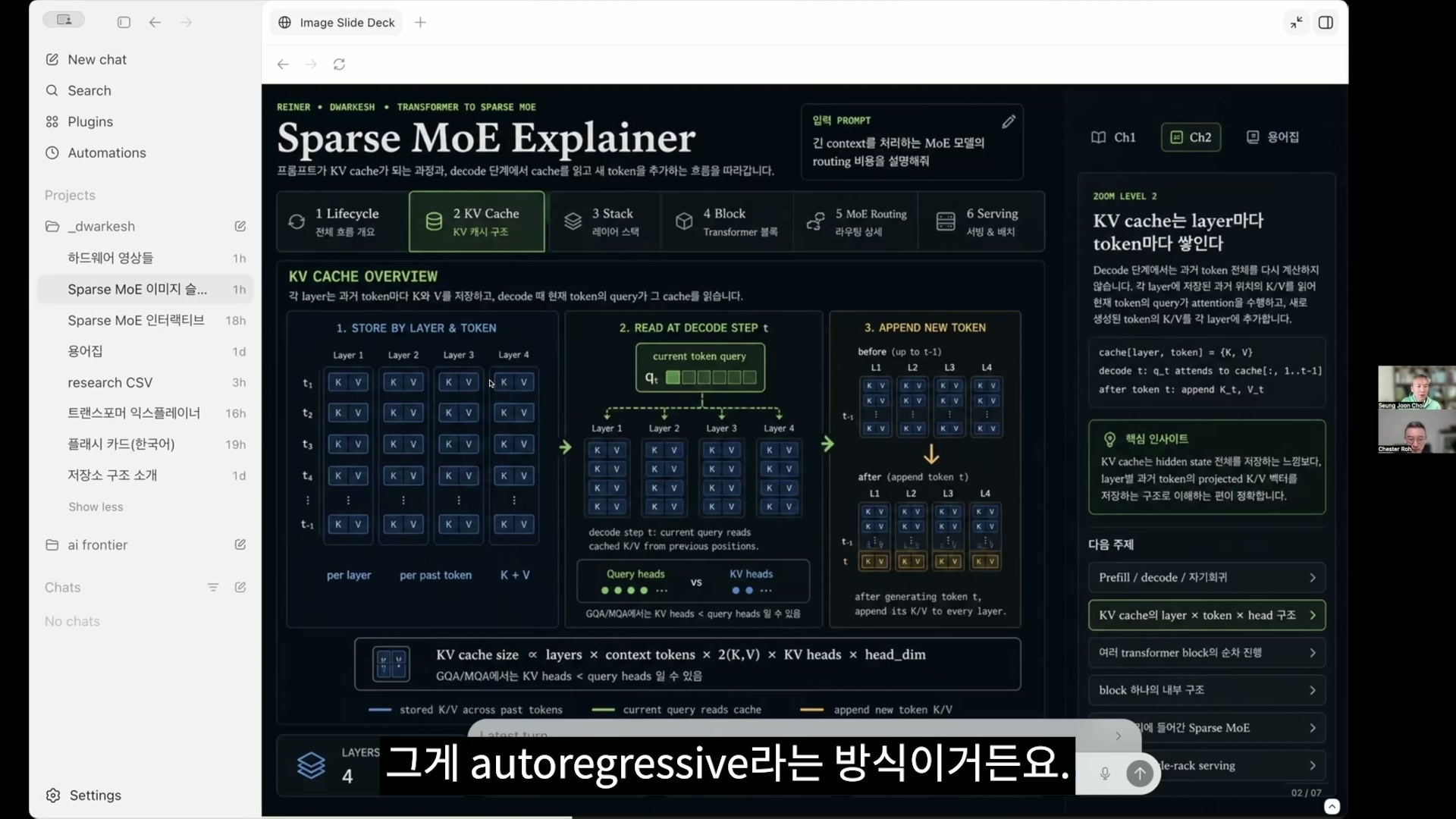
チェ・スンジュン それがautoregressiveという方式なんです。詳しい部分は少し時間がかかるかもしれませんが、このTransformer Explainerのサイトが非常によくできています。これは3次元で見るバージョンよりも理解しやすく説明されていて、GPT-2が実際に動くんですが、私がカチッと日本語版の説明を作ってみました。
ロ・ジョンソク ああ、Codexがやってくれたんですね。それでTransformerとはこういう話で、GPT-2 Smallを活用して
チェ・スンジュン 今、例を少し見せようとしています。それで今見るとQ、K、Vが一つのトークンに対してもmulti-headで付いて、このように多様に生成されます。ただこれは詳しすぎるのでいったんこのくらいにして先に進みます。それで “Data Visualization Empowers Users to”ところがEmpowersは二つのトークンに分離されることがあります。トークンと単語は少し違うんです。ざっくりまとめて単語だと考えますが、はい。では、これを一度追ってみます。
トークン化 token ID vocab sizeの概念 15:29
チェ・スンジュン それでこの次に来る可能性が最も高いトークンは何か、指示文どおりに生成を押してみます。するとあれがこのように計算されて、それでcreateの次に来る単語がcommaだと今出ました。21.17%で。だからこの過程を経て
commaがまた入力に行って、その次が生成されるんです。それでもしまた生成すると、manageが出ましたよね。いろいろな候補がありますが、だからこれがprefillの後にずっと繰り返されるんです。それで今のprefillは、これが一度にこうずらっと全部QKVが計算される、そういう過程だったわけです。もう少し詳しく見てみると、ここを見ると
embeddingといって、これはtoken IDは固定なんですが、それをベクトルに変えてくれる作業をします。それでああいう形で
ロ・ジョンソク token IDというのは何ですか?token IDというのは、これは通常GPT-3の頃には
チェ・スンジュン 5万個ほどのvocabulary辞書があって、実際にこのtokenizationされるEmpowersが二つのトークンになるんですが、emが795番というID、これは固定です。powersが30132番、このように固定されているんです。これはIDは固定なのでいつも最初は同じものが割り当てられますが、ベクトル化された後は内部のresidualに沿って流れると文脈が混ざって変わるんです。
ロ・ジョンソク すると、あのトークンは単語ごとにただ付いている一種の通し番号だと考えればよくて、その次に私たちがよくvocab sizeと言うものはこのモデルが持っているこの単語帳に単語がいくつあるのか、そういうことですよね。そうです。ただ重要なのは、この後もトークンと
チェ・スンジュン hidden spaceを混ぜて話すことになるんですが、stateを、実際にはベクトル化されるのでこのベクトルを私たちはhidden state、またembedding、いろいろな言い方を混ぜて呼ぶんです。ただそれは文脈に応じて改めてお話しします。とにかく、このトークンそれぞれに
ベクトルが生じることが重要です。そしてpositionalは少し難しいので
さっと飛ばして、とにかく位置に関する情報を注入して、それをTransformerブロックが、同じものが先ほどロさんがおっしゃったとおり、GPT-2の場合はこうしてずっと並んでいます。なので同じものが今いくつ残っているか、それを示しているわけです。
そしてこれを通過し続けながら、どちらの方向へ行くべきか、最終的に出力すべきものがどちらの方向へ行くべきかを導き出すための計算が進んでいきます。そしてそのすべての層でQKVが作られ、KVは残しておきます。後でまた計算するためです。なのでqueryはこのプロンプトから、
Attention causal maskとKV圧縮手法 18:29
チェ・スンジュン トークンから作られた問い合わせのような感じだとすると、keyとvalueは実際に知識の中からこれをsoft searchという概念で説明することが多いんです。正確にkey-valueを探すのではなく、softに情報を探すような、そういう感じなんです。つまり皆さんがこれを見ながら
ロ・ジョンソク QKVの何らかの意味を理解しようとすると難しくなります。これはTransformerの著者が「このトークンたちが入ってくるものをその中で互いの関連性を計算させるにはどうすればいいのか?」と言いながら自分たちが構造的に作った一種のbiasです。だからそのトークンが入ってくると、
それをquery、key、valueに分けて全部計算し、QKVはこういうふうに計算させよう、という形にしたわけです。もちろん哲学的な意味は当然あります。
でも、そうやって作っておいた一種のinductive bias、私たちは単に、ある著者の設計だと考えれば合っています。これがなぜこうなると
queryになり、keyになり、valueになるんですか、という質問はせずに
先に進みましょう。ただ、このアニメーションは面白いので一度見てみましょう。attentionを詳しく見てみると、ああいう形ですべての互いのトークンに対して何かを計算します。それでその文脈情報が生まれるんです。ただ、ここで三角形の形になっているのは、未来のものをプロンプトに入力するとき、そこは飛ばします。causal maskを説明しようとすると少し難しいので。はい、そこはそのまま飛ばしましょう。当然、前のものだけを見るべきですよね。
なぜなら未来のトークンはまだ到着していない状態だからです。あの三角形になっているものは、単にcausal maskといって、ああいうものがあります。著者がうまく作ったものです。ところで、それで、そういうものがmulti-headであり、
チェ・スンジュン 昔のTransformerと最近のTransformerの違いは、以前はこういうKVを全部残していたとすると、最近はそれを圧縮することもまた重要なのですが、それは後で、後で扱います。
ロ・ジョンソク はい。そこにはすごいテクニックがたくさんあるのですが、それから最近、
チェ・スンジュン MLAやsparse attention、そういったもの全部ですね。そうです。
ロ・ジョンソク その究極形が、先週扱ったDeepSeek V4が究極形を一度見せてくれた、と考えて先に進みましょう。はい。なぜなら多くなりすぎるんです。
MLPとMoE構造 sparse MoEの直感 21:06
チェ・スンジュン 保存するには。それで次に、ここがMLP部分ですが、attentionを通過した後にはFFNと言ったりもしますし、MLPと言ったりもして、とても小さな層のhidden stateが、hiddenが1つくらいは、hidden layerが1つくらいあるMLPを通過するんです。1つ、または2つになる場合もありますが、そうなるとそこでも感覚的には、
何らかの情報を、そこに入っていくベクトルによって引き出す規模で見ると、attentionよりMLPのほうがはるかにweightが大きいんです。なのでここに何かがより多くあり、
この部分がMoEとつながる部分です。はい。あのMLP部分は昔は大きな1つのブロックで、
ロ・ジョンソク そのすべてを全部計算する、denseだという表現をしましたよね。密だと、全部計算しなければならなかったのですが、MoEがそれを分割したわけです。
チェ・スンジュン なのでこれは今、sparse MoEの場合、先週DeepSeek V4を扱ったときに、384個のうち6個くらいがactivateされる、そういう
ロ・ジョンソク 数字は忘れましたが、実際かなり大きな数字で、非常にsparseでした。はい。
チェ・スンジュン なのでそれが今日も何度も重要に出てきます。そうして複数の候補、ここを見るとlogitという概念が出てきますが、logitというのは結局、ある確率にする前のものなんです。なので何らかのスコアが出てきて、それを確率にして、5万個くらいの語彙の中から何がトークンになるか、そのためこのときはベクトルではなく、再びトークンにし、そのトークンがIDのまま最初に戻った後にまたベクトルになること、それがautoregressiveという方式になるわけです。なのでinputに入れたものは、複数の単語が一度に処理されますが、
ロ・ジョンソク その次の単語予測は、単にその次の単語予測は、前にあるものが1つ出てこないと、その上に積み上げて、また次の単語を要求することができないわけですよね。そして良いアイデアは、すでに前のKVは
チェ・スンジュン 前のものを全部計算しておいたということなんです。再利用できる。queryは新しく生じた1つのトークンに対してまた作られますが、残りはすでにあったものを使い、新しく生じたトークンのKVをそこに合わせて加える、そういう方式で進んでいきます。ここでtop-k、top-pは飛ばすことにします。なのでここまでがTransformerをかなりquickに
ロ・ジョンソク そうです。Transformerはこういう形をしています。単語が入ってくると、単語をトークンというものに分割して変換し、それを私たちが認識するhelloは何番で、何は何番で、という名札があるのですが、その名札をモデルに入れるために、何らかのpositionも足して、embeddingを経て理解できるようなベクトルに変えます。単語がです。そして今、私たちが
それを実はトークンと呼んでいるのであり、それが入ってattentionを経て、そしてattentionブロックの中に重要な概念としてKV cacheというものがあり、そしてその出てきたattentionブロックを出た後に、再びMLPブロックに入って演算をして出てくるわけです。はい。そして出てきたものがこうして回っていくのですが、
チェ・スンジュン 重要なものを1つ抜かしていたのが、residual streamの概念を話しておくべきだったんですが、それが一つずつ出てくると自分自身に足し込んで、少しずつ意味を更新していくんです。はい。それが実はとても重要な部分です。
ロ・ジョンソク 重要な概念ですが、
チェ・スンジュン なので、こうしてそのたびにresidual streamが生じます。すべてのベクトルについて、トークンがベクトルになったものについて、attentionした情報を自分自身に足し、それからMLPしたものを自分自身に合わせ、それをすべてのブロックに対して連鎖させていくんです。はい、そうですね。
これが実は重要な流れが生まれる重要なそうですね。こちらの図でご覧になっているブロック1、2、3、4、5、nがありますが、
ロ・ジョンソク DeepSeekの場合は、これが61ブロックあるわけです。
チェ・スンジュン GPT-3はむしろもっと多かったです。90個くらいでしたし、そうなんですね。そして、そのブロックの中に存在するものが
ロ・ジョンソク attentionとMLPブロックで、それが二つの核心で、それから私たちが最近見ているいろいろな最新モデルのアーキテクチャ変化は、ほとんどがその中にあるattentionをどうやってより少ないメモリで使い、計算をより速くさせるかということと、それからdenseブロック、そこをどうやってさらに小さくして、計算をより効率化するか、ということです。その通りです。それで、こうしてLM headの説明をしていませんでしたが、
チェ・スンジュン LM headはとにかく一番最後に、多くのことを計算しておいて、それで一番最後にあるトークンに、つまりこのベクトルについてだけ、次のものを推論する、次のトークンに何が出てくるかを予測するのに使われるんですが。それと次のスライドが、たぶん先ほどお話しくださったそれのメカニズムをダイアグラムで表したもので、足し算があるところがresidualを合わせる部分です。
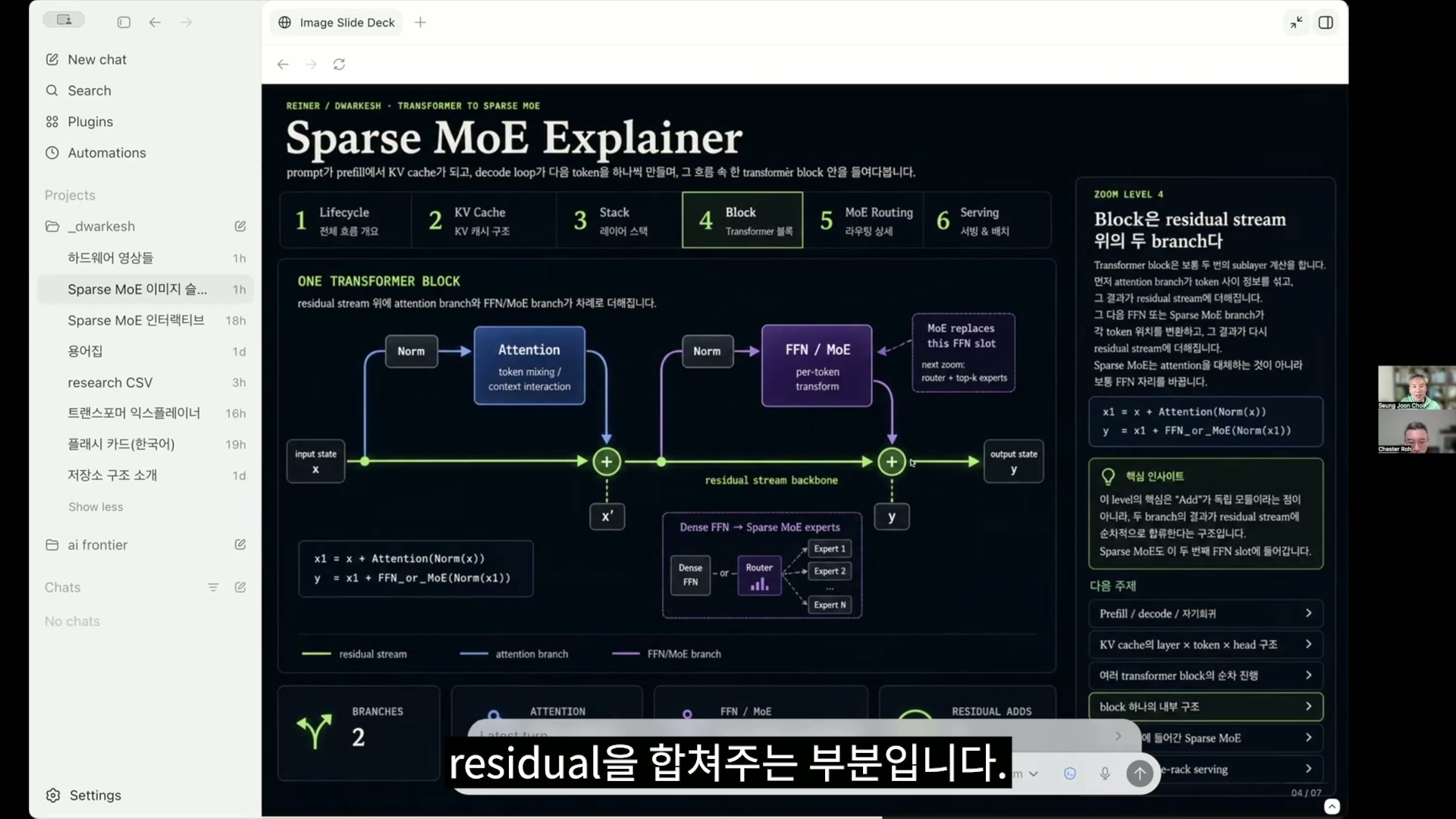
ロ・ジョンソク 下の緑色の線がresidual connectionですね。
チェ・スンジュン 残差接続をするわけです。
ロ・ジョンソク 今これはtransformerブロック一つを示しているんですね。
チェ・スンジュン そうです。なので一つのブロックを図式化することができます。ただ、ここで今のFFNまたはMLP、そしてMoEとなっているものが、
最近はparameterを大きくしなければならないので、メモリに載せられるくらい大きくするには、分けなければならないという問題が生じるんです。これが今日の核心の一つですが、それを私がinteractiveなバージョンにしたものが、つまりこれがトークンまたはベクトルごとに、一部のMoEだけがオンになるじゃないですか。
それで最初に、たとえば一つだけオンにしたとすると、今ここで私が二つだけ、実際とは違って、全体16個のMoEのうち、二つだけ接続されるようにしたんです。これについては二つの何らかのFFNまたはMLPが作動するようにしたわけです。
そしてそれに重み付き和をして、次へ接続してあげるのですが、これが一つだと四つになりましたよね。ところが時々見ると、
二倍ではない場合が生じることがあります。これまでは全部二倍でしたが、今は1、2、3、4、5、6、8。二倍でしたね。
別のrouteを一度見てみます。それでこのときは1、2、3、4、5、6、7。7個なので、
8個になりそうですが7個になるのは、一つの専門家。expertが二回行ったわけですね。
ロ・ジョンソク ここでMoE、Mixture of Expertsと言うので、多くの方が混乱する部分が、expertという概念が専門家だから、数学を聞いたら数学はあるexpertが処理し、物理を聞いたらあるものは別のexpertが処理して、expertが知識を持っている別の単位なんだろうと考える方がいますが、そうではありません。“I am a boy.” と打ったとしても、それがそれぞれ別のexpertを通過する可能性があります。
チェ・スンジュン それにトークン、さっきのようにトークンごとに別のexpertを通りますね。それがただ束ねられているだけなんです。
ロ・ジョンソク なので、そういうものがなぜそうなのかと聞かれても、私たちにも分かりません。
チェ・スンジュン そして専門家たちはtransformerブロックごとに複数あるんです。数百個が。なので、その部分も重要です。そして最後には、そうしたものが
ラック内通信 NVLink NVSwitchとラック間ボトルネック 28:43
チェ・スンジュン どのようにservingされるのかというハードウェア構造ですが、普通、一つのデータサーバーラックと言いますよね。ラックという形がどういうものなのか、少し後で動画で一度見るのですが。
その中にGPUがいくつもありますが、一つのGPUの中にMoEを一緒に二つくらいまとめておくのがよさそうでした。最近やっているものを見ると、その場合、それらが互いにすべて接続されていてこそ、速く計算できるんです。この中での計算は、NVLinkのようなもので非常に
速く行われ、最近はNVSwitchというものもまたあるようです。速く行われますが、ラック間ではこれが少し時間がかかり、遠くなるようです。ハードウェア上。これは少し後で私たちがラックの概念について一度見ることにはなりますが、
ロ・ジョンソク 実際、ラック内ではGPU同士が通信するのが速く、ラックの外へ出ると遅くなるので、最も速いネットワークの中で処理するのが絶対に正解ですね。
チェ・スンジュン そして、このGPU間で渡すものは、結局はtensorのようなものですよね。activationされたものや、そうしたものが互いに渡されるのですが、同時多発的に互いをこうして接続してあげなければならない問題があるので、そういうアーキテクチャが必要なのだと思います。では、まずNVL72が先ほども少し言及されたその動画を見ると、これは2分くらいの動画なんです。はい、私たちの機械がどう作られるのかを見せていますね。
NVL72ラック構成の映像で見るデータセンター 30:00
ロ・ジョンソク Blackwell GPU一枚が、この二つのダイを合わせて作られた。数字が速く過ぎてはいきますが。

チェ・スンジュン あの黄色で付いているものがHBMです。HBMメモリですね。そして二つに、一つが付いています。
ロ・ジョンソク GPU二つにCPU一つ。
チェ・スンジュン Superchipと呼ばれるものです。
ロ・ジョンソク そしてCPUとGPUの間も非常に高速につながるんですね。
チェ・スンジュン だからこれが1つのスロットになるわけです。
ロ・ジョンソク では1スロットにGPUが4つ、CPUが2枚。
チェ・スンジュン つまりBlackwell 2つにCPU 1つですね。
ロ・ジョンソク さっきは通信用のinterfaceカードが入って、それでこれを合わせると72個積めるという。

チェ・スンジュン そしてこれがスイッチ、少し前のダイアグラムで見たものですね。あれをspineに挿して、結局はどんな高速道路を敷けるか、ということだと思います。物理的に。だからここにラック1つ、72個を、
ロ・ジョンソク 72個のGPUが入った。
チェ・スンジュン ところでInfiniBandというものがあります。大きな帯域幅が必要なものは、さっきのようにラック間で接続するために、これはDCスイッチとも呼ぶようです。そしてあれが冷却パイプライン。水冷式。それでAIファクトリーのデータセンターを、
こういうふうに、ものすごい費用がかかりそうではありますが、作れる。Blackwellの時代に見せてくれましたが、Rubinの時代に見せているものは、さらにもう一段上がっていました。
ロ・ジョンソク はい。それで動画がもう1つあるのですが、これは、今年のGTCで、これがずっとどういうふうに、
Video 10年前の2016年4月6日、私たちはDGX-1を発表しました。説明してくれるものがあるんです。
チェ・スンジュン GTCの1時間7分あたりから出てきます。なので、それを一度見てみるとよいと思います。それで、これが最近どこまで来ているのか、そういうことです。
Jensen Huang 45度の温水は、データセンターへの負荷を取り除き、そのコスト、そのエネルギーのすべてを取り除きます。
チェ・スンジュン ここまでは、これも今や72個。
Jensen Huang LPDDR5を使っています。LPDDR5と、驚異的なシングルスレッド性能です。
チェ・スンジュン もうJensen Huangが持ち上げて見せられない。以上です。私たちは、
Jensen Huang これら残りのラックと一緒に使えるように、それを作りました。agentic processingのためです。ここまではBlackwellです。
チェ・スンジュン こういう形でNVLinkを運用する。それでこのDwarkeshの動画を見てから、Jensen Huangのキーノートをもう一度見返すようになりました。そうですね。
ロ・ジョンソク では、スンジュンさん、前段の背景説明を少ししましたので、今日のメインコンテンツを始めてみましょう。私たちが3日間勉強したコンテンツは、このDwarkeshがReiner Popeという方と一緒に行った講演なのですが、
roofline analysisで見るLLMサービング時間の分解 33:31
ロ・ジョンソク これらのGPUがどのようにservingされるのかを、簡単な数式を使って、いくつかの数字に隠されている意味を私たちが読み取れるようにしてくれたセッションです。このセッションを一度、私たちが追いながら、意味を確認していきたいと思います。
roofline analysisをしてくれる、という話をしながら、話を進めていくのですが。この方が話しているのは、私たちは結局、ただCodexやClaude Codeや、あるいはChatGPTに何か文章を書いてEnterを押すと、その結果が返ってくるまでの時間があるじゃないですか。でもその結果も、ただA4用紙1枚に
どんと出てくるのではなく、トークンがgenerateされるのが
見えるではないですか。decodeされていく過程が見えますね。そうです。その過程が、あるものは非常に速く、
あるものは遅い。もちろん今はかなり底上げされていますが、以前は遅い場合も私たちはしばしば目にしましたよね。
チェ・スンジュン そうですね。それに最初のトークンが出る時間も微妙に違いませんか。そうです。ですが、そういうものが
ロ・ジョンソク いったい中でどんなことが起きているのか、その概念について説明してくれるのですが、これを私たちがただ飛ばして結論だけ話すには、途中にある内容を少し追わないと難しい部分があるので、私たちも一歩ずつ追ってみたいと思います。いいですね。ここで今、t = 時間ですね。
t_memとt_computeで見るlatencyの決まり方 35:12
ロ・ジョンソク つまり、かかる時間は、LLMが何かをこうして結果として出すのにかかる時間は、T_memとT_compute、この2つで話すんです。つまりメモリ時間とcompute時間、その2つのうち多くかかるほうに制限される、boundされる、という話をここでしているようです。そうですね。それで、computeにかかる時間は? と言っています。
チェ・スンジュン active parametersという話が出ました。このcomputeにかかる時間は、
ロ・ジョンソク 実は私たちがさっきtransformerで話しましたよね。computingするうえで主にかかる要素は、実はattentionを計算する部分と、その後ろのdenseブロック、MLPブロック、multi-layer perceptronと呼ばれる、私たちが従来からなじんでいるそういうneural networkです。これは名前が紛らわしいです。
チェ・スンジュン MLPと呼ぶこともあればFFNと呼ぶこともありますが、同じものを指していますよね。
ロ・ジョンソク そうです。同じものを指しているんです。
そうです。同じものを指しているんです。今はexpertを指しているわけで。そうです。ところが、その2つのブロックを計算する時間の合計なのですが、
そうです。ただ、ここではT_computeを計算しながら、そのdenseブロックだけを計算しました。計算の便宜上、ここでcomputeにかかる時間は実際には何でしょうか。このparameterの数に、実は私たちが入れるトークンの数を掛けたものですよね。そうです。入れるトークンはbatchで処理するのですが、このbatchという概念を、実は説明してから入る必要がありそうですね。つまり、
推論batchの概念とスケジューリングオーケストレーション 36:46
チェ・スンジュン sequence lengthに近いと見てもいいのではないですか。ただ、複数の人が使うsequence lengthというか。
ロ・ジョンソク つまりここで、trainingにおけるbatchと推論におけるbatchを少し区別する必要はありそうです。つまりtrainingでのbatchは、複数の文章を一度に計算するために、私たちはbatchという表現を使うじゃないですか。
チェ・スンジュン そうですね。GPQAを一度に回すためにそうしますね。一度に回すために。なのでbatchがあると、
ロ・ジョンソク 1つのbatchのsequence lengthは、普通trainingが許容する範囲で、例えば4K、8Kだとすると、その範囲のあいだsequence lengthはぎっしり埋まっています。そうです。だから普通trainingするときには、私たちが何かを入れるテンソルのdimensionを見るとbatch、その次にsequence length、その次にembedding、私たちがhidden dimensionと呼ぶこの3つの積なんですが、
チェ・スンジュン d_model。そうです。これがぎっしり埋まっているんです。
ロ・ジョンソク だからbatch掛ける何らかのsequence lengthが事実上データセットのサイズになるわけですが、inferenceの場合は少し問題が変わってきます。どう変わるでしょうか?
チェ・スンジュン どんな入力をするかによって生成される長さも違うし、入力も違うし、全部違うんじゃないですか?そうです。ただ、私たちがprefillするときは
ロ・ジョンソク 複数のトークンが一度に入るので、場合によってはtrainingに近い状況になることもありますが、decodeの場合は必ずこの前のトークン1つが入ってこないと次の1トークンが前に進まないですよね。だから実は入力されるトークンが1つしかないということです。
つまりsequence lengthが1つしかないわけですから。
なので単に従来のtrainingの観点から見ると、batchを1人のユーザーだと仮定したとき、あるユーザーは「Hi」と一文だけ書くこともあるし、あるユーザーは単にCodexで50Kのcontextを投げることもあるし、あるユーザーはただ1段落かもしれないし、実際にはlength、つまり長さがあまりにもばらばらになりますよね。もしそれをtrainingと同じ
そういうdimensionに埋めなければならないとしたら、他の部分はpaddingで押し出さないといけないじゃないですか。何も入っていない。遊んでしまいますよね。そうです。そうすると途方もないメモリの無駄になるので、
普通に考えればpaddingを全部なくして全部つなげればいいじゃないですか。
そうです。それが推論における実質的なbatchの概念なんです。そうです。これをつなげると実際にはめちゃくちゃになる区間が、
dimensionやKVなどが全部壊れてしまいますよね。実際そうなんです。trainingするときは1つのbatchに
ずっと入っているsequence lengthに従ってKVが正確にalignされているのですが、推論するときはただ1つのbatchに複数ユーザーのその1個だけのものに、単にnext tokenへ進むためのそのトークンを全部入れてしまうと、KV cacheが全部壊れてしまうじゃないですか。
チェ・スンジュン 詳しくは分かりません。私も。これが壊れてしまうので、
ロ・ジョンソク 実際にはそれはvLLMやSGLangのようなものがメタレイヤーを置いて全部マッチングしてくれるんです。なので結論だけ見れば、結局inferenceもその1つのbatchに、私たちが今使っている、私たちが1つのGPUに何千人も同時につながっていると見ればいいわけです。
チェ・スンジュン スケジューラーが必要になりますね。それは。はい、スケジューラーがあります。
ロ・ジョンソク スケジューラーがあり、メタレイヤーがあって、それを「このbatchの中で100番目にあるものはユーザーのスンジュンさんで、103番目にあるトークンはロさんで、誰のトークンは誰のものだ」とそのトークンに対するインデックスを全部持っていて、その次にそれがtransformer blockを通って演算を経て出てくると、その間に途中途中でKV演算を全部しなければならないですよね。そうです。ただ、そのユーザーたちの状況も全部違うはずです。
あるユーザーは前のcontextをすでに80万contextも使ったユーザーもいるし、あるユーザーはcontextが0かもしれない。
チェ・スンジュン cacheが飛んだ場合もたくさんあるでしょうね、はい。compactされて飛ぶ場合もありますし。
ロ・ジョンソク ただ結局、その前にあるcontextというものは先ほど話したKV cacheの塊なので、そのKV cacheの塊を全部マッピングしてくれるメタが全部動きます。メタレイヤー、orchestration layerが全部動くと考えればよいです。
なので推論とtrainingにおけるdimensionは少し違い、trainingに慣れている方々が考えるbatchと今日私たちが話している、このDwarkeshが言っているbatchは、推論におけるbatchは今は違うものだと申し上げる必要がありそうです。そうする理由が重要なんです。
こうする理由が、ある意味で最も重要な理由だと思います。
GPU utilizationとMFUの違い 41:36
チェ・スンジュン とてつもないGPUを遊ばせてはいけないから。高価なリソースなので、遊んでいてはいけないんです。
ロ・ジョンソク 遊ばせてはいけないので、この1ステップ、ステップを回すたびにぎっしり詰めて回さなければなりません。だからGPU utilizationをだいたい70から80%くらいで回してこそこれが採算の合う商売になるわけです。MFUがそれですか?
チェ・スンジュン Model FLOPs Utilization、それが関係しているんじゃないですか?
ロ・ジョンソク MFUとGPU utilizationは少し違う概念だと見るべきだと思います。MFUは実際にはFLOPsなので、このGPUが出せるこれがフルに回ったと仮定したとき、
チェ・スンジュン アウトプットが最大のとき。
ロ・ジョンソク はい。メモリbottleneckなどを計算に入れず、単に計算だけをoptimalにしたとき、これが100を計算するのですが、実際の現実での計算はそうはいかないじゃないですか。データが準備されるまで待たなければならないし、何かしなければならないし、blockされるものが非常に多いので、実際には多くの演算がcompute-boundになるのではなく、memory-boundになる場合が多いので、MFUは全部使い切ることができません。ただ、MFUとI/Oなどを全部計算に入れて、
単にGPUが動いていれば、これは動いているという概念がGPU utilizationだと思います。
なのでtrainingやinferenceでは、MFUの数値を高めるのが無条件によいわけです。そしてこれは少し後で話すのですが、MFUがmaximizeされるポイントがただT_computeとT_memが同じならそれがmaxになるんじゃないかと、ざっくり片づけて進むということです。
チェ・スンジュン まず、このように出会う交差点のようなもの。それで私が言葉で説明はしましたが、
ロ・ジョンソク これが少なくともtransformerのtrainingにおけるさっき話したB、N、その次にモデルdimension、このテンソルの概念が頭にしっかり入っていないと実際、これをそのまま理解し続けるのは少し難しいのでそういうものかと思って流していただければいいです。ところが推論では
batchとsequenceをそのまま一つに全部展開してしまってそれを一つの列車として置いてその列車の中に複数ユーザーのworkloadを同時に乗せるわけです。なので一つのclockがピョンと回るときに
できるだけ多くのユーザーを乗せるために、ただその列車には非常に多様な乗客が乗っているわけです。例えばそのユーザーが
ただdecode、全員がdecode過程にあると仮定すると実際にはinputとして入れるtokenは一つしかないはずで、すると例えばbatchが2000個だとすると2000人を同時に乗せることもできるわけです。うん。もし単に少し荒く言うと、
チェ・スンジュン 何かモデルがずっとそのweightに行列積をしてやらないといけないのですが、その行列積する対象を乗客たちのデータで埋める、そういう感じなわけです。一度にそれをやらなければならず、それを20msなり何なりでこれがずっと繰り返されて列車はずっと出発する、そういう感じですよね。
ロ・ジョンソク 一つのclockをそのまま20msに設定しているのですが、それはこの後でまた話が出てくるのでなぜ20msなのかは一度話してみることにして。結局は列車を埋めるのですが、
さっきの話をそのまま締めると、一tokenずつだけ入るなら2000人が同時に使うこともできるのですが、例えば誰かがClaude Codeでコードを一気に押し込んでprefillしなければならないものが1000個入っているとすると実際にはその1000個がprefillで埋まり、その次にdecodeするユーザーたちはその後ろに1000人くらい入ることになるので。
このようにprefillとdecodeされる過程をどのようにoptimizeするのかということが最近の現代的なLLM servingのほぼ核心なんですよ。
その目的は何か。結局、ある単位時間あたりのメモリやcomputeや
これを全部maximizeしなければならないわけです。utilizationを。どうやってこれを目いっぱい使うかに
すべてが合わせられていると見れば合っているでしょう。いいです。ではそのくらいにして、後ろに進みながらまた概念が出てきたら
一つ一つやってみることにしましょう。
それでT_computeは、これが単にこう言っているわけです。
batch、何人を乗せるのか。
便宜上、一tokenだとしてみましょう。
すると2000人を乗せるとするとBが2000ということです。
そしてN_activeは、ただactivateされるparameterの数。
ここでこの人がMoEの概念を持ってきて実際にはsparsityの概念として、全体のparameterはこれだけあるけれど、MoEの核心概念は、計算するときにはいくつかのexpertだけを高速に計算するということじゃないですか。
そのために実際、computingでの効率が生まれるわけです。
チェ・スンジュン parameter全体のサイズを大きくする方法でもあり、効率でもあり、そういうことですね。
ロ・ジョンソク そうです。その効率のために、だからこれはT_computeはbatch掛けるこのnumber of parameters、active parametersのnumberにboundされると表現するためにこの表現を使ったわけです。それをFLOPs、1秒あたり何回計算できるかで割るとそこにかかる単位時間が出るはずです。そうですよね?下は単に分母を
チェ・スンジュン computing powerだと大まかにまとめて考えれば
ロ・ジョンソク 仮定するわけです。
チェ・スンジュン こう出るはずですね。はい、出ますね。
ロ・ジョンソク それで、もちろんここではattention、これが一つ抜けているのですが、これが抜けていることを、この人は便宜上ここではこう計算の概念のためにやると言っているわけです。ただattentionがsequence lengthの中に入るそのcontext lengthが大きくなると、実際attentionのコストは高くなり、小さくなると減るわけです。ただ実質的に重要なポイントなのでこれはお話ししてから進むべきだと思うのですが、
実際にはこれが長くても全部分割して入れるようなんですよ。例えば私たちが入れなければならない
Claude Codeから送られるコードが5万tokenだとしてもその5万tokenを同時には入れないようなんです。またそれを全部分割して、1000個ずつくらいに分けて他の人たちのdecode tokenと全部混ぜて乗せる
チェ・スンジュン どうにかして埋めるということですよね。そうです。どうにかして埋める。
ロ・ジョンソク それでそういう話を、ちょうどDwarkeshが聞くんですよ。私たちはこの話をほとんど全部したのでではメモリの方にそのまま移ることにします。それでこの式を
チェ・スンジュン いまdecodingされるものを書いているようですね。はい。
ロ・ジョンソク はい、decodingされるものを書きながらずっと進むのですが、実際には私たちはもうこれを置いて計算をすぐ見るのがよさそうです。ではmemory timeはどのように決まるのか。一つ目はN_totalなのですが、実はですね。ここはtotalです。なぜなら、これは全部持っていなければならないじゃないですか。計算するときにメモリにこのモデルweight全体を全部載せて持っていなければならないですよね。そしてexpertの場合にはactivateされるexpertだけ計算すればいいので、そうなるのでcomputeはこれをactiveにしたわけです。そうですね。計算するときは
メモリ時間モデル 全体ロードとKV cacheコスト 48:16
チェ・スンジュン activeなものだけweightを引っ張ってきて使えばいいのですが、メモリを計算するときは全部持っていなければならないということですね。
ロ・ジョンソク そうです。ただメモリを計算するときは全部持っていなければならないのでN totalにしたわけで、その次にプラス、ここに実はこのattentionで上では抜かしていたのですがここではまた入れています。batchに、そして各batchごとにlengthが全部違いますよね。contextがdecodeの場合には1でしょうし、それから誰かがprefillをしている過程にあるならこれはかなり長くなるでしょうし、それに従って、ここはtokenあたり何byte入るのかを掛けてやると、これが出てくるわけです。そうです。ここも実は少し私が
チェ・スンジュン 混乱しているのですが、decodeのときは1なんですか?結局は前でprefillされたものにプラス1ずつずっと進んでいくんです。lengthなので。違います。そうではなく、なぜならその部分が実はスンジュンさんがかなり混乱しやすい部分ではあるんですが、
ロ・ジョンソク 実際にdecodeするときに入るトークンはその前で、つまり直前の段階でoutputされた最後のトークン。それ1つだけがinputとして入るんです。
チェ・スンジュン なぜなら、もう前のKVはあるから。
ロ・ジョンソク そうです。だからinputとして入って、実質的にそのtransformer blockでこのflowに乗るtensorはそのinputトークン1つです。
ただ、そのinputトークン1つが入るとはいえ、それぞれのtransformer blockで、前にあったprefill済みのものでも、あるいは前のdecode段階のものでも、先行contextのKV cache blockがblockごとに全部あるはずです。そうです。全部あります。それはcacheから呼び出すんです。それがHBMにあれば速く処理できて、
HBMになければ別のところへ行ってかき集めてこなければならず、いずれにしてもそれをともかくHBMにloadingしないと計算はできないわけです。その計算をするので、
実は先ほど申し上げたように、この1つのinference batchに非常に多くのユーザーを一緒に載せられるんです。なぜならdecodeの場合はinputトークンが1つだけ通るからです。
チェ・スンジュン そうですね。そういうふうに混ざっているということですね。
ロ・ジョンソク つまり、ここが複雑になる部分なんですが、その代わりユーザーたちのKV cacheは長さがそれぞれまちまちなはずなんです。ある人は長く、ある人は短く、そういうものが。KV cacheは時間が経つと消えるものなので、
チェ・スンジュン またprefillで最初から前の入力まで全部かき集めて、作り直すこともあるわけですよね。
ロ・ジョンソク そうです。もしcacheがhitしなければ、何かを言ってEnterを押したところで急に隣から誰かに呼ばれて、ご飯を食べて戻ってきて、1時間後に来たら、実質的にcacheから全部消えています。そういう場合は、実際にはまたprefillなんです。そうです。またprefill loopをあの前のところから回しながらKV cacheをbuildingしなければならないので、実はinputトークンの価格がそのとき再計算されるので高くなります。
チェ・スンジュン そうですね。高くなるわけですね。でも、もしcacheから呼び出すのであれば、
ロ・ジョンソク cacheがhitすれば安く持ってこられるので安くなり、こういうところにinferenceの経済学があるんです。ただ、KV cacheが先ほど申し上げたようにまた戻って、1つのbatchに複数ユーザーのそうした1つずつのdecodeトークンを載せて、上へそのcycleを計算しながら進んでいくと考えてみると、KV cacheの長さはユーザーごとに全部違うはずですよね。
チェ・スンジュン もちろんそうでしょうね。その違う部分を非常に効率化して、
PagedAttentionとKV cacheのメモリ効率化 52:12
ロ・ジョンソク 1つのmemory blockにただ大量に入れておけるようにするのが、実はvLLMが作ったPagedAttentionという革新なんです。もしPagedAttentionがなかったら、
ユーザーたちのKV cacheを、私たちのtrainingのように非常にstaticなtensorに入れて、空いている部分はただpaddingで埋めなければならず、そういうことが起きるのでメモリの無駄が大きかったはずですが、それをそうせず、ただ1つのblock単位に分けて、まるで私たちがpointerで全部、そのKV cacheがどこにあるのかをすべて指しておくんです。だからその演算が上へ上がれば上がるほど、
そのKV cacheにあるpageを探して、これらのtokenを全部計算してくれる役割を果たすんです。こういうものをどうやって
1つのvectorized演算として全部作るかが、この推論過程の本当にすべてだと言っても差し支えないんですよ。
なので、この会話の途中途中でずっと話すことになりますが、これをする目的は何か。
ただGPU utilizationをmaximizeするために、こうした考慮をすべてしていると思っていただければよく、つまり1つのGPUを決められた時間内にそのようにutilizationをmaximizeして、2千人ずつ同時にservingしなければ、私たちはこれを20ドルずつ払って使うことはできないんです。また気になってくるのが、あとで必ず出てくるとは思うんですが、
チェ・スンジュン 今メモリ、つまりいずれにせよHBMを使っているのが、モデルのweightにも使っていて、KV cacheにも使っていて、そういうことですよね。最近はどこにより多く使われるんでしょうか。
ロ・ジョンソク ここでも算数が必要なんですが、例えば私たちがさっき見てきた最新のGB300のNVL72でつながったあのrack、それだと1rackに
20TB HBMにおけるモデル重みとKV cacheの配分 54:03
チェ・スンジュン だいたい2TBくらい?
だいたい2TBくらい?いいえ。20です。
20。そうですね。20TB、1つが。そうです。1rackに入っているHBMが約20TBくらいになって、
ロ・ジョンソク そしてそこにCPUにもまたLPDDR5が全部つながっているんです。でもそのメモリのサイズもだいたい20TBくらいになります。
それで合計すると…CPU用として?CPU用として。
私たちが普通に知っているRAM、それが20TBあって、合計でだいたい40TBくらいのメモリを持っていて、中にstorageがSSDとしてあるのか、それはよく分かりませんね。
とにかくstorageも…そうですね。それをoffloadingしないといけないわけですよね。あるでしょう。あるとして。でも計算するときは、
普通storageまでは計算に入れないので。
チェ・スンジュン Blue何とかがありました。忘れましたけど。(NVIDIA BlueField)そう考えるとメモリがだいたい40TBあるわけですが、
ロ・ジョンソク HBMには普通、私たちのweightを全部載せますからね。20TBが実質的に、私たちがdeep learning演算をするためにあると仮定してみてもいいわけです。
チェ・スンジュン ではモデルを単にFP8で、つまりbyteとして考えれば、かなり余裕があるんじゃないですか、最近は。
ロ・ジョンソク そうです。はい。5TB、5Tモデルが5TBですから。
5TモデルをスンジュンさんがおっしゃったようにFP8で計算すると、それがモデルをただfullyに積載するだけで5TBの容量を奪っていくわけです。そうです。すると残り15TBが残るじゃないですか。それで多くの方が
また混乱される部分が、ではそこにモデルを4つ積載すればいいのではないか、とおっしゃるんですが、違います。
実際には、これはinputが入ってくるその容量も必要ですし、そのinputがtransformer blockを回るたびにattentionを計算するのに実際には、そのactivationする部分についてメモリが全部必要じゃないですか。中間計算のために、その中間結果値を使って、そのactivationされるvalueを保存することも必要ですし、何よりも一番大きく占めるのはKV cacheですよね。
contextが長かろうが短かろうが、すべてのユーザーのKV cacheを全部持っていなければならないので、KV cacheがかなり占めているんですが、これは配分次第です。ここで実際batchをどれくらい取るのか、そしてユーザーに許容するcontext lengthをどれくらい与えるのか、これによって実際KV cacheの数が決まるわけですよね。
だからそれらには多少のtrade-offがありますが、20TBメモリくらいがあると、5TBはモデルに割り当てて、また実際にはそれよりもっと小さいこともあるでしょう。最近はFP4でもっとかなり減らしますから。だから20TBのうち、
13、14TBくらいはKV cacheに割り当てているようです。そして2TBくらいを中間で計算するactivation variableたちに。
ただ、そのvariableたちはずっとoverwriteすればいいので、それらはそこまで多く持っていなくてもいいです。
チェ・スンジュン ただ、私たちが今、話を少し先取りしたようではありますが、とにかく5Tというモデルを想定したとき、そもそも5Tというモデルを想定すること自体が今問題ではあるんですが。実際、今私たちが知っているのは、1Tから2T程度のモデルのservingで、NVL72が出て5T程度になったのだと推定することになるわけですよね。
ロ・ジョンソク そうです。実際training過程はこれでなくてもできる方法はたくさんありますから、H100やH200 clusterでも5Tモデルを学習させようと思えば、学習させる方法は当然ありますが、こういう大きなモデルを実際にはH100やH200のようにメモリが小さく、その次にNVLinkのようなGPU間通信が非常に小さい、nodeの数が…2023年までは8個が1つでしたよね。
チェ・スンジュン 22年か23年か、とにかくそのくらいだったと思うんです。
ロ・ジョンソク 25年初めまでではなかったでしょうか?NVL72が出る前は。
チェ・スンジュン 出る前は8個でしたよね。
ロ・ジョンソク 8個でしたね。でもNVL72が出てからまだそれほど経っていません。実際。
チェ・スンジュン 2024年末でした。そうです。私たちはこういう発売時期や数字や
ロ・ジョンソク architectureには少し弱いですよね。ジョンギュさん代表がいらっしゃれば、ここで一気に解説してくださったはずですが、今は私たち二人が苦労して勉強しているので、ひとまず今日はそのまま進めることにします。
なので結局、スンジュンさんがおっしゃったポイントは合っています。NVL72になったので、最も新しい現代のあるinference環境ではものすごい利得がある、というくらいに話せばよさそうです。私たちがこのメモリの話をしているうちに突然話がここに飛びましたが、もう一度この数式2つを整理すると、これを理解してこそ、その次のものが全部理解できるんです。なのでこれは当然理解できましたよね?computeは理解しましたし、
batchによるlatencyグラフとamortizeの概念 59:07
ロ・ジョンソク メモリはtotal memoryをloadingするそういう時間、その次にここは、今度はcontextをloadingするのにかかる時間、これらを足したものをメモリ帯域幅で割ったものですよね。結局メモリも、この全体を取り出してくるのに時間がかかりますから。
チェ・スンジュン 分母に少し全部、時間termがあるのは、これがtを計算するものだからですよね。さっきのFLOPsもfloating point、浮動小数点をper secondでどれくらい計算するのかで、今も帯域幅をbyte per secondにしたものなので、結局は
ロ・ジョンソク 隠れていた秒が
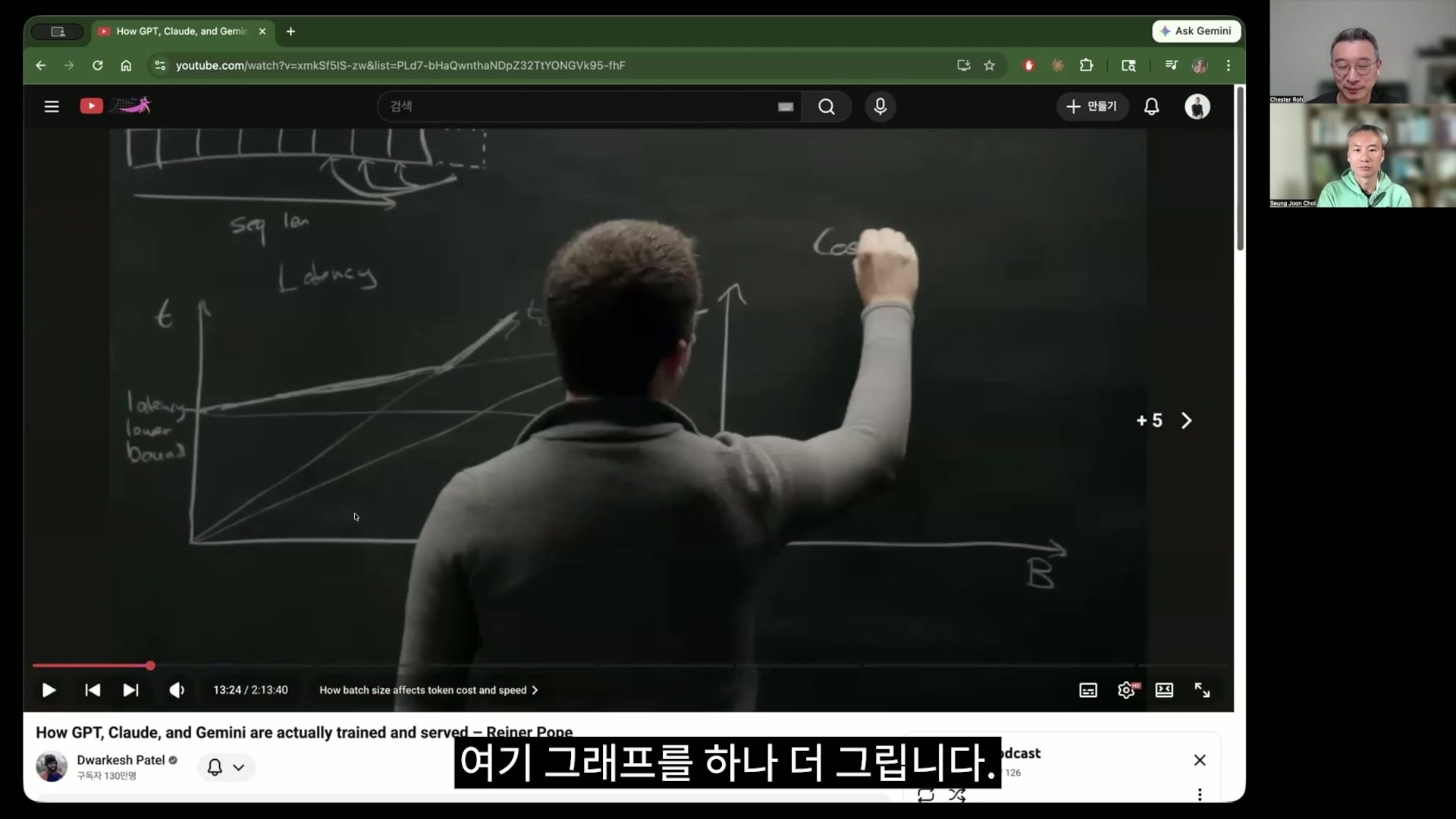
チェ・スンジュン tとして上がってくるわけですよね。そうです。算数ですよね。だから上下にあるその核心は全部容量ですから。なので結局、秒が出てくるわけです。それでこの2つを使って、現代のLLM inferenceがいったいどこで時間がかかるのかを見ようということです。だからこれとt_memoryがbatchとcontext lengthに大きく影響を受けるという話をしているわけです。では進んでみましょうか。そこでこのグラフを、私が字幕を少し消します。このグラフを描くことが、今日理解する上で非常に重要じゃないですか。この右側のx軸にはbatch、つまり1 timeあたりユーザーをどれくらい処理するのかというこのbatch sizeと、それによってかかる時間、これの関数をこれが描いてみるわけです。そうしながら、この前にあるこのtermたちで私たちが算数をします。t_computeは実際ここではbatchに対する線形関数でしょうから、これをこう線形に描いたわけで、その次にこのメモリ時間で、total memoryをloadingする時間は、一度loadingすればその後はずっと取り出して使えるので、だからここに非常に大きなintuitionが1つ入っていますよね。このメモリを一度載せてしまえば、これは長く使えば使うほど、実際そこにかかったコストを相殺できるわけですから、この表現ではamortizeするといって、分割償却するという話を会計用語から持ってきて使うんですが、その話を非常によくします。amortizeは何度も出てきました。それから、その次のグラフを描くのがこのKV cacheを持ってくる時間ですよね。ただ、これはbatchが長くなればなるほど当然KV cacheをloadingする時間は長くなるはずなので、これも、ではなぜcomputeより下に描いたのか。これはただこの人の好みです。だいたいこのくらいでこのcache timeが増えるだろうと話しているわけです。ただ今、N_totalとN_activeは違いはありますが、ざっくりまとめて扱ったんですよね。そうです。ざっくりまとめているわけです。ただcomputeには実際、N_totalは影響を与えませんからね。なぜならN_totalはメモリ側の変数であって、computeするときはあの total memory がコンピューティングする時間に何の影響も与えないんですよ。なぜなら active なものだけを計算するからで、そういう話だと受け取ればいいです。ではここで、さっきのこの人のグラフがよく見えるようにしてみましょう。あそこがまた掛け算ではなく足し算だったので、いずれにしても。そうですね。でもここでですね。これ、スンジュンさん、次に進む前にさっき DeepSeek の話で見たものが、ここに大きく影響するんですが、この KV cache time と、この t_compute time、この2つの線形グラフがあるじゃないですか。そうですよね。このグラフの傾きによって実は時間とコストを全部説明しているわけです。でも DeepSeek がこれをぐっと下げたことが問題なんです。これが下がることで、すべての frontier curve が全部下がるわけです。そうすると交点も下がるので、それに関する話をすることになりますね。それで、それについての話をこれからすることになります。なので、この compute の青いグラフはさっきの compute から来ていて、KV cache と、単に total parameters をロードすることにこの線形関数、この2つをこれが足すわけですね。常識的なレベルで、私もハードウェアは詳しくありませんが、HBM がいくら速いとはいっても on chip ではなく、GPU の横にあるものじゃないですか。だから時間がかかるんですよね。そうでしょうね。だから今、そういうものがコストに入っているわけですよね。あまりにも多くのものが絡み合っていて、私は今回のセッションが、このハードウェアの形と、それから実際にアルゴリズムが動くことにそれがどこでかみ合って入っていくのか、そこについてこうスパークを飛ばしてくれるのがよかったんです。ではまたこのグラフに少し戻ると、難しいですが、これは算数ですが難しいです。それで、さっき描いた t_compute と t_mem をこれがここのグラフに図式化したもので、さっき描いたこの少しピンク色のグラフがKV cache これと、それからこの total parameters をロードする time、この2つをただ足したものです。2つを足すと、実は中学校のときに習ったあれが出てきますよね。これが出てくるわけです。実質的にこれが t_mem ですね。そして結局 t_mem は、さっき一番最初に見ましたよね。私たちが認識する total time は何か。ここに bound される。この2つのうち max であるものにbound されるということが出てくるわけです。でもあの折れ曲がる部分が B とつながるわけですね、今。そうですね。あの折れ曲がる部分がどうなるかによって、ハードウェアのスペックやモデルの形などによって全部変わるでしょう。すると、私たちが一番最初にやったことは、max 関数を置いて、2つのうちどちらが大きいかに bound されるという話でしたが、t_compute に bound されるものと、t_mem に bound されるものが2つのうちより大きいものによって bound されるわけで、今それが B によって決まるということですね。なので最適な B 点をうまく決めると意味があるという話をするためにこれをやっているんですが、ここを見るとこれですね。バッチが小さいときはメモリに bound されて、そうですね。バッチが大きくなると compute に bound されるというintuition が出てきますね。意味が。なのでこれは、実質的にこれが T なので、T とは何か。latency のことを言っているんですよ。つまりどれだけ長く待たなければならないか。だからここは、どんな小さな task を始めるとしても、この weight を全部ロードする時間は基本的にかかるので、これを latency lower bound と言っているわけです。なので latency と言って、このように latency lower bound という表現をして、このグラフは latency のグラフです。もう1つ描きます。さっき私たちがした説明を、ここでします。latency が気になる方は、この間にしていた説明がこれです。スンジュンさんと私がさっき交わした会話のように、では attention の何が減ればあれが減るのか、増えるのか、こういう話をしましたし、ここにグラフをもう1つ描きます。cost、トークンあたりの cost なんです。でもこれですね。これが割り算で入っていますね。そうですね。結局これは、全体時間をバッチで割ったものなので、これがどれだけ処理したのか、単位時間あたりどれだけ処理したのかを表すんですよ。するとこれもやはり B、x 軸はそのままにして、このグラフの y だけをもう一度変えるわけです。算数ですが、算数ですが、この内容をしっかり追わなければなりません。あの前で t_compute はただ linear に増加するグラフなので、ここではただずっと線を引くことになります。割ってしまったので。これは理解しにくいと思います。初めて見る方は、バッチから T から latency から、私たちが話している term が頭に入ってこない方も非常に多いと思うので、これを無理に理解しなくてもいい。重要なのは、私たちは結論だけ切り取ってもいいということですが、結論を切り取るために、スンジュンさんと私が久しぶりに思考トークンを今回してみることにしたわけなので。私たちが勉強したということですね。ではここに今描きます。t_compute はここでただ linear だったので、ここにある B 割る T なので、ただ直線になるはずで、直線になって、KV cache はこれより傾きが少し低い linear グラフなので、その下にただ線になるはずで、そしてこのメモリは左側ではただ直線だったので、これを B で割るとどうなりますか?この parabola になるでしょう。こんなふうにずっといって、こういう関数になるでしょう。そうですね。ではここでも t_compute はただ決まっていて、t_memory が実はこの KV cache とこれの和なので、ではここで計算するとどうなるでしょうか?当然ですが、上にもう1本線ができるでしょう。上にもう1本線ができることが、実質的には t_memory の bound であり、max で計算してみると、この決まったかかる時間は、T は常に compute bound とこの memory bound の中で、より長くかかるものに制約される。bound されるというのが、もともと最初の出発点の前提でしたから。でもこれに似たものが、まったく同じではありませんが、似たようなものが、Jensen Huangの今回のGTC keynoteでもtoken economicsの部分で出ていたと思います。似た感じで。全部同じではないでしょうか。それでこれをそのまま計算してみると、こうなるわけです。どうやってか。このトークン価格は、これが価格ですよね。そして縦軸はcostになりました。トークン当たりのcost。トークン当たりのcostは、batchが低いとすごく高くてbatchがある程度になると、このcompute boundで、今度はこれのせいでさらに多くなるわけです。ここにboundされるということを話しているわけです。すると、結局これは次のページにつながる話なのですがこの地点をどこに置くかによってoptimumが生まれる、という話をしてくれます。私はこの部分、この次の話は生まれて初めて聞きました。生まれて初めて聞きました。ああやって計算すればいいんだなということは私たちが計算も考えもしたことがなかったという事実を私も知ることになりましたし、これを理解すると実はIDCの価格が、ハードウェア価格をあれだけ投入して私がトークン当たりいくらで生成するのか、その価格をinput token 100万トークン当たり5ドル受け取り、それからoutput tokenは10ドル、15ドル受け取り、こういうものを計算するとそのフロンティアラボたちのinference farmの経済性や歩留まり、そういうものが改善できるのだろうと。この方たちがreverse engineeringしたわけですよね、一種の。価格を使って。そうですね。それをすることについての観点が私にも今回初めて生まれました。それでこのグラフを描いてくれたわけです。それでこの議論をしながら、batchをいくつにするのが最善なのか計算してみよう、という話をします。ただ、この計算は正確ではありません。繰り返し言いますが。この方たちもroofline analysisと言っているんですよ。ただ天井にぼんやりした線を引いて大きな思考実験をしてみるのであって、正確な計算ではない、という話を途中で何度もします。なぜなら、この次に進むと、この正確ではないということが計算されるからです。あのルートをかぶせた部分も、実は面白くはありましたけど。sparse attentionの部分ですよね。その話はまた後ろで一度だけしましょう。ここで結局、仮定を置くわけです。これが結局バランスになってこのthroughputをmaximizeする地点は、computingする時間とmemoryする時間が同じになればその2つが調和してうまくやり取りするはずなのでその地点にbatch sizeをmaximizeすればよい。そういう話をしながら簡単な数式を1つ持ってきます。これ、どこに行ったかな、ここで。このメモリ帯域幅とN_totalはこのT_memからattention部分を全部取り除いてただこれだけを持ってきたものです。attention部分は実は非常に重要で大きな部分なのですが計算の便宜のために、これを取り除いてしまいます。今、何かequalに置いていますね。等式として。そうなんです。これはT_computeで、これがT_memじゃないですか。同じ時間だから。そうです。memory timeでは、ここにB関数が入っているのですがそれを取り除いて、ただ便宜上この2つを同値に置きます。するとそのままequationになったわけですね。算数が出てくるわけです。この算数が出てくるわけです。これをプラスを下に持っていって、こう位置を入れ替えたわけです。Bの値を計算するために。そうやって計算してしまうと実質的には、全体でロードされるこのパラメータ数に対するactivationされるパラメータ数の比率が出てきてこれ、どこかでよく聞いたものですよね。sparsity。そうです。私たちがDeepSeek論文とKimi論文を扱いながらずっと話していたsparsityの話ですよね。そしてsparsityについては論文が多いです。それがなぜ成り立つのかについては、私もまだ理解できていませんがこれを広げて、total parametersのサイズを大きくし、sparsityを増やしてただactivateされるパラメータを少数にしたとしても性能上の利得があるということを今、私たちは発見したわけじゃないですか。heuristicみたいなものですが、何かあるのでしょうね。まだ分からないそうです。それでここで実質的に先ほどスンジュンさんがおっしゃったように右側にある項はsparsityになるわけで左側にある項がFLOPs / メモリ帯域幅なのですがそうですね。FLOPsも実はハードウェアで全部決まる数字でメモリ帯域幅も、そのまま全部決まっている決まっている数字ですよね。ただ確かなのはH100、H200、GB200、GB300、Rubinと進むにつれてすべての数字は良くなります。FLOPsも良くなり、HBM容量も大きくなりそしてHBMの帯域幅も大きくなります。ところが面白いことにこの数字が合っているかどうかは分かりませんがこの人たちもただguesstimationをしているのですがFLOPs / メモリ帯域幅の大きさはハードウェアが発展し続けているにもかかわらずFP4を仮定したとき約300の倍率を維持している。ここで300という数字が出てきたわけです。それがmagic numberのような感じではありますがとにかく300だと。そうです。すると、これでBの計算がそのままできるわけです。batchの計算が。それでいくらになるのか。Bは、あの300という数字とsparsityを掛けたもの。厳密に言うと、sparsityで割った数字でなければならないわけです。sparsityは分数ですから、例えば最新のsparsityがだいたい8分の1から12分の1になるので例えば8分の1だとします。計算してみると、batchが8掛ける300で、2400。これはたぶんDeepSeek V3の例でやっていませんでしたか。はい、V3でやりました。それで2400だと。その8だから。おそらく私たちが今年の半ばを過ぎて来年の初めになると実は単なるMoE関連のこうしたguesstimationではなくsparse attentionまで計算に入れたものを議論しているでしょうね。そうですね。でも実は私はDeepSeek V4が私はDeepSeek V4を今メインモデルとして使っているんですよ。もちろんCodexを回すときはGPT-5.5を使うんですが、私が普通の業務をして、自分のEmacsから呼び出すモデルはDeepSeek V4をつないで一度使っているんです。いいですよ。これはClaude Opus級だ。その級だとは言えませんが、確実なのはClaude Sonnetよりはいいです。確実に。そうなんですか?APIで使っているんですか?APIを使っています。AI APIの料金がものすごく安いんです。DeepSeekが。今またリリース記念割引までしているので、さらに安いんですが、私は2ドル入れておいたんですが、2ドルを使い切るのも大変です。このコーディングワークロードを回さない限りは。私がただ自分のものをあれこれやり取りして、自分のEmacs Roam Notesで回す用途では、今1ドルも使い切れていません。正直。なのでここで見ると、メインの話に戻ると、あのバッチをいくつにするかという部分に、実は今日の核心的な内容が全部入っているんですが、sparsityを高めるとバッチを大きく使える。バッチを大きく使えるというのはどういうことか。1サイクルあたりにサービングできるユーザー数をはるかに増やせるということです。それはどういうことか。すると結局GPUを買ってNVIDIAに払ったお金と、単位時間あたりにかかる電気代は固定なので、結局フロンティアラボの立場では、これが単位時間あたりにより多くのユーザーをサービングすることが無条件に利益だという話なんです。逆に言えば、それだけのユーザーを集められない会社は不利ということですね。そうです。つまりトラフィックが全部遊んでいるわけです。減価償却をずっと食らいながら、実質的に回せていないので、そういう計算をするんです。Bでsparsityの計算をして、その話をしばらくして、広告に入ります。広告も面白くやっていましたね。はい。この広告を出している会社がJane Streetという会社なんですが、それなんです。quantの会社なんです。ただアルゴリズムでお金を稼ぐ会社ですが、よく稼いでいます。それから次の話に移るのが、電車の話の少し前に、電車の話でしたね。電車の話、この話をします。inferenceをするとき、1回の演算サイクル、このクロックがなぜそう決まったのかは分かりませんが、これが20ミリ秒くらいだと言っています。これが1つのバッチを満たして、そのバッチを演算させて、そうすると上の方がprefillならLM headはないでしょうし、decodeしたものならLM headがあるでしょうし、ということで、値が出てくるわけですよね。この前の乗り場でトークンが乗ったら、それが一度ずらっと全部演算をして、あの上の乗り場で降りるんですが、そこまでにかかる時間がだいたい20msになるように調整すると言っているんです。tensor計算だけをするのではなく、いろいろ合わせて20msということですよね。はい、ただその20msの境界を決める非常に重要な変数を、ここに今書いていますが、メモリ容量をこの帯域幅で割った値なんです。するとその容量。混乱するのは、計算ではなく、バッチだけを今これで考えていたんでしたっけ?バッチを含めたものなんですか?バッチと計算を全部含めたものです。なぜならメモリロードとcomputeは常に同時に回るからです。そのメモリcomputeよりは、メモリが遅いのは確実なので、ここで下に書いてありますよね。300の差があるじゃないですか。FLOPsの方がはるかに速くて、メモリを行き来するのは遅いんです。なのでその比率が300程度で維持されているという話をしたわけで、だからこれは一度に演算が起きるそのサイクルを何を基準に組めばいいかというところで、この人もguesstimationをものすごくたくさん使います。guess + estimation。そうです。そこでこのdrain timeという用語を持ってきます。このdrain timeはHBMメモリが288GBで、GB300基準でその帯域幅がもう20TB/sなので、バイトですよね。ビットではなく。バイトです。割ってみると、あれは上が容量なので、Bが消えますね。はい、そうすると分子としてsecondだけが出るじゃないですか。そのsecondが20ミリ秒だと。最新のGPUは15、次に古いものは40ですが、その比率のために、おおよそ20から30ミリ秒くらいがこれは維持される。300を20で割ると10、とにかく。300を20で割ったものなので、あれは15にならないと合わないですよね?そうですね。まあ、とにかく、行ったり来たりするという。ざっくり20から30ミリ秒くらいが、このHBMが全体メモリを一度全部読み出す時間だと。つまりそれが20msなので、20msを基準に1サイクルを組めばよさそうだ、というものを作ったわけです。その中でweightも引っ張ってこなければならないし、バッチも作って埋めなければならないし。はい、なので実質的に私たちはいつもtraining側にばかり関心が多くて、inference側でこのハードウェアとどのように組み合わさりが起きているのかについては、実は私も最近までこれを考えたことがなかったのだと気づきました。考えたことがないんです。ただJensen HuangがFP4がどうなって、何がどうなって、そうすると自分がClaude Codeを200ドルならどれくらい使えるのか、というところまでしか考えが浮かばず、これがどのように発展しているのかについてはまったく計算していなかったんですが、今回これをやりながら、私もかなりきつめに一度全部計算してみたケースになりましたね。この回を見たあとに、その前の回であるJensen Huang回を見ると、また違いそうです。そうです。なので結局この話の核心に移っていくわけですが、そこで最近のある、ここでReiner PopeとDwarkeshが話しているわけではありませんが、それから私がChatGPTとClaudeにこの内容を渡して、私にあれこれ教えさせながら最新のservingアーキテクチャであるvLLMやSGLangなどが内部で一体何をしているのかについてこれに合わせてAIが私に一通り教えてくれたんです。驚きました。ただ核心だけを見ると、結局20msに一度ある演算を実行するのですがその演算にどれくらいのbatchを詰め込むのがよいのかというのはここではだいたい2400から3000くらい。かなり乱暴に要約すると、結局20msに一度出発する演算列車にbatchの最適値はいくつだ、と言ってくれているわけですがそのbatchをどう取りこぼさず、ぎっしり詰めて送るのか。そうするとユーザーが何万人も、何千人も同時に接続してその人たちがClaudeにかけるワークロードは本当に多様じゃないですか。ある人はClaude Codeを持ってきて、ある人は「こんにちは」を持ってきてある人は何か別のものを持ってくる。そうやって非常に多様なワークロードが来るのですがそれをどうorchestrationすればそれぞれのrackにある列車が毎回20ミリ秒分のtokenをぎっしり詰めた状態で回れるのか、ということです。そしてそれを可能にするようなアルゴリズム上の改善がvLLMや、あれはどこでしたっけ?SGLangなどに非常にたくさんあります。batchごとにKV cacheがすべて変わる部分はどうPagedAttentionでメモリ容量を減らしながらそれぞれのtokenが保持しているKV cacheのポインタを効率よく持ってきて一度に演算するのか、という部分でもあります。それからdecode過程では実際inputは一つずつしか入ってきませんがprefill過程では非常にたくさん入ってくるじゃないですか。でもそのprefillとdecodeを一つのワークロードでどう同時に処理するのか。ではprefillが非常に長くなると実際には一つだけdecodeするものたちがそこに押しのけられる可能性があるのでprefillも5万tokenのものが入ってきたとしてもそれを非常に細かく分けて、あちこちに入れるんです。そうやって入れて、それをchunked prefillと呼んでいたのですが、そういう形です。ただ、ここで言っている2400というのはユーザーが2400人という意味ではないですよね。ユーザーはもっとずっと多くなければならないわけじゃないですか。違います、違います。そうではありません。batchが2400だと言うならですね。厳密に言うと、あるユーザーがもしdecode段階で実際その正確な数字はハードウェアなどによって違うでしょうが例えばメモリ状況などによってすべて変わるでしょうが、2400 batchでそれが全員decodeだとするとただの2400バイトです。では、その高価なものを2400人が同時接続して使うというのはただ、trainごとということですから。そうです。trainごと、1サイクルごとに2400人ずつ乗るということでただ、もし2400バイトとして、そのlengthは固定しておきます。そうしてこそ、このすべてをそれに対してoptimizeできるわけですから。だからそういう形でcomputationを規格化してoptimizeできるわけです。ところが一方で、一方でKV cacheの場合はユーザーごとに状況があまりにも違うんです。ある人は短く、ある人は長い、こういう状況のためにある程度以上のワークロードになると実際にはmemory boundになるわけです。KV cacheのために、すべてがcompute boundではなくmemory boundの問題に転換され得るわけです。つまり今、前段で解いたのはcompute boundになるものに関する数式だったんですね。300掛けるsparsity。はい。ただ、ここを見ると、ここに見えるのですがもう少し説明しながら進むと話がところどころ飛びはしましたがそのvLLMやSGLangやこういったものがこれをoptimizeするために本当に過酷なconsiderationがなされている、という話を私はしたかったんです。そしてフロンティアラボの本当の、彼らの資産、moatと言えるものはこうしたエンジニアリングインフラ能力だと思います。このエンジニアリングインフラ能力が最も核心になってきていると思います。どうハードウェアをよく理解し、ユーザーのワークロードをうまく扱ってこのserving throughputを増やせるのかというのはこれは非常に重要な技術です。そしてこれらを外部にすべて共有してはいません。ワークロードごとに、あるワークロードは実際には「こんにちは。」「何してる?」という具合に、非常に短いcontext lengthがどんどん落ちてくるそういうワークロードがあり得ますししかしそういうものはユーザー数を増やして受け入れられるわけです。そうすると安くなるべきですよね。でも、もし何らかのchunkに分けるとしてもcontext lengthが長くなるワークロード、コーディングやこういったものを見ると実際、1000kから数万kくらいまでは普通に出るじゃないですか。そういうものは、どのユーザーを乗せるかという点でつまりユーザー数が少し減るでしょう。なぜなら単位rackあたりcomputationとメモリが限られているとするとinputが短いユーザーは、ユーザーをより多く受け入れられinputが長いユーザーは、ユーザーを少なく受け入れなければならず、こういうことはすべてすでに決まっているわけですから。そうです。ただlong-contextになったとき実際、このグラフで言っていることをかなり乱暴に要約するとcomputeとKV cacheが均衡する、そういう地点があるじゃないですか。でもその地点を越えてしまうと実際、このグラフで見えますよね。computationが余る時点になるわけです。computationはいくら速くなってもメモリがそれについていけないため全体的な速度がすべてmemory-boundに落ちるそういう時点が生じるのですが、KV cacheの長さのためにそれがこの方々の推定ではそのoptimal pointが200kくらいのようだ、と。だから価格をそう設定したことから逆算したわけですよね。実際。そうです。だから200k以下のものはすべて同じワークロードで処理してもそれが大きな支障を与えない程度にoptimizeされているのですが、200kを超えると、それを処理するためにユーザー数を著しく少なく受け入れなければならないそういうGPUクラスターがあるわけです。そして多くのコーディングワークロードやそういったものが、そちらに配置されている可能性があり、そこは実際、提供者の立場では少し高く取らないといけないそういう領域なんです。つまり、これは経済性の原理ですね。こういうものを使って逆算をずっとしてみると、Googleでも、私たちが秒あたり何トークンを処理しているかをたまにカンファレンスで発表するじゃないですか。では、その発表内容を計算して逆算してみると、ああ、ラック1台が全体のトークン処理量のうち約1,000分の1を担っている、つまり結局ラックが1,000台くらいあるだろうという推定もできるわけです。そうですね。それから、このお二人が話している中に、そういう話がありましたが、結局は価格をコスト近辺に設定していて、なぜなら競争状況だから、それによって逆算が可能だ、そういうニュアンスを話していたと思います。そうしたフロンティアラボが意図せず、今情報を出していた。つまり、彼らがAPI価格として掲げているそういうものを見ると、彼らが内部的に持っているある種のtoken economics、それがどのような形で構成されているのかを示している、という話ですね。そして、そのcacheの価格の話をしながら、私たちは少しこう考えるとよさそうなのですが、私はClaude Codeで作業をしています。では、その作業を続けている間は、実質的にKV cacheがどこかのマシンのHBMに載っているはずじゃないですか。そうすると、私が行う作業はずっとそのマシンに送るほうが絶対に有利ですよね。でも、私がちょっと水を飲みに来ている間にも、これが1分以内に来るのか、30秒以内に来るのか、10分以内に来るのか、実際そのAIは、そのGPUファームは分からない状況で、だから一定期間、例えば1分はHBMでそれを保持しているわけです。メモリ上でそのまま待つほうが、これを消して別のユーザーのワークロードを受け入れてしまうよりも利益になる状況があるので、それがcache戦略なのですが、だからHBMにあればすぐhitするわけです。でも、私が10分ほど遊んで戻ってきたとします。そうすると、これを10分間HBMに保持しておくのはまた彼らにとって損なので下ろしてしまうわけで、下ろす段階がCPUの横にあるDRAMへ下ろすこと、それが1段階くらい。次にflash driveに載せるのが2段階。あるいは本当に伝統的なHDDに下ろしてしまうのが4段階。こういう形でやって、それすらもすべて時間がexpireしてしまったら、すっかり消してしまう。そういう形でcache価格がずっとそれぞれ違ってくる形も実はこうしたdynamicsの中にあるわけです。私たちはまだ2年しか経っていないじゃないですか。これがAIはすごいだの何だのと言っても、Claude Codeを本格的に使う前までは、私は全部子どもの遊びだったと思うんです。ただChatGPTに入れて、何かを入れて、というものを見ると、ワークロードはそれほど高くなかったのですが、実際Claude Codeが出て、Codexが出てくる中で、これらが使うinference量が本当にものすごく増えたじゃないですか。そしてthinking tokenも大量に回し、thought token、reasoning tokenも大量に回し、そのうえ途中でtool callが一度行って戻ってくると、tool callが読み込んでくる情報もすべてprefillしなければならないデータで、だからcontextをどうmanageするかが最も核心的なbottleneckになってしまい、それらが最大の技術発展において最も重要な要素になってしまったという気がします。モデルをtrainingすることとはあまり関係のない、完全にinferenceとservingのinfrastructure技術なんです。この部分は、私たちがあまり認識できていませんが、実際には非常に多くの重要な核心が入っている部分だと考えられると思います。それで私たちは実は、この2時間の講演のうち冒頭30分を見たわけです。30分見た話をこんなに長くしましたが、後半は実は、ここへの理解をもとにさらに面白い内容がずっとあるのですが、それは一度宿題として残しておきます。だからDwarkeshは本当にすごいと思います。そうですね。この人にしかできないコンテンツです。正直に言って。では一度、スンジュンさん。Dwarkeshがこれを準備する過程もまた面白かったです。それでDwarkeshが、自分がこれをどう勉強したのかをflashcardを作ってやったものを、私がCodexに翻訳させてみました。それで、もともとあったものの韓国語版を作ったんです。これは自分で当ててみようとして、こういうものを自分で問題として出して、知っているか知らないか、そういうことを確認しているようです。これは私たち、扱いましたよね。1回のforward pass、1回の時間の方程式は何か。そしてT_computeの方程式は何か。ロさんが一生懸命説明してくださいましたが、暗記してはいません。私も。でも何が入っていましたっけ?何が入っていましたっけ?これ、これactive plusです。はい、batch掛けるactive。これをつまりDwarkeshも一番重要なものとして一番上の3つに挙げたわけです。T_mem、ここは少し長くなっていましたよね。sequence lengthがあって、そうですよね。これ。それからlatencyの線を描いてみよ。これは時間をかなり使って話しましたよね、これ。そういうことはあり得ますね。weight fetch lower bound、これはどこから来るのか。lower boundの話をしましたよね? 何でしたっけ?loadingするtimeがlower bound。メモリ。メモリのために。とにかくこういう形で、自分でもずっと勉強していたわけです。それで私はここにもう一つ付け加えて、この内容が講義のどの部分にあるのか、そういうものを作ってはおきました。いいですね。こういう欲しかったものを、Dwarkeshもこれをワンクリックで作ったんですが、そうですよね。スンジュンさんがそれをまた持ってきて、これをするのをまたワンクリックでやったと。クリック、クリック、本当にいい時代に生きています。ただ問題は、私たちが今日ずっとこれを、互いに話しながら、こうやって反芻していたじゃないですか。知っていることを話してみて。これがないと、実際すぐに飛んでいってしまうんですよ。これを作ったからといって、自分のものになるわけではないじゃないですか。今日は久しぶりに、かなり頭が熱くなる、思考トークンがたくさん使われるセッションでした。いつも何がどうだこうだと言いながら、instruct modelの形でいつもやっていたんですが、久しぶりに濃く思考トークンをたくさん使うそんなセッションでした。後半にこういう内容も実は面白いんです。中盤だったかな。中盤のtrainingのところで。中盤、こういうものがなぜ6になったのか、こういうことも面白かったんですが、とにかく私たちが全部扱うことはできないので、このくらい紹介させていただきます。そうですね。実は重要な内容は前の方でかなり使い切ってしまったので、後ろの内容は皆さんがDwarkeshを直接追いながら一度ずつやってみると、もっと面白い内容がいくつかあります。私も本当に締めくくりに宣伝を一つします。こどもの日の頃なんですが。久しぶりに子ども向けの展示を一つやっていて、ここ京畿道にある想像キャンパス、水原の方にある場所で体験展示に参加しているんです。スンジュンさんが参加されています。それで私は最後の部分にコースとして参加しているんですが、こういうものを作ってみました。それで手で触れて。もちろんこれもAIたちの力を借りて作ったものですが、こうやって手を伸ばして、惑星や恒星のようなものを少し扱えるようにする。それでこうしてもう一度触れるとできて、あれを操作できるんです。そしてここ、このくらいを一度見てみましょうと言って拳を握って待つと、また新しい恒星系が作られる、そういうものを作ってみたんです。そういうことをやってみました、という宣伝を一度させていただいて、今日長い時間、私がこう締めくくるのは少し違う気がするんですが、どう締めくくればいいでしょうか?スンジュンさんが作った作品なんですよね、あれは?そうです、展示が。スンジュンさんの本業はまたメディアアーティストでいらっしゃるので、こういうものをなさっていて、今展示中ですから、関心のある方は一度訪れてみるといいと思います。それでは長い時間、今日。内容が本当に難しくて大変で、私たちも頭が熱くなって。このDwarkeshのポッドキャストは本当に学ぶことが多いです。そしてこの人はいつも、どうすれば知識のfrontierをさらに前進させるべきか、そしてそれを少しわかりやすく話して大衆に伝えるべきか、何か明確にポジションを取ったように思います。それで今日は長い時間、探究の過程だったんですが。Dwarkeshが最近、NYTにもまた記事として登場していました。でも見ると、本当に一生懸命勉強しているんです。インタビュー相手に一人会うと、2週間ほど勉強するそうです。それを私が翻訳しておいたんですが、どうしてDwarkeshがこれほど人気があり、人々が期待するのかという理由は、他の誰にもできないような質問をしてのけるからだそうなんです。ですから、そういうDwarkeshの勉強の仕方のようなものにも、今日の文脈でもう一つ階層があるとすれば、こういうものをどう掘り下げたのか、Dwarkeshがこういうものをどう学び取ったのかということも、見てみるポイントになるのではないかと思って、それを締めくくりに。おかげで私たちも休日に頭に汗をかくほど勉強してみましたし、本当に多くのことを知ることになった貴重な機会になりました。お疲れさまでした。今日はお疲れさまでした。休日に遊ばず仕事をした、ということで。では、残りの休日もゆっくりお休みください。お疲れさまです。