EP 96
LLM 推理基础设施与 Token 经济学
假期期间学习的 Dwarkesh 新一期节目 0:00
卢正锡 今天录制的时候是2026年5月4日,星期一早上。我们在这次连休期间学习了 Dwarkesh 的新一集。Dwarkesh 改了形式。突然拿来一块黑板,一边板书一边讲解,采用了这种新的形式。内容非常好。在当前这个时间点,我们
崔升准 是4月30日那集吧。对。我们花了大概三天学习这个,
卢正锡 到目前为止一直都在讲 training 怎么样,还有模型规模怎么样,基本都是这些话题,但其实无论是我们的 Claude Code 也好,Codex 也好,inference 的重要性不是变得大得多了吗?是吧。所以一跑代码,context 也必须放得非常长,
而且那么长的 context 还会不断变化,这样的 workload 也越来越多,期间 reasoning token 也会消耗非常多。
就连我也是给 GPT-5.5 开 x-high,再把代码放进去,这样推进工作,那个 workload 是相当大的。
所以让这些成为可能的现代推理基础设施。我们之前聊模型时讲了很多 training,但现在已经到了inference 比 training 重要得多的时期,所以 inference 到底是怎么发生的,我们有必要深入学习一次,而这次 Dwarkesh 的节目正好就在讲这个内容。
今天这些内容虽然相当难,但会很有意思,所以我们就试着把这些内容一点点拆开来讲,做成这样一集。
崔升准 那就直接开始吧。我们上周聊过 DeepSeek,
通过 DeepSeek 图表看上下文成本降低 1:38
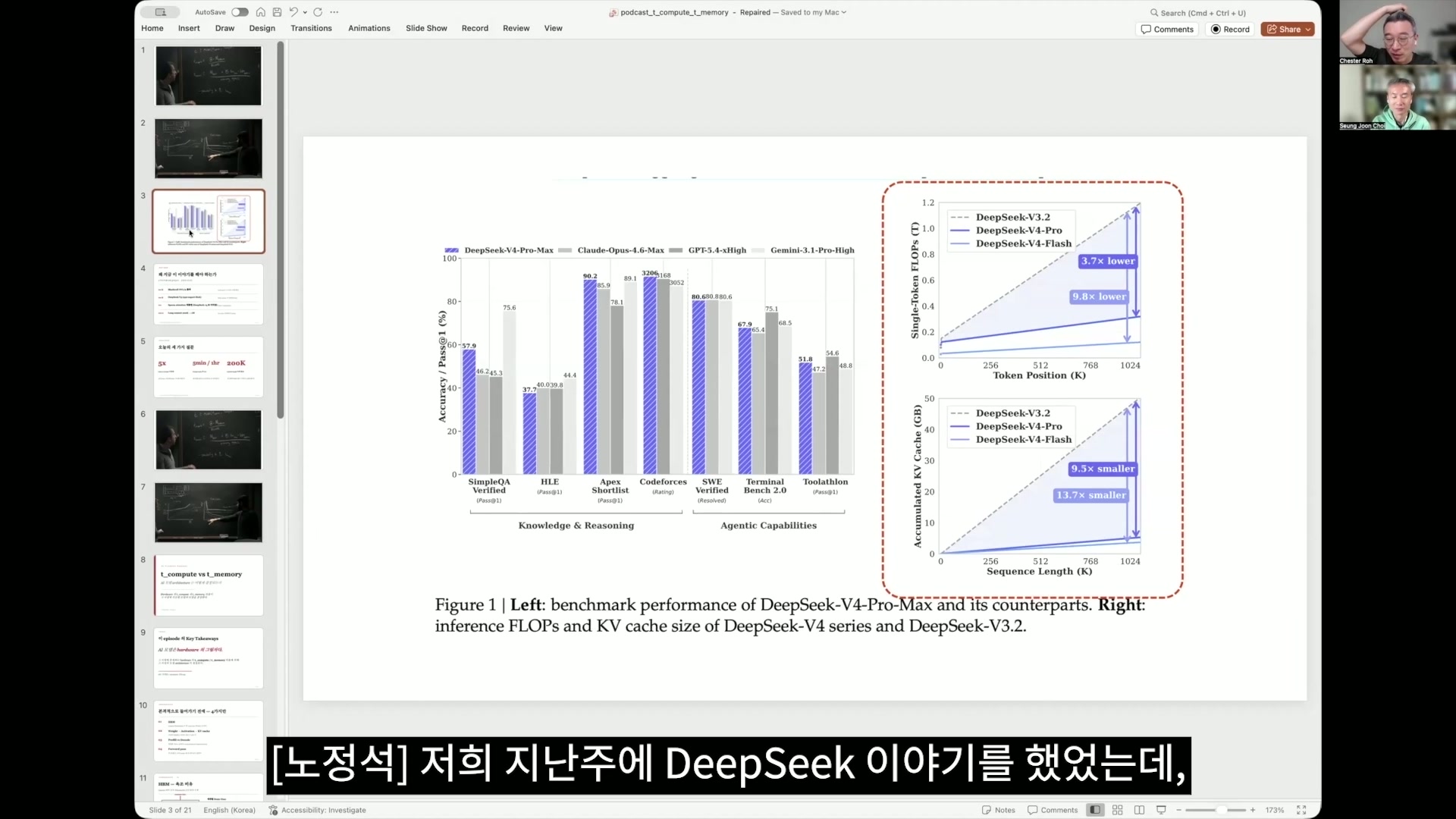
卢正锡 其实 DeepSeek 在论文第一页最核心提出的内容,不就是这个吗?右边这张图,我说过其实就是这篇论文的精华,上面是关于 computation 的内容,下面是关于内存的内容。简单概括的话,因为 token position 是 k,
表示的是从0到100万,最近各个 frontier lab都提供100万 token 的 context length,但其实100万是非常昂贵的 serving。所以现实中大多数情况下,我知道大概在20万左右会分出 tier,至于为什么会分这个 tier,我这次也明白了。而这个 DeepSeek,
在 computation 和内存使用上,即使 context 变大,也做得非常高效。computation 减少到三分之一,内存减少到十分之一,这在如今这个 agent 世界、agentic该说是什么 era 呢?在正在走向 agent 世界的这个时代,究竟有多大的意义,只要跟着今天这一集看下来,就能够理解。
以 NVIDIA GPU 和 HBM 为中心的服务基础设施概览 2:53
卢正锡 讲模型时,其实一提到 NVIDIA,大多数人都听不懂。对吧。虽然大家会说有 GPU,而且要有 GPU模型才能运行,Jensen Huang 每次都出现在这些活动上,把硬件都展示给大家看,
崔升准 还拿着到处展示。对。有 GPU 芯片,然后一说到芯片,
卢正锡 旁边总会讲计算单元增加了多少,速度变快了多少,紧挨着旁边的就是韩国最近正大受其益的HBM 贴在旁边,它们捆在一起,再和 CPU 捆在一起,成为一个机架,然后是 GPU 之间的通信,再然后是机架之间的通信,关于这些东西的基础设施,他们会一个一个全部说明,但我们并没有准确理解那些内容。今天我们就来聊一聊
这些内容。其实如果先把我们今天要讲的内容结论铺在前面,
Blackwell NVL72 与机架级内存扩展 3:52
卢正锡 这个 Blackwell NVL72 的 GPU 间通信,以前、过去最多只能到8个,现在变成了72个,而且单个 GPU 的容量其实就连 Elon Musk 在 Colossus 上部署的H100 或 H200,每个 GPU 的内存也不过是80GB、100GB左右。
但是现在正在推出的,从去年到今年陆续出货的GB200 或 GB300,内存有192GB的,甚至还有288GB的。而这些东西
在一个机架里有72个全部连接成一个整体,
崔升准 那是多少?大概20TB吗?大概20TB。其实这些都各自有其含义,
卢正锡 现在最新的模型真的非常充分地利用了这种硬件结构,甚至可以说模型架构也是由此形成的,它们之间就是有这种程度的关联,
崔升准 这就解释了为什么最近遇到的模型从4.5、4.6左右开始突然变了。这就能解释了。没错。从发布时间来看也是。
而且 GPT-3.5 是在2022年10月出来的,之后 GPT-4.5是在一年半到接近两年之后才出来,这期间 GPT-4.0 玩了很长一段时间,那是2023年3月吧。
卢正锡 对。当时我们不是认为它大概是1.8T左右的模型吗?还有 Claude Opus4.5 或 4.6 这些,按我们 Swyx 的说法,只是坊间传闻,谁也没有 confirm,但说它最大可能是1T到2T的模型,曾经有过这样的说法。可是现在突然出现的模型,动不动就是5T模型、10T模型,这种模型规模突然一下子变大了。
崔升准 是的。Mythos 是 10T,然后大概 5T 左右的模型现在应该已经在 serving 了,这样的推测很多。这些事情为什么现在突然发生了呢。
卢正锡 这件事突然反复出现,是有原因的。所以 Dwarkesh 和一位叫 Reiner Pope 的Google 硬件出身的创业者出来,
Reiner Pope 演讲与今天的路线图 6:09
崔升准 原来是做 TPU 的人。一边在这块黑板上板书,一边给大家解释。
卢正锡 所以今天我们会跟着那块黑板上的几处板书内容走一遍,最后也会谈到现代的LLM serving 架构到底是怎么运转的,他们到底在玩什么样的游戏等等,我们也打算跟着展开聊一大段。今天这一集的内容
所以可能会让人感觉相当难。不过各位如果只是想使用 Claude Code或者类似这样的东西,只是单纯想拿来用的话,这一集的内容可能不会特别有趣。但是 NVIDIA GPU 的出货时间,以及接下来模型出货时的
架构,还有这些东西如何显示未来,都是先行指标。没错。这不只是 NVIDIA 自己的事情,
崔升准 因为竞争对手也不得不做类似的事情,所以我感觉这大概会成为读取
当下时代状况的一个指标。今天我们就来聊聊这个。
token 价格表与缓存价格的意义 7:22
卢正锡 所以为什么我们在用 Claude Code,还有跟各位聊缓存优化这些话题的时候,会很自然地用到这些说法。
input token 和 output token 之间有价格差异,而且这个价格差异有些地方差不了多少,有些地方则差很多。
DeepSeek、Gemini、Anthropic它们的 pricing scheme 都不一样。
这个也不同,然后缓存也是,有 5 分钟缓存、1 小时缓存,它们的价格也全都不一样。甚至你去看 Gemini 这类东西的话,context length 到 200K,也就是 20 万以内还算可以,但超过 20 万之后就按另一个价格档位收费,也有这样的价格表。到底为什么会有这些东西,
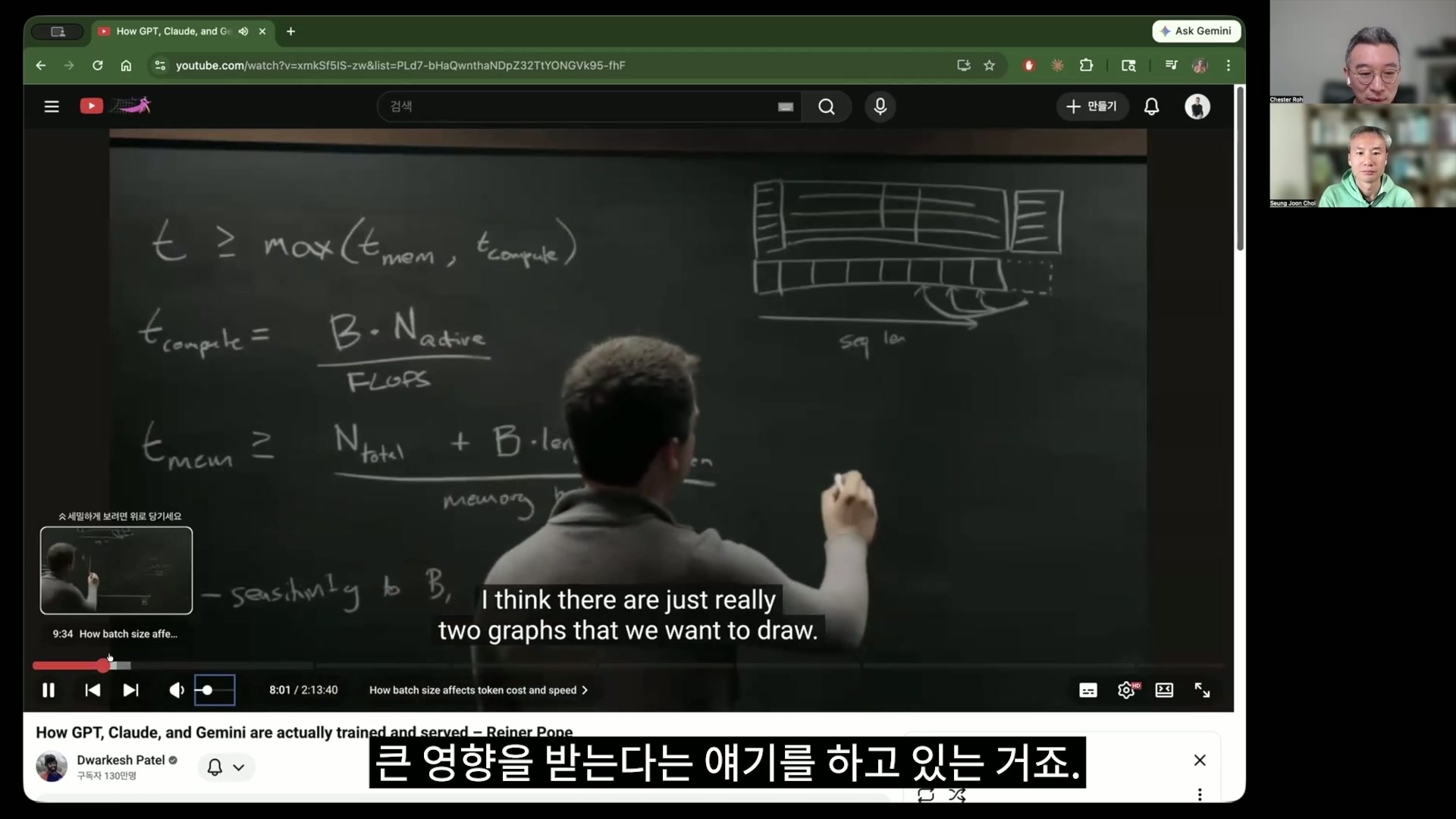
最新的 LLM serving 架构和硬件以及这些东西之间究竟有什么关系,今天我们想来了解一下。解释这些问题的内容就出现在这位先生的这段板书里,这段板书的内容待会儿我们先把基础讲一遍之后,再回来看看这个 T_compute 和 T_mem,以及这些东西为什么会这样构成,我们到时候再了解一下。
所以他们会用这个公式推导出这张图。最终就是每个 batch size 所花的时间,
以及每个 batch size 产生的价格表,看着这些价格表,其实刚才前面提到的这些问题都可以得到回答。
所以核心关键词是受限于 T_compute 和 T_mem。
崔升准 这里的 T 是什么?是时间吧?时间。计算所需要的时间,
卢正锡 以及 recall 这段内存所需要的时间,由这两者的组合决定了现代 LLM inference 的所有价格。今天我们想聊的就是这样的内容。所以 AI 模型是硬件的影子。
推理基础术语整理 KV cache prefill decode 9:19
卢正锡 因为模型这样发展,硬件也会朝那个方向转变,而因为硬件已经是那样了,模型也会为了 fully utilize 它而发生变化。今天的内容是不是有点难?
胜准,其实我们在做节目时,一直尝试过很多次,想把 transformer讲得更容易理解。但这件事实在不太容易。
总是会牵涉到 HBM,接着是 transformer 的基本结构,在其中 attention 和 fully connected layer,dense block 到底意味着什么,KV cache 的话题,到处都有人讲,但那东西到底是什么,然后 prefill 和 decode 是什么,以及 forward pass 是什么。
但幸运的是,推理无论如何都比 training 容易。
崔升准 因为我们不会去讲 training。
卢正锡 大家就从这一点获得一点安慰吧,今天关于推理,我们只讲到 forward pass。backward pass 其实是 training 的内容,那个我现在也不想看了。在所有现代架构中,到底要怎么用铺好的这些 MoE 和 sparse attention来进行 training,这个我现在也实在不敢打开去看了,所以就先讲到这个程度吧。那么,胜准,我们关于 transformer 的话题再讲一次好吗?
Transformer 运行流程与 KV cache 复用 10:49
崔升准 我觉得需要从大的结构上说起。
现在我们会深入到这里面,不过在把握整体图景时,为什么要讲这些呢,不只是 IT 领域,其他地方大概也一样,只要有资源,就会倾向于把它尽可能榨出来。不能让它闲着嘛。所以这类内容后面也还会再出现,
总之我先讲一下跟 transformer 相关的东西。
整体来说,如果我们写了某个 prompt,它就会成为所谓的 prefill,然后一次性并行地全部计算完,在并行计算的时候会生成 KV cache。我稍后会说明。如果 KV cache 在这里生成了,
完成之后,就会在最后那个 token 接续下来的那个向量上推理下一个 token,它又会回到输入,这里的箭头就是这样画的。然后继续 decode。所以把已经 prefill 的部分
和之后逐个 token 进行 decode 的阶段区分开来思考,可能是很重要的。所以这个真的得讲得非常简单才行,
卢正锡 其实如果能理解 prefill 和 decode 的概念,说实话就可以毕业了。是这样吗?不,我是半开玩笑说的。从第一次听到这个的初学者角度来看,
如果这个概念能让您有感觉,其实就已经很优秀了,我是想表达这一点才这么说的。只是为了帮助理解,我再简单说明一次,您也请补充评论一下,胜准。我们在 Claude Code 里说“喂,帮我看看这段代码。”然后突然把一千行代码啪地塞进去的话,
崔升准 对。就得做 prefill。对。那东西进入 transformer 之后,
卢正锡 为了让这个模型吐出下一个 token,不是得先做准备嘛。对吧。做这个预先准备的过程,就可以理解为我们说的 prefill。而且这个 prefill 大部分可以粗略理解为和很长的 input token 有关。
崔升准 还有用户输入的东西也会被 prefill。因为是用户 prompt,所以也是一样的。输入就是那个。
卢正锡 没错。因为是长输入,所以 input token 一定会被 prefill。所以它会进去,而那些被 prefill 的 token也是 token by token,每一个 token都会各自计算一次 QKV。但是在 QKV 里,Q 用一次就丢掉,KV 则越往后,后面的 query token就越需要看到前面的所有 KV。所以可以理解为它们会一个个全部存起来,这样想应该是对的。
所以待会儿我们会再更仔细地看,但刚才您说的内容里,transformer 有很多个 block。DeepSeek V4 好像有 61 个来着。
没错。上周我们看过的就是这个,所以每个地方、每个 token都会附上 KV。所以如果输入有 100 个字,每 100 个字在一个 layer 里都会附上 KV,到下一个 layer 又会附上 KV,可以大致理解为这 61 次里,每 100 个字都会全部附上 KV。没错。
崔升准 数量会变得非常庞大。
卢正锡 我们待会儿看 transformer block 的时候也会讲到,其实 token 一旦被输入,它会经过长得一模一样的东西,这也是 transformer 的魅力,就是把长得一模一样的 transformer block 重复 61 次,让 token 穿过去。胜准刚才说的就是这个,然后 output token 是从最上面的 block 取出来,再把它转换回 token。对。最后生成出来的东西现在要返回出去,
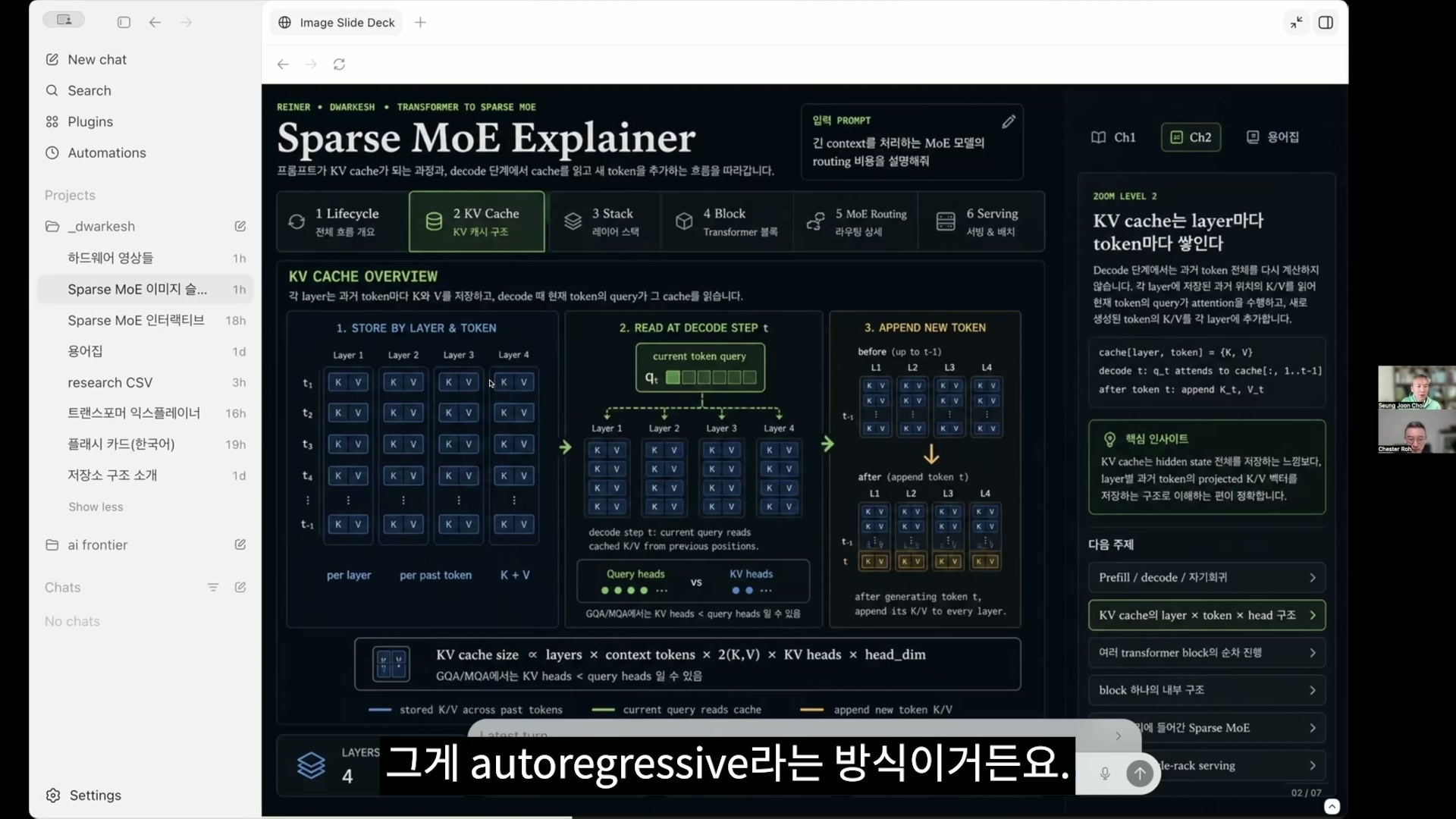
崔升准 这就是 autoregressive 这种方式。细节部分可能会花一点时间,但这个 transformer explainer 网站做得非常好。比起用 3D 来看的版本,它解释得更容易理解,GPT-2 也会实际运行。我点了一下,做了一个韩语版本的说明。
卢正锡 哎呀,是 Codex 帮您做的吧。所以 transformer 讲的就是这些,这里用 GPT-2 Small
崔升准 现在想给大家展示一些例子。所以现在来看,Q、K、V 即便是针对一个 token,也会以 multi-head 的形式附上,并这样生成出多种东西。但这个太细了,所以先到这个程度就继续往下。所以 “Data Visualization Empowers Users to”但是 Empowers 可以被拆成两个 token。它是可以被分开的。token 和单词有点不一样。大致上可以笼统地当作单词来想,嗯。好,我们来跟着看一下。
tokenization token ID vocab size 概念 15:29
崔升准 所以下一个最有可能出现的 token 是什么,我按一下按照指令生成。那么那个就会这样被计算出来,所以 create 后面要来的单词现在被预测成了 comma。概率是 21.17%。所以经过这个过程,
comma 又回到输入里,然后再生成下一个。所以如果再生成一次,就出来了 manage。这里有各种候选项,所以这就是在 prefill 之后不断重复的过程。所以现在的 prefill,就是这一整段一次性这样把 QKV 计算出来的过程。再稍微仔细看一下,这里有个叫
embedding 的东西,它的 token ID 是固定的,然后会把它转换成向量。所以会像那样。
卢正锡 token ID 是什么?token ID 通常在 GPT-3 时代,
崔升准 大概有一个 5 万个 vocabulary 的词表,实际上会被 tokenization 的Empowers 会变成两个 token,em 是 795 号这个 ID,这是固定的。powers 是 30132 号,就是这样固定的。这个 ID 是固定的,所以一开始总是会被分配同样的东西,但向量化之后,沿着内部 residual 流动时,上下文混进去,就会变得不同。
卢正锡 那么那个 token 可以理解为每个单词上附着的一种序列号,然后我们常说的 vocab size,就是这个模型拥有的词表里有多少个单词,是这个意思吧。对。不过重要的是,后面我们也会把 token 和
崔升准 hidden space 混在一起说,state 实际上会被向量化,所以这个向量我们会称为 hidden state,也会叫 embedding,会混用好几种说法。不过那个我会根据上下文再说明。总之,对每个 token
都会产生向量,这一点很重要。还有 positional 有点难,
所以快速跳过去,总之它会注入与位置有关的信息,那个会经过一模一样的 Transformer block,正如刚才正石所说,以 GPT-2 为例,会这样一直存在。所以现在是在展示还剩下几个相同的东西。
因此它会不断通过这些模块,计算应该往哪个方向走,最终应该输出的东西应该往哪个方向走,相关的计算就会进行下去。而且在所有层里都会生成 QKV,KV 会被留下来。为了之后再次计算。所以 query 是从这些 prompt,
Attention causal mask 与 KV 压缩技术 18:29
崔升准 从 token 生成出来的一种提问的感觉,而 key 和 value 实际上是从知识中很多时候会用 soft search 这个概念来解释。不是精确地去找 key-value,而是比较 soft 地去寻找信息的那种感觉。所以各位在看这个的时候,
卢正锡 如果想理解 QKV 到底有什么意义,就会变得很难。这是 Transformer 的作者在想“这些 token 输入进来以后,要让它们在内部计算彼此之间的关联性,应该怎么做呢?”的时候,他们在结构上做出来的一种 bias。所以 token 输入进来以后,
就把它拆成 query、key、value 全部进行计算,然后规定 QKV 就按这种方式来计算,当然其中哲学上的意义肯定是有的。
但它就是这样设计出来的一种 inductive bias,大家可以把它理解成某位作者的设计。不要问为什么它这样之后
就会变成 query、key、value,
我们先跳过去吧。不过这个动画挺有意思的,我们来看一下。如果仔细进入 attention 来看,它会像那样对所有 token 彼此之间计算某些东西。所以就会产生上下文信息。但这里之所以呈现三角形形状,是因为在 prompt 输入未来内容时,这个先跳过。causal mask 要解释起来有点难,对,直接跳过吧。当然只能看前面的东西。
因为未来的 token 还没有到达,那个三角形的东西就叫 causal mask,有这么一个东西。是作者做得很好的设计。不过所以这种东西会以 multi-head 的形式存在,
崔升准 旧式 Transformer 和现在 Transformer 的区别是,以前会把这种 KV 全部留下来,现在压缩它又变得很重要,这个以后再说,以后再说。
卢正锡 对。这里面有非常多厉害的技巧,而且最近
崔升准 MLA、sparse attention,这些都是。没错。
卢正锡 我觉得它的终极形态,就是上周讲过的 DeepSeek V4展示过一次终极形态,我们先这样理解然后继续。对。因为数量会变得太多。
MLP 与 MoE 结构 sparse MoE 直观理解 21:06
崔升准 从存储角度来说。然后接下来这里是 MLP 部分,通过 attention 之后,也会叫 FFN,也会叫 MLP,会通过一个非常小层级的 hidden state,hidden 大概有一个,也就是有一个 hidden layer 的 MLP。有时也会是一个或两个,所以这样一来,在那里,从感觉上来说,
某种信息会由这些正在输入的向量以提取的规模来看,MLP 的 weight 比 attention 大得多。所以这里面会有更多东西,
这个部分就是和 MoE 连接起来的部分。对。那个 MLP 部分以前是一个大的 block,
卢正锡 所有东西都要计算,用的说法是 dense。也就是很密集,全部都要计算,而 MoE 就是把它拆开了。
崔升准 所以现在像 sparse MoE 的情况,上周讲 DeepSeek V4 的时候,是 384 个里面大概 activate 6 个那种,
卢正锡 数字我忘了,但实际上是相当大的数字,而且非常 sparse。对。
崔升准 所以这在今天也会多次重要地出现。这样就会有多个候选项,这里可以看到logit 这个概念,logit 最终就是在变成某种概率之前的东西。所以会出现一些分数,再把它们转成概率,在大概 5 万个词表里决定哪个会成为 token,所以这时不是向量,而是重新变成 token,那个 token 连同 ID 回到最开始之后,再次变成向量,这就是所谓 autoregressive 的方式。所以放进 input 的东西,多个单词可以一次性处理,
卢正锡 但接下来预测下一个单词,就只是预测下一个单词,必须先出来前面的一个,才能叠在它上面,再去要求下一个单词,对吧。而且好的想法是,前面的 KV
崔升准 已经全都计算好了。可以重复利用。query 会针对新生成的那一个 token 重新生成,但其余的就使用已有的东西,再把新生成 token 的 KV 合并到那里,就是以这种方式进行。这里 top-k、top-p 就跳过。所以到这里为止,我们把 Transformer非常 quick 地
卢正锡 没错。Transformer 大概就是这样长的。单词进来以后,把单词拆成并转换成一种叫 token 的东西,它只是我们所认知的hello 是几号,什么又是几号,这样的标签,为了把这个标签放进模型里,还会加上某种 position,并经过 embedding,转换成模型能够理解的向量。单词会这样。然后现在我们
其实把那个叫作 token,它进去以后经过 attention,而且在 attention block 里有一个重要概念叫 KV cache,然后从那个 attention block 出来之后,又进入 MLP block 进行运算再出来。对。然后出来的东西会这样循环,
崔升准 但漏掉了一个重要概念,就是 residual stream 的概念。本来是应该讲一下这个的,如果它一个个出来的话,会加到自身上,一点点更新含义。对。那其实是非常重要的部分。
卢正锡 是很重要的概念。
崔升准 所以这样一来,每到这个时候都会产生 residual stream。对于所有向量,也就是 token 变成向量之后,把 attention 得到的信息加到自身上,然后再把经过 MLP 的结果合并到自身上,所以会对所有 block 一直这样串联下去。对,是这样。
这其实是形成重要流动的关键。没错。这里图里看到的有 block 1、2、3、4、5、n,
卢正锡 像 DeepSeek 的话,它有 61 个 block。
崔升准 GPT-3 反而更多。大概有 90 个。原来如此。然后存在于那个 block 里面的东西,
卢正锡 就是 attention 和 MLP block,这两个是核心。还有我们最近看到的各种最新模型的架构变化,几乎大部分都是关于里面的 attention 要怎样更少占用内存,以及怎样让计算更快,接着就是 dense block 那里,要怎样把它做得更小,怎样让计算更高效。是的。所以这里还没有解释 LM head,
崔升准 LM head 总之是在最后,前面已经算了很多东西之后,对最后一个 token,也就是说只针对这个向量,用来推断下一个东西,也就是预测下一个 token会是什么。这个和下一页,大概就是把刚才您说的那个机制用图表示出来的。这里有加号的地方,就是把 residual 合并进去的部分。
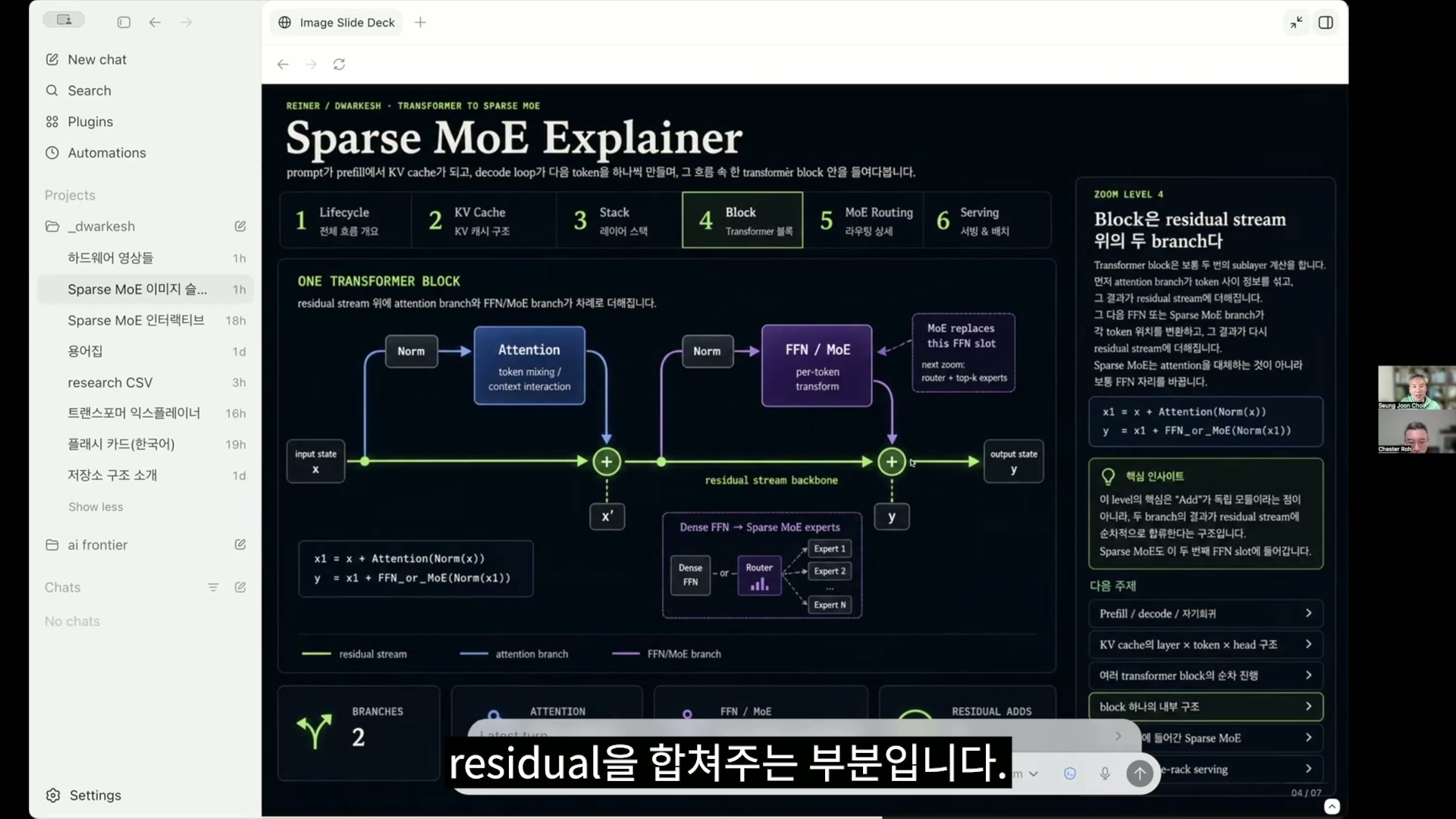
卢正锡 下面的绿色线就是 residual connection。
崔升准 就是在做残差连接。
卢正锡 现在这是在展示一个 transformer block。
崔升准 对。所以一个 block可以这样图示化。不过这里刚才说的 FFN 或 MLP,还有 MoE 这些,
因为现在需要把 parameter 做大,如果要大到能放进内存的程度,就会出现必须拆分的问题。这是今天的核心之一。我把那个做成了一个 interactive 版本,所以这是每个 token 或向量只会启用一部分 MoE。
所以一开始比如说只启用一个的话,现在我这里和实际不同,只让两个,在总共 16 个 MoE 当中,只连接两个。对这个来说,就是让两个某种FFN 或 MLP 运作。
然后对它们做加权求和,再连接到下一步。这样一个的话就变成四个了吧。不过有时候看起来
会出现不是两倍的情况。到现在为止都是两倍,现在 1、2、3、4、5、6、8。是两倍。
我们看一下别的 route。所以这时候是 1、2、3、4、5、6、7。因为是 7 个,
感觉应该会是 8 个,但变成 7 个,是因为有一个 expert。expert 被用了两次。
卢正锡 这里说 MoE,也就是 Mixture of Experts,很多人容易混淆的一点是,expert 这个概念叫专家,所以会以为如果我问数学,数学就由某个 expert 处理,问物理的话,某些东西就由另一个 expert 处理,于是觉得 expert 大概是承载不同知识的单位,但并不是这样。就算输入 “I am a boy.”,它也有可能分别经过不同的 expert。
崔升准 而且 token,刚才说每个 token 都会经过不同的 expert。它只是那样被分组而已。
卢正锡 所以如果问为什么会这样,我们也不知道。
崔升准 而且每个 transformer block 里都有很多个 expert。几百个。所以这一点也很重要。最后就是这些东西
机架内部通信 NVLink NVSwitch 与机架间瓶颈 28:43
崔升准 如何 serving 的硬件结构。通常叫一个数据服务器 rack。rack 这种形态到底长什么样,稍后我们会通过视频看一下。
里面有多个 GPU,而在一个 GPU 里面,把大概两个 MoE 放在一起会比较好。看最近的做法是这样。那样的话,它们彼此都必须连接起来,才能快速计算。这里面的计算通过 NVLink 之类的东西
会非常快,而且最近还有 NVSwitch 这种东西。是很快,但 rack 之间似乎会花更久,从硬件上看距离也更远。这个稍后我们会对 rack 的概念看一下,
卢正锡 其实在 rack 内部,GPU 之间通信很快,但一旦跨到 rack 外面就会变慢,所以在最快的网络内部处理肯定就是答案。
崔升准 而且这些 GPU 之间传递的东西,归根结底就是 tensor 之类的。activation 后的东西,或者类似的东西会相互传递,但因为存在需要同时并发地把彼此这样连接起来的问题,所以似乎需要那样的架构。那么先看 NVL72,刚才也稍微提到过,看那个视频,这是一个大概 2 分钟的视频。好,这展示了我们的机器是怎么制造出来的。
通过 NVL72 机架组成视频看数据中心 30:00
卢正锡 一张 Blackwell GPU 是由这两个 die 合在一起做成的。数字会很快地闪过去。

崔升准 那个黄色贴着的就是 HBM。是 HBM 内存。然后在两个上面,接上了一个。
卢正锡 两个 GPU 加一个 CPU。
崔升准 被称为 superchip。
卢正锡 而且 CPU 和 GPU 之间也连接得非常快。
崔升准 所以这就成为一个插槽了。
卢正锡 那么一个插槽里有 4 个 GPU、2 颗 CPU。
崔升准 也就是说,两个 Blackwell 配一个 CPU。
卢正锡 刚才是放入了用于通信的 interface 卡,所以加起来可以堆叠 72 个。

崔升准 然后这个是交换机,就是刚才在图里看到的那个。把那个插到 spine 上,最终关键好像在于能铺设什么样的高速公路。从物理上来说。所以这里一个机架,72 个,
卢正锡 装有 72 个 GPU。
崔升准 不过有个东西叫 InfiniBand。需要大带宽的部分,是为了像刚才那样连接机架之间,这个好像也叫 DC 交换机。然后那个是冷却管线。水冷式。所以 AI 工厂数据中心,
虽然感觉会像这样花费极其庞大的成本,但可以建出来。Blackwell 时代展示过,到 Rubin 时代展示的又再上了一个台阶。
卢正锡 是。所以还有一个视频,这个是在今年 GTC 上从头梳理这是如何一路发展过来的。
Video 2016 年 4 月 6 日,也就是十年前,我们发布了 DGX-1。里面有帮忙梳理的内容。
崔升准 大概从 GTC 1 小时 7 分左右开始。所以大家可以去看一下那个。也就是看看它现在发展到哪里了,这些内容。
Jensen Huang 热水,45 度,这会减轻数据中心的压力,减少所有这些成本、所有这些能源消耗。
崔升准 到这个程度,这也是 72 个。
Jensen Huang 它们使用 LPDDR5,LPDDR5,以及惊人的单线程性能。
崔升准 现在已经是 Jensen Huang 没法拿起来展示的程度了。就是这样。我们打造了
Jensen Huang 这个东西,让它可以和这些机架中的其余部分一起用于 agentic processing。到这里为止就是 Blackwell。
崔升准 所以就是以这种方式运行 NVLink。所以看完这个 Dwarkesh 的视频之后,我就又回去重新看 Jensen Huang 的 keynote 了。没错。
卢正锡 好,胜准,既然我们前面已经做了一些背景说明,那就开始今天的主要内容吧。我们这三天学习的内容,是 Dwarkesh 和一位叫 Reiner Pope 的人一起做的讲座。
通过 roofline analysis 拆解 LLM 服务时间 33:31
卢正锡 它讲的是这些 GPU 是如何 serving 的,用简单的公式,让我们能够从几个数字中读出隐藏在背后的那些含义的一场 session。这场 session 我们就跟着看一遍,一起梳理其中的含义。
他一边说要做 roofline analysis,一边展开说明。这位先生讲的是,我们最终不就是在 Codex 或 Claude Code,或者 ChatGPT 里写点什么,然后一按回车,就会有结果返回的那段时间嘛。但是那个结果也不是直接像一张 A4 纸那样
一下子“啪”地出现,而是 token 被 generate 的过程,
我们不是看得到吗?能看到 decode 的过程。对吧。那个过程有些非常快,
有些比较慢,当然现在整体水平已经提高很多了,但以前我们不是也经常见到很慢的情况吗?
崔升准 没错。而且第一个 token 出来的时间也会有微妙差异吧?对吧。不过这些东西,
卢正锡 到底内部发生了什么,他是在解释这方面的概念。但这个如果我们直接跳过去只讲结论,中间的内容如果不稍微跟着走一遍,会有比较难理解的地方,所以我们也一步一步跟着看。好。这里的 t 就是时间。
从 t_mem 与 t_compute 看 latency 决定因素 35:12
卢正锡 也就是说,所花的时间,是 LLM 这样生成某个结果所需要的时间,可以用 T_mem 和 T_compute 这两个来说明。所以内存时间和 compute 时间,受这两者中耗时更长的那个限制,这里好像是在说会被 bound。对吧。然后所以 compute 所花的时间是?他在讲这个。
崔升准 出现了 active parameters 这个说法。这个 compute 所花的时间,
卢正锡 其实我们刚才在 transformer 里讲过了。computing 的主要耗时因素,其实是计算 attention 的部分,以及后面的 dense 块,也就是叫 MLP 块、multi-layer perceptron 的我们传统上很熟悉的那种 neural network。这个名字容易让人混淆。
崔升准 有时候叫 MLP,有时候也叫 FFN,说的是同一个东西吧。
卢正锡 没错,说的是同一个东西。
没错,说的是同一个东西。现在说的是 expert。对吧。不过现在这两个块的计算时间之和,
对吧。不过这里在计算 T_compute 的时候,只计算了那个 dense 块。为了便于计算,这里的 compute 所需时间其实是什么?就是这个 parameter 的数量,乘以我们输入的 token 数量,对吧。对吧。输入的 token 我们是按 batch 来处理的,其实需要先解释一下batch 这个概念。也就是说,
推理 batch 概念与调度编排 36:46
崔升准 可以看作有点像 sequence length 吧?不过是多个人使用的 sequence length 之类的。
卢正锡 所以这里我们需要稍微区分一下 training 中的 batch和推理中的 batch。也就是说,training 中的 batch,是为了让我们一次计算多个句子,所以才使用 batch 这个说法。
崔升准 对吧。为了把 GPQA 一次跑完才那样做。为了一次跑完。所以如果有 batch,
卢正锡 一个 batch 里的 sequence length 通常在 training 允许的范围内,比如说是 4K、8K 的话,在那个范围内 sequence length 是填满的。对吧。所以通常在 training 的时候,如果看我们塞进去的那个 tensor 的 dimension,就是 batch,然后是 sequence length,再然后是 embedding,也就是我们称为 hidden dimension 的这三个相乘,
崔升准 d_model。对。这个是填满的。
卢正锡 所以 batch 乘以某个 sequence length,实际上就成了数据集的大小;但在 inference 的情况下,问题就有点不一样了。会怎么不一样呢?
崔升准 根据输入什么内容,生成的长度也不同,输入也不同,全都不一样,不是吗?没错。不过我们做 prefill 的时候,
卢正锡 多个 token 会一次性进去,所以一不小心也可能变成和 training 类似的情况;但 decode 的时候,前面这个 token 必须先进来,下一个 token 才会往前推进嘛。因此实际上输入的 token只有一个。
也就是说 sequence length只有一个。
所以从传统 training 的角度来看,假设 batch 是一个用户,有的用户可能只写一句“Hi”,有的用户可能直接在 Codex 里扔一个 50K 的 context,有的用户可能就只有一个段落,实际上 length,也就是长度,会差很多。如果说那也必须像 training 一样
填满那种 dimension,那其他部分不就得用 padding 顶上去吗?里面什么都没有。就空转了。对。那样会造成巨大的内存浪费,
所以合理的想法就是把 padding 全部去掉,然后全部接在一起就行了,不是吗?
对。这其实就是推理里的 batch 概念。没错。把这些接在一起,其实会有一段变得乱七八糟,
dimension、KV 之类的全都会坏掉嘛。实际上是这样。training 的时候,在一个 batch 里
按照连续放进去的 sequence length,KV 是精确 align 好的;但推理的时候,如果直接在一个 batch 里,把多个用户各自那唯一的一个,为了走向 next token 的那些 token 全部塞进去,KV cache 不就全乱了吗?
崔升准 细节我也不太清楚。因为这个会乱,
卢正锡 所以实际上 vLLM 或 SGLang 这类东西会放一个 meta layer,把这些全部匹配起来。所以只看结论的话,最终 inference 也是在一个 batch 里,我们现在正在使用的,也就是在一块 GPU 上,可以理解为有几千个人同时连在一起。
崔升准 那就需要 scheduler 了吧。那个,对,有 scheduler。
卢正锡 有 scheduler,也有 meta layer,它会记录“这个 batch 里第 100 个是用户 胜准,第 103 个 token 是 正石,某个 token 属于谁”之类的,它会持有这些 token 的全部 index,然后它通过 transformer block,经过运算出来之后,中间还得做各种 KV 运算嘛。对吧。而且这些用户的情况也都会不一样。
有的用户前面的 context已经用了 80 万 context,有的用户 context 可能是 0。
崔升准 cache 被清掉的情况应该也会很多,对。也有 compact 之后被清掉的情况。
卢正锡 不过最终前面的那个 context,因为就是我们前面说过的 KV cache 块,所以会有一整套 meta 去映射那些 KV cache 块。可以假设 meta layer,也就是 orchestration layer,都在完整运行。
所以 inference 和 training 里的某些 dimension 有点不同,熟悉 training 的人所想的 batch,和今天我们这里 Dwarkesh 所说的这个 batch,也就是 inference 里的 batch,我觉得必须说明它们是不一样的。这样做的理由很重要。
从某种角度说,这样做的理由可能是最重要的。
GPU utilization 与 MFU 的差异 41:36
崔升准 因为不能让那么昂贵的 GPU 空转。因为是很贵的资源,所以不能让它闲着。
卢正锡 因为不能让它闲着,所以每一个 step,每次跑 step 的时候,都必须塞得满满地跑。所以 GPU utilization至少要跑到大概 70% 到 80%,这生意才有赚头。MFU 是那个吗?
崔升准 Model FLOPs Utilization,那个不是有关系吗?
卢正锡 MFU 和 GPU utilization 应该看作有点不同的概念。MFU 实际上是 FLOPs,所以这块 GPU 能输出的,假设它完全跑满的话,
崔升准 输出最大的时候。
卢正锡 对。不计算 memory bottleneck 之类的,只是在计算本身做到 optimal 的时候,它能算 100,但现实中的计算做不到那样嘛。要等数据准备好,还要做各种事情,因为被 block 的东西非常多,所以实际上很多运算不是 compute-bound,而是很多时候会变成 memory-bound,所以 MFU 不可能全部用满。但把 MFU 和 I/O 这些都算进去之后,
只要 GPU 在转,就把它视为在运行的概念,我觉得这就是 GPU utilization。
所以在 training 或 inference 里,提高 MFU 数值当然是越高越好。然后他稍后会讲到,MFU 被 maximize 的那个点,就是如果 T_compute 和 T_memory 相等,那不就是 max 吗,他就这样简单带过去。
崔升准 先看成像这样相交的交点。所以我虽然用语言展开讲了一下,
卢正锡 但至少在 transformer 的 training 里,前面说过的 B、N,然后是model dimension,这个 tensor 的概念如果没有牢牢记在脑子里其实要一直理解这个,多少会有点困难,所以大家就当作是这样,然后先往下看就行。不过在推理中,
会把 batch 和 sequence 直接全部摊平成一个维度,就把它当成一列火车,在那列火车里同时装载多个用户的 workload。所以当一个 clock 啪地转一次的时候,
为了尽可能装载更多用户,可是那列火车里其实坐着非常多样的乘客。比如说那个用户
如果假设所有人都处在 decode 过程中,其实作为 input 放进去的 token 就只有一个,那么比如 batch 是两千个的话,就可以同时装载两千个人。嗯。如果只是稍微粗略地说,
崔升准 模型要不断对那些 weight 做矩阵乘法,而要做矩阵乘法的部分,就用乘客们的数据来填满,是这种感觉。必须一次性做完这个,而且不管是 20ms 还是什么,这个会不断重复,火车就一直出发,是这种感觉嘛。
卢正锡 把一个 clock 就设成 20ms,这个后面还会再讲到,为什么是 20ms,我们到时候再聊一下。最终就是要把火车填满,
把刚才的话收个尾,如果每次只放一个 token,两千个人也可以同时用,但比如有人在 Claude Code 里一下子塞进大量代码,需要 prefill 的东西有一千个,那其实那一千个就会被 prefill 占掉,然后正在 decode 的用户后面大概还能塞一千个人。
像这样,prefill 和 decode 的过程要以什么方式 optimize,这就是最近现代 LLM serving 几乎最核心的东西。
目的是什么呢?最终就是每单位时间的 memory 或 compute,
这些都要 maximize。utilization。可以说一切都是围绕着
怎么把它用满来设计的。好。那么先讲到这个程度,后面继续讲的时候如果又出现概念,
我们再一个一个来看。
所以 T_compute 说的就是这个。
batch,也就是要装载多少人。
为了方便,就假设是一个 token 吧。
那如果说装载两千个人,B 就是两千。
而 N_active 就是被 activate 的 parameter 数量。
这里这位把 MoE 的概念带进来了,其实 sparsity 的概念是,总 parameter 有这么多,但 MoE 的核心概念是,计算的时候只快速计算几个 expert,不是吗。
正因为如此,在 computing 上才会有效率。
崔升准 这也是扩大 parameter 总规模的方法,同时也是效率,对吧。
卢正锡 对。为了表达这个效率,所以这里的 T_compute是 batch 乘以这个 number of parameters,也就是被 active parameters 的 number 所 bound,他才用了这个表达。把它除以 FLOPs,也就是每秒能计算多少次,就会得到所需的单位时间,对吧?下面就把分母
崔升准 大致笼统地理解成 computing power 的话,
卢正锡 是在做这个假设。
崔升准 就会这样出来吧。对,是会出来。
卢正锡 所以当然这里漏掉了 attention 这一项,这个漏掉的部分,他只是为了方便,为了说明这种计算概念,先这样处理。不过 attention 里进入 sequence length 的那个 context length 变大时,attention 成本其实会升高,变小时就会降低。可是这实际上是很重要的点,所以我觉得还是得讲一下再过去。
事实上,即便这个很长,也都会切开再放进去。比如说我们需要放进去的
Claude Code 发送来的代码,就算有五万 token,也不会把那五万 token 同时放进去。也会把它全部切开,比如每一千个切一块,再和其他人的 decode token 全部混在一起装上去。
崔升准 也就是说无论如何都要填满。对,无论如何都要填满。
卢正锡 所以这些话题,Dwarkesh 也正好会问到。因为我们差不多已经把这部分都讲了,接下来我们就直接转到 memory 这边来看。所以这个公式
崔升准 现在好像是在写 decoding 的东西。嗯。
卢正锡 对,一边写 decoding 的东西一边往下写,但其实我们现在应该把这个放在这里,直接来看计算。那 memory time 是怎么决定的呢?第一是 N_total,其实呢,这里是 total。因为这个必须全部拿着,对吧。计算的时候,要把整个模型 weight 都加载到 memory 里,必须持有着。而 expert 的情况,只要计算被 activate 的 expert就可以了,所以compute 这边用了 active。对。计算的时候
内存时间模型:整体加载与 KV cache 成本 48:16
崔升准 只把 active 的那些 weight 拉出来用就行,但算 memory 的时候必须全部持有,是这个意思吧。
卢正锡 对。可是算 memory 的时候必须全部持有,所以用了 N_total,然后再加上这里,其实上面 attention 那里漏掉了,这里又放进来了。batch,再加上每个 batch 的 length 都不一样。如果 context 是 decode 的情况,那就是 1,然后如果有人正处在 prefill 的过程中,这个就会变得相当长,取决于那个,而这里再乘以每个 token 需要多少 byte,就会得到这个。对。这里其实我也先稍微
崔升准 我有点混乱,decode 的时候是 1 吗?归根结底就是前面已经 prefill 的部分再加上不断每次加 1。因为是 length。不是的。之所以不是那样,是因为那部分确实是胜准很容易混淆的地方,
卢正锡 实际上 decode 的时候进去的 token是在它前面,也就是紧接着上一步output 出来的最后一个 token。只有那一个会作为 input 进去。
崔升准 因为前面的 KV 已经有了嘛。
卢正锡 对。所以它作为 input 进去,实际上在那个 transformer block 里走这个 flow 的 tensor就是那一个 input token。
但虽然只有那一个 input token 进去,在每一个 transformer block 里,前面不管是 prefill 过的,还是前面的 decode 阶段,之前 context 的 KV cache block每个 block 里都会有。对吧。全都有。那是从 cache 里调出来的。如果它在 HBM 里,就会很快,
如果不在 HBM 里,就得去别的地方抓过来,不管怎样,它无论如何都要 loading 到 HBM 里,计算才能进行。因为做的是这个计算,
所以其实就像刚才说的,在一个 inference batch 里可以同时装进非常多的用户。因为在 decode 的情况下,只有一个 input token 会经过。
崔升准 对。也就是说会那样混在一起。
卢正锡 所以这就是复杂起来的地方,但用户们的 KV cache长度都会各不相同。有的人长,有的人短,诸如此类。KV cache 过一段时间就会消失,
崔升准 所以也会重新从 prefill 开始,把前面的输入全都抓一遍,再重新生成,对吧。
卢正锡 对。如果 cache 没有 hit,比如我说了点什么,按下回车,突然旁边有人叫我,我去吃了饭,一个小时后回来,实际上 cache 里就全都没了。那种情况下,其实就又是重新 prefill。对。要重新从前面开始跑 prefill loop,building KV cache,所以 input token 的价格那时就要重新计算,成本就高。
崔升准 对。就会变贵。但如果是从 cache 里调出来,
卢正锡 cache hit 了,就能便宜地拿到,所以成本会低,这些就是 inference 的经济学。但 KV cache 就像刚才说的,再回到前面,如果想象在一个 batch 里,把多个用户的那些每人一个的 decode token 放进去,一边往上计算那个 cycle,KV cache 的长度会因用户而完全不同。
崔升准 当然会。把这些不同的部分非常高效地处理,
PagedAttention 与 KV cache 内存效率优化 52:12
卢正锡 让它们大量放进一个 memory block 里,其实就是 vLLM 做出的名为 PagedAttention 的创新。如果没有 PagedAttention,
用户们的 KV cache 就会像我们 training 时那样,放进非常 static 的那些 tensor 里,空的部分只能用 padding 填满,这样就会造成很严重的内存浪费,但它不是那样做,而是按一个个 block 单位切分,就像我们用 pointer 把所有 KV cache分别在哪里全都标出来一样。所以随着这个运算越往上走,
它就会找到 KV cache 里的 page,负责把这些 token 全都计算出来。这些东西究竟要怎样
全部做成一个 vectorized 运算,可以说就是这个推理过程的全部核心。
所以在这段对话中间我还会不断提到,做这件事的目的是什么。
就是为了 maximize GPU utilization,可以理解为所有这些考量都是为此而做的,也就是说,如果不能在规定时间里把一块 GPU以那样的方式 maximize utilization,同时 serving 两千名用户,我们就不可能花 20 美元来使用它。我又开始好奇了,虽然待会儿肯定会讲到,
崔升准 现在 memory,也就是无论如何正在使用 HBM 的东西,既有模型的 weight,也有 KV cache,对吧。现在更多会用在哪里呢?
卢正锡 这里也需要算一下,比如我们刚才看过的最新 GB300 通过 NVL72 连接起来的那个 rack,如果是那个,一个 rack 里
20TB HBM 中模型权重与 KV cache 的分配 54:03
崔升准 大概 2TB 左右?
大概 2TB 左右?不是。20。
20。对,20TB,一个。对。一个 rack 里的HBM 大约是 20TB,
卢正锡 而且 CPU 上还连接着 LPDDR5,全都挂着。那个 memory 的大小也大概是 20TB。
所以总计……CPU 用的?CPU 用的。
就是我们通常知道的 RAM,那有 20TB,总共大概有 40TB 的 memory,里面 storage 是不是 SSD,这个我不太清楚。
总之 storage 也……对。那个是要 offloading 的嘛。应该有吧。就当它有。但计算的时候,
一般不会把 storage 算进去。
崔升准 有个 Blue 什么的。我忘了。(NVIDIA BlueField)这样算的话,memory 大概有 40TB,
卢正锡 HBM 里通常会把我们的 weight 全部放上去。可以假设那 20TB 实际上是为了让我们做 deep learning 运算而存在的。
崔升准 那如果把模型直接按 FP8,也就是按 byte 来想,不是相当宽裕吗?现在。
卢正锡 对。是的。5TB,5T 模型就是 5TB。
如果像胜准说的那样,把 5T 模型按 FP8 来计算,它光是 fully 加载这个模型就会占掉 5TB 容量。对。那剩下 15TB。所以很多人
又会产生混淆的地方是,那是不是在那里把 4 个模型加载进去就行了?但不是。
其实这里也需要输入进来的那部分容量,而且每当那个 input 经过 transformer block 时,在计算 attention 的时候,其实对于那些 activation 的部分,都需要内存嘛。为了中间计算,要保存那些中间结果值,也需要保存那些被 activation 的 value,最重要、占用最大的还是 KV cache。
不管 context 是长是短,所有用户的 KV cache都必须拿着,所以 KV cache 会占掉很多空间,但这个要看怎么分配。这里实际上 batch 要取多少,以及给用户允许的 context length 要给多少,其实 KV cache 的数量就是由这些决定的嘛。
所以这些之间会有一点 trade-off,如果有大约 20TB 内存的话,5TB 会分配给模型,其实也可能比这个更小。因为现在用 FP4 会进一步压缩很多。所以在 20TB 里面,
大概会把 13、14TB 分配给 KV cache。然后大概 2TB 左右,给中间计算用的 activation variable。
但那些 variable 可以不断 overwrite,所以它们不需要保留那么多。
崔升准 不过我们好像把话题提前讲了一点,总之在假设一个 5T 模型的时候,其实假设 5T 这个模型本身现在就是问题。实际上我们现在知道的是,1T 到 2T 左右模型的 serving,而因为 NVL72 出来了,所以变成了 5T 左右,我们是这样推测的嘛。
卢正锡 对。事实上 training 过程即使不是这样,也有很多方法可以做,在 H100 或 H200 cluster 上,如果要训练 5T 模型,当然也有训练的方法,但这些大模型,其实在 H100 或 H200 这种内存比较小,然后像 NVLink 这样的 GPU 间通信非常小、node 数量又……到 2023 年为止也还是 8 个算 1 个吧。
崔升准 是 22 年还是 23 年,总之我觉得差不多是那个时候。
卢正锡 不会是到 25 年初为止吗?在 NVL72 出来之前。
崔升准 出来之前是 8 个。
卢正锡 是 8 个。但 NVL72 出来也没多久。其实。
崔升准 是 2024 年末。对。我们对这种发布时间、数字和
卢正锡 architecture 方面有点弱。如果正圭代表在这里,就会在这里一下子讲清楚,但现在我们两个人在艰难地学习,所以今天先这样跳过去。
所以归根结底,胜准说的点确实是对的。因为变成了 NVL72,所以在最新的现代某种 inference 环境里,有巨大的收益,大概这样说就可以了。我们刚才在讲这个内存,话题突然跳到了这里,重新整理这两个公式的话,必须理解这个,后面的东西才能全部理解。所以这个当然已经理解了吧?compute 已经理解了,
batch 对应的 latency 图表与 amortize 概念 59:07
卢正锡 memory 是 loading total memory 的那种时间,然后这里现在是loading context 所花的时间,把这些加起来后除以内存带宽。最终内存也是把这整个取出来需要时间。
崔升准 分母里面多少都有时间 term,因为这是在计算 t。刚才 FLOPs 也是 floating point 浮点数每 second 能计算多少,现在也是把带宽当作 byte per second,所以最终
卢正锡 隐藏着的秒
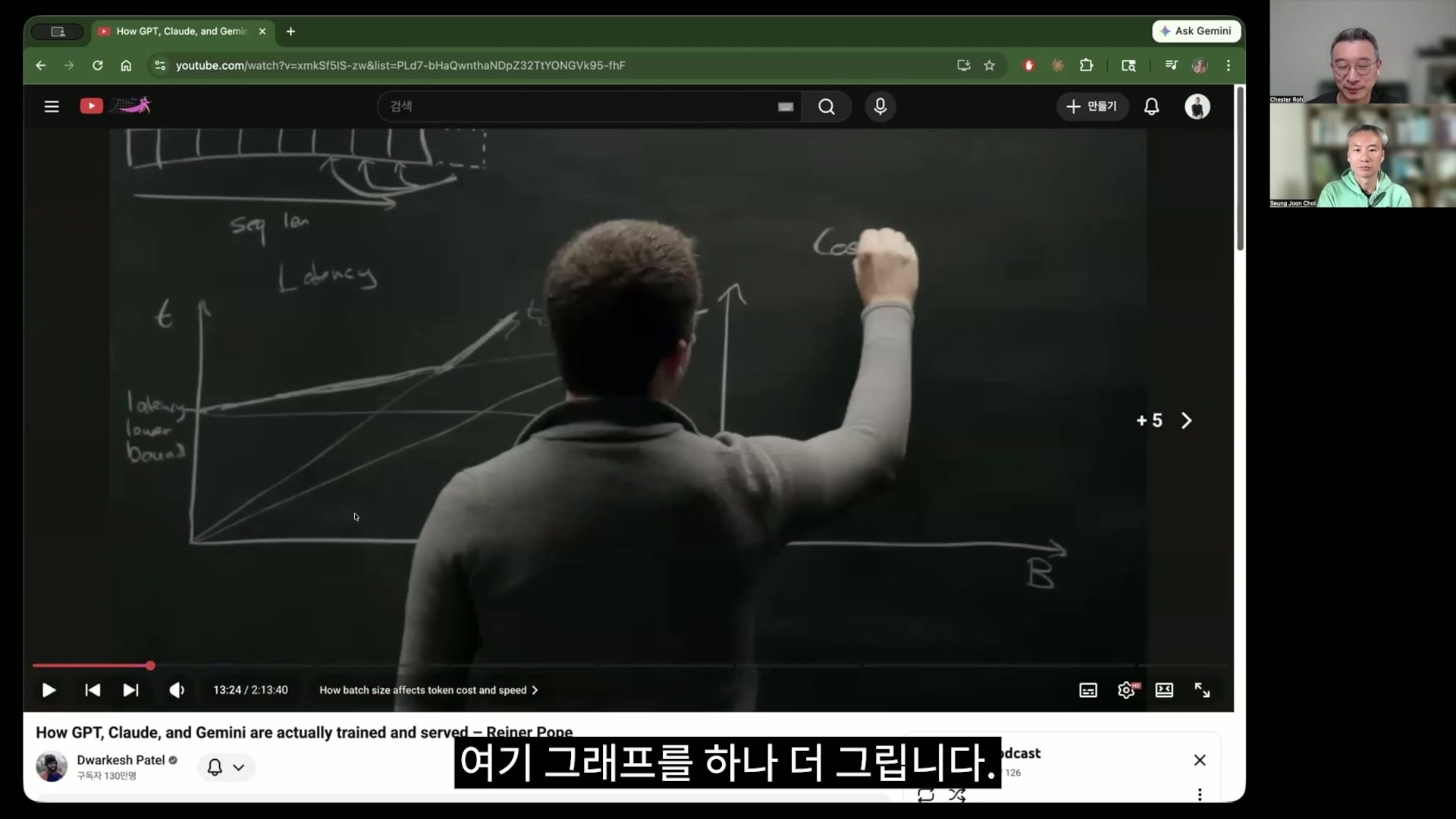
崔升准 会升到 t 上来嘛。是的。就是算术。所以上下的核心其实都是容量。所以最后会得到秒。所以要用这两个,来看现代 LLM inference到底时间卡在哪里。所以这里是在说,这个和 t_memory 会受到 batch 和 context length很大的影响。现在要继续往下看吗?所以这张图,我先把字幕关一下。画这张图对今天的理解非常重要嘛。右边的 x 轴是 batch,也就是每个 time 要处理多少用户,这个 batch size,以及因此花费的时间,它是在画这个函数。同时从前面的这些 term 里,我们来做算术。t_compute 其实会是这里 batch 的线性函数,所以它是这样画成线性的,然后在这个 memory time 里,loading total memory 的时间只要 loading 一次,之后就可以一直取出来用,所以这里包含了一个非常重要的 intuition。这个内存一旦加载上去,用得越久,其实就越能抵消当时投入的成本,这个表达会说 amortize,借用会计术语来说就是分期摊销,这种说法会经常出现。amortize 出现过好几次。然后接下来画的图,就是取 KV cache 所需的时间。但这个呢,batch 越长,loading KV cache 的时间当然就会越长,那为什么它画在 compute 下面呢。这只是这个人的主观画法。大概是在说这个 cache time会以这种程度增加。不过现在 N_total 和 N_active 确实不一样,只是粗略合在一起说了吧。对。就是粗略合在一起说。但是在 compute 里其实N_total 不会产生影响。因为 N_total 是内存侧的变量,计算的时候那个 total memory 对计算时间完全没有任何影响。因为只计算 active 的部分,可以把它理解为是在说这个。这样接受就可以了。那我们在这里把刚才这位先生的图调得更清楚一点吧。那里又不是乘法,而是加法,所以不管怎样。对。可是这里呢。这个,胜准,在继续之前,刚才 DeepSeek 那段里看到的东西,对这里影响很大,这个 KV cache time 和这个 t_compute time,这两个线性图,不是吗。对吧。其实用这个图的斜率,就能说明时间和成本。但问题是 DeepSeek 把它大幅往下降了。由于它降下来了,所有 frontier curve 也都跟着降下来了。那么交点现在也会降低,所以就会开始讲和它相关的内容。所以关于那部分,现在就会讲到。所以这个 compute 的蓝色图,来自刚才的 compute,而 KV cache 和单纯加载 total parameters 的时间,这两个线性函数,现在它会把它们相加。从常识层面来说,我也不太懂硬件,但 HBM 再怎么快,也不是 on chip,而是在 GPU 旁边嘛。所以会花时间。应该是这样。所以现在这些东西都进入成本里面了。太多东西交织在一起,我觉得这次 session 很好的一点是,它把硬件的样子,以及算法实际运行时到底在哪里咬合起来,激发出了这种火花。那么再回到这个图,虽然难,这是算术,但很难。所以刚才画的 t_compute 和 t_mem,它在这里用图表示出来了,刚才画的这个有点粉色的图,就是 KV cache 这个,以及这个 total parameters加载的 time,这两个单纯相加。两个相加的话,其实就会得到我们初中学过的那个东西。就会得到这个。实际上这就是 t_mem。而最终 t_mem,刚才最前面也看过了。我们感知到的 total time 是什么?它被这里 bound。它被这两个之中 max 的那个bound,结论就是这样。但那个折点就是 B 连上的地方吧,现在。对。那个折点会怎样,会根据硬件规格、模型形状等等全都改变。那么我们最一开始做的是,放一个 max 函数,说它会被两者之中更大的那个 bound,被 t_compute bound 和被 t_mem bound,它是由两者中更大的那个来 bound 的,现在看来那是由 B 决定的。所以为了说明好好决定最佳的 B 点是有意义的,才在讲这个。这里看的话就是这个。batch 小的时候会被 memory bound,对吧。batch 变大之后,就会被 compute bound,这样的 intuition 就出来了。意义就是这样。所以现在这个,实际上因为这是 T,那么 T 是什么?它说的是 latency。也就是说要等多久。所以这里即使开始某个很小的 task,加载这个 weight 的时间也会作为基础花掉,所以才说这是 latency lower bound。所以把它叫作 latency,也使用 latency lower bound 这样的表达,这个图就是 latency 图。再画一个。我们刚才做过的那些说明,会在这里讲。对 latency 感兴趣的人,中间我们讲的说明就是这个。像胜准和我刚才的对话那样,那么 attention 的什么减少了,那个就会减少吗,还是增加吗,我们讲了这些。这里再画一个图。cost,是每个 token 的 cost。就是这个。它是作为除法放进去了。对。最终这是把总时间除以 batch,所以表示的是处理了多少,单位时间内处理了多少。那么这个同样也是 B,x 轴保持不变,只是把这个图的 y 再换一下。是算术,是算术,但要好好跟上这个内容。前面那个 t_compute因为只是线性增加的图,所以这里就会直接拉成一条线,因为已经除掉了。这个大家可能不会理解。第一次看的朋友,从 batch 到 T,到 latency,我们正在讲的这些 term 可能进不了脑子的人应该也会非常多,所以不一定非得理解这个。重要的是我们只拿结论也可以,但为了拿到结论,胜准和我久违地把思考 token现在跑一遍。我们是在学习嘛。那么这里现在画一下。t_compute 在这里本来就是 linear,因为是这里的 B 除以 T,所以就会是一条直线,会变成直线,而 KV cache 比这个斜率稍微低一点,是 linear 图,所以会在下面变成一条线,然后这个 memory 在左边原本就是直线,把这个除以 B 会怎样?会变成这个 parabola。像这样一路下来,就会变成这样的函数。对吧。那么这里 t_compute 也是固定的,t_memory 实际上是这个 KV cache 和这个的和,那么在这里计算的话会怎样?当然很自然地,上面会再多出一条线。上面再多出一条线,实际上就是现在 t_memory 的 bound。用 max 来计算的话,这个确定的耗时,T 总是会在 compute bound 和这个 memory bound 中,被耗时更长的那个约束。被 bound,这本来就是最初出发的前提。但是有个类似的东西,虽然不完全一样,类似的东西,在 Jensen Huang 这次 GTC keynote 里好像也出现在 token economics 那部分。感觉很类似。不都一样吗?所以把这个直接算一下,就会变成这样。怎么算?这个 token 价格,这就是价格。现在纵轴变成了 cost。每个 token 的 cost。每个 token 的 cost 在 batch 低的时候会非常贵,batch 到了一定程度之后,就因为这个 compute bound,会变得更多。这里说的就是会被这个 bound 住。那么这最终就会进入下一页的内容,取决于把这个点放在哪里,就会出现 optimum。我这部分,后面这个说法真的是生平第一次听到。真的是生平第一次听到。原来可以那样计算啊,也让我意识到我们其实从来没有算过、想过这个事实。而理解了这个之后,其实 IDC 价格,投入那么多硬件成本,然后我生成每个 token 要多少钱,input token 每 100 万 token 收 5 美元,然后 output token 收 10 美元、15 美元,把这些东西算进去的话,frontier lab 的 inference farm 的某种经济性、良率,这些东西就有可能得到改善。这相当于是他们做了 reverse engineering,对吧,某种意义上。用价格来反推。对。对于做这些事情的视角,我也是这次第一次有了。所以才画了这张图。所以讨论这个的时候,他们说我们来算一下 batch 设成多少个才是最好的。但这个计算并不精确。我反复说过。他们也叫它 roofline analysis。就是拿着天花板上一条模糊的线,做一个大的思想实验,不是精确计算,这一点中间也说了好几次。因为后面做的时候,这个“不精确”会被算出来。那边开根号的部分其实也挺有意思的。那是 sparse attention 的部分。那个话题后面再简单讲一次。这里最终是在做假设。这个最终会达到均衡,而 maximize 这个 throughput 的点,就是 computing 的时间和memory 的时间相等的时候,这两者就能协调地配合起来,所以把 batch size maximize 到那个点就可以了。他们一边这样说,一边拿出一个简单的公式。这个去哪儿了,在这里。这个内存带宽和 N_total,是从这个 T_mem 里面把 attention 部分全拿掉,只拿了这个过来。attention 部分其实是非常重要、非常大的一部分,但为了方便计算,就直接把它拿掉了。现在好像把它们设成 equal 了。用等式。是啊。这个是 T_compute,这个是 T_mem 对吧。因为是相同的时间。对。memory time 这里本来有 B 函数在里面,他们把它拿掉,只是为了方便,把这两个设为等价。那这样就只是变成 equation 了。就会出现算术了。就会出现这个算术。这个加号移到下面,然后这样换一下位置。为了计算 B 值,这么一算之后,实际上就会得到被整体加载的参数数量中,被 activation 的参数数量的比例,这个不是在哪儿听过很多次吗。sparsity。对。这就是我们讲 DeepSeek 论文和 Kimi 论文时一直在说的 sparsity。而关于 sparsity,其实论文很多。至于它为什么成立,我也还没有理解,但把它加宽、把 total parameters 的规模做大,再提高 sparsity,就算让实际 activate 的参数变成少数,也会有性能上的收益,这是我们现在发现的东西。虽然像 heuristic,但应该有什么机制吧。只是还不知道。对。所以这里实际上,就像刚才 胜准 说的那样,右边这一项会变成 sparsity,左边这一项就是 FLOPs / 内存带宽,对。FLOPs 其实也是硬件上都已经定好的数字,内存带宽也都是已经定好的,是固定的数字。但可以确定的是,从 H100、H200、GB200、GB300 到 Rubin 这样发展下去,所有数字都会变好。FLOPs 会变好,HBM 容量也会变大,而且 HBM 的带宽也会变大。但有意思的是,虽然我不知道这个数字对不对,这些人也只是做 guesstimation,但 FLOPs / 内存带宽 的大小,尽管硬件一直在进步,在假设 FP4 的情况下,大约维持在 300 倍这个比例。这里就出现了 300 这个数字。那感觉有点像 magic number,反正就是 300。对。那么这个 B 就可以直接算出来了。batch 的计算。所以是多少?B 就是那个 300 这个数字乘以 sparsity。严格来说,应该是除以 sparsity 的数字。因为 sparsity 是分数,比如最新的 sparsity大概是 1/8 到 1/12,比如说是 1/8。算一下,batch 就是 8 乘以 300,2400。这个大概是用 DeepSeek V3 做例子吧?对,是用 V3 做的。所以是 2400。因为那个 8。大概等我们过了今年年中,到明年初的时候,其实就不只是这种关于 MoE 的 guesstimation,应该会在讨论连 sparse attention 都计算进去的东西吧。对。可是其实我觉得 DeepSeek V4我现在就是把 DeepSeek V4 当主力模型在用。当然跑 Codex 的时候用 GPT-5.5,但我平时做一般工作、在我的 Emacs 里调用的模型,是接上 DeepSeek V4 试着在用。挺好的。说它是 Claude Opus 级别。虽然不能说就是那个级别,但可以确定的是,比 Claude Sonnet 好。确实。是吗?您是用 API 吗?用 API 啊。AI API 的费用便宜得惊人。DeepSeek 是这样。现在还在做发布纪念折扣,所以更便宜,我充了 2 美元,但连 2 美元都很难用完。只要不跑这种 coding workload。我就是拿自己的东西不停来回对话,在我的 Emacs Roam Notes 里跑这些,到现在连 1 美元都还没用完。说实话。所以从这里看,回到主线的话,关于要把 batch 设成多少这一点,其实今天的核心内容都包含在里面了,提高 sparsity,就可以把 batch 用得更高。可以把 batch 用得更高是什么意思呢?就是每一个 cycle 能服务的用户数量可以大幅增加。这又是什么意思呢?反正 GPU 买了,付给 NVIDIA 的钱,以及单位时间消耗的电费都是固定的,所以最后站在 frontier lab 的立场上,它在单位时间内服务更多用户,就一定是有利的。反过来说,没法聚集到那么多用户的公司就不利了。对。所以流量其实都闲置着。一边持续承受折旧,实际上又跑不起来,就会做这些计算。在 B 里做 sparsity 计算,然后围绕这个讲了很久,接着进广告。广告也做得挺有意思。对。做这个广告的公司叫 Jane Street,就是那个。是一家 quant 公司。就是靠算法赚钱的公司,而且赚得很多。然后接下来转到下一个话题,在讲火车之前,是火车的比喻吧。火车的比喻,讲的就是这个。做 inference 的时候,一次运算 cycle,我不知道这个 clock 为什么会这样定,但他们说它大概是 20 毫秒。也就是说填满一个 batch,然后让那个 batch 去运算,如果上面是 prefill,那就不会有 LM head,如果是 decode,那就会有 LM head,然后就会产生值,对吧。如果 token 在前面的站台上车,它就会完整地运算一遍,然后在上面的站台下车,到那个时候为止所花的时间,他们说会调整到大约 20ms。不只是 tensor 计算,而是把各种东西加起来是 20ms,对吧。对,不过决定这个 20ms 边界的一个非常重要的变量,他现在在这里写了,就是内存容量除以这个带宽的值。那这个容量。我有点混淆,这里想的不是计算,只是 batch 吗?还是包含 batch?batch 和计算都包含了。因为内存加载和 compute 总是同时进行的。相比那个 memory compute,内存肯定更慢,这里下面不是写着吗。有 300 的差距嘛。FLOPs 快得多,而内存来回读写很慢。所以他们说这个比例大概维持在 300 左右,所以这里是在说,一次发生运算的那个 cycle 应该以什么为基准来设计比较好。这位先生也用了非常多 guesstimation。guess + estimation。没错。所以他引入了 drain time 这个术语。这个 drain time 是,HBM 内存有 288GB,以 GB300 为基准,它的带宽现在是 20TB/s,是字节吧。不是比特。是字节。一除的话,上面就是容量,B 就约掉了。对,那分子就只剩 second 了嘛。那个 second 就是 20 毫秒。最新的 GPU 是 15,旧一点的是 40,因为这个比例,大致 20 到 30 毫秒左右会被维持住。300 除以 20 是 10,总之。是 300 除以 20,所以那个应该是 15 才对吧?对。不过总之,会上下浮动。粗略算成 20 到 30 毫秒左右,就是这个 HBM 把整个内存完整读一遍的时间。所以既然那是 20ms,就以 20ms 为基准来设计一个 cycle,他就是这样推出来的。在那里面还要把 weight 拉进来,也要把 batch 做好并填进去。对,所以其实我们一直都只对 training 那边很感兴趣,对于 inference 这边和这些硬件到底是以什么方式组合起来的,其实我也直到最近才意识到,自己从来没有想过这个。真的没想过。只是 Jensen Huang 说 FP4 怎么样了、什么怎么样了,那我想到的也只是如果 Claude Code 200 美元,我能用多少,至于它到底在以什么方式发展,我完全没有计算过,这次做这个的时候,也算是我自己认真把这些都算了一遍。看完这一集之后,再去看前一集 Jensen Huang 那集,感觉应该会不一样。没错。所以最后要进入这个话题的核心了,所以最近的某种,这里 Reiner Pope 和Dwarkesh 虽然没有直接讲到,然后我又去问了 ChatGPT 和 Claude,把这些内容给我,让我一边学各种东西,最新的 serving 架构,比如 vLLM 和 SGLang 这些,它们内部到底在做什么,AI 按照这些内容给我系统地讲了一遍。很惊人。但只看核心的话,最终就是每 20ms执行一次某种运算,而那次运算里填入多少 batch 比较好,这里大概是 2400 到 3000。如果极度概括,最终就是每 20ms出发的一趟运算列车上,batch 的最优值是多少,它会告诉你,问题是怎样才能不漏掉这些 batch,把它们塞满再发出去。那么用户可能有几万人,几千人同时接入,他们给 Claude 的 workload 真的各种各样。有人拿来 Claude Code,有人只是发“你好”,有人又拿来别的东西。这样会来非常多样的 workload,要用什么方式 orchestration 它,才能让每个 rack 里的列车每天每 20 毫秒的 token都在塞得满满的状态下运转。而为了让这件事成为可能而做出的那些算法改进,在 vLLM 或者那个叫什么来着?SGLang 这些里面非常多。对于每个 batch 的 KV cache 都会不同的部分,如何通过 PagedAttention 降低内存容量,同时高效地拿到各个 token 持有的 KV cache 指针,从而一次性进行运算,也包括这一部分。然后在 decode 过程中,其实 input 每次只进来一个,但在 prefill 过程中会进来非常多个。那么 prefill 和 decode 要怎样在一个 workload 里同时处理?如果 prefill 变得非常长,其实那些只 decode 一个的任务就可能被它挤出去,所以即使进来的是 5 万 token 的 prefill,也会把它切得非常细,塞到这里那里。这样塞进去,那个好像就叫 chunked prefill,用这种方式。不过这里说的 2400,并不是说用户是 2400 个吧。用户应该要多得多才对。不是,不是。不是的。如果说 batch 是 2400 的话,严格来说,如果一个用户处在 decode 阶段,其实那个准确数字会根据硬件之类的不同而变化,比如根据内存状况之类的,全都会变,但如果是 2400 batch,而且全都是 decode 的话,那就是 2400 字节。那么那么贵的东西,让 2400 人同时在线使用,不过这是按每趟 train 来算的。对。每趟 train、每个 cycle 有 2400 人上车,但如果只是以 2400 字节来定,那个 length 就先固定下来。这样才能把所有这些东西针对它进行 optimize,所以可以用这种方式把 computation 规格化,然后进行 optimize。但另一方面,另一方面,像 KV cache 这种情况,每个用户的情况差异太大了。有人短,有人长,因为这种情况,当 workload 达到某种程度以上时,其实就会变成 memory bound。因为 KV cache,问题可能不再是 compute bound,而是转变成 memory bound 问题。所以刚才前面解出来的,是关于 compute bound 的公式啊。300 乘以 sparsity。对,不过这里能看到,我再稍微多解释一下再往下说,虽然中间话题有点跳,vLLM 和 SGLang这些东西为了 optimize 它,真的是做了极其严苛的 consideration,我想说的就是这个。而且 frontier lab 真正的某种资产,可以说是 moat 的东西,我觉得就是这种工程基础设施能力。这种工程基础设施能力似乎正在变成最核心的东西。如何充分理解硬件,又很好地处理用户的 workload,从而提升这个 serving throughput,这是非常重要的技术。而且这些现在并没有都对外共享。按 workload 来看,有些 workload 其实就是“你好。”“在干嘛?”这种非常短的 context length 不断落下来,可能会有这样的 workload,而这些东西就可以接收更多用户。那价格就应该变便宜才对。但如果即使把某个 chunk 切分开,对于 context length 变长的 workload,比如编码这些东西来看,其实从 1,000k 到几万 k 左右都会直接出现。这种情况下能承载哪些用户,也就是说用户数量会减少。因为如果假设每个 rack 的computation 和内存是有限的,input 短的用户就可以接收更多用户,input 长的用户就必须少接收一些用户,这些都是已经确定的。对吧。但当变成 long-context 的时候,其实把这张图里说的内容极度概括一下,compute 和 KV cache 会有一个达到平衡的点。但一旦超过那个点,其实这张图里也能看到。就会进入 computation 有富余的时点。computation 无论变得多快,因为内存跟不上它,整体速度都会下降到 memory-bound,会出现这样一个时点,而这是因为 KV cache 的长度。按这些人的估算,那个 optimal point 大概是 200k 左右。所以其实是从他们那样定价这件事反推出来的。对。所以 200k 以下的东西,即使都在同一个 workload 里处理,也已经 optimize 到不会造成太大问题的程度,但超过 200k 的话,为了处理它,就必须显著减少接收的用户数量。也就是说,有这样一个 GPU 集群。而且很多编码工作负载或者这类东西,很可能正在被调度到那边,从提供方的角度来看,那里其实是需要收得贵一点的这样一个领域。所以这是经济性的原理。拿这些东西一路倒推计算的话,Google 也会说我们每秒处理多少 token,偶尔会在会议上发表嘛。那么把他们发表的内容算一算、倒推一下,啊,一台机架在整体 token 处理量里大约占千分之一,也就是说最终大概会有 1000 台机架,也可以做出这样的推测。没错。而且这两位谈到的内容里也有这种说法,最终价格会定在接近成本的位置,因为是竞争状态,所以才可以倒推,我觉得他们说的是这样的语气。那些 frontier lab正在无意中提供信息。也就是说,看他们以 API 价格拿出来的那些东西,就能看出他们内部拥有的某种 token economics,它是以什么方式构成的,他们是在说这个。然后在谈到 cache 价格的时候,我觉得我们可以这样想。我正在用 Claude Code 工作。那么当我持续做这个工作的时候,实际上 KV cache 应该会被放在某台机器的HBM 上,对吧。那么我做的工作持续发送到那台机器上,肯定是有利的。但即使我只是暂时去喝水,它也不知道我会在 1 分钟内回来、30 秒内回来,还是 10 分钟内回来,事实上那个 AI,那个 GPU farm是无法知道的,所以在某一段时间内,比如 1 分钟,它就会把那个东西留在 HBM 里。因为在内存里等着,比起把它删掉然后接收其他用户的工作负载,有时会更有利,所以这就是 cache 策略。所以如果在 HBM 里,就会立刻 hit。但如果我玩了大概 10 分钟才回来。那么把它在 HBM 里留 10 分钟对他们来说又是亏的,所以就会降下来,而降下来的阶段是降到 CPU 旁边的 DRAM,算第 1 阶段。接下来放到 flash drive 上,是第 2 阶段。或者真的降到传统 HDD 上,是第 4 阶段。会以这种方式处理,连这些也都到期 expire 之后,就全部删掉。以这种方式,cache 价格一路都变得不同,其实也是因为这种 dynamics。我们才过了 2 年嘛。即使说 AI 很神奇什么的,在正式使用 Claude Code 之前,我觉得那些全都是小孩过家家。只是往 ChatGPT 里放点东西、再放点东西来看,工作负载并没有那么高,但实际上 Claude Code 出来、Codex 出来之后,这些东西使用的 inference 量真的变得非常庞大。而且 thought token 也大量运转,thought token、reasoning token 也大量运转,然后中间一旦 tool call 往返一次,tool call 读取进来的信息也全部都是需要 prefill 的数据,所以如何 manage context变成了最核心的 bottleneck,我觉得这些东西在最大的技术发展中已经变成了最重要的因素。这和 model training 没什么关系,完全是 inference 和 serving 的 infrastructure 技术。这一部分我们虽然没有太多意识到,但实际上可以认为其中包含了非常多重要的核心内容。所以我们其实在这 2 小时的讲座里,只看了前面 30 分钟。光是看了 30 分钟的内容就讲了这么久,后面其实是在理解这些的基础上,还有一连串更有意思的内容,那个就留给大家当作业吧。所以我觉得 Dwarkesh 真是很厉害。没错。这是只有这个人才能做的内容。说实话。那么我们来看看,胜准。Dwarkesh 准备这个的过程也很有意思。所以 Dwarkesh 把自己是怎么学习这个的,做成了 flashcard,我让 Codex 翻译了一下。所以是在原来的基础上做了韩语版本。这是他为了自己试着答对,自己出这些题目,然后确认自己知不知道,好像是在检查这种东西。这个我们讲过吧。一次 forward pass,一次时间的方程式是什么。还有 T_compute 的方程式是什么。正石很努力地说明过,但我并没有背下来。我也是。不过里面放了什么来着?放了什么来着?这个,这个 active plus。对,batch 乘以 active。也就是说,Dwarkesh 也把这个选作最重要的内容,放在最上面的三个里。T_mem,这里当时稍微更长一点吧。有 sequence length,对吧。这个。接下来,画出 latency 的线。这个当时花了很多时间讲吧,这个。是可以这样的。weight fetch lower bound,这是从哪里来的。讲过 lower bound 吧?是什么来着?loading 的 time 是 lower bound。内存。因为内存。总之像这样,他自己也一直在学习。所以我在这里又加了一个东西,这个内容在讲座的哪个部分,我也做了这种东西。很好。像这些我们想要的东西,Dwarkesh 也用一键点击做出来了,对吧。胜准又把那个拿过来,这个过程也又是一键点击完成的。点击点击,我们真是生活在一个很好的时代。不过问题是,我们今天一直彼此对话,同时这样反复咀嚼了这些内容。也把知道的东西说出来。如果没有这个,其实很快就会消散掉。并不是说做出了这个,它就会变成我的东西。今天我们久违地有点脑袋发热,思考 token用得很多的一场 session。以前总是说什么怎么样、那样,以 instruct model 的形式一直在做,但这次久违地浓厚地用了很多思考 token,是这样的一场 session。后半部分其实也有这种内容,很有意思。是中段吗。中段,在 training 那里。中段,这些内容里为什么会出现 6,这些也很有意思,总之因为我们不可能全部讲到,就先介绍到这个程度。没错。其实重要内容前面已经讲得太多了,后面的内容大家可以直接跟着 Dwarkesh自己试一试,还有几个更有意思的内容。我也真的在结尾做一个宣传。差不多是儿童节前后。久违地做了一个儿童展览,在京畿道这里的想象校园,水原那边的一个地方,我正在参与一个体验展。胜准正在参与。所以我在最后部分以一个路线的形式参与,做了这样的东西。可以用手去触碰。当然这个也是借助 AI 的力量做出来的,像这样伸出手,就可以稍微操作一下行星或者恒星之类的东西。所以像这样再触碰一下就可以,能够操控那个。然后这里到这个程度,说“我们来看一下”,握拳等一会儿,就会重新生成一个新的恒星系,我做了这样的东西。就算是做个宣传,说我尝试了这样的东西,今天这么长时间,我这样收尾好像不太行,该怎么收尾呢?那是胜准做的作品,对吧?对,是展览。胜准的本职又是媒体艺术家,所以做了这些东西,而且现在正在展出中,感兴趣的朋友可以去参观一下。所以今天这么长时间。内容真的很难、很吃力,我们也脑袋发热。这个 Dwarkesh 播客真的有很多值得学习的东西。而且这个人总是在思考如何进一步推进知识的 frontier,以及如何把它更容易地讲出来,传达给大众,感觉他已经非常明确地找到了自己的定位。所以今天是一段很长时间的探索过程。Dwarkesh 最近又登上了 NYT 的报道。不过看起来,他学习得非常努力。据说每见一位受访者,就会学习大约两周。我把那篇翻译好了,讲的是 Dwarkesh 为什么这么有人气,人们为什么期待他,是因为他能够提出别人都提不出来的问题,说是这样。所以从 Dwarkesh 这样的学习方法里,如果说在今天的语境上还能再多一层的话,他是怎样深入钻研这些内容的,Dwarkesh 是怎样把这些内容学下来的,这也许也会成为一个值得大家关注的点,就用这个来收尾。拜此所赐,我们也在休息日学得脑袋冒汗了一次,也成为了让我们了解到很多东西的宝贵契机。辛苦了。今天辛苦了。算是在休息日没有玩,而是工作了。那么剩下的休息日也请好好休息。辛苦了。