EP 90
AlphaGo之后,十年 (feat. HyperAccel CTO 李镇元)
开场与嘉宾介绍(HyperAccel CTO 李珍元) 0:00
卢正石 好,今天录制的日期是2026年3月14日。是 Pi Day 的周六早晨。
今天想来聊聊 AlphaGo 10周年相关的话题,跟大家回顾一下。令人惊讶的是,AlphaGo 带给我们的震撼已经过去整整10年了。所以我们想把这10年简单 recap 一下。今天除了和胜准一起之外,我们还请来了一位新嘉宾。
今天邀请到了 HyperAccel 的 CTO 李珍元。欢迎您。大家好。
李珍元 感谢邀请。李珍元 CTO,
卢正石 最近也担任过独帕模(韩国自主基础模型构建项目)的评委,而且在我们深度学习早期阶段,也是做出过很多贡献的人。我们那个 PR 12,是该读作 PR Twelve 吗?我们的论文读书会持续了非常久,我自己也从中受益很多。李珍元 CTO,也请您简单介绍一下您现在正在做的业务。
HyperAccel 介绍:推理专用 AI 半导体与服务价格问题 0:59
李珍元 大家好。我是 HyperAccel 的 CTO,我叫李珍元。简单介绍一下我们公司,HyperAccel是一家做推理专用 AI 半导体的公司。
前不久也有相关新闻出来,大家在使用 AI 服务的时候都会觉得价格很贵。原因有很多,比如 HBM 这种昂贵的内存,还有昂贵的制程,使用这些之后就导致普通用户现在要用这些服务价格负担还是比较重。所以我们想做出一种半导体,能让更多人用上更高质量的服务。因此我们不用 HBM,而是采用叫做 LPDDR 的低功耗内存,希望能以十分之一的价格提供服务器,把现在最便宜的服务目前大概要每月150元人民币左右,压到25元以下,我们正带着这样的宏大目标努力开发芯片。
卢正石 我觉得方向很对。这些事情其实早在2017年,那个时候今天大概也会聊到很多,
PR 12 论文阅读会与社区的力量 2:05
李珍元 当时社区的作用是非常大的。现在当然也不能说不重要,但那时候社区的力量尤其强,为了推动韩国的深度学习发展,我自己也受到了很多人的帮助。当时和现在 Upstage 的代表金成勋,以及几位朋友一起,在一个叫 TensorFlow Korea 的聚会里大家有了共同想法。那时候论文大量涌现,新的算法也层出不穷,大家都不知道该看哪些论文,而且读一篇也要花很久。所以我们想稍微帮大家一把,基于这个初衷在2017年的时候,我们在 Zoom 上每周轮流由两个人来做论文 review,然后像现在这档播客一样,原样全部录下来上传到 YouTube,这个活动到现在还在继续。做得很开心,也很有意思。我现在暂时休息一下,休息过后会再回来继续参与。那么这些事情的发生
崔胜准 可以说是受到了 AlphaGo 的影响吗?是大家受到冲击之后才开始学习的吗?当然。那时候开始,韩国这边确实掀起了很大的热潮。
李珍元 我自己其实在那之前,大概从2014年左右开始就一个人在摸索学习、做各种尝试了,但当时困难很多。资料也不多,国外好像也没有特别丰富。
但是在2016年 AlphaGo 事件之后,韩国这边尤其掀起了很大的热潮,大家的关注度也提高了,社区也更活跃了,也正是在这样的背景下,我们才开始做这件事。最近到了 AlphaGo 10周年,
AlphaGo 十周年官方文章与 Noam Brown 的洞见 3:50

崔胜准 Demis Hassabis 和Google DeepMind 那边都发了正式文章,其中有一篇叫做“从游戏到生物学,乃至更远:AlphaGo 留下的十年影响”的文章,另外就是去年我们在节目里播放过一次的那个 Google DeepMind podcast,当时还给大家介绍过那一年的最后一期。结果今年的第一期内容也是,去年的最后一期是和 Demis Hassabis 的访谈,而今年则是以 AlphaGo 10周年相关的 podcast 开场。我觉得这两部分内容都很好,所以拿来聊聊。
具体内容我就不展开细讲了,大家有空可以自己看看,另外关于这件事,Noam Brown 还发过这样一则 post。翻译过来的意思大概是,今天最前沿的推理模型其核心方法,令人惊讶地与 AlphaGo 很相似。先模仿海量的人类数据,为了获得更好的推理在推理时增加计算量。当年是 Monte Carlo Tree Search,而今天则是 Chain of Thought。再通过强化学习超越单纯模仿。这套方式非常相似,我记得 Demis Hassabis 还在下面留了评论。总之,在 Noam Brown 说完这些之后,
Demis Hassabis 留言的大意是,朝着 AlphaZero 的方向前进,需要非常谨慎。我们是否要打开那个开关,这件事还是要认真考虑。这背后的含义,说到底就是一种自我增强的系统。所以今天我们可能也会聊到这些话题。
不知道这两篇文章或者视频,您是否看过,或者有没有什么想评论的部分?您觉得哪些点值得重点看?关于能不能走向 AlphaZero,
李珍元 我自己想过很多,后来实际查了一下,发现确实已经有这种动向了。走向 AlphaZero 的方向,本质上就是不依赖人类数据。也就是说,不经过现在这种大规模 pretraining,只靠强化学习能不能做到,甚至做出超过当前水平的东西。不过我感觉那边实际上确实有很多动作,所以我一直很有兴趣地在看。
崔胜准 归根结底,这次在 Google DeepMind 播客里提到的,还有之前发的博客文章,感觉都是在帮我们梳理,现在这个方向是如何自然而然地连接到科学和创新上的轨迹。还有一点也很有意思,那栋楼叫 37手大楼。
第37手与 Platform 37:对局瞬间如何成为象征 6:13

崔胜准 就是取自 AlphaGo 那步惊人的棋。那人类棋手李世石九段那步惊人的棋是第几手来着?是第 78 手。李世石是 78 手,AlphaGo 是 37 手,所以他们好像是沿用了这步 37 手的名字来给 Google DeepMind 的新总部命名。说是从夏天开始入驻。
李珍元 这是第二局吧。
卢正石 应该是第二局的第 37 手。我记得当时大家,尤其那些解说员,都在说“咦,为什么会下在那里”,因为如果是人类根本不可能下出那一步,后来
李珍元 也有很多人说像是下错了。如果回头看 2016 年,也就是 10 年前,
2016 年 AlphaGo 对局现场故事 6:54
卢正石 那时正好是 TensorFlow 刚出来,大概 2015 年那会儿。虽然 TensorFlow 已经出来了,但当时世界上几乎没人真正知道那是什么,那时候大家还在讨论深度学习到底是什么,看着 NVIDIA keynote 研究 softmax,然后从 MNIST 开始,MNIST 做完以后再去跑CNN 之类最基础的东西,所以那时候其实不太常说 AI。当时更多说的是 machine learning、deep learning,而且大家对它的期待也没有那么高。但实际上到了 2016 年 AlphaGo 出现之后,
AlphaGo 刚开始比赛的时候,我本人也在现场,在那之前不是还有个前夜活动嘛,也就是 gala show,我去的时候看到 Eric Schmidt 还有各种名人都到了,李世石、Eric Schmidt 还有一些超级 VIP坐在最中间前面的桌子,其他名人都坐在后面,那时候李世石本人还是信心满满的。人类会赢。但反过来,我当时想,Google 那边能让这么多大人物都飞过来,说明他们肯定是带着某种确信来的,不可能只是随便来看看,所以我当时押的是 AlphaGo 会压倒性获胜,现在还记得当时大家打赌打得很热闹。不过第一局结束之后,说实话大家都受到了很大冲击。太压倒性了。
崔胜准 你们两位当时都是看了直播吧?
李珍元 对,看了。看了。因为我自己也不是完全懂围棋,
卢正石 所以那些招法到底有多深,我其实并不真正理解,但是看着那些负责解说的人发出的叹息、惊讶和挫败感,我就意识到,啊,这真的是很了不起的事。还有一点特别有意思的是,当时包括 YouTube 在内,
李珍元 很多不同频道都在解说,也就是所谓的职业围棋棋手在做讲解,但大家的意见分歧非常大。每下一手都去看大家怎么解读,那也是很有意思的记忆。
崔胜准 当时像策略网络、价值网络这些术语,我那会儿也不太懂,所以还在想这到底是什么意思,还去翻博客来看,挺有印象的。
卢正石 AlphaGo 对局结束之后,很多教授或者知名人士都开始讲它到底是怎么做出来的,一下子冒出了很多讲解资料、YouTube 录播,我记得真的非常多。某种程度上,也可以说韩国因此受益了吧?是不是也能这么看?
崔胜准 因为很早就被正面重击了一下,带着切身感受去看这件事,而这大概就是 Demis Hassabis在对局结束后于 KAIST 做演讲的视频。他在里面讲了 DQN 之类的内容,还梳理了它具体处在什么样的脉络中,也讲了这些东西,所以那时候确实能更有实感地看到这些内容,这大概就是我对 2016 年的体验。
卢正石 如果说 14 年、15 年、16 年那时候,光是 DQN都已经算是非常前沿的技术了,而且那时大家也开始在 OpenAI Gym 里一点点尝试一些偏 RL 的东西。我也记得当时把一些感想
崔胜准 带着情绪写在了社交媒体上。所以在我们今天正式聊回顾这 10 年历史之前,我最近觉得有件事和这个挺有关联的,那就是 Autoresearch 很火。Andrej Karpathy 去年是靠 vibe coding先占住了 coding 的 meme,今年又靠 Autoresearch,有点像一下子把这个概念牢牢抓住了,你们怎么看?
Andrej Karpathy 的 Autoresearch 与可验证信号的反复迭代 10:24
卢正石 这个和 Ralph loop 有什么区别?就是 Ralph loop。只不过它是在
崔胜准 非常明确的 domain、非常明确的可评估 validation 上运作,仅此而已。不是做到 test 那一步,而只是拿 validation 分数,朝着能把那个分数压低的方向不断提出各种点子,反复实验、继续实验,让它能一直这样做下去,大概就是这种感觉。
卢正石 从概念上说,其实和 RLVR 很像。只不过层次不一样。RLVR 讲的是在训练过程中,如果能给出某种 verifiable 的,也就是可验证的信号,那模型就能在那个 domain 里持续训练下去。而这个则是把它实际拉到了应用过程中来,对吧。研究这类事情,归根结底也是如果面对一个非常强的模型,能给它设定奖励信号,也就是朝着变好的方向的目标,那它就能自主地朝着那个目标前进,这次其实就是证明了这一点。这个奖励信号不是 RL 里的那种奖励信号,
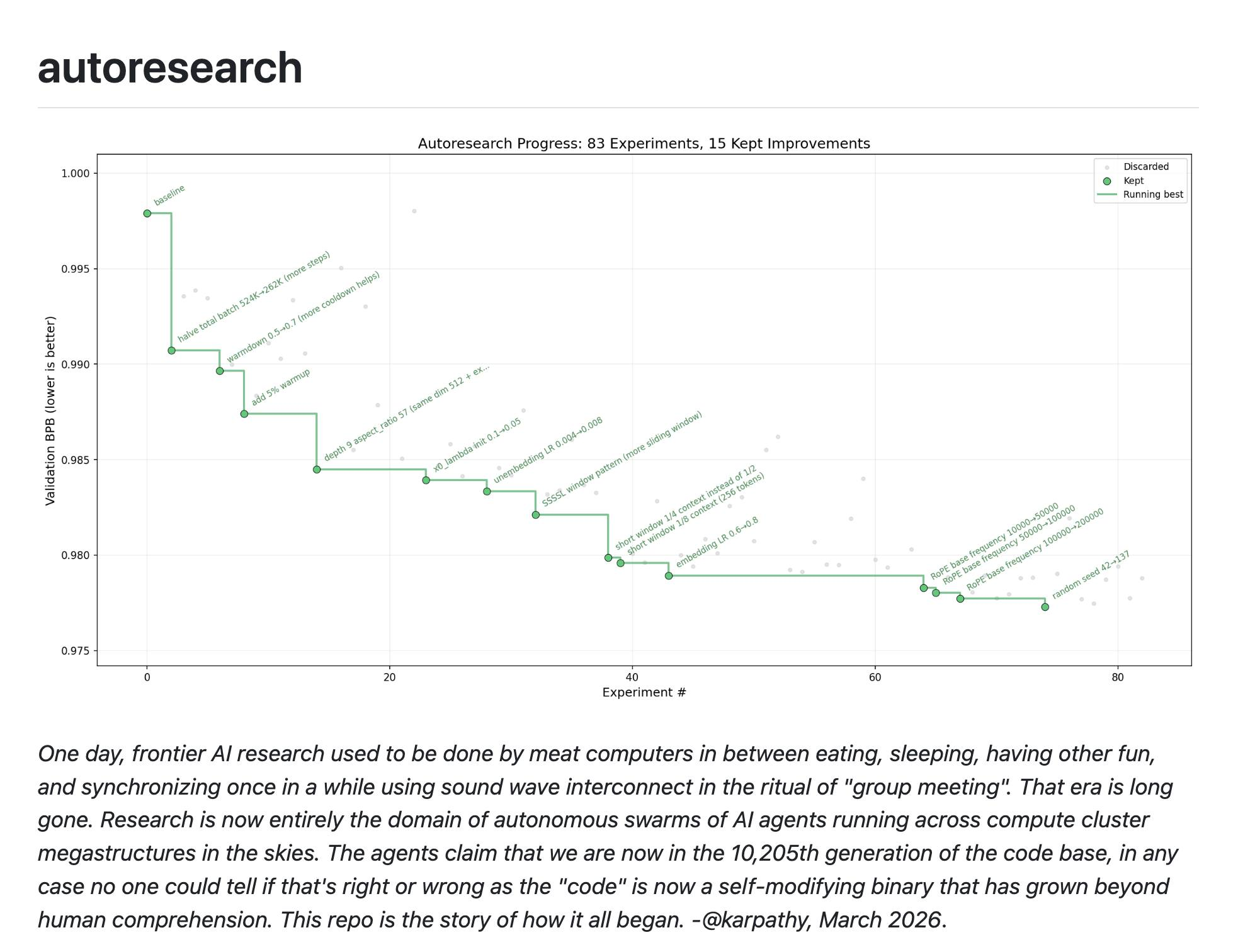
崔胜准 虽然它并不可微,但只是给出一个能不能成的判定,就这么简单,只要有几个非常简单的文件,prepare.py,这个倒不是很重要,再有 train.py、program.md 这些,它就会朝着满足这个条件、直到成功为止不断把指标压低的方向去做 research,而且那个 MD 文件也不算长。最后有个很有意思的点,never stop。不要停,如果卡住了,想法卡住了,就去读论文再回来立这个假设试试看,再试试那个假设,别一直来问我要不要继续往下做最后那句咒语好像就是继续做下去而且实际已经开始看到成果的那些东西也在这里用图表展示出来了。就是这么回事,然后这里的 Andrej Karpathy 和
一位叫 Yuchen Jin 的人,最近这位好像也是做过 CEO,现在像是卸任去做别的事情了他们甚至聊到了这样的想法。如果说现在这是在运转一个 squad,或者说像是一个 agent 一路这样深入下去的感觉,那把这些研究者的社交媒体做成 notebook 怎么样甚至都聊到了这个程度,我觉得那篇社交媒体帖子挺有意思的。还有一些衍生工作,
这个是在讲怎样优化 TinyStories,而且 TinyStories 本身也是数据集比较小、整理得也很干净,这是他通过把那个压低之后学到的东西。然后这个叫 Sparse Autoencoder,是在 mechanistic interpretability 研究里让那些常用的方法能做得更好,也是用 Autoresearch 的方式来做。然后这个是 Simon Willison 分享的一个案例,Shopify 的 CEO,也就是这位 Tobias,把自己以前做过的某个东西提升到了快 53% 的速度,他就是把 Autoresearch 应用进去做成的。也就是说,在能跑通的领域里,这一套都行得通。当然也会有不行的地方,而且不行的领域肯定更多,
但在能跑通的领域里,用简单又优雅的方式,把 token 真正烧在刀刃上去做这件事,这样的路径正在被不断发现。不过那个真正好用的领域偏偏就是训练 AI 的那个领域吧。对,只要目标足够明确,
卢正石 只要能把 evaluation metric 定义清楚,只要 benchmark 存在,那地方就一定能做成。
崔胜准 对。去年正石还说过,只要把事情变得 verifiable,很多问题看起来就能解决了。
卢正石 是啊。最近流行的那些 framework感觉也都是类似的方向。先是为了产出结果,不管怎样都挂上 hook,默认内置一个让它永远重复下去的 Ralph loop,而 Ralph loop 要想成功,只要把前后两端控制好就行了。一开始要用非常明确、干净的 context 来启动,也就是帮它做好那个 plan,再把“做到这样就算成功”的那个 evaluation metric 定义清楚。所以本质上大家都是 Ralph loop,无限重复这一点是一样的,但最近这个社区似乎正在往如何把前后两端做得更精细这个方向发展。所以我自己也见到过效果,
崔胜准 我在 3 月的时候一直解不开、一直解不开,虽然现在也还没做到 100%,但成功的那个案例,归根到底是我把这个东西,就是原本补不上的那一块,全都写了建模代码,自己亲自建模,等于说是我提供了一种 ground truth,然后让它一直跑,直到做到和这个接近为止,最后算法就出来了。
卢正石 你就是一直让它跑到成功为止。它不是只会一路往前,
崔胜准 而是会退回来立假设,再往前试;不行的话,就再退回来重新立假设,我很有意思地看到了它一步步去找到能成立算法的过程。得到的教训是,啊,准确的反馈和准确的数据真的非常重要。
我自己去构思各种算法,或者引导模型去构思的方法也许有一部分会奏效,但原来直接 end to end 也能做,这点让我挺有感触的。前两天具峰
Ralphthon:规划与评测 harness 设计的重要性 16:05
卢正石 搞了一个 Ralphthon。他和 OpenAI 一起办了 Ralphthon,特别有意思的是,计划一旦制定好,接下来的 12 小时就不能再动手干预了。只能靠 RL loop 自己转,很巧的是,拿到第 1、第 2 名的人全都是 harness 的设计者。第 1 名是做了那个叫 Ouroboros 的 harness 的人,拿了第一;第 2 名则是
崔胜准 就是会一直转下去嘛。
卢正石 做了 Oh-My-Codex 的许艺灿好像拿了第二,看那些逻辑,里面其实都有原则。无限、直到成功为止的无限重复,这一点没错,但怎么把计划做精细,以及怎么 evaluate 这个结果,在这些部分把 harness 设计得更精密的人,最后往往就能做得更成功,这就是当时的 learning。古峰把自己得到的learning 整理成了一页 slide,我读过那个,感觉方向非常对,刚才说的 Autoresearch 这些,我觉得脉络也都差不多,我是这么想的。还记得吗?类似的东西大概在去年 10 月,
崔胜准 OpenAI 也提过。
卢正石 当时是 Sam Altman 和 Chief ScientistJakub Pachocki 两个人出来,在去年 10 月做的发布。他们在发布 OpenAI 的 vision 时说,到 26 年 8 月,AI research差不多到那个时候,AI research intern 会完成,再过 2 年之后,AI research PhD 也会完成,他们当时是这么比较模糊、绕着说的,而所谓 AI research intern,其实就是说它会变成一种很像 Autoresearch 的工作。
崔胜准 所以现在 Andrej Karpathy 也是,他在 Twitter 或博客里写的那些内容,归根到底就是说,这会是 Big Tech正在做、正在竞争的领域。他说的是那种自我增强的方向,他自己也是抱着这种想法来做的。做得非常简单,也很朴素,但现在它确实有点在 viral 的感觉,大概这就是 2026 年 3 月的现状吧。
卢正石 对。大家不都半开玩笑地这么说嘛。我们也会在群聊里聊这个,要是我们的一些服务之类的发到群里,就会说“啊,这个离 1 딸깍 away 还差一步”或者“这个大概还差 2 딸깍s away,3 딸깍s away”我们会这么开玩笑地说这些话,就这样度过着 2026 年 3 月。那现在要不要回到过去看看?
“想当年啊” - AI 十年回顾开始 18:44
卢正石 要不要进入一下我们的“想当年”环节?

崔胜准 我们这样你来我往地聊,可能会讲到我们各自的经历,也会讲当时有哪些发展脉络,我自己有印象的东西里,挑了几个一时能立刻想起来的。大概在 2011 年前后,我是在时间线上看到这个的。这是 Peter Norvig 的,Google现在应该还在吧,至于是不是还在 Google 我有点记不清了,反正他当时是最资深的 scientist 之一。就是和 Peter Norvig 一起做过 X 的那位。Google X,Sebastian Thrun。后来创办 Udacity 的那位当时一起在 Stanford 开了 AI 课程,Andrew Ng 也开了机器学习课程,然后好像还有一门数据库课程。我回头翻了下那段时间线,就看到了这些内容。所以 Stanford 当时做了 MOOC,可以说是现代 MOOC 起点的那类实验,而且这些全都是 AI、ML、数据库这些方向,据说吸引了这么多人参与。
不过这里有个名字叫 Daphne Koller,Daphne Koller 后来和 Andrew Ng 共同创办了 Coursera,这位还创办了 insitro。她和生命科学也有很深的关联,总之当时有这些事情,也正是在那里,很多人,包括我在内,其他人应该也差不多,
都是从那时开始接触 deep learning 的。珍元,你是怎么开始接触 deep learning 的?我的话,某种意义上其实
深度学习入门期:ImageNet 与三星电子 NPU 开发 20:22
李珍元 也可以说和这个播客有点像,一开始是我在工作的时候,想跳出那种日常 routine,想看看有没有什么东西是真能改变世界的,大概是带着这种好奇去找的。后来 2014 年的时候,我看到 Google 在 ImageNet 拿了第一之类的消息,从那时起就开始感兴趣了,想着这 deep learning 到底是什么,也就是从那时开始去查资料的。不过以前我们也都常说,
deep learning、AI 或者机器学习曾经有过所谓的寒冬期,对吧。所以从某种意义上说,deep learning 其实是重新包装后的名字,要是说 neural net 之类的,大家都会很排斥,所以为了突破那种局面,就用了 deep learning 这个说法,让人会想“这是什么”,结果一看本质上还是同一脉络的东西,只是规模变大了,而且正如我们之前在这个播客里也多次提到的 Bitter Lesson 所说,AI 的发展最终还是朝着减少人类 inductive bias、扩大 scale 的方向前进,而当时有一个叫 ImageNet 的东西,那时它就是一个我们必须攻克的 benchmark。那是大家都在挑战它的时代嘛。所以我是从那时候开始关注的。
不过随着这些东西自然地出现,我当时所在的地方,也就是我那时在三星电子做的是智能手机里用的半导体开发,那边也开始做所谓的 NPU,在做这个的过程中,我好像也想得更多了。我以前做的半导体是什么类型呢,比如说视频 codec 之类的。这种东西的特点就是标准 spec 是定死的。大家聚在一起把 spec 定好,那么该做什么,这颗半导体该做什么其实已经确定了,剩下的就是怎么把它高效地跑起来,如果说把这个做好,就是好半导体的标准,那所谓 NPU 这种 AI 半导体,它到底该做什么却一直在变。新的算法不断出现,演进速度又快得惊人,当时我就觉得,如果我在做优秀半导体这件事上,不能很好地理解 AI 算法,那说自己能做出好的半导体,根本就说不通。
所以我从那时起看了很多论文,刚才前面提到的那个 PR 12,我想也是那样开始的。因为我自己也在大量看论文,就想着如果能和一起看的人交流意见、
也能分享出来就好了,这样还能顺便学习、读论文,于是就是那样开始的。
崔胜准 大概是 2014 年开始的。对,我开始接触这个,其实就是为了学习。然后不知道你们还记不记得这个,
YouTube 猫识别实验与涌现现象 23:00

崔胜准 要看核心的话,就是这张图。就是 YouTube 开始识别猫了,那件事。这个实验具体是怎么设计的,
卢正石 其实并没有写得特别清楚,但看到这张图的时候,我记得我还和李相浩博士一起特别激动地讨论过这件事,它当时好像是把大概一千台左右的 cluster 搭起来,然后放上类似 CNN 的结构,就这样用 unsupervised 的方式把 YouTube clips 全部喂进去,结果在某个特定 layer 的某处,长出了一个能识别猫脸的 filter,当时有好几张这样的图。
所以这就说明了,所谓智能其实未必需要做什么特别的设计,光靠学习本身就可以所谓地自发涌现,可以 emerge,这就是它给人的例子。不过也过去太久了,具体实验设计是怎么做的我也记不太清了。如果我没记错的话,
李珍元 应该是用 autoencoder 的形式做的。就是把这张图像输入进去,再把它重建出来的那种方式。这样一来,这其实就是非常典型的我们在 LLM 里经常说的涌现现象。
就像刚才说的那样。很震惊吧。所有人都震惊了。因为这怎么看都是只猫。当时虽然也挺震惊的,
崔胜准 但我就觉得原来如此,感觉本来就应该能做到,甚至还有种“这居然到现在还没做到?”的感觉。我当时也就是当个新闻看过去了,
卢正石 那时候比起 deep learning、ImageNet 这些,还有 IBM 做的那个。就是去问答节目上答题的,出现在 Jeopardy 里的 IBM 的Watson。那时候正是 Watson 的 pipeline 很流行、很多人在研究的时候。还有语音识别这类东西,在当时也不是用 neural network,而是用 HMM,也就是 Hidden Markov Model 来做的时候。我觉得那是个一训练起来这类东西会更先做出来的时期。其实我也是直到大概 2014 年的时候,才只是觉得,哦,原来有这种东西,真神奇,也只是知道 machine learning 是什么而已,真正开始想着要认真学一下 deep learning,大概也是从 14 年开始的。我也是知道有 Andrew Ng 的课程,
崔胜准 还有 Peter Norvig 的课程,视频和资料也看过几次,但没想过要深入钻研。
Andrej Karpathy 文档与 ImageNet 黄金时代:CS231n、DeepDream、Chris Olah 25:21
崔胜准 后来在时间线上火起来的一个东西,是 Andrej Karpathy 的一篇叫 Hacker’s guide to Neural Networks 的文章,当时也被非常频繁地提起。
你们还有印象吧?
就是 backprop 怎么做,computation graph 长什么样,一边说这东西其实没想象中那么难,一边用 JavaScript 来解释这些内容。这就说明,在哪个时期、和谁一起、
卢正石 在什么地方做什么事,其实很重要,这就是人生的 timing。Karpathy 当时是在做 ImageNet,那正是 ImageNet 处于话题中心的时候,他是 Fei-Fei Li 教授的博士生。
崔胜准 所以这里写着 PhD student Stanford,还做了 ConvNetJS。ConvNetJS 本来就和 Fei-Fei Li 的工作脉络相关,他一边做这些,Karpathy 还一边传播这些东西,看得出来他特别喜欢分享和交流。那时候的 benchmark 就像现在的 AIME,
卢正石 或者 Humanity’s Last Exam 这样的 benchmark 一样,当时最火的 benchmark 就是 ImageNet 分数嘛。看的是 top-5 accuracy,那时候还有 VGG。
崔胜准 所以当时也会做这种东西拿来分享。在网页上也能做这些。我也想到一个,就是 VGG,VGG 在 2014 年拿了第 2,
李珍元 在 classification 里拿了第 2,但它的使用量比 GoogLeNet 高得多。在当时。因为 VGG是非常简单的 architecture,连 convolution 也是只不断堆叠 3x3 convolution,证明这样也能做出来,所以因为它很简单,大家就觉得可以应用到很多地方,所以很多人都去尝试了。我那时候也记得,我家里的 GPU,
在当时显存只有 2GB。我还插着那块 2GB 的 GPU,想着试着训练一下。不过 batch,我记不太清了,感觉 batch 好像最多也就到 2 左右。所以即便这样我也想试试看,就一直开着跑,记得很清楚。那时候真的是做什么都觉得特别神奇。
卢正石 我记得 2014 年是 VGG,不对,是 GoogLeNet 拿了冠军,然后 2015 年是 ResNet 拿了冠军。所以当时那种,和 vision 相关的东西特别火。
崔胜准 所以 CS231n 最初的标题就是Deep Learning for Computer Vision。所以这里面也出了很多后来非常有名的人物。后来也都陆续出现了。
李珍元 在那里讲课的人后来很多都成了明星人物,确实如此。
卢正石 那位 Justin Johnson,没错。是个很有名的人。
崔胜准 现在他在和 Fei-Fei Li 一起做 World Labs。对。他先去了密歇根大学当教授,
卢正石 后来好像又和 Fei-Fei Li 一起创业了。
崔胜准 还有 Jian Fan。Jian Fan 也是这里出来的。还有当时很流行的一个东西,
卢正石 叫 style transfer,就是把照片变成梵高风格的画。
李珍元 就是当时说的 neural style。
就是当时说的 neural style。对,neural style。我们那位 Justin Johnson用 Lua 做了一个很干净的 Torch implementation,我记得我当时也跑了很多次。
崔胜准 还有,在那些和 vision 相关的东西里,关于它为什么能起作用,真正提供线索的,最终还是 Chris Olah、以及 Alexander Mordvintsev、Mike Tyka这些人参与做过的那个叫 DeepDream 的工作,这个虽然在艺术领域也被反复提起,但归根结底它就是 feature 放大嘛。现在也可以说,这还是某种 interpretability 研究的起点性工作,从谱系上是可以这样讲的,而这类故事的脉络,在以 Chris Olah 为核心做的
Distill.pub 上留得非常完整。所以 Olah 做的这类东西,你看这些标题和作者,里面有 David Ha,也有 Olah。所以这里还有用 RNN 来做手写预测之类的内容。前期主要还是很多 vision 方向的话题,但这里也有 RNN 的内容。还有 Chris Olah,
Jeff Dean 当时就对 Olah在他年纪还很小的时候说过,“这个人一定得招进来”,还有这样一段轶事。大概在 2014 年,Karpathy 经常分享这些东西的时候,Olah 明明年纪还更小,
却已经在分享这类工作了,
还收到过 Yann LeCun 的评论之类的。那些博客到现在都还保存得很好,所以那边也挺有意思的。那时候开始做这些的人,过了大概 4 到 5 年后,其实就成了主流了。而且在 2014 年,哪怕只说 2014、2015 年,我们那时都还在聊图像、style transfer、CNN、这些东西,还有 ImageNet 之类的,但 Ilya Sutskever 发表 sequence to sequence 论文是 14 年。可当时我们拿着 RNN开始学习一些新奇的东西,然后做 chatbot、开始拿来玩,大概是 15 年之后的事了,
卢正石 应该是在 16、17 年左右。Ilya Sutskever 的 sequence to sequence 共同作者是 Oriol Vinyals 来着吗,那位现在还在 DeepMind。我可能记混了。不过好像是这样的。总之,这样的发展轨迹后来由 Chris Olah他最终也成了 Anthropic 的联合创始人之一,在 Anthropic 的可解释性研究中也通过 Transformer Circuits 的文章等
崔胜准 持续不断地延续了下来。不过我一想到 Chris Olah,其实最先想到的是和 RNN 相关的那些图示,在博客里直到现在我上课时还会把那些图拿来用。
画得非常干净利落。而且还能做一些交互式操作。我个人的话,TF.js 一开始是叫 Deeplearn.js,后来改成了 TF.js,这段代码在 AlphaGo 出来后让我挺受冲击的,因为它算是我勉强还能看懂的实现程度,所以我把这段代码贴在墙上,像背书一样反复看。backprop 是怎么做的,该怎么处理。所以那时候刚好也是我孩子出生前后,我记得自己背着婴儿背带来回走着看这个。然后接下来这个是 16 年,正石你能讲讲这段故事吗?听说当时在 구캠,也就是 Google Campus Seoul,有过这样一个活动。
深度学习框架的演变:从 Theano 到 PyTorch 31:04
卢正石 对,我没去。其实那时候 Eric Schmidt 也来过 Google Campus,TensorFlow Korea 的聚会也在这里办,随着 AlphaGo 的出现,Google当时非常强势地站到了社区的中心。所以我记得 Jeff Dean 那时候也来过,
不过我没去。我当时去过,不过其实已经记不太清了。当时来了非常多的人,我记得的是,大家那时候对 chatbot也已经很感兴趣了,但 Jeff Dean 在我印象里对 chatbot 好像没那么感兴趣,像是说过一句“chatbot 那有什么难的”,
李珍元 我大概还记得是这种感觉的回答。不过这时候其实还是 AlphaGo 前后那段时间,再早一点吧。因为 AlphaGo 是从 3 月 9 日开始的,所以就是紧挨着之前,而 TensorFlow当时其实大家用得最多的还是叫 Caffe 的那个,但 Caffe 毕竟是学校开发出来的 framework,而 Google 这次是正式下场来做这件事,
所以当时大家对 TensorFlow 的关注度非常非常高。我会想到 session、feed_dict 这些术语。
崔胜准 对。说到这些工具名,Andrew Ng 课程前半部分是要学 Octave 的,也就是说得拿它做练习,
那算是 MATLAB 的……
卢正石 有点像开源版。对,开源、自由、GNU,也就是 GNU 版本。总之就是很吃力,但还是硬着头皮做下来了。我也记得,如果想跑 DeepDream 之类的,那时还得用 Caffe 或 Theano 这些。当然,DeepDream 的 TensorFlow 实现后来也出来了,但如果想做一些衍生的东西,还是得折腾这些。我刚刚看了下时间顺序,Torch 是 2002 年,Theano 是 2007 年,Caffe 是 2013 年,Keras 好像还比 TensorFlow 稍微早一点。Keras、TensorFlow、PyTorch,
崔胜准 大概就是按这个顺序出来的,我看了一下。其实 Theano 可以说是 TensorFlow 的前身。
李珍元 很多开发者后来也过去了。不过真正方便很多,还是等到 PyTorch 出来以后,我记得那时候确实感觉更轻松了。
卢正石 对。其实到 2016 年左右,
已经是 PyTorch 和 TensorFlow 双强格局逐渐固定下来的时候了。
崔胜准 现在还有人在用 TensorFlow 吗?我都不太清楚了。
卢正石 是啊。我自己也可以说基本不怎么用 PyTorch 了。这么一想,我上次跑 PyTorch其实也已经是很久以前了。这几年里,也就是偶尔在 Google Colab 上弄点什么,
崔胜准 差不多就那样,真要说正经做过什么,已经没什么印象了。
卢正石 对,我大概也是 2020 年左右之后就没怎么碰了。所以说,当时另一个很有名的人是金圣勋代表,那时候他还在香港科技大学。所以也是他在讲《大家的 Deep Learning》这类课程的时候,而这正好是 2016 年初,这归根结底我觉得还是 AlphaGo 冲击带来的连锁反应。大家被 AlphaGo 震撼到了,觉得必须认真了解这个,于是形成了那种一起学习的氛围,后来 Facebook 上还建了 TensorFlow Korea 的 Facebook 群组,
崔胜准 也办活动,甚至一起去济州岛开 workshop 之类的。我当时也在这个 TensorFlow Korea,现在改名叫 AGI Korea 了,Facebook 上已经换了名字,我那时也是 TensorFlow Korea 的运营成员,里面有很多很有意思的事。而且 TensorFlow 这个组织,虽然严格来说不太能算 user group,但不管怎么说也有那种性质,如果把它算作 user group 的话,那它是全球规模最大的。所以实际上在 Google 的一些活动上也曾被专门介绍过。一开始大概是 Google Korea 的权顺序
和金圣勋代表一起做起来的,后来很多人也一起作为运营委员参与进来了。还有生活 coding 的 egoing,和 TensorFlow Korea 一起。当时感觉 Facebook 时间线上总能看到这些内容,那个社区确实是很有活力的一段时期。不过我当时还看到一个挺有意思的博客,
David Ha 与创意编程:社区留下的痕迹 35:45
崔胜准 那会儿有个有点神秘的博客。就是这种风格的博客,这样一路往下翻,上面会发一些用 machine learning 做的,有点像 media art,
也有点 creative coding 风格的东西。有这么一个人一直在发这些内容。然后这个人用的名字 otoro,意思就是金枪鱼大腹,我当时还经常去看那个叫“金枪鱼大腹工作室”的网站之类的内容,里面会看到很多用 TensorFlow做的创作作品。这类东西当时也很多,这个虽然视觉上不算特别惊艳,但在这些已经发表出来的作品里,让我印象比较深的是早期创作中有一项,是把汉字里原本不存在的字造出来这个在当时还挺有名的像这样去创造出世界上不存在的汉字他做过这样的作品。
不过说到这个人是谁,他原本在金融行业,后来接触到 Processing 之后离开了,学习了像 Processing 这样的东西,然后把自己的作品这样发布到网上的人是谁呢,他现在是先后待过 Google,如今担任 Sakana AI 代表的 David Ha。我记得我也曾在 David Ha 的网站上看过很多有意思的东西,并从中学到不少。
李珍元 在讲这个之前,其实有件事我挺想先聊一下的,感觉这跟胜准最有关系,其实在我还把这叫做深度学习的那个时期,虽然现在某种程度上也是这样,但当时读论文的时候,我就经常会强烈感觉到这个领域特别追风口。只要大家觉得这个方向效果不错,像 AlphaGo 那时候,大家对强化学习就投入了非常多的关注,就那样一波一波潮流不断流动的过程中,其实从某种意义上说,在现在 diffusion generation 之前,有个叫 GAN 的东西当时特别火,有段时间几乎所有论文都在往那个方向涌。胜准你当时也有实际用过那类东西的经验吗?
GAN 的流行与生成式 AI 的开端 37:01
崔胜准 是的,是的。和 GAN 相关的东西,我虽然没能完整实现出来,但确实是认真钻研过的,而且在那时候 NeurIPS 还没这么叫,
还是叫 NIPS 的年代,这类讨论真的特别特别多。
李珍元 有意思的是,在 Ian Goodfellow 的 GAN 论文故事里,不是有那个酒吧酒吧,对。去喝啤酒的时候,
因为啤酒太难喝了,于是就在那儿想到了研究点子,有这么一段轶事。
崔胜准 就是在 generator 和负责判别的 discriminator之间,让它们彼此竞争的那个思路,
也火了很长一阵子。不过那个出来的结果里,确实有很多特别神奇的东西。现在回头看,那算是我们第一波生成案例了。像 image-to-image translation,还有 text-to-image translation,包括 DCGAN 之类的各种 GAN,分支好像也特别多。我那时候正好在做时尚相关业务,也记得曾经拿那个
卢正石 来做风格生成之类的事情。把用 AI 做出来的东西真正发布出去的时候,像 StyleGAN 这样的东西
崔胜准 也曾被用上,我也记得有过那样的时期。是个叫 Refik Anadol 的艺术家。不过在当时看来,虽然确实很新奇,但整体评价还是觉得这东西还没到能真正拿来用的程度。
Clubhouse 时代的 WeeklyArxiv 与向 Transformer 转折的关键点 38:52
卢正石 那时候更多只是觉得神奇而已,感觉居然还能做到这些。Clubhouse 那个时期,大家没法见面,所以就有很多在线聊 AI 的房间。后来,现在已经成了首席的河正宇博士,不是还做过 WeeklyArxiv talk 和闲聊那样的活动吗?我记得是在 Zoom 上办的。我自己也以嘉宾身份参加过一两次,在 DALL-E 刚出来的时候。说起来,这个也和珍元有关系吧?
李珍元 对,这个也是我一开始启动的时候,和现在的河正宇首席一起当 moderator,当时我们在 Clubhouse 上不是总把 moderator当成一种流行说法来用嘛,
我当时是作为固定 moderator 参与的,那时候每周一次,轮流聊当周出来的 AI 论文
还有 AI 新闻之类的内容。Clubhouse 本来就是那种形式嘛,谁都可以举手上来发言,没什么要说的又下去。感觉当时玩得还挺有意思的。
卢正石 我们刚才一下子突然往前跳了 18 年,一下就蹦过去了,但其实在 2021 年 HyperCLOVA 出来之前,有个事件我们一定得提一下,
Transformer 与 Attention 的起源:从 Bitter Lesson 的视角看 40:02
卢正石 那就是 Transformer。Transformer 我们之前已经讲过太多次了。
而且哪怕只看到 2016 年左右,
那时候好像正是 attention 刚出来、开始兴起的时候。
崔胜准 attention 最初其实也是先从图像那边开始,后来才转过去的。当时有像 Show, Attend and Tell 这样的论文。也就是说看着一张图,去生成对它的描述时,会考虑该把 attention 放在什么位置,类似这样的研究。再往后一点的话,2017 年的 ImageNet,其实 2017 就是最后一届比赛了,当时夺冠的网络叫做 Squeeze-and-Excitation Network,那个其实也是在 CNN 里,图像会这样一层层堆成 feature map,它学的就是该对其中哪些 feature map 做 attention。其实当时大家并没有把它叫做 attention,但后来回头看才发现,
李珍元 原来这其实也是 attention。说到 Transformer,我自己也有很多记忆,那篇 Transformer 论文标题就叫做 “Attention Is All You Need”,其实从标题开始就挺吸引人注意的。而且那时候我经常挂在嘴边的一句话是,深度学习界三巨头就是 OpenAI、Google DeepMind 和 Facebook。也叫 FAIR。那种说法我当时经常反复提,而就在 Transformer 出来的前后,Facebook 还发过一篇叫 ConvS2S,也就是 convolutional sequence-to-sequence 的论文。所以在那个时候,
RNN 最大的缺点就是所有东西都只能按 sequentially 的方式,以前面的结果为基础 auto-regressive 地往下做,换成现在 LLM 的说法就是,哪怕 prompt 需要并行处理,也还是得先处理前面的词,才能继续到下一个词,所以为了克服这种缺点,大家就很渴望能够提高 parallelism 的算法。而 Google 提出的是 attention,我们不用 RNN,只靠 attention 来做。而 Facebook 则说,我们只用 convolution 来做。这有点像一场竞争,虽然结果是 Transformer 活了下来。后来人们会这样解读这件事,
说到底,CNN 也就是 convolution,其实是加入了 bias。人们把图像里的局部信息聚合起来,再把 layer 一层层堆起来,那个叫 receptive field 的东西就会变大,从而在全局范围内汇总信息,这其实在 scale 的层面上也体现了 Bitter Lesson。说到底,当 scale 变大之后,更通用的模型 Transformer 性能会好得多。
卢正石 你们第一次读 Transformer 论文是在什么时候?我感觉珍元应该是一出来就读了。
李珍元 对,我是一出来就马上读了。
崔胜准 我倒是打开看过,但没看懂。我也是打开看过,但没看懂,
卢正石 其实我是到 2020 年才真正理解 Transformer。从 2017 年到 2020 年那段时间,我也没有特别认真地持续关注 AI。
崔胜准 我是从 2022 年初开始想认真研究 Transformer 的。要说起这件事,也会勾起一些回忆,
李珍元 其实 2017 年这篇论文刚出来时确实很轰动,但说实话,谁也没想到后来会发展成今天这样。不过真正让它开始爆发式增长的,在我看来,第一个契机,我个人感觉是从 BERT 出来开始的。2018 年 Google 也推出了 BERT,其实 GPT 比它还更早一点出来,那时候是 GPT-1。GPT-1 的性能并没有那么好,而 BERT 这个东西,这种 encoder-decoder 结构最大的缺点是,它本来是翻译模型嘛。那 Transformer 就必须始终有正确答案配对才行。如果要把英语翻成法语,就得需要已经翻译好的数据,但 BERT 不需要那个,只拿 encoder 来用,通过制造空格再去填空的方式来进行训练。这就相当于做了一种非常强大的 self-supervised learning,也就是人们常说的那种方法,从那时开始,海量数据在不需要标注的情况下也能使用,所以 scale 才开始爆发式扩大。所以即便是在那个时候,就连 BERT 也是,
BERT 的出现与 GPT decoder 的扩展性:通往 LLM 的道路 43:14
李珍元 大家都会说,这东西太大了,到底该怎么训练,成本又高,如果要在云端使用的话,我记得当时大家都在讨论这些。而 GPT 则完全相反,是 decoder 方式,现在的 LLM 基本上全都是 GPT 这种形态,其实当时这两派之间竞争也很激烈,后来回头看,最终还是 GPT 赢了,但如果事后再来想这件事,BERT 是 encoder,而 GPT 是 decoder,两者最大的区别就在于,encoder 会从前面的词也向后面的词做 attention。因为它默认所有输入都已经给定了,是在填中间的空缺,所以它会同时看前后文来判断。性能自然会更好,毕竟连后面的词也能看到。
GPT 则始终只能看自己前面的词,去预测下一个词,所以在数据量较少的时候,性能必然会偏低,但它有一个巨大的优势,那就是,如果把词看作是一个个逐步追加进去的话,encoder 必须从最前面的词开始,把所有计算重新做一遍。但像 GPT 这样的 decoder,因为它始终只看自己前面的词,所以前面那些词对应 token 的计算没必要重新做,最后就能以现在这种 key-value 的形式拿来用,只需要为这次新生成的词新增计算,就能完成所有事情,在扩展性方面,它拥有一种完全没法相比的结构优势。所以结果上就是通过这样的过程,才一路发展到了今天的 LLM。
卢正石 到了 BERT 时代,当时真的冒出了很多公司。刚才珍元提到的那个最大的 BERT,我记得好像还不到 1 billion。
李珍元 是的。对,但即便那样,当时大家也都说这已经大得惊人了。还有个有趣的地方是,
因为 BERT 本身也是 Sesame Street 的角色名,所以那时候一度很流行用那类角色名字来给论文命名,像 ELMo 也出来了,在韩国我记得还有一篇题为 뽀로로 的论文。是有这么回事。
卢正石 对,我记得当时很多公司想拿这种 BERT 类模型来做 QnA,或者做那种填空,拿这些模型去做真正可落地的服务。有点像现在聊天机器人很原始的版本。用户提问后让它回答,或者判断这个对不对,做 evaluation,或者针对质量之类的内容,判断它是正面还是负面,做这种 classifier。实际运行效果是相当不错的。但在完成度这个层面上,总是在最后差那么一点,而且以当时的成本来看,做这些东西非常贵,所以那时候那些想拿 BERT来做某种服务的公司,我印象里基本都经历了不小的困难。
崔胜准 这可能是一种历史规律。
卢正石 然后大家的兴趣也稍微冷了下来,觉得这 AI 虽然很神奇,但就是做不成,那种印象当时也很普遍。那时候也有人说 AI winter 又要来了之类的,接着就是,当初 BERT 刚起来时,那些砸钱投资的公司回报也不理想,就是那样一个时期,
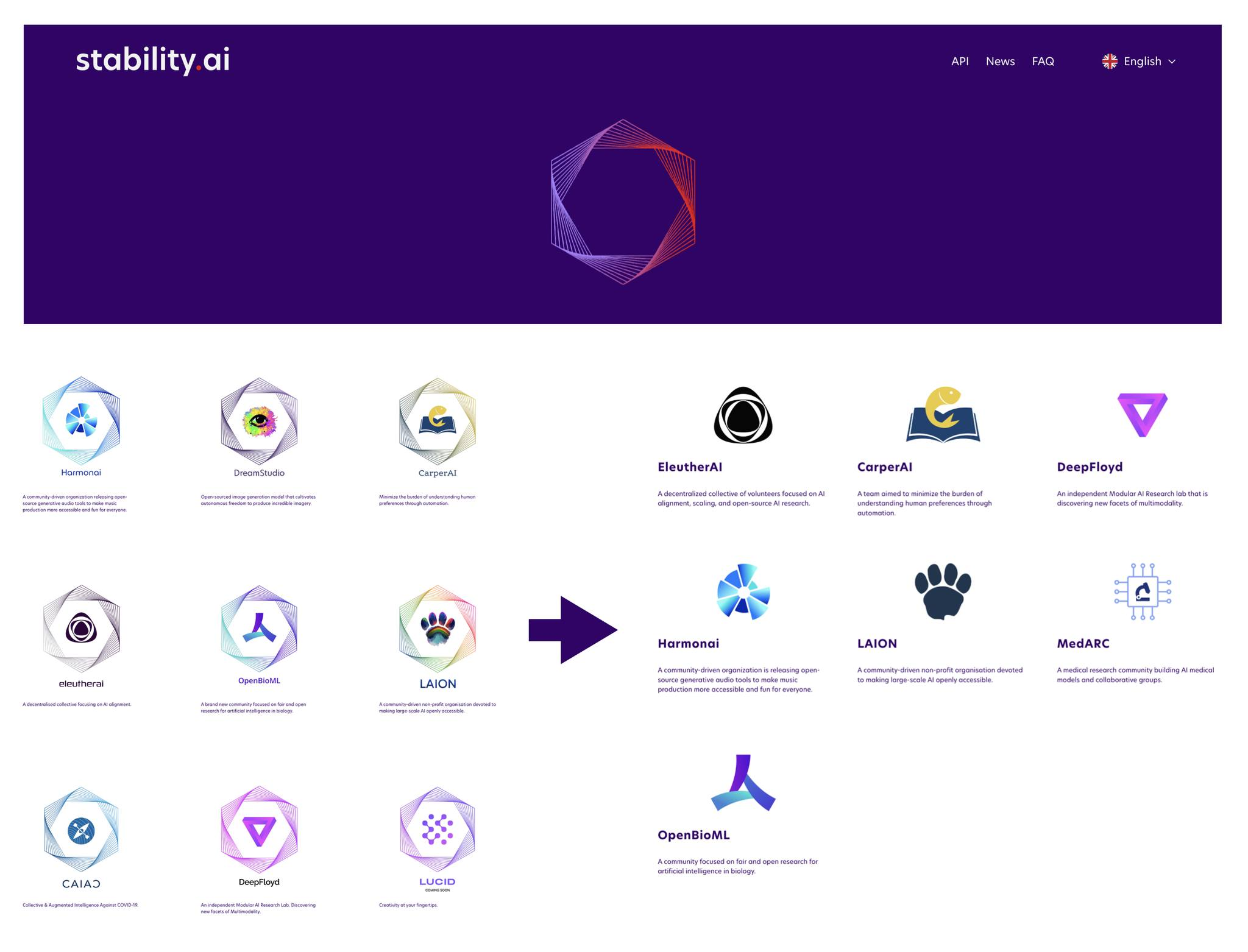
崔胜准 我觉得聊聊那个时间点的事应该会挺有意思。22 年的时候,Stability AI 很火。Stability AI 靠着 Stable Diffusion 一举冲了出来,在 Stability AI 这把伞下面,聚集了各种社区,像 Eleuther、LAION 这些,当时都有一种群雄并立的态势。不过这里有意思的是,
Stability AI 社区与韩国的 foundation model:HyperCLOVA 47:30
崔胜准 像 LAION 和 Eleuther,最近韩国有位叫凯文高的人,就是最近加入 Upstage 的那位,在做开源活动的时候也为这个社区做出贡献,还做过一些有意思的项目像 Polyglot 之类的还有就是,不知不觉间有一天回头一看 HyperCLOVA我当时还说韩国也在做这种东西两位不是更了解这里面的背景吗?
我已经找到了 NAVER 在 2021 年发布 HyperCLOVA 等内容时的AI NOW 资料。不过那是在 2020 年就已经做出的判断吧。是看到 GPT-3 出来之后,觉得该狠狠干一笔大投资了大概是那个时候做出的判断吗?
卢正石 对,算是 NAVER 先投了一步。我记得当时买了很多 A100。对,然后就推出了 HyperCLOVA。现在其实已经过去太久了,相关的 metric 之类的这些我都记不清了,不过当时的 GPT-3虽然也谈不上真的好用但以当时的标准来看,已经是令人惊叹的新鲜事物了。AI 终于会思考了会说话了,还能通过 few-shot 学习,像人一样回答问题这些东西都已经展现出来了。我是韩国人,如果问独岛是哪国领土
李珍元 它会回答是韩国的;但如果设定成人物是日本人它又会回答是日本的,这种回答方式在当时真的会让人觉得,这都能做到?我记得当时这种感觉特别强烈。
崔胜准 不过不管怎么说,韩国当时已经有 HyperCLOVA 了我那阵子也正好在时间线上一直发一些 LLM 学习内容还有在 OpenAI Playground 里做过的东西发着发着他们就联系我了所以在对外试用这件事上我也曾作为早期参与者活动过一阵子。当时还有这些事刚才也提到了 Stability AI
所以总之,我们也得拥有自己的 foundation model。
其实这段期间 Kakao 那边也发生了很多事吧。所以 Kakao 那边也在做模型还出现了 Tunib 这样一家公司也有拆分出来独立的总之围绕 LLM 做模型这件事韩国这边那段时间也一直都在积极推进,不是没做。现在独파모里提到的
李珍元 LG AI研究院当时也很努力在做,虽然最后掉队了我也记得 KT 当时同样做得很积极。随着它的影响力变得越来越大
人们对未来发展可能性的感受也越来越强各国就都会担心,这东西会不会变成一种战略资产,以后会不会像军事武器那样也会出现这种不安感。所以我觉得,这也是为什么后来会开始认为即便我们自身还存在不足也必须拥有自己的技术和模型
Vision Transformer 与数据规模的瓶颈 50:40
李珍元 这件事很重要。突然想到一个过去的点,顺便说一下在 Transformer 这条发展脉络里就像我们前面一直说的那样一开始是以计算机视觉这边的 ImageNet 为首那一侧的研究更活跃而且人们毕竟看到可视化的东西时更容易产生直观感受所以如果说计算机视觉这边曾经有过更多活跃的研究和成果的话那么通过 Transformer大量的重心又转移到了自然语言这边可在那个时候也开始出现一种动向,说那不如在计算机视觉里也试试 Transformer,随着 BERT 出来以及 GPT-2、3 相继出现,这股风潮就起来了最后还出现了所谓的 Vision Transformer而最先把这个做出来的,果然还是 Google。几乎所有这种先驱性的技术,Google 都发布了很多有意思的是,2017 年,刚才说是 6 月来着?Transformer paper 发布的时候。可是 Vision Transformer 论文是在 2020 年 10 月才出来的。这中间的 gap 非常大。那为什么会拖这么久呢,倒也不是大家没试过其实做过非常多尝试,但最后基本都失败了我记得这篇叫 Vision Transformer 的论文是发在 ICLR 上的,而且那里会做 open review。所以论文公开时作者信息会被隐藏但那篇一出来,大家都知道这是 Google 的。
因为 Vision Transformer最后之所以能做成功,说白了就是喂了很多数据。没有别的答案,方法本身其实很简单,就是把图像切开做成 patch,再展开成向量后喂进 Transformer,但问题在于,要让它跑出性能要让它比原来的 CNN 表现更好就必须喂很多数据,而它当时是用 supervised learning 训练的当时的 ImageNet 数据总共大概有 1400 万张图。可 Google 手里有上亿级别的数据,也就是一个叫 JFT 的、Google 没有公开、只自己使用的数据集当他们把这种规模的数据喂进去之后就展示出了性能上升的曲线。而且大家看到里面写着 JFT 这个数据就知道,哦,这是 Google 的东西。所以那时候我又一次感受到
原来 scale 的可怕就在这里。所以说到这里,这个阶段也让我想到Stability AI 当时带来突破口的 Stable Diffusion归根结底并不是 Stable Diffusion 自身的技术而是原本那些人,现在先去了 Runway,后来又去了 Black Forest 来着?总之是分散到了 Black Forest 研究所。那两位核心研究者比如 Patrick 这些人做出来的基于 latent diffusion 的那套技术。其中还有一位韩国人道烨,刚才那个 PR
崔胜准 你们也一起做过吧。对,一起做过。对,然后
他先是在 Kakao,后来去了 Runway现在又打算重新创业,一提到这里我就会想到道烨,虽然我本人没见过他,但会想起这个人。
卢正石 而且那时候吧,Stability AI、Stable Diffusion 出来的时候还在 ChatGPT 之前呢。
那时候可太火了,大家都在拿它生成图片。不过现在再看 SeeDance 2.0 这种东西
崔胜准 感觉像是另一个时代。
卢正石 是啊,为什么当时会拿着那种东西那样做呢。
崔胜准 为什么会想去创业呢?对。是啊,我当时也围绕那个做了非常多 pipeline。
卢正石 是啊,现在这都已经是 Nano Banana 在做的事了。我这只是把 2022 年写在时间线上的那些内容都收集起来了。写着写着太多了,就放弃了,结果最后还是从开始用 LLM 的时候整理起来的。记得当时是按天各种都试着写过。我们的起点,
Podcast 回顾与重访 Man-Computer Symbiosis 54:18
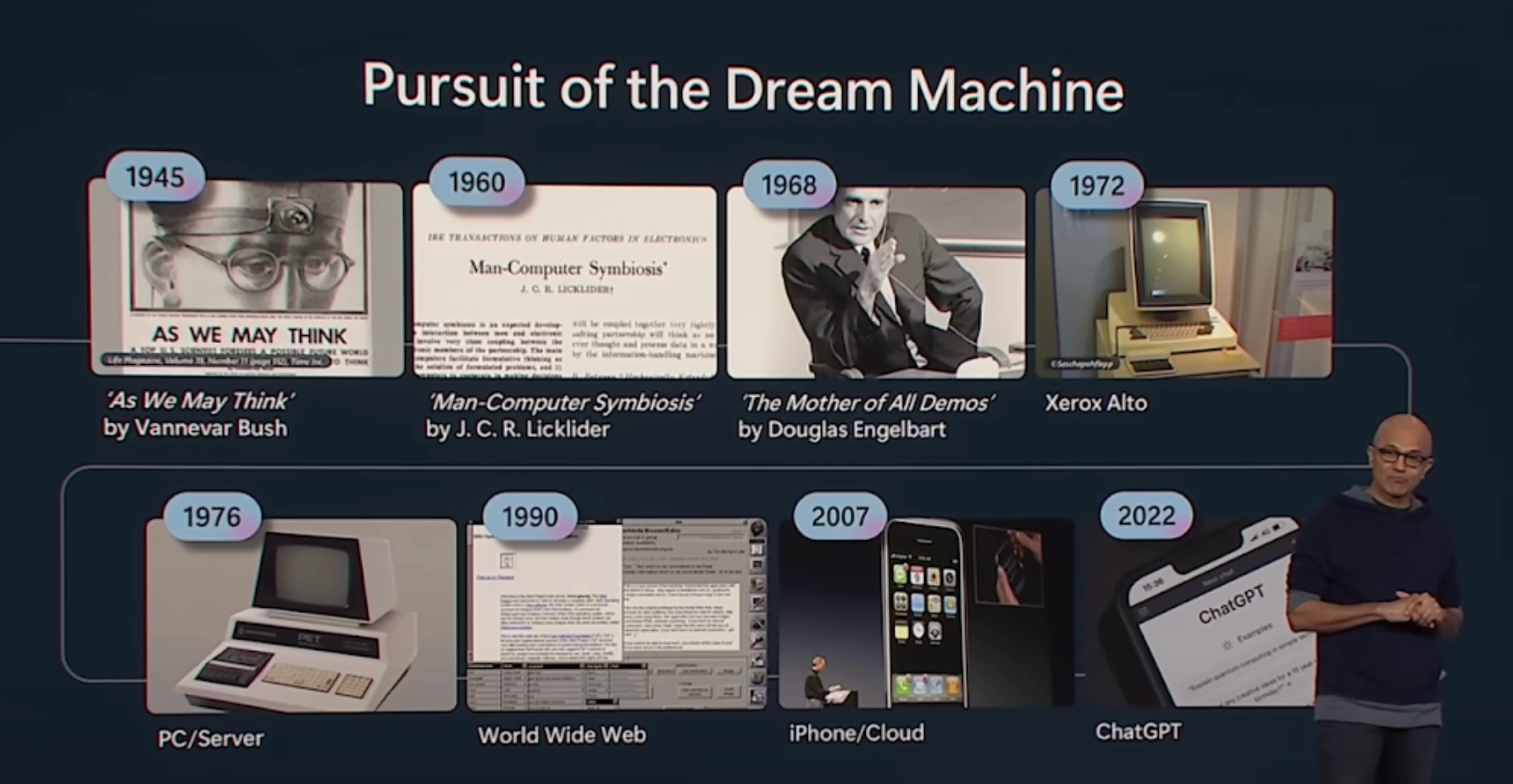
崔胜准 靠近我们播客起点的时候,第 3 期聊的就是历史和技术。所以当时 Satya Nadella在 Build 2023 的时候提到过这个。从 1945 年的 As We May Think 开始,到 1960 年的 Man-Computer Symbiosis,一路讲下来,梳理了是如何走到 ChatGPT 的,
我们当时也试着去读一读其中的意义,等我们的节目走到现在,差不多已经快 90 期了。不知不觉 3 年已经飞快过去了,这之后发生的事也都非常惊人。
卢正石 是啊,还在加速。
而且越来越快。所以我又重新回看了 1960 年 J. C. R. Licklider 讲的那个,也就是 Man-Computer Symbiosis 这个话题,所谓人机共生前面先讲它到底指的是什么,再往后看有一段像预言一样的文字,讲的是那会是怎样一个时代。所以我从这部分开始读。一个审视空军未来研发问题的跨学科研究团队认为,随着人工智能的发展,机器单独就能进行具有军事意义水平的思考或问题解决的时间点大约会在 1980 年。那么,大约还剩 5 年来发展人机共生,以及 15 年来利用它。这 15 年也可能是 10 年,也可能是 500 年,但那将会是人类历史上最具创造力、最令人兴奋的智识时代。我觉得这个预测虽然没有完全说准,但从方向上看,这的确很像我们在超智能出现之前所经历的时期,那会是一段充满创造力、
崔胜准 也令人兴奋的时代,这一点我很认同。我们把这大约 10 年的故事捋一遍之后,真有点适应不过来。说实话,我们已经活了挺久那种拿一周前出来的东西
卢正石 就能改变世界的时代了。大概从 2024 年、GPT-4 之后的这将近 2 年里,真的是一路狂奔过来,而且越往后越是被压缩的时代。所以当我们戴上关于这种速度的镜片,再去看更早之前,就觉得那像是非常非常久以前的事。现在还活下来的几乎一个都没有,当然,它们作为种子一路发展到了今天,
但还是会有种被压倒的感觉。2022 年以后,事件的那些点实在打得太密了。就算只挑大的来记,也还是太多了。再过一些时间,应该就能整理清楚。再过 10 年,到时什么才是真正的核心,我们现在像今天这样回看这 10 年,那些如今看来显而易见的重要事件
崔胜准 会被梳理出来一样,再过 10 年,这个时期的那些点也会更清楚。事后回看,洞察确实会更深。会怎么样呢?跟那些人聊天的时候,
加速变化与未来展望:验证难度 57:15
卢正石 一说到 3 年后,10 年太长了。问 3 年后会在做什么,这种话就经常会出来。说可能到时候正在领 Elon Musk 发的养老金。对,活都由 Optimus 干了,这些劳动也全都由 Tesla 来做,智力工作则全都由 frontier labs 之类的地方在做,
所以我们是不是只能领着养老金玩了。现在换个角度看,其实大家也都在做梦,想着在这个时期自己也做点什么,每个人都抓着一个方向,但这些东西到底能不能成功,好像已经有人开始怀疑了。觉得反正成不了,所以尽量晚点开始,越晚开始反而越有利,这种想法对某些人来说甚至已经成了 playbook。本来应该先动起来建立 advantage,结果不是,而是先冲上去当殉道者。你把东西做好之后,拥有比你更多 computing 资源、比你更多 market share 的家伙,啪一下就把一切都拿走了,
因为这种事也完全可能发生。我也经常会这么想,现在的先行者们提出某种方向,也让人看到原来这也能做,做这个会不错,只要把这种可能性展示出来,后面的大公司就会一拥而上把那个市场全吃掉,
李珍元 这种事好像一直在重复。但即便如此,也还是有人逃离了那些引力场,做出了服务。以前我们做 Web 2.0、做网页那个时代,最基本的问题就是,这东西要是 Naver 和 Daum 做了不就结束了吗,但后来移动时代来了,在新的 form factor 里,出现了新的 distribution channel,而当时那个新的 distribution channel说到底就是 App Store。借着那些并非韩国本土强者、而是更大的强者所创造的那种机会,
卢正石 整个生态也曾经被彻底改写过一次。而 AI 这一次,如今的强者又恰好是移动时代的强者。Coupang,Toss,Kakao,Naver,Baemin,这些中间层玩家也都已经站稳了脚跟,
但现在又一次 platform shift 正在到来。ChatGPT 和 Gemini 会不会成为控制所有用户信息获取入口的世界,会到来吗?会的。但如果说,不,不会那样,现在意见还是很分裂,就像胜准写的那样,这只是 timing 的问题,该来的东西终究还是会来,所以大家怎么准备,每个人的看法好像也都不一样。playbook 没有标准答案。
李珍元 这好像才是最难的问题。我也算幸运,到目前为止,在我做的领域里 AI还没能那么深地渗透进来。不过仔细想想,这确实也是 verifiable 的,因为做 verify 这个过程很耗时间,也很难。比如说如果要制造半导体,要判断这是不是好的半导体,虽然也可能有很多评估它的 metric,但连评估这些 metric 的过程本身都很漫长,所以现在数据也还有些不足,虽然有这些问题,但我一直都会跟我们公司的员工们有机会聊天的时候把“3年后我不会再做这份工作了”这句话挂在嘴边。然后我就会想那该做什么、该做些什么,还有哪些事情做了会比较好,想了很多,但到现在还是没找到答案。
接着又继续想,然后又有该做的事、眼前必须做的事情一股脑涌来,就又去做那些事,一有空又会去想这个,就这样一直反复。
卢正石 我觉得这大概就是所有人的人生。白天养牛,晚上学习,大概就是这样,刚才不久前我们逃跑者联盟题解班的
AlphaGo 第37手的意义与下期预告 61:00
卢正石 那些人在聊天的时候,珍元和胜准是在后面进来的,有个人不是说了那句话吗?“我就算失败了也不怕,因为有 Claude Code。”说是只要有 Claude Code,随时都能东山再起,大家当时都笑了,我还记得。
总之,定义这个时代的价值生产,我觉得人们对于“价值生产”这件事的视角正在发生变化。并不是软件要结束了,而是软件的时代才真正全面展开,
只是做软件的人的时代结束了。技术本身我觉得倒没什么可担心的。
崔胜准 人更让人担心。对啊。那不就得慢慢适应吗?
是啊。总之,我们从在公开时间线上看到的Google DeepMind 和 Demis Hassabis 这些文章,以及他们是如何看待未来的,从这些出发,稍微回顾了一下这10年。归根结底,AI 以及 Platform 37 这个含义,它并不局限于围棋,而是在各个地方都会发生那样的事,那种“第37手”般的时刻,会在各处出现,我在想它是不是在指向这个。我稍微这么想了想。虽然他们没有直接这么说,但我是从字里行间读出来的。
像第37手这样的事情,会在这个 domain、那个 domain不断发生,而 Google DeepMind 正在追求这个,其中他们正在关注的一个领域就是生物学之类的,我们其实只是看到了表面,那些我们至今还没真正处理的、此刻正在发生的,已经在发生的方向性,以及这些事情,之后也得慢慢聊一聊。不过我们今天还是特地想要
回顾一下这10年,因为那样的故事以后还会不断出现,所以我觉得在某个时点回头看看很重要,因此今天就把它定成了回顾这10年的时间。很有意思。珍元
又讲了很多我原本不知道的内容,真的很好。对啊。而且珍元今天虽然是临时请来的嘉宾,但很快我们会正式请他来一次,从 chip 的视角聊聊我们到底该怎么看待未来,像 gigawatt 和 chip 这些话题,
卢正石 不是说好了要来听一场吗?对,我今天也聊得特别开心,在这个过程中,所谓 AI infra,包括半导体在内的这些东西,也经历了非常多的变化、起伏和 challenge,现在也还在经历。下次找个合适的时间再来,一起聊聊这些话题应该会很好。
没错。说起来我今天早上看到Dwarkesh Patel 在聊天时也提到,这个 chip 和 100 gigawatt 时代会是什么样子,他也聊了这样的话题。到时候也可以围绕这些内容,请来专家珍元一起好好聊一聊。
崔胜准 好,很期待。今天很有意思。
卢正石 今天就先到这里,胜准和我们接下来大概也会试着转向别的主题。对于那些 one click away 的东西,我们自己如果一直维持这种大惊小怪模式,也会觉得太累了。我们也想把更多 weight转到 AI science这类方向上,正处在这样的阶段。我很期待。
OpenClaw 活动与结束致辞 64:02
李珍元 说到 one click,我也有很多感受,因为能靠 one click 做的事情变得太多了,要把这些全都覆盖很难,要全都追着看也很难,
从某种角度看,好像还会让人有点审美疲劳。大家好像都在一点点适应这种变化的速度。这其实就是在接受一种全新的速度。
崔胜准 但 hedging 不是一直都很重要吗?今天赛奥尼克不是还在办 OpenClaw 活动吗,
珍元不是也要去吗?
李珍元 对,录完这个我就马上出发。
崔胜准 至少得知道都发生了些什么。不过我觉得 OpenClaw 真的非常重要。对所有人来说,我们在上一期不是聊过吗,说每个人都会过上会长的生活。不管做什么,都会带着最强、顶级的秘书团队,哪怕只是做再小的事,如果世界正在朝这个方向发展,那么谁能把这支顶级秘书团队打造好,并最终以 assistant 的形态面向消费者,成为最末端、直接出现在我眼前、被我选中的那个 assistant,谁就会掌握全部主导权,所以大家似乎都判断 OpenClaw 在这里有很大的意义。
卢正石 大家似乎都是这么看的。
崔胜准 原来如此。那你这个周末又会过得很有意思了。
卢正石 对,我会去认真听一听。
崔胜准 好,那今天就先到这里。今天就先这样收尾吧。
卢正石 珍元,感谢你今天过来。