EP 99
Opus 4.8リリース、いまのAI競争と人間の仕事
Google I/OとOpus 4.8以後のAIの流れ 0:00
ロ・ジョンソク 録画をしている今日は2026年5月30日、 土曜日の朝です。 私たちは数週間勉強して戻ってきたのですが、 その間にGoogle I/Oがあり、 また新しいバージョンのOpusが発表され、 世の中はまた一歩進歩しました。 そこで、これに関連してスンジュンさんと一緒に、 どんなことが起きたのか、それらの含意は何なのか、 久しぶりにじっくり見ていきたいと思います。
Opus 4.8の43日リリースサイクルと加速するモデル交代 0:27

チェ・スンジュン 数日前でしたよね。2日前だったかな、昨日の明け方でしたか。 とにかくOpus 4.8がまた突然出ました。 まだ私は使ってもみていないのですが。 それでもタイムラインで状況を少し見てはいたので、 その話から一度始めてみたいと思います。 それで今ブログ投稿があり、 日付を少し確認してみました。 私がタイトルに「2カ月以下のリズム」と書いてみたのですが、 Opus 4.7が出たのが4月16日なんですよ。 つまり今ちょうど1カ月半くらい経ったわけです。 それでOpus 4.7が出た時、 私たちはたぶん19日に録画をしたのですが、その時はこんなふうに、 最近Opusが出ているのはおおよそ70日間隔だという話でした。 そうすると2カ月を少し超える間隔でしたよね。 ところが今は43日ぶりに出たことになるんです。 そうですね。2カ月に1サイクルくらいで
ロ・ジョンソク 回るだろうと予想していたのに、さらに短くなっていますね。
チェ・スンジュン 2カ月というのは何となく出てくる話ではなく、 あちこちで出てくる話なんです。 それでReiner Pope-Dwarkesh回をやった時、 Dwarkeshがflashcardなどの問題を解くことについて、 最近のモデルはこのChinchilla optimalの100倍くらい over-trainedされているようだ、という話をして、 そこで「2カ月」という表現をするんです。 つまりfrontier modelが2カ月間deployされていたなら、 それは2カ月ごとにretire されるというパターンがあったということを、 Dwarkeshも前提にしているわけですが、 その時に何tokenで学習されたのかを、 かなり粗いと言うべきか、 とにかくざっくりざっくり推定したものなんです。 とにかくそこで2カ月という表現が出てきます。 つまり2カ月ごとにモデルが新しく出て、 retireしていく、そういうパターンがあるということです。 そしてこれも国内ニュースに移された内容ですが、
Sam Altmanがオーストラリアのイベントでビデオ対談をした時、 「2カ月で世界が変わるのに会社の年間計画は必要か」という 刺激的な文句を抜き出していましたが、 とにかくSam Altmanがそういうニュアンスの話をしたようです。 それでこの2カ月というのが、 2026年のある種のパターンだと思っていたんです。 ところが43日が出てきたので、私もちょっと、あれ、と思いました。
シンギュラリティへ向かう開発速度の加速 2:43
ロ・ジョンソク でもこれは、私たちがシンギュラリティという表現をする時に、 いつも予想していたことじゃないですか。
チェ・スンジュン この周期がどんどん短くなっていく。 発展速度は上がり続け始めて、
ロ・ジョンソク ある時点になると、それが無限に増加するその時点になる。 そしてその地点をシンギュラリティと言うわけですが、 その地点に向かっているわけですね。
AnthropicのOpus効率化とMythos級モデルの予告 3:05
チェ・スンジュン Anthropicのブログで私はベンチマークなどを見るよりも、 一番最後の話が少し印象に残ったので、一度読んでみます。 ユーザーはOpus 4.8が以前のモデルに比べて小さいながらも、 はっきり体感できる改善を遂げたと感じるでしょう。 まだやるべきことが残っています。 私たちはOpusと同じ能力を多数提供しながらも、 より低いコストで使えるモデルを開発し、 リリースするために努力しています。 そして、より高い知能を備えた
新しい系列のモデルをリリースする計画です。 それでMythos Previewを 一部の少数の組織が使っているのですが、 安全装置が準備できれば公開すると言っていましたよね。 ところがその安全装置の準備が 急速に進展していて、今後数週間以内に Mythos級モデルをすべての顧客に提供できるだろうと 期待しています。 ですから今後数週間というのは10週以下でしょう。 10という数字以下だろうと考えることになりますが、 そうすると最大2カ月、そうですよね。
ロ・ジョンソク 何かこのモデルrange、階級を少し調整している感じですね。 これからMythosが新しいOpusになり、OpusがSonnetになり、 実際、今のSonnet、Haikuはいくつかの 本当にembeddingモデルらしい そういう単位task以外では有名無実じゃないですか。 みんなClaude Codeを使う時もOpusを付けて使っていますし。 だからとにかくOpusが
チェ・スンジュン 名前としてどう変わるかは予測しにくいですが、 より高い階級のモデルが出る予定で、 それがおそらく夏にまたがる、夏から初秋 ただ今のパターンを見ると、このくらいなのかなと。 私は6月か7月に 何かOpus 4.8くらいが出るだろうと思っていたのですが、 5月末に出たわけです。 つまりこれも前倒しして推定するなら、 7月くらいに何かあるのではないかと 考えるようになります。 7月または8月。 それで、そうなるとまた新しくunlearningして、 学ばなければならないことがありそうですが、 まだ始めてもいません。
Gemini 3.5 Flashと夏のモデル競争の兆し 5:12

チェ・スンジュン ところで私たちはただ大きなイベントになるだろうと期待していたら、 結局ふたを開けてみた時には、触れていなかった Google I/Oもまたあったわけですよね。 Google I/OではGemini 3.5 Flashが主役だったじゃないですか。 つまりProは準備できていませんでした。 でもキーノートの話を聞いてみると、 ずっとその話をしているんです。 数週間後には私たちが次のものを公開できるだろう。 夏ごろになりそうだ、そんな話を少ししていたんですよ。 だからこれが時期として合ってきている、 今の方向性として、夏に何かGoogleも今の状況で、 もちろん全社的に、全方位的にこれを防ぎ切ってはいるものの、 大きな一発はなかった感じだったのですが、 それらを、それが何になるかは分からなくても準備していて、 その次にAnthropicは今、先手を打って出てきていて、 ところが依然として性能についての話は、 タイムラインではGPT-5.5の話をしているんです。 Codexの話をしていて、だからGPT-5.6が出るタイミングは、 Opus 4.8がGPT-5.5を倒せない感じの時は出てこず、 だいたいこういう話が出てくる時には出るのでしょう。
トークン経済とレイテンシ中心のモデル選択 6:26
ロ・ジョンソク おそらく。ところでAnthropicも 先ほど「小さくなったモデル」という表現を使ったじゃないですか。 Opus 4.8は確かにOpus 4.7やOpus 4.6と比べて 少し小さく、効率化されたけれど、 性能は維持した、そういう形のモデルだと 話していて、また外から見えるベンチマークや 人々の反応を見ても、Opus 4.8の性能が 落ちたようだという話は。 そうですね。いくつかはありますね。 ベンチマーク指標は
チェ・スンジュン 実際にOpus 4.7比で落ちているものもありますね。 上がっているものもありますし。 だからこれは結局、このtoken economicsで 生き残るための必死のあがきではないでしょうか。 変化し続けている時期ですからね。 これは昔、自動車の時もそうだったんですが、
ロ・ジョンソク 自動車が排気量競争をしていた時期があったんですよ。 それで4,000cc、5,000cc、6,000ccと次々に出てきて、 ある程度効率化を実現した後には、 商業的な運用ではこのくらいで十分だとして、 少しflatになった時期がありましたが、 モデルもそうなるのではないかと思います。 実際、最近の私たちの業務の大半と言えば、
CodexやClaude Code、あるいは それで構成されたagent systemとinteractionすることが 会社の仕事になりつつあると感じているんです。 ほとんどの人も、以前はメールとPowerPointと Excelが立ち上がっていたとしたら、 今は画面にほぼagent applicationが立ち上がっているんですよ。 私たちの会社は、そちらの方向に ほとんど全部変えておいて、人々が完全にSlackに張り付いて agentと仕事をするだけで仕事が終わるように そういうふうに少し作っているところなんですが、 ただ物足りなく感じる部分はlatencyです。 この話が出てくると思うんですよ。
なぜなら、何か満足できる結果が出た後に 次に求めるのは当然、それが早く出ることなんです。 そしてそのlatencyが定められた品質の範囲内で出るなら、 それがOpusであれ何であれ、最高級モデルではなく ただ速くて良いモデルという概念が生まれそうです。 それがGoogleでこのFlashモデルをメインとして 今回打ち出した理由。 そういうところをずっと触っている感じです。
チェ・スンジュン ただ、人々は実際にその性能が出ないと すぐ上のtierに行って、 そういうものを探っているのが最近のようですが、
Gemini FlashのDoom起動デモと長時間タスク 8:44
チェ・スンジュン Gemini 3.5 Flashに関しては、 私はこの動画ひとつが一番印象に残りました。 Varun Mohanが見せてくれたものなんです。 はい、一度見てみましょうか。
チェ・スンジュン それで、これはVarun Mohanがデモした時、 何かこれを読んでから見るとよさそうですね。 93個のsubagentを稼働させて、 15,000回余りのmodel callを通じて、 custom kernel、filesystem、driverを一から書かせて、 12時間後にDoomが起動しました。 それなんですよ。なのでこれをずっと送ってみると、
そういうものをAntigravityが自分でやって、 OSを作り、後にはそこでDoomを動かす、 ここではDoomを動かす部分は出てこないようですが、 これはおそらくsourceが今どう変わっているのか、 それを見せているものですね。 Varun Mohanが見せてくれたものでは、 それが全部出てくるところまで見せていたんですよ。
だから結局、こういうある種のlong-horizon作業を 低いtoken消費で、ただGemini 3.5 Flashは 以前のFlashより3倍高いモデルでしたね。 だから適正水準のモデルで それをやり遂げる作業を見せているのが、 それでも少し印象に残りました。 だからそれを皆やりたがっているようですが、
Anthropic Dynamic Workflowsとサブエージェントの調整 10:00
チェ・スンジュン Dynamic Workflowsが今回Opus 4.8と一緒に出たんですよ。 これはもうGoogle I/Oの話ではなく、また、そうですよね? そうですよね? もうAnthropicの話に戻って、
ロ・ジョンソク 昨日出たDynamic Workflowsというものについて。
チェ・スンジュン たとえばultracodeという表現を使うと、 UIが派手に変わって、 また何か面白いものが出てくるんですよ。 なのでここにはそこまでは出ていないようですが。 一度ざっと見ていただくと。そして最近のClaudeは こういうかわいい感じがコンセプトみたいですね。 動画をとてもきれいに作るんですよ。 ただ一度さっと過ぎていくので、 どんな内容なのか詳しく見るのは難しいですが、 それでも何かアプリを作ろうとしているようです。 演出なので、あんなに速く回っていなかった可能性はあります。 ただチェックリストをサクサクと進めて、 pushしてmergeして、そういうことができるということですが、 ここではDynamic Workflowsが 紹介されてはいませんが、そういうふうにやることになる。
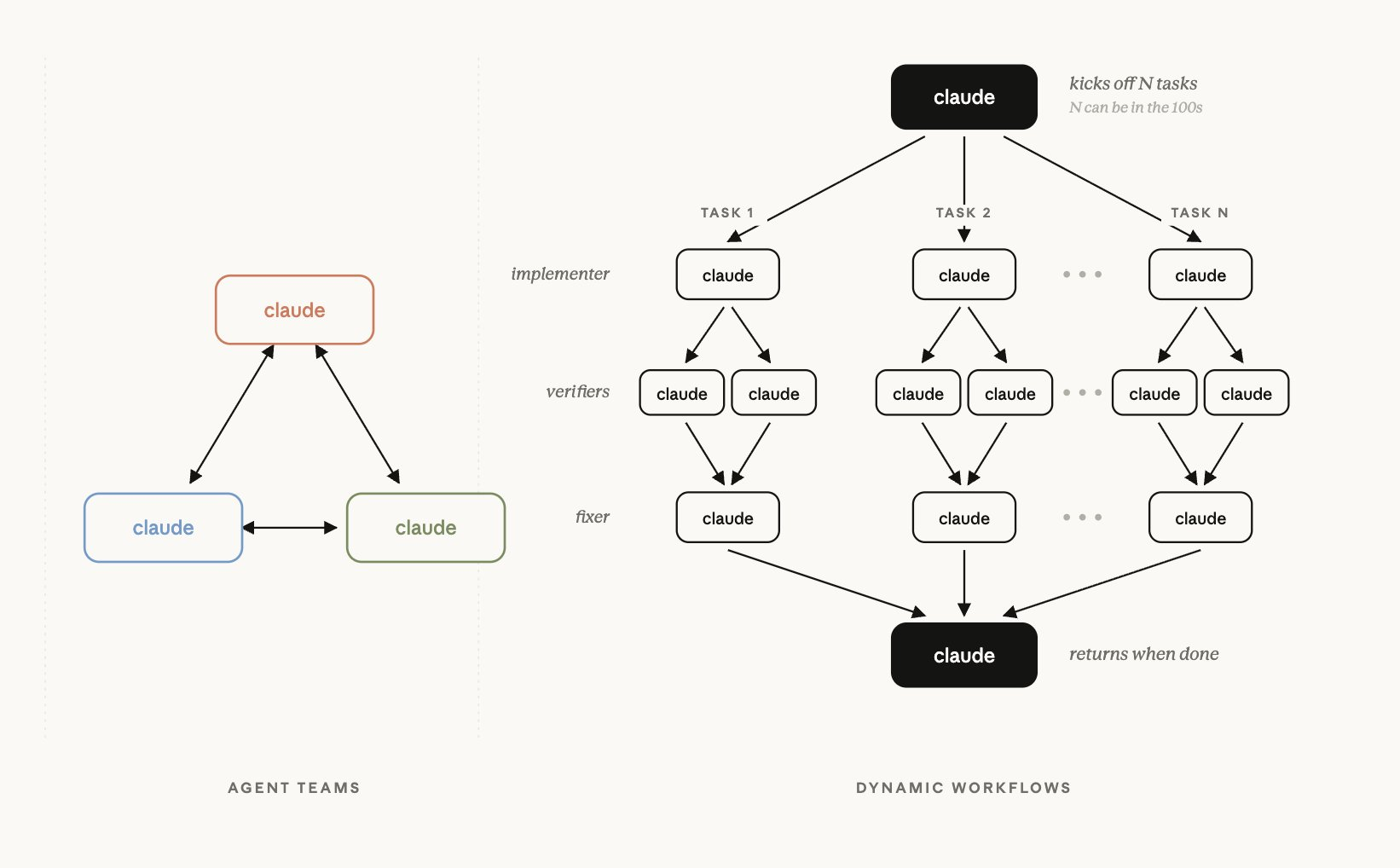
それでDynamic Workflowsとは何かというと、 Cat Wuが上げたツイートを見ると、 こういうふうにClaudeがいて、複数の別のClaudeに渡して、 そこで渡して、それを総合して総合する、 つまりこれは実際、これまでよく見てきたそういう概念なのですが、 Agent Teamsという既存のAnthropic製品とは少し変わる。 ただ、これで興味深いポイントは、 大きなモデルがずっとこれを調整するのではなく、 最初にどうorchestrationするかを決定的なコードとして書き、 それができるまでずっと進める、そういう感じでした。
ロ・ジョンソク すると、この分岐点をモデルが全部読んで その合間合間で判断するのではなく、 最初に何か、何と言えばいいでしょうか。 dynamic harnessと言うべきなのか、 こういうharnessを自分たちで生成した後に。 そういう感じです。
チェ・スンジュン 私もまだ使っていないので正確にはわかりませんが、 動画をいくつか見たのと、この文章を見た限りでは、 これはsubagentを調整するJavaScriptということなんです。 Dynamic Workflowsが、だから これは見方によってはモデルに任せると、 実際モデルは怠けるじゃないですか。 評価して、自分がやったことを、 自分に評価させると、できたと嘘をついたりするケースが、 特に難しい仕事をさせる時にはそういうことがありますが、 そういうものを、どうにか回数を少し締めようとする時には、 決定的なツールやコードを使ってチェックすることが必要ですが、 それをまた自分のcontextの中で 評価させると問題になるんですよ。
だから最初から新しいcontextであるsubagentたちの中で そういう何らかの状況で、それを手際よく処理して、 もちろん、これがこういう方式のとき、 さっきのような図での方式のときは、 この集計することの問題は、集計するまで待つその、 何だっけ、pipeline parallelismに似た感じで、 ここに問題が起きそうだとは思うんですが、 とにかく、その時間とは別に、こういう感覚的な感じでやり遂げる、 何か新しいものを紹介した。 ところがタイムラインの反応は、私たちもそういうことをやっていました、というのが すごく多かったんですよね。 これはすでにある概念で、Anthropicが少し早かったんだろうな、という そうですね。またコンセプトとしては、私たちのoh-my-open agentや
ロ・ジョンソク OMXみたいなところでも、かなりうまく回していたコンセプトではありますね。
チェ・スンジュン そういう少し愚痴というか、虚脱感のようなものが タイムラインには少しありました。
Managed AgentsとRecursive Language Modelsのつながり 14:00

チェ・スンジュン ただ、ここのこのブログ投稿では 出てはいないんですが、その前にManaged Agentsを扱った、 少し脳と手を分離するという記事には、 興味深い研究が一つ引用されていて、 ここでprior workとして、 今見ると、たとえば、 contextが一種のobjectになり得て、 どこでのobjectかというとREPL、つまりREPLです。 つまりREPLはコーディングツールじゃないですか。 feedback loopがあるread-eval-print loopでしたっけ? 急に思い出せないんですが、 とにかく普通、私たちはREPLを使うと よく言うんですが、 そういうものをLLMがprogrammaticallyに できるようにする、 ある決定的なツールを使って行う、そういう感じです。 ところが、ここで引用した論文が Recursive Language Modelsという論文です。 それで、このalex zhangという方がこういう話をしました。 つまり、私たちのpaperを読んでみてくれと。 これはすでに行われていた、そういう何らかのregimeがあるんだと。 そういう話をしたのは、これ一つだけではなかったんですよ。 ところが、このRLMというものがDSPyに入っていたんです。 それで、
ロ・ジョンソク でも、そのRLM論文の著者にOmar Khattabがいますが、 Omar KhattabはStanfordでDSPyを作った人ですから、 当然入れたんだと思います。 私はそれを、DSPyをよく知らず、そういうものがあって、
チェ・スンジュン 人々がよく話している、という程度だけ認識していたんですが、 こういう形でやることが、 少しまたtrendになりつつあるんだな、と。それで、
DSPyとTextGradから見るメタ最適化 15:40
ロ・ジョンソク 単にDSPyや、それからTextGradとか、 さっき話したものや、そういうものを見ると、 一種の全部meta optimizationじゃないですか。 スンジュンさん、だから結局、一つのlayerが積み上がると、 そのlayerの上にまた別の何かが積み上がり、 そのlayerの上で積み上がって、 それで、このoptimizationの階層をもう一段上げる、 そういう感じだと考えれば合っていると思います。 あのDSPyも結局、あるprompt自体の性能も、 あるmeta optimizerを回して継続的に上げられる。 Karpathyが話していたauto researchの概念とまったく同じなんです。 どんな問題でもevaluation metricさえ存在すれば、 モデルは私たちが何を設定しても、 ただoptimize computingを投入して、 性能を上げる方向へ、つまりただ検索する方向へ転換して、 解けるという、その核心概念なのだと思います。 ここを見ると、いくつかだけ読んでみると、
チェ・スンジュン LLMにcode executionをさせて、 recursive sub-LLM callをさせることが、 DSPy側で、つまりRLMで扱っている話で、 それからManaged Agentsでは、 session abstractionをこうしてcontextの外のobjectとして置き、 sandboxとREPLを使う、 そういう何らかの接続線がある部分がありました。 それからDynamic Workflowsは、それをorchestrationするときに、 scriptに何かを置くということです、contextではなく。 だから、これが決定的なツールを、 結局harnessがそれをやるわけじゃないですか。 それでscriptを活用して、それをぎゅっと締め付けて、 制御させる、そういう感じへ進んでいます。
ただ、おそらくそのGemini 3.5 Flash、 さっき高速に動いていた映像で言おうとしていた、 隠れている部分も似た階層なのだろうと推測するんですよ。 ただモデルがやるのではなく、 それを行うscaffoldやharnessを使ってOSを作り、 Doomをすぐ立ち上げられるくらいに、 一度にずっとlong-horizon taskをやるわけです。
ロ・ジョンソク そうなんですよ。 そのlong-horizon taskも実際には中をのぞいてみると、 これがきれいにone-shotで終わったというよりは、 数多くのerrorを、そうですね、errorを、 絶えずevaluationを回しながら、 これは間違っているな、これを直してきて、またこれは間違っているな、 これを直してくるという、少しいわゆるtinkeringの過程が、
チェ・スンジュン ものすごく。数学で起きることも似ていますが、 仮説を立てて、それを実験して、問題が起きたなと。 記録して、その記録から洞察を得て、次の仮説を立てて、 これをずっと押し進めていくんですよ。 そうですね。だから、今紹介してくださった文章も、
ロ・ジョンソク 結局、このモデルに該当するobjectiveを何に変えたのかだけが 違うのであって、使っている方法論は実際には同じmetaです。
Code as harnessとCloudflare Dynamic Workflows 18:27
チェ・スンジュン そういう話をCorcaのCTOであるギュヨンさんとしていて、 ギュヨンさんが興味深い表現をしてくださったんですが、 code as harnessという表現をしてくださいました。 聞いていて、少し耳になじむ表現だったんですが、 そうしながらCloudflareのDynamic Workflowsと このProject Thinkを紹介してくださったんですが、 私はこれを知らなかったんですよ。 ところが、ここも名前が同じですね。 Dynamic Workflowsで。 それで、ここでも次世代agent構築において、 つまりcode as harnessになる、 だからここでは、何を持ってきてもそれをやり遂げられる、 あるcloud platformを作る、そういうことをしていて、 同じ話がまた出てきますよね。 長期実行agent、actor model、Durable Objects。 だから、みんなこういう方向に進んでいるんだなということを、 詳細にではないとしても、 感覚的に把握する程度でした。
企業のエージェント活用で高まるレイテンシとharness需要 19:22
ロ・ジョンソク そうですね。私も私たちのSlackで、私たちの会社のメンバーたちが taskを指示するものを毎日見ていますから、 そうすると、agentにかなり複雑な仕事をさせると、 基本20分、30分ずつは回って、どんなに短く回っても、 10分ずつは回るんですよ。 そうしているうちに、latencyに対するニーズがどんどん出てくるんです。 それから、あのharnessも 今は私たちが 公開されているharnessを主に使っているんですが 自分たちだけのharnessを使う必要があるんだなという そういうニーズもずっと出てきています。 そうですね。 ただ、あとで一度紹介したいとは思っているんですが
チェ・スンジュン 私が1年前にMinecraftでagentを作ることを 最近また見直しているんですが、世界が変わっていたんですよ。 昨日寝る前に10時間のものを走らせて寝たんですが 朝には何か成果が見えていたんです。 ただ、その過程を見ても、Minecraftの最新版に まだMineflayerというボットを付けるものが まだオープンソースプロジェクトとして追いついていなくて 私がゼロから一度作ってみたんですが それをやるときにprotocolを推測して、block IDを抽出して そうやって積み上げていくのがとても面白かったです。 あとで一度紹介しますね。
ロ・ジョンソク もう今は、考えればいいという感じがありますからね。 ただ残念だったのは、起きて見たら
Codex weekly limitが8%残っていると報告されていて tokenをたくさん使うことになるわけです。
AIが解いたエルデシュ問題と数学研究の変化 20:42
ロ・ジョンソク それで、そういうこととは別に 数学でも5月に興味深いことがあったんですが これが関係していると、少し前にもちらっと申し上げましたが 関係があるように感じるんです。 それで私も数学を深くやっているわけではないので ざっと見ただけなんですが エルデシュ問題の一つを 解く、エルデシュ問題はいろいろありますが そのうちの一つを解くことをモデルが成し遂げて 世界がまた少し驚いた時期が5月中旬にありました。 それでOpenAIがそれをGPT-5.5ではなく おそらくこれは内部モデルだったようです。 内部モデルでそれを特殊なscaffoldingによって成し遂げたようなんですが そうしたらSholtoが今はAnthropicにいるじゃないですか。 それでそれを一度褒めて その次にMythosも成し遂げたという投稿をしたんです。 ただ、ここにリンクは今出していませんが、Geminiも成し遂げた、 というのがありました。 それで似たようなものをみんな成し遂げた。 ただ、それ以外に私が面白く見たのは Noam Brownのこの表現が面白かったんです。 それでこれがリンクをたどっていくと どんどん別の人へ移っていくんですが それを私がここに翻訳しておいたんです。 ただ、翻訳はしておきましたが、意味を読み取るのは難しいです。 ただ、いずれにしても数学にいる方々がみな これが非常に興味深いことを話していたんですが
AlphaGo以後の囲碁のように強くなる人間の数学者 21:59
ロ・ジョンソク Noam Brownの話を先に紹介すると Noam Brownは、AlphaGo以降、人間の囲碁棋士たちの実力は 目に見えて向上した。 私は数学でも似たパターンが現れると思う。 それでこれはこの話、 数学者たちが話した内容は何かというと OpenAIのモデルが解いた話ではなく 数学者たちが解いた話なんです。 それで、そのエルデシュ問題を モデルが成し遂げたことが知られたあと 数学者たちも刺激を受けて 何かを急速に前進させた現象が起きたということです。 それで、それがとても興味深い。 それで、ここにTimothy Gowersがいますが、また有名な数学者なんです。 それで今回は加法的組合せ論のまた別の問題、 主要な問題が解決された。 今回はAIではなく人間たちが成し遂げたことだが 単位距離予想に対する AIの解法に関連した方法を使った。 AIの解法を学んで活用したということですね。 ただ、それが申眞諝九段などがこうされていること、 AIとたくさん対局しながら自分で学んでいくじゃないですか。 そういうことが起きているわけですが 今回のOpenAIのその試みも興味深いのは 人間にとても重要な役割を与えたんです。 モデルが一人で推し進めてやるのではなく 評価を人間がきちんと行う そういうメカニズムが少し入っていて 既存の試みとは少し違っていたんです。 つまりhuman in the loopを 重要に少し扱う感じが生まれ始めました。 それでこれはGPTと読んだ内容なんですが AlphaGo以降、人間の囲碁が強くなったように、AIが数学でも 人間の探索空間と 直観を広げ始めたのではないかという話です。
ロ・ジョンソク あまりにも当然にそうなると思います。
チェ・スンジュン OpenAIの今回のエルデシュ問題でも ただ人間、人間の一人の数学専門家であれば 一つの数学分野の中でもいろいろなジャンルがありますが 数論に精通した学者、組合せ論に精通した学者、 でも互いの文献を知らないことがあり得るじゃないですか。 ところがAIはpretrainingを通じて全体を知っているので その文献同士をつなげられるようになる そういうニュアンスがかなり大きかったんです。 それで、そういうものに刺激を受けて 人間もこういうものをつなげられるんだと気づくようになると 転移させることが可能になるんですが そういうことが起き始めたというシグナルを読み取ることになります。
それで、ここにこうしてただモデルと会話した内容は 面白くはありますが、そのままさらっと流します。 つまり、人間の創造性の地形を変えた出来事だ。 創造性を殺した出来事ではなく。
生成AIによる認知低下とintelligence augmentationの共存 24:31
チェ・スンジュン それで私が最近よく悩んでいたのが 生成型消化不良という話を 去年の春ごろにしていたんですが、最近考えていたのは 生成型認知低下なんです。 自分の考えをしきりにoffloadingして、モデルに委任して 代わりに考えさせていると 自分の考える力、筋肉が減っていく感じ。 それからDwarkesh編を勉強しながらも flashcardに刺激を受けたのは、深く会話をしてから それについてflashcardを作って質問してみると 多くのことを自分がすぐに忘れているんだなと。 代わりに生成させることは、認知低下を引き起こしたということです。 つまりskillが減っていく、自分の力量が減っていく そういう感じを強く受けて、悩みが多かったんですが そういうことは現在、明らかに起きているんです。 懸念される形で。ただ一方では まったくintelligence augmentation またはamplificationをする部分があります。 だから今回もやはり、この局面でも また技術が格差の道具として働いているのか そんなことを少し考えてしまいます。 私は超知能に近づいたり、AGIに近づくほど それは格差を薄くする何かになるだろう、 新しい、前人未踏の機会に なるだろうと去年の夏に想像していたんですが 実際にふたを開けてみると これがslot machineのようにdopamineは出るけれど 仕事はもちろんこなすけれど、 自分の能力そのものは低下することが起きているかもしれず 一方では能力を獲得するケースも起きている。 これについて少し考えさせられるということです。
AI時代に変わる仕事と人間の条件 26:05
ロ・ジョンソク これはまた、観点をどう見るかによって 正反合の形でずっと変わっていく問題のような気はします。 目先では格差を広げているように見えますが、結果的に見れば 格差をかなり縮めることになるでしょうし
チェ・スンジュン 平均は上がる可能性がありますよね。 いずれにしても。
ロ・ジョンソク そうですね。昔は仕事の概念が、私たちが考える 今の概念とはまったく違うものになる気がします。 以前、たとえば家を建てるときに 単位時間あたり土をどれだけ多く運べるかと言えば 当然、体力と要領、 そういうものがその人の能力値だったんですが ショベルカーのような掘削機のような そういう機械が出てきたことで 実際、今はその資格試験、 運転免許試験に変わっているじゃないですか。 それと同じように、私たちが まだ像を結べてはいませんが 知識産業に関する部分も、何かを私たちが思考の筋肉で 問題解決するために使ってきたのだとすれば それがもはや必要なくなり、別の形の、別の層位の 何か新しい資格や能力のようなものが 生まれると見るべきでしょう。 私たちも今、agentで毎日仕事をしているので これは果たして、仕事がうまいとは何なのかについて 私も本当にいろいろ考えていますし 今日扱う話ではありませんが これは非常に悩ましいことなんですよ。
チェ・スンジュン 人間の条件とつながることなので、考えることが 人間の仕事だったじゃないですか。 ところがそれが移動しているので、かなり悩ましいです。
チェ・スンジュン 個人的には。 考えることが人間の仕事だというのも、実は通念ですよね。 果たしてそうなのか。そうですね。 では挑戦的な問いを投げかけられそうですね。
Simon Willisonが見るOpenAIとAnthropicのproduct market fit 27:40
チェ・スンジュン それで今日の話の最後は、少しまた現実に戻って AnthropicとOpenAIは product-market fitを見つけたようだ。 Simon Willisonがこの投稿をしたのが、とても印象的でした。 5月27日だったんですが、 OpenAIは703件の求人投稿をしていて Anthropicは390件の公開求人を出しているということを APIを使ってSimonが分析していたんです。 なのでこれを全部読むわけではありませんが、それでも読んでみると 企業顧客がもうAPI料金を払っている。lock-inされたわけです。 もう川を渡ってしまったじゃないですか。 使わないわけにはいかないんです。 もちろんです。 1人あたり100ドル、200ドルの料金プラン、
ロ・ジョンソク ほとんどみんな一つずつ付与していませんか。もうエンジニアだけでなく 他の人たちもClaude Codeを今はみんな使っているので 私たちのところでも非エンジニアの方々が 100ドル、200ドルのプランを使う比率が 高くなっています。
チェ・スンジュン 私はagentを広範に使っている企業も 似たような割引を受けているのだと思っていました。 ところが実は完全に間違っていた。高くなっていて もうAPI料金を払わなければならないんです。 払わないわけにいかないので、今はそのusage feeについて みんなペナルティを課しているじゃないですか。 Claudeもそうですし、Geminiもそうですし OpenAIはまだ大丈夫ですが、usage feeのペナルティを課されて API料金を払わなければならないとなると、Slackに入れるのは かなり高くなるんですよ。 でも使わなければなりません。
ロ・ジョンソク ではCodexに移ればいいですね。 そうですね。ただCodexも持ちこたえられなければ もう変えられるので
チェ・スンジュン 完全に安心はできない可能性があると思います。
トークン価格とAI需要の長期的な方向 29:11
ロ・ジョンソク ところでどう見ていますか。 このトークン価格は、短期的には上昇余地が大きいんですが。
チェ・スンジュン 中国側も上昇しています。 需要が増え続けているわけですよね。
ロ・ジョンソク 今メモリ価格が上がっているのを見ると 需要が増え続けているのは確かですから。 ただ、この需要には二つの見方があります。 使う人はもうみんな使っていて、ほぼ終わりに来た、 このplateauに到達したと見る見方があり、 ただ、そういう見方を持っている方々は ほとんど大半がこのtech worldの外にいる方々です。 外にいて、投資の観点から これはこうだああだ、AnthropicとOpenAIが 危ないと解釈する、そういう勢力があり、 でもこの内側でJensenのkeynoteに熱狂して それからOpenAIやGoogleの発表を見ながら こうして拍手を送る そういうテックの内側にいる人たちの立場から見ると まだようやく始まったばかりではないか、とよく思います。 まだようやく始まったばかりではないか。トークン価格は 電気のようになる気がします、電気。 だからそれがどうなるかは
チェ・スンジュン 私にも正確にはわかりません。この前の段階での予測は 当然安くなるだろう、だったじゃないですか。 ところが今のラリーが、このピークが どこまで行くかはわかりませんが、少し傾きが変わった感じで それがまたどこへ行くかは誰にもわからないことではないでしょうか。 ただ私は歴史的に見たとき
ロ・ジョンソク これは下がるに賭けるほうが、無条件に確率の高い値です。
チェ・スンジュン なのでいずれにせよ企業はlock-inされていて お金を払っているので、お金を払っているわけですから 少なくとも二社はproduct-market fitを見つけたというのがSimonの見方です。 IPOをどちらも準備していますが 今、多くの人が料金を払っているので もしかすると黒字転換も可能なのではないか。 そういう話があるということです。 IPOの前に。そういう話が少し出ていて
AI企業の採用拡大と開発者雇用の再解釈 31:13
チェ・スンジュン それに続くのが、拡大しているということです。 それで自分で調べてみたら OpenAIは現在703件の公開求人を出していて そのうちサポート関連が229件、 いろいろなものです。そしてそこにはGo To Marketや FDEのような職務が含まれる。 そしてAnthropicも390件の公開求人を出している。 それでMetaは最近8千人をlayoffする件で また話題になっていましたし Microsoftもずっと少し減らしている感じだったのに こういう方面では増やしているということですよね。
そしてまた最近、韓国のタイムラインで出ているのが 開発者の雇用が増えている部分もある、 というようなニュースを少し見たんですよ。 だから今これもまた、二つが両立しているのではないでしょうか。 一方ではtalent densityを高めて 小さなチームでこう押し進めることも起きていますが またこうしてAIを使う開発者たちは 依然としてAIだけではないので、さらに必要になって 雇用を増やすことも同時に進んでいるのでしょうか。 私もよくは分からないんです。
エンジニアからAI native problem solverへの転換 32:19
ロ・ジョンソク 私は今、開発者という表現の意味が…
チェ・スンジュン みんなただのビルダーだと? はい、みんな新しい層の上で
ロ・ジョンソク ある種のproblem solverになったのであって、 Claude Codeを扱えるなら その人たちを新しいエンジニアと呼ぶのか。 エンジニアの誰一人として、今コーディングはしていないんですよ。 ただ今、問題解決がうまいエンジニアを見ると どういうエンジニアかというと、それでもさまざまな層について AWSでどんな問題が起きるのか、 それからWebサーバーでどんな問題が起きるのか、 Redisでそのworkloadをどう分散するのか、 DB最適化はどうすべきか、SQLとは何か、Cとは何か、 そういったOS全般から アーキテクチャリングからサービスまで その多様な部分の観点を持っていた人が Claude Codeに出会ったとき、はるかに強力なんです。 ジュニアがやるべきだったことを。 ただ問題はそこまでなんです。 顧客はそうしたアーキテクチャを買うわけではないんですよ。 顧客は自分たちの問題が解決されることを買うんです。 では以前、何が速くなったのかというと 何かアプリを作ってくれと言われたとき その単位アプリに要件が生まれて その中でPMが要件分析をして デザイナーがそれを展開したあとPRDを書いて それをtaskに分けて、あれこれして ビルドされて顧客の目の前に新しいUX workflowを 持っていく、その区間だけが短くなったのであって、 ではそれを使って本当に顧客をさらに獲得し 問題を解決していく その区間は依然として残っている問題なんですよ。
では今度は、その能力をすべて備えた状態で 顧客の問題が何なのかを理解し それに合わせて、もはやマーケターや営業を間に置いて 顧客に対応するのではなく、その人たちすら飛び越えて 顧客と直接話さなければならない能力が必要なんです。 つまり今は、そうしたエンジニアリング能力を備えて 顧客の問題を解決できる、 私たちのいわゆる昔の表現で言えば マーケターやセールスの能力まで全部備えていてこそ この問題が一度で終わるんです。 だから今、エンジニアの採用が増えているという部分は 私は慎重に見なければならないと思います。 ただ伝統的な基準でのエンジニアの人数が増えて Claude Codeを使える?はい、使えます、と そういう人が会社の中に一人増えて座っているからといって 何かが良くなるわけではないんですよ。
結局は、私たちがずっと話していた顧客の問題に関する そのdomainの何らかの問題解決点、 それをClaude Codeにどううまくやらせるか、 Claude Codeにどううまくやらせるかというところで エンジニアリング能力があることは助けになりますが そうした能力さえも、実は私たちが agentでworkflowを作っていると よく感じることですが、どんどん暗黙知化されて agentのメモリの中に蓄積されていくんです。 それで以前は、昨日の売上、とだけ言うと それが勝手にhallucinateしていたとしたら その間ずっと積み上がってきたcontextがあるので 今はただ私たちのagentに昨日の売上と言っても 正確に会社が望む観点で加工して持ってくるんです。 同じように、このエンジニアリングに関する アーキテクチャリングなども十分に むしろより構造的に暗黙知化されて agentに蓄積され得るので だんだん、ある意味では私たちが過去に持っていた エンジニアリング能力も少し必要なくなっていくんです。
encapsulationされて下のlayerへ積み重なって降りていくものなので 今もっと明確に表現すると、これからはエンジニアという概念より ただ全員が問題解決者であり、単位事業の事業家だと 定義するのが正しく、私も会社でメンバーたちに 今、私たちがClaude Codeを使って伝統的な概念で エンジニアリングをしているその職群のうち 伝統的なエンジニア出身は半分です。 残りの半分は伝統的なエンジニア出身ではありません。 以前はマーケターだった人、 以前はただのPMだった人。 さらには、そういう方々がClaude Codeを組み合わせるようになり すでにエンジニアたちが作ってくれた暗黙知promptを そのまま持ってきて、そのskillとして呼び出して使い始めるので 問題が一度で終わる経験をたくさんするんです。 これからは人材に対する概念が変わるだろう。
まだその用語が明確に出てきていないのだと思います。 ただ私たちがそれを 総称してエンジニアと呼んでいるだけであって もし単に、何の脈絡もなくClaude Codeを使える エンジニアを採用しようという意思決定がある企業で出たなら その企業の経営者が問題の本質が何なのかを まだまったく分かっていない可能性があるわけです。 つまりエンジニアの概念からもう少し進んだものが いわゆるFDE、Forward Deployed Engineerというものですが 今後はFDEよりもさらに少し進むと思います。 私はAI native talentと 個人的に今呼んでいるのですが もうすべてを備えた人がいます。
AIを使う人材需要と問題解決市場の拡大 37:26
チェ・スンジュン 結局、このAIを供給する側から見れば 誰であっても関係ないわけじゃないですか。 AIを使う人が結局は 自分たちの何らかの顧客になるわけなので、誰であっても関係なく エンジニアであれビルダーであれ そのAIを使う人を必要とする 職業が減っていくのではなく 増えていく局面もあり得るのだな、という考えは Simon Willisonの話を見ながら持つようになったんです。 私もその点には同意します。 これからは実際、人がやるべきことがもっと増えるじゃないですか。
ロ・ジョンソク それにその時、ジョンギュさん代表もその話をされていましたよね。 人々は問題を解決する速度より 問題を作る速度のほうが速いので 需要はまたかなり増えるはずです。 そして今、私たちが伝統的にエンジニアと呼んでいた概念は おそらく一つ下のlayerに降りていって これからinferenceをどうさらに速くするのか、 高度なtoken engineering、infrastructure engineering、model building、 そういう方向に移っていくのではないかと。 AXがもし成功するなら
チェ・スンジュン AIをうまく使える人材になるわけですから その人は雇用を維持して さらに新しいAIを使ってくれる人が まだ必要なステージだとすれば 雇用が増えることもあり得るのだな、という考えを Simon Willisonの話を見ながら少し持ちました。
APIコスト上昇とオンプレミスモデル需要 38:50
チェ・スンジュン ただ、わからないことではあります。 それでここの後半は、AIのせいで コストが大きくなった。 ところが今これが、11月に人々が 去年予算を組んで 今年の予算を使っているので gap、つまり差が発生しているのであって、 これからなら、それもまた調整できるはずだという 感覚的な感覚として私は読みましたが とにかく今、4月頃が一度大きな変曲点になったというのが Simon Willisonの話でした。 それでここは今、私が途中を少し飛ばしたんですが 研究所の何らかの投資が引き続き どれほどこれを支えられるかはわかりませんが 進んでいて、 API売上の重要性は下がっている。これがどういう話だったのか 今はよく思い出せません。 みんな200ドルのseatに人々がずっと集まっていて、 それに例えば大企業、銀行業界だとか あるいは超大型IPを持って事業をしている会社は Claude Codeのようなものを使うのは少し難しいんです。 だからClaude Code harnessを持って そのままローカルモデルのQwenや GLMのようなものをつないで回す必要があるんですが、 例えばGLM 500Bくらいのモデルや Qwenのそのくらいのモデルはかなり性能がいいんです。 CursorのモデルもQwen baseで作られたと 私たちには知られていますよね。 そのように、ただその中の需要もものすごくあるんです。 大型エンタープライズ内での on-premiseとしての、いずれにせよClaude CodeやCodex。 実際にはもうClaude CodeやCodexがコーディングエージェントではなく ごく基本的なdefault問題解決アプリになったように思います。 それをよく理解しておく必要がありますね。
チェ・スンジュン 結局、私たちが扱うべき問題の規模が どの級のモデルで解くべきかを 細かく把握してうまく配置しないと、 そうでなければ予算に大きなズレが出て あっという間に飛んでいってしまうじゃないですか。
ロ・ジョンソク モデルの性能、私たちがaccuracyと言うべきでしょうか。 モデルの何らかのベンチマーク性能と latencyのtrade-offではないかと思います。 とにかくそういう話も含めて
チェ・スンジュン 私ももう、こうして一日、昨日読んだのに 記憶がよくありません。
夏に予想されるGemini、Mythos、GPT競争 41:19
ロ・ジョンソク 最近、私たちは一カ月が一年のようだと言っていましたが、 二週間が一年のようだと言っていましたが、 今ではほとんど一週間の間にも驚くようなgrowthが
チェ・スンジュン そうでもありますし、何かをたくさん見ているうちに ただ私の認知能力の低下が少し起きているようです。 何かをたくさん見て消化しようとしたとは言うものの 失敗しているわけです。 それでもインデックス程度は残るんです。 まだ、それでも何を見たか、何が重要か、 これを少し紹介してみよう という程度のインデックスに残ったものの一つが 今週はSimon Willisonの記事でした。 これが、4月が変曲点だった。 この部分には私も同意するようになって 振り返ってみると。
チェ・スンジュン そして夏に一度clashがありそうだという 見通しぐらいは持つようになります。 そのAnthropic Mythos級、それに対抗するOpenAIのモデル、 Geminiのモデル、そうしたものが今すべて指し示している方向が 今、明日が6月、明後日が6月なんですが 夏に入っていきながら、これから一度私たちを苦しめつつ また期待させる
ロ・ジョンソク Gemini 3.5 ProとAnthropicのMythosと GPT-5.6程度に代表される世界のメジャープレイヤーたちの そうなると、既存でうまく回っていたものを維持するのか、
チェ・スンジュン それともmigrationして一度すべて入れ替えるのか、 そういうことをまた大騒ぎしてやることになるでしょう。 予定されたことだということです。
ロ・ジョンソク もうあまり残っていません。 二カ月以内に。
チェ・スンジュン だから何かを勉強して自分の力量を伸ばそうとするなら モデルが出たらそのモデルを勉強しなければならないじゃないですか。 つまり集中すべきことに集中できなくなる、そういうことが 今、堂々巡りのように繰り返されていて 私たちが前回DwarkeshやReiner Popeの回で学んだようなことを 学ぶなら早くしなければならない。 そうなんですよ。
モデル性能より重要になるharnessとコスト最適化 43:07
ロ・ジョンソク 私たちが実際、モデルの話をかなりしていないということを 私は強く感じているんです。 これはある一定水準以上を越えた。これの進歩を追うことが それほど重要な話ではなくて これからは次の層の上へ、ギアが少し変わりました。 モデルはもう十分よくなっていて そのよくなることが上で、これがAGIへ行くにせよ行かないにせよ、 私は自分の単位業務をどう最も安い価格で 最も速く解決するのか。 それはモデルの能力とharnessの程度と これらをどううまくalignする のかということを判断する、そういうことが 重要になる時期へ少し移っているように思います。
a16z視点のAIプラットフォームサイクルとインフラブーム 43:51
ロ・ジョンソク それから私は今日の朝だったか、ふと見ていたんですが a16zから出た話があるんです。 私たちがいつも言うインターネット時代、モバイル時代、そういうものにおいて 過去に何らかのテックブームがあったとき どんなことが起きていたのか。いつも最初はチップだとか、 モバイルのときもそうでしたよね。 低消費電力チップだとか、そういうものがしばらく大きな話題で、 QualcommだとかARMだとか そういう会社の恩恵がずっと続いて、 その次がiPhoneやAndroidのような会社で、 その上は実際アプリケーションだったじゃないですか。 その上にUberだとかカカオトークだとか あるいはAirbnbだとか そういう新しい階層のアプリが次々に浮上したのですが、 今AIも同じことをしているように思います。 もしかすると、そう見ると今NVIDIAと ハイニックスやサムスン電子の株価が こんなふうに高いピークをつけているのは、これがピークで もうすぐAIブームは消えます、ということではなく このブームの始まりを告げる序幕にすぎない と見ることもできるということです。
つまり人々にはいつも過去の基準で 未来を評価する悪い癖があるんです。 過去のパターンは繰り返されますが、 そのパターンの中で、このようにy軸として存在する intensity、amplitudeは 相対的にすべて補強、補正して使わなければならないんです。 inflation adjustedをしなければならないわけですが、 以前モバイルでこれくらい行ったから、今回もそれと比べれば ピークだと言うのは、私はかなり間違っている可能性があると思います。
Vinod Khoslaが語るintelligence需要の上振れ 45:30
ロ・ジョンソク そしてKhosla Venturesの Sun Microsystemsを作った 私が尊敬しているおじいさんが一人います。 Vinod Khoslaという方です。 そのVinod Khoslaが これは既存のアプリとは違う。 なぜならこれはintelligenceなので、上限がない。 たとえば無限に、永遠に生きられる薬を、 がんを解決した。では人々はがんを解決したから それで終わるでしょうか。 いいえ。無限に生きたいと思うでしょうし、無限に生きたいというところで終わるでしょうか。 いいえ。もっと美しく、もっと健康な人生を送りたいと思うでしょうし、 それが終わればまた次のものを探すでしょう。これには終わりがない。 人間の欲求は開かれている。 でも過去のあるプラットフォームの移行は いつもそれがdeliveryできる 上限の終わりがぎっしり閉じていたんです。 インターネットが出てきた。すると、まあ市場は少し大きくなるでしょうが、 過去のテレビや新聞などと比べて 何倍。モバイルによって何かが起きた。 するとPCを買えない人も持てるようになるので 何倍にはなるけれど、これはintelligenceです。 ほとんど永遠に需要が増加するという話をしていましたが、 私はその言葉に非常に共感します。
OpenAIとAnthropicのIPO可能性と意味 46:42
チェ・スンジュン 近い未来について、ただ何でも話してみるなら 私はOpenAIとAnthropicが 今年中にIPOをするかもしれないという ニュースをたくさん見ながら、それは分かるのですが、 IPOをすると何が起きるんですか。
ロ・ジョンソク IPOをすると何か、今すでにprivate marketでも fundraisingをするのに何の問題もないので IPOをすれば、それなりに一つのmilestoneになると思います。 今は彼らの会社の立場では 実際private marketで受け取った株式だとか そういうものを構成員が売るのに何の問題もなく、 みんな買いたがっていますし、 IPOに行けば、ただそれに流動性が一気に増えるわけです。 その次に既存の投資家たちに 縛られていた非常に多くのobligationがあるんです。 たとえばprivate roundで Series A、B、C、D、Eというふうに受けていけば valuationを高めることはできますが、 それらには会社の経営陣を締めつける 非常に多くの条件がついてきます。
でもたいていそれらをすべてreleaseして、 投資家たちは5年が会社と 何の関係もなく全員去っていくのが 実はIPOという起点なんです。 public marketに入ると そのときは自由市場競争体制の中で 株価が下がることで反応するにせよ、 あるいは売りたければ売り、 買いたければ買う、そうなるわけですから。 それが継続的に投資を受けてきた会社の立場では それを一度解消するタイミングであり、 また合法的に、もう誰かに依存せず 会社主導でfundraisingを続けることができ、 さらにvaluationを高めることが それなりの順位づけになるじゃないですか。 今見ても1位はどこで、2位はどこで、3位はどこで、 そうするとその人たちの間でも それなりのleaderboardができるわけです。私はIPOした。 会社のvaluationはいくらだ。そういうものを 単純にobjectiveとして刻んで進んでいるのではないかと思います。 ただ私たちのような投資家の立場でもっと重要なのは そのIPOが始まりなのか、終わりなのか。
チェ・スンジュン とにかく4文字のcodeができるわけじゃないですか。
ロ・ジョンソク 見守らないといけませんね。 そうですね。何になるかは分かりませんが
チェ・スンジュン 何と言うか、OpenAIの何か(ティッカー)ができるんでしょうね。 もう全部先取りしておいたんじゃないでしょうか。
100回と3周年以後のハードウェアとinference探究 48:54
ロ・ジョンソク 気になりますね。私たちは次がいよいよ100回ですね。 それで私たちは5月に始めたので
チェ・スンジュン 100回と3周年と、それから登録者3万人を超えましたよね。
チェ・スンジュン いろいろなことが重なりましたが、 いろいろなことが重なりましたが、 淡々と日常のように進めるべきではないでしょうか。
チェ・スンジュン どんなことを少し扱うかという計画のようなものはありますが、 Dwarkesh編で勉強したことの延長線上で こうしたハードウェアをなぜ知る必要があるのか、 今起きていることの基盤となる技術について もう少し深く知ろうと、ゲストの方々に こうしてお話をお願いしているステージじゃないですか。 はい、実際にはエージェント時代になりながら
ロ・ジョンソク inferenceの重要性がものすごく高まっていて、 実際ものすごい量のトークンが押し寄せてきているので、 そのトークン工場の中を一度のぞいてみることに 私たちは意味があると思いましたし、 それに関連してハードウェアの深いところから それらをorchestrationするorchestration layerですね。 その上へ上がっていくソフトウェア領域、 その間を一度見てみようと考えていて うまくやっていけるかは分かりませんが
チェ・スンジュン そういう方向性を少し持っている、という程度でお話ししておきます。
シリコンバレー日程と次回予告 50:07
ロ・ジョンソク そうですね。 それから、もう夏も近づいてきていますし、 またロさんも別のご予定があるようですから その通りです。 私も6月にはシリコンバレーにいる予定なので
ロ・ジョンソク 現地でベイエリアにいらっしゃる方々は、ぜひたくさんご連絡いただければ また近況などを一度共有できたらいいなと思います。
チェ・スンジュン リモートでも一度やらないといけなさそうですね。
ロ・ジョンソク はい、リモートで何回かやることになりそうですね。
チェ・スンジュン 楽しい時間をお過ごしください。
ロ・ジョンソク はい、スンジュンさん。それでは本日はお時間をいただき、ありがとうございました。