EP 92
EP 92. 루프를 닫아라
Andrej Karpathy와 Terence Tao 이야기 예고 0:00
노정석 녹화를 하고 있는 오늘은 2026년 3월 28일 토요일 아침입니다. 저희가 지난주에 강화학습 RL을 이용해서 컴퓨팅 자원을 투입하면, 그리고 보상 신호를 확실하게 만들 수만 있다면 그 도메인은 쉽게 정복된다는 이야기를 했습니다. 앞으로는 컴퓨팅을 이용한 search problem으로 모든 문제가 해결될 것이라는 이야기와 함께 비즈니스 관련 이야기들도 해드렸는데요.

그 사이에 Andrej Karpathy가 Sarah Guo와 함께 또 한 편의 팟캐스트를 찍었는데, 거기에 나온 내용들도 저희가 이야기했던 내용과 매우 비슷합니다. 그래도 Andrej Karpathy의 이야기를 한 번은 짚어보는 것이 의미가 있기 때문에, 오늘은 Karpathy의 이야기 그리고 덧대어 Terence Tao, 승준님이 매우 좋아하는 수학자죠.
Terence Tao가 Dwarkesh Patel과 인터뷰를 한 내용 그리고 그 행간에 있는 내용들을 한번 짚어보도록 하겠습니다.
딸깍 되는 일 vs 딸깍 안 되는 일 0:58
최승준 그래서 일단 오늘 진행할 내용을 앞으로 끌어올려서 두괄식으로 만들어 봤는데요. 요새 마크다운이 국가 인공지능 전략위원회에서도 중요한 포맷으로 밀어주고 있어서 반가운 소식인데, 저도 재미 삼아 3D로 마크다운 렌더러를 만들어 봤습니다.
일단 딸깍 되는 일은 쉬운 일인 것 같습니다. 뭐든지 쉽게 되고 있으니까요. 그런데 딸깍으로 만든 것이 자신에겐 가치 있을 수 있지만, 다른 사람에게도 가치 있을지는 모르는 일이라는 생각을 요새 하게 됩니다. 그냥 쉽게 만들어지니까요.
그래서 Andrej도 ephemeral software라는 용어를 쓰더라고요. 복리를 굴리기도 쉽지 않고 재미있게 만들어지기는 하지만 덧없을 수 있다. 그러므로 딸깍 되지 않는 일에 도전해야 하는데, 딸깍되지 않는 일이 앞으로도 딸깍 안 되리라는 보장은 없으니까 어떤 것은 시간이 지나면 딸깍 될 수 있는 딸깍 후보의 일이라는 생각을 해봤습니다.
연장해서 연결해 보면, 딸깍 후보는 기다리면 되는 상대적으로 가치가 적은 쉬운 일 후보가 아닌가 하는 생각도 해봤고요. 물론 그 시간을 의미 있게 기다리면, 시간이 충분히 길다면 의미가 발생할 수는 있겠죠.
그러면 소거법으로 남은, 앞으로도 딸깍되지 않을 일은 무엇일까. 안 되는 일이고 안 될 일이지만 그래도 가치는 생산하는 일이 혹시 있을까, 그런 고민들을 해봤습니다. 오늘 이야기가 이것과 관련이 있을 것 같은데요.
어디로 도망갈 것인가 2:37
노정석 이것이 저희가 항상 어디로 도망갈 것인가라는 질문과 맥이 맞닿아 있는 일이죠. 당장 할 수 있는 일이지만 남도 다 할 수 있는 일이라면 상대적 가치는 굉장히 떨어지기 때문에, 나만 할 수 있는 일, 그리고 시간의 상대적 우위를 오랫동안 지킬 수 있는 일, 그런 일들에 대한 질문이 요새 굉장히 많습니다. 사람들이 다 이런 고민을 하고 있습니다.
최승준 맞아요. 정규님도 될 일이면 하지 마라, 그런 얘기를 벌써 한 달도 넘게 전에 하셨었고요. 그래서 그런 고민을 앞에 두고 한번 이야기를 따라가 보겠습니다.
Andrej Karpathy와 Sarah Guo가 말하는 manifest의 시대 3:18
지금 여기가 코드 에이전트, 오토 리서치, 그리고 루프의 시대에 관하여라는 제목인데, Sarah Guo가 Andrej를 다시 센세이를 초청한다, 선생님을 초청한다 하고 포스팅을 올렸고 거기에 Noam Brown이 댓글을 단 것이 재미있는데, 이따가 한번 소개해 보겠습니다.
manifest의 시대라고 해서 manifest라는 용어를 처음부터 소개해 줍니다. manifest라는 용어를 어떻게 보셨나요?
노정석 Sarah Guo가 express my will, AI에게 나의 의지를 표현하는 행위를 하고 있는 것 같다고 했습니다. 요새 나머지는 AI가 알아서 해주니까라고 하니까, 그 express my will이라는 표현을 Andrej가 manifest라는 것으로 살짝 바꿔주죠. manifest, 이것이 한국말로 딱 맞는 단어는 없는 것 같은데 발현이라고 번역해 두셨나요?
최승준 현현, 발현. 그래서 의지를 가지고서 뭔가를 실제로 이렇게 나타나게 하는 그런 쪽인 것 같습니다.
그래서 보통은 manifest.json, JSON 파일이 있고 그런 게 먼저 떠오르는데 여기서는 약간 다른 뉘앙스로 쓰이는 것 같기도 하고요.
여기 보면 재미있는 표현이 초반에 AI psychosis라는 표현이 나옵니다. 정신증으로 일단은 번역을 해두긴 했는데, AI와 강박적인 관계, 집착적인 관계, 계속 시켜야 되고 쿼터가 남아 있으면 불안함이 생기는 그런 것을 이야기하더라고요.
노정석 요새 많이 하시는 분은 Claude Code나 Codex 같은 것을 8개씩 띄워놓고 일을 시키시던데요.
Andrej Karpathy의 코딩 습관 변화 5:01
최승준 Andrej가 10월에는 톤이 많이 달랐어요. 그때 Dwarkesh Patel과의 인터뷰에서는 아직 여전히 차근차근 천천히 가는 부분이 있고 Tab 위주로 한다고 했었는데, 금방 바뀌었죠.
지금 12월 이후로는 코드 한 번 타이핑한 적이 없다고 합니다. 예전에는 10월 정도에 80대 20으로 얘기했다가 지금 20대 80으로 바뀌었다고 하면서, 달라진 요즘의 모습을 고백했고요.
재미있는 게 Peter 워너비가 됐어요. OpenClaw 만든 Peter Steinberger, 나도 Peter같이 되고 싶다.
노정석 여기 나와 있네요. Peter Steinberger가 굉장히 많은 터미널을 띄워놓고 하죠.
최승준 어떤 분들은 Andrej가 예전의 진중한 모습보다 hype 쪽으로 너무 많이 넘어간 것 같다고 말씀하시는 분도 있고요. 그런데 좀 더 내려보면 나름의 관점을 이야기하는 부분이 있습니다. 이 부분에서는 Andrej가 인간의 skill에 대한 이야기를 했었어요. Sarah Guo가 질문한 것이 거기에서 연결되어 숙달이 되는 게 어떤 모습일까, 그런 식으로 이야기를 풀어냈는데요.
이 흐름은 다 짚기에는 너무 길어지기 때문에 조금 넘어가서 제가 포인트를 두고 있었던 부분을 짚어보겠습니다. 간략히 소개를 드리면, Peter가 해낸 것 중 중요한 부분은 에이전트의 성격을 만드는 것 등 한 5개 정도의 중요한 부분이 있고, Peter를 굉장히 칭찬하는 부분이 있었고요.
그다음에 Andrej Karpathy의 경험 부분에서는 딸깍 된 것이 자기의 홈 오토메이션을 OpenClaw로 리버스 엔지니어링하듯이 쉽게 이루어진 부분을 소개하는 부분이 있습니다. 프롬프트 3개로 됐다, 그런 식으로 소개한 부분이 있었고요.
그다음에 소프트웨어의 미래, 사람들이 원하는 것 같은 부분들은 저희가 그동안 해왔던 세션의 이야기와 결이 맞습니다. 그래서 그 부분을 자세하게 들어가지 않고, 제가 중요하게 봤던 부분은 오토 리서치의 한계입니다. 자기 개선하는 루프를 성공시키는 것을 Andrej Karpathy가 오토 리서치라는 이름으로 포장해서 지금 이슈가 되고 있는데, 그런 것이 안 되는 영역이 있다는 점을 저는 중요하게 봤어요. 오토 리서치를 복습을 좀 해볼까요?
검증 가능하면 자동화되는 오토리서치 복습 7:50
노정석 목표가 명확히 되고 그 목표에 대한 결과물의 evaluation을 확실하게 할 수만 있다면, 그 중간에 있는 것이 문서든 연구든 GitHub 레포든 모델이든 어떤 형태로든 LLM을 투입해서 토큰을 투입해서 최적화, optimize 할 수 있다는 것이죠. 솔루션을 찾아낼 수 있다는 것이죠.
최승준 Andrej Karpathy가 잘하는 것이 그런 것을 매우 미니멀하게 구현하는 것이거든요. 이번에 오토 리서치도 굉장히 미니멀하게 MD 파일 3개, 코드 MD 파일인 program.md 하나, 그다음에 Python 파일 하나. 그것이 계속 자기 자신을 갱신하면서 레포가 쌓여가는 구조였잖아요.
노정석 그 부분에 대해서 간단하게 배경을 설명하면 이렇습니다. 모델의 성능을 높이는 것, Andrej Karpathy가 만든 굉장히 간단한 모델의 성능을 높이는 것인데 program.md가 사실은 이것의 manifest죠. 어떻게 하라, 나는 어떤 목적을 갖고 있다는 것을 명확하게 적어 놓은 것이고, 그다음에 그것의 대상이 되는 프로그램으로 train.py와 prepare.py 같은 것들을 준 거죠.
최승준 이것은 준비하는 정도고 핵심은 train 파일을 계속 개선하는 것이죠.
노정석 이건 목표가 loss 값을 떨어뜨린다는 명확한 목표가 있으니까, 측정 가능한 verifiable한 evaluation이 있으면 그다음에 모델에게 맡기면 됩니다. 알아서 논문 찾아오고 알아서 자기가 알고 있는 것을 이렇게 고쳐보고 저렇게 고쳐보고, 양의 피드백 음의 피드백을 다 받아들이면서 되는 것들은 강화하고 아닌 것들은 버리면서 끊임없이 최적의 해를 찾아서 나아가는 것이 오토 리서치의 핵심인 거죠.
최승준 Andrej Karpathy 스스로가 만들어 놓고서 놀란 것이, 자기가 20년 동안 이런 일을 했는데 자신이 빼먹은 것들을 모델이 잡아냈다는 점입니다. 실제로 validation loss가 줄어든 코드에 배울 것들이 있었다는 것이 놀라운 부분이었죠.
노정석 Andrej Karpathy보다 나은 것이니까 웬만한 사람들보다 훨씬 나은 것이에요, 모델이.
농담과 검증 불가능한 영역에서 드러나는 오토리서치의 한계 10:16
최승준 Sarah Guo가 도전적인 질문을 합니다. program.md를 Andrej Karpathy보다 더 잘 쓰게 하는 것도 이 방법으로 되는 것 아니냐고요. 하지만 그래도 한계는 있습니다.

그 한계에 대한 부분을 저는 관심을 가지고 봤는데, 검증 가능한 영역에서는 너무 잘 작동하지만 검증하기 어려운 것에서는 다 drift한다, 표류한다는 표현을 썼습니다. 여기 보면 Andrej Karpathy가 가설을 이야기한 것이 있는데, 이 부분이 방황한다는 표현이었고요.
그런 것의 대표적인 예가 농담입니다. 농담을 시키면 최신의 모델도 3~4년 전 모델이 하는 정도의 농담을 벗어나지 못합니다. Andrej Karpathy가 생각하기에 이것은 현재 RL이 커버하지 않는 영역인 것 같다는 것이죠. 그런 영역들이 꽤 있고 그래서 능력이 들쭉날쭉한 것 같다는 이야기를 합니다.
노정석 jagged라는 표현을 굉장히 많이 하죠. 어떤 건 정말 슈퍼 천재인데 어떤 건 형편없는 바보.
최승준 그런 이야기를 하다가 제가 후반부에서 관심이 있었던 부분은, 오토 리서치 같은 것을 SETI@home이나 Folding@home 같은 프로젝트처럼 하고 싶다면 할 수 있을 것 같다는 이야기입니다. SETI@home이 외계 문명 찾는 것이고 Folding@home은 AlphaFold 나오기 전에 단백질 접힘을 크라우드 소싱으로 하는 것이었잖아요.
microgpt는 왜 에이전트로 만들 수 없었나 11:47
에이전트를 보내서 사람들이 내 에이전트를 통해 복잡한 문제를 푸는 것에 대한 야심을 이야기한 부분이 있었고요. microgpt도 저번에 저희가 한번 소개해 드렸는데, 200줄로 GPT를 압축했었잖아요.
그런데 이것은 아까와 같은 방식으로는 안 된다고 합니다. microgpt 같은 코드를 만드는 것은 에이전트를 돌려서는 거기까지 도달하지 못하고, 이것은 자신만 할 수 있었던 20년의 압축 경험의 결과라는 것이죠. 흥미로운 이야기는 Andrej Karpathy가 Eureka Labs를 창업했지만 한 일이 별로 없다는 점입니다. microgpt를 내놓은 다음에는 예전 같았으면 유튜브를 찍어서 알려주었을 텐데, 더 이상은 할 필요를 못 느낀다는 이야기를 합니다.
노정석 왜 그럴까요?
최승준 왜냐하면 에이전트에게 알려주기만 하면, 코드와 MD 파일로 알려주면 그것을 좀 더 쉽게 다뤄주는 콘텐츠는 얼마든지 AI가 생산할 수 있기 때문에 굳이 자신이 할 일은 아닌 것 같고, 자신이 할 일은 정말 비트를 깎아서 이런 200줄짜리의 미학적인 것을 만들어내는 것이 아닌가 하는 뉘앙스의 이야기를 합니다.
에이전트에게 가르치는 것으로 바뀌는 교육의 미래 12:55
교육의 미래가 사람에게 가르치는 것에서 에이전트에게 가르치는 것으로 바뀌고, 에이전트가 할 수 있게 되면 사람들을 가르치는 것은 그때그때 인터랙티브 콘텐츠 같은 것으로 만들어질 수 있다는 이야기가 저에게는 기억에 남았던 세션이었어요.
정석님은 또 인상적인 부분이 다른 것이 있으셨을 수도 있을 것 같은데, 어떻게 보셨나요?
노정석 저는 두 가지 이야기를 하는 것 같거든요. 첫 번째는 방금 이야기했던 대로 무엇이든지 verifiable한 측정 장치를 끼울 수만 있다면, 모델의 학습뿐만 아니라 일반적인 문제들도 다 풀 수 있다는 부분에 대해 이야기를 해주는 것이 하나 있었고
두 번째로는 레이어가 모델을 트레이닝하고 분석하는 것을 넘어서서, 모델 자체를 예전으로 이야기하면 CPU 같은 하나의 엔진으로 만들고 있다는 점입니다. Andrej Karpathy가 이야기하는 것이 그런 것이 있잖아요. 작년 12월까지는 직접 코드를 만지며 코딩을 했었는데 이제는 완전히 그런 것들은 하지 않는다고 이야기하면서, 매니페스트와 연결된 말인데 이제 한 계층 위로 올라간 느낌이에요. 그 계층 위에 있는 것들의 가치에 대해 이야기를 하고 있거든요.
모델의 성능이 뭐가 좋다, 벤치마크가 어떻게 좋다가 아니라, 이것을 가지고 어떤 문제를 추가적으로 풀 수 있을 것이고 우리의 일들을 어떻게 바꿀 것이고 교육을 어떻게 바꿀 것이고 하는 애플리케이션 영역, 한 층 높은 영역으로 어젠다가 다 스위칭했습니다. 이것이 제가 얻은 확실한 느낌이었습니다.
에이전트가 못하는 것이 당신의 일이다 14:45
최승준 Andrej Karpathy가 이번 세션에서 맨 마지막에 한 말은 이것입니다. 에이전트가 못하는 것이 이제 당신의 일이다. 에이전트가 할 수 있는 것은 아마 당신보다 더 잘하거나 곧 그렇게 될 것이다. 그래서 실제로 시간을 어디에 쓸지 전략적이어야 한다. 이런 이야기로 인터뷰를 마무리했습니다.
노정석 그런데 이것은 굉장히 열린 질문입니다. 아까 초반에도 이야기했듯이, 1~2주일에 될 만한 일이면 딸깍하지 마라. 왜냐하면 사방에서 딸깍거려서 리얼타임으로 만들었을 테니까요. 그러면 6개월 있다 될 일들을 해야 된다는 이야기인데, 그러한 주제를 세팅하는 능력, 지금 현재의 맥락을 읽고 주제를 명확하게 세팅할 수 있는 능력이 중요합니다. 이것이 시간을 어디에 쓸지 전략적이어야 한다라는 말의 해석일 것 같아요.
최승준 하여튼 고민되는 지점들이 있으면서도 재미있게 이야기를 풀어냈는데, Andrej Karpathy가 이야기를 엄청 빨리 하더라고요. 0.8배속으로 들으면 정상 속도라고 하는
노정석 Andrej Karpathy 같은 유명인이 해주는 이야기가 어쩌면 승준님과 제가 하는 이야기에 나름의 evaluation인 셈이거든요. 저희가 Karpathy가 하는 이야기들과 그렇게 맥락이 다르지 않았다는 점에서, 저는 좋은 평가를 얻은 것이라는 피드백을 받았습니다.
최승준 결이 맞는 부분이 있어서 다행입니다. 하여튼 Andrej Karpathy도 인터뷰에서 자기가 더 이상 프론티어 랩에 있지는 않지만 자율권을 가져서 말하고 싶은 것을 말하는 장점이 있다고 했습니다. 그런데 최신의 정보를 알려면 들어왔다 나왔다 하는 것을 반복해야 된다는 이야기도 하더라고요.
노정석 다 듣겠죠.
최승준 그렇죠. 친구들이 있다 보니까, 과학 쪽에서 Periodic Labs를 만든 Liam Fedus가 Andrej Karpathy의 친한 친구라서 거기를 다녀왔다는 이야기도 합니다. 자세하게 언급하지는 않았지만, 과학 쪽에서 어떤 것들이 가능해지는지 파악하고 있는 것으로 추측됩니다.
Andrej Karpathy의 생명공학 관심과 도메인으로의 도피 16:47
노정석 Andrej Karpathy가 예전부터 굉장히 관심이 있는 분야가 생명공학이에요. 본인이 molecular biology 두꺼운 책이라든지 생명공학 책들도 가지고 와서 그 필드를 굉장히 공부하고 있는 것으로 알고 있거든요.
저희가 어디로 도망가야 되는지에 대한 이야기를 많이 하지만, 딸깍딸깍해서 끝나는 일들의 단가가 계속 하락하고 있거든요. 시장의 진입자도 굉장히 많아지고 있고, 두 달 먼저 갔다는 정도지 뒤에서 따라오는 사람들이 캐치업하기가 너무 쉬워요. 솔직히
최승준 뒤로 갈수록 더 유리해지죠. 모델이나 하네스의 성능이 더 높아지기 때문에
노정석 맞아요. 더 좋은 도구를 가지고 전쟁에 뛰어드니까, 앞 사람들이 지난 6개월 동안 팔아왔던 것들이 아무 의미가 없어지는 출발선이 끊임없이 리셋되는 것을 저희가 목격하고 있기 때문에, 올해 AI 사이언스를 하려고 하고 Terence Tao나 이런 분들 이야기도 많이 했었는데
그 똑똑한 분들이 지금 도망가고 있는 영역을 보면, Periodic Labs가 하는 것 같은 재료 공학이나 새로운 소재를 찾는 일, 혹은 AlphaGenomics나 AlphaFold 같은 것들 때문에 생명공학 자체가 완전히 소프트웨어화되고 있거든요. 더 이상 비커에 물을 넣거나 실험을 하지 않아도 되는 소위 wet lab, 젖은 랩이라고 부르는 것들이 필요 없는 소프트웨어 환경으로 급격하게 가고 있고, 그쪽으로 다들 도망가고 있는 것 같아요.
그런데 그런 쪽은 아주 깊은 도메인 knowledge를 필요로 합니다. 적어도 박사 과정에 준하는 정도의 도메인 knowledge를 필요로 하기 때문에, 그런 쪽에서 사람들이 사업을 하나씩 차리고 있는 느낌이고, 그것을 빨리 알아보고 사업을 차리거나 그 사람들을 빨리 알아보고 투자하거나 하는 것이 지금의 트렌드인 것 같아요.
Dwarkesh Patel과 Terence Tao 인터뷰에서 본 수학과 AI 18:51
최승준 분명히 그것이 말이 되면서도 한번 재방문해야 할 지점인 것 같은데요. 일단 제가 늘 재미있게 보고 있는 Dwarkesh Patel이 이번에는 저명한 수학자인 Terence Tao를 인터뷰했는데, Dwarkesh Patel은 늘 의도를 가지고 인터뷰를 하는 것 같아요. 당연하겠지만 자기가 하고 싶은 말에 아젠다 세팅을 하는 경향이 있는데, Andrej Karpathy가 이야기한 것을 한 번 더 강조하면 RL 범위 안에 있으면 초광속으로 달리고 범위 밖이면 모든 것이 표류한다는 이야기를 했었습니다. 그다음에 농담의 사례 같은 것을 이야기했었고, Dwarkesh Patel은 수학에 관련된 이야기를 Terence Tao와 하면서 이 인식론적 지옥에서 살아남는 이유는 우리가 명확히 말할 수도 없고 강화학습 루프에 코드화할 수도 없을 만큼 제대로 이해하지 못하는 판단력과 휴리스틱의 혼합이라고 합니다.

다시 인터뷰 내용으로 축약해서 말씀드리면, 처음에 케플러 이야기부터 합니다. 케플러가 천동설 지동설 그즈음의 것이잖아요. 궤도가 무엇에 비례한다, 중학생 때인가 고등학생 때 배웠는데 a 제곱 b 3승 그런 느낌의 공식 있었지 않습니까? 그런 것을 알아내는 과정의 역사를 풀어내면서, 그 당시에는 혁신적인 아이디어가 오히려 부정확했다는 점을 짚습니다. 예전의 천동설 방식으로 했을 때가 초기에는 오히려 더 정확했고, 지동설의 방식으로 했을 때가 부정확했는데 사실은 맞은 것은 지동설이었습니다. 그것이 정상 과학의 궤도에 편입되어 제대로 작동하기까지는 상당한 시간이 걸렸고요. 그렇기 때문에 초기에 locally incentive가 있는 것은 긴 궤도에서는 오히려 맞지 않을 수 있다는 뉘앙스로 빗나가는 것들을 이야기합니다.
Terence Tao를 소환하는 이유는 작년 말 올해 초에 AI 수학으로 Paul Erdős 문제들이 많이 풀렸기 때문입니다. 그런데 지금 plateau에 있는 현상을 말하게 합니다. 한동안은 계속 풀리다가 쉬운 문제들, low-hanging fruit들은 다 얻어내고, AI를 활용해서 search space를 탐색할 수 있는 것들이 확 추수된 다음에는 현재 다시 plateau에 접어들었습니다. 그러면 실제로 수학자가 해야 되는 일은 무엇인가, 연구하는 방식은 무엇인가, 그런 것들을 계속 밀어붙이면서 인터뷰를 합니다. Dwarkesh Patel의 의도는 지금의 레짐으로는 안 되는 무엇인가가 더 있다는 것이고, 그것을 압축해서 표현한 것이 아까 그 인식론적인 거대한 휴리스틱과 암묵지를 이야기하게끔 하는 부분이었습니다.
AGI 논쟁과 march of nines 21:58
노정석 그런데 참 재미있는 것이, 아까 승준님 말씀하셨지만 Paul Erdős의 문제 같은 것들도 만약 3년 전에 GPT-3.0이 풀었다면 정말 경천동지할 일이고 이건 AGI다라고 했을 겁니다.
최승준 그런데 작년에도 그런 것을 푼 것은 경천동지할 일이긴 했어요. 작년 말에
노정석 그런데 저희의 기대치가 상대적으로 계속 올라가는 것이죠. 지금 모델의 성능은 젠슨 황도 지난번 GTC에서 그랬고 일론 머스크도 이야기하고 있고, 이미 AGI 성능 아니냐고 질문하고 있는 건데, 그럼에도 불구하고 사람들은 끊임없이 안 되는 것을 찾으면서 안 되잖아 안 되잖아라고 이야기하고 있습니다. 저는 이러한 지점들이 우리 개개인이 가져야 하는 균형 감각과 연관이 많이 되어 있다고 생각해요.
왜냐하면 이미 Andrej Karpathy도 march of nines, 9의 행진이라는 이야기를 하면서, 90까지는 문제가 있지만 99부터는 쓸 만하다, 그러나 끊임없이 99.9, 99.99, 99.999가 되는 형태로 나아가게 된다는 이야기를 했었는데, 섹터에 따라 다르지만 굉장히 많은 부분에서 이미 99의 영역에 도달한 것들이 많이 있잖아요. 그런데 뒤에 9가 몇 개 더 안 붙었다고 안 된다고 이야기하는 것은 조금 가혹하지 않나 하는 생각이 들고요.
최승준 그런데 Terence Tao가 안 된다고만 이야기하는 것은 아닙니다. Terence Tao는 AI를 적극적으로 활용해서 돌파구를 계속 찾으려는 태도를 가지고 있고, Dwarkesh Patel도 안 된다고 선을 긋는 것이 아니라 세션마다 저글링을 합니다. 이 사람에게는 hype 쪽으로 다가갔다가 이 사람에게는 중립적으로 다가갔다가 하고 있기 때문에, 의도를 가지고 이 편을 했다고는 생각하는데요. 실제로 보면 논리를 재미있게 풀어낸 부분이 있습니다.
high temperature LLM이라는 비유를 하면서, 그 당시로는 생각하지 못하는 temperature가 높은 의외의 생각을 하는 것들이 LLM이 잘할 수 있는 영역이고 우리가 그것을 통해서 leverage를 얻을 수 있다는 함의를 끌어냅니다. Terence Tao를 통해서 말하게 하려는 것은 후반부에 각각의 장점이 있다는 것을, 인간 수학자도 여전히 AI와 함께하여 오히려 더 잘할 수 있는 부분이 있다는 것을 짚어내는 것이 있고요.
Terence Tao가 말하는 semi-formal 언어의 필요성 24:42
제가 이 세션에서 가장 흥미롭게 본 것은 가장 후반부에 나오는 이것입니다. semi-formal 언어가 필요하다는 것인데, 앞에서 Andrej Karpathy가 한 것과 비슷하게 Gwern Branwen을 통해 지금 수학에서 AI 혁신들이 일어난 것이잖아요. 검증 가능하게 증명 기계를 써서 LLM이 그 증명 기계를 작동시키고 피드백을 받아서, 되는 쪽으로 밀어붙여 문제들이 풀리곤 했었는데, 지금 Terence Tao의 이야기는 실제로 수학자들이 고민하고 협업하는 암묵지적인 것을 Lean 같은 완전한 formal 언어가 아니라 반형식 언어로 어떻게 만들 수 있을까 하는 프론티어의 고민을 했다고 저는 느꼈거든요.
회사로 치면 조직의 문화와 비슷한 것일 수도 있고, 수학자들이 협업하는 방식이라든가 생각하는 방식을 어떻게 semi-formal하게 만들 수 있는가, 이런 고민을 하는 것이 매우 중요하다고 느껴졌어요.
노정석 LLM 덕분에 다들 이 층위가 레이어가 다 올라가고 있어요. 다 더 abstract 레이어로 끊임없이 다 밀려나고 있습니다. 나쁘게 얘기하면 밀려나고 있고 좋게 얘기하면 끊임없이 진보하고 있는 거죠.
최승준 그런 것들이 시간의 시험을 받아야 한다는 이야기도 하는데, 이 시간의 시험도 상당히 납득이 가는 이야기였고요. 뒤의 이야기는 조금 사변적이긴 합니다만, Dwarkesh Patel이 이끌어낸 Terence Tao의 결론은 인간-AI 하이브리드가 수학을 더 오래 지배할 것이라는 것입니다. 각각의 역할이 있고 협업하는 체계가 어쩌면 Terence Tao가 그리는 상일 수도 있겠죠. 그런데 미래는 불확실하다, 내가 이야기한 것이 꼭 맞지 않을 수도 있다는 disclaimer는 Andrej Karpathy도 잡고 Terence Tao도 똑같이 잡습니다. 성현님이 fog of progress 이야기했듯이 이런 사람들 또한 전혀 예측할 수 없습니다.
프린스턴 고등연구소에서 배우는 Richard Feynman과 비효율의 가치 26:59

앞으로 어떤 일이 펼쳐질지는 모르지만, 재미있었던 것은 비효율성을 오히려 예찬하는, serendipity를 중요하게 생각하는 Terence Tao 이야기입니다. 사변이긴 하지만 흥미로운 에피소드가 있었어요. 재미 삼아 소개를 드리는데, 프린스턴 고등연구소라고 해서 뉴저지에 있는 연구소입니다. 저명한 과학자들이나 갈 수 있는 곳이거든요. Terence Tao가 산만함이 없는 훌륭한 곳이다, 거기서 오로지 연구만 하면 된다, 처음 몇 주는 훌륭한데 시간이 지나면 영감이 고갈된다는 이야기를 했습니다. 이것에 대해 Dwarkesh Patel의 트윗에 누군가 댓글을 달았는데, Richard Feynman도 똑같은 이야기를 했다고요. 연구만 할 수 있는 상황은 과학자를 망치는 지름길이라는 뉘앙스로 이야기한 것을 짚어줍니다. 실제로 사람들을 만나고 학생들에게 알려주려고 기초적인 것을 다시 생각해 보는 것들이, 편안하게 연구만 명상하듯이 할 수 있는 곳에서는 일어나지 않는 의미 있는 경험이라는 이야기를 했고요. Richard Hamming이라는 컴퓨터 과학 쪽에 유명하신 분도 똑같은 이야기를 했습니다. 고등과학연구소가 많은 위대한 과학자들을 망쳐 놓았다고요. 제가 이것을 끌고 들어온 것은, 의외의 것들, 노이즈 같아 보이는 일련의 것들도 사실은 인간에게 매우 도움이 되는 경험일 수 있다는 재미있는 포인트가 있었고요.
Anthropic AI 과학 블로그가 보여주는 vibe physics와 대학원생으로서의 Claude 28:25
그것은 빠르게 지나가고, 정작 흥미로운 글들이 나온 것은 Anthropic에서 매우 실용적인 글들이 많이 나왔다는 점입니다. AI 과학이 중요한 지금, Anthropic에서 23일 즈음에 AI 과학 블로그를 론칭하고 첫 글로 “vibe 물리학”과 “과학적 컴퓨팅을 위한 장기 실행 Claude”라는 두 가지 글을 올렸거든요. 상당히 길기는 하지만, 요즘 과학자들이 AI를 어떤 식으로 쓰고 있는지를 프롬프트 포함해서 매우 자세하게 소개했습니다. 프롬프트 예시도 들어 있고 코드도 들어 있고, 아주 꼼꼼하게 소개해서 깜짝 놀랐습니다.
vibe physics의 대강의 내용과 결론을 말씀드리면, Matthew Schwartz라는 꽤 지명도가 높은 물리학자가 최근에 양자장론에 대한 논문을 AI와 내서 물리학자들에게 상당한 반향을 불러일으켰다고 합니다. 의미 있는 논문이고 그것을 어떻게 썼느냐, 그 과정을 아주 상세하게 이야기합니다. vibe 대학원생이 무엇이냐 하면, 아직은 동료 과학자가 아니라 대학원생이라는 것입니다. 그 대학원생을 어떻게 매니징해서 실제로 논문을 공동 저작하고 출판했는가에 대한 굉장히 자세하고 흥미로운 이야기입니다. 여기 보면 무엇이 되고 무엇이 안 되는지를 2026년 초 현재의 상황으로 매우 꼼꼼하게 짚어주었는데, 내용이 충실하고 재미있었습니다. 어떤 것은 과장된 기대가 있지만, 그럼에도 불구하고 채팅 기반이 아니라 에이전트를 써야 되는 이유, 그리고 대학원생 지도하듯이 Claude를 지도하면서 멋진 논문이 나오게 된 여정을 짚어서 상당히 재미있습니다.
노정석 이 모든 문제 접근 방식이 다 이런 방식인 것 같아요.
최승준 실제로 Claude Code 화면이라든가 초고도 보여주는데, Claude가 실수하는 것들, Claude가 맞춰주는 것을 좋아하는 것, 해냈다고 거짓말하는 것, 그런 것들을 다 어떻게 지도했는지 그 과정을 이야기합니다. 이 사람은 도메인 전문가니까 삐걱거리는 것들을 교정해서, 하네스까지는 아니더라도 촘촘하게 잡아채면서 제대로 일을 하게 합니다. 결과물은 혼자 했으면 3~4개월 걸렸을 일을 10일에서 2주 정도 사이에 논문을 출판할 수 있었다는 이야기인데, 딸깍으로 되는 것이 아니라 굉장히 지도가 필요했다는 결론이었습니다.
노정석 맞습니다. 여기서 결국은 본인을 evaluator로 쓴 거죠. 그러나 이것도 상위에서 동작하는 방법론은 역시 auto research였던 거죠.
최승준 개입을 중간에 하긴 하지만, auto research 비슷한 턴들이 있는 것이죠. 여기도 처음에 Claude가 잘하는 것이 지치지 않는 반복, 불평 없음.
노정석 불평 없음. 중요하네요.
최승준 기초는 다 알고 있음, 그림 잘 그림, 문헌 종합 잘함. LaTeX이나 도식을 만드는 것은 Terence Tao도 똑같은 이야기를 했는데, 매우 시간이 걸리는 일인데 다 잘해줍니다.
Claude가 못하는 것은, 규약이 비표준적일 경우 잘 알려져 있는 것이 아니면 자꾸 기본값으로 돌아간다고 합니다. 끝까지 밀어붙이는 것도 부족한 부분이 있다는 것이 이 사람의 평이에요. 그다음에 방향을 읽는 것, 미감이 부족하다는 점, 압박을 견디는 것이 안 된다는 점 등을 짚습니다. 어쨌든 탑티어의 연구자니까 이런 이야기를 하는 것 같습니다.
효과가 있었던 요령, 교차 검증하고 계층 구조를 유지하고 반복 질의하는 것들을 통해 이런 결론이 나왔다는데, 결국에는 AI가 어떻게 박사 수준으로 가는가, 그리고 인간 대학원생들은 무엇을 해야 하는가의 문제입니다. 실험을 분리하는 것도 좋은 방법일 수 있다는 이야기도 합니다.
노정석 이분이 그럼 그냥 Claude 클라이언트를 그냥 쓰신 거죠? Claude.
최승준 Claude Code, Claude Code를 쓴 겁니다. Claude Code에 본인의 하네스를
노정석 조금만 더 정교하게 적용했으면 앞에서 이야기했던 Claude가 못하는 것의 문제도 솔직히 다 해결할 수 있는 영역의 것들이네요.
최승준 이것을 Anthropic 공식 과학 블로그에서 한 것은, 실제로 이런 사례가 있고 이 정도의 능력과 인식이 있는 상태라는 것을 보여주기 위해서입니다. 현장 첨병에 있는 과학자들이 이런 것을 해낸다는 것을 드러내는 하나의 에피소드이고요.
나머지 하나는 여기 보면 지표도 나옵니다. 총 Claude 세션 수, 입력 토큰이 2,750만인데, 많은 논문들을 넣었을 수 있겠죠. 상당한 분량이 진행된 것을 볼 수 있습니다.
노정석 그런데 저렇게 큰 문제를 풀어도 토큰의 숫자가 합하면 한 3천만~4천만 토큰 정도인데, 아마 지금 엔지니어링에서는…
Codex와 Claude Code의 바닐라 하네스 철학 비교 33:39
최승준 억 단위로 쓰고 계시죠?
노정석 맞아요. 그런데 제가 드리고 싶은 말씀은, 억 단위 토큰을 쓴 것이 잘한 것만은 아니라는 점입니다. 사실 저것이 정상이거든요. 3천만 토큰 안에서 성과가 강하게 나올 수 있도록 가이드하고 목표 설정을 잘 하는 것이 저는 좀 더 의미 있는 방향성이라는 생각이 듭니다.
저희 팀에도 굉장히 잘하는 엔지니어가 한 명 있는데, 이 친구는 순정주의자거든요. 덕지덕지 하네스를 많이 붙이지 않습니다. 예를 들어서 Claude Code나 Codex 말고도 위에 붙는 메타 하네스들이 많이 있고 요새 유행인데, 사실 메타 하네스가 갖고 있는 기능들을 어제 당장 Codex 0.117이 나오면서 없던 기능들이 대거 들어왔거든요. 밖에 있었던 메타 하네스의 기능들이 안으로 다 들어오고 있어요.
그런데 다 들어오는 것들을 보면, Claude Code는 밖에 있는 좋은 것들을 일단 집어넣고 나중에 정리하는 느낌이라면, Codex는 제가 Codex를 더 좋아하는 이유이기도 한데 굳이 필요 없는 클러터들은 다 걷어내 주고 본질만 바닐라에 잘 담아주는 느낌입니다. Codex에 hook이 들어온 지도 얼마 안 됐고 겨우 앱 서버라든지 클라이언트 구조로 분리해서 teamworks로 나누는 것을 할 수 있게 해 놓은 상황인데
제가 드리고 싶었던 말씀은, 그 잘하는 엔지니어가 방금 승준님이 보여주신 이런 방법론을 쓴다는 것입니다. 사람이 잘 가이드해서 그 일을 정확하고 빨리 끝내는 것이 중요하지
최승준 모델을 계속 돌릴 필요는 없다는 거죠.
노정석 예, 너무 과하게 search problem으로 하는 것도 답은 아닙니다. 물론 저는 몇백억 토큰을 넣어서 모든 것을 search problem으로 바꿔서 풀 수 있는 것도 가능하다고 생각하는데, 옳은 접근 방식은 이것인 것 같아요. 아마 인간의 가치와 AI의 가치가 극강으로 결합하는 영역일 것이라는 생각이 듭니다.
최승준 이 후반부는 물리학 연구원이 시뮬레이터를 만든 이야기를 매우 자세하게 풀어냅니다. 여기도 프롬프트가 공개되어 있고 코드도 공개되어 있습니다. 우주 배경 복사에 관련된 시뮬레이션을 상용 모델 급은 아니지만 자기 연구에 커스텀할 수 있는 정도의 것을 JAX로 구축하는 과정이 나옵니다.
여기도 자신이 얻었던 교훈들, 하네스 비슷한 것이나 git의 커밋 히스토리가 남는 것의 가치, 그리고 루프는 결국 일종의 Ralph loop를 돌렸다는 이야기가 나옵니다. 어느 정도 쓸 만한 수준이 됐는가를 짚어준 구체적인 블로그를 계속 이어가겠다는 약속이 Anthropic 블로그의 이번 주 소개였습니다. 이런 시리즈를 계속 이어가겠다고 하니, 기대가 됩니다.
과학자와 엔지니어가 서로 침범하는 AI for Science 37:01
다 이해는 못하더라도, 현장 첨병에 있는 과학자들이 AI를 어떻게 쓰는지의 사례를 Anthropic이 보여주는 것인데, OpenAI에서도 물론 하고 있지만 조금 더 구체성을 가지고 이야기해 주는 느낌이 있고
노정석 조금 생각해 보면, 아까 초두에도 말씀드렸지만 실리콘밸리에 있는 똑똑한 사람들이 다 사이언스로 도망가고 있다고 했잖아요. 코딩에서 일어났던 일이 사이언스에서 일어나지 말라는 법은 없거든요.
그리고 이것이 지금 저희의 기회라고 생각하는데, 지금 누구나 코딩하잖아요. 사실 아무나라는 표현이 좀 그렇지만, 못하던 사람들도 모델의 capability overhang과 결합해서 본인이 모르는 것을 배워가면서, 의지만 있으면 예전에는 최고급 엔지니어만 할 수 있었던 일들을 할 수 있는 시대가 된 것이죠. 저는 사이언스도 똑같이 치환될 것이라고 생각합니다.
예전에 신약 개발을 한다든지, 암을 치료하기 위해 유전자 시퀀싱을 해서 달라진 부분을 찾고, 달라진 부분 때문에 발현되는 단백질을 찾아서 AlphaFold로 visualize 해보고, 거기에 맞는 antibody 후보들을 찾는 것은 적어도 생명공학 박사 레벨의 지식이 필요했고 트레이닝이 필요했는데, 이제는 정말 잘 정리된 책 1권을 읽고 철학적인 깨달음만 얻으면 그 단계에 가볼 수 있게 됐거든요.
예전 같았으면 되지 않았을 일들이 되고 있습니다. 생명공학 박사도 아니고 MD, 의사 자격증이 있는 사람도 아닌데 지금 biology의 최전선에서 엔지니어가 들어가서 그런 일들을 하는 것이 우리 눈앞에서 벌어지고 있는 것이고, AI for science라는 이름 아래 Anthropic도 그렇고 OpenAI도 그렇고, Bay에 있는 많은 사람들이 도메인으로 도망간 것이죠. 더 어렵고 더 똑똑한 사람이어야만 하는 도메인으로 간 시대가 된 것 같고, 이것도 될 것 같다는 생각이 듭니다.
최승준 그런데 이것이 경쟁은 아니지만, vice versa이니까 아까 사례는 JAX 같은 것을 모르는 과학자가 엔지니어링을 해서 도구를 만든 것이고, 침범이에요. 다 서로 상호 침범이거든요.
노정석 Rust가 최근에 인기를 끈 것도, Rust 엔지니어가 되기 위해 노력을 많이 하신 분들이 많은데 요새는 엔지니어가 아니었던 분이 와서 백엔드를 Rust로 만들어 다시 쓰고 있다는 이야기를 들으면, 이것을 어떻게 해석해야 될까 저도 양가감정이 많이 듭니다. manifest라는 단어를 깊게 생각해 봐야 되겠네요.
루프와 인수 조건으로 산문을 만드는 글쓰기 실험 40:09
최승준 되게 좋은 단어를 얻었다는 느낌이 있었고요. 저도 실험을 해봤습니다. 무슨 실험을 했냐 하면, Andrej Karpathy가 농담은 안 된다고 해서 글쓰기로 다시 돌아가서 실험을 했는데, 몇 개의 재미있는 글들이 나왔거든요.
여기 귤이라는 글에서 시작했습니다. 이미지로 그려놓은 것이 루프 닫기라고 표현했는데, 나름의 평가 체계를 만들어서 헌법을 쓰고 시 초안 같은 것을 작성한 다음에 스스로 호되게 평가하고, 인수 조건을 설정합니다. ATD(acceptance test driven)라는 개념이 있더라고요. 인수 조건을 설정한 다음에 그 인수 조건을 달성할 때까지 루프를 돌리는 방식으로 했거든요.
아직은 Claude만 이것이 잘 되는데, Claude는 저장소 개념 비슷한 것을 웹 세션에서도 가질 수 있습니다. Claude Code는 당연히 되고 Claude 웹에서도 저장소 비슷하게 쓸 수 있거든요. 지금 보면 아까 보여드린 것이 이 창작 작업을 한 저장소입니다. 그 저장소에서 auto research 비슷하게 결과물도 계속 수정하고, 그것을 만드는 하네스, 메인이 되는 프롬프트조차도 재귀적으로 수정하게 했거든요. 인수 조건을 계속 escalate하는 방식으로 했을 때, 산문에서 재미있는 것들이 나오는 것을 관찰할 수 있었습니다.
이것은 헤일메리 영화를 보고 와서 SF 소설을 쓰게 해 봤는데, 읽으면서 나름 재미있는 소설이 나왔던 경험이었고 이것이 제일 놀랍거든요. 프롬프트는, 물론 자세한 지시문이 앞에 한 500라인 이상 있었고, 실제로 무엇을 만들라고 지시한 것은 이 부분이었거든요.

시각화와 표상이라는 제목으로, 단어를 보이게 만드는 기술로서의 글쓰기 창작이라는 것을 임완철 교수님과 이야기를 나누다가, 교수님이 AI와 쓴 논문 제목을 이것으로 잡으신 것이 있어요. 그것으로 산문을 만들어보면 어떨까 해서 이것이 나왔는데, 읽으면서 저는 깜짝 놀랐습니다. 제 관점에서는 상당히 창의적으로 잘 쓴 글이 나왔어요.
대강 말씀드리면, 교열자가 어떤 작가의 글을 읽다가 게슈탈트 붕괴가 됩니다. 원래 이 교열자는 글을 읽으면 주지적으로 이미지를 떠올릴 수 있는 능력을 가진 사람인데, 어느 날 갑자기 ‘물’ 하면 ㅁ, ㅜ, ㄹ로 글자만 인식되고 이미지가 안 떠오르는, 자기가 실명해 가는 단계를 거치는 느낌인데, 깜짝 놀랐던 부분은 자모를 분해해서 의문의 느낌을 살리는 내용을 쓰는 것을 보고 이것은 어떻게 이런 발상을 했지 하고 느끼는 부분이 있어요.
자음 모음을 분해해서, 더 이상 이미지는 떠올리지 않지만 다른 감각이 환기되면서 사운드적으로 느끼는 것을 이야기로 썼거든요. 이건 뭐지 하면서 봤는데, 거기에 들어간 것이 ‘은’이라는 주인공을 설정하고 상황과 환경, 어떤 식으로 이야기 arc를 전개할 것인가에서 무엇을 버리고 무엇을 선택했는지를 계속 루프를 돌면서 했더니, 최종으로 나온 것을 보니 한 30분 돌아갔나, 놀랐어요. 이것은 좀 다른 느낌입니다.
같은 하네스로 농담을 시도했으나 실패 44:03
산문은 괜찮은데, 같은 메커니즘으로 농담을 쓰게 했거든요. 하나도 안 웃깁니다. 시트콤의 장면을, 며칠 전에 밤에 버스를 타고 오면서 심야버스를 화두로 똑같은 메커니즘으로 글을 쓰게 했는데, 똑같이 루프를 돌긴 했지만 웃기지는 않았어요.
그런데 그 안에 들어있는 메커니즘은 기존에 잘 알려져 있는 스탠드업 코미디라든가 시트콤이라든가 일본의 만자이 같은 방법론을 리서치하고 평가하는 계획들은 다 있었는데, 실제로 나온 것은 별로라는 것이죠.
생성된 산문은 탁월하게 느껴지는데 왜 같은 접근으로 농담은 안 될까가 이번 주에 고민이었습니다. 왜 그것을 고민했냐 하면, 만약 농담 같은 것이 non-verifiable한 것이라면 non-verifiable한 것은 이 방식으로 안 되는 것인가가 궁금했던 것이에요.
노정석 그런데 그것도 인간이 즐거워, 재밌어라고 하는 농담의 레벨이 있잖아요. 아래 레벨을 시키면 정복되지 않을까요? 아직 verifier가 없는 것뿐이죠.
최승준 RL을 안 시켰을 수도 있고, 왜냐하면 코딩에 비해서 이득이 있는 것도 아니고요. 들쭉날쭉한 RL 훈련의 환경일 수도 있고
OpenAI가 작년 이맘때 GPT-4.5를 내고는 금방 철회했잖아요. pre-train이 더 크게 됐던 것으로 추정했던 모델이고 글을 매우 창의적으로 잘 썼는데, 비즈니스의 영역이 아니라고 판단해서 철회했을 가능성도 있고, 모르겠어요.

어쨌든 현재 모델로는 같은 하네스를 쓰더라도 농담은 잘 작동하지 않습니다. 또는 Andrej가 말했듯이 제가 하네스를 만든 skill이 부족했을 수도 있고요. 계속 이렇게저렇게 해보고 있는 중인데, “오빠는 딸깍쟁이야”라는 노래를 개사해서 웃음 포인트를 잡기도 했습니다. 재미있는 것은 무엇이 웃기고 안 웃기고를 모델들이 요새 풀이하는 것은 굉장히 잘하는데, 그 정도 수준을 만들어내려고 하면 안 됩니다. 제가 정리한 것은, 현재 레짐이 프리 트레이닝으로 다 깔아놓고 미드 트레이닝으로 도메인 훈련을 시키고 포스트 트레이닝으로 RL+환경에 하네스까지 하는 것으로는 농담 같은 것들은 포착이 안 되는 쪽이라는 잠정 결론입니다. 투자를 안 했을 수도 있고, 포착이 안 되는 것일 수도 있습니다.
싫어하는 것도 강력한 시그널이 되는 취향의 힘 46:38
노정석 사람들이 여기에 별 관심이 없을 거예요, 아마.
최승준 그럴 수도 있고 아닐 수도 있고라고 생각을 하는 편입니다만
노정석 지금 이 인더스트리에 있는 사람들이 다 극 T들의 집합체인데 F의 영역들은 evaluation을 어떻게 해야 될지도 모르는 사람들이 거의 대부분일 거라서요.
최승준 그런데 F의 영역에도 비즈니스는 많은 것 아닌가요?
노정석 그렇겠죠. 그런데 그것에 누군가가 길을 열면 그쪽으로 갈 텐데, 이런 부분들이 사실 저희가 도망가기에 좋은 영역인 것이죠.
최승준 이진원 님이 메신저에서 이야기하다가 가치 함수라는 말과 닿아 있을 것 같다는 말씀이 저에게도 와닿았어요. 그런데 아직 그것을 어떻게 구현할지는 알려진 바가 없는 것 같습니다. 감정이 가치 함수라는 말과 닿아 있다는 것이 아직은 잘 모르는 영역입니다.
노정석 value function = evaluation metric이잖아요. 다 비슷한 얘기네요.
최승준 그런데 질은 매우 달랐습니다. 산문과 웃음 포인트를 자아내는 것은 현재의 방식으로는 쉽게 되지 않는 것 같습니다. Andrej Karpathy가 어쨌든 한 말을 저도 확인한 것이죠.
노정석 네, 좋은 글쓰기의 RL 환경은 굉장히 많이 발전하고 있는 것 같아요. 예전에도 작년 논문에서 많이 봤었던 것 같고, 요새는 시간이 없어서 논문을 잘 안 보게 되는데, Kimi라든지 이런 논문에서도 상당 부분 양을 투입했던 것이 on-policy로 모델 스스로의 능력을 가지고 좋은 글에 대해 끊임없이 하는 RL 환경은 꽤 중요하게 다뤄졌던 것으로 기억합니다. 그런데 거기에 시나 농담은 당연히 없을 것 같아요.
최승준 저의 prior는 그랬던 것 같아요. 개그를 짠다는 표현이 있잖아요. 코미디언들도 회의를 하면서 이런저런 가설을 세우고 실험해 보고 평가회를 해서 안 웃겨, 안 웃겨 하면서 깎아내는 작업을 하는데, 비슷하게 하면 될 것 같았으나 실제로 나온 것을 보면 그런 수준이고,
취향에 관련된 인사이트도 이번 주에 있었어요. 무엇을 좋아한다만이 취향이 아니라, 무엇을 싫어한다가 굉장히 강력한 취향이더라고요. 프롬프트에서 거절, 나는 어떤 이유로 그것을 채택하지 않는다는 것이 있을 때 확실히 글의 품질이 좋아졌어요.
노정석 그것도 피드백이니까요.
최승준 취향은 좋아하는 것만의 취향이 아니라 싫어하는 것도 굉장히 중요한 시그널이구나.
또 재미있는 것은, 요새 작업하는 것들이 다 루프성을 가지다 보니 사람들과 같이 하다 보면 에이전트가 돌아가는 동안 무엇을 해야 하는가 하는 문제입니다. 최근에 몇몇 분들과 워크샵 비슷한 것을 할 때 드는 생각은, 합의해서 에이전트에게 일을 시킨 다음에 사람은 무엇을 재미있게 할 수 있느냐 하는 점이 흥미로운 포인트라는 것입니다. 소셜 코딩이라고 이야기하는 분들도 있는데, 에이전트에게 일을 계속 줄 수는 있지만 그것이 돌아가는 동안 몇 명이 대화를 나누거나 아이디어를 개진하거나 다음에 무엇을 할지 계획을 세우는 것을 해볼 수 있지 않을까 해서 실험을 해보고 있는 것이 있는데, 그것은 나중에 한번 말씀드리고요.
암묵지 리버스 엔지니어링 가설 49:53
마무리로 이번 주의 경험을 압축해서 가설을 하나 생각해 봤습니다. 암묵지에 관한 리버스 엔지니어링 가설입니다. 어떤 인물이 해낸 결과물이 있을 때, 그 결과물을 해내길 기대하는 최소한의 하네스와 인수 조건, 그리고 그것들을 스스로 들어 올리는 부트스트래핑 루프로 작동하는 저장소를 만든다는 것입니다. 무엇이든 저장소를 만들어야겠다는 생각을 요새 하고 있어요.
노정석 네, 메모리.
최승준 저장소에는 여러 가지 파일이 될 수도 있고요. 저장소에는 결과물에 점근하는 과정이 부산물, MD 파일이든 코드든 커밋 히스토리든 남는다. 만약 그 부트스트래핑 루프가 인수 조건을 통과해서 결과물에 준하는 것을 만들었다면 그 수준의 다른 결과물이 생성되는지 커버리지를 넓히며 반복하면서 루프를 또다시 진행한다.
그러면 이 가설에서 가장 구현하기 어려운 부분은 무엇인가라는 질문이 떠올랐고, 만약 당신 자신의 암묵지를, 왜냐하면 자기가 글 쓰고 자기가 하네스 만들 수 있잖아요, 자기가 잘 평가할 수 있으니까, 자신의 암묵지를 착즙하는 데 성공했고 복제 가능해졌다면 그때 자신의 가치는 무엇이 되는가. 당신 자신은 복제할 수 있는데 타인은 복제할 수 없는 조건이 있는가. 이 질문이 떠올랐거든요. 내가 복제할 수 있으면 다른 사람도 복제할 수 있는 것 아닌가요?
노정석 그렇긴 한데, 그것을 조금 더 잘 아는 사람, skill이 있기 때문에 잘하는 사람의 가치가 있고, 물론 그 가치가 LLM 때문에 광속으로 줄어들고 있는 것이 문제인데 결국은 이 모든 것이 타이밍 이슈로 점근될 것 같아요. 내가 빨리 한 것의 시간 가치가 얼마냐, 상대적인 시간 가치의 문제입니다.
그리고 남들이 이것을 딸깍해서 복사하는데, one 딸깍 away인지 three 딸깍s away인지가 중요한 것이죠. 그 시간 감각을 앞으로는 비즈니스 세계에서 회사의 가치, 사람의 가치로 evaluation하게 될 가능성이 높습니다. 누가 항상 새로운 것들을 제일 먼저 내보내면, 남들이 다 가져갈 수 있지만 가방은 모두가 만들 수 있어요. 그럼에도 불구하고 사람들이 에르메스 가방을 사는 이유는 무언가를 계속 해왔기 때문에 브랜드가 된 것이잖아요. 브랜드가 되면 사람들은 또 거기로 몰려갑니다.
그러면 그것들을 딸깍딸깍을 하는 사람이 있더라도 똑같이 다 방망이 깎는 그런 노인이 있더라도 제일 잘하는 게 오랫동안 반복했던 사람이 있고 그렇다면 그 재능이 온전히 다 평등하더라도 사람들은 저걸 사요. 왜냐하면 그 브랜드에 대한 선호가 생기기 때문에. 그래서 저는 승준님이 말씀해 주신 이 루프는 너무 다 맞는 얘기고 그다음에 이런 세상을 우리가 이미 살고 있다라는 생각은 드는데 그럼에도 불구하고 우리가 도망갈 영역은 여전히 계속 생긴다.
최승준 정석님이 그동안 하신 이야기를 봤을 때, 정석님은 스스로의 암묵지를 자동화하고 싶은 것 아닌가요?
노정석 많이 하고 있죠. 많이 하고 있고 그러면서 현실과도 많이 부딪힙니다. 회사에서도 저 기능 저 기능은 자동화해야 되겠다고 했는데, 자동화하는 과정 자체를 아예 이해하고 싶지 않아 하는 사람들도 있고, 본인들이 익숙한 조직 구조를 빨리 다시 만들어 달라고도 합니다. 그럼에도 불구하고 사람이 다 해야 되는 일이 있지 않느냐는 것인데, 저는 그 사람이 지금은 사람만 할 수 있는 일이지만 저 부분을 자동화해 내야 된다는 일종의 manifesto가 있는 것이고, 그 기저가 다르다 보니까 의견이 갈립니다.
OKR로 모든 업무를 verifiable하게 만들기 53:47
그런 부분들이 저에게만 일어나는 일이 아니라 앞으로 다른 곳에서도 다 일어날 일이겠다는 생각이 들고, 제가 요새 연습하고 있는 것은 과학 논문이나 남들이 만들어 놓은 하네스, article 같은 것들이 있을 때 암묵지의 영역 중에서 굉장히 중요한 능력이 되는 것이 모호한 영역들에서 무엇을 목표로 설정하는가의 능력인데, 아직은 LLM에게 물어봐도 잘 못하는 경우가 많거든요. 엔지니어링이라든지 수학 과학 같은 경우에는 모델이 저보다 더 많이 알고 있으니까, 혹은 제가 그 부분을 많이 알지 못하기 때문에 모델이 더 잘하는 경우가 많은데, 예를 들어 비즈니스적 판단이라든지 조금 더 글에 가깝고 사람에 가까운 영역에서는 metric을 잘 못 만듭니다. 그러면 그 metric들을 정의하는 것, 어디까지가 성공이고 어느 방향이 진보하는 것인가를 정하는 것이 사람의 능력인 것 같아요.
그러한 식으로 요새 저의 모든 문제를 다 치환해서 풀고 있거든요. 목적물이 엑셀이다, 슬라이드다, report다 하면 그 목표는 무엇인가. 경영학에서 이야기하는 OKR이라는 것이 있거든요. 업무와 성과를 어떻게 규정할 것인가 하면 Objective and Key Results입니다. 예전에 구글 다닐 때 어마어마하게 훈련받고 그것으로만 했었던 것이 이제 어쩌다 보니 인생이 좀 굳어졌는데, 무엇을 하든지 그것의 목표는 무엇인가를 objective로 강하게 쓰고, 그 목표가 이루어질 때 우리가 보게 되는 기대되는 key result, 핵심 결과물은 무엇인가. 그것이 OKR인데 최대한 감성적으로 쓰지 말고 다 숫자로 치환해서 쓰라고 합니다. 언제까지 무엇을 론칭한다고 하면 정확한 날짜가 있어야 되고, 기대되는 visual들이 다 describe 되어 있어야 되고, 그것이 matching되면, expectation이 맞으면 0.7, 0.8을 주는 것이고 훨씬 잘하면 1.0을 주는 것이고 아니면 0을 주는 것이고, 그런 식으로 끊임없이 objective와 key result의 보상을 주는 실험을 해왔던 것이 제가 지금 무엇을 하는 데도 굉장히 도움이 됩니다.
auto research도 OKR을 쓰거든요. 가장 최근의 경험은, 예를 들어 저만의 하네스로 Chedex라는 것을 만들어서 Codex 위에 살짝 얹혀 쓰는데, 매우 진한 Ralph loop과 auto research loop, 그리고 Ultrawork 같은 것들을 가져온 것인데, 그 가져오는 과정에서 쓴 것도 비슷한 루프입니다. 결국 비슷한 것들을 어떻게 적용할 것이냐. 목표는 Codex의 bare metal 버전이 계속 올라가고 있지만 올라갈 때마다 달라지는 점에 대해서, 새로 들어온 native feature와 이미 만들어 놓았던 Chedex에 있었던 feature, 그리고 reference로 했었던 예찬님의 Oh My Codex 같은 것들 사이에서, 그것도 변하고 Oh My Codex도 변하고 native도 변하고 Chedex도 바뀌는데 내가 원하는 것은 무엇인가. native를 최대한 유지하면서 native가 제공하는 hook의 기능으로만 일종의 governing structure, loop structure를 짜고, 그럼에도 불구하고 저쪽에 있는 기능들을 가져와야 한다면, 그 사이사이에 무엇이 옳은 metric인가를 정의해 줘야 합니다. 저쪽에 있는 것을 objective B, 이쪽에 있는 것을 objective A, 목적물 C 이렇게 해놓고, 이것과 이것의 delta를 scalar로 정의하고 저것과 저것의 delta를 scalar로 정의합니다. 어느 정도 feature가 꺼내졌으면 그때부터는 C라는 결과물을 놓고 스스로의 자기 개선 루프를 돌립니다. auto research loop를 걸어서 문서와 코드의 정합성, 코드가 전략적으로 가지고 있는 문제점들에 대해서 고문하는 것이에요. defect로 찾아낸 것들의 숫자가 0이 될 때까지 루프를 계속 두라고 하면, 어설프게 착즙해왔던 것들의 대략의 목적성이 뽑히고 나면 사실은 objective라는 상을 가져오는 것이잖아요. 그러면 스스로 recursive한 루프를 돌면서 모델의 능력에서 뽑아낸 우수성 때문에 스스로 진화합니다. 0이 될 때까지 그런 것들이 다 matching되어 제가 계산하는 metric 범위 안에 들어오면, 중간 산출물이나 코드를 한 번도 본 적이 없고 열어보지도 않지만 한 2시간 돌더라고요. 2시간 돌고 나면 그것을 배포하고 믿고 씁니다.
그런 식으로 업무 루프를 다 바꾸고 있어요. 사람과 무슨 일을 할 때도 objective와 key results를 최대한 모델이 verifiable reward 형태로, scalar의 value 형태로 받아들일 수 있게 정의하는 것이 요새 저의 모든 업무가 되고 있거든요. 효과가 매우 좋습니다.
GAN에서 영감받은 Anthropic의 멀티 에이전트 하네스 설계 가이드 59:13
최승준 비슷한 이야기의 다른 변주라고 느껴지기는 하는데, 어쨌든 그것을 verifiable하게 번역하는 능력이 지금은 중요한 것이잖아요. 거기에 dependency가 있는 것이죠. 그런데 제가 아까 빼먹은 것이, Anthropic에서 이번 주에 공개한 장시간 애플리케이션 개발을 위한 하네스 설계도 거의 같은 이야기가 있습니다.
제가 몇 개를 강조해 놨는데, GAN의 아이디어를 썼습니다. Generative Adversarial Network의 영감을 받아 에이전트 평가기와 에이전트로 이루어진 멀티 에이전트 구조인데, 이것도 Ralph loop입니다. 하고자 하는 바가 디자인 영역에서 주관적인 판단을 구체적으로 채점 가능한 항목으로 바꿔준 기준 집합을 개발해야겠다는 서론에 나오고, 이것도 결국 점수화시키는 것이죠. 일견 점수화시키기 어려운 것입니다. 그냥은 안 됐는데 순진한 구현이 아니라 하네스를 깎아서 쌓아 올려 어떻게 했느냐의 스토리가 있고, 맨 마지막 부분으로 점프해서 보면, 한번 읽어볼게요.
다음에는 무엇이 올까? 모델이 계속 좋아질수록 대체로 더 오래 일하고 더 복잡한 작업을 해낼 수 있으리라 기대할 수 있다. 어떤 경우에는 모델 주변의 스캐폴딩이 시간이 갈수록 덜 중요해져 개발자는 다음 모델을 기다리는 것만으로도 일부 문제를 자연스럽게 해결할 수 있다. 반면 모델이 더 좋아질수록 베이스라인만으로는 할 수 없는 복잡한 작업을 달성하는 하네스를 개발할 수 있는 공간도 더 커진다.
이 점을 염두에 둘 때 이번 작업에서 앞으로도 가져갈 만한 몇 가지 교훈이 있다. 자신이 기반으로 삼는 모델을 직접 실험해 보고 현실적인 문제에서 그 trace를 읽고 원하는 결과를 얻도록 성능을 조정하는 것은 언제나 좋은 습관이다. 더 복잡한 작업에서는 작업을 분해하고 각 측면에 특화된 에이전트를 적용하는 것에서 추가적인 여지가 생기기도 한다. 그리고 새로운 모델이 등장하면 일반적으로는 하네스를 다시 검토해 더 이상 성능이 핵심이 아닌 부분은 걷어내고 이전에는 불가능했던 더 큰 능력을 끌어낼 새 구성 요소를 추가하는 것이 좋다. 이번 작업을 통해 내가 갖게 된 확신은 이렇다. 모델이 좋아질수록 흥미로운 하네스 조합의 공간이 줄어드는 것이 아니다. 오히려 그 공간은 이동한다. 그리고 AI 엔지니어에게 흥미로운 일은 그다음에 새로운 조합을 계속 찾아내는 것이다.
노정석 제가 이야기했던 부분의 정리된 에디션이네요. 저도 정확하게 이렇게 생각합니다.
최승준 지금 모두 다 인식은 같아요. 2026년 현재 가능한 게 뭔지 다 인식은 같고
노정석 중요한 포인트는 drift라는 표현을 요새 많이 하잖아요. 우리가 목적하는 바와 벌어진 이격, 델타를 drift라고 표현하고 이것이 상당히 유행어가 되어 가고 있는데, 저는 그 drift의 기준점을 항상 최신의 프론티어 모델과 그 프론티어 모델에 정확하게 맞춰진 하네스의 최전선으로 잡습니다.
최승준 그게 이동하는 거죠.
노정석 계속 좋아지죠. 계속 좋아지는 것 때문에 예전에 안 되던 일들, 아까 이야기했던 것처럼 제가 신약 개발을 할 수도 있는 세상이 된 것이죠. 저도 신약 개발을 해보려고 하고 있고, 그런 것들을 위해서는 또 다른 하네스를 필요로 합니다. 새로운 하네스에 대한 definition이 있을 것이잖아요.
그것이 AI 시대에 우리가 모두 추구해야 하는 가치 지점이에요. 이런 경험을 계속하면서, 다음 도전의 영역은 여기고 본질은 여기고 여기에 더 집착해야 한다는 것이 조금 생기고 있는 것 같아요.
카피바라 모델 소문과 다음 프론티어 62:50
최승준 이동의 측면에서는 소문이 있습니다. 다음 모델에 대한 것인데, 카피바라라는 것이 모델명이 아니라 정확하지는 않지만 Opus 다음의 tier라고 합니다.
노정석 더 훨씬 좋은 모델이다.
최승준 Opus 그다음에 카피바라다라는 얘기가 소문이 좀 나오고 있습니다.
노정석 현재 Opus가 Kimi나 DeepSeek 같은 모델을 보면, 프론티어급 성능과 비슷한 것이 1T에서 2T 정도 사이이고 Opus와 Gemini 3.1도 그 정도일 것이라는 추정들이 많더라고요. 진실은 Andrej Karpathy 정도는 알겠지만 저희는 모르는데
최승준 그래서 소문에서는 내부 모델이 10T다, 그런 얘기가 있기는 합니다만 나와 봐야지 아는
노정석 10T라니, Elon Musk가 다음 모델이라고 이야기한 것도 7T라고 했거든요. 10T이니까 서빙은 지금은 못 하는데, 또 하지 않을까요? 사실 컴퓨터 더 붙이면 되는 것인데
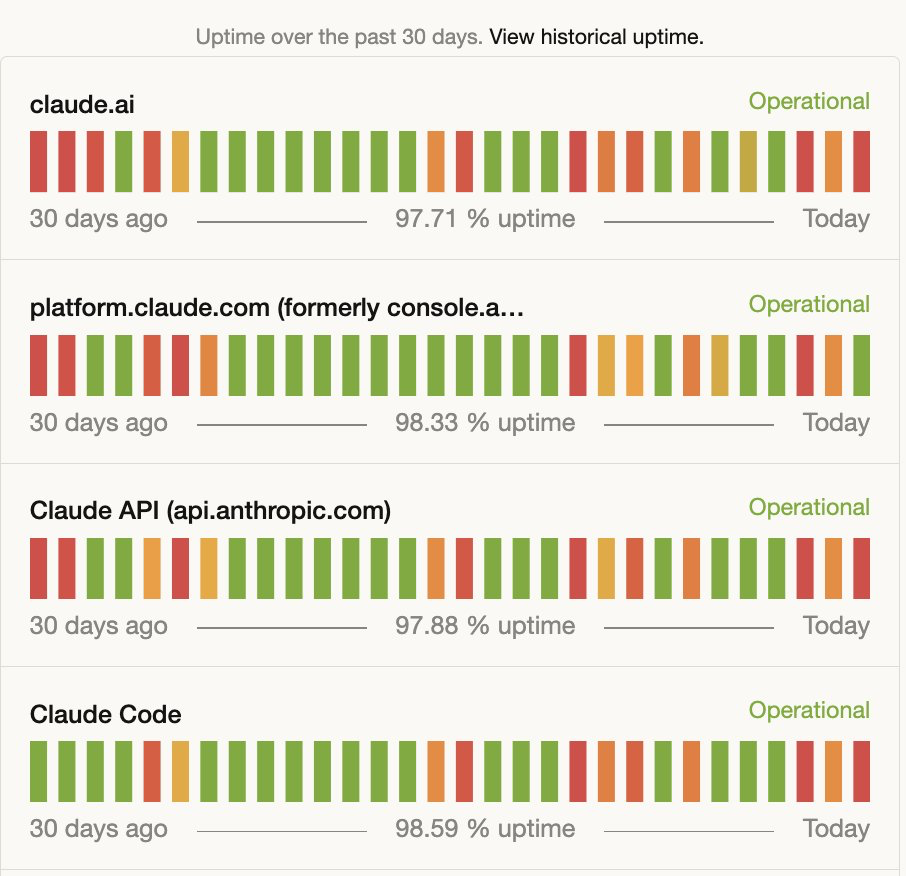
최승준 하여튼 얼리 액세스를 제공하겠다는 문건이 유출됐다 해서, 그런 것들이 이번 주 후반부에 있었고 당장의 문제는 이번 주에 Claude가 장애가 많았습니다.
노정석 수요가 높나 보다.
마무리 64:14

최승준 수요가 지금 많이 늘어나서, 이런 것이 멈추면 어떻게 되나 하는, 저번에도 한 번 언급했던 지구가 정지하는 날 생각이 한 번 더 납니다. 일단 오늘 준비한 것은 여기까지인데요. 제 관찰은 농담은 안 된다는 현재의 관찰이며, 혹시라도 유튜브 보신 분들 중에 도전해 보고 싶다 하시면 성공 케이스가 있으면 댓글로 알려주십시오.
노정석 이번 주에 델타를 한번 뽑아봤네요. Andrej Karpathy의 이야기는 굉장히 본질적인 내용들이 많기 때문에, 승준님이 준비해 주신 스크립트를 한번 읽어보시거나 모델에 넣고 티키타카를 해보시는 것이 큰 도움이 될 것 같고요.
최승준 그러면 또 저희는 다음 시간에
노정석 네, 다음 시간에 다음 주의 내용을 가지고 이야기해 보도록 하겠습니다. 이번 주는 여기까지 하겠습니다. 감사합니다.