EP 88
秘訣はない
オープニング: ソンヒョンとの再会 0:00
ロ・ジョンソク 収録している今日は2026年3月1日日曜日の朝です。久しぶりにソンヒョンさんをお迎えしました。
昨年の年末に最後の回をソンヒョンさんと一緒に撮りましたが昨年のモデルの変化を振り返るとRLVRの目覚ましい発展、そしてMoEのようなアーキテクチャによる効率の向上、こうした点を挙げていました。26年にはまたどんな注目ポイントがあるのかこうした予測をしながら締めくくりましたが、わずか2ヶ月が経ちました。多くの変化があったようでもあり、なかったようでもあり、
今日は久しぶりにソンヒョンさんをお迎えして、この2ヶ月間の所感を聞いてみて、今後どんなことが起こるのか予測してみたいと思います。ソンヒョンさん、いらっしゃいませ。
キム・ソンヒョン 以前出演したセッションでは、一つのテーマを決めてそのテーマについてたくさん話していたと思いますが。今回のセッションを準備しながら、かなり考えました。2ヶ月の間、折に触れてずっと、また参加するにあたってどんな話をすればいいだろうかとかなり考えていたのですが。それがなかなか難しかったんですよね。例えば技術的で細かいディテールについて、例えば最近話題になったDeepSeekのEngramやMHCのような話をたくさんすることもできますが、自分自身の視点が少し変わったような気もしますし。そしてそれが本当に今どれほど重要な課題、問題なのかという考えもありました。なので一つのテーマに絞って話し続けるよりはさまざまなテーマと所感についてお話ししてみるのがいいのではないかと思いました。私が思うのは、DeepSeek V4がDeepSeek特有の非常に独特なやり方で非常に多くの技術的革新とディテールがあり得るとは思います。ただ、その技術が興味深いこととは別に
”技術”ひとつでは語りにくい理由 1:17
キム・ソンヒョン この場で非常に興味深く紹介できるような何かパラダイムシフトだとか、こういった革新があったから今後はこう進んでいくだろうという話をするのは少し難しいかなと思います。DeepSeek V4が出たとしてもここでこういった進展があったから今後AIモデルの発展はこうなるだろうしこういったことが可能になるだろうという話をするには少し難しいのではないかと思いました。なのでこのセッションのテーマが特定の技術や技術の発展についてというよりはさまざまなテーマへの言及に近い理由でもあります。このスライドに「技術」と書いてありますがその意味は、なぜ技術というものについて、ある特定の技術について語ることが今とても難しいのかについての、ちょっとした弁明に近いです。最近DeepSeek V4ではありませんが
GLM 5レポートとRL中心の技術革新 2:23
キム・ソンヒョン 非常に興味深い研究レポートが出たのが、フロンティア級でレポートが出たのがGLM 5でした。Zhipu AIから出たレポートでしたがここに非常に興味深い技術的革新とディテールがたくさんあります。非常にざっくりまとめると3つです。RLをより効率的にすること、例えばSparse Attentionだとかそういったものが、またRL用のインフラストラクチャのようなものを、async RLだとか、こうした数多くの技術的ディテールがありますがその部分のかなりの部分がRLをより効率的に、計算効率的にすることです。コンテキスト長をより効率的に反映してより効率的にRLを進めること。次に、もう一つはRLのobjectiveのようなものを少しずつ修正してより安定的にできるようにすることが一つあります。そしてもう一つはRLをより多様にすること。最後に環境スケーリングについてお話しすると思いますが。より多様な課題に対してRLを実行できるようその環境を拡大し、環境をより効率的にスケールさせること。こういったことが主要なテーマです。
GLM 5というこのレポートで数多くの革新がほぼRLに関連しておりRLをより効率的に、より安定的に、より多様にすることが今最大の革新の方向性だということですね。この部分について考えるとYao Shunyuの”The Second Half”について考えることになります。“The First Half”の場合はベンチマークがあってそのベンチマークに対して手法を開発し手法を開発してそのベンチマークが解け始めると新しいベンチマークを作り、こうした手法に基づく時代だったと表現していましたが”The Second Half”に移行して、我々は手法について答えを見つけた、答案を見つけたのだからこの答えを持ってあちこちの問題に適用すればいいのだ、という表現をしていたんですよね。ある意味かなり傲慢に感じられる表現でもありますが同時にこれが本当に正確で、少なくとも今2025年からこれまでの1年間は非常に正確だったと思います。皆がRLが答案、答えとなり、RLをよりうまくやるためのこと、そしてRLをさらに拡張するためのことがほぼすべての努力のほぼ全部であり、今はなおさらそうです。
Yao ShunyuのThe Second Half: RLという解答 3:40
キム・ソンヒョン 技術と言ったとき、技術的革新と言ったとき強く感じるのはこの手法の革新ですが手法の革新について言えることは、興味深く語れることはあまりなく、ずっとRLですから。このRLがどれだけ拡張されていきより深みを増しているかという話を繰り返すしかないので、こういう感覚を受けるため私がある技術の軌道をもってこの技術がこう発展していて今後どう発展するだろうという話をするのが少し難しく感じられました。なぜなら少なくとも引き続きRLが適用され続け引き続き漸進的に発展することが予想可能であり今まさに起きていることですから。この観点からは秘密のレシピについて少し考えるようになりました。秘密のレシピというのは、フロンティアモデルが秘密のレシピを持っているとすれば、それは手法的な革新により近いと思うんですよね。彼らが全く知られていない何か秘密を持っていてその秘密を知らなければモデルを作れない、そういったものがあるという信念を持つようになりますよね。もちろん非常に多くのイノベーションがあります。
秘密のレシピは存在するのか 5:16
キム・ソンヒョン GLM 5のように非常に多くのイノベーションがあり非常に多くの改善があります。その改善があるのですが、それを否定しているわけではなく、MoEなどといったものも非常に重要なイノベーションでした。しかしそれが隠されていて知ることが非常に難しい秘密のレシピだったというよりは、GPT-3.5から今まで見守ってくるとすべて段階的にモデルを改善し開発していけば見えてくるし分かるものだったということに近いと思います。それでも秘密のレシピに最も近かったのはRLVRだったと思います。それ以外は、大部分が重要なイノベーションではありますが知らなければ絶対に追いつけずしかもそれを知ることが非常に難しいそういう形の秘密のレシピはなかったのではないかと思っています。もちろんこのように感じる背景には、中国企業が秘密のレシピをすべて独自に見つけ出したり開発して公になったということもありそれがもはや秘密ではないように感じられてそういう面もあるとは思いますが、今の感覚としてはそういうことです。単にエージェントRLやRL自体だけによって生じたものではなくこれまでにあった多くのイノベーションは概ね段階的で予測可能な軌道の中にあったものだったということです。
そういう意味で今さらに重要で自明に感じられるのは現時点が何か驚くべきイノベーション、そして驚くべき新しいアプローチというよりは、もちろんそういった小さなアプローチを否定するわけではなくそれは今後も続くでしょう。しかしそれよりもはるかに重要なのは基本に忠実であることだと思います。良いデータを作り、安定したインフラを整え、そして多くの計算資源を使ってモデルを作り上げていく、この最も基本的なこと。何か創造的な方法ではなくこの基本が今のモデルの性能を支配していると考えています。様々なモデルに様々な性能差があり人それぞれ好みのモデルがあると思いますが、その好みのモデルが、そのモデルを作った会社が持っている他の会社が全く知らない秘密のレシピではなくこの基本にはるかに近い問題、より良いデータを作りよりうまくスケーリングするといったこうした問題にはるかに近いと考えています。この基本に忠実であることが今非常に重要だと思います。だからこそ基本に忠実であれば多くの後発者が追いつける問題、状況が、環境が整っているようにも思えます。同時にこの基本に忠実な経験を多く積んできた現在のフロンティア企業がはるかに有利なポジション、時間的に有利なポジションにいるのも事実です。
基礎力の時代: データとプロダクト感覚 7:14
キム・ソンヒョン 同時にもう一つ思うのは、基本に忠実であるということがプロダクトを作る、プロダクトに向き合う姿勢に大きく、密接に関わっていると思います。AI組織は、私が経験したAI組織に限定して言う部分もありますが、研究的な志向が強い傾向にあると思うんですよね。研究的イノベーションや新しい研究的アプローチといったものに対してエンジニアの関心がそちらに向きがちだと思います。しかし私はプロダクトを作ることはそれとは少し違う感覚が必要だと感じています。多くの反復を重ね、多くの試行錯誤を経て、そして多くの使用を経ながら少しずつ少しずつ改善していき、少しずつ少しずつモデルをさらに磨き上げていくプロセスが非常に重要だと思うのですが、こうした感覚と姿勢の重要性が非常に高まっていると思います。少しずつ磨き上げていった時に感じられる違いがユーザーには非常に大きく感じられるものであり、そうでなければ、少しずつ隅々を埋めて磨き上げていくことよりも大きく、そして手っ取り早く性能的向上、数値的向上をもたらせるものに傾倒しがちになりますよね。しかし今の時点はそれよりもプロダクトを作り上げ基本に忠実であることが重要な時代のように感じます。なぜなら多くの重要な手法がすでに発見されているからです。考えてみればRLという手法がすでに発見されたからこそ、この手法の中で磨き上げることが非常に大きな違いを生む部分だと思います。同意します。本当にこの二ヶ月間、ある意味
ロ・ジョンソク 昨年の秋からソンヒョンさんが今おっしゃったこの瞬間までモデルが急激にいきなり2倍、3倍良くなったわけではないじゃないですか。ずっと良くなってはいましたが、実際のところ人々はこう判断しているようです。今のモデルでも十分使える。とても良い。だからそれを中心にプロダクトも多く生まれているようですし。
AIの社会的波及力の増大 10:19
キム・ソンヒョン 私はただ、AIが社会環境にどのような影響を与えるか、そういった部分について確信を持って語れるような専門家ではありません。だからこそなおさらそういった言及は控えるようにしています。しかしそれとは別に、AIの波及力がますますものすごく強くなってきていますよね。それは明らかな事実だと思います。
ロ・ジョンソク そうですね。Anthropicがどういった形のプロダクトを出した、サービスを出したというだけでも数多くの企業の株価が揺れ動いていますし。そしてアメリカ政府にモデルを導入するかしないか、導入するとしてもそれに対して一つのフロンティア企業がどのような条件を課すかによって国家的な問題にもなりますし、こうした波及力がますます大きくなっていると思います。
チェ・スンジュン 最近のDoWの話ですよね。戦争関連の。戦争関連の話で
キム・ソンヒョン それに対してAnthropicがどのような条件を付けているのか、どのような態度を取るのかが国家的な問題になり、その製品をアメリカで政府が使用してはいけない、いい、こうした論争になっていることを見ると、AIモデルの発展とその発展による波及効果が、今まさにこの時点でも非常に大きいと感じますね。私はこの部分について、自分が持っている考えや態度が少し違うと感じるのは、私はずっとモデルがある側面では発展せざるを得ないと考えているんですよ。そうすると、その発展した状況で、将来これらがどのような波及効果、影響を持つようになるのかということが少し怖くもなります。そうですね。とても怖いですよね。でもこれはずっとあったことじゃないですか。
ロ・ジョンソク 賢い人が10人集まった会社があったのに誰かが100人集めてもっと強力な会社を作り、でもまた時代が過ぎると5人のもっと賢い人がコンピュータと結合してもっと良い会社を作り、もっと良い事業を作り、こうした変化はずっと続いてきましたからね。ずっと行ったり来たりしながらハーネスとモデルの性能が
抜きつ抜かれつしながらどんどん良くなっていくんじゃないでしょうか?その形態がどうなるかに関わらず良くなることは確実だということには皆さん異論がないようです。
Fog of Progress: 未来予測が難しい構造 12:21
キム・ソンヒョン その観点で、私が以前のセッションで言及した部分でもありますが、進歩の霧、つまりFog of Progressです。ジェフリー・ヒントン教授がおっしゃった話がずっと頭に浮かびます。これらすべてが、将来がどうなるかという予測にかかっていると思うんですよ。そして皆さん、将来がどうなるかについてのビジョンを持っていますよね。でも、職業がどう変わるのか、
今AIを学ぶべきだ、学ばなくていい、こうしたことはすべて将来の予測にかかっている部分だと思います。例えば、AIを今学ぶべきだ、AIの使い方を学ぶべきだと考えるなら、AIの使い方が将来も大きくは変わらないだろう、そしてAIの使い方を熟知していることが将来にも大きな影響を与えるだろう、こうした仮定を置いているわけですよね。結局これらすべてが、職業についても同じです。職業がどう変わるのか、今後開発者が必要になるのか、必要なくなるのか、こうしたすべてのことが、実際に今後AIモデルがどのような形で発展しているかという仮定を持って始めるわけです。でももちろん、皆さん将来は
正確には分からないので仮定するしかなく、その仮定に基づいて話すしかないのですが、同時に私がずっと考えていることは将来は予測が難しいということです。すぐ近くの地点については、道路に霧がかかっているように、近い地点については見えますが、もう少し先に進むとそれは指数関数的に光子の量が減るため分かりにくくなります。短期的にはずっと発展し続けるだろうということは明らかですが、長期的にどうなっているかについては予測が難しいという話を繰り返しすることになります。
ロ・ジョンソク それは私たちが軽々しく語れる人はいないんじゃないですか?Elon Muskクラスぐらいにならないとそういうことは言えないと私たちはそう受け止めましょう。Elon Muskはもうすぐ外科医は必要なくなる、2年以内に必要なくなる、というようなことをおっしゃっていますがどうなるか分かりませんが、先ほどソンヒョンさんがおっしゃった
Fog of Progressのその比喩もとても適切で私たちは霧で前が見えないのは確かですがそれぞれが霧の中でどの位置にいるかは違うと思うんです。Frontier labはもっと前にいるので彼らが指数関数的により多くのものを見ているのは紛れもない事実ですし。私たちのような人間は追いかけながら見ているので彼らよりは当然少なく見ているはずですし、どこに立っているかはすべて相対的だと思います。
チェ・スンジュン 私は一つ冗談が浮かぶんですが、そのFog of Progressは光子に関係することじゃないですか。散乱が起きにくい水粒子に対して散乱が起きにくい波長であれば見えるものももっと増えるんじゃないですか?冗談ですが。そしてまた、ある人は
ロ・ジョンソク 運良くトンネル区間から始めることもあるんですよ。そうするとトンネルが終わるまで勢いよく走っていけますからね。予測するのは本当に難しいですが
環境スケーリング: エージェントRLのボトルネック 15:15
キム・ソンヒョン 私の考えでは、もう少し見積もりやすい問題の一つは環境スケーリングの問題ではあります。環境スケーリングというのは、RLにおける環境の話ですがRLにおける環境というのはあるagentがその中に入ってアクションを取り活動をして、それに伴う環境の変化を観察しその環境を観察した後に最終的にrewardを得る、こうしたことが起こる環境のことです。今のagent、LLM agentと言えば
例えばソフトウェアエンジニアリングのタスクのようなものが一つの環境になりますよね。このバグを直せと言われたらこのバグがあって、あるソースコードがあって、そのソースコードの中で使えるツールがあって、そしてそのツールを使ってインタラクションした後に最終的にrewardを得ることになります。こうした環境を多様に増やしていく必要があります。なぜなら、今は単純な作業をしていたのがどんどん多様な作業、より複雑な作業をしていますからね。今AIエージェントができることは非常に多いですよね。そしてもっと複雑なプログラムも作れるようになっています。そうなると、どんどん複雑なプログラムを作るための環境を作る必要が出てきます。以前は単純な関数を一つ作ることだったとすれば次は一つの完全なプログラムを作ることになり、今後はサービス一つを丸ごと作ることになるでしょう。そうすると、この環境をどんどん増やしていく必要がありますが、どんどん増やしていくことで発生する問題はこのレベルがどんどん上がるにつれて作らなければならない環境の複雑さもどんどん上がっていくということです。
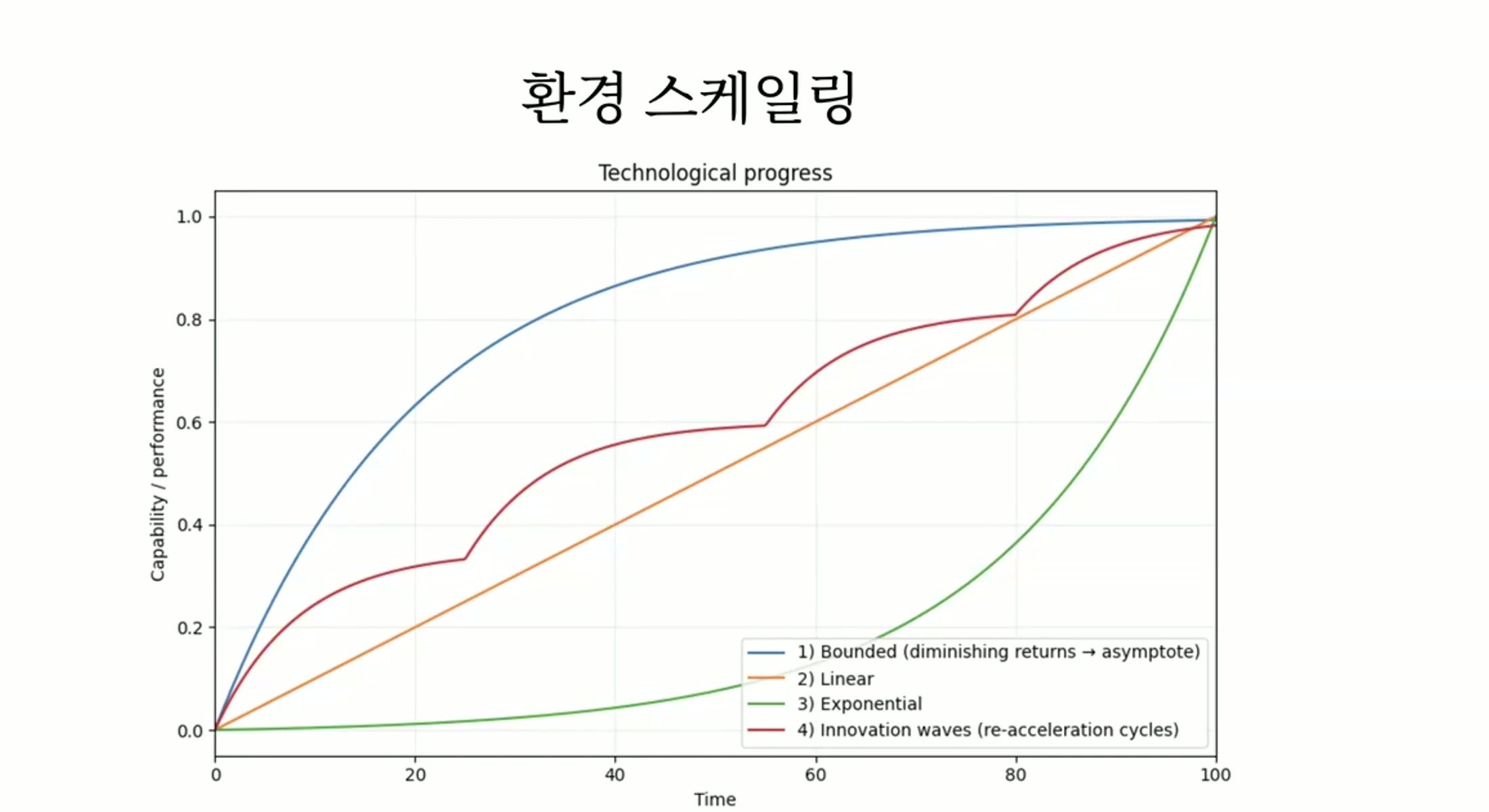
チェ・スンジュン このグラフを一度読み上げていただけますか。
キム・ソンヒョン では、その状況の中で、環境をスケーリングすることが最大のボトルネックだと考えてみましょう。そして環境を多様化することがモデルの発展において最も重要な局面だと考えてみます。The Second Halfを受け入れてRLを行い、RLができる環境があればどんな問題でもすべて解けると仮定した場合、そうだとすればどんな問題でもすべて解けるので環境を作ることがむしろ唯一の技術的ボトルネックになるわけですが。ではその技術的ボトルネックについてどのように解決されていくかについての可能な軌跡を一度考えてみます。最も楽観的に考える人たちは時間が経てばその技術的ボトルネックが
さらに簡単に解決されるだろうと考えられると思います。あり得ることです。ある中間地点あたりで環境をスケーリングした、環境を多様なタスクを作ることが突然非常に簡単に解決される方法を見つけたとすれば指数的にぐんと上がるでしょう。これが起こり得る
チェ・スンジュン 可能性が生まれるわけですね。緑のグラフです。
キム・ソンヒョン ずっと伸びていくでしょうが、そのようなことが可能な事例は私の考えでは継続学習の問題などが解決されればこのような似たことが起こり得るだろうと思います。そうすると環境をスケーリングする問題が技術によって解決されることになるんですよね。技術によって決定的に解決されることに近いですね。そうすると指数的に発展するでしょう。持続的な発展が私は可能だろうと思います。そのようなシナリオではもちろん現実的な制約がないわけではないでしょうが。悲観的に考えると複雑性が増え続けるため
その環境を作り上げていくコストと時間も増え続け、その複雑性がある対処不可能な水準に達すると発展が停止するだろうと考えることもできます。そうすると漸近する青い曲線のように漸近する形になるわけですね。対処しなければならない複雑性が大きくなりすぎてとても突破できない状況になるでしょう。私の考えではこれは技術的イノベーションが
ほとんど全くない場合に近いと思います。ほとんど全くなく、今のように続けて手作業で作り続けなければならない場合、そしてその複雑性が高まり続けるためその複雑性に比例して手作業のコストも比例して大きくなる場合青に近いと思います。そうではなく、ある程度の技術的イノベーションと改善を通じて、そして新しい環境、より複雑な環境を作り上げていくコストがそのように絶え間なく増加し続けない場合であれば直線に近い形でずっと漸進的に上がっていくと思います。
漸進的に上がったとしてもこれが体感の度合いが漸進的だということではありません。技術的な発展の差は非常に漸進的ですが、その体感はとてつもなく大きくなり得ます。しかし技術そのものだけを見たときはそのような形の発展が漸進的な発展になるのではないかと思いますし。この漸進的なものをもう少し詳しく見ると
このような形に近いのではないかと思います。少しずつ発展し続けていって、あるイノベーションによって発展していって複雑性が大きくなってこの速度がまた遅くなり、その頃にまたある技術的な発展やイノベーションなどを通じてこの複雑性をまた下げることになってこのような形が遠くから見ると直線のように見えるでしょう。
ロ・ジョンソク 現実のほとんどは4番ですね。このような軌跡が起こり得るだろうと思いますし。
キム・ソンヒョン もちろんこの曲線の中でどのようなことが実際に起こるかは私にはよくわかりません。私の考えでは未来を予測することにおいてこの環境スケーリングの問題であり、環境スケーリングの問題がどのように解決されるかによってこの軌跡が完全に変わるだろうと考えています。
チェ・スンジュン この文脈自体はRLから出たリファレンスですか?
キム・ソンヒョン The Second Halfが提示するようにRLが正解だ、すべての問題に対する答えだと仮定した場合、答えが与えられた場合でも与えられる問題はあるんですよね。その与えられる問題が環境スケーリングの問題なのです。
この環境スケーリングが解決されていくシナリオが私の考えでは3つだと思いますし、実はこの3つが可能なカーブをほぼすべて網羅する内容なので、実際には予測ではありませんがこの3つのシナリオがあるわけです。
チェ・スンジュン それをもう少し一般化して、未来予測の文脈に少し転移させてお話しされているんですね。
キム・ソンヒョン ここからもう少し具体的に申し上げますと、青色で、青色の軌跡は私の考えでは技術的イノベーションがあまりなくタスクの複雑性に応じてタスクを作るコストも同じように増加し続ける場合、あるいはそのタスクの複雑性に比べてコストの増加がはるかに大きい場合が青に近いと思います。本当に望む非常に複雑な問題を解こうとすると作らなければならない環境のコストが非常に大きく時間がとてもかかるのです。そのため技術の発展が非常に遅くなる場合が青になると思いますし。
この指数的な発展の場合は、この環境スケーリングの問題が技術的に完全に解決されて、一度に解決されてしまう場合がここに近いと思います。なので継続学習が解決されれば、
チェ・スンジュン 自分自身をブートストラッピングできるそういう種類の技術だということですね。
キム・ソンヒョン ブートストラッピングして、自分自身が環境を自ら発見して問題を解く場合。そうすると技術が技術の問題を解決してしまうわけですね。このようなことが起これば指数的な発展であるとか非常に発展が加速する経験をすることになると思いますし。そうではなくそこまでの技術的ジャンプはないけれどタスクの複雑性を解決していける技術が発生し、その技術を通じて再びより複雑なタスクを生み出し、再びまた技術の発展があって再び課題の複雑性を下げて、こういったことが繰り返されるシナリオだとするとやや線形的で直線的な流れに近く見えるのではないかと思います。もちろんこんなにきれいにグラフは出ないでしょうけど。
私の予想を申し上げると、この緑色が発生する可能性がかなり高いと思います。なぜなら継続学習のような問題は今、すべての人が注目し始めていますからね。ここ数ヶ月の間に、そしてこれを解こうと多くの人が試みていますので、こういった解決が起こり得るのではないかと思います。もちろん解決されたとしても、こんなにきれいに持続的に発展はできないかもしれませんし、試行錯誤も多いでしょうけど。4番に、4番に賭けていたんですが
チェ・スンジュン 3番、むしろ3番だとおっしゃったんですね。なぜなら私はそういったパラダイムの転換をずっと待ち望んでいる立場なんですよ。
キム・ソンヒョン ですので、やや期待に基づく予測ですね。ただ十分に、現実的に賭けるとすれば私は直線に近いのではないかと。継続して複雑性を減らすための試みを行い、それによって対処できる課題の複雑性も増えて、こういったことが一般的ではないかと思いますし。
チェ・スンジュン しかし線形的であっても体感レベルでは指数的になり得るということですよね。はい、その通りです。今、例えば人を通じて
キム・ソンヒョン 課題を作る、これもフロンティア企業は継続して莫大な資金をリソースを投資していると聞いていますが。そのリソースを投資している中でもそれを通じて継続的に発展が起きていますよね。そしてそれが人々にとっては突然急進的なイノベーションのように感じられますよね。そういうことが引き続き起こると思います。そういうことはほぼ基本的なベースに近いのではないかと思います。
2026年のキーワード: RLの突破口 23:36
ロ・ジョンソク ではソンヒョンさんがまとめると、2026年を支配する最も重要なキーワードもやはりモデルの、DeepSeekが見せたモデルの細かなアーキテクチャの変化や効率性の向上やこういった部分はやや当然のこととして受け入れる部分で、モデルの根源的なcapability、能力のジャンプはこのRLVR、このポストトレーニングで、RLでの誰がどのようなブレイクスルーを生み出すかが最も重要な要素になるだろうというお話をいただいたと私たちは理解すればよいですよね。
キム・ソンヒョン はい、そしてそのイノベーションが非常に急進的なものになる可能性もありますし。それが継続学習のケースで、そうでなくても解くべき複雑性を下げる小さな技術的イノベーション、合成データなどのイノベーション、そして小さな改善、こういったものが実質的な差を生み出すでしょう。
ロ・ジョンソク はい、先ほどGLM 5の論文も簡単にご紹介いただきましたがそこでも、私は実は読んではいないのですが大部分の内容がRLをどのように新しい方法を導入するか、効率を向上させるかという部分についての内容だったとおっしゃっていましたよね。なのでそれを踏まえてもう少し潜在空間を予測してみると、OpenAIですとかAnthropicですとかGoogleですとか、こういったフロンティアラボもほぼ大部分の努力がRLでのブレイクスルーを見つけることに注がれているだろうと推定されているわけですね。はい、RLでブレイクスルーを見つけ
キム・ソンヒョン 今起きているRLを改善することが最も大きな差だと思います。今AnthropicやGoogleやOpenAIが持っている差もそれらの企業がRLに対してどうアプローチし、RLの環境をどう構築し、モデルをどうガイドし、RLでガイドし、そういった部分によって決まるものですから。つまり例えば、
モデル傾向の違い: Pre-training vs Post-training 25:25
キム・ソンヒョン 私はプリトレーニングはGeminiが依然として一番よくできていて一番強いだろうと思いますが、ただプリトレーニングとは別に人々は、ある人はCodexを好んだりClaudeを好んだりしますよね。その差が生じるのはRLで、ポストトレーニングで生じるものですよね。
ロ・ジョンソク はい、人々がモデルの性向の違いについて好みが分かれますよね。Claudeは直感的で、はるかに人間の考えや人間のある種の性向、こういったものとよりアラインメントが取れているという感覚を持って選ばれる方が多いですし。Codexは追究するのが好きで
自分で勝手に何かの始まりから終わりまでやるので好む方がいます。Geminiはその二つのどこかで
実は少し中途半端な感じなんですよ。しかし実質的に持っている知識や品質やこういうものを見るとGeminiが実は一番幅広く持っているのは私たちは合っていると推定していますし。それがプリトレーニングの力でしょうね。
キム・ソンヒョン ただ性向の違いはポストトレーニングで作られるものですし。ただこのポストトレーニングを考えると、先ほど申し上げたように製品という観点に対しては影響が非常に大きく生じるものですよね。
なのでClaudeのキャラクターを好む方も多いですし、私もClaudeのキャラクターはとても好きです。Claude Opus 4.6を使ってさらにもっと好きになったのですが。もちろんコーディングとは別に私がただチャットをしていて感じたとき、このClaudeのキャラクターをとても好きなのですが、このClaudeのキャラクターというのがある技術的イノベーションによって作られたとは言い難いと思います。もちろん技術的イノベーションの助けは大いに受けましたが。Constitutional AIなどのイノベーションの助けは大いに受けましたが、あの有名なAmanda Askellのような人たちがconstitutionを作り、Claudeのキャラクターを確立し、Claudeというある種の製品にアプローチし、この製品を改善し、製品がどんなキャラクターを持ち性向を持ってほしいかというそういった側面での観点と改善が非常に大きく影響を及ぼしていて、そういう意味でポストトレーニングがこの上なく重要な状況なわけです。それでは最近、ハーネスをモデルがうまく使えるようにするとか
ハーネスとモデルの融合: プロダクトとモデルの境界 27:17
チェ・スンジュン エージェントswarmやエージェントチームのようなものも結局はRLが決定的な可能性があるわけですね。ハーネス自体が、
キム・ソンヒョン 例えばClaude Codeというハーネスがあるとすればそのハーネスに対してモデルが学習されることになるんですよね。これが今、あるハーネスへの特化ですとかハーネスの違いに対して大きな影響を及ぼす可能性がありますよね。これは以前Moonshot AIのCEOが言及していた話なんですが、製品とモデルの境界がますます近づいていることの一つの理由でもあります。なぜならモデル開発会社側では以前であれば
モデルを多様な用途に対して学習することが優先だったでしょうが、今モデル開発会社はagenticモデルを作りながらそのagenticモデルに特化したあるハーネスも持っているものなんですよね。なぜならそのハーネスが環境の一部だからです。
ですからAnthropicであればClaude Codeというハーネスが当然この環境スケーリングとpost-trainingでのコンポーネントとして入っていますよね。そうだとすればこのハーネスを通じてすでにモデルは学習されているわけです。そしてこのハーネスを使用する方法をモデルがすでに学習して出てくるため、このハーネスが、モデルとハーネスの結合がある製品だとすればその製品はすでに目前にある、モデルの学習が終わった時点に存在するわけです。これが正反合の形でずっと発展しているように思います。
ロ・ジョンソク モデルが良くなるとそれによってハーネスが良くなり、そのモデルと結合したハーネスが新しいある結果やフローを生み出すようになり、環境の役割を果たすようになるとそれ自体をまた次の世代のモデルが丸ごと内在化するそういったことを経験するようになり、より良い出発点からまたハーネスが作られ、こういった断絶的な変化とまでは言えませんが絶え間ない変化がずっと起きているのではないかと思います。これは飛躍かもしれませんが、
チェ・スンジュン 最近OpenClaw以降、環境について、エージェントが活動できる環境が非常に多様になったとすれば、それは実は微分可能な信号につながるわけではないですよね。それにもかかわらず何か今、環境自体が少し影響があるという、直感のようなものが飛躍かもしれませんが少し生じてはいるんですが、それについてどうお考えか気になりますね。多様な環境に入って
一般化と継続学習の可能性 29:32
キム・ソンヒョン 活動できるようになったことについて、一つの可能性は多様な環境にすでに入れてみたからかもしれないと思いますが、おそらくそれよりは予測可能なシナリオではなかったと思うので、それよりは汎化能力に近いと思います。環境スケーリングを突破できる一つの方法はモデルの汎化能力を拡張することではあるでしょうし。もっと簡単な環境やもっと異なる環境に対して学習をしてもモデルがより複雑な環境やより異なる環境に汎化できればこの問題がもう少し簡単になるわけですよね。その側面でそのような汎化能力が発現したことに
近いのではないかと思います。ただ、多様な環境に入れてみることができるということは、入れてみることができる状況は整っているわけです。ただおっしゃっていたようにこの多様な環境に入れてみることができることがモデルを発展させ、この多様な環境でモデルが適応できる機会につながりうるとすれば、問題が突然急進的に変わり始めるでしょう。Claudeボットたちがどこかでコミュニティ活動をするとか、文章を書くとか、自律的にある課題を遂行するとか、こういったことをした場合、そのような自律的に遂行できる空間は与えられていますがその空間の中である遂行をし相互作用をしながらそれがモデルを発展させ変化させるきっかけになりうるとすれば、モデルが突然大きく変わるでしょう。それが継続学習シナリオだと私は思います。それをつなげることができる方法は大変な技術的、パラダイム的革新が必要であり、そういったものを期待するようになりますね。
これが起こると考えるとおそらく人々が感じるものが大きく変わるでしょう。その数多くのClaudeボットたちが単に自律的にある課題を処理することを超えて、自律的に処理しながらフィードバックを得て自分自身を発展させるものを目にすることになるでしょうから。おそらくその頃になるとやるべきではないと言う人たちが大幅に増えるような気もします。これは露出させてはいけない、やってはいけないと。ええ、真剣に。私は以前からモデルがすなわち製品だということを信じてきましたし、それでも幸い以前は少しましだったと思いますが、次第に人々がより同意し始めたように思います。少し嬉しいです。ただモデルがすなわち製品だということを
話しながらできる話の中で一つは技術を待つこと、技術を待つ戦略です。実は私個人の戦略でもあります。2年前くらいだったでしょうか、あの頃はエージェントというものは出てきましたがモデルがエージェントとして学習されたとかそういったことはあまりなかった時期でしたよね。あの頃も人々がモデルを使ってある製品を作ろうと多くの試みをしました。あの頃のハーネスは本当にものすごいハーネスでしたよね。モデルがそれでも何かしようとする時にできるように手助けするツールを握らせる感じだとすれば、あの頃のハーネスは枠組みをすべてがっちり組んでおいてモデルをそこにはめ込む感じでしたから。そういった形のハーネスとでも言うべきでしょうか。それを外骨格と言うべきでしょうか。そういったものを通じてあるエージェントを作ろうと人々が多くの試みをしていましたが、非常にうまくいきませんでしたよね。うまくいかなかったし複雑性も非常に高かったです。ところがすでにその時点でも人々がしていた話が、このように数多くのハーネスを作り複雑に作って出来た製品よりも約3ヶ月から6ヶ月ほど待って新しいモデルが出た時にそのモデルを使ってシンプルなハーネスで製品を作る方がはるかに作りやすく性能もはるかに強力だったという話をしていました。そういったことを見せてくれるのが技術の発展がもたらす波及力は非常に大きく、製品を構成する方法や、モデルにアクセスする方法を大きく変化させ決定するということを示す事例だと思います。
技術を待つ戦略 31:39
キム・ソンヒョン そのため、今のモデルの性能をもとに人々がよく話をするようになります。今のモデルはこれができない、あれができない、これができないのを見ると、今後もできないだろうと。そして今後もできないだろうから、今後もできないだろうということは必ずしもAIに対して悲観的な立場ではありません。例えば、今後もこれがうまくいかないだろうと思えば、今後も指示をうまく出せなければうまくいかないだろうと考え、指示を本当に精巧に出さなければならないと考えるなら、だからこそ私たちはAIを学ばなければならないし、使い方を精巧に学ばなければならないし、プロンプトをうまく書く方法を学ばなければならないし、使い方を学ばなければならない、このようにつながることもあるんですよね。AIを肯定する立場からも、そのようにつながることがあるわけです。ですが私は、あえてそのような焦りを感じるよりは、もう一つの戦略は
技術が発展することを期待しながら楽しむこともまた一つの戦略だと思います。遅れていると感じるよりは、今後発展するモデルたちを待ちながら、そのモデルたちがもっと簡単に使えるようにしてくれるだろうし、もっと大きなことをもっと簡単に強力にできるだろうと期待することも一つの戦略だろうと思います。それが私の戦略でもありますし。もちろんこれは社会的に個人の戦略かもしれませんが社会的に良いことになると保証することはできません。技術の発展がですね。以前、AIモデルが
指をまともに描けないだけでなく顔すらもうまく描いた画像生成ができなかった時代がありましたよね。その頃、多くのアーティストたちは指すらまともに描けないAIをどうやって使うのかと考える人たちも多くいました。それは時間が経てば解決される問題にはるかに近かったのです。人々は現時点で可能なことと不可能なことを基準に、今後もそれが続くだろうと信じる傾向が思ったより大きくあるようです。多くの場合、その限界の多くの部分はただ時間が経てば解決される問題でしょう。そうだとすれば、実は予想は、時間が経って解決されたとき何が起こるかです。それを基準に考えるべきだと思います。
それでしばらくそのような画像のようなものが出回っていた時期がありました。アーティストたちは「AIを止めなければ、AIが芸術を破壊している」と反対しますがプログラマーたちはAIがプログラマーを代替するとなるとむしろ喜ぶ、「早く代替してくれ」という話をするという画像が出回っていた時期があったんですよね。私はその画像が出回っていた理由がまさにその考え方のためだったと思います。今のAIは私たちに少し助けになり簡単に問題を楽に解けるようにしてくれるからであって今後もずっとこの程度だろうからプログラマーの職業やアイデンティティのようなものが脅かされることはないだろう、そういう前提があったわけです。ところが時間が経ち、さらに多くのことができるようになり始めるともっと真剣にこれがむしろ脅威だと感じる人たちは以前よりはるかに多く増えたのではないかと思います。そしてそれ以前にアーティストたちが見せていた反応を示す開発者たちも多くいるようですし。
すでにそのようなすべてのことが、今の水準の発展が大きくないだろう、そして質的な発展はないだろうし今後も大きく変わらないだろうという前提を置いているために発生することだと思います。ですが私は、それがいずれにしても現実だと考えています。では、もちろん時間が経っても発展できない問題はあり得る、解決できない問題はあり得るでしょう。それは非常に興味深い問題ですよね。そのような問題にはどんな問題があるのかその問題は今後も絶対に解決されない、こういう問題は非常に興味深い問題でありそれ自体が研究的な価値のある問題でしょう。
ですがそれとは別に多くの、今直面している問題は時間が経てば解決できる問題でしょうし今解けないとされる問題も引き続き解いていくことができる。それらを前提として考えることが良いのではないかと思います。Claude Codeを作った
ロ・ジョンソク Boris Chernyも、今できない問題があるなら6ヶ月後のモデルになると想定して6ヶ月後のモデルを相手に製品を作るという話をしていましたよね。その言葉は正しいと思います。それはなおさらフロンティア企業にいたからこそなおさら可能だったでしょうね。
キム・ソンヒョン そのような感覚は、おっしゃったように霧の前側にいるからこそ可能なのだと思います。ですが霧の後ろ側にいるとすれば6ヶ月後も似たようなものだろうという前提を立てやすく、そうだとすればそれに合わせて戦略を立てることになるでしょうね。
ロ・ジョンソク 私たちが冗談でよくこんな話をしましたよね。このAI分野では1ヶ月は、以前は1年かかっていたことが1ヶ月の間に起こるという話をしていましたがその1ヶ月1ヶ月の変化の幅、一種のグラディエントを感じる感覚が人によって今みな違うわけでそれによってどんなアクションを取るかが今それぞれ違って映っているようです。
チェ・スンジュン 希望があるとすれば、お話を聞いてみるとAIだけでうまく解ける問題、そして人間とAIのケンタウロス形態でうまく解ける問題、人間だけがうまく解ける問題、この3つが共存するのが少し幸せな社会ですよね。はい、そうかもしれません。
検証可能性とコンテキスト長の限界 37:52
キム・ソンヒョン ですが私はそれよりもう少し身近なのは、例えば今、RLの重要なパラダイムは検証可能性ですが、人間の職務をよく分析してみたところ実は検証可能ではない部分が多かったとかこういうことがもう少し可能なシナリオかもしれないし
ないかと思います。例えばコミュニケーションが重要だとか、コードと言えばコードでもより検証しにくい部分がありますよね。コードクオリティとか品質と言われるもの、
そういった部分が。RLVRから逃げなきゃいけないんですね。はい、そういった部分が
おそらくずっとボトルネックになる可能性はあるかもしれません。しかしそういった問題はみんなが知っている問題なのでみんなが解決しようと試みるでしょうしすでにある程度は方向性を定めて解決していっていると思います。
ロ・ジョンソク それで今Transformerモデルのコンテキスト長が実は1Mで固定されてからもう2年が経っているんですよね。それを超えるのは実はコストの問題もあるでしょうがフロンティア企業もようやくAnthropicやOpenAIも1Mを提供している状況じゃないですか。Googleは以前からやっていましたが、それによって生じる限界を
私たちは実はエージェントエンジニアリングという名前で補完していて、それが定着した感じがします。そして少し前に去年ソンヒョンさんがおっしゃった時に
この全てのトークンのentropyがそれぞれ異なり決定的なトークン、そういうお話をされていましたよね。これによって後のコンテキストが全て変わりさらにそういったものを媒介にしてその中に入るこのattention scoreのentropyを全て計算して意味的にコンテキストブロックを全て分割しそれらをメモリ管理しようという試みも私がおとといYouTubeで見た気がします。それであるモデルを新しいCPUと定義して
既存のvon Neumannアーキテクチャから認知コンピューティングのモデルを新たに構築するこういった試みも最近非常に多く見られていると思います。それでソンヒョンさんがおっしゃっていたモデルとハーネスの弁証法的な関係、これとも関連があると思いますが、あまりにも多くの試みがあちこちで起きていて私もどの方向が正しいかについては本当にわかりません。本当に多様な分化が起きている時期なんですね。コンテキスト管理においては、おっしゃった方法のようなもの、
コンテキスト管理: Sparse Attentionとマルチエージェント 40:08
キム・ソンヒョン そしてSparse Attentionのようなものがはるかに伝統的に考えられている技術ベースの方法でしょう。次に今起きている重要な軸の一つはマルチエージェントと自体的な要約ですね。Compactionと表現することもありますがモデル自体がコンテキストを管理するようにする、マルチエージェントやCompactionといったこういったものが結局モデル自体がコンテキストを自ら管理するようにするものなんですよね。現在私たちが使っているモデルの中でも
ロ・ジョンソク そのようなauto compactionをしてくれるモデルはありますか?ほとんどハーネスではなくモデル自体でそれを処理しているんですか?
ハーネスが処理?ハーネスがやっています。
ハーネスが処理していると見るべきでしょうね。はい。ただ、それ自体が
キム・ソンヒョン RLを通じて可能になったことの一つはそれ自体が学習できるようになることですね。
ロ・ジョンソク その部分をもう少し詳しく説明していただけますか。私がよく理解できていない部分のようです。最近多く出てきている試みの一つが
キム・ソンヒョン モデルがあるコンテキストを持って作業をしている、作業を進めているのですがコンテキストの長さが長すぎるわけです。大体コンテキストの長さを見ると「ああ、今はここでは終われないな。次に回そう」と。でも回す時にこれまでの作業進行状況を引き継ぐために要約しておこう。こういった意思決定ができますよね。
例えばモデルがそれも一種のツール使用になります。結局は次のモデルをツールと見て次のモデルに渡そうと。ただ次のモデルに対して自分が探索したことの情報を渡そうと。そうすると次のモデルに引き継げますよね。すると次のモデルもずっと実行します。やっていてこれでもダメだ、次のモデルに渡そう。これがモデルが連鎖するということですね。一種のチェーン形態になるわけです。マルチエージェントも同様に考えることができます。モデルを分割してこれを処理するためにこの走者、次にその次のモデルから受け取ってその結果を受けてまたやろう、という形で結局モデル間の連携になるんですね。
ロ・ジョンソク でもそういった傾向性も学習されたものですよね。RLを通じて。
キム・ソンヒョン 学習させることができるという構造に近いです。結果的に最終的に出てくるのはモデルがコンテキストを自ら管理する形態になります。それで見てみると「ああ、到底このコンテキストは処理しきれない。渡そう、
他のモデルやエージェントに」と。こういった自体的なコンテキスト管理が、管理できるような枠組みを作ることができます。
そしてそういった枠組みを作ることができて報酬を与えられればRLで学習することができるわけですね。
そしてこういった形態の作業を多く行っていておそらくCompactionのような企業がハーネスが入ってはいますがそのCompactionシナリオに対するRLを実施したはずです。
Compactionが正確にどのように動いているか内部は分かりませんが。そういったものが入っているはずです。
チェ・スンジュン モデルだってSecond Brain使っちゃいけない法はないじゃないですか。Zettelkastenできるわけですよね。
キム・ソンヒョン そしてそれがある意味良い方向かもしれません。コンテキストを増やしてそのコンテキスト内に全て入れようとするよりはSecond Brainを使ってツールを使用しエージェント使用を通じてコンテキストを管理できるようにすることがより合理的な方向かもしれませんし。重要なのは以前であればそれを全てハーネスでやらなければならなかったですよね。
ハーネスで「ああ、このくらいになるとコンテキストがこのくらいになるとこれを分割して、どう分割して、どう要約して」と。要約した後に「渡して、渡した後に結果を受け取って」と。こういったもの全てシナリオを作ってハーネスで作らなければならなかったでしょう。
チェ・スンジュン そうですよね。フックをかけてこうなってそうしていたでしょうね。以前なら、去年ならそうしていたでしょうね。
キム・ソンヒョン 今はtool useのような限界がありますがそれらがいずれにせよ学習されるということですよね。そしてこれも私の個人的な信念ですがAIモデルにおいて学習が可能なものと可能でないものには質的な差異があります。今は学習可能な形の
チェ・スンジュン コンテキストエンジニアリングがある、すでにある。コンテキストを管理できる方法だということです。
キム・ソンヒョン contextをモデルが自ら管理すると考えた場合それならcontext管理を中心にしたあるハーネスに対する観点が少し変わる必要があるかもしれませんね。それでDario Amodeiの最近のインタビューで
Dario Amodeiインタビューと継続学習展望 43:40
チェ・スンジュン わざわざ継続学習しなくても問題を解ける、そういうニュアンスを見せたようにも思います。
キム・ソンヒョン ただ私は依然としてその部分についてはcontextだけでは不十分だと思いますし継続学習、学習が起きなければならない、これは単にそういうcontext管理を超える問題ではあります。context管理の観点から見ればいずれにせよ長さが問題であって、contextをうまく入れればすべてできるという感じですが私はそれよりも学習が必要だとは思います。そう考えています。それでそのインタビューでもそうですが
チェ・スンジュン 我々も継続学習をやっていると言ってはいましたね。みんなやっているんですよね。
キム・ソンヒョン 以前は継続学習はやらないという雰囲気に近かったようですが、だんだんメッセージが継続学習をやっているという方向に近づいているようですね。
チェ・スンジュン みんなやっているようですね。私はあまりにも自明にこれを解決すれば
キム・ソンヒョン とんでもないことが起きるだろうとみんな思っていますし。2026年がちょうど2ヶ月過ぎましたが
ロ・ジョンソク 6分の1ほど過ぎて、DeepSeek V4がまた私たちにどのような驚きを届けてくれるかはもう少し待ってみることにして。3月ですよ。
チェ・スンジュン もうすぐAlphaGo weekが近づいていますからね。
ロ・ジョンソク 3月、4月、そして5月まで
チェ・スンジュン また予定されているイベントがありますよね。
ロ・ジョンソク 猛烈にまた突き進む時期がまた始まりました。あとソンヒョンさん個人的にニュースが一つありますよね。ソンヒョンさんが今週韓国を離れてイギリスに行かれますよね。その個人的な近況トークを少ししていただけますか。
近況トーク: ロンドンへのリロケーション 44:54
キム・ソンヒョン 転職をしまして、転職先が転居を求めたのでイギリスの方に行くことになりました。
ロンドンの方に行く予定です。行かれたらあちらもそれなりにfrontierが動いている街ですから面白いニュースにたくさん触れられそうですね。そうだといいのですが。
噂に聞いていた立ち聞きができたらいいのですが。どんな期待がありますか?ソンヒョンさんの研究の好みですとか
チェ・スンジュン 今後そのフィールドでこういうことをやってみたいという期待感のような。なぜなら冒頭でおっしゃったこととつながる部分じゃないですか。最近起きていることへの関心が薄れていくことときっとその次のステップはそれを克服するための何かニーズがあったのではないかと思いますが。二つの観点から考えられると思います。
キム・ソンヒョン あるモデルを作るにあたって、そのモデルがfrontierで競争することが非常に重要であり、我々がfrontierを超えることに焦点を合わせることもできると思いますが、私はそれとは別にモデルを作ることが、そして良いモデルにつながる作業をすることが楽しいです。より良いモデルを作るためにどんな作業をしどんな技術を開発することが好きな方だと思います。そしてモデル開発そのものの外側については私は技術の発展について
みんなが少し近づいている技術を待つこともそのためだと思うのですが。これから起きることを、AIの発展を楽しめるようになったと思います。
ロ・ジョンソク イライラするよりも楽しむのが私たちらしいですよね。
チェ・スンジュン FOMOに振り回されるよりは自分が得意なことに集中して軸を見つけていく旅路として個人的に感じられますね。また未来は予測するのが本当に難しいと思いますし。
不確実な時代のバランス感覚 46:36
キム・ソンヒョン みんなある未来の予測に基づいて不安になること、不安になるようでもありますし、不安にもなるし楽観しすぎたりもしますし、すべてのことが起きますよね。しかしそういった楽観や不安を抱くには未来は予測するのがあまりにも難しいのではないかと思いますね。例えば期待値を求めるとすれば確率と結果を掛けて合計しますよね。
ところが非常に多様な可能性があって非常に多様なその確率を知ることができないので不確実性の側面から見ると、ある一つのことを信じてその信念によって揺らぐほど私たちが確実に知っているわけではないのではないでしょうか。
ロ・ジョンソク 最近、全地球人と表現するとちょっとあれですが、本当に全国民が予測エンジンとして生きている時代ですからね。みんなが株式市場に張り付いてそれぞれのbettingをしているので。やっていない人がいないんですよ。predictionと言えば
チェ・スンジュン 冗談のような冗談が思い浮かぶのですが、私も知らなかったのですがpreプラスdictionなんですよね。diction、話すことを事前にやってみること、そういうことだったんですね。
ロ・ジョンソク ソンヒョンさん、ではイギリスに行かれたら私たちが時差をうまく合わせて引き続きこのfrontierで起きていることとそれについての考えを、私たち非常に混沌とした時期ですからね。みんなが混沌とした時期ですし、私は悲観と楽観、この間でバランス感覚が結局一番重要だと思うのですが、そのバランス感覚に優れた人たちは常にどんな未来でもうまく適応して正しいbettingをするようになり、あるいはリスク管理をするようになり、そういうことを目にしますし、あまりにも極端に一方に行く人は誰かはチャンスを逃したり、あるいは誰かは一度は当てられても次は当てられなかったり、そういうケースをよく見ますね。いつも私も回り回ってどのようなバランス感覚を持っているかが人間として今一番重要な徳目だ、このように考えているのですが。ソンヒョンさんがロンドンに行かれるとしてもこのように落ち着いて一緒に振り返りながら
チェ・スンジュン お話しできる機会は貴重ですので、私たちが簡単にはお離しできないという。わかりました。
ロ・ジョンソク それでは今日も、この2ヶ月間にあった出来事とこれから起こることについてソンヒョンさんの思考tokenをqueryしてみる良い場でした。私たちは少しの不確実性を通過しているところですので、また1、2ヶ月経てば面白いことがたくさん起きているでしょうね。
締めくくりと感謝の挨拶 49:01
キム・ソンヒョン はい、そうなってほしいです。
ロ・ジョンソク それでは今日はこのあたりで締めくくりたいと思います。ソンヒョンさん、ありがとうございます。