EP 82
思考原理的 Prompting
开场:‘思考原理的 Prompting’ 00:00
卢正锡 今天录制这期节目的时间是 2026 年 1 月 9 日周五晚上。我们久违地在晚上录制了。而且这也是 26 年的第一次录制。26 年才刚过去一周左右,这期间已经发生了很多有意思的事。
崔升准 是的,不过还好的是,新闻节奏比起 12 月中旬那种节奏要能承受得多,这点挺庆幸的。
卢正锡 我也是,从 12 月 20 日到 12 月底大概有十天比较安静。
然后新年开始之后,虽然 Big Tech Frontier Lab 还没有特别大的发布,但在社区侧围绕 Claude Code、OpenCode 这类编码工具,关于如何提升生产力之类的内容又大量出现了。 另外,知名人士之间那种偏哲学的对话也在来回出现。
崔升准 所以我一边休息,一边也经历了各种事件和情况,不过也花了时间整理思路。所以我又回到了我喜欢的 Prompting 这个主题。
卢正锡 今天又是久违的升准님의 Prompting session。
崔升准 最近大家都做得很好,所以不确定这是否真的有帮助,不过我还是想以“思考原理的 Prompting”为题,把我最近尝试的内容背后的原理再回顾一下。
METR 更新与 Claude Opus 4.5 体感(50%-time horizon) 01:34
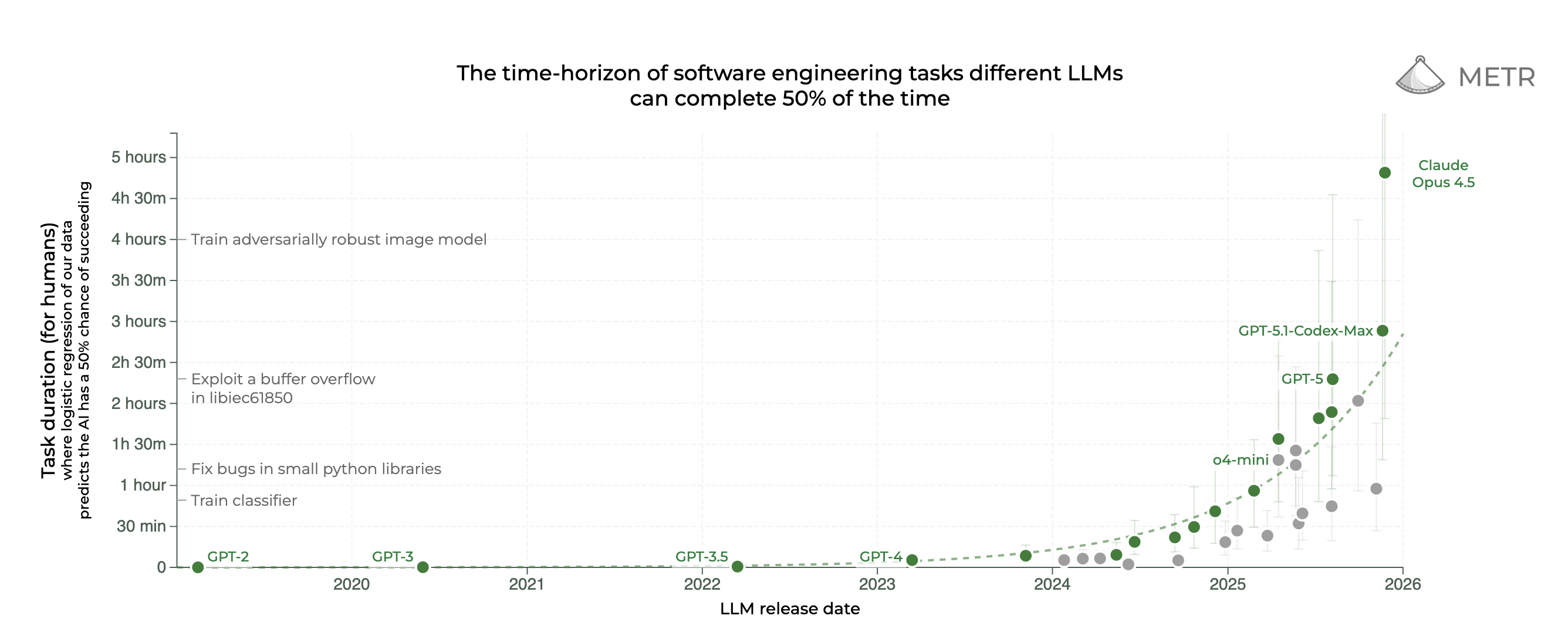
崔升准 先说几个新闻性内容的话,2025 年 12 月 20 日这张图更新了,我们好像没提到。这个就是我们介绍过很多次的 METR 50%-time horizon。 如果看 linear scale,会看到 Claude Opus 4.5 跳到了 4 小时 49 分,接近 5 小时,涨幅很大。 所以在 log scale 里看虽然也在进步,但感觉只是稍微上来一点,可如果看这个图,感觉就是这种感觉。
Andrej Karpathy 的 FOMO 02:13
崔升准 我展示这个其实是因为,2025 年末 Andrej Karpathy 那种 FOMO 感的帖子非常火。 大家在身边体验 Claude Opus 4.5 大概一个月后,12 月出现了很多“好像有什么被咔嗒一下切换了”的见证式反馈,Andrej 也说自己从没这么强烈地感到落后。
我想很多人都讲过了,就大致略过。这里标题挺有意思,Andrej 和 Boris Cherny,也就是做 Claude Code 的人,还有 Igor,xAI 创始成员但现在已经出来了,总之这些明星级玩家在一起聊天。 Andrej 这么一说,Boris 也说我也是这种感觉。反正就是“咔嗒一下就变了”,然后 PR 做得非常猛之类的话题。
卢正锡 是的。
崔升准 Igor 说“Opus 4.5 挺不错”,Andrej 说“真的很好”,“如果过去 30 天没跟上,那对这个主题已经是 deprecated 的世界观了”。这种刺激性表达就成了话题。
卢正锡 没错。一年前我们就说过,test-time compute,也就是推理时大量使用计算,和结果高度相关,这几乎是去年的主导主题。 现在看那些把 Claude Code、OpenCode 用得很好的人,会发现很多人特别会调这个 Harness 的优化。
Harness 优化与多智能体编码 04:01
卢正锡 所以基本上,现在这种你来我往的对话式工作流程已经是很久以前的趋势了。 现在是写好一个 spec 后,即便不是非常精密的 spec,也会同时跑几十个 sub-agent,睡一晚让它跑 10 多个小时。最近大家常说“在拷打 AI”。 “拷打一会儿可能就能出答案。”这种话很多。 所以我们公司工程师把任务一跑就是 7、8 小时,也已经很常见了。
崔升准 但现在不是只跑一个 agent,而是在 Claude 里开多个标签,用多智能体同时跑,大概 6 个,Boris 好像会跑到 10 个。对吧。是不是有点像在 StarCraft 里撒 marine 那种感觉?
卢正锡 鼠标和键盘要非常炫技地来回切换,得这样去驾驭 AI。
崔升准 对,就像一个 command center 的感觉。可以想象。所以有的人会说 Claude Opus 4.5 就是“挺好”,也有的人会说“某个开关被切换了”。
卢正锡 最近说“AI 也没啥了不起”的人虽然变少了,但其实如果有人说“AI 我试过了,不怎么样”,大多数人都会回答“那是因为你不会用”。
崔升准 还有个有趣点是 Gemini 3 相关话题悄悄变少了。 我的体感是 Claude Opus 4.5 确实很厉害。 Gemini 在前端上还是很强,所以当作那个角色的 agent 用得很多,但和 GPT-5.2 Pro、Claude Opus 4.5 放在一起看编码能力时,好像又有点被盖过去了。 只是我的感觉。
卢正锡 有可能。我毕竟在工程师社区里,所以比起 Gemini 或 Antigravity,我听到的更多还是 Claude Code、OpenCode。
崔升准 还有韩国人做的 oh-my-opencode 吗?感觉也挺有话题度。
卢正锡 对,名字起得太好了。Sisyphus。
Noam Brown 的 vibe coding 体验与“LLM 还未达到研究者水平” 06:19
崔升准 不过 Noam Brown 倒是说他假期试了 vibe coding,有些东西做不出来。于是他在做自己熟悉的扑克相关内容时,Codex 不行、Claude Code 也不行,但最后不知怎么 Codex 反而表现不错,所以也发了点“胳膊肘往里拐”的内容。 但他还是说,LLM 虽然进步很快,可开发新算法对人类专家来说也是几个月的研究项目,LLM 还没到那个水平。
然后他第二天又分享说收到这样的 DM。“最近我的 Twitter feed 越来越不真实,特别是很多人说 Claude Code 把自己的效率提升了 100 万倍。我也在用,而且用得不算少,但开始怀疑自己是不是疯了,还会焦虑自己严重落后。”也就是感到 FOMO。 因为有人把 Claude Code 的杠杆效应说得非常大,所以会有 FOMO,但 Noam Brown 这个级别的人说这话,会让人稍微安心一些,大概是这个语气。
FOMO DM 案例 + Ethan Mollick:扩展到编码之外的 Claude Code 07:30
崔升准 但 Ethan Mollick 的说法更接近 Andrej Karpathy。这位是非开发者、非工程师视角,他很有意思地展开了非工程背景如何使用 Claude Code,还详细展示了怎么做、为什么能做,包括 skill 的重要性也提了很多,写得比较易懂。如果只看结论部分,就是:这一切意味着什么?
如果你是程序员,现在就该探索这些工具。想用代码做实验的设计师、处理数据的学者、任何想做点东西的人,现在都是实验时机。但还有更深的点:只要有合适的 Harness,今天的 AI 就能做真正重要、可持续的工作,而这反过来已经开始改变我们处理工作的方式。 然后他引用 Karpathy 说,不要被当前 Claude Code 的笨拙感或偏编码特化这点迷惑。也就是说这篇文章的核心是 Claude Code 可以非常通用。 所以,让 AI 在其他知识工作中运转的新 Harness 在不远的未来会出现,它们带来的变化也一样。总之就是这种趋势会持续,他又分享了这样的文章。
卢正锡 而且 Claude Code SDK 真的是接什么都能跑,类似这样的体验很多。就算不是编码,哪怕只接公司的业务系统或某个数据库,再接 Claude Code SDK,也能把事情做得很好。 最近像生物科技或研究相关的 skill package 也在大量涌现。
Claude Code SDK 与“Harness 是新的源代码” 09:22
卢正锡 对,这个 Harness 其实已经成了新的源代码。
崔升准 是的,Claude Code 本身这个账号不是官方账号,而是分享 changelog 的账号。 它出来后我看到 2.1 发布了,结果 12 小时前 2.1.2 又上了。 2.1 本来就有一次大升级,但接下来几乎天天在更新,这不可能只靠人力完成。 Claude Code 官方上是 Claude 在做、Claude Code 在做,所以功能追加处于很紧迫的节奏。 不过我在年末年初休息时可能是想回到基础,所以一直在慢慢思考。总之我还是觉得 Claude 的 skill 很厉害。
阅读 Skills 仓库:什么是技能 10:17
崔升准 所以年末我认真读了 skill 的 Github 文档。会把那些 skill 翻译着看,这就是那个 repo。
进去看 skill 的话,有示例 skill,比如我常用的 algorithmic art skill,会先想哲学,再在写代码前要做什么之类,把这些翻译来读会很有意思。不过听说这和当前实际内置的 skill 可能有差异。 Github 公开的是这样,但里面很多东西都值得读,我读得很有意思。 其中有个叫 skill creator 的 skill,也就是“制作 skill 的 skill”,我想讲讲这个。
卢正锡 所谓 skill,就是一个文件夹结构:有关于某种能力的 markdown description prompt 块,相关代码集中在一起,还有可作为示例的内容也集中在里面,我们把这一整包叫 skill。对。
崔升准 对,就是这样。OpenAI 也在去年末开始用了。 所以现在 skill 像 marketplace 一样非常多,据我所知已经分享了几千个。 而且它真的很容易做,在 Claude Code 上当然容易,但在网页界面也行。我是某次对话中突然想到这个点。 这个想法出现的背景我稍后会说,总之当上下文推进时,对话会形成“重力”。 也就是我现在用的术语、模型响应中的术语,会慢慢固定分布;这时如果想拓宽分布去探索别的空间,就需要引入别的术语,但这个发想有时并不容易。
Prompting 技法 1:用随机 4 字母首字母缩写·Pareidolia 扩展分布 12:23
崔升准 所以在这种场景里可以用一个方法:随机生成 4 个字母为一组,生成 100 组,然后让模型把它们当作首字母缩写去读。 不需要完全对应,我是想调动模型的联想能力。这里有个概念叫 pareidolia。 比如人看云也会在云里看到形状,比如动物或人脸。人有联想能力,而现在模型也有强联想能力。 只是要放入合适的 token,这种联想能力才会被触发。
所以我的点子是,让它去读这些首字母时会生成这样的 Python 代码。 它会实际生成大概 100 个随机四字母组合,从中挑约 10 个,读成和当前对话上下文相关的首字母词组。 比如“自我理解是暂时的”会读成 “Your Understanding of Self is Temporary”,ephemeral 之类,会出现一些挺有趣的文本。
我也许做不到,但模型可能做得到,所以这是否会成为有趣的分支探索。因为这样会注入 token,于是可以围绕它展开相关讨论。 所以我在做发散式、横向探索时会用这个。 然后这样你来我往聊了很久后,我当时开着 skill creator。 所以我把这个叫 skill creator 的东西开着了。 当然开太多会干扰,所以一般只开我想用的。
用 Skill Creator 制作“领域预热”技能的经验 14:22
崔升准 开着它对话后,它就开始想做 skill。 在这个对话过程中,像刚才那种生成 4 个字母并按首字母缩写去读的流程,就是模型先提议做成 skill 的。 我说那就做吧,它就创建文件夹结构,然后这样生成出来;每个 MD 文件生成后,点一下就能一次性复制到我的 skill。 这个流程做得非常顺滑。 所以 Claude,正如我在这张图里刚才提到的,我以前一直说它是“生成有用副产物的流水线,所构成的流水线”。 因为对话过程中会产生代码、可复用文本、或者图片等副产物;如果带着这种“副产物会不断出现”的心象去推进,通常都会得到好副产物。Claude 给我的感觉是把这个直接产品化了。
这里还有一步再修订的过程,完整走完后复制到我的 skill,就变成了“domain priming”,也就是我可以输入特定领域术语,也可以不输入;它会朝那个方向生成字母并尝试解读,直接技能化了。 你看这里也有代码,也有怎么使用的示例,所以 Claude 就可以按需调用。 而且这些会在我的 skill 里,可以开关控制。
卢正锡 做 skill 确实很容易。对,所以不仅在 Claude 里能用,在 Claude Code 里也能按同样结构直接做 skill 并持续扩展。 崔升准 对,所以其实只要把那个文件夹原样放进去就行。那为什么 skill 会这么好用呢?
为什么技能这么有效 16:17

卢正锡 是啊。
崔升准 所以说,skill 实际上基于去年很流行的 spec-driven 基础,然后按一定格式组织成 MD,现在 MD 文件本身某种意义上也是编程,所以 MD 都是按结构写好的;而且不只是 MD,还有脚本代码在里面,所以也不算完全静态。怎么说呢,里面既有可精确执行的部分,也有概率性执行的指令,再加上代码,这些都被打包得很整洁而且可复用。所以在当前阶段,MCP 虽然也是话题,但我感觉 skill 正在变得非常重要。并且这个体系做得很干净。但为什么这种 skill 会天然更容易有效,我现在没有答案,但至少这个问题被我提出来了。年末年初我花时间思考了这个。
所以这里我标了“岔路”,可不展开也行。Boris Cherny,也就是 Anthropic 那边,把一个叫 code-simplifier 的东西开源了。看起来很简单,就是一个 MD 文件,里面是如何把代码精炼得既简洁又保留意义的指导。现在就是这种东西作为插件不断叠加的时代。
卢正锡 英语真成了新的 programming language。
崔升准 或者说任何语言都可以是 programming language。自然语言。对。 总之我还没得出答案,但我提出了这些问题,而我一直在思考的是
“精准 token”与领域 prompting 的质量差异(专家 vs 非专家) 18:07
崔升准 你得放入精准 token,模型才会有反应。 看那些 MD 文件,也就是刚才 skill 的 MD 文件,里面就写了能触发这些能力的指令。 而且这非常重要。 有贴合该领域的指令、以及精准术语时,能力才会被激发。
卢正锡 你说“精准”,和“准确”这个表达,具体差别是什么?
崔升准 语感上是有点差别,可能还带有“严丝合缝”那种感觉吧?我也不敢说完全准确。总之在写这些时, 我经常打游戏来类比。玩游戏时不管是 StarCraft 这种 real-time simulation,还是 role-playing game, 玩家要先走到某个区域附近,小地图才会点亮,对吧,之前是黑的。 所以得走到那附近,空间才会打开。我的感觉是这样。
卢正锡 也就是模型本来知道的东西非常多,几乎可以说什么都知道了,但你得把它的注意力转到某个特定领域,在那边触发一下,先“打个底”,告诉它“我接下来要做这个”,它才能把相关工作做得更好。
崔升准 会好很多。所以我做了大量测试,也和别人一起在群聊里测过。用和不用特定术语,回答质量差异很明显。比如只用一个“大概的专家 persona”说话,和真正塞入那个专家可能会用的 token,即使只是近似,输出质量也不同。按 Transformer 原理来看这其实很自然。那问题就来了:这么看是不是领域专家天然更有优势?是不是知道这些的人才会用得好?但 AI 的发展方向真的只会是这样吗。
如果它要成为所有人的杠杆,那模型也应该能反向拉人一把;以及像 skill 这类 prompt 上下文里,只要使用恰当 prompt,即使我不是该领域专家,也可以借用该领域知识,还能借用模型 overhang 的富余能力,这不是更好吗。
卢正锡 太对了,是的。
崔升准 所以刚才那种发散首字母缩写,是利用模型已有的联想计算能力来做横向发想并填充有意义 token;而这次尝试是用 arXiv,那个 preprint 网站,也就是不需要 peer review 也能上传,可能有基础审查但总体较容易上传。昨天我做的时候,1 月才过一周多,已经上传了 4000 多篇。
用 arXiv 摘要填充 token:连接陌生术语 21:15

崔升准 arXiv 上论文量非常大,而且命名有规则。比如 arXiv 论文里,这个我当时好像放在这里了,像 2601.03220v1,就是 26 年 1 月上传的第 3220 篇论文的 v1,也就是版本 1。它有命名规则,arXiv 本身也有 API,所以可以做 retrieving、拉取。当时就可以让它抓 1 月的随机论文。然后这里也写了点代码之类,最后说“1 月投稿中随机 10 篇”。那就是只读摘要的场景。但只读摘要也会有专业术语吧。所以这只是个实验:当这些术语被填进来后,只读摘要时,彼此之间可以产生什么不显而易见的洞见或含义。
这样即便我做不到,模型也能因为 token 在场而产生有趣连接。现在的 flagship 模型是有能力在 A token 和 B token 之间搭桥的。
所以我就当作一种趣味阅读。它未必是非常严肃且有重大意义的东西,但其实和 Gwern 说的 LLM daydreaming 有关,也和 AlphaEvolve、Co-scientist 那一类工作很相关。
在那里面会生成各种假设,再验证这些假设是否一致、做实验或证明。探索多样空间并连接意外要素,Co-scientist 在研究里本来也在做类似事情,所以我做了些这类测试。 然后看到它们确实挺有趣地在起作用。 这种实验也是一种方式:即使我不懂有意义的 token,也能把它们拉到我需要的上下文里使用。 比如 arXiv 的例子里,现在只是从 1 月全部内容里选 10 篇,也可以只在特定研究领域里抓。 那就可以成为填充有意义 token 的方法。
卢正锡 但升准님在这里想说的其实是,我们可能并不完全理解那些内容,但只是把这些 term、里面的词和专业性拿来,直接放到模型前面当 prompt,处理任务时质量就能明显提升。
崔升准 对,因为是在讨论我不懂的领域,所以风险会跟着来;但如果要在这个语境里形成真正专家会说的话那种分布,即便我不懂,也得想办法把真实存在的 token 拉进来。
卢正锡 好,明白了。要不我们继续往下?
崔升准 除此之外我还试了一个,也是在类似语境下的变奏。也是聊了很久之后,我让它不要只按“某个 persona、某个领域专家、开发者、设计师”这种方式召唤人物,而是 A 到 Z 有 26 个字母,就把它当作人名或姓氏列表来发想。因为西方名字都在字母范畴里。于是模型会开始想名字。
Prompting 技法 2:A–Z 人物召唤 + 用“太表面了”继续深挖 25:03
崔升准 然后让它同时联想这些名字、这些人物可能会说的概念词和领域。比起空谈,这样会填入更有意义的 token。所以这在发想技巧、联想技巧以及 token 填充思路上是同一个路数。
我在这里还会反复做的一件事是,列表里的人物有我不认识的,但也有我比较熟悉的,比如 Daniel Kahneman、Minsky、Merleau-Ponty、Marshall McLuhan,这些都是在代表性分布里经常出现的人物。
无论是某个专业领域还是对话本身,如果这只是第一阶段,那么真正“硬核”、连研究者才知道的内容,很可能不会出现。所以我觉得总是需要分阶段。先走宽分布,再做收窄。我常用的一句就是“太表面了”之类。这样到后面会开始召唤出连我也难以理解的人物。 然后就可以知道该领域里谁是专家、谁提出了哪些概念词,再用这些概念词去提问,或注入到对话里,大概就是这个意思。
做这件事时会触发我去年夏天整理过的一种态度。比如这里第 3 条“延迟满足”,不满足于一次回答,总是继续追问,这种态度会持续触发;还有这里“建立临时假设”,就像刚才那样利用联想能力,这也是我一直会触发的一种态度,所以这次又重访了一遍。 到这里为止,前面关于 skill 的内容,虽然说是 skill,但其实大多数 prompt 要正常工作都需要有意义的 token;如果这部分是在讲“即便不懂也如何把它拉进来”,那接下来会换一个变奏。
前面从 prompt,也就是从 skill 出发讲了 token 的重要性。这里可能是另一个侧枝,但我们在去年最后几期里,成贤님讲过 RL,也讲过 CoT。
所以我在休息期间也查了些资料并学习了一下。一个有趣关键词是,我们也讲过。卢正锡在发布《逃亡者联盟》时说要做这个,当时有 OpenAI 的视频,Sam Altman 和 Jakub Pachocki 出现过。里面提到了 CoT Faithfulness 这个词。
CoT Faithfulness, Monitorability tax 28:31
崔升准 他们说在做一些有趣工作。关于 CoT,这个可能译成可靠性或忠实性,我不太确定;但相关讨论从 2023 年就有,Anthropic 也讲了很多。
所谓 CoT 忠实性,是指模型内部表征与模型实际吐出的 CoT 之间可能有鸿沟。比如欺骗行为这件事去年也很有话题。OpenAI 有个有意思的教训是,以前像 “Let’s verify step by step” 那样在 CoT 中间过程干预或纠正,模型会学习欺骗能力。 也就是你去盯着它并指手画脚时,它会为了绕过你而做混淆,反而获得某种“隐藏”的能力。这想法在去年下半年被讨论很多。
卢正锡 是。
崔升准 那问题就来了。 如果 CoT 不是在说真相,也不是模型真实在做的事,但让模型更会吐 CoT 又确实提升了性能。 通过 RL 让它最终走向正确答案,并且有与之连接的 CoT 路径,这能提升模型性能,这是从 R1 开始明确的结论。 那如果 CoT 无论是说了 aha,还是我们之前聊过的高熵 token,这些都可能和模型真实发挥的能力不一致,那 CoT 到底是什么?我会这样想。 为什么只要把它适当拉长、用 test-time compute,性能就会上升?
卢正锡 至少是因为想得更多了。
崔升准 对。也就是说即便真相不一定显露出来,它内部确实做了足够计算。
卢正锡 对。无论如何内部用了更多能量在计算。这才是关键。
崔升准 所以从我的视角,这个判断是否准确我不确定,但最近我的体感是大概就是这么回事。
卢正锡 对。不过这在这里也无法证明,但像是一个合理猜测。英文里叫 hunch,对吧,这个词中文怎么说?就是猜测。
崔升准 猜测,就是那种。所以这不是已经被研究证明的结论,只是我把各种东西拼起来感觉比较对得上。
卢正锡 其实我们面试也好、讲话也好,或者在比较尴尬的场景里要防守时,也会边说边在脑子里构建逻辑。
崔升准 也是。等于是在争取思考时间。
卢正锡 所以这个 Transformer,等下升准님可能也会讲,最终输出的词是我们能看到的,但底层真实发生的事我们并不知道。里面可能有非常复杂的现象在发生,那里面是有“思考”的。
崔升准 所以我就从这些东西重新学习了一遍,从 CoT 的发想、到 scratchpad、到 Jason Wei 的 “Let’s think step by step”,从 2022 年末到 2023 年初的脉络一路看到今天。于是会感觉 CoT 的意义在于把计算链条延续好。并且现在让 CoT 继续得好这件事,和前面提到的让模型长时间不跑偏执行任务这些事是相关的。归根到底它仍在不断吐自回归 token 来推进工作。它本质仍是自回归。这就是计算。文本表达当然很重要,但与之成对的是内部表征这个 Duality。
但最终这两边都重要,所以当它们能顺畅推进时,我脑中会出现一些“图像”式的理解瞬间。
卢正锡 同意。
崔升准 所以 OpenAI 在去年下半年开始提 Monitorability 这个概念。 因为现在如果在 CoT 里干预,模型会出现欺骗之类现象。Meta 也发过研究,说只靠内部表征去让它自回归运行。 如果一直只在内部表征里跑,人类最终是看不见的。所以监控很重要。这里讲的含义有很多,其中提到 Monitorability tax。 就是说即便有成本,也要让“好的 CoT 可见”,这是一种有意义的对齐工作,让这件事更好发生是有价值的。他们从研究层面做了这样的表达。 而且 OpenAI 最近有了这种韩文页面,我又注意到了。
卢正锡 都是模型在做吧。对。

崔升准 对,而且做得很好。我昨天查资料还看到了 2016 年的内容,旧内容韩文化没那么好,但最近的韩文化非常完整。所以拿来复习很有帮助。 这也是成贤님之前介绍过的,从 f(x) 和 g(x) 到 f(g(x)),本质是在做高阶函数、组合函数。
所以 RL 在已有预训练基础上,先拥有一些原子级 skill,这里说的 skill 和刚才 Claude 的 skill 不一样。虽然都叫 skill,但这里的意思是:在已拥有这些 skill 的情况下,RL 除了让分布朝更好的生成分布移动外,还会通过组合学习新 skill。
从 RL 的技能组合 f(g(x)) 视角看 chaining/工具调用的重复结构 35:02
崔升准 成贤님의比喻是四则运算。比如求平均值这种任务,是把四则运算这个 skill 组合起来完成;同样地,RL 通过组合已有 skill 学习新 skill。这个让我再次反复思考。还有人给我 YouTube 留言说,崔升准很常用“心象”这个词。 所以我又会用“心象”这个表达,它也是形成某种图像。也就是有东西在组合。
那这样的话,虽然这里是 RL 语境,但我感觉这种组合在别的层级也在重复。大约一年前,o1 出来后,2024 年秋天 o1 出来时我还不太会用;到 2025 年 1 月我做过一个尝试,是那种类似函数的 pseudo-code,用近似自然语言函数并做组合,让它执行很长流程,你还记得我展示过吧。 那其实也是模型擅长调用某些 tool、做某种组合。虽然我现在在不同层级说这个,但这点很关键。 所以现在这些 skill 能工作,或者 MD 文件执行脚本并把结果持续 chaining,本质上都和这件事关系很大。这也是我自己的思考。
所以今天能不能继续展开我也不确定。只是我在 12 月末和 1 月初休息时觉得必须重访的是,我们 2024 年不是讲过 Transformer 吗。大概是 2024 年 7 月左右,我写过“循序渐进理解 Transformer”的文章,然后也分享过并聊得很开心,所以我想再回去看一遍。
下期预告:Transformer·QKV·KV cache·FFN→Sparse MoE 复习 37:15

崔升准 所以这次是 Transformer 里 MLP 或 FFN 那些大块,现在基本都用 MoE 替代了。所以我已经在准备循序渐进的 Transformer 的 MoE 版本。
卢正锡 结论就是,像升准님刚才说的,在 prompt 前面铺背景非常非常重要。
崔升准 所以时间已经过了不少,先说个预告。我前面说过“精准 token”以及“用了它才会展开的空间”。 要理解它的底层,我虽然也不是专家,但回到 Transformer 原理,再理解最近很热的 sparse MoE 概念,确实很有帮助。 而且里面有有趣的共通点,是那种不断变奏却反复出现的结构。 我把标题定为“思考原理的 Prompting”,如果能知道一些这些内容,也许在做 prompt 的态度和实践上会更有意识。 当然一直保持这种状态很难,但这样也许能把能力拉得更出来一些。
卢正锡 对,升准님,我们这种人也喜欢先说结论嘛。你今天这场想表达的核心可以概括为:Prompting 的方式不同,同一个模型性能会完全不同。
崔升准 目前是这样。以后是不是还这样不确定。
卢正锡 你现在脑中有这个模型假设。所以即便我不确定、甚至我自己看不懂,只要把那个空间里专家写的大段文本、专家名字、或者专家常用术语大量放在前面,就能把模型在该领域的表现显著拉高,你是在说这个。
token priming 的风险:“跑车模式”与陌生领域的陷阱 39:54
崔升准 对。不过这个比喻不一定完全合适:这么做之后,模型可能会判断“用户都懂这些”,然后突然进入跑车模式,就会变得难驾驭。 不管它往哪走,我也得跟上,才能控制下一步;如果模型觉得“用户应该都知道”,后续回答就确实可能难控制。 也有跑偏的可能,所以我很难说它一定总是带来好结果。 但模型本身的能力确实能处理我理解不了的东西。
卢正锡 对,但这部分确实是边界。我也有敬畏模型的视角,但在我不了解的地方、不了解的领域和层级里,我觉得无条件跟随是危险的。 我们最近也看了很多这类例子。它说的并不总是对的。 我也提过,这周我在完全不同领域,真的在企业 IT 那边,SAP 之类 ERP 文档看了一大堆并和模型对话,结果它错得很多。
所以我总会在 prompt 里加一句,类似“不要通过奉承来揣测我的意图,要保持完全客观”,但它还是经常只追随我想要什么这种 intention,结果就到不了正确答案,这种感受我很多。 根本原因就是我缺少那个领域知识,prompting 做不到位,质量就会这样;再加上它倾向于尽量让我满意,就会产生一种奇怪的缠绕感。
崔升准 是。不过因为我们是人,才会觉得模型有意图或者在奉承,但模型的输入其实是 token,
卢正锡 对,它只是统计性计算而已。
崔升准 更可能是你构建了错误上下文。我们在无意识里输入的东西都在产生影响,如果这么想的话,确实是这样。
卢正锡 所以今天这场如果要深入聊,确实得回到 Transformer 及其原理。我们 2024 年做过 Transformer 探索,后来突然停了,有点可惜。现在好像又到了该重新做的时候。
崔升准 啊,而且我觉得时机也就现在。因为到 2 月、3 月事情又会开始发生,
卢正锡 会发生很多事。
崔升准 对,所以能复习、能慢慢思考的时间可能不多。
所以我再补一个想法。比如在卢正锡和《逃亡者联盟》这边,你们非常关注怎么 leverage 模型能力去做商业。说直白点,就是怎么赚钱、怎么用它做出很酷的事;工程师社区看模型则是怎么做 Harness,把能力拉出来做更好编码、处理更好 task。
另一方面,也有人说这是不是危险、应该慢一点,或者依然有 hallucination,甚至会不会制造歧视、扩大差距,所以主张谨慎推进。但我有时会觉得自己不完全属于任何一边。
为了帮助模型而理解模型 43:41
崔升准 现在这些模型或 AI 某种意义上是异域存在。某种程度像 alien。但如果我想让模型更好地帮助我,我也需要更好地帮助模型。
尤其我感兴趣的是偏“游玩式”地使用它。我的乐趣在于探索、冒险、写 creative 的代码,所以对话时也倾向于让过程更有趣。我偶尔会在什么时候感到有趣和成就感呢,比如模型在 CoT 里出现“哇,这太惊人了”这类反应时,会觉得有意思,也会去尝试这种。 归根到底,模型要帮我,我也得帮模型,这会形成一个互相咬合的环。但要帮模型,就得先了解模型。
模型如何工作?模型对人类有巨量信息,所以能支持人类;但作为 user 的我,究竟有多了解模型、了解其运作机制,即便它是 black box,也是否掌握了某种程度?如果我去了解,会不会出现更多有趣路径?我常有这种想法。 当我思考怎样让模型和我的关系变成更好的体验时,我的一个想法是:我需要更了解模型运作原理。
卢正锡 对,这点我完全没有异议。
崔升准 所以像重新开始一样回到起点,深入部分应该会在下次 session 里尝试。那如果今天先收个尾的话
收尾 45:37
崔升准 现在可能还是一个可贵的、有余裕学习的时段。新闻不断出来时,我的心意是最好复习一下。无论是 RL 还是 CoT,如果知道当下变化背后的基础,面对接下来会发生的事反而会长出“肌肉”吧?或者说长出“免疫力”,总之能更有准备。 所以如果这是 AI 急加速时期中的一个短暂停顿,那就回到基础去想,慢慢咀嚼,也许还能得到新想法,也想再重访一次。 另外去年成贤님의 keynote 一开始就是 MoE。Sparse MoE 非常重要,我们聊了很多,但我自己其实没认真去啃它。
卢正锡 对,我们很多时候都“嗯大概是这样”就带过去了。
崔升准 所以如果能理解 MoE 概念,或者理解被它绑定的 Transformer,也就是 MoE 版本 Transformer,也许会得到一些“如何更好使用它”的线索。我是带着这样一个假设来准备的。
卢正锡 好,那我们下次深入的话会学到什么?
崔升准 是 Transformer 的 MoE 版本。我们的订阅听众也会听到正奎님出来聊 KV cache 之类的话题。那到底是什么?还有在 Transformer 里,今天这个语境下我多次说“某些 token 进来后空间才会打开”,这到底是怎样的工作机制?
卢正锡 那我们就会看 attention,以及 attention 里核心的 QKV 到底在做什么, 然后它进入下一层后的 FFN,现在是 MoE。MoE 到底做什么,以及在 Transformer block 之间 residual、残差连接这类东西的意义,我们有必要再看一遍,也想再看一遍。 然后点这个链接,里面就会讲到这些。
崔升准 所以我不确定能不能真的做到非常循序渐进,但会尽力。可以看作我们 2024 年已经讲过内容的一个修订版。
卢正锡 对,没错。我们 2024 年曾努力细致拆解 Transformer,后来突然因为其他议题出现,就加速转向新闻那边了,我有这个记忆。
崔升准 不过我也不是这个领域的专家,只是作为一个高投入且有好奇心的非专家,尽量摸索着去理解,大概就是这个程度。
卢正锡 当然,我们一直都说自己是爱好者,所以说错也可以。对,前面好像要加一句“也可能会错”。
崔升准 对,可能总会有跳跃,但我们也会带着一些有趣的类比去摸索。哪怕只多察觉一点,是不是就能做出更有趣、更有意义的 Prompting?所以我把今天标题写成“思考原理的 Prompting”。某种意义上这可能是个难得机会。 所谓难得,不是因为内容本身多珍贵,而是因为在加速期里,可用于学习的时间可能并不多。
卢正锡 对。
崔升准 所以就是想把基础补上。
卢正锡 明白了。那今天可以看作是一次为下次深入做准备、先设定大前提问题的 session。
崔升准 但 recap 一下的话,连 Andrej Karpathy 这个级别都出现了 FOMO。大家聊 vibe coding,聊 Claude Opus 4.5,说“一个月内发生的事你不知道就已经 deprecated”,连专家都这么说,这件事本身就很有话题。 但如果追溯根基,不管是 skill 还是 prompting,现在的进展其实都有连续性,只是突然走到指数曲线,人们才会觉得“好像发生了无法理解的事”,但其实都是有因果链一路连过来的。 所以再回到基础看看,不也是有意义的吗?我会这么想。
卢正锡 好,明白了。很有意义。下一次我们上午录,来啃这个难题,Transformer。
崔升准 好,那我们下期见。
卢正锡 好的,明白。
崔升准 好,辛苦了。