EP 99
Opus 4.8 发布、当下 AI 竞争与人的工作
Google I/O与Opus 4.8之后的AI走向 0:00
卢正石 今天录制的日期是2026年5月30日, 星期六早上。 我们学习了几周后回来了, 这期间有 Google I/O, 还有新版 Opus 发布, 世界又一次进步了。 所以关于这些,和胜准一起 看看发生了什么,这些事情的含义是什么, 久违地仔细聊一聊。
Opus 4.8的43天发布周期与更快的模型更替 0:27

崔胜准 是几天前吧。两天前吗,还是昨天凌晨? 总之 Opus 4.8 又突然发布了。 我还没来得及用。 不过我在时间线上大致看了一下情况, 我们就从这个话题开始吧。 所以现在有一篇博客文章, 我也查了一下日期。 我把标题写成“两个月以内的节奏”, Opus 4.7 是4月16日发布的。 所以到现在正好大约一个半月。 因此 Opus 4.7 发布的时候, 我们大概是在19号录制的,当时是说 最近 Opus 的发布间隔大约是70天。 那就是略超过两个月的间隔。 但这次等于是隔了43天就出来了。 是啊。原本预计大概是两个月一个周期
卢正石 来运转,现在变得更短了。
崔胜准 两个月并不是随便说出来的, 而是到处都能听到的说法。 所以在 Reiner Pope-Dwarkesh 那一期里, Dwarkesh 在谈到解 flashcard 等问题时, 说现在这些模型似乎已经相当于 Chinchilla optimal 的100倍左右 over-trained, 所以才会提到“两个月”这个说法。 也就是说,如果 frontier model 部署了两个月, 它每两个月就会 retire, 过去似乎有这样一种模式, Dwarkesh 也是以这个为前提的。 在这种情况下,它是用多少 token 训练出来的, 该说是非常粗略吗, 总之是很粗疏地估算了一下, 其中就出现了“两个月”这个说法。 也就是说,每两个月就有新模型出来, 然后 retire,存在这样的模式。 另外这也是被转成国内新闻的内容,
Sam Altman 在澳大利亚活动上视频对谈时, 媒体提炼出了“两个月世界就变了,公司还需要年度计划吗” 这样很刺激的句子, 总之 Sam Altman 似乎说了类似语气的话。 所以我原本以为这个“两个月” 是2026年的某种模式。 结果这次是43天,我也有点惊讶。
迈向奇点的开发速度加速 2:43
卢正石 不过这不就是我们说 싱귤래리티 的时候 一直预想的事情吗。
崔胜准 这个周期会持续缩短。 发展速度开始不断增加,
卢正石 到某个时间点就会变成无限增长的那个时刻。 而那个点就被称为 싱귤래리티, 现在就是在朝那个点前进。
Anthropic的Opus效率化与Mythos级模型预告 3:05
崔胜准 在 Anthropic 的博客里,比起 benchmark 之类, 我对最后那段话印象更深,我读一下。 用户会感觉到 Opus 4.8 相比之前的模型 实现了虽小但明确可感知的改进。 仍然还有工作要做。 我们正在努力开发并发布一种模型, 它能够提供许多与 Opus 相同的能力, 但使用成本更低。 并且我们计划发布
具备更高智能的新一系列模型。 所以 Mythos Preview 现在有少数组织正在使用, 之前说过,等安全机制准备好后就会公开。 而这个安全机制的准备工作 正在快速取得进展,所以预计未来几周内 就能向所有客户提供 Mythos 级模型, 他们是这样期待的。 所以“未来几周”应该是10周以内吧。 我会理解为低于10这个数字, 那最多就是两个月,对吧?
卢正石 感觉像是在调整这个模型 range,也就是量级。 现在 Mythos 会成为新的 Opus,Opus 会成为 Sonnet, 其实现在 Sonnet、Haiku 除了几个 真的很像 embedding 模型的 这种单位任务之外,基本已经名存实亡了。 大家用 Claude Code 的时候也都接 Opus 来用。 所以无论如何,Opus
崔胜准 名字会怎么变还很难预测, 但更高量级的模型会出来, 那大概会横跨夏天,从夏天到初秋, 不过看现在的模式,会不会就是这个程度。 我原本以为6月或7月 会有什么 Opus 4.8 之类的东西出来, 结果它在5月底就出来了。 所以如果把这个也往前推来估算, 我就会想,大概7月左右 会不会发生什么事情。 7月或者8月。 所以这样一来,又会有新的需要 unlearning 和学习的东西, 但我还完全没开始。
Gemini 3.5 Flash与夏季模型竞争的信号 5:12

崔胜准 不过我们原本只是期待会有一个大事件, 最后打开盖子一看,其实还有一个之前没提到的 Google I/O。 Google I/O 上 Gemini 3.5 Flash 是主角。 也就是说 Pro 还没有准备好。 但听 keynote 的内容, 他们一直在说那件事。 几周之后我们应该能够公开下一个东西。 可能会在夏天前后,他们说了这些话。 所以这个时间点正在对上, 现在方向上看,夏天 Google 也会在当前局面下 当然是在全公司、全方位地防守, 但感觉并没有特别大的一击, 而他们正在准备那些东西,不管那会是什么, 接着 Anthropic 现在是在抢先出手, 但关于性能的讨论 时间线上仍然是在谈 GPT-5.5。 也在谈 Codex,所以 GPT-5.6 出来的时机, 在 Opus 4.8 感觉还没能击败 GPT-5.5 的时候不会出来, 等到差不多开始出现这种说法时,就会出来吧。
以Token经济和延迟为中心的模型选择 6:26
卢正石 大概是。不过 Anthropic 也 前面用了“变小的模型”这个说法嘛。 Opus 4.8相较于Opus 4.7或Opus 4.6, 确实更小,也更高效了, 但性能仍然保持住了,是这种形态的模型, 他们是这样说的;而且从外部看到的基准测试、 以及人们的反应来看,也没有说Opus 4.8的性能 好像下降了。 对。确实也有几个是这样。 基准测试指标里,
崔胜准 实际上也有一些相比Opus 4.7下降的。 也有提升的。 所以这最终不就是为了在这种token economics里 活下去而拼命挣扎吗? 因为现在是持续变化的时期嘛。 以前汽车行业也是这样,
卢正石 汽车曾经有过拼排量的时期。 所以4,000cc、5,000cc、6,000cc这样不断出来, 等到效率优化到某种程度之后, 商业运营上就会说,这个程度已经足够了, 于是进入了一个有点变得flat的时期, 我觉得模型可能也会这样。 其实我们最近大部分工作,
如果说起来,就是和Codex或Claude Code, 或者由这些组成的agent system进行interaction, 我感觉这正在变成公司的工作。 以前大多数人的屏幕上可能是邮件、PowerPoint 和Excel开着, 现在屏幕上几乎都是agent application开着。 我们公司干脆朝那个方向 几乎全都改好了,所以大家基本都贴在Slack上, 只靠和agent一起工作就能把事情做完, 我们正在往这个方向打造。 不过让人觉得遗憾的部分是latency。 我觉得接下来会聊到这个。
因为如果某个结果已经令人满意, 那接下来想要的当然就是它必须快点出来。 而如果那个latency能在既定质量内达成, 那不管它是不是Opus,或者什么最高端模型, 都会出现一种“又快又好”的模型概念。 这就是Google这次把Flash模型作为主打 推出来的理由。 感觉他们一直在触碰这些东西。
崔胜准 但是一旦人们发现性能出不来, 就会马上升到上一层tier, 我觉得最近正是在探索这些东西。
Gemini Flash的Doom启动演示与长时间任务 8:44
崔胜准 关于Gemini 3.5 Flash, 我印象最深的是这个视频。 是Varun Mohan展示的。 好,要不要看一下?
崔胜准 所以这是Varun Mohan做demo的时候, 感觉先读完这个再看会比较好。 运行了93个subagent, 通过1万5千多次model call, 让它从零开始编写custom kernel、filesystem、driver, 12小时后Doom启动了。 就是这个。所以把这个一路翻下去的话,
会看到这些事情都是Antigravity自己做的, 它做出了OS,后来还在里面运行Doom, 这里好像没有出现运行Doom的部分, 这个应该是在展示source现在是怎么 发生变化的。 Varun Mohan展示的那个里面, 还展示到了那个全都跑起来的画面。
所以最终像这种long-horizon任务, 用较低的token消耗来完成;不过Gemini 3.5 Flash 好像比以前的Flash贵了3倍。 也就是说,用适当水平的模型 把这类事情完成, 这种展示还是挺让人印象深刻的。 所以我觉得大家都想做这个,
Anthropic Dynamic Workflows与子代理协调 10:00
崔胜准 这次Dynamic Workflows也和Opus 4.8一起出来了。 这已经不是Google I/O的消息了,又回来了,对吧? 对吧? 现在回到Anthropic的消息,
卢正石 说说昨天出来的Dynamic Workflows。
崔胜准 比如说使用ultracode这个表达, UI就会变得很华丽, 又会出来一些挺有意思的东西。 不过这里好像没有出现到那个程度。 可以先随便快速看一下。而且最近Claude 好像主打这种可爱的概念。 视频做得很漂亮。 因为只是很快地掠过去, 很难仔细看清具体是什么内容, 但感觉还是在尝试做一个app。 这是演出效果,所以实际可能没有转得那么快。 就是把checklist一项项完成, 然后push、merge,说是可以做这些事情。 这里并没有介绍Dynamic Workflows, 但就是会以这种方式来做。
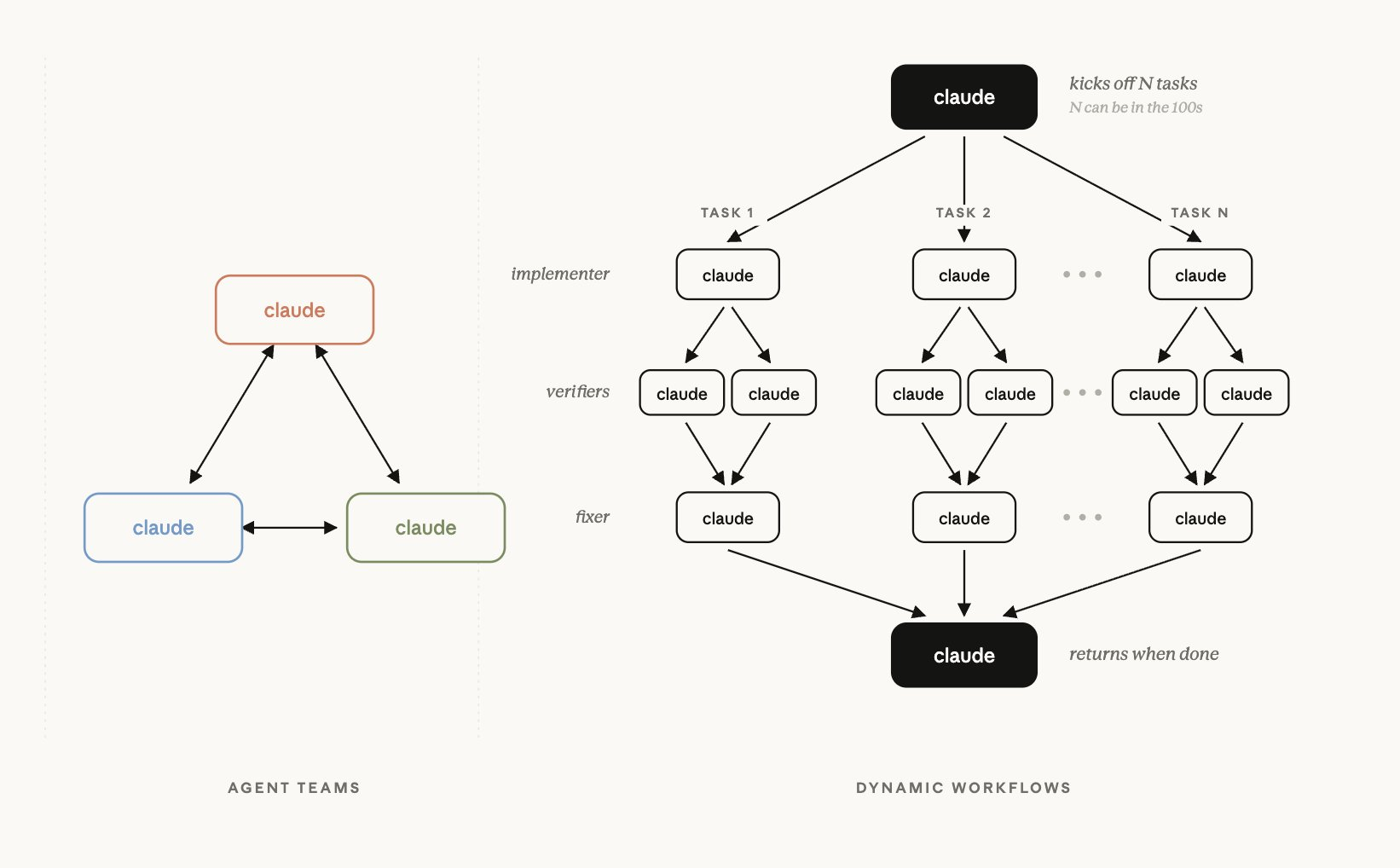
所以Dynamic Workflows是什么呢? 看Cat Wu发的推文, 就是像这样有一个Claude,把任务交给多个其他Claude, 那边再交出去,然后进行汇总、再汇总, 所以其实这是我们这段时间看过很多次的那类概念, 但它会和Anthropic现有产品Agent Teams有点不同。 不过这里有意思的一点是, 并不是由大模型一直来协调这个过程, 而是一开始就用确定性的代码写好要如何orchestration, 然后一直执行到它完成,感觉是这样。
卢正石 那也就是说,现在不是由模型全部读取这些分支点, 然后在中间逐一判断, 而是在最开始生成某种,该怎么说呢? 应该叫dynamic harness吗, 生成这种harness之后。 感觉就是这样。
崔胜准 我也还没用过,所以不能说得很准确, 但看了几个视频和这篇文章之后, 感觉它就是用来协调subagent的JavaScript。 所以Dynamic Workflows, 从某种角度看,如果交给模型去做, 其实模型会偷懒嘛。 让它评价自己做过的事情, 让它自己评价时,就会谎称已经做好了, 尤其是让它做困难工作时会出现这种情况。 如果想把这类事情的执行次数收紧一些, 就需要用确定性的工具和代码来检查, 但如果又让它在自己的context里 进行评价,那就会出问题。
所以干脆在全新的context,也就是subagent们里面, 在那些情况下,把那个一步步处理好, 当然,当它是这种方式的时候, 也就是像刚才那张图里的方式时, 这个汇总的问题在于,要一直等到汇总完成, 怎么说呢,有点像 pipeline parallelism, 我确实觉得这里会出现问题, 但无论如何,抛开那个时间问题不谈,就是以这种感觉上的方式完成了 某种新的东西的介绍。 可是时间线上的反应里,“我们也做过那种东西啊” 这种说法特别多。 说这是已经存在的概念,Anthropic 只是稍微早一点之类的。 是的。而且从概念上说,我们的 oh-my-openagent、
卢正石 OMX 这些地方也一直很好地运行着这种概念。
崔胜准 时间线上确实有一些 类似诉苦或虚脱感的反应。
Managed Agents与Recursive Language Models的关联 14:00

崔胜准 不过在这篇博客文章里, 虽然没有出现,但在之前讨论 Managed Agents 的 那篇类似“把大脑和手分离”的文章里, 引用过一项很有意思的研究, 这里称为 prior work。 现在来看,比如说, context 可以成为一种 object, 是哪里的 object 呢?是 REPL,所以是 REPL。 也就是说,REPL 是一种编码工具嘛。 是带有 feedback loop 的 read-eval-print loop 吗? 我突然想不起来了, 总之我们平常经常说 我们使用 REPL, 而这是让 LLM 能够 programmatically 去做那种事情, 借助某种决定性的工具来实现的感觉。 不过这里引用的论文 是一篇叫 Recursive Language Models 的论文。 所以这位 alex zhang 说了这样的话。 他说请读一下我们的 paper。 这是已经存在过的某种 regime。 这么说的并不只有这一篇。 不过这个叫 RLM 的东西已经进了 DSPy。 所以,
卢正石 不过那篇 RLM 论文的作者里有 Omar Khattab, Omar Khattab 是在 Stanford 做出 DSPy 的人, 所以我觉得当然会放进去。 我不太了解 DSPy,只是知道有这么个东西,
崔胜准 也知道很多人在讨论它这种程度, 但这种做法 好像又逐渐变成了一种 trend,所以,
从DSPy和TextGrad看元优化 15:40
卢正石 只要看看 DSPy、还有 TextGrad, 以及刚才说到的那些东西, 它们某种意义上都是 meta optimization。 胜准,所以归根结底,只要堆上一层 layer, 在那层 layer 之上又会堆起别的东西, 再在那层 layer 之上继续堆, 所以可以理解为是把 optimization 的层级 再往上抬一层的感觉。 DSPy 归根结底也是说,某个 prompt 本身的性能 也可以通过跑某种 meta optimizer 来持续提升。 这和 Karpathy 说的 auto research 概念是一样的。 无论什么问题,只要存在 evaluation metric, 模型不管我们设定成什么, 都可以直接投入 optimize computing, 转换成提升性能的方向,也就是转换成搜索的方向, 然后来解决。我觉得这是它的核心概念。 看这里的话,随便读几个,
崔胜准 让 LLM 做 code execution, 以及 recursive sub-LLM call, 这是 DSPy 那边,也就是 RLM 里讨论的内容。 然后在 Managed Agents 里, 是把 session abstraction 作为 context 外部的 object, 并使用 sandbox 和 REPL, 这里存在这样的连接线。 接着 Dynamic Workflows 是在 orchestration 它的时候, 把某些东西放在 script 里,而不是 context 里。 所以这些决定性的工具, 归根结底是 harness 在做那些事情。 因此它正在走向一种利用 script 把它牢牢收紧, 从而进行控制的感觉。
不过大概那个 Gemini 3.5 Flash, 刚才那个快速运行的视频里想表达的 隐藏内容,我推测也在类似的层级。 不是单纯由模型来做, 而是使用做这件事的 scaffold 或 harness 来制作 OS, 达到可以直接启动 Doom 的程度, 一口气完成 long-horizon task。
卢正石 就是这样。 那个 long-horizon task 其实往里面看, 与其说是干净利落地 one-shot 完成, 不如说是面对无数 error,对吧,那些 error, 不断地跑 evaluation, 发现这个错了,就改完回来,又发现这个也错了, 再改完回来,是一种所谓的 tinkering 过程。
崔胜准 非常庞大。数学里发生的事情也很类似, 提出假设,然后实验它,发现出问题了。 记录下来,再从记录中获得洞察,提出下一个假设, 然后把这个过程一直推进下去。 是的。所以刚才介绍的那篇文章,
卢正石 归根结底只是把对应于这个模型的 objective 换成了什么, 这一点不同而已,实际使用的方法论其实是同样的 meta。
Code as harness与Cloudflare Dynamic Workflows 18:27
崔胜准 Corca 的 CTO 圭英在说这类话时, 圭英用了一个很有意思的表达, 说的是 code as harness。 我听了之后觉得这个表达很顺耳, 同时圭英还介绍了 Cloudflare 的 Dynamic Workflows 和这个 Project Think, 这个我之前并不知道。 不过这里名字也一样。 也是 Dynamic Workflows。 所以这里也是在下一代 agent 构建中, 也就是说成为 code as harness, 因而不管拿来什么东西,都能把它完成, 通过做某种 cloud platform, 同样的话又出现了。 长期运行的 agent、actor model、Durable Objects。 所以大家都在朝这种方向走, 即便不是很详细, 我也只是从感觉上把握到了这一点。
企业代理应用中增长的延迟和harness需求 19:22
卢正石 是的。我也每天在我们 Slack 上看到我们公司成员 让 agent 去做 task 的情况, 那么只要让 agent 做相当复杂的事情, 基本都会跑二三十分钟,再怎么短, 也会跑十分钟。 于是就会不断产生对 latency 的需求。 还有那个 harness 也是, 现在我们 主要在用已经现成的 harness, 但也不断产生一种需求, 觉得我们应该用属于自己的 harness。 没错。 不过以后有机会我也想介绍一下,
崔胜准 我一年前用 Minecraft 做 agent 的事情, 最近又重新开始看,发现世界已经不一样了。 昨天睡前跑了一个 10 小时的任务就去睡了, 早上起来发现好像有成果了。 不过看那个过程的话,在 Minecraft 最新版本里, 现在叫 Mineflayer 的那个接 bot 的东西, 开源项目还没完全跟上, 所以我就从底层自己做了一遍, 做的时候推测 protocol、提取 block ID, 然后一点点搭起来,真的很有意思。 以后我再介绍给大家。
卢正石 现在有种感觉,就是只要去思考就可以了。 不过遗憾的是,早上起来一看,
报告说 Codex weekly limit 只剩 8% 了, 也就是说会用掉很多 token。
AI解决的Erdős问题与数学研究的变化 20:42
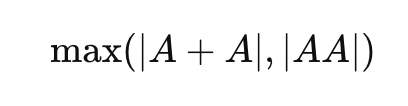
卢正石 所以和这些事情分开来看, 数学领域在 5 月也发生了一些有趣的事情, 这件事也有关系,刚才我也稍微提到过, 我确实感觉是有关联的。 我自己也不是深入研究数学的人, 所以只是大致看了一下, Erdős 问题中的一个, Erdős 问题有很多种, 其中一个问题,模型成功解了出来, 5 月中旬有一段时间,世界又因此有点震惊。 OpenAI 做到这件事的不是 GPT-5.5, 我猜这应该是内部模型。 似乎是用内部模型加上特殊的 scaffolding 做到的。 然后 Sholto 现在不是在 Anthropic 吗? 所以他先称赞了一下这件事, 然后又发帖说 Mythos 也做到了。 不过我这里虽然没有放链接,但也有说 Gemini 也做到了, 有这样的消息。 也就是说类似的事情大家都做到了。 不过除了那件事以外,我觉得有意思的是, Noam Brown 的这个说法很有意思。 所以这个顺着链接点进去, 会不断跳到其他人的内容, 我把它翻译放在这里了。 不过虽然翻译了,要读懂意思还是很难。 但无论如何,都是数学领域的人 在说这是一件非常有意思的事。
像AlphaGo之后的围棋一样变强的人类数学家 21:59
卢正石 我先介绍 Noam Brown 的说法, Noam Brown 说,AlphaGo 之后,人类围棋棋手的水平 明显提高了。 我认为数学中也会出现类似的模式。 所以这指的是这个故事, 数学家们讲的故事是什么呢, 不是 OpenAI 的模型解出来的那个故事, 而是数学家们解出来的故事。 也就是说,在大家知道 模型解决了那个 Erdős 问题之后, 数学家们也受到了启发, 出现了某种迅速推进的现象。 所以这点太有意思了。 这里的 Timothy Gowers 也是非常有名的数学家。 他说这一次,加法组合论中的另一个问题, 一个重要问题被解决了。 这一次不是 AI,而是人类做到的, 但他们使用了和 单位距离猜想的 AI 解法相关的方法。 也就是说,他们学习并利用了 AI 的解法。 这就像申真谞九段等人做的事情一样, 他们通过大量和 AI 对弈来学习。 现在发生的就是这样的事情。 这次 OpenAI 的那个尝试也很有意思, 因为它给了人类一个非常重要的角色。 不是模型独自推进完成, 而是让人类正确地进行评估, 加入了某种这样的机制, 所以和以往的尝试有些不同。 也就是说,human in the loop 开始给人一种被稍微更重要地对待的感觉。 这是我和 GPT 一起读到的内容, 就像 AlphaGo 之后人类围棋变强一样,AI 在数学中 是不是也开始扩展 人类的探索空间和直觉了,就是这个意思。
卢正石 感觉这太理所当然了,肯定会这样。
崔胜准 OpenAI 这次在 Erdős 问题上也是, 如果只是一个人类数学专家, 即使在数学的一个领域内部,也有很多不同类型, 有精通数论的学者,也有精通组合论的学者, 但他们可能并不了解彼此的文献。 可是 AI 通过 pretraining 了解整体情况, 所以能够做到把那些文献之间连接起来, 这种意味是很强的。 所以人类从这些事情中受到刺激, 如果意识到人类也可以连接这些东西, 就有可能进行迁移, 我读到的是,这类事情已经开始发生的信号。
所以这里这些只是我和模型对话的内容, 虽然挺有意思,但我就先快速略过。 所以这是改变人类创造性地形的事件。 而不是杀死创造性的事件。
生成式认知下降与intelligence augmentation的共存 24:31
崔胜准 我最近一直在思考的事情是, 我在去年春天左右说过 “生成式消化不良”这个说法,而最近在想的是, “生成式认知下降”。 如果总是把自己的思考 offloading,委托给模型, 让模型代替自己思考, 就会感觉自己的思考能力、思考肌肉在减少。 还有在学习 Dwarkesh 那一期的时候, 我也受到了 flashcard 的刺激,深入对话之后, 如果针对那些内容做 flashcard 来提问, 就会发现很多东西我很快就忘掉了。 让它代替我生成,其实会造成认知下降。 也就是说,skill 在减少,我自己的能力在减少, 我强烈感受到这种感觉,所以一直很苦恼。 这些事情现在显然正在发生。 令人担忧。不过另一方面, 也确实存在完全进行 intelligence augmentation 或者 amplification 的部分。 所以这次的局面现在果然也是 技术是不是又在作为拉开差距的工具发挥作用 我会有一些这样的思考。 我原本以为越接近超智能,或者越接近 AGI, 它就会成为某种把差距变薄的东西, 会成为机会,一个全新的、前人未至的机会, 去年夏天我曾这样想象过。 但实际打开盖子一看, 这东西像 slot machine 一样让 dopamine 爆发, 事情当然也能做成, 但我的能力本身可能正在下降, 另一方面,也有人正在获得能力。 这点让我不得不思考。
AI时代正在改变的工作与人的条件 26:05
卢正石 这个又取决于怎么看视角, 似乎会以正反合的形式不断变化。 眼下看起来像是在扩大差距,但从结果看, 应该会把差距大幅缩小,
崔胜准 平均水平有可能会上升吧。 不管怎样。
卢正石 是的。以前“工作”的概念,和我们现在想的 这个概念,好像会变得完全不同。 以前比如说盖房子, 如果说单位时间内能搬多少土, 那当然体力和技巧, 这些就是那个人的能力值。 但像挖掘机、铲车 这样的机械出现之后, 事实上现在就变成了资格考试, 变成驾驶执照考试了嘛。 就像那样,我们 虽然现在还没有形成清晰的图像, 但和知识产业相关的部分,如果过去我们是用思考的肌肉 来解决问题, 那么它会变得不再需要,而会出现另一种形式、另一层级的 某种新的资格证或能力, 应该要这样看吧。 我们现在也天天用 agent 工作, 所以对于到底什么才叫把工作做得好, 我自己也有很多各种各样的思考。 虽然不是今天要展开的话题, 但这真的是很令人苦恼的事情。
崔胜准 因为它和人的条件相连,思考 曾经是人的工作嘛。 可是这件事正在转移,所以相当令人苦恼。
崔胜准 就我个人而言。 说思考是人的工作,其实也是一种通念吧。 到底是不是这样。是的,是的。 那我们可以抛出一个有挑战性的问题了。
Simon Willison眼中的OpenAI与Anthropic product market fit 27:40
崔胜准 所以今天话题的最后,稍微再回到现实, Anthropic 和 OpenAI 似乎找到了 product-market fit。 Simon Willison 发这篇帖文让我印象很深。 是 5 月 27 日, 他说 OpenAI 发布了 703 个招聘岗位, Anthropic 发布了 390 个公开招聘岗位, Simon 是用 API 分析出来的。 所以虽然我们不会全部读,但读一下的话, 企业客户现在已经在支付 API 价格了。已经 lock-in 了。 现在已经过河了嘛。 已经没法不用了。 当然。 每人 100 美元、200 美元的套餐,
卢正石 现在几乎都在一人给一个吧?而且不只是工程师, 其他人现在也都在用 Claude Code, 我们这里非工程师 使用 100 美元、200 美元套餐的比例 也在提高。
崔胜准 我原以为广泛使用 agent 的企业 也会拿到类似的折扣。 但后来发现完全错了。它正在变贵, 现在必须支付 API 价格了。 因为没法不付,所以现在对于 usage fee 都在施加惩罚嘛。 Claude 是这样,Gemini 也是这样, OpenAI 目前还可以,但如果也开始对 usage fee 施加惩罚, 如果必须按 API 价格付费,把它放进 Slack 里 就会变得非常贵。 但还是得用。
卢正石 那就得迁到 Codex 上吧。 是的。不过如果 Codex 也撑不住, 到时候又可以换,
崔胜准 所以我认为可能也不能完全放心。
Token价格与AI需求的长期方向 29:11
卢正石 但你怎么看? 这个 token 价格短期来看还有很大的上涨空间。
崔胜准 中国那边也在上涨。 需求在持续增加。
卢正石 看现在内存价格上涨的情况, 需求确实还在持续增加。 不过对这个需求有两种视角。 一种视角认为,该用的人现在都已经用了,基本到头了, 已经到达这个 plateau 了。 但是持这种视角的人, 几乎大多数都是在 tech world 外面的人。 他们站在外部,用投资的视角 解读这件事是这样那样,认为 Anthropic 和 OpenAI 很危险,有这样一股力量。 但在这个圈子内部,对 Jensen 的 keynote 感到狂热, 然后看着 OpenAI 或 Google 的发布 就这样不断鼓掌的 那些科技圈内部的人来看, 很多人会觉得这不是才刚刚开始吗。 不是才刚刚开始吗。token 价格 感觉会变得像电一样,电。 所以那个会怎么发展,
崔胜准 我也不能准确知道。在前一个阶段的预测 当然是会变便宜嘛。 但现在这波 rally,这个峰值 会到哪里我不知道,只是感觉斜率有点变了, 而它又会走向哪里,谁也不知道,不是吗? 但是我从历史上看,
卢正石 押它会下降,肯定是概率值更高的选择。
崔胜准 所以无论如何,企业已经被 lock-in, 而且正在付钱,因为它们正在付钱, 所以至少这两家公司找到了 product-market fit,这是 Simon 的观点。 两家公司都在准备 IPO, 但因为现在很多人都在付钱, 是不是也有可能转为盈利? 有这样的说法。 在 IPO 之前。所以随着这些说法出现,
AI企业扩大招聘与对开发者就业的重新解读 31:13
崔胜准 接下来的就是它们正在扩张。 所以他自己查了一下,发现 OpenAI目前发布了703个公开招聘职位, 其中支持相关的有229个, 还有各种各样的职位。而且其中包括Go To Market 或FDE这类岗位。 Anthropic也发布了390个公开招聘职位。 所以Meta最近因为裁员8000人 又成了一个话题, Microsoft也一直给人一种在缩减的感觉, 但这些领域反而在扩张。
而且最近我们韩国这边的时间线上又出现了 开发者雇佣在增加的部分, 我也看到了一些类似的新闻。 所以现在这是不是也是两件事同时并存呢? 一方面通过提高talent density, 用小团队这样往前推进的事情在发生, 但另一方面,使用AI的开发者 因为AI仍然不能单独完成一切,所以需求更多, 因此增加雇佣,这两件事是在一起发生吗? 我也不是很清楚。
从工程师转向AI native problem solver 32:19
卢正石 我觉得“开发者”这个说法的意义现在已经……
崔胜准 都只是builder了? 对,都是在新的层之上
卢正石 成为了某种problem solver, 如果会使用Claude Code, 要不要把他们称为新的工程师。 现在没有任何一个工程师真的在写代码。 但是现在看那些很擅长解决问题的工程师, 他们是什么样的工程师呢?即便如此,他们对各种层级, 比如AWS上会发生什么问题, 接着Web服务器上会发生什么问题, Redis里该如何分散那个workload, DB优化该怎么做,SQL是什么,C是什么, 从OS整体开始, 从架构设计到服务, 对这些多种部分都具备视角的人, 在遇到Claude Code时会强大得多。 那本来是初级开发者应该做的。 但问题是,也就到那里为止。 客户买的并不是那样的架构。 客户买的是自己的问题被解决。 那么以前什么变快了呢? 当有人说“给我做一个这样的App”时, 那个单元App会产生需求, PM在里面做需求分析, 设计师把它展开之后写PRD, 再把它拆成task,诸如此类, 最后构建出来,把新的UX workflow 放到客户眼前,缩短的只是这一段, 那么拿着它真正去获取更多客户、 解决问题的 那一段仍然是留下来的问题。
那现在就需要在具备这些能力的状态下, 理解客户的问题是什么, 并且不再隔着市场和销售 去应对客户,而是连他们也直接跨过去, 需要具备直接和客户对话的能力。 所以现在要具备这样的工程能力, 能够解决客户的问题, 用我们以前的说法来说, 连市场或销售的能力也都要具备, 这个问题才能一次性结束。 所以现在说工程师招聘在增加的部分, 我觉得需要谨慎看待。 只是传统标准下的工程师数量增加, “你会用Claude Code吗?”“会,我会用”, 这样一个人多坐在公司里一个位置上, 并不会让什么变得更好。
最终还是我们一直在讲的、与客户问题相关的 那个domain里的某个问题解决点, 如何让Claude Code把它做好, 在如何让Claude Code把它做好这件事上, 有工程能力当然会有帮助, 但其实连这样的能力, 在我们用agent构建workflow时, 也会强烈感觉到,它会不断变成某种默会知识, 不断积累在agent的记忆里。 所以以前如果只说“昨天的销售额”, 它可能就会随便hallucinate, 但因为这期间持续积累下来的context, 现在即便只是对我们的agent说“昨天的销售额”, 它也会准确地按照公司想要的视角加工出来。 同样,与这类工程相关的 架构设计等等也完全可以 反而更结构化地变成默会知识, 积累到agent里, 因此从某种意义上说,我们过去拥有的 工程能力也会逐渐稍微变得不那么必要。
因为它会被encapsulation,沉积到下面的layer里。 如果现在更明确地表达,与其说是工程师这个概念, 不如说所有人都是问题解决者,也是单元业务的经营者, 这样定义才是对的。我在公司也会对成员们说, 现在我们使用Claude Code,在传统概念中 做工程工作的那些岗位里, 传统工程师出身的人只有一半。 另一半并不是传统工程师出身。 有以前是市场的人, 也有以前只是PM的人。 甚至这些人一旦结合Claude Code, 已经把工程师们做出来的默会知识prompt 直接拿来,以skill的形式调用起来, 就会有很多问题一次性解决的体验。 现在人力的概念会发生变化。
我认为只是那个术语还没有明确出现。 我们只是把它 统称为工程师而已。 如果某家公司做出了一个决策, 说要招聘一个毫无前提、只要会用Claude Code的工程师, 那么那家公司的经营者很可能 还完全不知道问题的本质是什么。 所以从工程师概念再往前一点, 就是现在所谓的FDE,Forward Deployed Engineer, 但我觉得还会比FDE再往前走一点。 我个人现在把它称为 AI native talent, 也就是有一种什么都具备的人。
会使用AI的人才需求与问题解决市场扩大 37:26
崔胜准 归根结底,从供应这个AI的一方来看, 不管是谁都无所谓。 最终会使用AI的人 会成为他们的某种客户,所以不管是谁都无所谓, 无论是工程师还是 builder 需要那些使用 AI 的人 的职业并不是在减少, 而是也可能存在一个不断增加的阶段, 我是看了 Simon Willison 的说法后才有了这样的想法。 我也同意这一点。 现在其实人要做的事情反而更多了。
卢正石 而且当时 正圭 代表也说过那句话。 因为人们制造问题的速度 比解决问题的速度更快, 所以需求还会大幅增加。 还有,我们传统上称为工程师的概念, 可能会下沉到下面一层, 变成怎样让 inference 更快, 高级的 token engineering、infrastructure engineering、model building, 可能会落到这些方向上。 如果 AX 成功的话,
崔胜准 就会成为能很好使用 AI 的人才, 那个人会维持就业, 而且如果现在还是一个 需要有人来使用新的 AI 的阶段, 就可能出现就业增加, 我看 Simon Willison 的话时有点产生了这样的想法。
API成本上升与本地部署模型需求 38:50
崔胜准 不过这是无法确定的事情。 所以这里后半部分是说,因为 AI, 成本变大了。 但是现在这是因为人们在 11 月 按照去年的预算编制, 今年使用预算, 所以才产生了 gap,也就是差异, 如果从现在开始,应该还能再调整, 我是带着这种感觉读的, 总之现在 4 月左右曾经成为一个很大的拐点, 这是 Simon Willison 的说法。 所以这里我中间稍微跳过了一些, 研究所的某种投资还在持续, 不知道这能支撑多久, 但它正在推进, API 收入的重要性正在下降。这到底是什么意思, 我现在记不太清了。 大家都明显涌向 200 美元的 seat, 还有比如大型企业、银行业, 或者那些拥有超大型 IP 来开展业务的公司, 使用 Claude Code 这类东西其实有点困难。 所以要拿 Claude Code harness, 接上本地模型 Qwen, 或者 GLM 之类的来运行, 比如 GLM 500B 左右的模型, 或者 Qwen 那种级别的模型,性能都相当不错。 Cursor 的模型也是基于 Qwen base 做出来的, 这是我们所知道的。 就像那样,但那里面的需求也非常大。 在大型 enterprise 内部, 作为 on-premise 的 Claude Code 或 Codex。 其实现在 Claude Code 或 Codex 已经不是 coding agent, 而像是非常基础的 default 问题解决 app 了。 那个得好好了解才行。
崔胜准 归根结底,我们要处理的问题规模, 应该用哪个级别的模型来解决, 必须细致了解并妥善配置, 否则预算会出现很大偏差, 一瞬间就直接烧掉了不是吗。
卢正石 模型的性能,我们该叫 accuracy 吗? 模型某种 benchmark 性能和 latency 之间的 trade-off,我觉得应该是这样。 总之包括这些话题在内,
崔胜准 我明明才过了一天,昨天读的, 现在就记不太清了。
夏季预期中的Gemini、Mythos与GPT竞争 41:19
卢正石 最近我们不是说一个月像一年吗, 还说过两周像一年, 现在几乎连一周之间都会出现让人吃惊的 growth,
崔胜准 也确实如此,而且因为看了太多东西, 我感觉自己的认知能力好像有点下降。 虽然说是看了很多东西,也试着消化, 但其实失败了。 所以即便如此,至少还会留下一个索引。 还算能记得我看过什么,什么重要, 这个应该介绍一下, 在这种程度的索引里留下来的其中一个, 这周就是 Simon Willison 的文章。 这件事说明 4 月是拐点。 对这一点我也变得同意了, 回头看才发现。
崔胜准 然后夏天可能会有一次 clash, 我大概会做出这样的展望。 那个 Anthropic Mythos 级别的、与之对抗的 OpenAI 模型, Gemini 的模型,这些现在指向的方向, 现在明天就是 6 月,后天就是 6 月了, 进入夏天之后,可能又会让我们辛苦一次, 同时又让我们有所期待。
卢正石 Gemini 3.5 Pro、Anthropic 的 Mythos, 以及以 GPT-5.6 左右为代表的全球主要玩家们的 那么是继续维护原本运行良好的东西,
崔胜准 还是进行 migration,把它整个推倒重来, 又会折腾这些事情吧。 这是已经预定好的事情。
卢正石 也没剩多久了。 两个月以内。
崔胜准 正因为如此,如果要学习什么、提升自己的能力, 模型一出来就得研究那个模型。 所以该集中精力的事情反而无法集中, 这样的事情现在像转轮一样反复发生, 我们上次在 Dwarkesh 或 Reiner Pope 那期学到的那种东西, 要学就必须快点学。 就是啊。
比模型性能更重要的harness与成本优化 43:07
卢正石 其实我强烈感觉到, 我们已经相当少谈模型本身了。 这个模型已经过了某个水平线以上。去观察它的进步, 已经不是更重要的话题了, 现在齿轮已经切换到下一层了。 模型现在已经足够好了, 至于这种变好往上走,它会不会走向 AGI, 我该如何以最便宜的价格 最快地解决我自己单位工作的任务。 这取决于模型的能力和 harness 的程度, 以及如何把这些东西很好地 align, 去判断这些事情, 我觉得正在进入一个这些变得重要的时期。
a16z视角下的AI平台周期与基础设施热潮 43:51
卢正石 另外我今天早上还是什么时候突然看到, a16z 有一个说法。 在我们一直说的互联网时代、移动时代这些东西里, 过去每当出现某种科技热潮时, 都发生过什么事情呢?一开始总是芯片之类的, 移动时代也是这样。 低功耗芯片之类的东西曾经是很大的议题, Qualcomm、ARM之类的 这些公司一路受益, 接下来就是iPhone或Android这样的公司, 再往上其实就是应用了嘛。 在那之上,Uber、KakaoTalk之类的, 或者Airbnb之类的, 这些新层级的应用陆续冒了出来, 现在AI似乎也在做同样的事情。 换个角度看,也许现在NVIDIA和 SK海力士、三星电子的股价 这样不断冲到高峰,并不是说这就是顶点, AI热潮马上就要熄火了, 而只是宣告这波热潮开始的序幕而已, 可以这样来看。
所以人们总有一种坏习惯, 就是用过去的标准来评估未来。 过去的模式会重复, 但在那个模式里,以y轴形式存在的 intensity、amplitude, 都需要相对地进行增强、校正之后再使用。 也就是要做inflation adjusted, 以前移动互联网走到了这个程度,所以这次跟那个相比 就是顶点了,我觉得这种说法可能很不对。
Vinod Khosla谈intelligence需求的上行空间 45:30
卢正石 还有Khosla Ventures的, 曾经创办Sun Microsystems的, 有一位我很尊敬的老爷子。 叫Vinod Khosla。 但是Vinod Khosla说, 这和过去已有的应用不一样。 因为这是intelligence,所以它没有上限。 比如说,能够无限地、永远活下去的药, 癌症被解决了。那么人们因为癌症被解决了, 就到此结束了吗? 不是。人们会想永远活下去,而想永远活下去就结束了吗? 不是。还会想过更漂亮、更健康的人生, 等那个结束之后,又会寻找下一个东西,这没有尽头。 人类的欲望是开放的。 但过去某些平台的迁移, 它能够delivery的 上限总是被封得很死。 互联网出现了。那么好吧,市场确实会变大一些, 但相较于过去的电视、报纸之类, 也就是几倍。因为移动互联网又发生了什么。 那么买不起PC的人也能拥有它, 所以会变成几倍,但这次是intelligence。 他讲的是需求几乎会永远增长, 我非常认同这句话。
OpenAI与Anthropic IPO的可能性及意义 46:42
崔胜准 如果随便说说近未来的话, 我看到很多新闻说OpenAI和Anthropic 今年之内也可能IPO, 这个我能理解, 但如果IPO,会发生什么呢?
卢正石 如果IPO的话,某种程度上,现在即使在private market里 fundraising也完全没有问题, 所以IPO应该算是某种milestone。 现在从他们公司的角度来说, 其实在private market拿到的股票之类, 成员想卖也完全没有问题, 大家也都想买, 一旦IPO,流动性就会大幅增加。 然后对既有投资者来说, 有非常多被绑定的obligation。 比如在private round里, 从Series A、B、C、D、E这样一路融资, valuation可以提高, 但那些会附带非常多 束缚公司管理层的条件。
但大多数这些都会被release, 投资者们在5年后 和公司再也没有任何关系地全部离开, 其实IPO就是这样一个节点。 进入public market之后, 那时在自由市场竞争体制下, 可以用股价下跌来反应, 或者想卖就卖, 想买就买,就是这样。 对于一直在接受投资的公司来说, 那就是把这个问题解决一次的时点, 而且也可以合法地不再依赖某个人, 在公司主导下继续fundraising, 另外提升valuation这件事, 也会变成某种排名。 现在看也是,第一是谁,第二是谁,第三是谁, 那么在那些人之间 也会形成某种leaderboard。我IPO了。 公司valuation是多少。诸如此类, 我觉得他们可能就是在把这些客观地打点记录下来。 但从我们这种投资者的角度来看,更重要的是, 这个IPO会是开始,还是结束。
崔胜准 不管怎样,会出现一个四个字母的code嘛。
卢正石 要观察才知道。 是啊。虽然不知道会是什么,
崔胜准 怎么说呢,OpenAI会有某个(ticker)出现吧。 他们不是早就都抢注好了吗?
第100期和3周年之后的硬件与inference探索 48:54
卢正石 我很好奇。我们下一期就是第100期了。 因为我们是5月开始的,
崔胜准 所以第100期、三周年,然后订阅者也超过3万人了吧。
崔胜准 好几件事重叠在一起了, 好几件事重叠在一起了, 是不是应该像日常一样平淡地过去呢?
崔胜准 我们是有一些计划,想稍微讲讲要处理哪些内容, 作为Dwarkesh那期学习内容的延长线, 为什么需要了解这种硬件, 对于正在发生的事情背后的基础技术, 我们想更深入了解,所以正在邀请一些嘉宾, 现在就是在这样一个阶段嘛。 是的,其实随着进入agent时代,
卢正石 inference的重要性正在变得极其巨大, 而且事实上,大量token正在涌来, 所以看一看那个token工厂的内部, 我们觉得是有意义的, 与此相关,从硬件深处开始, 到orchestration这些东西的orchestration layer。 再往上到软件领域, 我们正想着看一看这中间的部分。 不知道能不能顺利做好,
崔胜准 但大概是有这样一个方向性,先跟大家说明一下。
硅谷行程与下一期预告 50:07
卢正石 没错。 另外现在夏天也快到了, 而且正石好像也有其他日程, 是的。 我6月份预计会在硅谷,
卢正石 到时候在湾区的朋友们如果多多联系卢正石, 希望也能一起聊聊消息、分享一下近况。
崔胜准 看来我们也得远程做一次了。
卢正石 是的,应该得远程做几次。
崔胜准 祝正石度过一段愉快的时间。
卢正石 好的,胜准。那么感谢今天的时间。