EP 78
Ilya Sutskever 的说明
开场:Ilya Sutskever 与“研究时代”宣言 00:00
卢正锡 今天是我们录制节目的日子,2025 年 11 月 29 日,周六早晨。这周如果要选最大的新闻,应该就是 Ilya Sutskever 和 Dwarkesh Patel 的播客了。
Ilya Sutskever 说当前的 pre-training 已经撞到墙了。需要一些新的想法。现在 scaling 的时代过去了,研究的时代再次到来。围绕这些说法,社区确实震动了一次。可能因为影响太大,后来还发了修正推文。升准你来总结一下吧。
崔升准 听你这么说,感觉 Claude Opus 4.5 被埋了。都在聊 Ilya Sutskever。
卢正锡 也确实有那么一点,不过在工程师圈子里,大家都觉得 Claude Opus 4.5 非常聪明。所以 Antigravity 和 Claude Opus 4.5 来回切换,哪个先到 token limit 就切到另一个,现在好像基本稳定了。
崔升准 所以这周我们也是在大家期待的信息基本都摊开之后,先从 Ilya Sutskever 这个话题开讲,标题先定成了“伊利亚 token”。凌晨时间线太沸腾了,Noam Brown 还发了整理帖。成贤你怎么看这波时间线爆炸?为什么会发生这种事?
Scaling 争议:扩展为经济·安全问题的 AI 01:17
金成贤 如果 AI 这个领域本身只是学术领域,我觉得不会发生这种问题。学术圈里这类争论一直都有。LLM 行不行,围绕 Yann LeCun 也有很多类似争论,这本来就很常见。但我觉得 scaling 这个主题开始和太大的经济议题绑定了。对我来说也有点措手不及,也会让人非常谨慎。一旦把 scaling 变成核心议题,就意味着要建更多数据中心,要做巨量投资。
建很多数据中心不只是多买 GPU,还要有电力基础设施,要把这些基础设施准备好,最后投资规模变得越来越大,甚至推进到“需要政府担保”的层级。所以大家会问,scaling 真的有效吗?这种投资真的有概率成功吗?这么投就一定会来 AGI 吗?这个主题已经不是纯学术问题,而成了社会经济问题。甚至像是国家层面的问题,有些情况下还会以中美冲突的形式变成安全议题。它开始影响所有经济领域和国家安全领域。所以才会更沸腾。
类似模式也出现在 GPU 和 TPU 的争论里。Google 在用 TPU,这件事在 AI 工程师里不可能没人知道。Google 从早期开始,Gemini 1.0 起就一直在用 TPU。Gemini 3 用 TPU 也是理所当然,因为之前就用了。但“用了 TPU”这个消息传到另一类人群、传到原本不知道 Google 在用 TPU 的人那里后,就引发了巨大连锁反应。可能连股市都受到了实际影响。于是 NVIDIA 出来澄清:GPU 和 TPU 不一样,GPU 依然有竞争力。大概是这样的说法。
崔升准 俗话说就是,赌注太大了。
金成贤 规模实在太大了。变得太大了,围绕这个事实牵动的问题也都太大了,最近就是这样。
卢正锡 其实过去一周股市的走势就和成贤说的一模一样。因为“Google 做 Gemini 3 没用 NVIDIA GPU”这一个事实,Google 股价大涨,NVIDIA 股价就剧烈波动。说是晃得厉害更准确。
崔升准 原来还有这事。那我们先看看 Noam 具体说了什么,再回来聊。
人物介绍:Ilya Sutskever 03:59
卢正锡 在讨论之前,可能有不少人不认识 Ilya Sutskever、Noam Brown、Andrej Karpathy 这些人。Ilya Sutskever 是 Geoffrey Hinton 的传奇弟子,也是最早做出 AlexNet 的传奇 AI 研究者;后来去 Google 做了 sequence-to-sequence RNN 模型,也做了 language translation;再之后去了 OpenAI,上次因为和 Sam Altman 的某种控制权纷争离开了 OpenAI。他是 AI 时代的标志性人物。所以他说什么,市场都会震动,某种程度上像先知摩西那样的角色。正因为是这么有分量的人说的话,我们才有必要认真听。
崔升准 这次是 Dwarkesh Patel 对 Ilya Sutskever 的第二次采访。第一次是在 GPT-4 刚发布的 2023 年 3 月。所以这是第二次。这个采访和 Sutton 那期有点像,Andrej Karpathy 那期也有点像,Dwarkesh 现在在做这种策展。是在做一种想展示不同地平线的策展,所以会引发争论,但我觉得某种程度上也可能是健康方向。
Ilya 的澄清与 Noam Brown 的整理:Scaling 与研究的差距 05:15
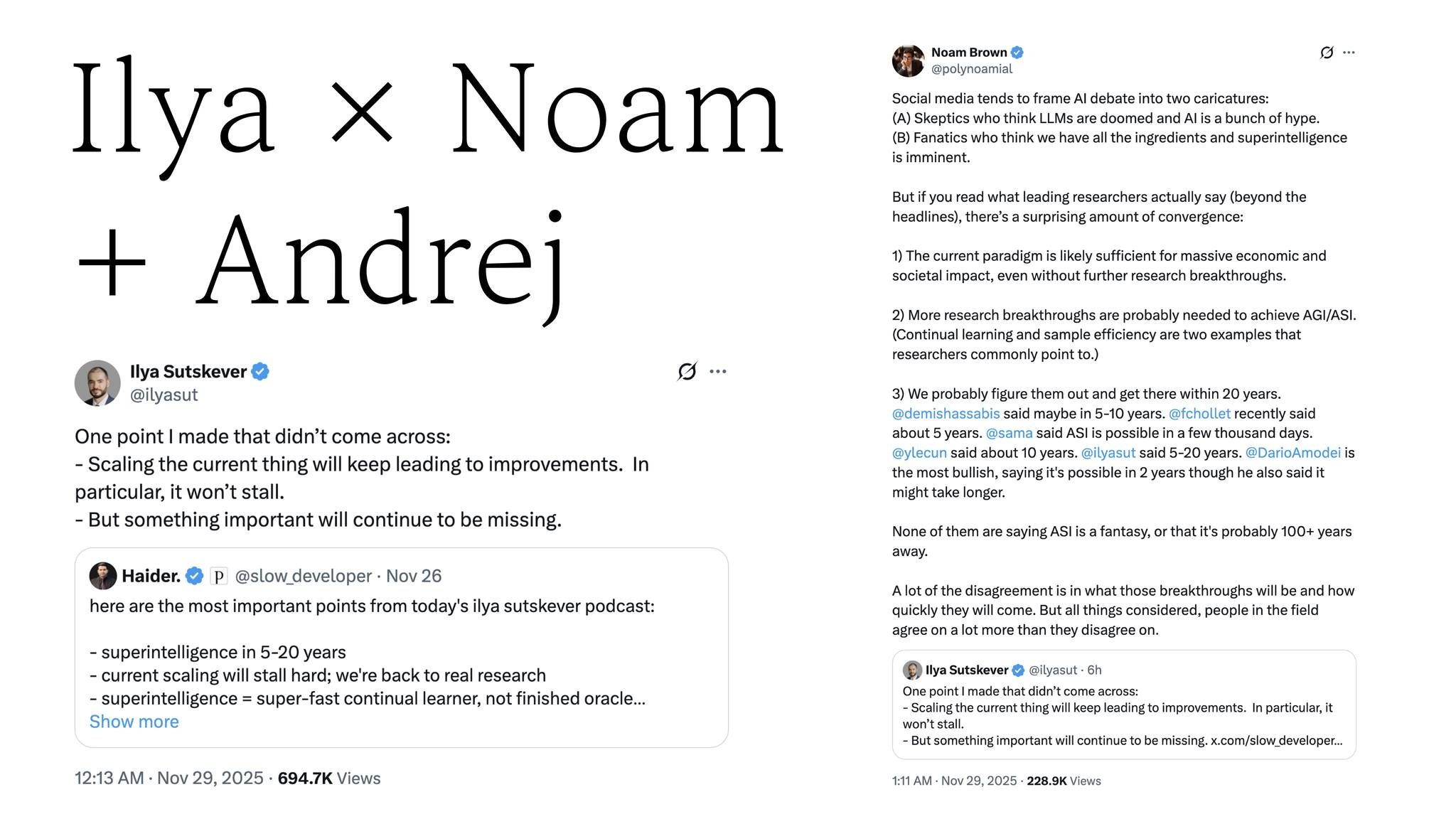
崔升准 不过凌晨 Noam 做了点整理。Ilya Sutskever 说自己在 Dwarkesh 采访里有些点没有被正确传达。他转推了别人引用他做的整理,并在那个引用里补充。意思是:按现在的方法继续做大、继续 scaling,性能还是会提升,不是说不会提升,只是他说的是存在一个 gap。还特别补了一句:这不会在中途停住。但即便如此,仍然会持续缺少某些关键东西。他说自己的重点在这里,并发了推文。
不过 Noam 把这个又放大解释了一层。Noam 强调的是:现在有怀疑派和狂热派,但听研究者实际在说什么,会发现收敛点很多。即便只靠当前范式、没有额外研究性突破,也很可能足以带来巨大的经济和社会影响。但如果真要走到 AGI、ASI,大概率还需要持续学习、样本效率等额外突破。而我们会找到这些突破,并在 20 年内到达。
但这个预测在各位先驱之间不同。Hassabis 说 5 到 10 年,Chollet 说 5 年,Sam Altman 说几千天,Yann LeCun 说 10 年,Ilya Sutskever 说 5 到 20 年,Amodei 最激进,说 2 年内也可能。也就是说,没有人说要 100 年。总体看,彼此一致的部分远多于分歧部分。
另外他还一路引用介绍了 Andrej Karpathy 上次发的内容。Karpathy 也是在上 Dwarkesh 后又发了一篇整理。我已经把内容翻译好了,大家可以通过链接去看。那到这个点,我们还有什么可以补充的吗?
研究者的共识与“持续学习(Continual Learning)”的必要性 07:34
金成贤 这里也可以聊一点。我觉得 Noam Brown 说研究者想法相近,这个判断是对的。因为像我自己在第一场里也提过 continual learning。那并不是我原创的想法,我当时也是听研究者在讲,介绍说最近在发生这些研究、大家有这样的议题意识。所以对我来说这非常自然。Ilya Sutskever 的说法也是一样。反而我更好奇,为什么会有人觉得这很奇怪。
其实类似的事以前也不是没发生过。pre-training 的 scaling 是第一个最大范式。但现在模型性能的提升并不只是靠 pre-training scaling 发生的。如果只靠 pre-training scaling 想达到今天这个水平,规模本来会非常夸张。真正找到突破口的是很研究导向的 o1 和 RL。通过 o1 和 RL,拉出了远超 pre-training scaling 的性能增幅。
如果是这样,那么未来继续发现这种范式当然也依然重要、也依然必要。这和 scaling 并不冲突。它不和 pre-training scaling 对立,但这类研究发现和开发会让模型更强。这和这里总结的内容很接近。也就是像 Ilya Sutskever 总结的那样,scaling 会持续带来性能提升,但会有缺口;而要在这个缺口上找到突破、拿到更大幅度的性能提升,就需要像推理那样的新范式。这种范式不是靠 scaling 自然得来,而是需要研究。
崔升准 所以 Ilya Sutskever 那期标题副标题就是“研究的时代”。
卢正锡 我自己第一次听 Ilya Sutskever 那段时有些抵触,和听 Sutton 时类似。现在只是继续加大 scaling,而且规模终点到底在哪里,谁也不知道。Google 做 Gemini 3 时也说在 pre-training 上解了某些东西,我们并不知道细节。我不太舒服的是那种断言:通过继续加资源、加 computation 去走的那条高洁方向是错的,只有改掉某种底层结构才能带我们去下一阶段。
不过成贤你可能会好奇,为什么从商业视角吸收信息的人会有不同理解。某种意义上,就像上次升准展示的那张“哥德尔、艾舍尔、巴赫”的图,问题本质可能存在于不同维度,但它确实存在。只是因为各自视角、术语定义不同,所以会形成不同表象;而这些不同表象之间其实又有同构性,本质上处理的是同一个问题。
所以 Ilya Sutskever 其实也像你刚说的那样,后来在 Twitter 上修正了一点意见。不是说 scaling law 错了,而是它会持续带来 gain,但要跳到下一阶段需要研究。这我当然同意。完全同意。

崔升准 这个挺有意思,金有珍告诉我后我也去看了,Dwarkesh podcast 的 thumbnail 变了。最开始写的是 “It’s back to the age of research, again, just with bigger computers.”,就是回到研究时代,只是用了更大的 computation。后来改成了 pre-training overshoot target。因为在社交媒体成了话题,感觉语气做了调整。
他说了什么我们等会儿再看,但现在有个正在被玩成梗的点。这个也是卢正锡你提过的,Dwarkesh 问 SSI 到底怎么赚钱,得到的回答是:专注研究,问题的答案会自己显现,会有很多可能答案。其实我感觉 Noam Brown 也说了类似的话。因为他说“我们大概会找到那些突破”。所以 OpenAI 会按自己的方式找突破,所有 top lab 都在找还有什么新东西,这太正常了,毕竟要做研究。
SSI 现在虽然不能公开,但路径是拿着融资先专注研究,而不是立刻赚钱。这个说法现在也确实成了一个梗。那 Ilya Sutskever 的内容我们没法全摘,但可以拿几张幻灯片来聊,这些是 Claude Opus 4.5 做的。AI 让我们来讲 AI 抽出来的重点,应该也挺有意思。
它抽的是已有内容。我先介绍第一张,这是采访前段一个很 informal 的场景。Dwarkesh 和 Ilya 还没正式开录,机器先开着,他们边聊边说,眼前景象像从 SF 里跳出来的一样。然后 Ilya 抛了个有意思的话,Dwarkesh 立刻把气氛收住说:“那我们现在开始聊聊,辩一辩?”画面就是这样展开的。下一张是“研究时代”,这个我们刚讲过就先略过。下面这个更值得聊,“惊人能力与离谱失误并存”。成贤你对这个应该有明确看法。
惊人能力与离谱失误并存(RL scaling 的局限) 13:40

金成贤 这好像是从“训练了 1 万小时的竞赛编程选手”和“只训练了 100 小时的人”的差异这个比喻展开的话题。我觉得这种现象可以有很多解释,但我认为是 RL scaling 目前的局限。要做 RL,最终得有环境。模型要在环境里做 RL、做学习,而这些环境都得一个个搭起来。再想想,评估通常希望能自动完成,或者即便有人介入也尽量少介入,所以评估本身就是一种环境。以这个环境为 target 做 RL,就能训练模型。那模型当然会评得很好。
但问题是,这个环境和真正有经济价值的工作、和人们实际使用之间有多大相关性,是另一回事。那就意味着,对于人类真实和模型交互的方式、对模型的使用方式,需要构造对应环境。而“怎么构造这个环境”才是现在最大的难题。和最近常说的 bench-maxxing 也是一脉相承。把 benchmark 当 target 去学,当然能把 benchmark 做好。但 benchmark 做得好,不代表模型在真实使用环境里就一定表现好。
这里会产生非常多问题。那这些环境要怎么建?靠人一个个搭有上限。人们希望模型完成的任务长度越来越长,越来越长的任务怎么建环境?这个环境怎么和真实人类使用环境更接近?这个环境最终必须由人来搭吗?能不能由模型来搭?再往前一步,模型在某个特定环境里学到的东西,怎么泛化到新环境?这些问题会不断出现。而怎么 tackle 这些问题,就是现在 post-training 阶段各家 big tech 在竞争的核心之一。
关于“环境怎么建”这件事,公开信息还更少。pre-training 时期也是,大家怎么做 pre-training,细节就有很多秘密,里面肯定也有很多 know-how。但至少还能猜一点。可扩展环境、做 post-training 这一块更被迷雾覆盖。大家实际怎么做,有什么 know-how,有哪些细节,都不太知道。
所以从这个角度看,Gemini、Claude、GPT-5 这些模型虽然都来自 frontier lab,但 post-training 后出来的结果一定不同。因为 post-training 的 know-how 等做法本来就各不相同。所以这本身也是研究问题,为了持续解决它,现在也在持续投入巨大努力。大家都在想办法把 RL 做得更好,去缓解这些问题;做着做着就会想,“有没有更好的方法?”“有没有更根本的解法?”我觉得这大概就是 Sutskever 在谈的问题之一,尤其是和泛化问题相关联的那部分。
崔升准 对。Sutskever 在这里抛的点是:评测上表现很好,但实际用起来为什么会出现离谱 bug?benchmark 明明过得那么好,为什么这个问题却解不了?能感觉到这种落差。还有就是做 RL 时会有点 spiky,有些能力特别强,但会有空白区,大概是这个语气。还有“1 万小时学生和 100 小时学生”的比喻,刚才成贤提过,就是模型像那个苦学 1 万小时的学生,但不像那个只有 100 小时却有感觉的学生。也就是模型的泛化能力明显不足。
金成贤 是的,可以这么看。说泛化明显不足也很合理。人如果学了那种规模的数据、在那种环境里训练,面对新问题应该也会很强吧?再进一步,即便是新问题,稍微学一下也能做好。但泛化会在很多维度上出问题。
刚才也说了泛化问题。比如在某个环境里学会了用 Claude Code 做事,那对新环境是不是也该做得好?这就是一种泛化。再比如如果能完成 5 分钟任务,那是不是应该也能泛化到 1 小时任务?这也是一种泛化。泛化可以在非常多轴上出现。对这些泛化,我们到现在并不算成功。
其实不只看 post-training 这个范式,放到整个深度学习来看,我认为在泛化问题上几乎没有进展。说“某个架构整体上更会泛化”,我觉得并没有特别成功的案例。现在的解法是做 pre-training,就是多喂数据。但泛化通常说的是数据效率高:用更少数据也能做好;即便 pre-training 规模一样,换一种方式 pre-training 就能明显更好。我们关心的是这类问题。可在这些问题上似乎几乎没进展。也确实是极难问题,非常难。谈不上有什么突破或明显进展。
情感就是价值函数:有限理性与启发式 19:44
崔升准 但 Sutskever 讲了个挺新奇、平时不常听到的点。价值函数在 RL 里是熟悉概念,但他说“情感是价值函数”,这部分我也不太容易一下理解。
金成贤 他说的是这个。人们常设想一种人:完全没有情感、绝对理性、只有理智。好像这样的人会永远做最理性的选择。但实际上这种人反而会完全做不出选择。
崔升准 他还提到了脑叶切除术之类的案例。
金成贤 因为有真实案例所以才会提。也就是说,人们以为没情感就能完美、严密地做理性决策,但实际发生的是完全无法决策。我没专门研究那个案例,所以不知道精确原因,但可能是面对海量可能性不断做理性分析,最后被信息和可能性压垮,陷入无法选择的状态。
有情感反而可能帮助解决这个问题。我们很多时候不能只靠理性做决策。最终总有要在不确定中跳跃的时刻。这个时候,情感会在和理性完全不同的维度发挥作用,提供帮助。那情感的功能是什么?可能有很多解释。我没特别深入想过,但既然他比喻成价值函数,就可以连着理解:价值函数就是描述某个状态会导向多大回报的函数。
也就是这个状态会导向更大回报,那个状态会导向较小回报,大致如此。直觉上可能会觉得这应该是非常理性地估计出来的。比如人通过理性理由把某个条件和高回报联系起来,判断这个状态、这个环境、这个条件更可能通向高回报。但人的决策真的如此运行吗?再进一步,世界真的按这种形式组织吗?这恐怕是另一回事。
世界里有很多不确定和不可预测因素。那在不确定中做决策,说“这个状态更好”“这个判断更好”,很可能是强烈情感化、基于信念的领域。而这种信念在决策中可能非常有帮助。
崔升准 这么一听,Sutton 在讲“大世界假说”时谈的是有限理性,Ilya 也是类似但语气不同。他像是在说,情感这类目前 LLM 里缺失的东西,可能才让人类成为可执行的 agent。好像那里藏着线索。
金成贤 用“有限理性”来表达,就是说仅靠理性条件无法判断所有问题。那时非常有帮助的就是 heuristic。比如看到脏东西会躲开。那是 heuristic。如果真要完全理性决策,就得分析这个脏东西对我是否有风险。但我们会用更直接的 heuristic。而“躲开脏东西”又和情感高度绑定,比如和厌恶情绪纠缠在一起。
不过我觉得在提到价值函数时,Sutskever 后面转到更机器学习相关的意思是:在 RL 里价值函数的作用,是让训练更 sample efficient、学习更快。那这件事即便没有价值函数,也可以低效地做到类似结果。也就是说,没有价值函数也能用低效方法接近类似结果。
但 Sutskever 似乎在碰触比这更根本的问题。不是“低效但还能到达”,而是“即便低效也到不了”的那类问题。他更在意的是这种问题,超出了价值函数本身。Sutskever 以前确实常讲类似内容。他也做过和情感相关的研究,以前还提过模型可能需要自我意识,有自我意识会更有用之类。他似乎一直在持续讲这条线。
“哥德尔、艾舍尔、巴赫(GEB)”与 AGI 的诞生条件(奇异环) 24:30
卢正锡 所以关于这个讨论,我自己有一套土味哲学。
崔升准 挺好奇。
卢正锡 关于“情感是什么”“灵魂是什么”这类问题,以前你也喜欢的 GEB,“哥德尔、艾舍尔、巴赫”,那本书很晦涩,所以解读很多、视角也分歧。你看,GEB 也在谈无法被证明的事实。那他真正想说的核心,是 “I, Who am I”,“我是谁”这个问题,也就是我们身体里循环着的“灵魂系统”到底是什么。他是想通过一本厚书去证明这个,Douglas Hofstadter 是这么说的。
他举的第一个例子是蚂蚁。单只蚂蚁其实也是某种 intelligence,是由一点 neural net 构成的 intelligence,这个单元本身也是 computation 单位,它们会形成群体。单只蚂蚁只是愚钝而简单的 instruction set,但当它形成巨大群体时,整体问题解决能力会很强,足以称作 intelligence。 他把这个叫作 “Ant Fugue”,意思是只要规模足够大,不管底层基质是什么,上层东西都会涌现。但这里还有更重要的一步,这还不够。光有 scale 不够。
所以他给“灵魂诞生”抓了两个条件,第一个是 scale,第二个是叫作 “Strange Loop” 的存在。这个 “Strange Loop” 其实和 generalization 密切相连。他说这是灵魂诞生点。 两面镜子对着放,中间会出现无限映像,而在处理这种“无限”的过程中,“我”这个概念会突然跳出来。
底层硬件和上层软件这样叠着。比如我们的思维就是这样。软件做出某个决定后,这个决定会反过来改变硬件,也就是介质。神经元连接会改变。所以软件和硬件不断耦合,就像 Escher 的画里无限上升的楼梯那样,上下层持续连接,最后会“啪”地诞生一个概念:I,也就是“我”,一个新的 OS 会出现。
像 Hofstadter 的 GEB 视角,就是底层有足够 scale,scale 的各层互相纠缠、循环,他用 “Strange Loop”“Tangled Hierarchy” 来描述。内部会产生矛盾,而为处理这个矛盾诞生的概念,虽然在系统内,却像是站在系统外看系统内的上位价值。那就是灵魂。他说这正是因为我们是硬件和软件结合的结构才会发生。
再回到 LLM。Hofstadter 说要让 “Who am I” 这个 soul operating system 出现有两个条件,一个是 scale。这个方向我们现在就在走。第二个是 “Strange Loop”。也就是 input 和 output 要纠缠起来。
这正好和成贤说的 continual learning 概念连上。但 continual learning 不一定非要在单个 Transformer circuit 里实现。就像人类也把备忘录、语言和所有环境拿来当 RAM。其实都在当 memory 用,流一直在循环。
所以我觉得现在我们用的 Transformer 只在输入瞬间做 autoregressive 运行,而当你给它增加 token 的激励时,它会在 token 内形成某种像奇异环那样的动力学。于是它看起来像有灵魂一样。那如果 Google 也好、OpenAI 也好,谁把这个和某个系统捆起来,把硬件和软件绑定,把 input 和 output 配上合适工具,让它在里面永续递归地跑,那按 Hofstadter 的说法,它就会必然去问“我是谁”,会成为一个跳出系统之外的新存在。
我个人觉得这就是 AGI。讲太长了,Long story short,我对现在这些研究视角都同意,但从哲学视角看,我认为 AGI 的诞生点是把 scale 和 loop 连起来。scale 这部分像是已经满足必要条件了;当第二个条件满足,它会自己思考并突然形成“自我”概念。到那时人类自认为只有人能做的事,它也会做。这个 loop 无论是奖励函数还是什么,都会成为它自我求解的起点。 所以也许问题会被很容易地解开,不,甚至可能已经结束了。这就是我一开始说“土味哲学”的原因。你们可能不一定同意。
崔升准 把卢正锡的说法再压缩一下,用我的话就是:computation 就是生命汤底。卢正锡现在是这么想的。那在我们往下走之前,有没有谁想补一句?
真正的智能不是模型,而是系统 30:35
卢正锡 对。我想听听成贤的反馈。其实不是我的理论,是 Hofstadter 的说法。
金成贤 其实那也确实是理解持续学习的一种方式。因为这种表达经常出现。好像是 OpenAI 的人说过:如果 OpenAI 里真出现了所谓 AGI,那不会是 GPT-5 这种单模型,而是训练 GPT-5 的 RL framework、系统,整体合在一起才是一个智能体。
那“RL 系统和模型结合”到底什么意思?如果这么想,RL 环境中的某些系统会持续修改模型。放在持续学习语境里,面对新问题、新任务,这个系统会修改它自己。说是修改自己,简单讲就是修改系统内模型的权重。
而这个“修改过程”会基于系统判断:应该这样改、应该以这种方式改、应该获得这些技能,会在这种判断和某种奖励下继续修改。再往前一步,决定“该怎么改”的也可能是系统里的模型本身。这样也能形成环。
是的,如果按 continual learning 来想,最容易想到的就是这种系统。模型改模型自己,或者系统改系统自己,针对新任务持续改。当然现在关键问题仍是如何实现,但这确实是一条可以直接想到的方向。
人类的样本效率与内在动机(社会性欲求) 32:16
崔升准 所以 Sutskever 用 6 岁孩子做比喻,说“人类样本效率高得多”。这和刚才价值函数、情感比喻也类似,进化可能给我们编码了某些欲望,而那最终驱动了我们这类存在的形成。如果你有想补充的就说,没有的话我继续。
金成贤 其实这两点我都有话说。一个是“社会性欲求”本身就很有意思。这个话题 OpenAI 以前的研究者也说过类似的。孩子会探索。孩子探索时更接近嗅觉等原始欲求。但孩子成长后进入语言游戏、进入语言社会,社会性欲求和语言问题会开始提供动机。比如会出现对社会地位的欲求。这些会成为内在动机。那内在动机如何实现?这就是有趣主题。OpenAI 研究者确实提过这个点。
崔升准 谁说过这个?
金成贤 Yao Shunyu 在采访里提过类似表述。怎么把这种 motivation 赋予模型,“这是个有趣问题”。这也和之前提过的 intrinsic motive、内在动机问题很像。内在动机会让人在没有奖励的情况下也持续追求某些目标。
当时 Yao Shunyu 举的例子是数学证明。比如费马大定理这种证明。完成这个证明的奖励,绝大多数人都拿不到,而且是花一生最终可能只经历一次的奖励。但为了抵达这个奖励,很多数学家靠内在动机去探索。
然后他们也许会在内在动机驱动下发现一些小突破并获得奖励。这种机制怎么发生,似乎是他们真正感兴趣的主题。也许 OpenAI 内部,或者 Ilya Sutskever 也经常讲这些。
崔升准 也有可能。类比 RL 的话,就是 rollout 长得夸张,但他们还是做了,就是为了那个奖励。
泛化(Generalization)与归纳偏置(Inductive Bias) 34:29
金成贤 泛化也可以聊聊。这也非常有意思。说到泛化,就得提一个现在机器学习研究者很不喜欢的概念:inductive bias。很多人会说,模型的发展过程是在不断粗暴地消除 inductive bias。 但泛化如果没有 inductive bias 根本不可能。因为 inductive bias 的定义本身就是:看到新数据时如何对其做预测,所需的偏置就是 inductive bias。
那人类的 inductive bias 是什么?这是很难的问题。人类有发现模式的能力,会发现模式、做总结、提炼原理,这是一种偏置。但人类发现的模式也不总是成功的。对某些现象,人会构造出非常离谱的解释,也会构造出非常复杂的解释。
但我也觉得,泛化到底该怎么处理非常难,尤其从机器学习角度。这里面有一个方向是最小算法。最简单算法,从信息论或 Solomonoff induction 那边看,可以理解为最短长度算法。
那就要找到最短长度算法。但 Solomonoff induction 本身是不可计算问题。那模型要泛化,就需要有一种偏置:偏好最短算法、最简单算法。
崔升准 就像奥卡姆剃刀。
金成贤 对,像奥卡姆剃刀。这个相关的我之前也简短讲过:最佳泛化是发现算法;而要发现算法,模型或训练条件必须具备执行算法的条件。我好像提过这一点。那可能只是最低条件。通过这个如何到达泛化,会是有趣话题。 比如推理就是比泛化更强的方法。而推理之所以能导向泛化,是因为推理条件里有某种 bias:偏好简单算法,避免死记硬背。 这是个有趣但很难的问题。它和现有范式在某些方面也冲突很多,所以最终怎么解,我也不确定。
卢正锡 其实 Transformer 也是一种 bias。它注入了“用这种方式在内部计算模式”的偏置。结果只是把 scale 拉大、塞数据,就开始出现魔法般的事情,甚至看起来会计算、会干别的、会思考。相比“Transformer 这个模型本体、GPT-5 本身要成为 AGI”的概念,像成贤刚才说的,GPT-5 也可以成为新 element。它可以变成一个神经元。它们在上层 harness 里 100 个聚合、1 万个聚合,从某种角度又能转译成另一种 scale 问题,这其实也是 research。
金成贤 这些问题确实一直缠在一起。想做 continual learning,样本效率高会好很多。不是 Ilya Sutskever 说的,好像是别人说的:人手碰到烫的东西,试一次之后就再也不会去碰。这对持续学习帮助很大。即便做持续学习,如果不是反复试错,而是一两次就能快速学会,那价值会高得多。
崔升准 这次 Opus 4.5 出来后也有人说,Opus 4.5 可能比 Sonnet 4.5 更便宜,因为 Opus 4.5 few-shot 就能搞定,不用跑很多轮。相比 Sonnet 长 rollout,性能更高还更省。也就是说样本效率高、一次把事做好,可能更有效。然后在你刚才语境里我想到一点,Noam 是不是也说了,方向可能是让模型能够生成 inductive bias。也就是让模型能构想到足以产生 inductive bias 的算法,这可能很关键。
这张图里有个有意思的点:这是 Claude Opus 4.5 做的。我没要求它做这个。它做了 flocking behavior,而且是在这个话题里做出来的。它是在把“社会性欲求驱动我们成为当下这种存在”的说法,类比成社会交互去表达。挺有意思吧?
直奔超智能(ASI):能学会一切的种子 39:17
崔升准 好,那我们进入下一段。直奔超智能。这个部分我觉得 Ilya 的视角很有意思:他要的不是某个特定领域里能力 spiky、参差不齐的 AGI,而是想做一个“能做一切”的种子。Dwarkesh 追问过:所以最终是要把这个部署到经济和社会中吗?但 Ilya 的遗憾是,现在那些用 RL 抬性能的 LLM 还会犯离谱错误。他想构想到某种能解决这些问题的新种子,这才是他理解的通向超智能路径。我是这么读的。有人有不同看法吗?
金成贤 他好像确实是这么表达的。不是说一开始就有个 agent 能解所有问题,而是那个 agent 本身一开始也有解不了的问题。但当它被 deploy 到真实现场后,会开发并学习它新需要的技能,然后把问题解好。
我同样觉得,这幅图很多人都在画。随着 continual learning 概念进入,大家想通过 continual learning 实现的就是这种图景。也确实有些领域天然只能这样。比如公司场景,公司有内部机密,信息不能外泄,公司内部又有 process。
在这种情况下,公司内部发生的事情不可能让模型提前学完。那么最有效的 agent 是什么?就是能进入公司、吸收公司内必要信息、学习公司 procedure 和 process,再去处理公司业务的 agent。这种 agent 会更合适。
崔升准 谁都会想要那样的东西。
金成贤 是的,我也认为很多研究者都在构想这个图景,很多提 continual learning 的人都在想这个。它也可能具备足以被称为超智能的特性。比如快速掌握公司内所有信息、所有 process,并持续学习,最终超过人的水平。
不是有这种说法吗:仅凭当前技术就足够产生经济影响;但仍需要新技术。大概就是这个意思。Dario Amodei 好像也这么表达过:现在模型已经可以创造经济收益;我们继续大规模投资,是为了通过下一代模型竞争。 所以,当前技术水平能创造经济价值,这几乎是确定的。但如果这些问题开始被解决,产生的经济价值会非常巨大。
崔升准 order 可能会不一样。
金成贤 是,规模会不一样。会是完全不同的感觉。
卢正锡 没错。所以刚才 Noam Brown 的那篇整理里,升准展示的内容也一定包含这一点:就算以当前 AI 水平也已经不差了,非常能用。其实从我们 3 年前、几年前的视角看,很多事已经像超智能。这个点绝不能忽视。还有,我们常说 AGI 要来了、要怎样,但人就是这样,如果预期不断后延,就会产生“不马上行动、先等等看”的激励,于是把更多期待押在未来。我觉得这也是个问题,所以我们自己也要非常警惕地解读。
崔升准 现在进入后半段。听众怎么想我不知道,但甚至连让我做这套幻灯片的我本人,今天也是没先深想内容就来录了。就是拿着 Claude Opus 4.5 抛给我的东西来聊。
卢正锡 TikTok 上很多 influencer 其实是假的,只是我们没识别出来而已。但如果我们作为用户看了视频觉得有趣、满意、对自己有帮助,那它是 AI 还是人,到底有什么区别?一样的。
做好研究所需的“品味(Taste)”与眼光 43:42
崔升准 最后 Sutskever,也就是 Ilya,在收尾时讲了“品味”,taste。我觉得这个词最近特别重要,是一个高度压缩的表达。品味。
金成贤 对,研究者也经常这么说。要有好品味。我自己也一直在思考这个问题。那就是,要有好品味,可这种好品味怎么培养?
崔升准 这就是把我们刚才一路聊的内容又打了个反复记号。
卢正锡 这里也是 strange loop 在形成。反复记号不断重复,上层和下层 entangle。Douglas Hofstadter 说这就是所有进步的起点。
崔升准 对。Douglas Hofstadter 的 GEB 其实就是那个 analogy 系列的最早作品。他很年轻时写的。Hofstadter 是那种持续在有趣事物之间建立类比、一路做到今天的人。也许他本身就有非常好的研究品味。
卢正锡 其实 Noam Brown 也说过类似的。他之所以去钻这个 thinking model,也是和 Ilya Sutskever 吃饭时,Sutskever 给了他奖励。被大师认可,再加上对方说“这个方向对”,于是靠那份信念继续往前,这可能也是一种方向性。
金成贤 品味确实是个很有趣的问题。某种意义上就是美学。但研究里也说美学重要,数学家也常说某个数学很美。所以“什么是美的数学”就是重要问题,对机器学习研究者也同样重要。如果说机器学习研究者的好品味是什么,应该是在研究结果出来之前,就知道该往那个方向走的能力。知道“朝这个方向推进更好”,这大概就是好品味。但问题还是,怎么培养这种品味,这才是关键问题。
卢正锡 对成贤刚才的话,我又有一套土味哲学。我就是相信量变到质变。量大了,质最终一定会出来。
量变到质变与高能量 token 45:59
崔升准 这和刚才说的一直是同一条脉络。
卢正锡 对,然后当“质”这种高价值信息也继续变多,就会再上到下一层。
崔升准 不过这中间有“压缩”啊。不是原样把量搬过去。是压缩出来之后质会提升。
卢正锡 对。其实是从量里抽 essence。那时我很喜欢成贤上次说的,能形成关键分岔的高能量 token。
崔升准 高 entropy 的。
卢正锡 对,我觉得那个特别好。高能量 token 之所以出现,也是因为前面堆了很多没用的低能量内容,才完成下一次跃迁。某种统计意义上它做了那个选择。所以这种“相变时刻”既存在于 thinking token 里,也存在于我们现在讨论的话语层次、层与层之间。因此我们常常用过于还原论的视角,只想在某一层上谈问题,但其实需要自然地在这些层之间穿梭思考。Douglas Hofstadter 最鲜明的类比就是那个:有水,水形成漩涡并猛烈翻卷,那两者关系是什么?底层与上层意义、substrate 与 meaning 的区别并没有直接因果,它会突然涌现。
崔升准 总之到这里我们把 Ilya 的内容做成幻灯片聊了一轮,Claude Opus 4.5 最后一页还给了黄金比例螺旋图。像是在表达“美”。这类品味、眼光,其实在用 LLM 时也很明显:你把边界设到哪里,就可能驱动它走到哪里。 不过今天还没结束。我们快进。
OpenAI 科学团队轶事:黑洞研究者与 GPT Pro 的协作 48:10

卢正锡 快点把现实里的几件事梳理一下,然后收尾吧。 崔升准 如果要选最近两周最让我有印象的两个视频,一个是 Ilya 这个,一个就是这个。Kevin Weil 和研究黑洞的科学家,以及播客主持人,现在虽然离开 OpenAI 了,但总之还在一起做事。压缩讲就是,这位叫 Alex 的人是黑洞研究者,后来来了 OpenAI。这里翻译成“AI 上头”,就是他说自己被 AGI pilled 了,有个契机。
他和 Mark Chen 聊,Mark Chen 当时想让科学家们把 AI 真正用起来、用得有意义,后来和这位碰面时让他扔一个难题,完全是 domain 专家的黑洞科学家就抛了个问题,和对称性有关,是他刚发论文的内容。GPT Pro 试着解,结果错了。于是他想“你看吧,人类还是更强”。Mark Chen 当时表情有点蔫,但他说“请给个简单点的问题”。就是在同一 context 里,哪怕不是黑洞本题,先给个简单一点的。它想了大概 9 分钟,给出了非常漂亮的答案。
然后关键在这里。“好,现在热身例子已经 priming 了,请在这个聊天窗口里再把难题扔一次。”它想了 18 分钟,给出了完全正确而且漂亮的答案。是最新、还没进 pre-training 的内容。他受到很大冲击,然后说“现在就该参与进来,不现在参与简直疯狂”,于是加入了 OpenAI 科学项目。
有这些小故事。但它有现实含义。哪怕在实用层面这个点也很关键。就是先做 priming。难题可以先扔,但热身这件事现在仍然需要,这里给了 insight。然后 Kevin Weil 点出了另一点:如果你给的是能力上限边缘的问题,出错很多,人类也一样。现在还不是全自动。所以需要大量交互、back and forth。真正会用模型的研究者,是能和模型耐心反复对话的人。这很自然,就像两个在能力边界上工作的人协作。
所以这期里其实有很多精华。很多人可能最近已经有感觉了,但也有更多人还没感到这些要点。我觉得这部分很好。然后落到地面,我们快速聊今天能讲的实用内容:Claude Opus 4.5 出了。
Claude Opus 4.5 实战测试:2 行做出“CloudBook” 51:04
崔升准 Claude Opus 4.5,我看 Matt Shumer 做了 vibe check,也跟着试了。我用自己的例子给大家看。prompt 是:做一个 Google Colab competitor,UI 上做个类似 Colab 的;再加一句“all compute is in browser”,做一个只在浏览器里跑的 Jupyter Notebook。Matt Shumer 就是这么做的,总时长 8 分钟。然后 Claude Opus 4.5 就一路规划,写了两行。
看看出来了什么。它直接做了个 CloudBook。现在能看到 Python、Markdown 执行。这里有个 Pyodide 的 WASM,WebAssembly,可以在浏览器里跑 Python 和 NumPy。就这样,跟 IPython Notebook 或 Jupyter Notebook 一样的东西直接做出来了。点一下就成。我又加了一步:在 Markdown cell 里写文字,让它加一个可以改 Python 代码的 generative feature。先说结论:点一下,也成了。现在在 Markdown cell 写文本,就能生成 Python 代码,NumPy 也能跑,全都能用。
卢正锡 哇,真是。哈哈。
崔升准 你都笑出无奈感了吧。这就是 Claude Opus 4.5 的 vibe check,直接手搓 computational notebook。
卢正锡 这种事其实几乎每 1、2 周就在发生。Opus 4.5 也是 4.1 出来后大概 3、4 个月就来了。

崔升准 而且它现在 3D 识别,就是 multimodal 虽然不能生成但读取能力 benchmark 很高,接近 Gemini,所以 voxel 之类也能做。Claude Opus 4.5 很神奇。然后我觉得这就是当下“绕开 continual learning”的一种形态。这篇文章很好,“面向长时运行 agent 的有效 harness”。它会结合 Git 版本管理做 rollback,节省 memory,压缩 context。人类其实也一样,会用 scratchpad、记事本做外化来管理 context,这是人类很大的优势。它展示的就是往那个方向走,而且很到位。
长时运行 Agent 与记忆外化(Harness) 53:00
崔升准 还有上周新闻,Claude Code 也进桌面端了。桌面端更新后有对话模式、代码模式,做了一个让新手也能很容易 spawn 多个实例并行管理的界面,而且很好看。这个我后面会说,有点像 Group Chat 的既视感,而且是同一个方向。也强烈建议去看 Google Antigravity 的 YouTube 频道。很短,但内容非常精。Artifacts、knowledge 的意义,以及外化,这些在 Antigravity 里都有。对抓当前趋势很有帮助。
我在这里写的是“通过外化,出现了用当前模型绕开 continual learning 能力不足的现象。”这和人类做 context 管理很像,也让我开始想象它在未来几个月可能会做得超人级。毕竟已经开始可用了。Group Chat 我最近在高强度练,还不太熟,但潜力很强。这个我再沉淀一周,练更多再详细介绍。有些点很有意思。先只说一个:多人同时交流时,它要同时回应多人,所以它会异步 queuing 回答。比如聊天中让它一次画 1、2、3、4、5,它会 spawn 开并一路全部回应出来。
卢正锡 就是说都在独立 instance 里跑。
崔升准 对。这里面有非常有趣的可能性,对话模式里也有精华,下次我再介绍。
卢正锡 对,我觉得这就是公司的未来。
崔升准 现在这个局面已经没法短短几句讲完了。
卢正锡 对,之后再专门讲一次吧。
结尾:逃亡者联盟与收尾 55:23
崔升准 今天的收尾。终于,当然成贤你是研究者,但像我们这种也只是 AI 爱好者的人,是否也能把 AI 当杠杆,在世界上留下更好的 token,并为进入 pre-training 做出贡献?能不能为更好的世界贡献一点? 不过申请加入逃亡者联盟的人,大家异口同声都在说同一件事,也让我产生既视感:想和看到类似风景的人聊聊,想聊点好东西,想分享,就是这个。
卢正锡 今天就先留一点余韵,先到这里收尾。
崔升准 祝大家周末愉快。
卢正锡 成贤今天来真的太好了。希望成贤能继续加入我们的对话,给我们各种不同视角的反馈。谢谢。
金成贤 谢谢。