EP 88
没有秘诀
开场:与成贤重逢 0:00
卢正石 今天录制的日期是2026年3月1日星期天早上。好久不见,今天请到了成铉。
我们去年年底最后一期就是和成铉一起录的回顾去年模型的变化RLVR取得了巨大的进展,还有MoE等架构带来的效率提升,当时我们提到了这些要点也展望了26年有哪些值得关注的看点我们做了一些预测就结束了,转眼才过了两个月。所以说有很多变化,也有些没怎么变,
今天好久不见请到成铉,聊聊过去两个月的感想听听他的想法,也预测一下未来会发生什么让我们一起来展望一下。成铉,欢迎欢迎。
金成铉 之前参加的几期节目中,基本上都是围绕一个主题就那个主题展开了很多讨论。而我在准备这次节目的时候思考了很多。两个月来一直在断断续续地想,再来参加的话聊什么话题比较好呢,想了很多。但这确实挺难的。比如说关于技术上的、细节方面的东西,比如最近出来的、引起热议的DeepSeek的Engram或者MHC之类的话题当然可以聊很多,但我自己的视角好像也稍微有了些变化。而且也在想,那些东西在当下真的是多么重要的课题和问题吗也有这样的思考。所以与其围绕一个主题一直聊下去不如聊聊各种话题和感想我觉得这样会更好我的想法是,DeepSeek V4以DeepSeek特有的方式带来了非常多的技术创新和各种细节,这是有可能的。但那些技术虽然有趣,但那是另一回事
为什么很难只用一种“技术”来概括 1:17
金成铉 在这个场合要非常有趣地介绍某种范式转换,或者说因为有了这样的创新未来将会这样发展——这样的话说起来会比较困难。即使DeepSeek V4出来了这里有了这些进展未来AI模型的发展将会怎样这些将变得可能——要说这些话的话可能会有些困难,我是这么想的。所以这次节目的主题与其说是关于某个特定技术和技术发展不如说更接近于对各种话题的探讨。所以在这张幻灯片上我写了”技术”意思是,关于为什么谈论技术,谈论某个特定技术在现在是件很难的事——这更像是一种辩解。最近虽然不是DeepSeek V4
GLM 5 报告与以 RL 为中心的技术创新 2:23
金成铉 但有一份非常有趣的研究报告出来了,在前沿级别中发布的报告是GLM 5。这是Zhipu AI发布的报告其中有非常多有趣的技术创新和细节。非常粗略地概括的话有三点。第一,更高效地进行RL,比如Sparse Attention之类的这些东西,还有用于RL的基础设施,比如async RL等,有很多很多技术细节其中相当大一部分是关于如何更高效地、以更少的算力进行RL。更高效地利用上下文长度来更高效地进行RL。接下来另一个是对RL的objective之类的东西做一些微调使其更加稳定,这是另一方面。还有一个是让RL更加多样化。最后会谈到关于环境扩展的话题。就是让RL能够应用于更多样的任务扩展环境,更高效地进行环境扩展。这些就是主要的主题。
在GLM 5这份报告中众多的创新几乎都与RL相关让RL更高效、更稳定、更多样化就是目前最大的创新方向。想到这一点就会联想到Yao Shunyu的”The Second Half”。“The First Half”的情况是,有一个基准测试针对那个基准测试开发方法开发了方法之后那个基准测试开始被攻克然后再创造新的基准测试,他说那是一个以方法为基础的时代到了”The Second Half”,我们已经找到了方法的答案,既然找到了答案,拿着这个答案应用到各种问题上就行了,他是这样表述的。从某种角度来看,这是一个非常傲慢的说法但同时,这确实是非常准确的,至少到目前为止从2025年到现在的这一年里我觉得是非常准确的。大家都认为RL就是答案,为了更好地做RL,以及为了进一步扩展RL几乎就是所有努力的全部,现在更是如此。
Yao Shunyu 的 The Second Half:RL 这份答案 3:40
金成铉 说到技术,说到技术创新感受最深的是方法上的创新但关于方法的创新,能说的,能说得有趣的东西并不多,因为一直都是RL。这个RL还在不断扩展还在不断加深——只能反复讲述这样的故事,正是因为有这种感觉所以要我以某种技术轨迹来说这个技术正在这样发展未来将会如何发展——说这样的话我觉得有些困难。因为至少RL会持续被应用并持续渐进式地发展,这是可以预见的而且现在就在持续发生。从这个角度来说我开始思考秘密配方的问题。所谓秘密配方,就是当说某些前沿模型拥有秘密配方时,我认为那更接近于方法上的创新。那些人拥有某种完全不为人知的秘密,如果不知道那个秘密就无法构建模型——人们开始形成这样的信念。当然,确实有非常多的创新。
秘密配方真的存在吗 5:16
金成铉 就像GLM 5那样,有非常多的创新,也有非常多的改进。这些改进确实存在,我并不是要否定它们,比如MoE之类的技术都是极其重要的创新。但那些并不是被隐藏起来的、极难获知的某种秘密配方,从GPT-3.5到现在一路观察下来,基本上都是在渐进式地改进和开发模型的过程中自然而然会出现、可以被发现的东西,我觉得更接近于此。如果说最接近秘密配方的,我觉得应该是RLVR。除此之外,虽然大部分都是重要的创新,但并不是那种不知道就绝对无法追赶、而且极难获知的那种形式的秘密配方,我是这么认为的。当然,产生这种感觉在很大程度上是因为中国企业自行发现或开发出了那些秘密配方并公之于众,所以让人感觉那些不再是秘密了,这方面的因素确实也存在,但目前的感受大致如此。并不是仅仅因为agent RL或者RL本身才导致了这一切,到目前为止的许多创新基本上都是渐进式的,都处于可预期的轨迹之内。
从这个角度来看,现在更加重要且显而易见的是,当前这个时期与其说是令人惊叹的创新、令人惊叹的全新方法论,当然我并不是否定那些小的探索,那些会一直存在,未来也会继续存在。但比起那些,更重要的是回归基本功。制造优质数据,构建稳定的基础设施,然后投入大量算力来构建模型——这些最基本的事情。不是什么创造性的方法,而是这些基本功在主导着当前模型的性能,我是这么认为的。各种模型之间存在各种性能差异,每个人都有自己偏好的模型,而那些受偏好的模型,并不是因为其开发公司拥有其他公司完全不知道的某种配方,而是更接近于基本功的问题——制造更好的数据、更好地进行scaling等等,我认为更接近于这些问题。回归基本功才是目前至关重要的关键,我是这么认为的。正因如此,如果能够扎实地回归基本功,许多后来者就有可能追赶上来,这样的局面、这样的环境似乎已经形成了。同时,那些在基本功方面积累了大量经验的当前frontier企业确实占据着更有利的位置,在时间维度上处于更有利的位置,这也是事实。
基本功时代:数据与产品感 7:14
金成铉 同时我还在想的一点是,回归基本功这件事与打造产品、对待产品的态度有着密切的关联。AI组织——我这里主要是基于我所经历过的AI组织来说的,往往会带有较强的研究导向,我是这么认为的。像研究性创新、新的研究方法论之类的东西,工程师们的关注度往往会更多地倾向于此。但我认为打造产品需要一种不同的感觉。经历大量的迭代、大量的试错,以及在大量使用的过程中一点一点地持续改进,一点一点地打磨模型的过程我认为是非常重要的,而这种感觉和态度的重要性正变得越来越高。当一点一点地持续打磨时,所产生的差异对用户来说可能会感受到巨大的不同,否则的话,比起不断填补细节、持续打磨,人们会更倾向于那些能带来大幅度、简单的性能提升和数值增长的方向。但在当前这个时间节点,比起那些,打造产品、回归基本功才更为重要,我有这样的感受。因为许多重要的方法论已经被大量发现了。可以说,既然RL这种方法已经被发现了,在这个方法的框架内精心打磨才是能产生巨大差异的关键所在。我同意。在过去两个月里,或者说
卢正石 从去年秋天到成铉您刚才所说的这个时刻,模型并没有突然激进地好了两倍、三倍,对吧。一直在变好,但实际上人们好像是这么判断的:现在的模型已经足够好用了。非常非常不错。所以围绕着它产品也大量涌现了。
AI 的社会影响力增强 10:19
金成铉 不过,关于AI将会对社会环境产生什么样的影响,在这方面我并不是能够有把握地发言的那种专家。所以我更加努力不去做那样的言论。但与此无关的是,AI的影响力正在变得越来越强大。这一点是确定无疑的。
卢正石 没错。仅仅是Anthropic推出了某种形式的产品、推出了某种服务,就已经导致无数企业的股价剧烈波动了。而且,是否将模型引入美国政府,即使引入了,一个frontier企业附加什么样的条件,都可能成为国家层面的问题,这种影响力似乎正在越来越大。
崔胜准 最近那个DoW的事情吧。跟战争相关的。说到跟战争相关的
金成铉 对此Anthropic提出了什么条件,采取什么态度已经成为国家层面的问题,而且这个产品在美国政府能不能使用,看到这些争论,AI模型的发展以及由此带来的影响,在当前这个时间点就已经非常巨大了。我对这个问题,我自己的想法和态度可能有些不同,我一直认为模型在某些方面必然会持续发展。那么在那个发展后的状况下,未来这些会带来什么影响、什么后果,想到这些就会感到有些恐惧。确实如此。确实很令人恐惧。但这种事情一直都在发生啊。
卢正石 曾经有一家公司聚集了10个聪明人,后来有人召集了100个人做出了更强大的公司,但时代变了之后,5个更聪明的人与计算机结合创造出更好的公司,做出更好的事业,这样的变化一直在发生。harness与模型性能一直在互相追赶,
你追我赶地不断进步,不是吗?不管最终以什么形态呈现,会越来越好这一点大家应该都没有异议。
Fog of Progress:难以预测未来的结构 12:21
金成铉 从这个角度来说,这也是我在之前的节目中提到过的,进步之雾,也就是Fog of Progress。Geoffrey Hinton教授说过的话一直在我脑海中回响。这一切都取决于对未来会变成什么样的预测,我觉得是这样的。而且每个人都有自己对未来会怎样的蓝图。但是职业会如何变化,
现在该不该学AI,这些都取决于对未来的预测,我认为是这样的。比如说如果认为现在应该学AI,应该学习AI的使用方法,那就是假设AI的使用方法在未来也不会有太大变化,而且熟练掌握AI的使用方法在未来也会产生很大的影响,这不就是建立在这样的假设之上吗。归根结底这一切,对于职业来说也是一样的。职业会如何变化,未来需不需要开发者,所有这些实际上都是基于未来AI模型会以什么形态发展的假设来展开讨论的。当然人们都知道未来
无法准确预知,所以只能做假设,只能基于假设来讨论,但同时我一直在思考的是未来是很难预测的。对于非常近的近距离范围,就像道路上弥漫着雾一样,近距离的范围是可以看到的,但再往远处因为光子数量呈指数级减少,就变得难以判断了。短期内会持续发展这一点是确定的,但长期会变成什么样很难预测,我一直在说这个观点。
卢正石 这个问题恐怕我们没有人敢妄下断言吧?大概得是Elon Musk那个级别的人才能说这种话,我们就这么理解吧。Elon Musk说过不了多久就不需要外科医生了,两年内就不需要了,他会说这样的话,虽然不知道会怎样,但刚才成铉提到的
Fog of Progress那个比喻非常恰当,我们确实是在看不清前方的迷雾中,但每个人在迷雾中所处的位置是不同的。frontier lab走在更前面,所以他们能看到指数级更多的东西,这是不争的事实。而像我们这样的人是跟在后面看的,自然比他们看到的要少,每个人站在哪里都是相对的。
崔胜准 我想到一个笑话,那个Fog of Progress是跟光子有关的嘛。如果是在水分子中散射较少的波长,那能看到的范围不就会更远一些吗?开个玩笑啦。而且有些人
卢正石 幸运地在隧道路段起步。那样的话在隧道结束之前可以一路畅通地跑出去。确实很难预测,
环境扩展:Agent RL 的瓶颈 15:15
金成铉 但我觉得有一个相对容易把握的问题是环境扩展的问题。所谓环境扩展,指的是RL中的环境,说到RL中的环境,就是agent进入其中进行活动、采取action,进行活动并观察环境随之产生的变化,观察环境之后最终获得reward,这些事情发生的场所就是环境。现在的agent,也就是LLM agent,
比如说软件工程任务之类的就是一种环境。比如说让你修复这个bug,那就有这个bug,有源代码,在源代码中有可以使用的工具,然后使用这些工具进行交互之后最终获得某种reward。这样的环境需要不断地多样化扩展。因为现在从做简单的任务逐渐转向越来越多样、越来越复杂的任务。现在AI agent能做的事情已经非常多了。而且能够创建更复杂的程序了。那么就需要为创建越来越复杂的程序构建相应的环境。以前可能是写一个简单的函数,之后就变成创建一个完整的程序,再往后就是完整地创建一个服务。那么这些环境就需要不断地扩展,但不断扩展带来的问题是随着水平不断提高,需要构建的环境的复杂度也在持续增加。
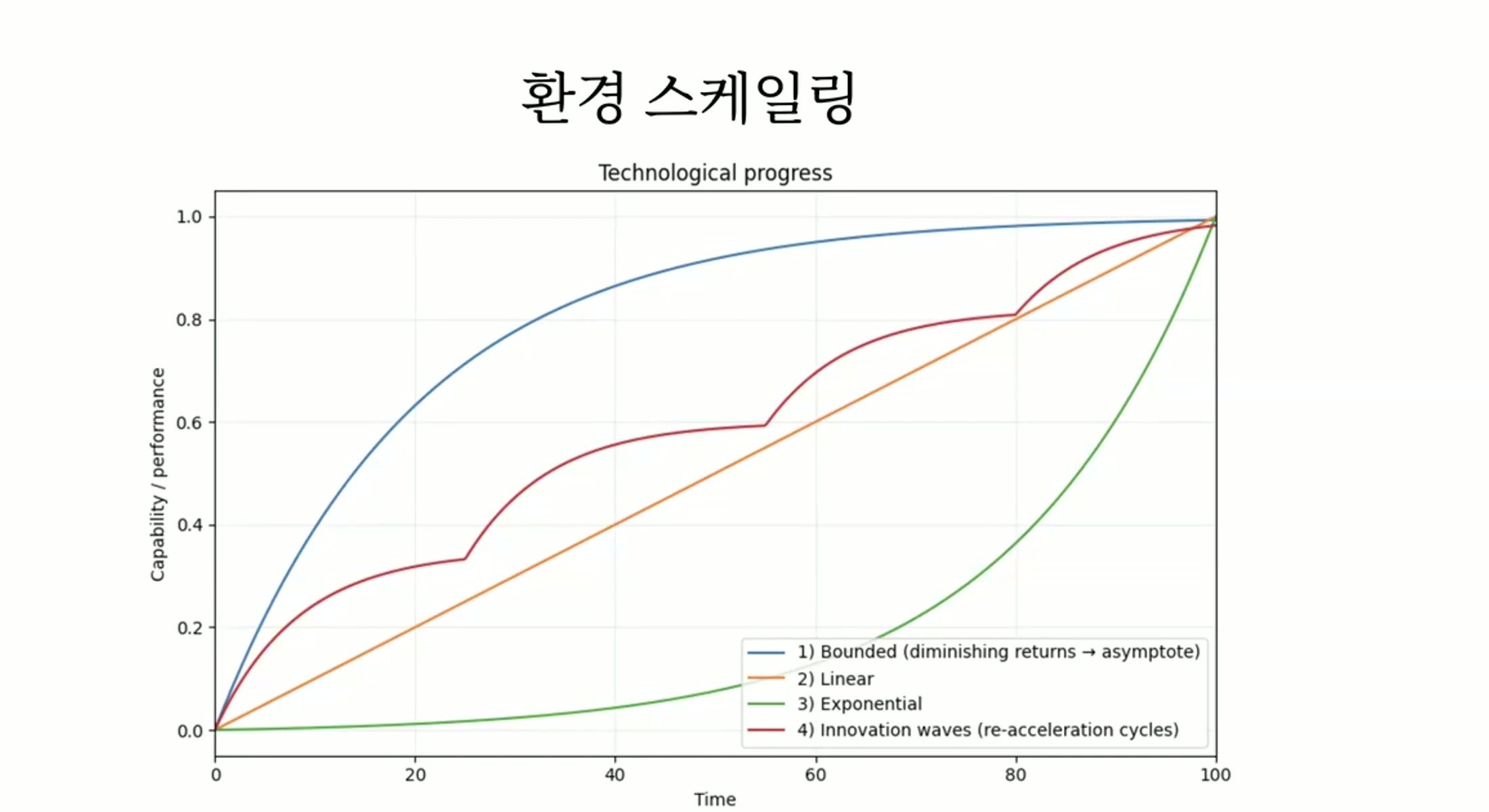
崔胜准 这个图表能不能请您解读一下。
金成铉 那么在这种情况下,如果我们假设环境的scaling是最大的瓶颈。而且我认为环境的多样化对于模型的发展来说是最关键的瓶颈。如果接受The Second Half的观点来做RL,只要有可以做RL的环境,假设什么问题都能解决的话,那既然什么问题都能解决,构建环境这件事反而会成为唯一的技术瓶颈。那么关于这个技术瓶颈将如何被突破,我们来思考一下可能的轨迹。我们来想一想。最乐观的人会认为随着时间推移,这个技术瓶颈
会越来越容易被突破。这是有可能的。如果在某个中间节点上,环境扩展,也就是构建多样化任务这件事突然找到了一种非常容易解决的方法,就会呈指数级飙升。这是有可能
崔胜准 发生的,对吧。就是绿色曲线。
金成铉 会持续增长,而这种情况可能发生的例子,我认为如果持续学习问题被解决的话,类似的事情就有可能发生。那么环境扩展的问题就变成了由技术来解决的问题。更接近于被技术决定性地解决。那就会呈指数级发展。我认为持续发展是有可能的。当然在那种场景下现实中的制约也不是完全没有。从悲观的角度来看,由于复杂性不断增加,
构建环境的成本和时间也会持续增长,当复杂性达到某种无法承受的程度时,也可以认为发展将会停滞。那就像蓝色曲线一样呈渐近的形态,变成渐近的形状。需要应对的复杂性太大,根本无法突破的情况。我认为这种情况接近于
几乎完全没有技术创新的情况。几乎完全没有,继续像现在这样必须靠手工持续构建的情况,而且由于复杂性不断增加,手工成本也随复杂性成比例增长的情况,应该接近蓝色曲线。如果不是那样,而是通过一定程度的技术创新和改进,以及构建新的环境,构建更复杂环境的成本并不会无休止地持续增长的话,就会以接近直线的形态持续逐步上升。
即使是逐步上升,体感程度未必也是渐进的。技术发展的差异可能非常渐进,但体感上可以是巨大的。但如果只看技术本身,这种形态的发展应该是渐进式的发展。再仔细看这个渐进过程的话,
我认为可能接近这种形态。一点点持续发展,然后通过某种创新继续发展,但复杂性增大后速度又会变慢,到那时再通过某种技术进步或创新重新降低这个复杂性,从远处看这种形态就像一条直线。
卢正石 大多数现实情况都是第四种。我认为这些轨迹都有可能发生。
金成铉 当然,这些曲线中实际会发生哪一种,我也不太确定。我认为在预测未来方面,这是环境扩展的问题,取决于环境扩展问题如何被解决,这个轨迹会完全不同。
崔胜准 这个语境本身是来自RL的参考文献吗?
金成铉 就像The Second Half所提出的那样,假设RL就是答案,是所有问题的解答,即使给出了答案,仍然存在需要面对的问题。那个问题就是环境扩展的问题。
环境扩展可能被突破的场景,我认为有三种,其实这三种基本涵盖了所有可能的曲线,所以严格来说并不算预测,但就是这三种场景。
崔胜准 您是把它更加泛化,放到预测未来的语境中进行了一定的迁移来讲述的,对吧。
金成铉 在这里再具体说一下的话,蓝色的,蓝色轨迹我认为是技术创新不多,随着任务复杂性增加,构建任务的成本也同等增长的情况,或者相对于任务复杂性,成本增长远大于此的情况,应该比较接近蓝色。真的想解决非常非常复杂的问题时,需要构建的环境成本非常非常大,需要非常长的时间。所以技术发展变得非常缓慢的情况应该就是蓝色。
而指数级发展的情况,是环境扩展问题在技术上被一次性完全解决的情况,应该接近这种。所以如果持续学习被解决的话,
崔胜准 就是能够自我bootstrapping的那种技术,对吧。
金成铉 bootstrapping,而且自己发现环境来解决问题的情况。那就是技术解决了技术本身的问题。如果这些事情发生,就会出现指数级发展或者非常加速发展的体验。如果不是那样,虽然没有那种程度的技术跳跃,但出现了能够应对任务复杂性的技术,通过那个技术再构建出更复杂的任务,然后再有技术上的进步,再次降低课题的复杂性,如果说这些是不断重复的场景的话,可能更接近于一种线性的、直线式的流程,我觉得会是这样的。当然图表不会画得这么漂亮。
说一下我的预测,我觉得这个绿色出现的可能性还是相当高的。因为像持续学习这样的问题,现在所有人都开始关注了。在这几个月里,而且为了解决这个问题很多人也在尝试,所以我觉得这些被解决的事情是有可能发生的。当然即使解决了,也不一定能像这样持续漂亮地发展,可能会有很多试错过程。我本来押注在第4个上,第4个上的,
崔胜准 结果您说的是第3个,反而是第3个。因为我一直在等待和期盼这样的范式转换。
金成铉 所以这多少是基于期望的预测。但如果现实地来押注的话,我觉得会比较接近直线。持续尝试降低复杂性,由此能够应对的课题复杂性也会增加,我觉得这些会是比较普遍的情况。
崔胜准 但即使是线性的,在体感层面上也可以是指数级的,对吧。是的,没错。比如说现在通过人来
金成铉 创建课题,这个frontier企业们也在持续投入大量资金和资源,据我了解。在这些投入资源的过程中也在不断地产生进步。而这些对人们来说会突然感觉像是激进的创新。我认为这样的事情会持续发生。这些事情几乎是最基本的baseline,我觉得会是这样的。
2026 关键词:RL 的突破口 23:36
卢正石 那么成铉总结一下的话,主导2026年的最重要的关键词果然还是模型的,就像DeepSeek展示的模型的各种小型架构变化或效率提升之类的这些部分当然是理所当然地接受的,而模型根本性的capability、能力的跃升就是这个RLVR,在post-training中,在RL中谁能做出什么样的突破将会是最重要的因素,您是这个意思吧,我们这样理解就可以了。
金成铉 是的,而且那个创新可能是极其激进的创新。那就是持续学习的case,即使不是那样,也需要降低要解决的复杂性的小型技术创新,比如合成数据之类的创新,以及各种小改进,这些才会创造出实质性的差异。
卢正石 是的,前面也简单介绍了GLM 5论文,其中,虽然我其实没有读过,但大部分内容是关于如何在RL中引入新方法,如何提高效率等方面的内容,您是这么说的。所以基于此再稍微对潜在空间做一些预测的话,OpenAI或者Anthropic或者Google这些frontier lab几乎大部分的努力都投入在寻找RL的突破口上,您是这样推测的对吧。是的,在RL中寻找突破口
金成铉 以及改进当前正在进行的RL我认为是最大的差异所在。现在Anthropic、Google和OpenAI之间存在的差异也是由这些企业如何对待RL,如何构建RL环境,如何引导模型,如何通过RL来引导,这些方面决定的。举个例子来说,
模型倾向差异:Pre-training vs Post-training 25:25
金成铉 我认为pre-training方面Gemini仍然是做得最好的也是最强的,但是和pre-training分开来看的话人们,有些人更喜欢Codex也有人更喜欢Claude。这种差异的产生是在RL中,在post-training中产生的。
卢正石 是的,人们对模型的性格差异有各自的好恶。Claude给人的感觉是更直觉性的,与人类的思维或人类的某种倾向更加align,很多人是因为这种感觉而选择的。Codex喜欢刨根问底,
而且因为它擅长自己独立完成从头到尾的工作所以有人喜欢。Gemini则是在两者之间
其实有点不上不下的感觉。但实际上就拥有的知识和质量来看的话Gemini其实拥有的范围是最广的,这是我们的推测。那就是pre-training的力量吧。
金成铉 但性格的差异是在post-training中形成的。而说到post-training的话,就像之前提到的从产品的角度来看影响是非常大的。
所以喜欢Claude性格的人也很多,我也非常喜欢Claude的性格。用了Claude Opus 4.6之后更加喜欢了。当然这跟coding无关,是我在聊天时感受到的,我非常喜欢Claude的性格,但这个Claude的性格很难说是通过什么技术创新创造出来的。当然确实得到了技术创新的很多帮助。比如Constitutional AI之类的创新帮了很多,但像那位著名的Amanda Askell这样的人制定constitution,确立Claude的性格,如何对待Claude这个产品,如何改进这个产品,希望产品具有什么样的性格和倾向,这些方面的视角和改进产生了非常大的影响,从这个意义上来说post-training是无比重要的。那最近让模型更好地使用harness
Harness 与模型的融合:产品与模型的边界 27:17
崔胜准 或者agent swarm、agent team之类的最终RL有可能是决定性因素。harness本身,
金成铉 比如说如果有Claude Code这样的harness,模型会针对那个harness进行训练。这对于针对某个harness的专门化,以及harness之间的差异,有可能产生很大的影响。这是之前Moonshot AI的CEO提到过的话题,也是产品与模型的边界越来越近的原因之一。因为对于模型开发方来说,以前的话
优先考虑的是让模型针对各种用途进行训练,但现在模型开发方在打造agentic模型的同时,也必然拥有针对该agentic模型专门化的harness。因为那个harness本身就是环境的一部分。
所以对于Anthropic来说,Claude Code这个harness自然会作为环境扩展和post-training中的一个组件被纳入。如果是这样的话,通过这个harness,模型已经完成了训练。而且模型已经学会了如何使用这个harness,如果说这个harness,模型与harness的结合就是产品的话,那么这个产品在模型训练完成的那一刻就已经存在了。这似乎是以正反合的形式不断发展的。
卢正石 模型变好了,因此harness也变好了,与模型结合的harness产生了新的成果和flow,当它扮演环境的角色时,下一代模型又会将其整体内化,经历这样的过程,然后在更好的起点上重新构建harness,虽然不能说是断裂式的变化,但持续不断的变化一直在发生,我觉得是不是这样。这可能有点飞跃,
崔胜准 最近在OpenClaw之后,关于环境方面,如果说agent能够活动的环境已经变得非常多样的话,那其实并不是通过可微分的信号连接的。尽管如此,现在环境本身似乎有些影响,这种直觉虽然可能有些飞跃,但确实有这种感觉,很好奇您怎么看。能够进入各种环境
泛化与 持续学习 的可能性 29:32
金成铉 并进行活动,一种可能性是因为已经在各种环境中都试过了,也许是这个原因,但比起那个,可能不太是预期中的场景,所以更接近于泛化能力。突破环境扩展的一种方法确实是扩展模型的泛化能力。即使是在更简单或不同的环境中进行训练,如果模型能够泛化到更复杂、更不同的环境,那么这个问题就会变得更容易一些。从那个角度来看,我觉得更接近于
这种泛化能力的体现。不过,能够放入各种环境中尝试这一点,尝试的条件已经具备了。但就像您说的,如果能在各种环境中进行尝试并推动模型进步,并成为模型在各种环境中适应的机会的话,那么问题将会突然开始发生剧变。Claude bot们去某个地方参与社区、写文章之类的,自主地执行某些任务,当这些事情发生时,虽然能够自主执行的空间已经存在,但在那个空间中执行并产生交互,如果那能够推动模型进步并成为改变的契机的话,模型将会突然发生巨大变化。我认为那就是持续学习场景。能够将其连接起来的方法需要巨大的技术性、范式性的创新,确实让人期待这些突破。
如果你想象这真的发生了,人们的感受大概会很不一样。那无数的Claude bot们不仅仅是自主地处理某些任务,而是在自主处理的过程中获取反馈,人们将会看到它们自我进化。大概到那时候,说不应该这么做的人会大量增加。不应该让它暴露出来,不应该这么做。是的,认真地说。我一直以来都相信模型即产品这个理念,好在以前认同的人还比较少,但越来越多的人开始认同了。有点高兴。不过在谈论模型即产品这个话题时
可以说的一件事情是,等待技术的策略,就是等待技术发展的策略。其实这也是我个人的策略。大概是两年前吧,那时候虽然agent这个概念已经出现了,但模型作为agent被训练这样的情况还不太有。那时候人们也用模型做了很多尝试去打造产品。那时候的harness真的是非常庞大的harness。如果说现在的感觉是给模型递上工具让它去做事的话,那时候是把框架全部搭好,然后把模型塞进去的感觉。应该说是那种形式的harness吧?或者应该叫外骨骼?人们通过那种方式尝试打造agent,做了很多尝试,但效果非常不好。效果不好,复杂度也非常高。但即使在那个时候,人们就已经在说,与其构建大量harness做出复杂的产品,不如等三到六个月,等新模型出来后用那个模型配合简单的harness来打造产品,不仅更容易开发,性能也更加强大。能够展示这一点的技术发展所带来的影响力是极其巨大的,无论是构建产品的方式,还是访问模型的方式,都会被大幅改变和决定,我认为这就是一个很好的例证。
等待技术的策略 31:39
金成铉 所以现在人们会围绕模型的某些性能进行大量讨论。现在的模型这个不行那个也不行,看到这些做不到的地方,就觉得以后也不行。然后因为觉得以后也不行,所以认为以后也做不到——这并不一定是对AI持悲观立场。比如说,如果你认为以后这个也做不好,认为以后如果指令给得不好就做不好,认为如果不给出非常精确的指令就不行的话,那正因为如此我们需要学习AI,需要精确地学习使用方法,需要学会写好prompt、学会使用方法,也可以这样延伸下去。即便是从肯定AI的立场出发,也可以这样延伸。但我觉得与其这样焦虑,另一种策略是
期待技术的发展并享受其过程,这也是一种策略。与其觉得自己落后了,不如期待未来即将出现的模型,那些模型会让我更轻松地使用它们,能够更轻松、更强大地完成更大的事情——抱有这样的期待也是一种策略。这也是我的策略。当然这作为个人策略可能没问题,但不能保证在社会层面上一定是积极的。我说的是技术的发展。以前AI模型
不仅画不好手指,甚至连脸都无法生成像样的图像,那个时代是存在的。那时候很多艺术家们觉得连手指都画不好的AI怎么能拿来用呢,有很多人这样想。但那其实是随着时间推移就能解决的问题。人们倾向于以当前时间点能做到的和做不到的为标准,认为以后也会一直如此,这种倾向比想象中要强烈得多。很多情况下,那些限制中的很大一部分只是随着时间推移就能解决的问题。如果是这样的话,其实我们该预想的是,当时间推移问题解决之后会发生什么。我认为应该以此为基准来思考。
所以有一段时间这样的图片在网上流传过。艺术家们说”必须阻止AI,AI正在摧毁艺术”,这样反对的同时,程序员们听说AI要取代程序员的话,反而很高兴,说”快来取代我吧”——这样的图片曾经流传过。我认为那张图之所以流传,正是因为那种想法。因为现在的AI能给我们一些帮助,能让我们更轻松方便地解决问题,以后也一直会是这个程度,所以程序员的职业和身份认同之类的不会受到威胁——他们心里有这样的假设。但随着时间推移,能做到的事情越来越多,开始更认真地感到这是威胁的人比以前多了很多。而且表现出之前艺术家们那种反应的开发者似乎也变多了。
所有这些其实都是基于一个假设:当前水平的发展不会有太大变化,不会有质的飞跃,未来也不会有太大改变——正是因为这样的假设才会产生这些现象。但我认为不管怎样,这就是现实。那么当然,即使时间过去也无法发展的问题、无法解决的问题确实可能存在。那是非常有趣的问题。那些问题具体是什么,而且那些问题以后也绝对无法解决——这类问题是非常有趣的,其本身就具有研究价值。
但与此同时,我们当前面临的很多问题是随着时间推移可以解决的,现在解决不了的问题也可以持续去攻克。如果以此为前提来思考的话,我觉得会更好。开发Claude Code的
卢正石 Boris Cherny也说过,如果有现在解决不了的问题,就假设6个月后的模型能解决,然后针对6个月后的模型来打造产品。我觉得这话说得对。那更是因为他身处frontier企业,才更有可能做到。
金成铉 正如您所说,因为他在迷雾的前方,所以才能做到。但如果你在迷雾的后方,就更容易做出”6个月后也差不多吧”这样的假设,那样的话就会据此制定策略。
卢正石 我们经常开玩笑说过这样的话嘛。在AI领域,1个月的时间,过去1年才发生的事情现在1个月内就发生了,我们说过这样的话。而感受每一个月变化幅度的那种感觉,也就是感知梯度的感觉,每个人现在都不一样,因此要采取什么样的行动现在在每个人看来都不同。
崔胜准 如果说有什么期望的话,听了您的话之后我觉得AI自己能很好解决的问题、人类与AI以centaur形式协作能很好解决的问题、以及只有人类才能很好解决的问题,这三者共存的话那就是比较幸福的社会了。是的,也有可能是那样。
可验证性与上下文长度的极限 37:52
金成铉 但我觉得更近一步来说,比如现在RL的一个重要paradigm是可验证性,当我们仔细分析人类的职务后发现,实际上有很多部分是不可验证的,诸如此类,这些可能是更现实的场景,
这样的想法。比如说沟通很重要之类的,说到代码的话代码中也有一些更难验证的部分。像代码质量啊,我们所说的品质,
这些方面。所以得从RLVR逃跑才行啊。是的,这些方面
可能会一直成为瓶颈。但是这些问题大家都知道,所以大家都会尝试去解决,我觉得已经在一定程度上理清了思路,正在逐步解决。
卢正石 所以现在Transformer模型的上下文长度实际上已经固定在1M,都过了两年了。要突破这个限制,虽然有成本问题,但就连前沿企业,Anthropic和OpenAI也才刚刚支持到1M的程度。Google虽然很早就做了,但因此产生的局限性
我们实际上都在以agent engineering的名义进行弥补,感觉这已经逐渐固化了。还有前不久去年成铉您说过
所有token的entropy都不同,关键token之类的概念。因为这个,后面的上下文会完全改变,甚至以此为媒介,计算其中attention score的entropy,从语义层面将上下文块全部分割,然后进行内存管理的尝试我前天好像在YouTube上看到过。所以把模型定义为一种新的CPU,
在原有的von Neumann架构基础上构建认知计算的新模型,这类尝试最近也非常多。所以成铉您之前说的模型与harness之间的辩证关系,这些也是相关的,但太多的尝试在各处同时发生,我也真的不知道哪个方向是对的。真是各种各样的分化正在发生的时期啊。在上下文管理方面,您提到的那些方法,
上下文管理:Sparse Attention 与多 Agent 40:08
金成铉 以及Sparse Attention之类的属于更传统的基于技术的方法。然后现在正在发生的一个重要方向是multi-agent和自我总结。也有人称之为Compaction,就是让模型自身来管理上下文,无论是multi-agent还是Compaction,这些归根结底都是让模型自行管理上下文的方式。在我们目前使用的模型中
卢正石 有做这种auto compaction的模型吗?大多数不是harness,而是模型自身在处理这个吗?
harness在处理?harness在做。
应该说是harness在处理吧。是的。不过通过RL
金成铉 变得可能的其中之一就是这件事本身可以被学习。
卢正石 这部分能稍微详细解释一下吗?我好像没太理解这部分。最近大量出现的尝试之一是
金成铉 模型在用某个上下文进行工作,正在进行作业时,发现上下文长度太长了。大致看了一下上下文的长度,“啊,现在在这里完成不了了。交接吧,下一个。“但在交接的时候把到目前为止的工作进展总结一下再交接。可以做这样的决策。
比如说模型这也算是一种工具使用。最终是把下一个模型视为工具,交给下一个模型。但是对于下一个模型,要把我探索过的信息传递给它。那就可以交给下一个模型了。然后下一个模型也会继续执行。做着做着觉得这样也不行,再交给下一个模型。这就是模型的链式连接。变成了一种chain的形式。multi-agent也可以类似地理解。把模型拆分,为了处理这个任务让这个runner,然后从下一个模型接收结果,再继续做,这样最终就是模型之间的联动。
卢正石 但是这种倾向也是通过学习获得的吧。通过RL。
金成铉 更准确地说是可以被训练的结构。最终产出的结果是模型自行管理上下文的形态。看了之后觉得”啊,实在是这个上下文应付不了了。交接吧,
给其他模型或agent。“这种自主的上下文管理,可以构建出能够进行管理的框架。
如果能构建这样的框架并给予奖励的话,就可以通过RL进行学习了。
而且这种形式的工作正在大量进行,像Compaction这样的企业虽然有harness的参与,但应该针对Compaction场景进行了RL训练。
Compaction具体是怎么运作的内部情况我也不太清楚。但这些东西应该都已经加入了。
崔胜准 模型也没说不能用Second Brain啊。可以做Zettelkasten嘛。
金成铉 而且从某种角度来看这可能是更好的方向。与其扩展上下文试图把所有东西都塞进上下文里,不如使用Second Brain、使用工具、通过使用agent让模型能够管理上下文,这可能是更合理的方向。重要的是,如果是以前的话那些全都得用harness来做。
用harness来”啊,差不多到这里了,上下文到这个程度就拆分,怎么拆分,怎么总结。“总结完之后”交出去,交出去之后把结果取回来。“这些都得创建场景然后用harness实现。
崔胜准 是啊。挂hook然后这样那样做的。如果是以前的话,去年的话就是那样做的。
金成铉 虽然现在还存在tool use之类的局限性但这些终究是可以被学习的。而且这也是我个人的信念AI模型中能够学习的东西和不能学习的东西之间存在本质上的差异。也就是说现在已经有了可学习形态的
崔胜准 上下文工程,已经存在了。就是一种能够管理上下文的方法。
金成铉 如果认为模型能够自主管理context的话那么以context管理为核心的对于各种harness的观点可能也需要改变了。所以Dario Amodei最近的采访中
Dario Amodei 采访与 持续学习 展望 43:40
崔胜准 透露出即使不做持续学习也能解决问题好像有那种意味。
金成铉 不过我个人在那方面仍然认为仅靠context是不够的持续学习,也就是需要发生学习的——这其实是超越单纯的context管理的问题。从context管理的角度来看,归根结底是长度的问题,只要context放得好就全都能搞定,是这种感觉但我觉得比起那个,学习还是必要的我是这么想的。所以在那个采访中也是
崔胜准 他也说了我们也在做持续学习。大家都在做。
金成铉 更早之前给人的感觉是不做持续学习但现在信息越来越偏向在做持续学习的方向了。
崔胜准 感觉大家都在做。我觉得大家都很明显地认为
金成铉 如果把这个问题解决了,就会发生了不起的事情。2026年刚刚过去了两个月
卢正石 过了大约六分之一,DeepSeek V4又会给我们带来怎样的惊喜就再等等看吧。已经三月了。
崔胜准 那AlphaGo纪念周也不远了呢。
卢正石 三月、四月,再到五月
崔胜准 还有很多预定的活动呢。
卢正石 又开始了疯狂奔跑的时期。另外成铉个人也有一个消息对吧。成铉这周要离开韩国去英国了。聊聊个人近况吧。
近况闲聊:搬迁伦敦 44:54
金成铉 因为跳槽了,新公司要求搬迁所以要去英国了。
计划去伦敦那边。去了之后那边也算是frontier发展的地方应该能接触到很多有趣的消息吧。希望能如此。
希望能实现传说中的偷听呢。有什么期待吗?比如成铉的研究兴趣
崔胜准 以后在那个领域想尝试做的事情之类的期待感。因为和您开头说的是相关联的部分嘛。最近发生的事情让人兴趣减弱下一步肯定会有想要克服这一点的某种需求吧。我觉得可以从两个角度来思考。
金成铉 在做模型的时候,那个模型在frontier上竞争当然是非常非常重要的,我们可以把关注点放在超越frontier上,但我觉得除此之外做模型本身,以及做那些能让模型变得更好的工作,本身就很快乐。为了做出更好的模型而做某些工作开发某些技术,我觉得我是喜欢这些的人。而在模型开发本身之外关于技术进步
大家都在期待着越来越近的技术我想也是因为这个原因。我已经开始享受未来将要发生的事情以及AI的发展了。
卢正石 与其焦躁不如享受,这才是我们的风格。
崔胜准 与其被FOMO牵着走,不如专注于自己擅长的事情找到自己的重心我个人觉得这也是一种旅程。而且未来真的很难预测。
不确定时代的平衡感 46:36
金成铉 大家基于对未来的某种预测而感到焦虑变得焦虑,也会变得过于乐观什么都会发生。但是与其那样乐观和焦虑,未来不是太难以预测了吗,我是这么想的。比如说要计算期望值的话不是要把概率和结果相乘再求和嘛。
但是有太多太多种可能性而且因为不知道那些概率从不确定性的角度来看,相信某一种可能性并因为那个信念而动摇我们其实并没有确切地知道那么多吧。
卢正石 最近说全球人类可能有点夸张但真的是全民都在作为预测引擎生活的时代。所有人都紧盯着股市各自在下注。没有不做的人呢。说到prediction
崔胜准 突然想起一个半开玩笑的事,我之前也不知道原来是pre加diction。diction,就是说话,提前说说看就是这么个意思。
卢正石 成铉,那去英国之后我们好好配合时差继续关注这个frontier上发生的事情以及对此的思考,我们正处于非常混沌的时期。所有人都处在混沌之中,我觉得在悲观和乐观之间平衡感终究是最重要的,那些平衡感出色的人总是能在任何未来中很好地适应并做出正确的选择,或者做好风险管理,我见过很多这样的例子,而走向极端某一边的人要么会错失机会,要么可能蒙对一次但下次就猜不中了,这种情况见了很多。我也总是兜兜转转拥有怎样的平衡感才是作为人类当下最重要的品质,我是这样想的。成铉,即使您要去伦敦,能像这样从容地一起回顾,
崔胜准 交流的机会非常珍贵,所以我们不会轻易放您走的。明白了。
卢正石 那么今天也是回顾这两个月发生的事情,以及展望未来将要发生的事情,向成铉查询思考 token 的一次很好的交流。我们正在经历一段不确定性时期,再过一两个月,应该会有很多有趣的事情发生吧。
收尾与致谢 49:01
金成铉 是的,希望如此。
卢正石 那么今天就到这里结束吧。成铉,谢谢您。